Обход GIL для параллельной обработки в Python
Оглавление
- Вспомним основы параллельной обработки данных
- Сравните многопоточность в Python и других языках
- Используйте параллелизм на основе процессов вместо многопоточности
- Заставьте потоки Python работать параллельно
- Попробуйте: Параллельная обработка изображений в Python
- Создайте графический пользовательский интерфейс с помощью Tkinter
- Определите интерфейс командной строки с помощью argparse
- Отобразите предварительный просмотр загруженного изображения в уменьшенном размере
- Взаимодействуйте С Вашим Приложением С Помощью Событий Мыши
- Напишите функцию на языке Си для вычисления формулы пикселя
- Обрабатывайте цветовые каналы в отдельных потоках выполнения
- Создайте таблицу поиска для общих значений пикселей
- Совместное использование памяти между Python и C с помощью указателей
- Заключение
Раскрытие истинного потенциала Python в плане скорости с помощью параллелизма с разделяемой памятью традиционно было ограниченным и труднодостижимым. Это связано с тем, что глобальная блокировка интерпретатора (GIL) не позволяет выполнять параллельную обработку на основе потоков в Python. К счастью, есть несколько способов обойти это пресловутое ограничение, которые вы сейчас изучите!
В этом руководстве вы узнаете, как:
- Запускайте потоков Python параллельно на нескольких ядрах процессора
- Избегайте сериализации данных накладных расходов, связанных с многопроцессорной обработкой
- Совместное использование памяти между средами выполнения Python и C
- Используйте различные стратегии, чтобы обойти GIL в Python
- Распараллеливайте свои программы на Python, чтобы повысить их производительность
- Создайте образец настольного приложения для параллельной обработки изображений
Чтобы извлечь максимальную пользу из этого расширенного руководства, вы должны понимать разницу между параллелизмом и параллелизмом. Вам будет полезен предыдущий опыт работы с многопоточностью на языках программирования, отличных от Python. Наконец, лучше всего, если вы стремитесь исследовать неизведанную территорию, например, вызывать внешние привязки Python или писать фрагменты кода на C.
Не волнуйтесь, если ваши знания о параллельной обработке данных немного устарели, так как в следующих разделах у вас будет возможность быстро освежить их в памяти. Также обратите внимание, что все примеры кода, файлы изображений и демонстрационный проект из этого руководства вы найдете в дополнительных материалах, которые вы можете скачать ниже:
Вспомним основы параллельной обработки данных
Прежде чем перейти к конкретным способам обхода GIL в Python, вы, возможно, захотите вернуться к некоторым связанным темам. В следующих нескольких разделах вы познакомитесь с различными компьютерными моделями обработки данных, типами задач, абстракциями на современных процессорах и некоторыми историческими фактами. Если вы уже знакомы с этой информацией, то смело переходите к классическому механизму для распараллеливания в Python.
Что такое параллельная обработка?
В соответствии с таксономией Флинна наиболее распространенные типы параллельной обработки позволяют выполнять одни и те же (SIMD) или различные фрагменты кода (MIMD) в отдельных потоках выполнения одновременно:
 Параллельное выполнение задач
Параллельное выполнение задач
Здесь две независимые задачи или задания выполняются параллельно друг другу. Для одновременного выполнения более чем одного фрагмента кода, подобного этому, вам понадобится компьютер, оснащенный центральным процессором (CPU), состоящим из нескольких физических ядер, который в наши дни это норма. Хотя в качестве альтернативы вы могли бы получить доступ к кластеру из географически распределенных машин, в этом руководстве вы рассмотрите только первый вариант.
Параллельная обработка - это особая форма параллельной обработки, которая является более широким термином, охватывающим переключение контекста между несколькими задачами. Это означает, что текущая задача может добровольно приостановить свое выполнение или быть принудительно приостановлена, чтобы выделить часть процессорного времени для другой задачи:
 Параллельное выполнение задач
Параллельное выполнение задач
В данном случае две задачи были разделены на более мелкие и взаимосвязанные блоки работы, которые совместно используют одно ядро одного и того же процессора. Это аналогично игре в шахматы против нескольких противников одновременно, как показано в одной из сцен популярного телевизионного мини-сериала Ферзевый гамбит. После каждого хода игрок переходит к следующему противнику в порядке по кругу, пытаясь запомнить ход соответствующей игры.
Примечание: Переключение контекста делает многозадачность возможной на одноядерных архитектурах. Однако многоядерные процессоры также выигрывают от этого метода, когда количество задач превышает доступную вычислительную мощность, что часто бывает. Таким образом, параллельная обработка обычно предполагает распределение отдельных фрагментов задач по нескольким процессорам, сочетая возможности переключения контекста и параллельной обработки.
Хотя людям требуется время, чтобы переключить внимание, компьютеры работают по очереди гораздо быстрее. Быстрое переключение контекста создает иллюзию параллельного выполнения, несмотря на использование только одного физического процессора. В результате несколько задач выполняются одновременно.
Из-за разделения времени общее время, необходимое для завершения ваших взаимосвязанных задач, выполняемых одновременно, больше по сравнению с действительно параллельной версией. Фактически, переключение контекста приводит к заметным накладным расходам, которые увеличивают время выполнения еще больше, чем если бы вы выполняли свои задачи одну за другой, используя последовательную обработку на одном процессоре. Вот как выглядит последовательная обработка:
 Последовательное выполнение задач
Последовательное выполнение задач
При последовательной обработке вы не приступаете к выполнению другой задачи, пока не завершится предыдущая, поэтому у вас нет затрат на переключение между ними. Эта ситуация соответствует тому, как если бы вы сыграли целую партию в шахматы с одним противником, прежде чем перейти к следующей. Тем временем остальные игроки должны сидеть смирно, терпеливо ожидая своей очереди.
С другой стороны, одновременное воспроизведение нескольких игр может максимально увеличить вашу пропускную способность. Когда вы отдаете предпочтение играм с игроками, которые быстро принимают решения, а не с теми, кому требуется больше времени на обдумывание, вы быстрее заканчиваете больше игр. Таким образом, переплетение может увеличить время ожидания или время отклика отдельных задач, даже если у вас есть только один поток выполнения.
Как вы, вероятно, можете догадаться, выбирая между параллельным, параллельным и последовательным обработка моделей может быть похожа на планирование следующих трех ходов в шахматах. Вы должны учитывать несколько факторов, поэтому универсального решения не существует.
Поможет ли переключение контекста, зависит от того, как вы расставите приоритеты в своих задачах. Неэффективное планирование задач может привести к нехватке процессорного времени.
Кроме того, решающее значение имеют типы задач. Две широкие категории параллельных задач - это Задачи, связанные с процессором и задачи, связанные с вводом/выводом. Задачи, связанные с центральным процессором, только выиграют от действительно параллельного выполнения и ускорятся, в то время как задачи, связанные с вводом-выводом, могут использовать параллельную обработку для уменьшения задержки. Сейчас вы узнаете больше о характеристиках этих категорий.
Чем отличаются задачи, связанные с процессором, и задачи, связанные с вводом-выводом?
Скорость выполнения параллельных задач может быть ограничена несколькими факторами. Вам необходимо определить эти узкие места, прежде чем принимать решение о том, подходит ли параллельная обработка для ваших нужд и как использовать ее в своих интересах.
Скорость задачи, выполняющей сложные вычисления, зависит главным образом от тактовой частоты вашего процессора, которая напрямую зависит от количества машинный код инструкции, выполняемые за единицу времени. Другими словами, чем быстрее может работать ваш процессор, тем больше работы он сможет выполнить за то же время. Если ваш процессор ограничивает производительность задачи, то считается, что эта задача привязана к процессору .
Если у вас есть задачи, связанные только с процессором, вы сможете повысить производительность, выполняя их параллельно на отдельных ядрах. Однако это будет работать только до определенного момента, прежде чем ваши задачи начнут конкурировать за ограниченные ресурсы, и тогда накладные расходы, связанные с переключением контекста, станут проблематичными. Как правило, чтобы избежать замедления, вам не следует одновременно запускать больше задач, связанных с процессором, чем требуется для вашего процессора.
Примечание: Если у вас больше задач, связанных с процессором, рассмотрите возможность постановки их в очередь или использования пула рабочих элементов, например пул потоков .
Теоретически, вы должны наблюдать линейный рост общей скорости или линейное уменьшение общего времени выполнения с каждым дополнительным процессором. Однако это не является универсальным правилом, поскольку для выполнения разных задач иногда требуется разный объем работы.
Процессор - не единственный ограничивающий фактор. Задачи, которые тратят большую часть своего времени на ожидание данных с жесткого диска, сети или базы данных, используют не так уж много процессорного времени. Операционная система может перевести их в режим ожидания и активировать при поступлении фрагмента данных. Эти задачи известны как Связанные с вводом-выводом, поскольку их производительность зависит от пропускной способности базового устройства ввода-вывода.
Представьте себе задачу, связанную с вводом-выводом, как игру в шахматы с одним конкретным противником. Вам нужно только время от времени делать свой ход, а затем позволять другому игроку делать то же самое. Пока он думает, вы можете либо подождать, либо заняться чем-то продуктивным. Например, вы можете продолжить игру с другим игроком или сделать срочный телефонный звонок.
В результате вам не нужно параллельно запускать задачи, связанные с вводом-выводом, для их одновременного выполнения. Этот факт снимает ограничение на максимальное количество одновременных задач. В отличие от своих аналогов, связанных с процессором, задачи, связанные с вводом-выводом, не ограничены количеством физических ядер процессора. В вашем приложении может быть столько задач, связанных с вводом-выводом, сколько позволяет объем памяти. Нередко можно столкнуться с сотнями или даже тысячами таких задач.
Так совпало, что память может быть еще одним фактором, ограничивающим выполнение параллельных задач, хотя и менее распространенным. Задания с привязкой к памяти зависят от доступного объема компьютерной памяти и скорости доступа к ней. Когда вы увеличиваете потребление памяти, вы часто повышаете производительность своей задачи, и наоборот. Это называется компромиссом между временем и памятью.
Хотя в параллельном программировании есть и другие ограничивающие факторы, наиболее важными из них, безусловно, являются центральный процессор и устройства ввода-вывода. Но почему и когда параллельная обработка данных стала настолько распространенной? Чтобы лучше понять его значение в современном мире, вы ознакомитесь с кратким историческим контекстом в следующем разделе.
Почему современные компьютеры предпочитают параллелизм?
Примерно до середины 2000-х годов количество транзисторов в компьютерных процессорах удваивалось примерно каждые два года, как предсказывает закон Мура. Это увеличение привело к постоянному повышению производительности новых моделей процессоров, а это означало, что вы могли просто подождать, пока компьютеры не станут достаточно быстрыми для выполнения задач, требующих больших вычислительных затрат.
К сожалению, бесплатный обед закончился, потому что размещать все больше и больше транзисторов на одном чипе для производителей больше нецелесообразно ни физически, ни экономически. Вместо этого полупроводниковая промышленность решила перейти к производству многоядерных процессоров, которые могут выполнять несколько задач одновременно. Идея заключалась в повышении производительности без увеличения скорости процессора. На самом деле, отдельные ядра могут работать медленнее, чем некоторые старые одноядерные чипы!
Примечание: С технической точки зрения, общее количество транзисторов в новых процессорах по-прежнему увеличивается, но теперь это увеличение распределено по отдельным ядрам. Однако скорость добавления новых ядер намного ниже.
Это изменение в базовой аппаратной архитектуре вынуждает вас, как программиста, адаптировать свой дизайн программного обеспечения к совершенно новой парадигме. Чтобы воспользоваться преимуществами нескольких процессорных ядер, теперь вы должны найти способы разложить монолитный фрагмент кода на части, которые могут выполняться в произвольном порядке. Это создает множество новых проблем, таких как координация задач и синхронизация доступа к общим ресурсам, которые ранее не вызывали беспокойства.
Более того, в то время как некоторые задачи по своей сути распараллеливаемы или, если использовать технический жаргон, невероятно параллельны, многие другие задачи требуют, чтобы вы выполняли их последовательно, поэтапно. Например, чтобы найти n-е число Фибоначчи, необходимо сначала вычислить предыдущие числа в этой последовательности. Такие ограничения могут затруднить, а иногда и сделать невозможным реализацию параллельного алгоритма.
На этом этапе вы понимаете концепцию параллельной обработки и ее значение в современных вычислениях. Следующим вашим шагом должно стать изучение доступных инструментов, которые позволят вам использовать параллелизм в ваших программах. Но вам также необходимо знать об их слабых местах.
Как вы можете использовать мощность нескольких процессорных ядер?
Различные механизмы демонстрируют параллельную природу современных процессоров, предлагая различные компромиссы. Например, вы можете запускать фрагменты своего кода в отдельных системных процессах. Такой подход обеспечивает высокий уровень изоляции ресурсов и согласованности данных за счет дорогостоящей сериализации данных. Что это означает на практике?
Процессы просты, поскольку обычно не требуют большой координации или синхронизации. Но из-за их относительно высокой стоимости создания и межпроцессного взаимодействия (IPC) вы можете создать всего несколько, прежде чем начнете получать убывающую отдачу. Лучше всего избегать передачи больших объемов данных между процессами из-за накладных расходов на сериализацию, которые могут перевесить преимущества такого распараллеливания.
Когда вам нужно выполнить большее количество параллельных задач или обработать гораздо больший набор данных, то потоки являются гораздо лучшим вариантом. Потоки более легкие и быстрые в создании, чем процессы. Они используют общую область памяти, что делает ненужной сериализацию и удешевляет их взаимодействие. В то же время они требуют тщательной координации и синхронизации, чтобы избежать сбоев в работе или повреждения данных, что может быть затруднительно.
Но даже потоки в какой-то момент не обеспечат достаточной масштабируемости . Массово параллельные приложения, такие как платформы обмена сообщениями в режиме реального времени или потоковые сервисы, требуют возможности управлять десятками тысяч одновременных подключений. Напротив, современные операционные системы могут обрабатывать до нескольких тысяч потоков.
Для выполнения такого огромного количества одновременных задач вы можете использовать сопрограммы, которые являются еще более простыми единицами выполнения, чем потоки. В отличие от потоков и процессов, они не требуют упреждающего планировщик задач потому что они используют совместную многозадачность добровольно приостанавливая их выполнение в определенные моменты. У этого есть свои плюсы и минусы, которые вы можете изучить в руководстве по асинхронному программированию на Python.
Примечание: Процессы и потоки, безусловно, являются наиболее распространенными компонентами параллельной обработки. Сопрограммы также популярны, но больше подходят для обработки параллельных сетевых подключений.
Волокна и зеленые нити являются менее известными альтернативами сопрограммам, иногда называемыми микропотоками. По сути, это потоки с совместной многозадачностью и потоки, запланированные пользовательским пространством, а не операционной системой, соответственно.
В Python вы можете использовать микропотоки через сторонние библиотеки, например greenlet или eventlet.
В этом руководстве вы сосредоточитесь в первую очередь на многопоточности как способе повышения производительности вашей программы за счет параллелизма. Потоки традиционно были стандартным механизмом параллельной обработки во многих языках программирования. К сожалению, использование потоков в Python может быть сложным, как вы сейчас узнаете.
Сравнение многопоточности в Python и других языках
Многопоточность обычно включает в себя разделение данных, равномерное распределение рабочей нагрузки по доступным процессорам, координацию отдельных работников, синхронизацию доступа к общим ресурсам и объединение частичных результатов. Однако сейчас вы не будете беспокоиться ни о чем из этого. Чтобы проиллюстрировать проблему с потоками в Python, вы одновременно вызовете одну и ту же функцию на всех доступных ядрах процессора, игнорируя возвращаемое значение .
Потоки Java Решают проблемы, связанные с процессором и вводом-выводом
В этом разделе вы собираетесь использовать Java, но вы можете выбрать любой другой язык программирования с поддержкой потоков, встроенных в операционную систему. Комплект для разработки Java (JDK), скорее всего, не поставляется вместе с вашим компьютером, поэтому вам, возможно, потребуется его установить. Вы можете выбрать одну из нескольких реализаций платформы Java, включая официальную Oracle Java и OpenJDK.
Примечание: В качестве альтернативы вы можете найти подходящий образ Docker с уже установленной Java.
В демонстрационных целях вы реализуете рекурсивный алгоритм для нахождения n-го числа из последовательности Фибоначчи. Формула, лежащая в ее основе, проста и элегантна, но в то же время требует больших вычислительных затрат, что делает ее идеальным эталоном для решения задач, связанных с процессором:
// Fibonacci.java
public class Fibonacci {
public static void main(String[] args) {
int cpus = Runtime.getRuntime().availableProcessors();
for (int i = 0; i < cpus; i++) {
new Thread(() -> fib(45)).start();
}
}
private static int fib(int n) {
return n < 2 ? n : fib(n - 2) + fib(n - 1);
}
}
Вы вызываете метод fib() в отдельных потоках выполнения, создавая столько потоков, сколько насчитывает ваш процессор. Введенного значения в сорок пять должно быть достаточно, чтобы ваш компьютер был постоянно занят, но если у вас мощная машина, то вы можете соответствующим образом изменить это число. Однако не стоит недооценивать этот, казалось бы, простой код. Ваш метод продолжает вызывать сам себя до тех пор, пока не достигнет одного из базовых значений, что приводит к значительному расходу ресурсов процессора при относительно небольших входных значениях.
Примечание: Поскольку каждый вызов функции разветвляется на два новых, пока не будет достигнут базовый вариант, рекурсивная реализация fib() имеет экспоненциальную временную сложность. Другими словами, объем работы, необходимый для вычисления данного числа Фибоначчи, не растет линейно по мере увеличения входного значения. Например, вызов fib(45) примерно в 123 раза дороже, чем fib(35), несмотря на то, что входное значение увеличивается всего на 29 процентов.
Хотя вы могли бы запустить свой исходный код Java напрямую с помощью команды java или использовать интерактивный инструмент JShell, эквивалентный REPL в Python —вы не хотите измерять шаг компиляции. Поэтому лучше всего скомпилировать Java-код отдельной командой, создав локальный файл .class с соответствующим байт-кодом Java .:
$ javac Fibonacci.java
$ time java Fibonacci
real 0m9.758s
user 0m38.465s
sys 0m0.020s
Сначала вы компилируете исходный код с помощью Java-компилятора (javac), который поставляется с вашим JDK, а затем time запускаете результирующую программу.
Согласно приведенным выше выводам, выполнение вашей программы заняло около 9,8 секунд, о чем свидетельствует прошедшее реальное время. Но обратите внимание на выделенную строку непосредственно под этим, которая представляет пользовательского времени, или общее количество процессорных секунд, затраченных во всех потоках. В этом примере общее время работы процессора было почти в четыре раза больше реального, что означает, что ваши потоки выполнялись параллельно.
Это отличная новость! Это означает, что вы почти в четыре раза увеличили скорость своей программы, используя многопоточность Java. Повышение производительности близко к линейному, но не совсем линейно из-за накладных расходов на создание потоков и управление ими.
Рассматриваемый процессор имел на борту два независимых физических ядра, каждое из которых могло параллельно обрабатывать два потока благодаря технологии Intel Hyper-Threading. Но, как правило, вам не нужно быть в курсе таких низкоуровневых технических деталей. С вашей точки зрения, было задействовано четыре логических ядра, о чем операционная система сообщит через свой графический интерфейс пользователя или служебные инструменты командной строки, такие как nproc или lscpu.
Еще один способ доказать, что потоки выполняются параллельно, - это проверить загрузку процессора с помощью инструмента мониторинга во время выполнения вашей программы:
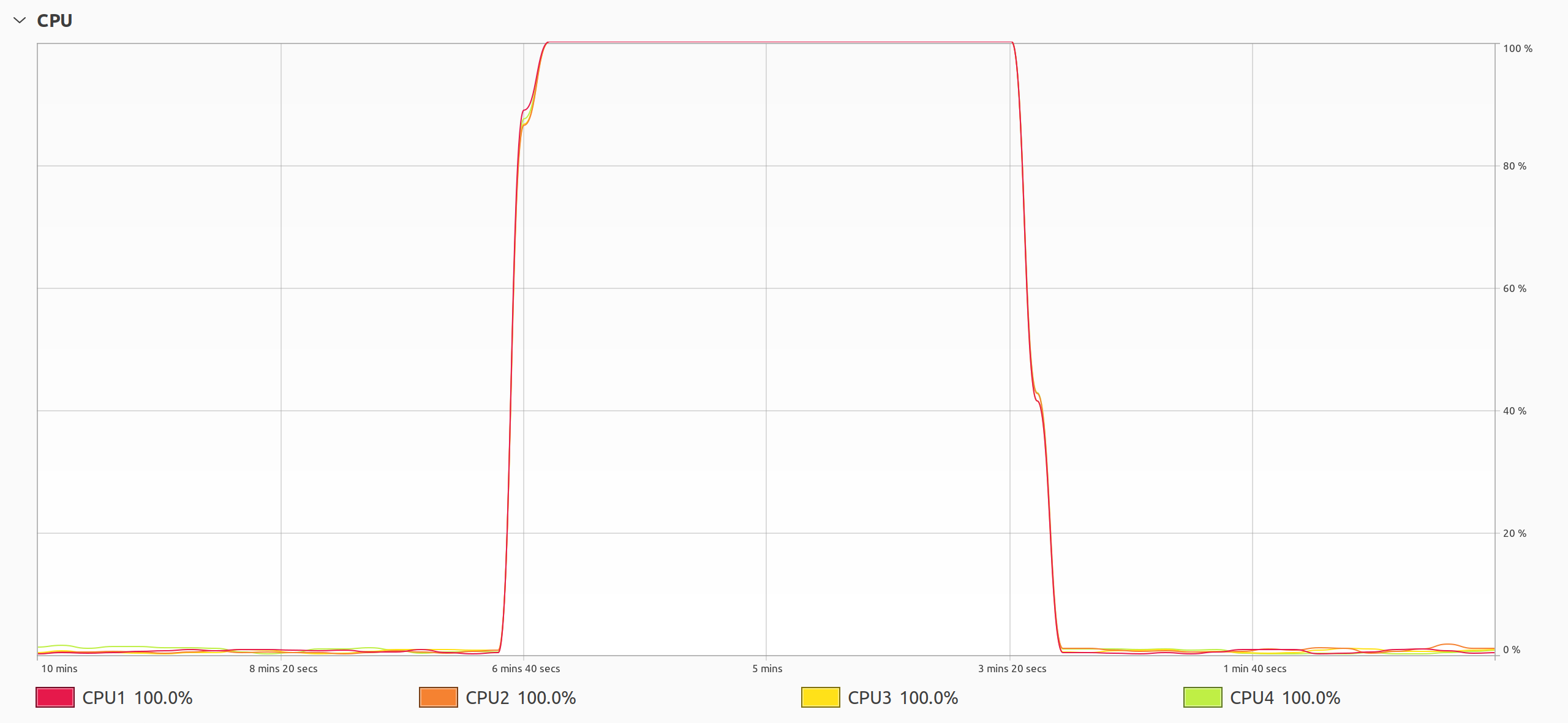 Потоки Java, работающие параллельно
Потоки Java, работающие параллельно
Это график, который вы хотите видеть при решении проблемы, связанной с процессором, с использованием потоков. Как только вы запускаете свою многопоточную программу, все ядра процессора внезапно начинают работать на полную мощность, пока программа не завершится. Вы даже можете услышать, как заработал вентилятор вашего компьютера, и почувствовать, как он выдувает горячий воздух, поскольку процессор работает интенсивнее, чтобы справиться с возросшей нагрузкой.
Напротив, потоки в Python ведут себя совершенно по-другому, как вы сейчас увидите.
Потоки Python решают только проблемы, связанные с вводом-выводом
Чтобы сравнить яблоки с яблоками, воспользуйтесь предыдущим примером. Продолжайте и перепишите свою Java-реализацию последовательности Фибоначчи на Python:
# fibonacci.py
import os
import threading
def fib(n):
return n if n < 2 else fib(n - 2) + fib(n - 1)
for _ in range(os.cpu_count()):
threading.Thread(target=fib, args=(35,)).start()
Этот код практически идентичен своему аналогу на Java, но использует синтаксис Python и соответствующие стандартные библиотечные привязки к потокам. Кроме того, входной аргумент fib() меньше, что объясняет тот факт, что код на Python выполняется на порядки медленнее, чем на Java. Если бы вы сохранили то же значение, что и раньше, то аналогичный код на Python выполнялся бы намного дольше, при условии, что у вас хватило бы терпения дождаться его завершения.
Поскольку Python является интерпретируемым языком, вы можете запустить вышеуказанный скрипт напрямую, не компилируя его явно, и измерить время выполнения:
$ time python3 fibonacci.py
real 0m8.754s
user 0m8.778s
sys 0m0.068s
Теперь затраченное время по сути совпадает с общим временем работы процессора. Несмотря на создание и запуск нескольких потоков, ваша программа ведет себя так, как если бы она была однопоточной. Что здесь происходит?
Чтобы разобраться в этом подробнее, обратите более пристальное внимание на загрузку процессора вашим скриптом на Python:
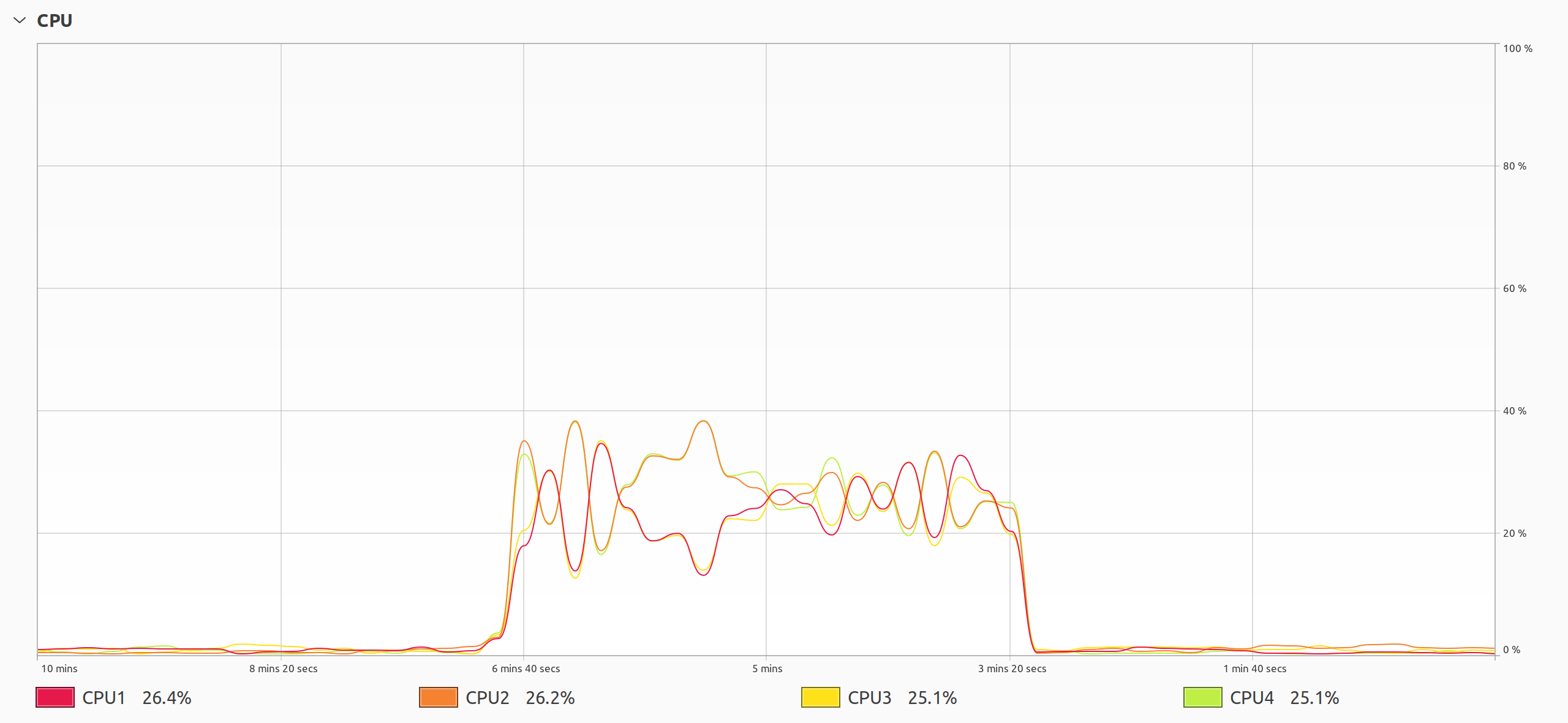 Потоки Python Конкурируют Друг С Другом за центральный процессор
Потоки Python Конкурируют Друг С Другом за центральный процессор
График показывает необычное поведение потоков в Python. Исходя из измеренного времени, можно было бы ожидать, что только одно ядро процессора будет работать с максимальной интенсивностью, однако происходит нечто более зловещее. Все четыре ядра процессора выполняют вычисления, но они задействуют только четверть своего потенциала. Это почти как если бы вы использовали только одно из ядер. Но дальше все становится еще интереснее.
Графики работы отдельных ядер имеют идеально симметричную форму с центром примерно в 25 процентов, что соответствует средней загрузке процессора. Симметрия указывает на непрерывную миграцию задач между процессорами, что приводит к ненужному переключению контекста и конкуренции за ресурсы. Когда несколько потоков борются друг с другом за ресурсы вместо того, чтобы совместно работать над достижением общей цели, это серьезно снижает их общую производительность.
Примечание: В некоторой степени вы можете управлять формами этих графиков, изменяя интервал переключения, который определяет предпочтительную продолжительность непрерывного выполнения потока. Однако этот механизм не дает строгих гарантий и основан на низкоуровневых деталях реализации, которые могут измениться в будущем.
Здесь задействована Печально известная глобальная блокировка интерпретатора (GIL), препятствующая вашим попыткам параллельного выполнения кода на Python. GIL позволяет запускать только один поток в любой момент времени, эффективно превращая вашу многопоточную программу в однопоточную. В то же время планировщик задач операционной системы пытается угадать, какой из потоков должен иметь наивысший приоритет, перемещая его с одного ядра на другое.
Означает ли это, что потоки совершенно бесполезны в Python? Не совсем так. Они по-прежнему подходят для одновременного выполнения задач, связанных с вводом-выводом, или для выполнения различных видов моделирования. Всякий раз, когда поток Python выполняет блокирующую операцию ввода-вывода, для возврата которой может потребоваться некоторое время, он освобождает GIL и сообщает другим потокам, что теперь они могут попытаться получить блокировку, чтобы возобновить выполнение.
Хорошей новостью является то, что потоки в Python, безусловно, могут выполняться параллельно, но глобальная блокировка интерпретатора препятствует этому. Далее вы подробно рассмотрите GIL и потоки в Python.
GIL В Python Предотвращает Параллельный Запуск Потоков
Потоки в Python несколько особенные. С одной стороны, это полноценные потоки, запланированные операционной системой, но, с другой стороны, они используют совместную многозадачность, что является довольно необычным сочетанием. Большинство современных систем предпочитают многозадачность с разделением времени и планировщиком с опережением, чтобы обеспечить справедливое использование процессорного времени во всех потоках. В противном случае жадные или плохо реализованные рабочие процессы могут привести к голоданию других.
Интерпретатор внутренне полагается на потоки операционной системы, предоставляемые такими библиотеками, как Потоки POSIX. Однако это позволяет выполнять только одному потоку, который в данный момент содержит GIL, что требует, чтобы потоки периодически отказывались от GIL. Как вы узнали ранее, операция ввода-вывода всегда приводит к тому, что поток отказывается от GIL. Потоки, которые не используют никаких подобных операций, все равно освободят GIL через определенный промежуток времени.
До Python 3.2 интерпретатор выпускал GIL после выполнения фиксированного количества инструкций байт-кода, чтобы дать другим потокам возможность запуститься в случае отсутствия ожидающих операций ввода-вывода. Поскольку планирование выполнялось — и до сих пор выполняется — операционной системой за пределами Python, тот же поток, который только что выпустил GIL, часто немедленно возвращал его обратно.
Этот механизм сделал переключение контекста невероятно расточительным и несправедливым. Кроме того, это было непредсказуемо, потому что одна команда байт-кода в Python может преобразоваться в различное количество команд машинного кода с различными сопутствующими затратами. Например, один вызов функции на языке Си может занять на порядки больше времени, чем вывод новой строки, хотя и то, и другое - всего лишь одна команда.
Способ выпуска и приобретения GIL оказывает удивительное влияние на производительность вашего приложения. Как ни странно, вы повысите производительность ваших потоков, привязанных к процессору, в Python, если будете запускать их на меньшем количестве процессорных ядер! Добавление большего количества может на самом деле снизить производительность . Это было особенно заметно до выхода версии Python 3.2, в которой была представлена переработанная реализация GIL для устранения этой проблемы.
С тех пор, вместо подсчета байт-кодов, потоки Python запускают GIL после интервала переключения, определенного времени, которое по умолчанию равно пяти миллисекундам. Обратите внимание, что это не точно, и это произойдет только в присутствии других потоков, сигнализирующих о желании захватить GIL для себя.
Тем не менее, новый GIL не устранил нежелательное поведение полностью. Вы все еще можете устранить проблему, установив соответствие процессора для вашего скрипта на Python:
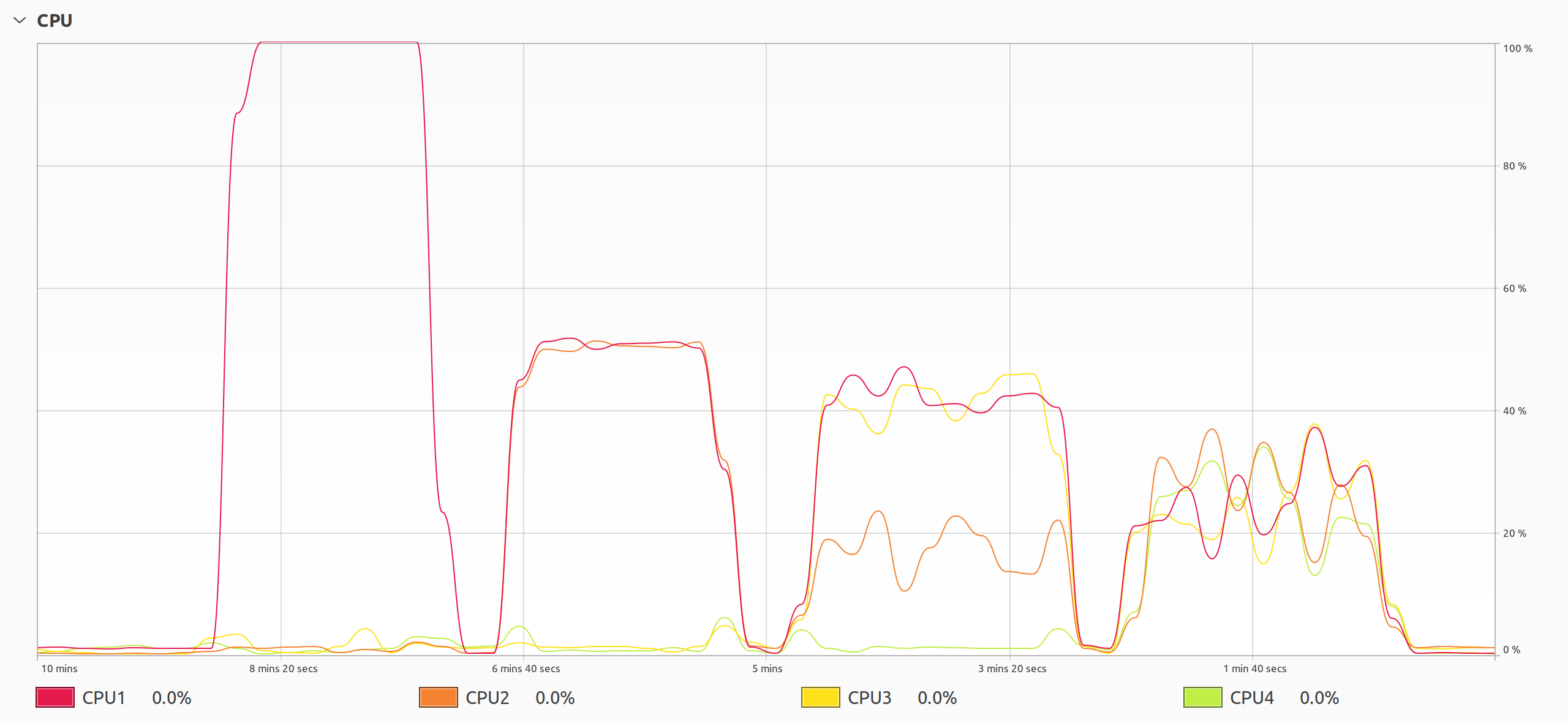 Потоки Python, работающие на одном, двух, трех и четырех процессорных ядрах
Потоки Python, работающие на одном, двух, трех и четырех процессорных ядрах
Если посмотреть слева, вы можете увидеть результаты привязки вашей многопоточной программы на Python к одному, двум, трем и четырем процессорным ядрам.
В первом случае одно ядро полностью загружено, в то время как другие остаются бездействующими, поскольку у планировщика задач нет особого выбора в отношении ядер процессора. Когда два ядра процессора активны, они работают примерно на половину своей мощности. При использовании трех из четырех ядер в среднем используется около трети общего объема процессора, а при работе всех четырех ядер - четверть. Узнаете ли вы знакомые симметричные фигуры на графиках?
Если вы используете Linux, то можете использовать команду taskset для привязки вашей программы к одному или нескольким ядрам процессора:
$ time taskset --cpu-list 0 python3 fibonacci.py
real 0m6.992s
user 0m6.979s
sys 0m0.012s
$ time taskset --cpu-list 0,1 python3 fibonacci.py
real 0m9.509s
user 0m9.559s
sys 0m0.084s
$ time taskset --cpu-list 0,1,2 python3 fibonacci.py
real 0m9.527s
user 0m9.569s
sys 0m0.082s
$ time taskset --cpu-list 0,1,2,3 python3 fibonacci.py
real 0m9.619s
user 0m9.636s
sys 0m0.111s
Хотя при использовании двух или более процессорных ядер нет существенной разницы во времени выполнения, результаты намного лучше при использовании только одного ядра. Это противоречит здравому смыслу, но в этом снова виноват GIL.
Если GIL настолько проблематичен для многопоточных программ с привязкой к процессору, то почему он вообще был частью Python? Вы получите некоторое представление в следующем разделе.
GIL обеспечивает потокобезопасность внутренних компонентов Python
При написании Python не учитывался принцип параллелизма. Сам язык появился незадолго до того, как стала актуальной многопоточность, когда на большинстве компьютеров все еще был установлен только один центральный процессор. Поскольку разработчики микросхем внезапно начали подталкивать программистов к использованию потоков в их коде для повышения производительности, многие библиотеки C не отказались от их использования.
Это стало настоящей проблемой для Python, который не мог обеспечить привязки для этих новых библиотек C, не обеспечив сначала потокобезопасность . Из-за лежащей в основе модели памяти и подсчета ссылок запуск Python из нескольких потоков может привести к утечкам памяти или, что еще хуже, сбой программы.
Было предложено несколько вариантов, но реализация глобальной блокировки интерпретатора показалась мне быстрым способом сделать интерпретатор потокобезопасным, позволяя использовать многопоточные библиотеки C.
Одним из вариантов было переписать весь интерпретатор с нуля, чтобы сделать его потокобезопасным. Однако это потребовало бы огромных усилий, поскольку все в Python было написано с учетом предположения, что всегда существует только один поток. Более того, это привело бы к появлению нескольких блокировок вместо глобальной, что неизбежно снизило бы общую производительность, особенно однопоточного кода. Кроме того, это усложнило бы понимание и поддержку кода на Python.
С другой стороны, GIL предоставил простой механизм для любого, кто хочет написать модуль расширения Python, используя API Python/C. По словам Ларри Хастингса, который наиболее известен благодаря созданию Gilectomy, форка Python без GIL, именно GIL был секретной основой успеха и популярности Python. Это позволило за короткий промежуток времени интегрировать Python с многочисленными библиотеками языка Си.
Несмотря на то, что GIL занимал свое место в разработке Python, на протяжении многих лет было предпринято несколько попыток его удаления с разным уровнем успеха, в том числе:
- многопоточность Грега Стайна (Python 1.4)
- pypy-stm от Реми Мейера и Армина Риго (Python 2.5.1)
- python-safethread автор: Адам Олсен (Python 3.0b1)
- PyParallel автор: Трент Нельсон (Python 3.3.5)
- gilectomy Ларри Хастингс (Python 3.6.0a1)
- nogil автор: Сэм Гросс (Python 3.9.10)
- PEP 703 автор: Сэм Гросс (Python 3.13)
Одной из самых больших проблем, связанных с тем, чтобы сделать Python по-настоящему параллельным, является обеспечение того, чтобы однопоточный код оставался таким же быстрым, как и раньше, без каких-либо потерь производительности. Создатель Python, Гвидо ван Россум, вот что сказал по поводу удаления GIL:
Я бы приветствовал набор исправлений в Py3k только в том случае, если производительность однопоточной программы (и многопоточной, но связанной с вводом-выводом программы) не снижается. (Источник)
К сожалению, до сих пор это было непросто, поскольку некоторые реализации приводили к снижению производительности более чем на 30 процентов! Другие использовали CPython, но так и не смогли освоить основное направление разработки, потому что из-за дополнительной сложности модифицированный код было сложно поддерживать.
В будущих версиях Python предпринимаются постоянные усилия по улучшению параллелизма путем использования нескольких подинтерпретаторов (PEP 554, PEP 683) или создания необязательный GIL (PEP 703). Между тем, вы можете использовать подпроцессов вместо потоков для параллельного выполнения вашего кода на Python, привязанного к процессору. Это всегда было официально рекомендуемым способом выполнения параллельной обработки на Python. В следующем разделе вы узнаете больше о параллелизме процессов в Python.
Используйте параллелизм на основе процессов вместо многопоточности
Классическим способом достижения параллелизма в Python является запуск интерпретатора в нескольких копиях с использованием отдельных системных процессов. Это относительно простой подход, позволяющий обойти GIL, но у него есть некоторые недостатки, которые могут сделать его неуместным в определенных ситуациях. Теперь вы познакомитесь с двумя модулями из стандартной библиотеки, которые могут помочь вам с этим типом параллелизма.
multiprocessing: Низкоуровневый Контроль Над Процессами
Модуль multiprocessing был намеренно создан по образцу аналогичного модуля threading, чтобы имитировать его знакомые строительные блоки и интерфейс. Это делает особенно удобным преобразование кода, основанного на потоках, в код, основанный на процессах, и наоборот. В некоторых случаях они становятся заменяющими друг друга.
Посмотрите, как вы можете изменить свой предыдущий пример Фибоначчи, чтобы использовать несколько процессов:
# fibonacci_multiprocessing.py
import multiprocessing
def fib(n):
return n if n < 2 else fib(n - 2) + fib(n - 1)
if __name__ == "__main__":
for _ in range(multiprocessing.cpu_count()):
multiprocessing.Process(target=fib, args=(35,)).start()
На первый взгляд, самым большим отличием здесь является добавление имя-основная идиома в нижней части вашего скрипта, которая защищает установочный код для нескольких процессов. В зависимости от метода запуска, который определяет, как создаются дочерних процессов, вам потребуется это условие для обеспечения переносимости между операционными системами. Идея состоит в том, чтобы избежать какого-либо глобального состояния в вашем модуле Python, сделав его доступным для импорта из дочерних процессов.
Кроме того, ваш новый скрипт практически идентичен потоковой версии. Вы просто заменили экземпляр Thread на объект Process, но остальная часть кода выглядит примерно так же. Однако вы заметите довольно значительное улучшение производительности, когда запустите свой модифицированный скрипт:
$ time python3 fibonacci_multiprocessing.py
real 0m2.187s
user 0m7.292s
sys 0m0.004s
Этот код на Python выполняется в несколько раз быстрее, чем ваша предыдущая многопоточная версия! На процессоре с четырьмя ядрами он выполняет ту же задачу в четыре раза быстрее. Приведенный выше вывод подтверждает, что Python задействовал несколько процессорных ядер, поскольку измеренное время пользователя больше, чем затраченное в реальном времени.
Но это еще не все. Модуль multiprocessing предлагает несколько новых API для работы с процессами, которые вы не найдете в модуле threading. Например, вы можете создать пул процессов для обеспечения параллелизма данных путем распределения блоков данных по рабочим процессам. Заранее создавая дочерние процессы и повторно используя их для будущих задач, вы также можете сэкономить время.
Здесь вы создаете пул из четырех рабочих процессов и используете их для вычисления первых сорока чисел Фибоначчи:
# fibonacci_multiprocessing_pool.py
import multiprocessing
def fib(n):
return n if n < 2 else fib(n - 2) + fib(n - 1)
if __name__ == "__main__":
with multiprocessing.Pool(processes=4) as pool:
results = pool.map(fib, range(40))
for i, result in enumerate(results):
print(f"fib({i}) = {result}")
Создание пула с помощью контекстного менеджера - это хорошая практика, позволяющая Python корректно завершать дочерние процессы и связанные с ними ресурсы. Метод пула .map() работает аналогично встроенной функции map(), становясь ее параллельным эквивалентом. В качестве первого аргумента он принимает вызываемый объект, за которым следует повторяемых входных значений для этого вызываемого объекта. В этом случае вызываемый параметр равен fib(), а повторяемый - это диапазон целых чисел от 0 до 39.
Вы можете поэкспериментировать с этим примером, изменив количество рабочих процессов, чтобы увидеть, как это влияет на общее время выполнения. Если вы не укажете количество процессов, то Python создаст столько ядер вашего процессора, сколько вам нужно, что, вероятно, и требуется при решении задач, связанных с процессором.
В более сложных случаях использования вы можете выбрать одну из нескольких абстракций в multiprocessing, которые аналогичны своим аналогам в threading. Они включают в себя примитивы синхронизации, такие как блокировки, семафоры, барьеры, переменные условий, события и многое другое. Чтобы обеспечить надежную связь между вашими процессами, вы можете использовать либо очередь, либо канал. Наконец, разделяемая память и менеджеры могут помочь вам совместно использовать состояние ваших процессов.
Хотя multiprocessing по-прежнему является мощным инструментом, дающим вам полный контроль над вашими дочерними процессами, разбираться со всеми техническими деталями низкого уровня, которые он предоставляет, может оказаться утомительным. Поэтому в Python появился высокоуровневый интерфейс под названием concurrent.futures, который позволяет запускать несколько процессов и управлять ими с меньшими затратами шаблонного кода, хотя и без такого детального контроля.
concurrent.futures: Высокоуровневый интерфейс для выполнения параллельных задач
Учитывая их поразительное сходство, можно утверждать, что модуль Python threading был в значительной степени вдохновлен потоками Java. Когда он впервые появился в стандартной библиотеке Python, в модуле были воспроизведены те же имена функций и методов, что и в Java. Они использовали регистр camel, нарушая соглашения о стиле, распространенные в Python, и следовали идиоме Java геттеры и сеттеры вместо того, чтобы использовать больше Pythonic содержит такие функции, как свойства.
Примечание: Эти имена в стиле Java, такие как .setDaemon(), устарели и были заменены свойствами, подобными .daemon в Python 3.10, но они все еще доступен для обеспечения обратной совместимости.
В Python 3.2 стандартная библиотека получила еще один модуль, разработанный на основе Java API. Пакет concurrent.futures моделирует утилиты параллелизма из ранних версий Java, а именно java.util.concurrent.Future интерфейс и Executor фреймворк. Этот новый пакет предоставляет унифицированный высокоуровневый интерфейс для управления пулами из потоков или процессов, что упрощает выполнение асинхронных задач в фоновом режиме.
По сравнению с multiprocessing компоненты в concurrent.futures предлагают более простой, но несколько ограниченный интерфейс, позволяющий абстрагироваться от деталей управления и координации отдельных сотрудников. Пакет строится поверх multiprocessing, но отделяет отправку параллельной работы от сбора результатов, которые представлены будущими объектами. Вам больше не нужно использовать очереди или каналы для обмена данными вручную.
Вот тот же самый пример Фибоначчи, переписанный для использования ProcessPoolExecutor:
# fibonacci_concurrent_futures_process_pool.py
from concurrent.futures import ProcessPoolExecutor
def fib(n):
return n if n < 2 else fib(n - 2) + fib(n - 1)
if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=4) as executor:
results = executor.map(fib, range(40))
for i, result in enumerate(results):
print(f"fib({i}) = {result}")
Хотя этот скрипт выглядит почти идентично версии multiprocessing, он ведет себя немного по-другому. Когда вы передаете работу исполнителю, вызывая его метод .map(), он возвращает объект генератора вместо блокировки. Этот лениво вычисляемый генератор выдает результаты один за другим по мере того, как каждый связанный будущий объект преобразуется в значение. Выполнение этого кода займет столько же времени, сколько и раньше, но результаты будут отображаться постепенно, а не все сразу.
Отлично! Вы видели, что разветвление процесса интерпретатора на multiprocessing или concurrent.futures позволяет использовать все доступные ядра процессора в Python. Так почему же люди продолжают жаловаться на GIL? К сожалению, высокая стоимость сериализации данных приводит к тому, что параллелизм на основе процессов начинает нарушаться, как только вам требуется передавать большие объемы данных между вашими рабочими процессами.
Рассмотрим следующий пример рабочего процесса, который получает некоторые данные и возвращает их обратно:
# echo_benchmark.py
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
def echo(data):
return data
if __name__ == "__main__":
data = [complex(i, i) for i in range(15_000_000)]
for executor in ThreadPoolExecutor(), ProcessPoolExecutor():
t1 = time.perf_counter()
with executor:
future = executor.submit(echo, data)
future.result()
t2 = time.perf_counter()
print(f"{type(executor).__name__:>20s}: {t2 - t1:.2f}s")
В этом примере вы перемещаете пятнадцать миллионов точек данных, используя два исполнителя, производительность которых вы сравниваете. Потоки обрабатывают первый исполнитель, а дочерние процессы - второй. Благодаря совместимым API-интерфейсам вы можете переключаться между двумя реализациями с минимальными усилиями. Каждая точка данных представляет собой комплексное число, занимающее тридцать два байта памяти, что в общей сложности составляет почти пятьсот мегабайт.
Когда вы отправите свою функцию echo() соответствующему исполнителю и измерите, сколько времени требуется данным для прохождения туда и обратно, результаты могут вас удивить:
$ python3 echo_benchmark.py
ThreadPoolExecutor: 0.00s
ProcessPoolExecutor: 45.03s
Фоновый поток возвращается мгновенно, в то время как дочернему процессу требуется целых сорок пять секунд, чтобы завершить работу! Обратите внимание, что ваша рабочая функция еще не выполнила никакой реальной работы. Этот тест всего лишь переносит данные из одного места в другое.
Причина такого существенного различия заключается в том, что потоки совместно используют память с основным процессом, поэтому они могут быстро получить доступ к вашим данным. В отличие от этого, Python должен копировать и сериализовать данные перед отправкой их другому процессу. Следовательно, вы всегда должны оценивать, компенсирует ли параллельный запуск кода издержки сериализации данных. В какой-то степени вы можете смягчить это, отправив местоположение данных вместо самих данных.
Еще одним препятствием, с которым вы можете столкнуться, является сама сериализация. Python использует модуль pickle under the surface для преобразования объектов в поток байтов перед передачей их в подпроцессы. Некоторые типы объектов, такие как lambda выражения, а также объекты, имеющие состояние, такие как генераторы или файловые объекты, не являются доступными для выбора, поэтому вы не сможете распределить их по нескольким процессам.
Подводя итог, можно сказать, что параллелизм на основе процессов в Python имеет следующие преимущества и недостатки:
- ✅ Это простая и часто используемая замена потокам.
- ❌ Создание системных процессов обходится дороже, чем создание потоков.
- ❌ Затраты на сериализацию данных могут свести на нет преимущества распараллеливания.
- ❌ Вы не можете сериализовать каждый тип данных с помощью модуля
pickle. - ❌ Могут существовать различия в том, как различные операционные системы обрабатывают дочерние процессы.
Как вы можете видеть, существует меньше аргументов в пользу параллелизма на основе процессов. Следовательно, пришло время изучить способы обхода GIL, чтобы раскрыть весь потенциал параллелизма на основе потоков в Python.
Заставить потоки Python работать параллельно
В этом разделе вы изучите различные подходы к обходу глобальной блокировки интерпретатора Python (GIL). Вы узнаете о работе с альтернативными средами выполнения, использовании библиотек, защищенных от GIL, таких как NumPy, написании и использовании модулей расширения C, использовании Cython и вызове внешних функций. В конце каждого подраздела вы найдете плюсы и минусы каждого подхода, которые помогут вам принимать обоснованные решения в вашем конкретном случае использования.
Используйте альтернативную среду выполнения для Python
Когда вы думаете о Python в контексте компьютерного программирования, вы можете иметь в виду одну из двух вещей:
- Язык программирования Python
- Интерпретатор Python, а также его стандартная библиотека
Как язык программирования, Python определяет формальный набор правил, регулирующих структуру хорошо сформированного и корректного кода. Грамматика Python определяет, как создавать программы из инструкций, таких как условных обозначений и выражений, таких как лямбда-функции. Синтаксис языка Python придает смысл его компоновочным блокам, включая зарезервированные ключевые слова , основные типы данных, и специальные символы, такие как операторов.
Это довольно абстрактные концепции, которые, по большей части, существуют на бумаге. Вы можете написать лучший в мире код на Python, но это не будет иметь значения, пока вы не сможете его запустить. Кто-то или что-то должно говорить на Python и уметь превращать его высокоуровневый, понятный человеку код в реальные действия. И это "что-то" - интерпретатор Python.
Интерпретатор Python - это программа, которая считывает и выполняет код на языке Python. Это движок, который запускает ваш код за кулисами. Стандартная библиотека - это набор модулей, функций и объектов, которые обычно являются частью интерпретатора. Он включает в себя встроенные функции, такие как print(), и модули, которые предоставляют доступ к базовой операционной системе, такие как модуль os.
Интерпретатором Python по умолчанию и на сегодняшний день наиболее широко используемым является CPython, эталонная реализация на языке программирования C. Он поставляется с GIL и использует подсчет ссылок для автоматического управления памятью. В результате его внутренняя модель памяти получает доступ к модулям расширения через API Python/C, что позволяет им узнать о GIL.
К счастью, CPython - не единственный интерпретатор вашего кода на Python. Существуют альтернативные реализации, основанные на внешних средах выполнения, таких как Java Virtual Machine (JVM) или Common Language Runtime (CLR). для приложений .NET. Они позволяют использовать Python для доступа к соответствующим стандартным библиотекам, манипулировать их собственными типами данных и соблюдать правила выполнения во время выполнения. С другой стороны, в них могут отсутствовать некоторые функции Python.
Замена CPython на другой интерпретатор Python, вероятно, является наиболее простым способом обхода GIL, поскольку обычно это вообще не требует каких-либо изменений в вашей кодовой базе. Если вы используете macOS или Linux, то вы можете использовать pyenv для удобной установки и переключения между различными интерпретаторами Python. В Windows вам нужно будет следовать инструкциям выбранного вами интерпретатора для ручной установки, поскольку pyenv-win поддерживает только CPython.
Jython и IronPython были двумя самыми популярными альтернативами CPython в прошлом. На сегодняшний день они оба устарели, поскольку в качестве основы для своей разработки они использовали устаревший Python 2.7.
В качестве альтернативы вы можете установить форк интерпретатора CPython, у которого нет GIL. Как вы узнали из предыдущего раздела о многопоточности в Python, было предпринято много попыток удалить GIL из Python. Например, интерпретатор nogil, судя по всему, находится в стадии активной разработки, но он все еще отстает от официальной версии на несколько поколений. Вот как вы можете использовать его для запуска своего потокового скрипта Фибоначчи:
$ pyenv install nogil
$ pyenv shell nogil
$ time python fibonacci.py
real 0m1.622s
user 0m6.094s
sys 0m0.018s
Сначала вы устанавливаете последнюю версию nogil, которая на момент написания статьи была основана на Python 3.9. После этого вы задаете команду python в вашей командной строке , чтобы она временно указывала на только что установленный интерпретатор. Наконец, вы вызываете свой скрипт fibonacci.py как обычно, определяя время его выполнения.
Если сравнить эти результаты с результатами обычного интерпретатора Python, разница будет ошеломляющей! Использование nogil вместо CPython ускоряет выполнение вашего скрипта в несколько раз. Это даже превосходит скорость версии, основанной на процессах. Из приведенных выше выходных данных вы можете ясно видеть, что Python запускал потоки на нескольких ядрах. Вы только что получили значительное повышение производительности бесплатно! Увы, это не все радуги и единороги.
У замены CPython на другую среду выполнения есть несколько потенциальных недостатков. Например, если ваш код использует синтаксические функции, такие как структурное сопоставление с шаблонами, или новые стандартные библиотечные модули, такие как tomllib, представленные в более поздних версиях Python, вы не сможете их использовать. Запуск вашего кода в чужой среде выполнения может привести к неожиданным результатам или помешать установке определенных сторонних модулей.
Короче говоря, переход на интерпретатор Python без GIL имеет следующие плюсы и минусы:
- ✅ Обычно это не требует внесения изменений в исходный код Python.
- ✅ Это может предоставить вам доступ к зарубежной стандартной библиотеке и типам данных.
- ❌ Интерпретатор может быть основан на устаревшей версии Python.
- ❌В стандартной библиотеке Python могут отсутствовать некоторые важные модули.
- ❌ Среда выполнения может демонстрировать неожиданное поведение и внешние типы данных.
- ❌ Возможно, вам не удастся установить сторонние модули расширения Python.
- ❌ Однопоточный код может выполняться медленнее, чем раньше.
Удаление GIL из Python не является новой концепцией. Было много попыток сделать это, но все они приводили к своим проблемам. Если вы станете жертвой одного из них, то сможете продолжить изучение хитроумных способов обхода GIL в Python.
Установите библиотеку, защищенную от GIL, например NumPy
Следующее лучшее, что вы можете сделать для параллельного запуска потоков, - это делегировать их выполнение за пределы Python, где GIL не является проблемой. Множество сторонних библиотек, таких как NumPy, могут использовать параллелизм на основе потоков, вызывая собственные функции через привязки Python. Это само по себе будет большим преимуществом, поскольку скомпилированный код выполняется намного быстрее, чем его эквивалент на чистом Python. В качестве бонуса потоки, управляемые извне, будут защищены от GIL в Python.
Обратите внимание, что вы не всегда можете контролировать параллельное выполнение операций, что может происходить прозрачно при использовании внешней библиотеки. Возможно, библиотека сама решает, достаточно ли велик размер данных, чтобы оправдать затраты, связанные с параллелизмом. Также имеют значение другие факторы, такие как конкретная конфигурация оборудования, ваша операционная система или наличие дополнительных библиотек, которые обрабатывают низкоуровневые сведения.
Например, NumPy использует высокооптимизированные библиотеки BLAS и LAPACK, которые могут использовать преимущества вашего процессора векторные функции и несколько ядер для эффективных операций линейной алгебры. NumPy попытается найти один из них на вашем компьютере и динамически загрузить его, прежде чем вернуться к стандартной реализации. Чтобы проверить, обнаруживает ли ваша установка NumPy такую библиотеку, вызовите np.show_config() или np.show_runtime():
>>> import numpy as np
>>> np.show_config()
openblas64__info:
libraries = ['openblas64_', 'openblas64_']
library_dirs = ['/usr/local/lib']
language = c
(...)
>>> np.show_runtime()
[{'numpy_version': '1.25.1',
(...)
{'architecture': 'Haswell',
'filepath': '/home/.../numpy.libs/libopenblas64_p-r0-7a851222.3.23.so',
'internal_api': 'openblas',
'num_threads': 4,
'prefix': 'libopenblas',
'threading_layer': 'pthreads',
'user_api': 'blas',
'version': '0.3.23'}]
В данном случае NumPy обнаружил библиотеку OpenBLAS, скомпилированную и оптимизированную для архитектуры процессора Intel Haswell. Он также пришел к выводу, что следует использовать четыре потока поверх библиотеки pthreads на текущем компьютере. Однако вы можете переопределить количество потоков, установив соответствующую переменную OMP_NUM_THREADS окружения.
Чтобы определить, действительно ли библиотека использует несколько потоков для обработки чисел, выполните такую утомительную задачу, как умножение матриц, и измерьте время ее выполнения. Не забудьте установить NumPy в виртуальную среду перед запуском следующего тестового скрипта:
# numpy_threads.py
import numpy as np
rng = np.random.default_rng()
matrix = rng.random(size=(5000, 5000))
matrix @ matrix
Вы импортируете numpy и запускаете генератор случайных чисел по умолчанию, чтобы создать квадратную матрицу размером 5000, заполненную случайными значениями. Затем вы используете оператор @, чтобы умножить матрицу на саму себя.
(venv) $ time python numpy_threads.py
real 0m2.955s
user 0m7.415s
sys 0m1.126s
(venv) $ export OMP_NUM_THREADS=1
(venv) $ time python numpy_threads.py
real 0m5.887s
user 0m5.753s
sys 0m0.132s
В первом случае реальное затраченное время в два с половиной раза меньше, чем процессорное время пользователя, что является явным свидетельством того, что ваш код выполняется параллельно, используя преимущества нескольких потоков. И наоборот, оба раза равны, когда вы применяете один поток с переменной окружения, подтверждая, что код больше не выполняется на нескольких ядрах процессора.
Использование библиотеки, защищенной от GIL, такой как NumPy, которая использует скомпилированный код для выполнения своих вычислений, может стать элегантным способом использования многопоточности в Python. Это просто и не требует выполнения дополнительных действий. В качестве побочного эффекта это дает возможность увеличить скорость выполнения машинного кода даже в однопоточном режиме. В то же время, это не идеальное портативное решение.
Выбранная вами собственная библиотека может не иметь соответствующей привязки к Python, что означает, что вы не смогли бы вызвать одну из ее функций из Python. Даже если соответствующая привязка существует, она может быть недоступна для вашей конкретной платформы, а скомпилировать ее самостоятельно не всегда просто. Библиотека может использовать многопоточность только в ограниченной степени или не использовать ее вообще. Наконец, функции, которые должны взаимодействовать с Python, по-прежнему доступны для GIL.
В целом, вот компромиссы, которые вам следует учитывать, прежде чем принимать решение о том, подходит ли вам библиотека, защищенная от GIL:
- ✅ Это быстрое, простое и элегантное решение.
- ✅ Это может ускорить выполнение вашего однопоточного кода.
- ❌ Библиотека Python, которую вы ищете, возможно, не существует.
- ❌ Базовая нативная библиотека может не иметь привязки к Python.
- ❌ Привязка Python для вашей платформы может быть недоступна.
- ❌ Библиотека может использовать многопоточность только частично или не использовать ее вообще.
- ❌ Библиотечная функция, которую вы хотите вызвать, возможно, не защищена от GIL.
- ❌ Библиотека может использовать многопоточность недетерминированным способом.
Если библиотеки, защищенной от GIL, или ее привязки к Python не существует, вы всегда можете создать свою собственную, внедрив пользовательский модуль расширения, что вы и сделаете далее.
Напишите модуль расширения на C с выпущенным GIL
Если замена CPython альтернативным интерпретатором вам не подходит, и вы не можете найти подходящую библиотеку Python с нативными расширениями, почему бы не создать свою собственную? Если вы не против пожертвовать переносимостью вашего исходного кода, то рассмотрите возможность создания модуля расширения Python C, чтобы перенести наиболее важные фрагменты кода на C, где GIL не будет обременительным.
Обратите внимание, что для продвижения по этому пути вам потребуется написать код на языке программирования Си. Кроме того, вам нужно будет знать, как правильно использовать Python/C API, поскольку вы не сможете создать модуль расширения только на чистом C. Но не волнуйтесь! Хотя в прошлом это могло стать препятствием, сегодня вы можете обратиться за помощью к ChatGPT, если вы застряли, или воспользоваться GitHub Copilot, который поможет вам в вашем путешествии в неизвестность.
Примечание: Помните, что искусственный интеллект полезен для поиска идей, но в конечном счете именно вам придется жить с результатами работы с плохим кодом. Поэтому важно, чтобы вы тщательно изучили содержащиеся в нем предложения, прежде чем внедрять их.
Чтобы продемонстрировать, как обойти GIL с помощью пользовательского модуля расширения, вы снова воспользуетесь Примером Фибоначчи, потому что это достаточно просто. Начните с создания нового файла с именем fibmodule.c, в который вы поместите исходный код вашего модуля расширения. Вот начальный каркас, на котором вы можете основать свои будущие модули расширения Python:
1// fibmodule.c
2
3#include <Python.h>
4
5int fib(int n) {
6 return n < 2 ? n : fib(n - 2) + fib(n - 1);
7}
8
9static PyObject* fibmodule_fib(PyObject* self, PyObject* args) {
10 int n, result;
11
12 if (!PyArg_ParseTuple(args, "i", &n)) {
13 return NULL;
14 }
15
16 Py_BEGIN_ALLOW_THREADS
17 result = fib(n);
18 Py_END_ALLOW_THREADS
19
20 return Py_BuildValue("i", result);
21}
22
23static PyMethodDef fib_methods[] = {
24 {"fib", fibmodule_fib, METH_VARARGS, "Calculate the nth Fibonacci"},
25 {NULL, NULL, 0, NULL}
26};
27
28static struct PyModuleDef fibmodule = {
29 PyModuleDef_HEAD_INIT,
30 "fibmodule",
31 "Efficient Fibonacci number calculator",
32 -1,
33 fib_methods
34};
35
36PyMODINIT_FUNC PyInit_fibmodule(void) {
37 return PyModule_Create(&fibmodule);
38}
В нем много шаблонного кода, который занимает большую часть места для такой маленькой функции. Но не расстраивайтесь, потому что вы можете разбить его построчно следующим образом:
- Строка 3 содержит заголовочный файл верхнего уровня с прототипами функций, объявления типов и макросы, которые предоставляют доступ к базовому интерпретатору CPython из вашего кода на C. Эти заголовки обычно поставляются вместе с установкой Python. Они должны присутствовать в вашей файловой системе, прежде чем вы сможете скомпилировать модуль расширения.
- Строки с 5 по 7 определяют вашу самую важную функцию, которая вычисляет n-е число Фибоначчи. Его структура очень похожа на реализацию Java, которую вы видели ранее, что неудивительно, учитывая, что Java и C принадлежат к одному и тому же семейству языков программирования.
- Строки с 9 по 21 определяют функцию-оболочку, видимую для Python и отвечающую за перевод между типами данных Python и C. Это связующий код между обоими языками, который принимает указатель на объект модуля и набор аргументов функции. Он вызывает вашу собственную функцию
fib(), которая выполняется напрямую, а не интерпретируется Python, а затем возвращает представление результата в Python. - Строки с 23 по 26 определяют набор функций верхнего уровня вашего модуля. В этом случае в вашем модуле есть только одна функция с именем
fib(), которая делегирует выполнение оболочкеfibmodule_fib(), принимает позиционные аргументы и имеет свою собственную строку документации . Последним элементом в массиве является специальное контрольное значение, обозначающее конец массива. - Строки с 28 по 34 определяют объект module, указывая имя, которое вы будете использовать при импорте на Python. Это определение также включает строку документации модуля, флаг
-1, указывающий на то, что этот модуль не поддерживает подинтерпретаторов, и, наконец, ваш набор функций. - Строки с 36 по 38 определяют функцию инициализатора модуля, которую интерпретатор будет вызывать при импорте вашего модуля расширения в Python.
Ключевая часть находится между строками 16 и 18, в которых используются специальные макросы из Python/C API для выделения потока-безопасный фрагмент. Они сообщают Python, что он может безопасно запускать другие потоки, не дожидаясь GIL во время выполнения вашей функции C. Это то, что обеспечивает подлинный параллелизм на основе потоков в Python с помощью модуля расширения.
Примечание: Вам разрешается использовать эти макросы только в том случае, если вы можете гарантировать, что код между ними никоим образом не взаимодействует с интерпретатором Python! Другими словами, не вызывайте никаких функций API Python/C, пока не будет выпущен GIL.
Теперь вы можете создать разделяемую библиотеку с вашим модулем расширения для Python, который будет динамически загружаться во время выполнения. Прежде чем двигаться дальше, убедитесь, что у вас есть вышеупомянутые заголовки Python и набор инструментов для сборки для C, например, компилятор gcc. Чтобы проверить расположение заголовков Python, вы можете выполнить следующую команду в своем терминале:
$ python3-config --cflags
-I/usr/include/python3.11
-Wsign-compare
-fstack-protector-strong
-Wformat
-Werror=format-security
-DNDEBUG -fwrapv -O2 -Wall -g
Выделенная строка указывает путь к папке, содержащей Python.h и другие важные заголовочные файлы. Если вы используете глобальный интерпретатор Python, который поставляется вместе с вашей операционной системой, вам может потребоваться установить соответствующие заголовки, выполнив соответствующую команду менеджера пакетов. Например, если вы используете Ubuntu, то установите пакет python3-dev.
Хотя вы обычно используете setuptools или аналогичный инструмент для создания вашего модуля расширения, вы также можете использовать компилятор вручную, что будет быстрее для целей данного руководства. Возьмите выделенный флаг компилятора и вставьте его в следующую команду:
$ gcc -I/usr/include/python3.11 -shared -fPIC -O3 -o fibmodule.so fibmodule.c
Флаг -I добавляет путь к заголовочным файлам Python, чтобы компилятор знал, где найти необходимые определения для сборки вашего модуля. Параметр -shared указывает компилятору на создание файла общего объекта, а параметр -fPIC предназначен для генерации позиционно-независимого кода который может быть загружен в адресное пространство Python динамически во время выполнения. Флажок -O3 обеспечивает наивысший уровень оптимизации. И, наконец, последний параметр, -o, указывает имя выходного файла.
Приведенная выше команда не должна выдавать никаких результатов, но если это произойдет, то, скорее всего, что-то пошло не так, и вам нужно будет изучить и исправить ошибки. С другой стороны, если команда будет выполнена успешно, то будет создан двоичный файл с именем fibmodule.so, который является общим объектом, который вы можете импортировать в Python.
Если Python сможет найти этот файл в вашем текущем рабочем каталоге или по одному из путей, определенных в переменной окружения PYTHONPATH, вы сможете импортировать свой модуль расширения и вызывать его единственную функцию, fib():
>>> import fibmodule
>>> fibmodule.__doc__
'Efficient Fibonacci number calculator'
>>> dir(fibmodule)
[..., 'fib']
>>> fibmodule.fib.__doc__
'Calculate the nth Fibonacci'
>>> fibmodule.fib(35)
9227465
На функциональном уровне ваш модуль расширения работает должным образом. Однако, хотя скомпилированная функция C возвращает правильный результат, пришло время проверить, работает ли она быстрее. Измените свой тест Фибоначчи на Python и сохраните его в другом файле с именем fibonacci_ext.py:
# fibonacci_ext.py
import os
import threading
import fibmodule
for _ in range(os.cpu_count()):
threading.Thread(target=fibmodule.fib, args=(45,)).start()
Помимо замены чисто питоновской реализации fib() на ее аналог fibmodule.fib(), вы возвращаете исходный входной аргумент, равный сорока пяти. Это позволяет запускать скомпилированный код на C, который выполняется значительно быстрее, чем на Python, в том числе в однопоточном режиме.
Без лишних слов, вот результат запуска вашего нового теста:
$ time python fibonacci_ext.py
real 0m4.021s
user 0m15.548s
sys 0m0.011s
Отлично! Это в два раза быстрее, чем в аналогичном примере на Java, и более чем в четыре раза быстрее, чем в однопоточном коде. Когда вы посмотрите на загрузку процессора, вы увидите, что все ядра работают на сто процентов, что и было вашей основной целью.
Примечание: Если вам интересно, то вы можете удалить макросы, освобождающие GIL, из вашей функции-оболочки, перекомпилировать модуль расширения и снова запустить тот же тест. Как вы думаете, каким будет результат такого быстрого эксперимента?
В общем, вот аргументы за и против написания модуля расширения для экранирования GIL в Python:
- ✅ У вас есть детальный контроль над GIL в Python.
- ✅ Это может ускорить выполнение вашего однопоточного кода.
- ❌ Знакомства с C недостаточно — вам также необходимо знать API Python/C.
- ❌ Создание модуля расширения - относительно сложный процесс.
- ❌ Вам нужны дополнительные инструменты и ресурсы, такие как заголовки Python.
- ❌ Модули расширения не так портативны, как пакеты на чистом Python.
- ❌ Они будут работать только на CPython, но не на других интерпретаторах.
- ❌ Смешение двух языков и их экосистем создает дополнительные сложности.
- ❌ Ваш код становится менее читаемым и его сложнее поддерживать.
- ❌ На написание и сборку модуля расширения требуется время.
Создание модуля расширения для Python вручную утомительно и чревато ошибками. Кроме того, для этого требуется глубокое знание языка Си, API Python/C и инструментов компилятора. К счастью, вы можете сократить путь, автоматизировав большую часть сложной работы с помощью таких инструментов, как компилятор mypy (mypyc) или генератор кода, такой как Cython. Последнее дает вам полный контроль над GIL, так что вы сейчас прочтете об этом.
Попросите Cython Сгенерировать для Вас модуль расширения C
Вы можете представить себе Cython как гибрид C и Python, который сочетает в себе синтаксис высокого уровня знакомого языка программирования со скоростью скомпилированного кода на языке Си. Разработчики, как правило, используют Cython для оптимизации критически важных для производительности фрагментов кода с гораздо меньшими усилиями, чем при написании модуля расширения вручную. NumPy и lxml являются яркими примерами проектов на Python которые в значительной степени используют Cython для ускорения своих вычислений.
Примечание: Не путайте Cython с CPython! Первый - это язык программирования, компилятор и генератор кода, в то время как второй - основной интерпретатор Python, реализованный на C.
Более конкретно, Cython - это надстройка Python с дополнительными элементами синтаксиса, основанная на устаревшем языке Pyrex Грега Юинга, который первоначально он был разветвлен на. Вот пример фрагмента кода на Cython:
# fibmodule.pyx
cpdef int fib(int n):
with nogil:
return _fib(n)
cdef int _fib(int n) noexcept nogil:
return n if n < 2 else _fib(n - 2) + _fib(n - 1)
Оператор cpdef заставляет Cython генерировать две версии одной и той же функции: чистую функцию C, а также оболочку, которую вы можете вызвать из Python. И наоборот, оператор cdef объявляет функцию C, которая не будет видна за пределами этого модуля.
nogil Диспетчер контекста освобождает GIL-файл Python, в то время как модификатор nogil в сигнатуре функции помечает его как потокобезопасный. Модификатор noexcept отключает генерацию кода для обработки исключений. Это делается для предотвращения взаимодействия Cython с интерпретатором Python через API Python/C, когда он выполняется в многопоточном контексте.
Примечание: Обычно ваш код на Cython помещается в файл с именем и расширением .pyx. Когда вы это сделаете, ваша среда IDE или редактор кода должны распознать и включить подсветку синтаксиса для Cython.
Хотя для успешного начала использования Cython вам нужно всего лишь выучить несколько новых ключевых слов, таких как cdef и cpdef, недавний выпуск Cython 3.0.0 был капитальный ремонт, который снизил барьер для входа, введя вариант синтаксиса , основанный на чистом Python, . Этот режим дает вам возможность использовать подсказки по вводу текста, аннотации переменных и другие относительно новые возможности родного языка Python вместо того, чтобы полагаться на внешний синтаксис.
В этом руководстве вы будете использовать новый синтаксис, для которого требуется Cython 3.0.0. Вы можете установить его как обычный пакет Python с помощью pip:
(venv) $ python -m pip install cython
В качестве побочного эффекта вы сможете поместить свой код в файл .py вместо .pyx и запустить его через стандартный интерпретатор Python без использования Cython, если хотите.
Вы можете использовать Cython для компиляции существующего кода на Python как есть, без каких-либо изменений. В этом случае инструмент сгенерирует эквивалентный модуль расширения на C, который вы можете скомпилировать как обычно, или вы можете позволить setuptools скомпилировать его за вас. Однако, если вы добавите в код объявления типов и будете использовать функции, специфичные для Cython, вы получите еще больший прирост производительности.
Примечание: Независимо от того, создаете ли вы модули расширения вручную или с помощью Cython, они ориентированы на интерпретатор CPython. Но Cython имеет базовую поддержку модулей расширения PyPy, что позволяет перенести ваш код Cython в PyPy для дополнительного ускорения.
Ниже приведена эквивалентная реализация fibmodule.pyx, которая использует вариант синтаксиса Python, представленный в Cython 3.0.0:
# fibmodule.py
import cython
@cython.ccall
def fib(n: cython.int) -> cython.int:
with cython.nogil:
return _fib(n)
@cython.cfunc
@cython.nogil
@cython.exceptval(check=False)
def _fib(n: cython.int) -> cython.int:
return n if n < 2 else _fib(n - 2) + _fib(n - 1)
if cython.compiled:
print("Cython compiled this module")
else:
print("Cython didn't compile this module")
Поскольку этот модуль использует стандартный синтаксис Python, вы можете импортировать его непосредственно из интерпретатора. Единственное требование - наличие модуля cython, доступного в вашей виртуальной среде. Чтобы узнать, используете ли вы чистый код на Python или код на C, скомпилированный с помощью Cython, вы добавили флажок в нижней части модуля, который отобразит соответствующее сообщение.
Вы можете повторно использовать тестовый скрипт из предыдущего раздела, чтобы протестировать вашу новую реализацию последовательности Фибоначчи. Убедитесь, что и fibmodule.py, и fibonacci_ext.py находятся в одной папке, без каких-либо других файлов. Вам особенно не нужен тот общий объект (.so), который вы скомпилировали ранее! Лучше всего создать отдельную папку, например extension_module_cython/, и скопировать туда оба исходных файла, чтобы избежать путаницы:
extension_module_cython/
│
├── fibmodule.py
└── fibonacci_ext.py
Как только у вашего модуля Cython появится новый дом, измените на него текущий каталог и запустите тестовый скрипт, пока не компилируя модуль расширения:
(venv) $ time python fibonacci_ext.py
Cython didn't compile this module
real 18m43.677s
user 18m45.617s
sys 0m6.715s
Если у вас хватит терпения дождаться завершения работы скрипта, то вы сможете увидеть, что он работает в однопоточном режиме благодаря GIL. Как будто этого недостаточно, сообщение на экране подтверждает, что вы действительно используете чистый код на Python. Теперь пришло время скомпилировать ваш модуль расширения с помощью Cython и повторно запустить тест!
Существует несколько способов создания кода на Cython. В большинстве случаев лучше всего использовать setuptools, но для удобства вы можете вызвать утилиту cythonize в командной строке:
(venv) $ cythonize --inplace --annotate -3 fibmodule.py
Эта команда преобразует указанный модуль Cython, fibmodule.py, в соответствующий модуль расширения C. Кроме того, опция --inplace компилирует сгенерированный код C в общий объект, который вы можете импортировать из Python. Переключатель --annotate выдает раскрашенный HTML-отчет, показывающий, какие части вашего модуля Cython взаимодействуют с интерпретатором Python и в какой степени. Наконец, флаг -3 устанавливает уровень языка на Python 3.
В результате вы увидите, что появилось несколько новых файлов и папок, выделенных ниже:
extension_module_cython/
│
├── build/
│ └── lib.linux-x86_64-cpython-311/
│ └── fibmodule.cpython-311-x86_64-linux-gnu.so
│
├── fibmodule.c
├── fibmodule.cpython-311-x86_64-linux-gnu.so
├── fibmodule.html
├── fibmodule.py
└── fibonacci_ext.py
fibmodule.c - это модуль расширения, основанный на вашем коде на Cython. Обратите внимание, что сгенерированный код на C довольно подробный и не предназначен для изменения вручную. Поэтому, как правило, вы захотите исключить его из системы управления версиями, добавив, например, соответствующие шаблоны имен в ваш файл .gitignore.
Наконец, когда вы снова запустите тест, вы увидите совершенно другие цифры:
(venv) $ time python fibonacci_ext.py
Cython compiled this module
real 0m4.274s
user 0m15.741s
sys 0m0.005s
В приведенном выше сообщении говорится, что Python запускает скомпилированный модуль расширения, который вы создали с помощью Cython. Неудивительно, что ваш код без GIL использует все ядра процессора и работает более чем в 260 раз быстрее, чем аналогичная реализация на чистом Python! Это колоссальный прирост производительности при минимальных затратах.
В целом, Cython обладает некоторыми преимуществами и недостатками обычных модулей расширения, но в то же время у него есть дополнительные плюсы и минусы:
- ✅ Использовать Cython проще, чем писать модуль расширения вручную.
- ✅ Модули расширения, созданные с помощью Cython 3.x, могут быть переносимыми, хотя и медленнее.
- ✅ Вам не нужно много знать о C или API Python/C.
- ✅ Код на Cython более удобочитаем, чем расширение на чистом C.
- ✅ У вас есть детальный контроль над GIL в Python.
- ✅ Скорее всего, это ускорит выполнение вашего однопоточного кода.
- ❌ Вам все равно нужно немного освоить новый синтаксис или API.
- ❌ Сгенерированный код является длинным, многословным и сложным для отладки.
- ❌ Вам нужны дополнительные инструменты и ресурсы, такие как заголовки Python.
- ❌ Модули расширения будут работать только с некоторыми вариантами интерпретатора Python.
- ❌ Смешение двух языков и их экосистем создает дополнительные сложности.
Возможно, у вас возникнет соблазн скомпилировать весь ваш проект на Python с помощью Cython, но это не лучший подход из-за перечисленных выше недостатков. Как правило, вам следует профилировать свой код на Python, а затем стратегически выбирать узкие части для цитонизации. Таким образом, вы сохраните удобочитаемость и динамичность Python, одновременно целенаправленно повышая производительность.
Что делать, если вы не можете или не хотите использовать внешние инструменты, такие как Cython? Возможно, вы хорошо знаете язык программирования C, но не так хорошо знакомы с API Python/C. В таком случае, возможно, вы захотите воспользоваться модулем ctypes из стандартной библиотеки, с которым вы сейчас ознакомитесь.
Вызовите внешнюю функцию C, используя ctypes
Благодаря тесной интеграции C и Python, интерпретатор поставляется со стандартным библиотечным модулем под названием ctypes, который позволяет выполнять вызовы функций C из Python. Этот механизм известен как интерфейс внешних функций (FFI), поскольку он позволяет вам напрямую взаимодействовать с библиотеками C, не упаковывая их в модули расширения. Python использует библиотеку libffi, которая обеспечивает эту функциональность.
Примечание: Можно создавать совместно используемые объекты или библиотеки динамической компоновки путем компиляции кода, отличного от C-например, C++, Растите или Переходите. Просто убедитесь, что вы компилируете код в библиотеку, совместимую с вашим интерпретатором Python, ориентируясь на ту же аппаратную архитектуру и операционную систему.
После динамической загрузки скомпилированного общего объекта в Python во время выполнения вы готовы к доступу к его внешним функциям. Поскольку библиотека C не использует ни один из API Python/C, она будет работать с выпущенной блокировкой GIL, что позволит запускать ее код в нескольких потоках одновременно:
Блокировка глобального интерпретатора Python снимается перед вызовом любой функции, экспортируемой этими библиотеками, и повторно запрашивается после этого. (Источник)
Вы можете проверить это поведение, создав еще одну реализацию последовательности Фибоначчи. Создайте новый исходный файл с именем fibonacci.c и скопируйте функцию fib() из вашего пользовательского модуля расширения C, который вы написали ранее:
// fibonacci.c
int fib(int n) {
return n < 2 ? n : fib(n - 2) + fib(n - 1);
}
Этот код практически такой же, как и предыдущий, но без дополнительных возможностей Python / C API для его реализации. Поскольку приведенный выше код больше не зависит от заголовков Python, вы можете скомпилировать его, не указывая дополнительный флаг компилятора -I, который указывает путь к этим заголовкам:
$ gcc -shared -fPIC -O3 -o fibonacci.so fibonacci.c
В результате вы создадите двоичный общий объект с именем fibonacci.so, который вы можете загрузить в Python, используя ctypes примерно так:
# fibonacci_ctypes.py
import ctypes
import os
import threading
fibonacci = ctypes.CDLL("./fibonacci.so")
for _ in range(os.cpu_count()):
threading.Thread(target=fibonacci.fib, args=(45,)).start()
Вы вызываете ctypes.CDLL(), указывая путь к локальному файлу, который вы только что создали. Важно указать полный путь, включая начальную точку (.) и косую черту (/), обозначающие текущий рабочий каталог. В противном случае Python попытается найти подходящую библиотеку в системных каталогах, таких как /lib или /usr/lib.
Запуск и синхронизация этого примера дают ожидаемый результат:
$ time python3 fibonacci_ctypes.py
real 0m4.427s
user 0m17.141s
sys 0m0.023s
Потоки, вызывающие функцию fib() из скомпилированной библиотеки, выполняются параллельно, используя все доступные ядра процессора. Время выполнения сопоставимо с решением, основанным на модуле расширения, написанном вручную или сгенерированном с помощью Cython. Однако ctypes иногда может быть менее производительным из-за затрат на преобразование данных, аналогичных затратам на сериализацию данных в параллелизме на основе процессов которые вы исследовали ранее.
Модуль ctypes должен выполнять дополнительную работу за кулисами. Когда вы вызываете внешнюю функцию, которая принимает аргументы, ctypes преобразует типы данных Python в их аналоги на C, а затем наоборот, прежде чем вернуть результат в Python. Это преобразование может оказаться дорогостоящим, особенно когда вы имеете дело с большими объемами данных или более сложными структурами данных.
Примечание: Иногда вы можете уменьшить эти издержки, заменив указателями на данные, размещенные в C. В следующем разделе вы увидите практический пример использования этого метода. В частности, вы будете передавать адрес массива NumPy внешней функции, определенной в пользовательской библиотеке C.
В то же время вы всегда должны осознавать связанные с этим риски. Использование необработанных указателей потенциально опасно и может привести к утечке памяти, повреждению данных или ошибкам сегментации .
Пример Фибоначчи работает так, как ожидалось, потому что ваша функция fib() имеет сигнатуру, которая соответствует значениям по умолчанию, принятым в ctypes. В общем, вам следует определить явные прототипы функций, сопроводив собственные символы из общей библиотеки ожидаемыми типами данных C. Это обеспечит правильное преобразование типов и, возможно, предотвратит случайный сбой интерпретатора Python:
# fibonacci_ctypes.py
import ctypes
import os
import threading
fibonacci = ctypes.CDLL("./fibonacci.so")
fib = fibonacci.fib
fib.argtypes = (ctypes.c_int,)
fib.restype = ctypes.c_int
for _ in range(os.cpu_count()):
threading.Thread(target=fib, args=(45,)).start()
Здесь вы указываете типы входных аргументов функции fib(), назначая соответствующую последовательность из типов C в .argtypes, и вы устанавливаете функциювозвращает тип через атрибут .restype. Установка этих параметров предотвратит вызов функции с неправильным типом аргументов, а также преобразует значения в ожидаемые типы данных.
В заключение, вы можете использовать ctypes для обхода GIL в Python, рассмотрев следующие сильные и слабые стороны:
- ✅ Модуль
ctypesдоступен "из коробки" в стандартной библиотеке Python. - ✅ Вы можете использовать чистый Python для вызова внешних функций с выпущенным GIL.
- ✅ Общие библиотеки более переносимы, чем модули расширения C.
- ❌ Накладные расходы, связанные с преобразованием типов данных, ограничивают прирост производительности.
- ❌ В более сложных случаях использования вам действительно понадобятся некоторые знания языка Си.
Несколько других инструментов, включая CFFI, SWIG и pybind11, позволяет вам взаимодействовать с C и C++, чтобы избежать использования GIL в Python. Кроме того, такие инструменты, как PyPy, Numba, Nuitka, Shed Skin и другие могут обеспечить значительное повышение производительности, не выходя за рамки однопоточного выполнения, благодаря just-in-time (JIT) сборник. У каждого из них есть свои недостатки, поэтому изучите все доступные варианты, прежде чем решать, какой из них использовать.
Примечание: В последние годы Taichi Lang набирает все большую популярность, поскольку он может автоматически переводить ваш код на Python в высокопроизводительный язык. оптимизированные ядер, которые могут работать на графическом процессоре (GPU).
Итак, приготовьтесь засучить рукава и погрузиться в практический пример параллелизма с разделяемой памятью в Python. Не волнуйся. Это будет ближе к реальному сценарию, чем вычисление числа Фибоначчи!
Попробуйте: Параллельная обработка изображений в Python
В этом заключительном разделе вы воспользуетесь тем, что узнали о параллельной обработке данных в Python, создав интерактивное настольное приложение. Приложение позволит вам загрузить изображение из файла, используя библиотеку Pillow, настроить его значение экспозиции, выполнить гамма-коррекцию, и выполните предварительный просмотр как можно быстрее. Вот как будет выглядеть главное окно:
 Настройка экспозиции и гаммы изображения с разрешением более 40 мегапикселей
Настройка экспозиции и гаммы изображения с разрешением более 40 мегапикселей
Два ползунка в верхней части окна позволяют управлять экспозицией и гаммой соответственно. По мере их настройки изображение предварительного просмотра, расположенное ниже, обновляется в режиме реального времени, отражая изменения. Строка состояния внизу показывает, сколько времени требуется для вычисления новых значений пикселей, а также общее время рендеринга.
Математическая формула, которую вы будете применять к цветовой составляющей каждого пикселя, 𝑥, выглядит следующим образом:
 Уравнение для экспозиции и гамма-коррекции
Уравнение для экспозиции и гамма-коррекции
Обратите внимание, что вы должны нормализовать входное значение так, чтобы оно находилось в диапазоне от нуля до единицы, прежде чем вы сможете ввести его в эту формулу. Аналогично, вы должны денормализовать результирующее выходное значение, масштабировав его до цветового пространства изображения . Переменная EV представляет значение экспозиции, а греческая буква γ - это гамма, обозначаемая ползунками.
К концу работы ваш проект будет иметь следующую структуру папок:
image_processing/
│
├── parallel/
│ ├── __init__.py
│ └── parallel.c
│
└── image_processing.py
Помимо основного скрипта, называемого image_processing.py, существует пакет, содержащий наиболее ресурсоемкие операции, реализованные на C. Модуль-оболочка Python, __init__.py, отвечает за загрузку соответствующего общего объекта и вызов его функций. Таким образом, вы можете импортировать parallel в Python для доступа к вашим скомпилированным функциям.
После создания желаемой структуры папок и виртуальной среды для вашего проекта установите Pillow и NumPy. Это единственные сторонние зависимости, которые требуются вашему проекту:
(venv) $ python -m pip install pillow numpy
Вы будете использовать Pillow для загрузки растрового изображения в Python и NumPy для представления пикселей в памяти компьютера.
Если вы не хотите начинать с нуля или хотите сверить свою реализацию с окончательным проектом, загрузите вспомогательные материалы, перейдя по ссылке ниже:
Получите свой код: Нажмите здесь, чтобы загрузить бесплатный пример кода, который показывает, как обойти GIL и добиться параллельной обработки в Python.
В качестве бонуса к материалам прилагается модифицированная версия этого приложения, которая позволяет переключаться между различными режимами обработки с помощью дополнительного выпадающего списка. Не стесняйтесь поэкспериментировать с ним, чтобы сравнить производительность чистого Python, NumPy и параллельной реализации без GIL.
Теперь вы можете без лишних слов погрузиться в игру!
Создайте графический интерфейс пользователя с помощью Tkinter
Чтобы этот пример был достаточно простым, вы будете использовать встроенный в Python графический интерфейс Tkinter для создания визуальных компонентов вашего пользовательского интерфейса. Начните с определения класса для главного окна:
# image_processing.py
import tkinter as tk
import numpy as np
import PIL.Image
class AppWindow(tk.Tk):
def __init__(self, image: PIL.Image.Image) -> None:
super().__init__()
# Main window
self.title("Exposure and Gamma Correction")
self.resizable(False, False)
# Image pixels
self.pixels = np.array(image)
self.mainloop()
def on_slide(self, *args, **kwargs) -> None:
pass
def show_preview(self, image: PIL.Image.Image) -> None:
pass
Метод инициализатора класса , .__init__(), принимает изображение подушки в качестве аргумента и извлекает его пиксельные значения в массив NumPy, с которым вы будете работать позже. Он также вызывает super() для настройки главного окна, задает заголовок окна и делает его не изменяемым в обоих измерениях. Наконец, он входит в цикл обработки событий Tk , чтобы начать реагировать на действия пользователя.
Два других метода в вашем классе являются заполнителями, подключаемыми с помощью инструкции pass, которую вы скоро реализуете. В частности, .on_slide() будет обрабатывать события, связанные с перемещением обоих ползунков влево или вправо, а .show_preview() будет отображать изображение с настроенной экспозицией и гаммой. Но прежде чем сделать это, вам нужно будет завершить создание своего пользовательского интерфейса.
Создайте рамку с границами и надписями вокруг двух ползунков, используя Тематические виджеты Tk (ttk) для более современного оформления графического интерфейса пользователя:
# image_processing.py
import tkinter as tk
import tkinter.ttk as ttk
import numpy as np
import PIL.Image
class AppWindow(tk.Tk):
def __init__(self, image: PIL.Image.Image) -> None:
super().__init__()
# Main window
self.title("Exposure and Gamma Correction")
self.resizable(False, False)
# Parameters frame
self.frame = ttk.LabelFrame(self, text="Parameters")
self.frame.pack(fill=tk.X, padx=10, pady=10)
self.frame.columnconfigure(0, weight=0)
self.frame.columnconfigure(1, weight=1)
# Image pixels
self.pixels = np.array(image)
self.mainloop()
# ...
Фрейм использует менеджер геометрии сетки для размещения дочерних виджетов, которые вы будете размещать в указанных строках и столбцах. Заполните кадр, добавив два горизонтальных ползунка и их надписи, соответствующие значению экспозиции и параметрам гаммы:
# image_processing.py
# ...
class AppWindow(tk.Tk):
def __init__(self, image: PIL.Image.Image) -> None:
# ...
# EV slider
self.var_ev = tk.DoubleVar(value=0)
ev_label = ttk.Label(self.frame, text="Exposure:")
ev_label.grid(row=0, column=0, sticky=tk.W, padx=10, pady=10)
ev_slider = ttk.Scale(
self.frame,
from_=-1,
to=1,
orient=tk.HORIZONTAL,
variable=self.var_ev,
)
ev_slider.bind("<B1-Motion>", self.on_slide)
ev_slider.grid(row=0, column=1, sticky=tk.W + tk.E, padx=10, pady=10)
# Gamma slider
self.var_gamma = tk.DoubleVar(value=1)
gamma_label = ttk.Label(self.frame, text="Gamma:")
gamma_label.grid(row=1, column=0, sticky=tk.W, padx=10, pady=10)
gamma_slider = ttk.Scale(
self.frame,
from_=0.1,
to=2,
orient=tk.HORIZONTAL,
variable=self.var_gamma,
)
gamma_slider.bind("<B1-Motion>", self.on_slide)
gamma_slider.grid(row=1, column=1, sticky=tk.W + tk.E, padx=10, pady=10)
# Image pixels
self.pixels = np.array(image)
self.mainloop()
# ...
Вы подключаете оба ползунка к переменным с плавающей запятой двойной точности типа tk.DoubleVar,, к которым вы можете получить доступ, чтобы получить числовые значения параметров. Благодаря двусторонней привязке данных в Tk соответствующая переменная будет автоматически обновляться всякий раз, когда вы перемещаете один из ползунков в новое положение. И наоборот, присвоение переменной нового значения приведет к соответствующему перемещению ползунка, но привязка в этом направлении вам не понадобится.
Обратите внимание, что вы также регистрируете обработчик событий , отслеживающий событие <B1-Motion>, чтобы перемещение любого из ползунков при нажатой основной кнопке мыши запускало .on_slide() способ.
Наконец, добавьте предварительный просмотр изображения и строку состояния в окно чуть ниже ползунков:
# image_processing.py
# ...
class AppWindow(tk.Tk):
def __init__(self, image: PIL.Image.Image) -> None:
# ...
# Image preview
self.preview = ttk.Label(self, relief=tk.SUNKEN)
self.preview.pack(padx=10, pady=10)
# Status bar
self.var_status = tk.StringVar()
status_bar = ttk.Label(
self, anchor=tk.W, relief=tk.SUNKEN, textvariable=self.var_status
)
status_bar.pack(side=tk.BOTTOM, fill=tk.X)
# Image pixels
self.pixels = np.array(image)
self.mainloop()
# ...
Предварительный просмотр изображений - это виджет меток, который может отображать изображения. В строке состояния будет отображаться значение, хранящееся в переменной tk.StringVar, которую вы сохраняете как элемент экземпляра класса.
Отлично! Теперь, когда у вас есть базовая структура вашего окна, пришло время отобразить ее на экране и заставить ваше приложение делать что-то полезное.
Определите интерфейс командной строки с помощью argparse
Ваша программа ожидает, что в командной строке будет указан один позиционный аргумент, указывающий путь к файлу загружаемого изображения. Давайте определим синтаксический анализатор аргументов командной строки, используя стандартный модуль Python argparse:
# image_processing.py
import argparse
import pathlib
import tkinter as tk
import tkinter.ttk as ttk
import numpy as np
import PIL.Image
# ...
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument("image_path", type=pathlib.Path)
return parser.parse_args()
Синтаксический анализатор преобразует указанную строку в pathlib.Path экземпляр, заключенный в специальный объект пространства имен, который вы можете получить и ввести в программы.>точка входа примерно так:
# image_processing.py
# ...
def main(args: argparse.Namespace) -> None:
with PIL.Image.open(args.image_path) as image:
AppWindow(image)
if __name__ == "__main__":
main(parse_args())
В нижней части вашего скрипта, в блоке кода, обозначенном именем-главной идиомой, вы вызываете parse_args() и немедленно передаете результат в main() функция. Эта функция загружает изображение из данного файла и, в свою очередь, передает его новому экземпляру вашего класса AppWindow.
Теперь вы можете запустить свой скрипт, вызвав следующую команду:
(venv) $ python image_processing.py sample_image.jpg
Не стесняйтесь либо протестировать скрипт с вашими собственными изображениями различных размеров, либо использовать примеры файлов изображений из вспомогательных материалов:
Получите свой код: Нажмите здесь, чтобы загрузить бесплатный пример кода, который показывает, как обойти GIL и добиться параллельной обработки в Python.
После запуска вашей программы вы пока не увидите на экране ничего интересного, потому что вы не определили метод .show_preview(). Сейчас вы это исправите!
Отобразить предварительный просмотр загруженного изображения в уменьшенном виде
Поскольку Tkinter, Pillow и NumPy легко интегрируются, вы можете легко переключаться между их представлениями значений в пикселях. К сожалению, время рендеринга будет немного увеличено из-за необходимых преобразований, которые могут включать копирование больших объемов данных. Чтобы добиться максимальной производительности рендеринга, рассмотрите возможность использования других графических фреймворков или библиотек, таких как PyGame.
Для отображения предварительного просмотра загруженного изображения требуется, чтобы вы вызвали свой метод .show_preview() в инициализаторе класса:
# image_processing.py
import argparse
import pathlib
import tkinter as tk
import tkinter.ttk as ttk
import numpy as np
import PIL.Image
class AppWindow(tk.Tk):
def __init__(self, image: PIL.Image.Image) -> None:
# ...
# Image pixels
self.pixels = np.array(image)
self.update()
self.show_preview(image)
self.mainloop()
# ...
Кроме того, поскольку вы хотите, чтобы предварительный просмотр отображался на экране, вы также должны учитывать размеры других визуальных компонентов, занимающих окно приложения. В обычных условиях Tkinter рассчитывает размеры виджетов после их отображения на экране. Вызывая .update() в окне, вы заставляете его быстрее размещать свои виджеты.
Как только вы это сделаете, вы можете создать миниатюру , преобразовать ее в представление, подходящее для Tkinter, и обновить виджет предварительного просмотра:
# image_processing.py
import argparse
import pathlib
import tkinter as tk
import tkinter.ttk as ttk
import numpy as np
import PIL.Image
import PIL.ImageTk
class AppWindow(tk.Tk):
# ...
def on_slide(self, *args, **kwargs) -> None:
pass
def show_preview(self, image: PIL.Image.Image) -> None:
scale = 0.75
offset = 2.0 * self.frame.winfo_height()
image.thumbnail(
(
int(self.winfo_screenwidth() * scale),
int(self.winfo_screenheight() * scale - offset),
)
)
image_tk = PIL.ImageTk.PhotoImage(image)
self.preview.configure(image=image_tk)
self.preview.image = image_tk
# ...
После того, как вы определите свой размер экрана, вы можете немного уменьшить его, чтобы оставить немного свободного пространства вокруг окна вашего приложения. Вы также вычитаете высоту рамки, содержащей ползунки, из высоты предварительного просмотра, чтобы избежать обрезки содержащегося в ней изображения.
Хотя приложение отображает изображение, которое вы указываете в командной строке после запуска, при перемещении ползунков, похоже, ничего не меняется. Пришло время добавить немного кода, чтобы сделать вашу программу интерактивной!
Взаимодействуйте С Вашим Приложением С Помощью Событий Мыши
При перемещении любого из ползунков требуется выбрать параметры экспозиции и гаммы из соответствующих переменных, которые вы определили ранее. Однако, прежде чем передавать эти параметры в сложные вычисления, вы должны преобразовать их в желаемое числовое пространство:
# image_processing.py
# ...
class AppWindow(tk.Tk):
# ...
def on_slide(self, *args, **kwargs) -> None:
# Get parameters
ev = 2.0 ** self.var_ev.get()
gamma = 1.0 / self.var_gamma.get()
# ...
# ...
Значение экспозиции выражается в логарифмической шкале, представляющей собой удвоение или уменьшение вдвое количества света, попадающего на аналоговую пленку или цифровой датчик. Гамма-коррекция, с другой стороны, представляет собой степенную функцию с дробным показателем степени, имитирующую нелинейный отклик зрительная система человека. Таким образом, вы умножаете значение ползунка экспозиции на два в степени, обратной величине ползунка гаммы.
Примечание: Хотя вы могли бы выполнить преобразование значений линейного ползунка позже в рамках обычных попиксельных вычислений, быстрее и эффективнее сделать это сразу.
Далее вы будете обрабатывать значения пикселей в нескольких потоках, измеряя время выполнения. Вы можете использовать модуль time, чтобы определить, сколько времени требуется для настройки экспозиции и гаммы изображения. Вы также можете импортировать свой локальный пакет для быстрой параллельной обработки. Ваш редактор кода начнет жаловаться на отсутствие модуля parallel, но это нормально, потому что вы скоро его реализуете:
# image_processing.py
import argparse
import pathlib
import time
import tkinter as tk
import tkinter.ttk as ttk
import numpy as np
import PIL.Image
import PIL.ImageTk
import parallel
class AppWindow(tk.Tk):
# ...
def on_slide(self, *args, **kwargs) -> None:
# Get parameters
ev = 2.0 ** self.var_ev.get()
gamma = 1.0 / self.var_gamma.get()
# Process pixels
t1 = time.perf_counter()
pixels = self.pixels.copy()
parallel.process(pixels, ev, gamma)
t2 = time.perf_counter()
# ...
# ...
Обратите внимание, что вы создаете копию массива пикселей, прежде чем передать ее вместе с преобразованной экспозицией и гаммой в функцию parallel.process(). Это очень важно, поскольку позволяет изменять массив вместо без затрат на преобразование данных между C и Python. Вызов .copy() для массива указывает NumPy выделить новую память в C, на которую вы будете ссылаться с помощью указателя , который вы можете передать в свою скомпилированную библиотеку.
Наконец, вы хотите отобразить предварительный просмотр и обновить строку состояния:
# image_processing.py
# ...
class AppWindow(tk.Tk):
# ...
def on_slide(self, *args, **kwargs) -> None:
# Get parameters
ev = 2.0 ** self.var_ev.get()
gamma = 1.0 / self.var_gamma.get()
# Process pixels
t1 = time.perf_counter()
pixels = self.pixels.copy()
parallel.process(pixels, ev, gamma)
t2 = time.perf_counter()
# Render preview
image = PIL.Image.fromarray(pixels)
self.show_preview(image)
t3 = time.perf_counter()
# Update status
self.var_status.set(
f"Processed in {(t2 - t1) * 1000:.0f} ms "
f"(Rendered in {(t3 - t1) * 1000:.0f} ms)"
)
# ...
# ...
Вы преобразуете обновленный массив пикселей обратно в изображение-подушку и используете его в качестве основы для создания уменьшенных миниатюр. Кроме того, вы измеряете общее время рендеринга отдельно, поскольку отображение предварительного просмотра может быть намного медленнее, чем фактическая обработка пикселей.
На этом заканчивается большая часть вашего кода на Python в этом проекте. Готовы ли вы переключиться и ненадолго надеть шляпу программиста на Си?
Напишите функцию на языке Си для вычисления формулы пикселя
Большинство современных форматов файлов изображений используют цветовую модель RGB для хранения значений в пикселях. В этой модели каждый пиксель состоит из трех цветовых каналов: красного, зеленого и синего. Таким образом, вы можете представлять двумерные изображения в виде трехмерных массивов чисел. Действительно, когда вы преобразуете изображение подушки в массив NumPy, вы обычно получаете такой многомерный массив.
Несмотря на то, что массив NumPy типичного RGB-изображения имеет три измерения, соответствующие высоте, ширине и глубина (количество каналов), память вашего компьютера является только одномерной. На самом деле это хорошая новость, потому что она позволяет рассматривать такой трехмерный массив пикселей как повторяющуюся последовательность переплетенных цветовых компонентов - например, R1, G1, B1, R2, G2, B2 и так далее.
Предполагая, что вы можете получить указатель на такой массив цветовых компонентов и знать его длину, вы можете обработать значение каждого пикселя с помощью следующей функции C:
// parallel/parallel.c
#include <math.h>
void process(
unsigned char* pixels,
int length,
float ev,
float gamma)
{
for (int i = 0; i < length; i++) {
float value = powf((pixels[i] / 255.0f * ev), gamma) * 255.0f;
pixels[i] = (unsigned char) fmin(fmax(0.0f, value), 255.0f);
}
}
Функция process(), описанная выше, принимает следующие четыре параметра:
pixels: Указатель на массив байтов без знакаlength: Количество элементов в массивеev: Значение экспозиции преобразовано в логарифмическую шкалу с основанием 2gamma: Значение гамма-коррекции преобразовано в показатель степени
В отличие от списков Python , массивы в C не содержат информации о своей длине, поэтому вы должны указать количество элементов массива в качестве дополнительного параметра функции.
В теле функции вы выполняете итерацию по отдельным цветовым компонентам каждого пикселя в массиве, вычисляете новое значение и присваиваете его обратно входному массиву с соответствующим индексом. Для этого вы вызываете несколько стандартных функций языка Си из библиотеки math.
Популярные форматы файлов RGB, такие как JPEG, используют тип данных unsigned char для представления интенсивности 256 каналов, в то время как формула для экспозиции и гаммы предполагает нормализованные значения в пикселях. Вот почему вы делите pixel[i] на максимальное значение 255, прежде чем вводить его в формулу, а затем умножаете результат на 255.
Кроме того, вы ограничиваете результирующее значение диапазоном от 0 до 255, чтобы избежать переполнения целого числа при преобразовании числа обратно в unsigned char.
Этот код уже выглядит достаточно прилично и должен обеспечить вам ощутимый прирост производительности при компиляции. Однако ваша цель - обойти GIL в Python, чтобы вы могли запускать несколько потоков одновременно. В следующем разделе вы измените свою реализацию, чтобы сделать именно это.
Обрабатывать цветовые каналы в отдельных потоках выполнения
Если вы хотите обрабатывать данные параллельно, вы должны подумать о том, как наилучшим образом разделить их на фиксированное количество блоков примерно одинакового размера, чтобы обеспечить равномерное распределение по доступным ядрам процессора. Хотя вы могли бы разделить свой пиксельный массив на нескольких измерениях, возможно, было бы достаточно обработать каждый цветовой канал в отдельном потоке. В результате на изображение будет приходиться три рабочих потока, что сократит время обработки в три раза.
Еще одной причиной в пользу такого распределения рабочей нагрузки является то, что при этом не требуется думать о расположении данных. Массивы NumPy по умолчанию используют порядок следования основных строк, что иногда может повлиять на расположение ваших данных в кэше процессора, в зависимости от того, как вы получаете доступ к элементам. Однако в данном случае расположение данных не имеет значения, поскольку вы собираетесь применять идентичную формулу к каждому элементу массива независимо. Порядок их обработки для вас не имеет значения.
Вам не нужно сильно изменять существующий код, чтобы запустить функцию только для определенного цветового канала, а не для всего изображения. Чтобы избежать копирования отдельных цветовых компонентов в новые массивы, вы можете передать тот же массив функции, но попросить ее начать итерацию со смещением и пропускать вперед каждые три элемента:
// parallel/parallel.c
#include <math.h>
void process(
unsigned char* pixels,
int length,
int offset,
float ev,
float gamma)
{
for (int i = offset; i < length; i += 3) {
float value = powf((pixels[i] / 255.0f * ev), gamma) * 255.0f;
pixels[i] = (unsigned char) fmin(fmax(0.0f, value), 255.0f);
}
}
Вы вводите другой параметр с именем offset, который может быть равен нулю, единице или двум. Кроме того, вы изменяете цикл for, чтобы выполнять пошаговую обработку трех элементов одновременно. Это позволяет обрабатывать разные части одного и того же массива в разных потоках выполнения одновременно.
Примечание: Несмотря на то, что все потоки изменяют один и тот же массив, они не наступают друг другу на пятки, поскольку нет общего состояния. Смещение устраняет необходимость в дорогостоящей синхронизации доступа.
Прежде чем завершить реализацию вашего проекта на языке Си, есть один мощный метод оптимизации, который вы сейчас примените. Он слишком хорош, чтобы его упустить, поскольку может помочь вам значительно сократить объем вычислений.
Создайте таблицу поиска для общих значений пикселей
Обратите внимание, что каждый обрабатываемый вами компонент цвета имеет одно из 256 различных значений. В то же время изображения могут легко содержать десятки миллионов таких элементов, что делает неизбежным дублирование значений из-за принципа упорядочения. Однако при текущей реализации вы продолжаете снова и снова вычислять дорогостоящую формулу для одних и тех же входных значений, что является невероятно расточительным процессом.
Когда вы настраиваете экспозицию и гамму, вы, по сути, преобразуете один из 256 уровней интенсивности в другое значение в пределах того же диапазона. Таким образом, вместо многократного вычисления формулы для одинаковых значений в пикселях, вы можете создать таблицу поиска (LUT) один раз для всего диапазона возможных входных значений. Затем вы можете воспользоваться таблицей, чтобы быстро найти соответствующее выходное значение:
// parallel/parallel.c
#include <math.h>
void process(
unsigned char* pixels,
int length,
int offset,
float ev,
float gamma)
{
unsigned char lookup_table[256];
for (int i = 0; i < 256; i++) {
float value = powf((i / 255.0f * ev), gamma) * 255.0f;
lookup_table[i] = (unsigned char) fmin(fmax(0.0f, value), 255.0f);
}
for (int i = offset; i < length; i += 3) {
pixels[i] = lookup_table[pixels[i]];
}
}
Сначала вы объявляете локальную переменную, представляющую пустой массив с фиксированным размером в 256 элементов. Это ваша таблица поиска. Затем вы заполняете ее, применяя формулу ко всем возможным значениям. Обратите внимание, что вы используете индекс i в качестве входных данных формулы, тогда как ранее вы использовали pixels[i]. Наконец, вы выполняете итерацию по массиву пикселей, как и раньше, но подключаете таблицу поиска вместо вычисления новых значений пикселей для каждого элемента.
Здесь все еще присутствует элемент избыточности, поскольку каждый поток повторно вычисляет одну и ту же таблицу поиска для заданной пары экспозиции и гаммы. Потенциально вы могли бы смягчить это, объявив LUT как глобальную переменную, сохранив значения последней экспозиции и гаммы и синхронизировав доступ к общему состоянию.
К сожалению, использование взаимного исключения, чтобы избежать условий гонки приводит к огромным накладным расходам и, в первую очередь, не позволяет запускать несколько потоков. Блокировка предотвратила бы прогресс других потоков, в то время как другой поток вычислял бы общую таблицу поиска.
В любом случае, создание таблицы поиска по-прежнему стоит затраченных усилий. Несмотря на эту небольшую избыточность, вы должны ожидать ускорения на несколько порядков! Но чтобы увидеть его в действии, вы должны сложить последний кусочек пазла.
Совместное использование памяти между Python и C с помощью указателей
В этом разделе вы напишете удобную оболочку на Python для вашей библиотеки C, чтобы инкапсулировать технические детали динамической загрузки общего объекта с помощью ctypes. Вы также реализуете некоторый вспомогательный код, чтобы корректно передавать адрес памяти массива пикселей, выделенный NumPy, в вашу библиотеку. Наконец, вы запустите потоки и позволите им творить чудеса.
Теперь откройте свой терминал, измените текущий рабочий каталог на parallel/ package и выполните следующую команду для компиляции исходного кода на C:
$ gcc -shared -fPIC -O3 -o parallel.so parallel.c
Это должно выглядеть знакомо, поскольку вы уже использовали подобные команды для создания своего пользовательского модуля расширения C и реализации последовательности Фибоначчи на C. Он должен создать локальный файл с именем parallel.so без вывода каких-либо выходных данных на экран.
Теперь снова вернитесь в свой редактор кода, откройте модуль __init__.py, расположенный в вашем пакете parallel, и напишите в нем этот фрагмент кода на Python:
# parallel/__init__.py
import ctypes
import pathlib
# Load the compiled C library
library_path = str(pathlib.Path(__file__).parent / f"{__package__}.so")
library = ctypes.CDLL(library_path)
Вы создаете абсолютный путь к только что скомпилированному общему объекту, ожидая найти его в той же папке, что и текущий пакет, и под тем же именем (parallel.so). Затем вы пытаетесь динамически загрузить соответствующую библиотеку в Python.
Как только вы добьетесь успеха, вам следует определить прототип для вашей функции C, чтобы обеспечить правильное преобразование между типами данных Python и C:
# parallel/__init__.py
import ctypes
import pathlib
# Load the compiled C library
library_path = str(pathlib.Path(__file__).parent / f"{__package__}.so")
library = ctypes.CDLL(library_path)
# Define a C data type for "unsigned char*"
UnsignedByteArrayPointer = ctypes.POINTER(ctypes.c_ubyte)
# Define a prototype for the C function
library.process.argtypes = [
UnsignedByteArrayPointer, # unsigned char* pixels
ctypes.c_int, # int length
ctypes.c_int, # int offset
ctypes.c_float, # float ev
ctypes.c_float, # float gamma
]
Вы сообщаете Python, что в загруженной библиотеке есть функция с именем process(), которая принимает пять параметров указанных типов. Первый параметр - это указатель на массив байтов без знака или unsigned char элементов, использующих словарь языка Си. Чтобы избежать повторений в дальнейшем, вы сохраняете этот тип указателя во вспомогательной переменной.
В качестве последнего шага определите вспомогательную функцию, которую вы можете вызвать из Python:
# parallel/__init__.py
import ctypes
import pathlib
import threading
import numpy as np
# Load the compiled C library
library_path = str(pathlib.Path(__file__).parent / f"{__package__}.so")
library = ctypes.CDLL(library_path)
# Define a C data type for "unsigned char*"
UnsignedByteArrayPointer = ctypes.POINTER(ctypes.c_ubyte)
# Define a prototype for the C function
library.process.argtypes = [
UnsignedByteArrayPointer, # unsigned char* pixels
ctypes.c_int, # int length
ctypes.c_int, # int offset
ctypes.c_float, # float ev
ctypes.c_float, # float gamma
]
# Define a wrapper function accessible from Python
def process(pixels: np.ndarray, ev: float, gamma: float) -> None:
pointer = pixels.ctypes.data_as(UnsignedByteArrayPointer)
threads = [
threading.Thread(
target=library.process,
args=(pointer, pixels.size, offset, ev, gamma),
)
for offset in range(3)
]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
Эта функция имеет несколько более простую сигнатуру, чем ее аналог на C, потому что Python уже знает размер массива NumPy, поэтому ей не нужен параметр length. Более того, ваша функция-оболочка не ожидает смещения цветового канала, поскольку она заботится о запуске потоков и распределении рабочей нагрузки между ними.
Обратите внимание, как вы получаете указатель на свой массив pixels с помощью атрибута .ctypes, который предоставляет NumPy. Этот указатель обеспечивает параллелизм в общей памяти, позволяя вашим потокам ссылаться на один и тот же адрес памяти. Каждый поток обновляет массив на месте, к которому вы затем можете получить доступ в Python для предварительного просмотра. Нет необходимости копировать данные из одного места в другое или возвращать что-либо из вашей функции-оболочки.
Как только вы загрузите Изображение в формате Full HD (1920 × 1080 пикселей) в готовую программу, настройка экспозиции и применение гамма-коррекции приведут к мгновенному обновлению предварительного просмотра.
Обработка более шести миллионов элементов массива занимает всего несколько миллисекунд, в то время как общий рендеринг занимает в десять раз больше времени. Тем не менее, накладные расходы на графический интерфейс в данном случае не имеют большого значения, потому что вы в любом случае получаете отличную производительность.
По мере увеличения размеров изображения производительность начинает падать. Например, панорамное изображение в материалах состоит из почти 130 миллионов элементов массива. Их обработка занимает около пятидесяти миллисекунд, что все еще приемлемо, поскольку считается, что все, что длится менее ста миллисекунд, для большинства людей воспринимается мгновенно. К сожалению, общее время рендеринга увеличивается почти до четверти секунды.
Наконец, стоит отметить, что вам не нужно обрабатывать все пикселя только для отображения небольшого предварительного просмотра. Чтобы постоянно получать мгновенную обратную связь независимо от размера изображения, вы можете сначала уменьшить его масштаб и обработать значительно меньшее количество точек данных. Однако целью этого упражнения было проиллюстрировать один из способов раскрытия потенциала производительности Python путем отказа от GIL.
Когда вы дойдете до конца этой части, вы всегда сможете бесконечно расширять свой проект, если захотите. Например, вы можете добавить выпадающий список с выбором режимов обработки, включая однопоточный режим, многопоточный режим и даже режим с графическим ускорением. Вы могли бы даже попробовать Тайчи Ланг.
Заключение
На данный момент у вас должно быть четкое представление о параллельной обработке данных и различных способах использования ее возможностей в Python. Вы знаете, как многопоточность в Python сравнивается с другими языками программирования. Попутно вы узнали о глобальной блокировке интерпретатора (GIL) и традиционных способах ее обхода, а также о недостатках этих подходов.
Кроме того, вы изучили несколько стратегий, позволяющих заставить потоки Python действительно работать параллельно. После замены CPython альтернативной средой выполнения и использования библиотеки, защищенной от GIL, вы углубились в взаимодействие вашего кода на Python с C. Вы даже разделяли память между обоими языками с помощью низкоуровневых указателей.
Наконец, вы ознакомились с практическим примером параллельной обработки изображений на Python, создав небольшое настольное приложение.
В этом руководстве вы узнали, как:
- Запускайте потоков Python параллельно на нескольких ядрах процессора
- Избегайте сериализации данных накладных расходов, связанных с многопроцессорной обработкой
- Совместное использование памяти между средами выполнения Python и C
- Используйте различные стратегии, чтобы обойти GIL в Python
- Распараллеливайте свои программы на Python, чтобы повысить их производительность
- Создайте образец настольного приложения для параллельной обработки изображений
Вы прошли большой путь и углубили свои знания о внутреннем устройстве Python. Если вы хотите ознакомиться со всей проделанной вами работой, вы можете загрузить пример кода и изображения для этого руководства ниже:
Получите свой код: Нажмите здесь, чтобы загрузить бесплатный пример кода, который показывает, как обойти GIL и добиться параллельной обработки в Python.
Back to Top