Журналирование Python: прогулка по исходному коду
Оглавление
- Как следовать дальше
- Прелиминарии
- Архитектура пакетов: MRO Logging
- Всеобъемлющий корневой регистратор
- "Почему мое сообщение в журнале никуда не делось?" Dilemma
- Использование преимуществ ленивого форматирования
- Функции против методов
- Что на самом деле делает getLogger()?
- Библиотека против регистрации в приложении: Что такое NullHandler?
- Что логирование делает с исключениями
- Запись в журнал трассировок Python
- Заключение
Пакет Python logging - это легкий, но расширяемый пакет для более точного отслеживания того, что делает ваш собственный код. Его использование дает вам гораздо больше гибкости, чем просто замусоривание кода лишними вызовами print().
Однако пакет Python logging может быть сложным в некоторых местах. Обработчики, регистраторы, уровни, пространства имен, фильтры: нелегко уследить за всеми этими частями и за тем, как они взаимодействуют.
Один из способов связать концы с концами в вашем понимании logging - заглянуть под капот к его CPython исходному коду. Код на языке Python, лежащий в основе logging, лаконичен и модулен, и чтение его может помочь вам в тот самый aha момент.
Эта статья призвана дополнить документ по логированию HOWTO, а также Logging in Python, в котором рассказывается о том, как использовать пакет.
К концу этой статьи вы будете знакомы со следующим:
loggingуровни и как они работают- Безопасность потоков против безопасности процессов в
logging - Проектирование
loggingс точки зрения ООП - Запись в библиотеки и приложения
- Лучшие практики и паттерны проектирования для использования
logging
По большей части мы будем построчно рассматривать основной модуль в пакете logging Python, чтобы составить представление о том, как он устроен.
Как следовать за ним
Поскольку исходный код logging занимает центральное место в этой статье, вы можете считать, что любой блок кода или ссылка основаны на определенном коммите в репозитории Python 3.7 CPython, а именно коммите d730719. Сам пакет logging можно найти в каталоге Lib/ в исходниках CPython.
Внутри пакета logging большая часть тяжелой работы происходит внутри logging/__init__.py, и именно на этот файл вы потратите больше всего времени:
cpython/
│
├── Lib/
│ ├── logging/
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── handlers.py
│ ├── ...
├── Modules/
├── Include/
...
... [truncated]
С этим давайте перейдем к делу.
Примитивы
Прежде чем мы перейдем к тяжелым весовым категориям, первые сто строк __init__.py вводят несколько тонких, но важных понятий.
Примечание #1: Уровень — это просто целое число!
Объекты типа logging.INFO или logging.DEBUG могут показаться немного непрозрачными. Что представляют собой эти переменные внутри и как они определяются?
Фактически, прописные константы из Python logging - это просто целые числа, образующие перечислительную коллекцию числовых уровней:
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
Почему бы просто не использовать строки "INFO" или "DEBUG"? Уровни - это int константы, позволяющие просто и однозначно сравнивать один уровень с другим. Им также даются имена, чтобы придать им семантический смысл. Сказать, что сообщение имеет уровень серьезности 50, может быть не сразу понятно, но, сказав, что оно имеет уровень CRITICAL, вы поймете, что где-то в вашей программе есть мигающий красный свет.
Теперь, технически, вы можете передавать только str форму уровня в некоторых местах, например logger.setLevel("DEBUG"). Внутренне это вызовет _checkLevel(), который в конечном итоге выполнит поиск dict для соответствующего int:
_nameToLevel = {
'CRITICAL': CRITICAL,
'FATAL': FATAL,
'ERROR': ERROR,
'WARN': WARNING,
'WARNING': WARNING,
'INFO': INFO,
'DEBUG': DEBUG,
'NOTSET': NOTSET,
}
def _checkLevel(level):
if isinstance(level, int):
rv = level
elif str(level) == level:
if level not in _nameToLevel:
raise ValueError("Unknown level: %r" % level)
rv = _nameToLevel[level]
else:
raise TypeError("Level not an integer or a valid string: %r" % level)
return rv
Какую форму вы предпочитаете? Я не слишком высокого мнения на этот счет, но примечательно, что в документации logging постоянно используется форма logging.DEBUG, а не "DEBUG" или 10. Кроме того, передача формы str не является опцией в Python 2, а некоторые методы logging, такие как logger.isEnabledFor(), будут принимать только int, а не его str кузена.
Предварительное замечание №2: Ведение журнала безопасно для потоков, но не для процессов
Несколькими строками ниже вы найдете следующий короткий блок кода, который незаметно является критически важным для всего пакета:
import threading
_lock = threading.RLock()
def _acquireLock():
if _lock:
_lock.acquire()
def _releaseLock():
if _lock:
_lock.release()
Объект _lock - это реентерабельная блокировка, которая располагается в глобальном пространстве имен модуля logging/__init__.py. Она делает практически все объекты и операции во всем пакете logging потокобезопасными, позволяя потокам выполнять операции чтения и записи без угрозы возникновения состояния гонки. В исходном коде модуля видно, что _acquireLock() и _releaseLock() вездесущи в модуле и его классах.
Однако здесь кое-что не учтено: как насчет безопасности процесса? Короткий ответ заключается в том, что модуль logging является не безопасным для процессов. По своей сути это не является недостатком logging - как правило, два процесса не могут писать в один и тот же файл без особых усилий со стороны программиста.
Это означает, что вы должны быть осторожны, прежде чем использовать такие классы, как logging.FileHandler, с многопроцессорной обработкой. Если два процесса захотят одновременно читать из одного и того же базового файла и записывать в него, вы можете столкнуться с неприятной ошибкой на полпути к выполнению длительной процедуры.
Если вы хотите обойти это ограничение, то в официальной книге Logging Cookbook есть подробный рецепт. Поскольку это влечет за собой приличное количество настроек, одной из альтернатив является ведение журнала каждым процессом в отдельный файл, основанный на его идентификаторе процесса, который можно получить с помощью os.getpid().
Архитектура пакета: MRO Logging
Теперь, когда мы рассмотрели некоторые предварительные настройки, давайте посмотрим на то, как устроен logging. В пакете logging используется здоровая доза OOP и наследования. Вот частичный обзор порядка разрешения методов (MRO) для некоторых наиболее важных классов пакета:
object
│
├── LogRecord
├── Filterer
│ ├── Logger
│ │ └── RootLogger
│ └── Handler
│ ├── StreamHandler
│ └── NullHandler
├── Filter
└── Manager
Приведенная выше древовидная диаграмма охватывает не все классы модуля, а только те, которые наиболее достойны внимания.
Примечание: Вы можете использовать атрибут dunder logging.StreamHandler.__mro__, чтобы увидеть цепочку наследования. Окончательное руководство по MRO можно найти в документации по Python 2, хотя оно применимо и к Python 3.
Это перечисление классов обычно является одним из источников путаницы, потому что происходит много событий, и все они написаны на жаргоне. Filter против Filterer? Logger против Handler? Бывает сложно уследить за всем, а тем более представить, как все это сочетается. Картинка стоит тысячи слов, поэтому вот схема сценария, в котором один логгер с двумя прикрепленными к нему обработчиками пишет сообщение журнала с уровнем logging.INFO:
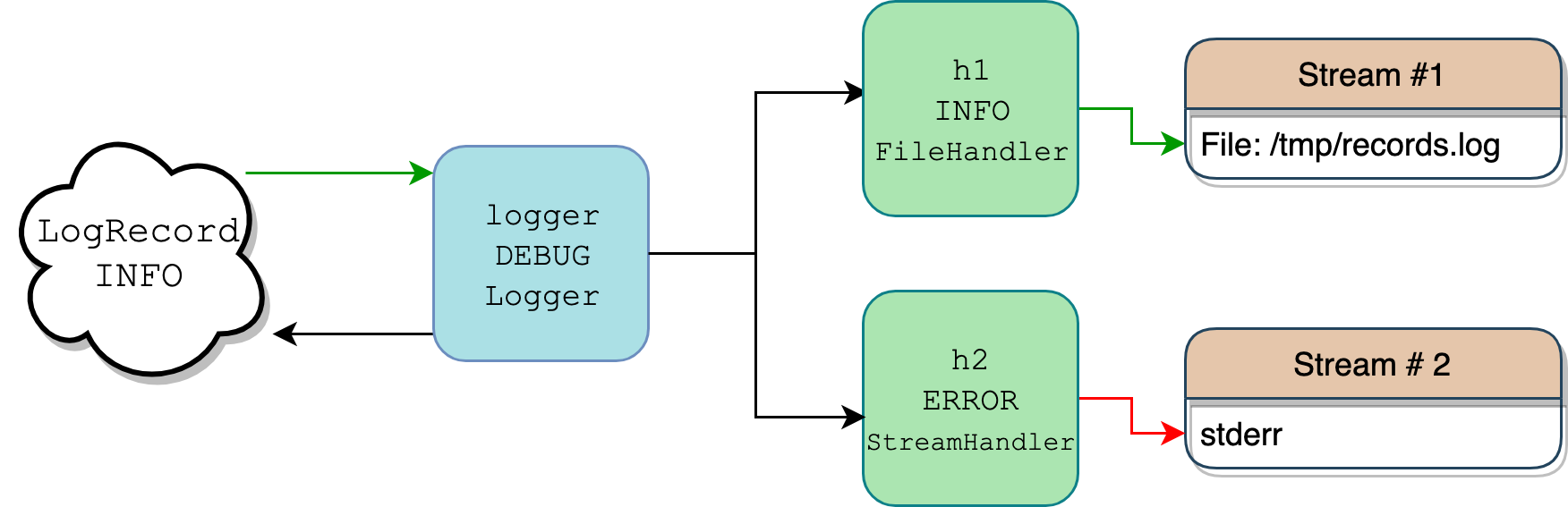
Поток объектов протоколирования (Изображение: Real Python)
В коде Python все вышеописанное выглядело бы так:
import logging
import sys
logger = logging.getLogger("pylog")
logger.setLevel(logging.DEBUG)
h1 = logging.FileHandler(filename="/tmp/records.log")
h1.setLevel(logging.INFO)
h2 = logging.StreamHandler(sys.stderr)
h2.setLevel(logging.ERROR)
logger.addHandler(h1)
logger.addHandler(h2)
logger.info("testing %d.. %d.. %d..", 1, 2, 3)
Более подробная карта этого потока есть в Logging HOWTO. То, что показано выше, - это упрощенный сценарий.
Ваш код определяет только один экземпляр Logger, logger, и два экземпляра Handler, h1 и h2.
При вызове logger.info("testing %d.. %d.. %d..", 1, 2, 3) объект logger служит в качестве фильтра, поскольку с ним также связан объект level. Только если уровень сообщения достаточно серьезный, регистратор будет что-то делать с сообщением. Поскольку регистратор имеет уровень DEBUG, а сообщение имеет более высокий уровень INFO, он получает разрешение двигаться дальше.
Внутри logger вызывает logger.makeRecord(), чтобы поместить строку сообщения "testing %d.. %d.. %d.." и его аргументы (1, 2, 3) в добросовестный экземпляр класса LogRecord, который является просто контейнером для сообщения и его метаданных.
Объект logger ищет свои обработчики (экземпляры Handler), которые могут быть привязаны непосредственно к самому logger или к его родителям (это понятие мы рассмотрим позже). В этом примере он находит два обработчика:
- Один с уровнем
INFO, который сбрасывает данные журнала в файл по адресу/tmp/records.log - Один, который пишет в
sys.stderr, но только если входящее сообщение имеет уровеньERRORили выше
На этом этапе начинается еще один раунд проверки. Поскольку LogRecord и его сообщение несут только уровень INFO, запись записывается в поток обработчика 1 (зеленая стрелка), но не в поток stderr обработчика 2 (красная стрелка). Для обработчиков запись LogRecord в их поток называется выдачей , что фиксируется в их .emit().
Далее давайте разберем все, что было сказано выше.
Класс LogRecord
Что такое LogRecord? Когда вы регистрируете сообщение, экземпляр класса LogRecord является объектом, который вы посылаете для регистрации. Он создается для вас экземпляром Logger и содержит всю необходимую информацию об этом событии. Внутри он представляет собой не более чем обертку вокруг dict, содержащую атрибуты записи. Экземпляр Logger отправляет экземпляр LogRecord к нулю или более экземплярам Handler.
В LogRecord содержатся некоторые метаданные, например, следующие:
- Имя
- Время создания в виде временной метки Unix
- Само сообщение
- Информация о том, какая функция выполнила вызов логирования
Вот взгляд на метаданные, которые он несет с собой, и которые вы можете изучить, пройдя через вызов logging.error() с помощью pdb модуля :
>>> import logging
>>> import pdb
>>> def f(x):
... logging.error("bad vibes")
... return x / 0
...
>>> pdb.run("f(1)")
Пройдя через несколько функций более высокого уровня, вы оказываетесь в строке 1517:
(Pdb) l
1514 exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
1515 elif not isinstance(exc_info, tuple):
1516 exc_info = sys.exc_info()
1517 record = self.makeRecord(self.name, level, fn, lno, msg, args,
1518 exc_info, func, extra, sinfo)
1519 -> self.handle(record)
1520
1521 def handle(self, record):
1522 """
1523 Call the handlers for the specified record.
1524
(Pdb) from pprint import pprint
(Pdb) pprint(vars(record))
{'args': (),
'created': 1550671851.660067,
'exc_info': None,
'exc_text': None,
'filename': '<stdin>',
'funcName': 'f',
'levelname': 'ERROR',
'levelno': 40,
'lineno': 2,
'module': '<stdin>',
'msecs': 660.067081451416,
'msg': 'bad vibes',
'name': 'root',
'pathname': '<stdin>',
'process': 2360,
'processName': 'MainProcess',
'relativeCreated': 295145.5490589142,
'stack_info': None,
'thread': 4372293056,
'threadName': 'MainThread'}
Внутри LogRecord содержится множество метаданных, которые используются тем или иным образом.
Вам редко придется иметь дело с LogRecord напрямую, поскольку Logger и Handler сделают это за вас. Но все же стоит знать, какая информация содержится в LogRecord, потому что именно оттуда берется вся полезная информация, например временная метка, когда вы видите сообщения журнала записи.
Примечание: Ниже класса LogRecord вы также найдете функции setLogRecordFactory(), getLogRecordFactory() и makeLogRecord() фабрики . Они вам не понадобятся, если только вы не захотите использовать пользовательский класс вместо LogRecord для инкапсуляции сообщений журнала и их метаданных.
Классы Logger и Handler
Классы Logger и Handler занимают центральное место в работе logging, и они часто взаимодействуют друг с другом. У Logger, Handler и LogRecord есть .level, связанный с ними.
Logger принимает LogRecord и передает его Handler, но только если эффективный уровень LogRecord равен или выше, чем у Logger. То же самое относится и к тесту LogRecord против Handler. Это называется фильтрацией на основе уровней, которую Logger и Handler реализуют немного по-разному.
Другими словами, прежде чем сообщение, которое вы регистрируете, попадет куда-либо, проводится (как минимум) двухступенчатая проверка. Для того чтобы сообщение полностью перешло от регистратора к обработчику и затем было занесено в конечный поток (которым может быть sys.stdout, файл или электронное письмо по SMTP), LogRecord должно иметь уровень не ниже как , так и регистратора и обработчика.
PEP 282 описывает, как это работает:
Каждый объект
Loggerотслеживает уровень (или порог) журнала, который его интересует, и отбрасывает запросы журнала ниже этого уровня. (Источник)
Так где же на самом деле происходит эта фильтрация на основе уровня для Logger и Handler?
Для класса Logger разумно предположить, что регистратор сравнит свой атрибут .level с уровнем LogRecord и на этом закончит. Однако все обстоит несколько сложнее.
Поуровневая фильтрация для логгеров происходит в .isEnabledFor(), который, в свою очередь, вызывает .getEffectiveLevel(). Всегда используйте logger.getEffectiveLevel(), а не просто обращайтесь к logger.level. Это связано с организацией объектов Logger в иерархическом пространстве имен. (Подробнее об этом будет рассказано позже.)
По умолчанию экземпляр Logger имеет уровень 0 (NOTSET). Однако у регистраторов также есть родительские регистраторы , один из которых является корневым регистратором, который функционирует как родитель всех остальных регистраторов. Логгер Logger будет подниматься вверх по иерархии и получать свой эффективный уровень по отношению к своему родителю (который в конечном итоге может быть root, если не найдено других родителей).
Вот где это происходит в Logger классе:
class Logger(Filterer):
# ...
def getEffectiveLevel(self):
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
try:
return self._cache[level]
except KeyError:
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
Соответственно, вот пример, вызывающий исходный код, который вы видите выше:
>>> import logging
>>> logger = logging.getLogger("app")
>>> logger.level # No!
0
>>> logger.getEffectiveLevel()
30
>>> logger.parent
<RootLogger root (WARNING)>
>>> logger.parent.level
30
Вот вывод: не полагайтесь на .level. Если вы явно не задали уровень для своего объекта logger и по какой-то причине полагаетесь на .level, то ваша настройка протоколирования, скорее всего, будет вести себя не так, как вы ожидали.
А как насчет Handler? Для обработчиков сравнение между уровнями проще, хотя на самом деле оно происходит в .callHandlers() из класса Logger:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
Для данного экземпляра LogRecord (названного record в исходном коде выше) регистратор проверяет каждый из своих зарегистрированных обработчиков и выполняет быструю проверку атрибута .level этого экземпляра Handler. Если .levelno атрибута LogRecord больше или равен атрибуту обработчика, только тогда запись передается дальше. В docstring в logging это называется "условно выдать указанную запись протоколирования".
Самым важным атрибутом для экземпляра подкласса Handler является его атрибут .stream. Это конечное место, куда записываются журналы, и им может быть практически любой файлоподобный объект. Вот пример с io.StringIO, который представляет собой поток в памяти (буфер) для ввода/вывода текста.
Сначала создайте экземпляр Logger с уровнем DEBUG. Вы увидите, что по умолчанию у него нет прямых обработчиков:
>>> import io
>>> import logging
>>> logger = logging.getLogger("abc")
>>> logger.setLevel(logging.DEBUG)
>>> print(logger.handlers)
[]
Далее, вы можете подклассифицировать logging.StreamHandler, чтобы сделать вызов .flush() неоперативным. В этом случае мы захотим прошить sys.stderr или sys.stdout, но не буфер в памяти:
class IOHandler(logging.StreamHandler):
def flush(self):
pass # No-op
Теперь объявите сам объект буфера и привяжите его в качестве .stream для вашего пользовательского обработчика с уровнем INFO, а затем привяжите этот обработчик к логгеру:
>>> stream = io.StringIO()
>>> h = IOHandler(stream)
>>> h.setLevel(logging.INFO)
>>> logger.addHandler(h)
>>> logger.debug("extraneous info")
>>> logger.warning("you've been warned")
>>> logger.critical("SOS")
>>> try:
... print(stream.getvalue())
... finally:
... stream.close()
...
you've been warned
SOS
Этот последний кусок - еще одна иллюстрация фильтрации на основе уровней.
По цепочке передаются три сообщения с уровнями DEBUG, WARNING и CRITICAL. Сначала может показаться, что они никуда не попадают, но два из них попадают. Все трое выходят из ворот logger (которые имеют уровень DEBUG).
Однако только два из них выдаются обработчиком, потому что он имеет более высокий уровень INFO, который превышает DEBUG. Наконец, вы получаете все содержимое буфера в виде str и закрываете буфер, чтобы явно освободить системные ресурсы.
Классы Filter и Filterer
Выше мы задали вопрос: "Где происходит фильтрация на основе уровней?". Отвечая на этот вопрос, легко отвлечься на классы Filter и Filterer. Парадоксально, но фильтрация по уровням для экземпляров Logger и Handler происходит без помощи классов Filter и Filterer.
Filter и Filterer предназначены для того, чтобы вы могли добавлять дополнительные фильтры на основе функций поверх фильтрации на основе уровней, которая выполняется по умолчанию. Мне нравится думать об этом как о а-ля-карт фильтрации.
Filterer является базовым классом для Logger и Handler, поскольку оба эти класса могут получать дополнительные пользовательские фильтры, которые вы указываете. Вы добавляете к ним экземпляры Filter с помощью logger.addFilter() или handler.addFilter(), на которые и ссылается self.filters в следующем методе:
class Filterer(object):
# ...
def filter(self, record):
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record)
if not result:
rv = False
break
return rv
Данная запись record (которая является экземпляром LogRecord), .filter() возвращает True или False в зависимости от того, получила ли эта запись разрешение от фильтров этого класса.
Вот .handle(), в свою очередь, для классов Logger и Handler:
class Logger(Filterer):
# ...
def handle(self, record):
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
# ...
class Handler(Filterer):
# ...
def handle(self, record):
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
Ни Logger, ни Handler по умолчанию не содержат никаких дополнительных фильтров, но вот пример того, как их можно добавить:
>>> import logging
>>> logger = logging.getLogger("rp")
>>> logger.setLevel(logging.INFO)
>>> logger.addHandler(logging.StreamHandler())
>>> logger.filters # Initially empty
[]
>>> class ShortMsgFilter(logging.Filter):
... """Only allow records that contain long messages (> 25 chars)."""
... def filter(self, record):
... msg = record.msg
... if isinstance(msg, str):
... return len(msg) > 25
... return False
...
>>> logger.addFilter(ShortMsgFilter())
>>> logger.filters
[<__main__.ShortMsgFilter object at 0x10c28b208>]
>>> logger.info("Reeeeaaaaallllllly long message") # Length: 31
Reeeeaaaaallllllly long message
>>> logger.info("Done") # Length: <25, no output
Выше вы определяете класс ShortMsgFilter и переопределяете его .filter(). В .addHandler() можно также просто передать вызываемый объект, например функцию или лямбду или класс, определяющий .__call__().
Класс Manager
Есть еще одно закулисное действующее лицо logging, на котором стоит остановиться: класс Manager. Важнее всего не класс Manager, а его единственный экземпляр, который выступает в качестве контейнера для растущей иерархии логгеров, определенных в пакетах. В следующем разделе вы увидите, как один-единственный экземпляр этого класса играет центральную роль в склеивании модуля и позволяет его частям общаться друг с другом.
Всеобъемлющий корневой регистратор
Когда речь заходит об экземплярах Logger, один из них выделяется. Он называется корневым регистратором:
class RootLogger(Logger):
def __init__(self, level):
Logger.__init__(self, "root", level)
# ...
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
Последние три строки этого блока кода - один из хитроумных приемов, используемых пакетом logging. Вот несколько моментов:
-
Корневой логгер - это просто не требующий особых усилий объект Python с идентификатором
root. Он имеет уровеньlogging.WARNINGи уровень.name"root". Что касается классаRootLogger, то это уникальное имя - все, что в нем есть особенного. -
Объект
rootв свою очередь становится атрибутом класса для классаLogger. Это означает, что все экземплярыLoggerи сам классLoggerимеют атрибут.root, который является корневым регистратором. Это еще один пример применения в пакетеloggingшаблона, подобного синглтону. -
Экземпляр
Managerзадается в качестве атрибута.managerкласса дляLogger. В конечном счете это используется вlogging.getLogger("name")..managerвыполняет все действия по поиску существующих регистраторов с именем"name"и их созданию, если они не существуют.
Иерархия регистраторов
Everything является дочерним элементом root в пространстве имен logger, и я имею в виду все. Это включает в себя логгеры, которые вы определяете сами, а также логгеры из сторонних библиотек, которые вы импортируете.
Помните, как ранее .getEffectiveLevel() для наших экземпляров logger был равен 30 (WARNING), хотя мы не задавали его явно? Это потому, что корневой регистратор находится на вершине иерархии, и его уровень является запасным, если вложенные регистраторы имеют нулевой уровень NOTSET:
>>> root = logging.getLogger() # Or getLogger("")
>>> root
<RootLogger root (WARNING)>
>>> root.parent is None
True
>>> root.root is root # Self-referential
True
>>> root is logging.root
True
>>> root.getEffectiveLevel()
30
Та же логика применима к поиску обработчиков логгера. Поиск фактически представляет собой поиск в обратном порядке по дереву родителей регистратора.
Конструкция с несколькими ручками
Иерархия логгеров может показаться аккуратной в теории, но насколько она полезна на практике?
Давайте отвлечемся от изучения кода logging и займемся написанием собственного мини-приложения - такого, которое использует преимущества иерархии логгеров таким образом, чтобы сократить количество шаблонного кода и сохранить масштабируемость при росте кодовой базы проекта.
Вот структура проекта:
project/
│
└── project/
├── __init__.py
├── utils.py
└── base.py
Не беспокойтесь об основных функциях приложения в utils.py и base.py. Здесь мы уделяем больше внимания взаимодействию в объектах logging между модулями в project/.
В этом случае, допустим, вы хотите разработать многоцелевую систему протоколирования:
-
Каждый модуль получает
loggerс несколькими обработчиками. -
Некоторые обработчики разделяются между различными
loggerэкземплярами в разных модулях. Этим обработчикам важна только фильтрация по уровню, а не модуль, из которого поступила запись журнала. Есть обработчик дляDEBUGсообщений, один дляINFO, один дляWARNINGи так далее. -
Каждый
loggerтакже привязан к еще одному дополнительному обработчику, который получаетLogRecordтолько экземпляры от этого одинокогоlogger. Это можно назвать обработчиком файлов на основе модулей.
Визуально то, к чему мы стремимся, выглядит примерно так:
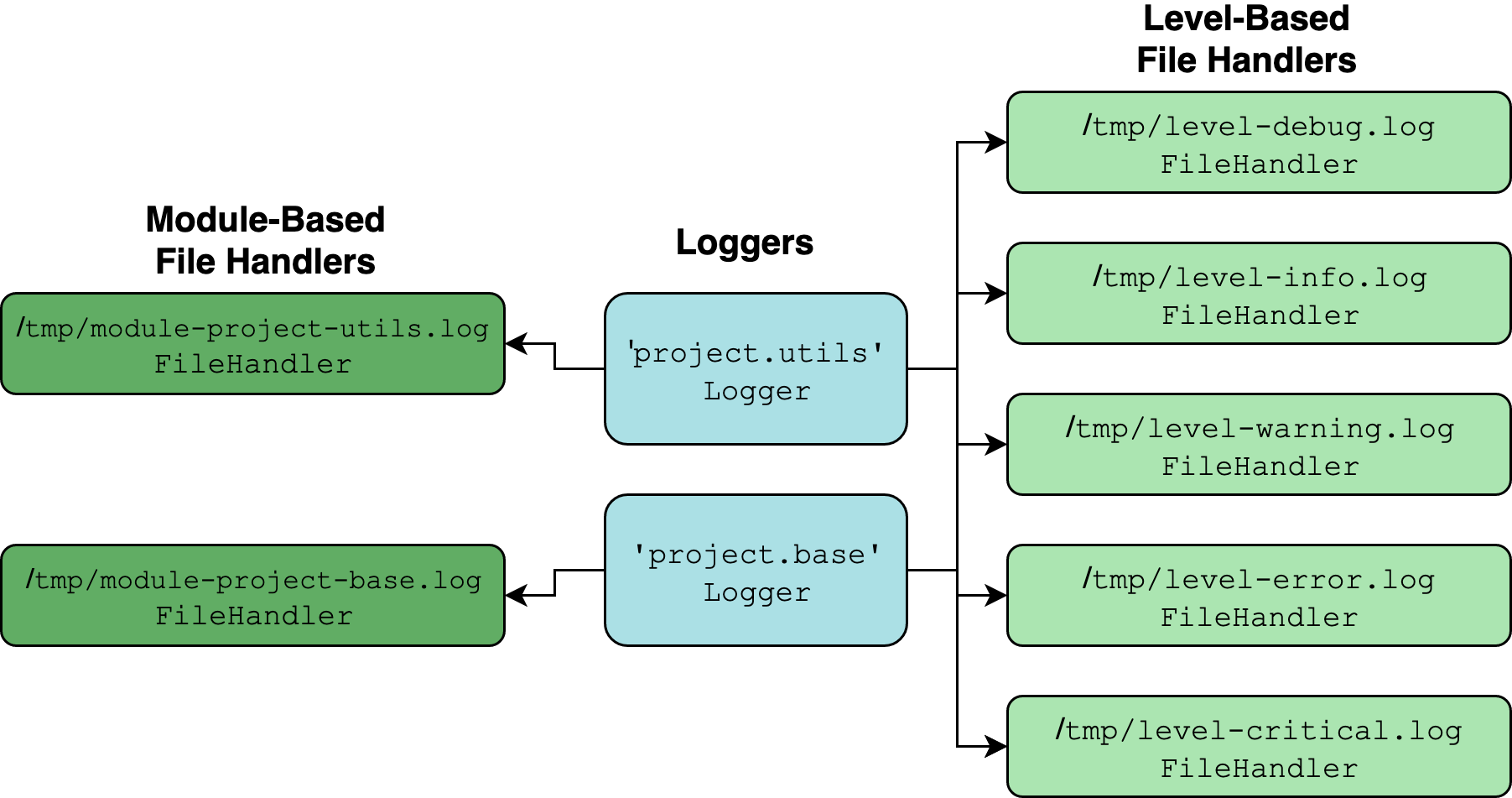
Многоцелевая конструкция логирования (Изображение: Real Python)
Два бирюзовых объекта - это экземпляры Logger, созданные с помощью logging.getLogger(__name__) для каждого модуля в пакете. Все остальное - это экземпляры Handler.
Идея такого дизайна заключается в том, что он аккуратно разделен. Вы можете удобно просматривать сообщения, поступающие от одного регистратора, или просматривать сообщения определенного уровня и выше, поступающие от любого регистратора или модуля.
Свойства иерархии логгеров делают ее пригодной для создания такой многосторонней схемы логгер-хендлер. Что это значит? Вот краткое объяснение из документации Django:
Почему иерархия важна? Потому что логгеры можно настроить так, чтобы они передавали вызовы логирования своим родителям. Таким образом, вы можете определить один набор обработчиков в корне дерева логгеров, а все вызовы логирования перехватить в поддереве логгеров. Обработчик журнализации, определенный в пространстве имен
project, будет перехватывать все сообщения журнализации, выданные на регистраторахproject.interestingиproject.interesting.stuff. (Источник)
Термин propagate относится к тому, как логгер продолжает идти по цепочке своих родителей в поисках обработчиков. Атрибут .propagate по умолчанию является True для экземпляра Logger:
>>> logger = logging.getLogger(__name__)
>>> logger.propagate
True
В .callHandlers(), если propagate является True, каждый последующий родитель переназначается на локальную переменную c, пока иерархия не будет исчерпана:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None
else:
c = c.parent
Вот что это значит: поскольку переменная __name__ dunder в модуле __init__.py пакета - это просто имя пакета, логгер в нем становится родителем для любых логгеров, присутствующих в других модулях того же пакета.
Вот атрибуты .name, полученные в результате присвоения logger с помощью logging.getLogger(__name__):
| Module | .name Attribute |
|---|---|
project/__init__.py |
'project' |
project/utils.py |
'project.utils' |
project/base.py |
'project.base' |
Поскольку регистраторы 'project.utils' и 'project.base' являются дочерними по отношению к 'project', они будут цепляться не только за свои собственные прямые обработчики, но и за любые обработчики, прикрепленные к 'project'.
Давайте соберем модули. Сначала идет __init__.py:
# __init__.py
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
levels = ("DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL")
for level in levels:
handler = logging.FileHandler(f"/tmp/level-{level.lower()}.log")
handler.setLevel(getattr(logging, level))
logger.addHandler(handler)
def add_module_handler(logger, level=logging.DEBUG):
handler = logging.FileHandler(
f"/tmp/module-{logger.name.replace('.', '-')}.log"
)
handler.setLevel(level)
logger.addHandler(handler)
Этот модуль импортируется при импорте пакета project. Вы добавляете обработчик для каждого уровня с DEBUG по CRITICAL, а затем прикрепляете его к одному регистратору на вершине иерархии.
Вы также определяете служебную функцию, которая добавляет еще один FileHandler к логгеру, где filename обработчика соответствует имени модуля, в котором определен логгер. (Это предполагает, что логгер определен с помощью __name__.)
Затем вы можете добавить минимальную шаблонную настройку логгера в base.py и utils.py. Обратите внимание, что вам нужно добавить только один дополнительный обработчик в add_module_handler() из __init__.py. Вам не нужно беспокоиться об обработчиках, ориентированных на уровень, потому что они уже добавлены в родительский логгер с именами 'project':
# base.py
import logging
from project import add_module_handler
logger = logging.getLogger(__name__)
add_module_handler(logger)
def func1():
logger.debug("debug called from base.func1()")
logger.critical("critical called from base.func1()")
Вот utils.py:
# utils.py
import logging
from project import add_module_handler
logger = logging.getLogger(__name__)
add_module_handler(logger)
def func2():
logger.debug("debug called from utils.func2()")
logger.critical("critical called from utils.func2()")
Давайте посмотрим, как все это работает вместе в свежей сессии Python:
>>> from pprint import pprint
>>> import project
>>> from project import base, utils
>>> project.logger
<Logger project (DEBUG)>
>>> base.logger, utils.logger
(<Logger project.base (DEBUG)>, <Logger project.utils (DEBUG)>)
>>> base.logger.handlers
[<FileHandler /tmp/module-project-base.log (DEBUG)>]
>>> pprint(base.logger.parent.handlers)
[<FileHandler /tmp/level-debug.log (DEBUG)>,
<FileHandler /tmp/level-info.log (INFO)>,
<FileHandler /tmp/level-warning.log (WARNING)>,
<FileHandler /tmp/level-error.log (ERROR)>,
<FileHandler /tmp/level-critical.log (CRITICAL)>]
>>> base.func1()
>>> utils.func2()
В результирующих лог-файлах вы увидите, что наша система фильтрации работает как надо. Обработчики, ориентированные на модули, направляют один логгер в определенный файл, а обработчики, ориентированные на уровни, направляют несколько логгеров в разные файлы:
$ cat /tmp/level-debug.log
debug called from base.func1()
critical called from base.func1()
debug called from utils.func2()
critical called from utils.func2()
$ cat /tmp/level-critical.log
critical called from base.func1()
critical called from utils.func2()
$ cat /tmp/module-project-base.log
debug called from base.func1()
critical called from base.func1()
$ cat /tmp/module-project-utils.log
debug called from utils.func2()
critical called from utils.func2()
Недостатком, о котором стоит упомянуть, является то, что такая конструкция вносит много избыточности. Один экземпляр LogRecord может обращаться не менее чем к шести файлам. Это также немалый объем файлового ввода-вывода, который может увеличиться в критически важном для производительности приложении.
Теперь, когда вы увидели практический пример, давайте переключимся и рассмотрим возможный источник путаницы в logging.
"Почему мое сообщение в журнале никуда не отправилось?" Дилемма
Есть две распространенные ситуации с logging, когда легко споткнуться:
- Вы записали в журнал сообщение, которое, казалось бы, никуда не делось, и вы не уверены, почему.
- Вместо того чтобы быть подавленным, сообщение в журнале появилось там, где вы этого не ожидали.
У каждого из них есть причина или две, которые обычно ассоциируются с ним.
Вы зарегистрировали сообщение, которое, похоже, ни к чему не привело, и вы не уверены, почему.
Не забывайте, что эффективный уровень регистратора, для которого вы не задали пользовательский уровень, равен WARNING, потому что регистратор будет подниматься по иерархии, пока не найдет корневой регистратор со своим WARNING уровнем:
>>> import logging
>>> logger = logging.getLogger("xyz")
>>> logger.debug("mind numbing info here")
>>> logger.critical("storm is coming")
storm is coming
Из-за этого умолчания вызов .debug() никуда не приведет.
Вместо того чтобы быть подавленным, сообщение журнала появилось в том месте, где вы этого не ожидали.
Когда вы определяли свой logger выше, вы не добавили к нему никаких обработчиков. Так почему же он пишет в консоль?
Причина в том, что logging незаметно использует обработчик lastResort, который пишет в sys.stderr, если не найдено других обработчиков:
class _StderrHandler(StreamHandler):
# ...
@property
def stream(self):
return sys.stderr
_defaultLastResort = _StderrHandler(WARNING)
lastResort = _defaultLastResort
Это срабатывает, когда логгер пытается найти свои обработчики:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
Если регистратор отказывается от поиска обработчиков (как собственных прямых обработчиков, так и атрибутов родительских регистраторов), то он подбирает обработчик lastResort и использует его.
Есть еще одна тонкая деталь, о которой стоит знать. В этом разделе речь шла в основном о методах экземпляра (методах, определяемых классом), а не о функциях уровня модуля пакета logging, которые носят то же имя.
Если вы используете функции, например logging.info(), а не logger.info(), то внутри происходит нечто несколько иное. Функция вызывает logging.basicConfig(), которая добавляет StreamHandler, записывающий в sys.stderr. В итоге поведение практически не меняется:
>>> import logging
>>> root = logging.getLogger("")
>>> root.handlers
[]
>>> root.hasHandlers()
False
>>> logging.basicConfig()
>>> root.handlers
[<StreamHandler <stderr> (NOTSET)>]
>>> root.hasHandlers()
True
Использование преимуществ ленивого форматирования
Пришло время переключить передачу и рассмотреть подробнее, как сами сообщения соединяются с данными. Несмотря на то, что его вытеснили str.format() и f-строки, вы наверняка использовали форматирование в стиле процентов в Python, чтобы сделать что-то вроде этого:
>>> print("To iterate is %s, to recurse %s" % ("human", "divine"))
To iterate is human, to recurse divine
В результате у вас может возникнуть соблазн сделать то же самое в вызове logging:
>>> # Bad! Check out a more efficient alternative below.
>>> logging.warning("To iterate is %s, to recurse %s" % ("human", "divine"))
WARNING:root:To iterate is human, to recurse divine
Это использует всю строку формата и ее аргументы в качестве аргумента msg для logging.warning().
Вот рекомендуемая альтернатива, прямо из logging документации :
>>> # Better: formatting doesn't occur until it really needs to.
>>> logging.warning("To iterate is %s, to recurse %s", "human", "divine")
WARNING:root:To iterate is human, to recurse divine
Выглядит немного странно, верно? Это кажется нарушением правил форматирования строк в стиле процентов, но это более эффективный вызов функции, потому что строка форматирования будет отформатирована небрежно, а не небрежно. Вот что это значит.
Сигнатура метода Logger.warning() выглядит следующим образом:
def warning(self, msg, *args, **kwargs)
То же самое относится и к другим методам, например .debug(). При вызове warning("To iterate is %s, to recurse %s", "human", "divine") оба метода "human" и "divine" перехватываются как *args, а в области действия тела метода args равен ("human", "divine").
Контрастируйте это с первым вызовом выше:
logging.warning("To iterate is %s, to recurse %s" % ("human", "divine"))
В этой форме все, что находится в скобках, немедленно объединяется в "To iterate is human, to recurse divine" и передается как msg, а args представляет собой пустой кортеж.
Почему это важно? Повторные вызовы логирования могут несколько ухудшить производительность во время выполнения, но пакет logging делает все возможное, чтобы контролировать это и держать под контролем. Не объединяя строку формата со своими аргументами сразу, logging откладывает форматирование строки до тех пор, пока LogRecord не будет запрошен Handler.
Это происходит в LogRecord.getMessage(), поэтому только после того, как logging сочтет, что LogRecord действительно будет передан обработчику, он становится полностью объединенным.
Все это говорит о том, что пакет logging делает некоторые очень тонкие оптимизации производительности в нужных местах. Это может показаться мелочью, но если вы делаете один и тот же вызов logging.debug() миллион раз внутри цикла, и args - это вызовы функций, то ленивая природа того, как logging выполняет форматирование строк, может иметь значение.
Прежде чем выполнить слияние msg и args, экземпляр Logger проверит свой .isEnabledFor(), чтобы узнать, следует ли вообще выполнять это слияние.
Функции против методов
В самом низу logging/__init__.py находятся функции уровня модуля, которые рекламируются в публичном API logging. Вы уже видели методы Logger, такие как .debug(), .info() и .warning(). Функции верхнего уровня являются обертками вокруг соответствующих одноименных методов, но у них есть две важные особенности:
-
Они всегда вызывают соответствующий метод из корневого логгера,
root. -
Перед вызовом методов корневого логгера они вызывают
logging.basicConfig()без аргументов, если уrootнет обработчиков. Как вы видели ранее, именно этот вызов устанавливает обработчикsys.stdoutдля корневого регистратора.
Для примера, вот logging.error():
def error(msg, *args, **kwargs):
if len(root.handlers) == 0:
basicConfig()
root.error(msg, *args, **kwargs)
Вы найдете ту же схему для logging.debug(), logging.info() и других. Проследить цепочку команд очень интересно. В конце концов, вы окажетесь в одном и том же месте, где вызывается внутренняя команда Logger._log().
Вызовы debug(), info(), warning() и других функций, основанных на уровне, направляются сюда. _log() в основном имеет две цели:
-
Вызовите
self.makeRecord(): Создайте экземплярLogRecordизmsgи других аргументов, которые вы ему передадите. -
Вызов
self.handle(): Это определяет, что на самом деле будет сделано с записью. Куда она будет отправлена? Попадет ли она туда или будет отфильтрована?
Вот весь этот процесс в одной диаграмме:

Внутреннее устройство вызова журнала (Изображение: Real Python)
Вы также можете проследить стек вызовов с помощью pdb.
>>> import logging
>>> import pdb
>>> pdb.run('logging.warning("%s-%s", "uh", "oh")')
> <string>(1)<module>()
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1971)warning()
-> def warning(msg, *args, **kwargs):
(Pdb) s
> lib/python3.7/logging/__init__.py(1977)warning()
-> if len(root.handlers) == 0:
(Pdb) unt
> lib/python3.7/logging/__init__.py(1978)warning()
-> basicConfig()
(Pdb) unt
> lib/python3.7/logging/__init__.py(1979)warning()
-> root.warning(msg, *args, **kwargs)
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1385)warning()
-> def warning(self, msg, *args, **kwargs):
(Pdb) l
1380 logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
1381 """
1382 if self.isEnabledFor(INFO):
1383 self._log(INFO, msg, args, **kwargs)
1384
1385 -> def warning(self, msg, *args, **kwargs):
1386 """
1387 Log 'msg % args' with severity 'WARNING'.
1388
1389 To pass exception information, use the keyword argument exc_info with
1390 a true value, e.g.
(Pdb) s
> lib/python3.7/logging/__init__.py(1394)warning()
-> if self.isEnabledFor(WARNING):
(Pdb) unt
> lib/python3.7/logging/__init__.py(1395)warning()
-> self._log(WARNING, msg, args, **kwargs)
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1496)_log()
-> def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
(Pdb) s
> lib/python3.7/logging/__init__.py(1501)_log()
-> sinfo = None
(Pdb) unt 1517
> lib/python3.7/logging/__init__.py(1517)_log()
-> record = self.makeRecord(self.name, level, fn, lno, msg, args,
(Pdb) s
> lib/python3.7/logging/__init__.py(1518)_log()
-> exc_info, func, extra, sinfo)
(Pdb) s
--Call--
> lib/python3.7/logging/__init__.py(1481)makeRecord()
-> def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
(Pdb) p name
'root'
(Pdb) p level
30
(Pdb) p msg
'%s-%s'
(Pdb) p args
('uh', 'oh')
(Pdb) up
> lib/python3.7/logging/__init__.py(1518)_log()
-> exc_info, func, extra, sinfo)
(Pdb) unt
> lib/python3.7/logging/__init__.py(1519)_log()
-> self.handle(record)
(Pdb) n
WARNING:root:uh-oh
Что на самом деле делает getLogger()?
Также в этой части исходного кода скрывается верхний уровень getLogger(), который оборачивает Logger.manager.getLogger():
def getLogger(name=None):
if name:
return Logger.manager.getLogger(name)
else:
return root
Это точка входа для реализации конструкции однопользовательского регистратора:
-
Если вы указываете
name, то нижележащий.getLogger()выполняет поискdictв строкеname. Это сводится к поиску вloggerDictстрокеlogging.Manager. Это словарь всех зарегистрированных регистраторов, включая промежуточные экземплярыPlaceHolder, которые генерируются, когда вы ссылаетесь на регистратор далеко внизу иерархии, прежде чем обратиться к его родителям. -
В противном случае возвращается
root. Существует только одинrootэкземплярRootLogger, рассмотренный выше.
За этой особенностью скрывается трюк, который позволит вам заглянуть во все зарегистрированные регистраторы:
>>> import logging
>>> logging.Logger.manager.loggerDict
{}
>>> from pprint import pprint
>>> import asyncio
>>> pprint(logging.Logger.manager.loggerDict)
{'asyncio': <Logger asyncio (WARNING)>,
'concurrent': <logging.PlaceHolder object at 0x10d153710>,
'concurrent.futures': <Logger concurrent.futures (WARNING)>}
Подожди минутку. Что здесь происходит? Похоже, что что-то изменилось внутри пакета logging в результате импорта другой библиотеки, и именно это и произошло.
Прежде всего, напомним, что Logger.manager - это атрибут класса, где экземпляр Manager прикрепляется к классу Logger. Атрибут manager предназначен для отслеживания и управления всеми экземплярами синглтонов Logger. Они размещаются в .loggerDict.
Теперь, когда вы первоначально импортируете logging, этот словарь пуст. Но после импорта asyncio этот же словарь заполняется тремя логгерами. Это пример того, как один модуль устанавливает атрибуты другого модуля in-place. Конечно, внутри asyncio/log.py вы найдете следующее:
import logging
logger = logging.getLogger(__package__) # "asyncio"
Пара ключ-значение задается в Logger.getLogger(), чтобы manager мог контролировать все пространство имен логгеров. Это означает, что объект asyncio.log.logger регистрируется в словаре логгеров, принадлежащем пакету logging. Нечто подобное происходит и в пакете concurrent.futures, который импортируется asyncio.
Вы можете увидеть силу конструкции синглтонов в тесте на эквивалентность:
>>> obj1 = logging.getLogger("asyncio")
>>> obj2 = logging.Logger.manager.loggerDict["asyncio"]
>>> obj1 is obj2
True
Это сравнение иллюстрирует (упуская некоторые детали), что в конечном итоге делает getLogger().
Библиотека и журнал приложений: Что такое NullHandler?
Это приводит нас к последней сотне или около того строк в источнике logging/__init__.py, где дается определение NullHandler. Вот определение во всей его красе:
class NullHandler(Handler):
def handle(self, record):
pass
def emit(self, record):
pass
def createLock(self):
self.lock = None
В NullHandler речь идет о различиях между ведением журнала в библиотеке и в приложении. Давайте посмотрим, что это значит.
Библиотека library - это расширяемый, обобщающий пакет Python, предназначенный для установки и настройки другими пользователями. Он создается разработчиком с явной целью распространения среди пользователей. Примерами могут служить такие популярные проекты с открытым исходным кодом, как NumPy, dateutil и cryptography.
Приложение (или приложение, или программа) предназначено для более конкретных целей и гораздо меньшего числа пользователей (возможно, только одного пользователя). Это программа или набор программ, настроенных пользователем на выполнение ограниченного набора действий. Примером приложения может служить приложение Django, которое располагается за веб-страницей. Приложения обычно используют (import) библиотеки и инструменты, которые они содержат.
Когда дело доходит до протоколирования, есть разные лучшие практики в библиотеке и в приложении.
Вот тут-то и пригодится NullHandler. По сути, это класс-заглушка, который ничего не делает.
Если вы пишете библиотеку Python, вам действительно необходимо выполнить эту минимальную настройку в пакете __init__.py:
# Place this in your library's uppermost `__init__.py`
# Nothing else!
import logging
logging.getLogger(__name__).addHandler(NullHandler())
Это служит двум важнейшим целям.
Во-первых, библиотечный логгер, объявленный с помощью logger = logging.getLogger(__name__) (без какой-либо дополнительной настройки), по умолчанию будет вести журнал в sys.stderr, даже если конечный пользователь этого не хочет. Это можно описать как подход opt-out, когда конечный пользователь библиотеки должен сам отключить ведение журнала на своей консоли, если он этого не хочет.
Общепринятая мудрость гласит, что вместо этого нужно использовать подход opt-in: не выдавать никаких сообщений в журнал по умолчанию, и пусть конечные пользователи библиотеки сами определяют, хотят ли они в дальнейшем настраивать журналы библиотеки и добавлять к ним обработчики. Вот как более прямолинейно сформулировал эту философию автор пакета logging Винай Саджип (Vinay Sajip):
Сторонняя библиотека, использующая
logging, не должна по умолчанию выводить логи, которые могут быть не нужны разработчику/пользователю приложения, которое ее использует. (Источник)
Таким образом, пользователь библиотеки, а не ее разработчик, должен самостоятельно вызывать такие методы, как logger.addHandler() или logger.setLevel().
Вторая причина существования NullHandler более архаична. В Python 2.7 и более ранних версиях попытка записать в журнал LogRecord из логгера, у которого не установлен обработчик, вызовет предупреждение . Добавление класса no-op NullHandler позволит избежать этого.
Вот что конкретно происходит в строке logging.getLogger(__name__).addHandler(NullHandler()) сверху:
-
Python получает (создает) экземпляр
Loggerс тем же именем, что и ваш пакет. Если вы создаете пакетcalculusвнутри__init__.py, то__name__будет равен'calculus'. -
К этому логгеру будет прикреплен экземпляр
NullHandler. Это означает, что Python не будет по умолчанию использовать обработчикlastResort.
Помните, что любой логгер, созданный в любом из других .py модулей пакета, будет дочерним по отношению к этому логгеру в иерархии логгеров и что, поскольку этот обработчик также принадлежит им, им не нужно будет использовать обработчик lastResort и они не будут по умолчанию регистрировать стандартную ошибку (stderr).
В качестве примера, допустим, ваша библиотека имеет следующую структуру:
calculus/
│
├── __init__.py
└── integration.py
В integration.py, как разработчик библиотеки, вы можете делать следующее:
# calculus/integration.py
import logging
logger = logging.getLogger(__name__)
def func(x):
logger.warning("Look!")
# Do stuff
return None
Теперь появляется пользователь и устанавливает вашу библиотеку из PyPI через pip install calculus. Он использует from calculus.integration import func в коде приложения. Этот пользователь может свободно манипулировать и настраивать объект logger из библиотеки, как любой другой объект Python, по своему усмотрению.
Что делает ведение журнала с исключениями
Одна вещь, которой вы можете опасаться, - это опасность исключений, возникающих при вызове logging. Если у вас есть вызов logging.error(), предназначенный для предоставления более подробной отладочной информации, но сам этот вызов по какой-то причине вызывает исключение, это будет верхом иронии, не так ли?
Если пакет logging столкнется с исключением, связанным с протоколированием, то он выведет traceback, но не вызовет само исключение.
Вот пример, в котором рассматривается распространенная опечатка: передача двух аргументов в строку формата, которая ожидает только один аргумент. Важным отличием является то, что то, что вы видите ниже, - это не вызываемое исключение, а скорее распечатанная трассировка внутреннего исключения, которое само было подавлено:
>>> logging.critical("This %s has too many arguments", "msg", "other")
--- Logging error ---
Traceback (most recent call last):
File "lib/python3.7/logging/__init__.py", line 1034, in emit
msg = self.format(record)
File "lib/python3.7/logging/__init__.py", line 880, in format
return fmt.format(record)
File "lib/python3.7/logging/__init__.py", line 619, in format
record.message = record.getMessage()
File "lib/python3.7/logging/__init__.py", line 380, in getMessage
msg = msg % self.args
TypeError: not all arguments converted during string formatting
Call stack:
File "<stdin>", line 1, in <module>
Message: 'This %s has too many arguments'
Arguments: ('msg', 'other')
Это позволяет вашей программе изящно продолжить выполнение своего фактического программного потока. Это объясняется тем, что вы не хотите, чтобы не пойманное исключение возникло из самого вызова logging и остановило программу на полпути.
Откаты могут быть запутанными, но этот вариант информативен и относительно прост. Что позволяет подавлять исключения, связанные с logging, так это Handler.handleError(). Когда обработчик вызывает .emit(), то есть метод, в котором он пытается зарегистрировать запись, он возвращается к .handleError(), если что-то идет не так. Вот реализация .emit() для класса StreamHandler:
def emit(self, record):
try:
msg = self.format(record)
stream = self.stream
stream.write(msg + self.terminator)
self.flush()
except Exception:
self.handleError(record)
Любое исключение, связанное с форматированием и записью, перехватывается, а не поднимается, и handleError изящно записывает трассировку в sys.stderr.
Запись трассировок Python
Говоря об исключениях и их отслеживании, как насчет случаев, когда ваша программа сталкивается с ними, но должна зарегистрировать исключение и продолжить выполнение?
Давайте рассмотрим несколько способов сделать это.
Вот надуманный пример симулятора лотереи, использующего код, который специально не является питоновским. Вы разрабатываете онлайн-лотерею, в которой пользователи могут сделать ставку на свое счастливое число:
import random
class Lottery(object):
def __init__(self, n):
self.n = n
def make_tickets(self):
for i in range(self.n):
yield i
def draw(self):
pool = self.make_tickets()
random.shuffle(pool)
return next(pool)
За фронтенд-приложением сидит критический код, приведенный ниже. Вы хотите быть уверены, что отслеживаете все ошибки, вызванные сайтом, из-за которых пользователь может потерять свои деньги. Первый (неоптимальный) способ - использовать logging.error() и записывать в журнал str форму самого экземпляра исключения:
try:
lucky_number = int(input("Enter your ticket number: "))
drawn = Lottery(n=20).draw()
if lucky_number == drawn:
print("Winner chicken dinner!")
except Exception as e:
# NOTE: See below for a better way to do this.
logging.error("Could not draw ticket: %s", e)
Это позволит вам получить только фактическое сообщение об исключении, а не обратную трассировку. Вы проверяете журналы на сервере вашего сайта и находите это загадочное сообщение:
ERROR:root:Could not draw ticket: object of type 'generator' has no len()
Хм. Как разработчик приложения, вы столкнулись с серьезной проблемой, и в результате пользователь оказался обманутым. Но, возможно, само сообщение об исключении не слишком информативно. Было бы неплохо увидеть трассировку, которая привела к этому исключению?
Правильным решением будет использование logging.exception(), которое регистрирует сообщение с уровнем ERROR, а также выводит трассировку исключения. Замените две последние строки выше следующими:
except Exception:
logging.exception("Could not draw ticket")
Теперь вы лучше понимаете, что происходит:
ERROR:root:Could not draw ticket
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
File "<stdin>", line 9, in draw
File "lib/python3.7/random.py", line 275, in shuffle
for i in reversed(range(1, len(x))):
TypeError: object of type 'generator' has no len()
Использование exception() избавляет вас от необходимости самостоятельно ссылаться на исключение, поскольку logging подтягивает его вместе с sys.exc_info().
Таким образом, становится ясно, что проблема связана с random.shuffle(), которому необходимо знать длину объекта, который он тасует. Поскольку наш класс Lottery передает генератор в shuffle(), он задерживается и поднимается, прежде чем пул может быть перетасован, а тем более сгенерирован выигрышный билет.
В больших, полноценных приложениях logging.exception() будет еще полезнее, когда задействованы глубокие, многобиблиотечные трассировки, в которые невозможно попасть с помощью живого отладчика, как pdb.
Код для logging.Logger.exception(), а значит и для logging.exception(), состоит всего из одной строки:
def exception(self, msg, *args, exc_info=True, **kwargs):
self.error(msg, *args, exc_info=exc_info, **kwargs)
То есть logging.exception() просто вызывает logging.error() с помощью exc_info=True, который по умолчанию является False. Если вы хотите зарегистрировать обратную трассировку исключения, но на уровне, отличном от logging.ERROR, просто вызовите эту функцию или метод с помощью exc_info=True.
Помните, что exception() следует вызывать только в контексте обработчика исключений, внутри блока except:
for i in data:
try:
result = my_longwinded_nested_function(i)
except ValueError:
# We are in the context of exception handler now.
# If it's unclear exactly *why* we couldn't process
# `i`, then log the traceback and move on rather than
# ditching completely.
logger.exception("Could not process %s", i)
continue
Используйте этот паттерн редко, а не как средство подавления любого исключения. Он может быть наиболее полезен при отладке длинного стека вызовов функций, где в противном случае вы увидите двусмысленную, неясную и трудноотслеживаемую ошибку.
Заключение
Похлопайте себя по спине, ведь вы только что прошли через почти 2 000 строк плотного исходного кода. Теперь вы лучше подготовлены к работе с пакетом logging!
Помните, что этот учебник далеко не исчерпывает всех классов пакета logging. Есть еще больше механизмов, которые склеивают все вместе. Если вы хотите узнать больше, то можете обратиться к классам Formatter и отдельным модулям logging/config.py и logging/handlers.py.