Ваше руководство по исходному коду CPython
Оглавление
- Часть 1: Введение в CPython
- Часть 2: Процесс работы интерпретатора Python
- Часть 3: Компилятор CPython и цикл выполнения
- Часть 4: Объекты в CPython
- Часть 5: Стандартная библиотека CPython
- Исходный код CPython: Заключение
Есть ли в Python определенные части, которые просто кажутся волшебными? Например, почему словари намного быстрее, чем поиск элемента по списку. Как генератор запоминает состояние переменных каждый раз, когда выдает значение, и почему вам никогда не приходится выделять память, как в других языках? Оказывается, CPython, самая популярная среда выполнения Python, написана на удобочитаемом языке C и на коде Python. В этом руководстве вы познакомитесь с исходным кодом CPython.
Вы познакомитесь со всеми концепциями, лежащими во внутренней части CPython, с тем, как они работают, и наглядными объяснениями по ходу работы.
Вы узнаете, как:
- Читать исходный код и ориентироваться в нем
- Скомпилировать CPython из исходного кода
- Ориентируйтесь и постигайте внутреннюю работу таких понятий, как списки, словари и генераторы
- Запустите набор тестов
- Модифицируйте или обновляйте компоненты библиотеки CPython, чтобы добавить их в будущие версии
Да, это очень длинная статья. Если вы только что приготовили себе чашку свежего чая, кофе или вашего любимого напитка, к концу первой части он остынет.
Это руководство состоит из пяти частей. Уделите время каждой части и обязательно ознакомьтесь с демонстрациями и интерактивными компонентами. Вы можете испытывать чувство удовлетворения от того, что овладели основными понятиями Python, которые могут сделать вас лучшим программистом на Python.
Скачайте бесплатно: Ознакомьтесь с примером главы из CPython Internals: Ваше руководство по интерпретатору Python 3, в которой показано, как разблокировать внутреннюю ознакомьтесь с работой языка Python, скомпилируйте интерпретатор Python из исходного кода и примите участие в разработке CPython.
Часть 1: Введение в CPython
Когда вы вводите python в консоли или устанавливаете дистрибутив Python из python.org , вы запускаете CPython. CPython - это одна из многих сред выполнения Python, поддерживаемая и написанная разными командами разработчиков. Возможно, вы слышали о некоторых других средах выполнения, таких как PyPy, Cython и Jython.
Уникальность CPython в том, что он содержит как среду выполнения, так и общую языковую спецификацию, используемую во всех средах выполнения Python. CPython является “официальной” или эталонной реализацией Python.
Спецификация языка Python - это документ, содержащий описание языка Python. Например, в нем говорится, что assert является зарезервированным ключевым словом и что [] используется для индексации, нарезки и создания пустых списков.
Подумайте о том, что вы ожидаете увидеть в дистрибутиве Python на вашем компьютере:
- Когда вы вводите
pythonбез файла или модуля, появляется интерактивное приглашение. - Вы можете импортировать встроенные модули из стандартной библиотеки, такие как
json. - Вы можете устанавливать пакеты из Интернета с помощью
pip. - Вы можете протестировать свои приложения, используя встроенную библиотеку
unittest.
Все это является частью дистрибутива CPython. Это гораздо больше, чем просто компилятор.
Примечание: Эта статья написана на основе версии 3.8.0b4 исходного кода CPython.
Что содержится в исходном коде?
Исходный код CPython поставляется с целым рядом инструментов, библиотек и компонентов. Мы рассмотрим их в этой статье. Сначала мы сосредоточимся на компиляторе.
Чтобы загрузить копию исходного кода CPython, вы можете использовать git чтобы загрузить последнюю версию в рабочую копию локально:
$ git clone https://github.com/python/cpython $ cd cpython $ git checkout v3.8.0b4Примечание: Если у вас нет доступного Git, вы можете загрузить исходный код в виде ZIP-файла непосредственно с веб-сайта GitHub.
Внутри только что загруженного каталога
cpythonвы найдете следующие подкаталоги:cpython/ │ ├── Doc ← Source for the documentation ├── Grammar ← The computer-readable language definition ├── Include ← The C header files ├── Lib ← Standard library modules written in Python ├── Mac ← macOS support files ├── Misc ← Miscellaneous files ├── Modules ← Standard Library Modules written in C ├── Objects ← Core types and the object model ├── Parser ← The Python parser source code ├── PC ← Windows build support files ├── PCbuild ← Windows build support files for older Windows versions ├── Programs ← Source code for the python executable and other binaries ├── Python ← The CPython interpreter source code └── Tools ← Standalone tools useful for building or extending PythonДалее мы скомпилируем CPython из исходного кода. Для этого шага потребуется компилятор C и некоторые инструменты сборки, которые зависят от используемой операционной системы.
Компиляция CPython (macOS)
Скомпилировать CPython на macOS несложно. Сначала вам понадобится необходимый набор инструментов для компиляции C. Инструменты разработки командной строки - это приложение, которое вы можете обновить в macOS через App Store. Вам необходимо выполнить первоначальную установку на терминале.
Чтобы открыть терминал в macOS, перейдите на панель запуска, затем Другое затем выберите приложение Терминал. Вы захотите сохранить это приложение в своем Dock, поэтому щелкните правой кнопкой мыши по значку и выберите Сохранить в Dock.
Теперь в терминале установите компилятор C и инструментарий, выполнив следующее:
$ xcode-select --installПосле выполнения этой команды появится всплывающее окно с запросом на загрузку и установку набора инструментов, включая Git, Make и компилятор GNU C.
Вам также понадобится рабочая копия OpenSSL, чтобы использовать ее для получения пакетов с веб-сайта PyPi.org. Если в дальнейшем вы планируете использовать эту сборку для установки дополнительных пакетов, потребуется проверка SSL.
Самый простой способ установить OpenSSL на macOS - это использовать HomeBrew. Если у вас уже установлен HomeBrew, вы можете установить зависимости для CPython с помощью команды
brew install:$ brew install openssl xz zlibТеперь, когда у вас есть зависимости, вы можете запустить скрипт
configure, включив поддержку SSL, обнаружив местоположение, в которое был установлен HomeBrew, и включив отладочные перехватчики--with-pydebug:$ CPPFLAGS="-I$(brew --prefix zlib)/include" \ LDFLAGS="-L$(brew --prefix zlib)/lib" \ ./configure --with-openssl=$(brew --prefix openssl) --with-pydebugВ корневом каталоге репозитория будет создан
Makefile, который вы можете использовать для автоматизации процесса сборки. Шаг./configureнужно выполнить только один раз. Вы можете создать двоичный файл CPython, выполнив команду:$ make -j2 -sФлаг
-j2позволяетmakeвыполнять 2 задания одновременно. Если у вас 4 ядра, вы можете изменить это значение на 4. Флаг-sне позволяетMakefileвыводить на консоль каждую команду, которую он выполняет. Вы можете удалить это, но результат будет очень подробным.Во время сборки вы можете получить некоторые ошибки, и в сводке будет указано, что не все пакеты удалось собрать. Например,,
_dbm,_sqlite3,_uuid,nis,ossaudiodev,spwd, и_tkinterне удалось бы выполнить сборку с использованием этого набора инструкций. Это нормально, если вы не планируете разрабатывать на основе этих пакетов. Если да, то ознакомьтесь с веб-сайтом руководство для разработчиков для получения дополнительной информации.Сборка займет несколько минут и сгенерирует двоичный файл с именем
python.exe. Каждый раз, когда вы вносите изменения в исходный код, вам нужно будет повторно запускатьmakeс теми же флагами. Двоичный файлpython.exeявляется отладочным двоичным файлом CPython. Выполнитеpython.exe, чтобы увидеть рабочий REPL:$ ./python.exe Python 3.8.0b4 (tags/v3.8.0b4:d93605de72, Aug 30 2019, 10:00:03) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>Примечание: Да, все верно, сборка для macOS имеет расширение
.exe. Это , а не , потому что это двоичный файл Windows. Поскольку файловая система macOS не чувствительна к регистру, а при работе с двоичным файлом разработчики не хотели, чтобы пользователи случайно ссылались на каталогPython/, поэтому во избежание двусмысленности был добавлен.exe. Если позже вы запуститеmake installилиmake altinstall, файл будет переименован обратно вpython.Компиляция CPython (Linux)
Для Linux первым шагом является загрузка и установка
make,gcc,configure, иpkgconfig.Для Fedora Core, RHEL, CentOS или других систем на базе yum:
$ sudo yum install yum-utilsДля Debian, Ubuntu или других систем, основанных на
apt:$ sudo apt install build-essentialЗатем установите необходимые пакеты для Fedora Core, RHEL, CentOS или других систем на базе yum:
$ sudo yum-builddep python3Для Debian, Ubuntu или других систем, основанных на
apt:$ sudo apt install libssl-dev zlib1g-dev libncurses5-dev \ libncursesw5-dev libreadline-dev libsqlite3-dev libgdbm-dev \ libdb5.3-dev libbz2-dev libexpat1-dev liblzma-dev libffi-devТеперь, когда у вас есть зависимости, вы можете запустить скрипт
configure, включив отладочные перехватчики--with-pydebug:$ ./configure --with-pydebugПросмотрите выходные данные, чтобы убедиться, что поддержка OpenSSL отмечена как
YES. В противном случае инструкции по установке заголовков для OpenSSL можно найти в вашем дистрибутиве.Далее вы можете создать двоичный файл CPython, запустив сгенерированный
Makefile:$ make -j2 -sВо время сборки вы можете получить некоторые ошибки, и в сводке будет указано, что удалось собрать не все пакеты. Это нормально, если вы не планируете разрабатывать на основе этих пакетов. Если да, то ознакомьтесь с веб-сайтом руководство для разработчиков для получения дополнительной информации.
Сборка займет несколько минут и сгенерирует двоичный файл с именем
python. Это отладочный двоичный файл CPython. Выполните./python, чтобы увидеть рабочий REPL:$ ./python Python 3.8.0b4 (tags/v3.8.0b4:d93605de72, Aug 30 2019, 10:00:03) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>Компиляция CPython (Windows)
В папке PC находится файл проекта Visual Studio для создания и изучения CPython. Чтобы использовать его, на вашем компьютере должна быть установлена Visual Studio.
Новейшая версия Visual Studio, Visual Studio 2019, упрощает работу с Python и исходным кодом CPython, поэтому она рекомендуется для использования в этом руководстве. Если у вас уже установлена Visual Studio 2017, это также будет работать нормально.
После того, как вы загрузите программу установки, вам будет предложено выбрать компоненты, которые вы хотите установить. Минимум для этого руководства:
- Разработка на Python Рабочая нагрузка
- Дополнительные Собственные средства разработки на Python
- 64-разрядный Python 3 (3.7.2) (можно отменить, если у вас уже установлен Python 3.7)
Любые другие дополнительные функции можно отменить, если вы хотите более бережно относиться к дисковому пространству:
Затем программа установки загрузит и установит все необходимые компоненты. Установка может занять около часа, поэтому вы можете продолжить чтение и вернуться к этому разделу.
После завершения установки нажмите кнопку Запустить, чтобы запустить Visual Studio. Вам будет предложено войти в систему. Если у вас есть учетная запись Майкрософт, вы можете войти в систему или пропустить этот шаг.
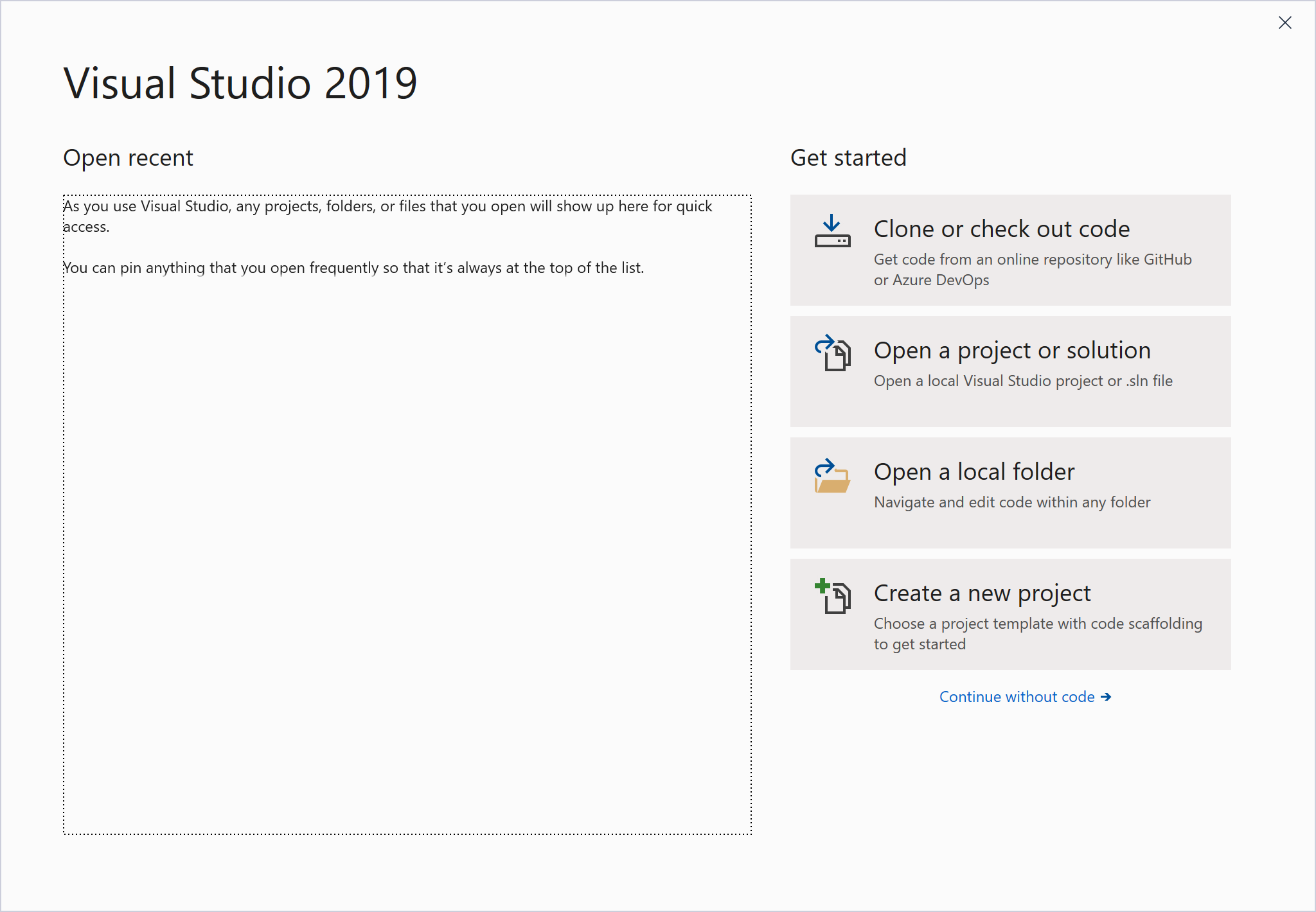
Как только Visual Studio запустится, вам будет предложено открыть проект. Самый простой способ начать работу с конфигурацией Git и клонированием CPython - это выбрать опцию Клонировать или проверить код:
В качестве URL-адреса проекта введите
https://github.com/python/cpythonдля клонирования: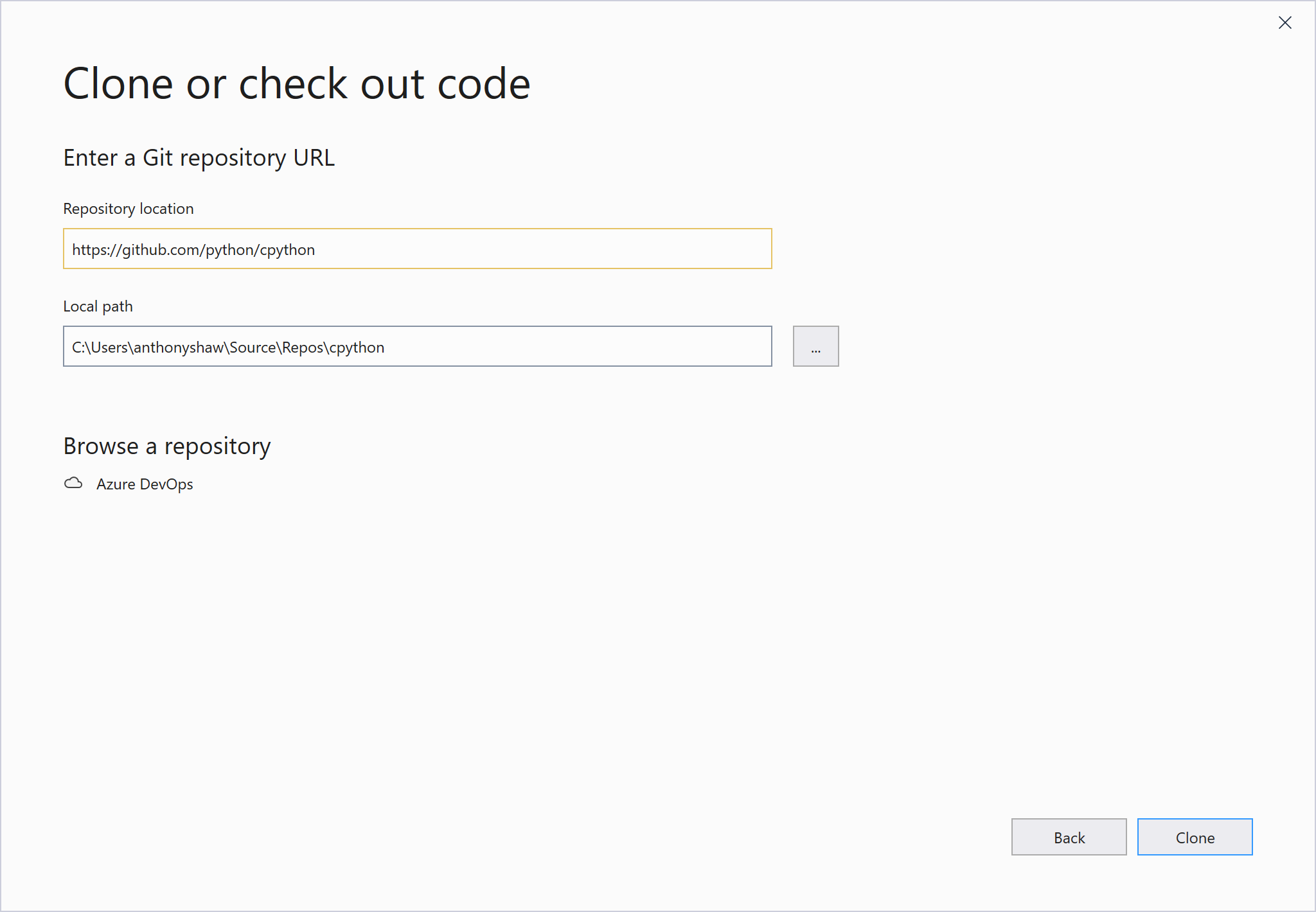
Затем Visual Studio загрузит копию CPython с GitHub, используя версию Git, поставляемую в комплекте с Visual Studio. Этот шаг также избавит вас от необходимости устанавливать Git в Windows. Загрузка может занять 10 минут.
Как только проект будет загружен, вам нужно указать на него в файле решения
pcbuild, нажав на Решения и проекты и выбравpcbuild.sln: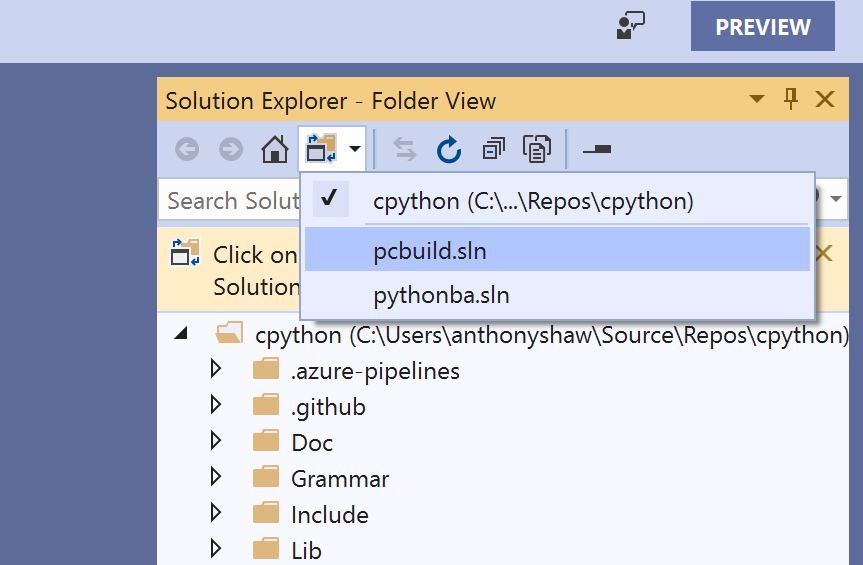
Когда решение будет загружено, вам будет предложено перенастроить проект внутри решения на версию установленного вами компилятора C/C++. Visual Studio также будет ориентирована на версию установленного вами пакета SDK для Windows.
Убедитесь, что вы изменили версию Windows SDK на последнюю установленную версию, а набор инструментов платформы - на последнюю версию. Если вы пропустили это окно, вы можете щелкнуть правой кнопкой мыши на решении в окне Решения и проекты и нажать Переназначить решение.
Как только это будет завершено, вам нужно будет загрузить несколько исходных файлов, чтобы иметь возможность собрать весь пакет CPython целиком. В папке
PCBuildнаходится файл.bat, который автоматизирует это для вас. Откройте приглашение командной строки в загруженномPCBuildи запуститеget_externals.bat:> get_externals.bat Using py -3.7 (found 3.7 with py.exe) Fetching external libraries... Fetching bzip2-1.0.6... Fetching sqlite-3.21.0.0... Fetching xz-5.2.2... Fetching zlib-1.2.11... Fetching external binaries... Fetching openssl-bin-1.1.0j... Fetching tcltk-8.6.9.0... Finished.Затем, вернувшись в Visual Studio, создайте CPython, нажав Ctrl+Shift+B, или выбрав Создать решение в верхнем меню. Если вы получаете какие-либо сообщения об отсутствии пакета SDK для Windows, убедитесь, что вы правильно настроили параметры таргетинга в окне Решение для ретаргетинга. Вы также должны увидеть Комплекты Windows в вашем меню "Пуск" и Комплект для разработки программного обеспечения Windows внутри этого меню.
В первый раз этап сборки может занять 10 минут или более. После завершения сборки вы можете увидеть несколько предупреждений, которые можно проигнорировать, и, в конечном итоге, завершить.
Чтобы запустить отладочную версию CPython, нажмите F5, и CPython запустится в режиме отладки прямо в REPL:
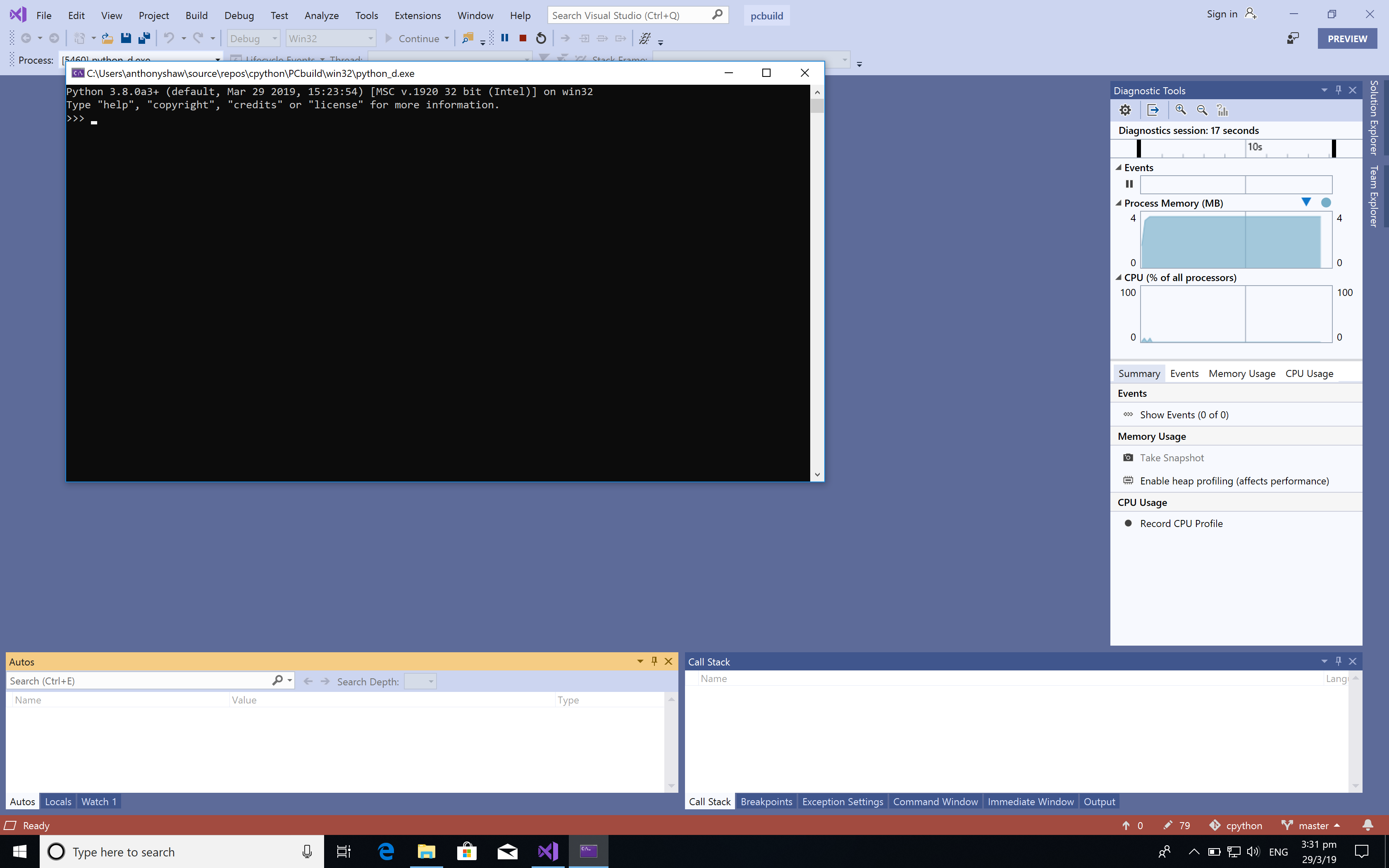
Как только это будет завершено, вы можете запустить сборку для выпуска, изменив конфигурацию сборки с Отладка на Выпуск в верхней строке меню и снова запустите сборку решения. Теперь у вас есть как отладочная, так и выпускная версии двоичного файла CPython внутри
PCBuild\win32\.Вы можете настроить Visual Studio таким образом, чтобы она могла открывать REPL либо с выпуском, либо с отладочной сборкой, выбрав
Tools->Python->Python Environmentsв верхнем меню: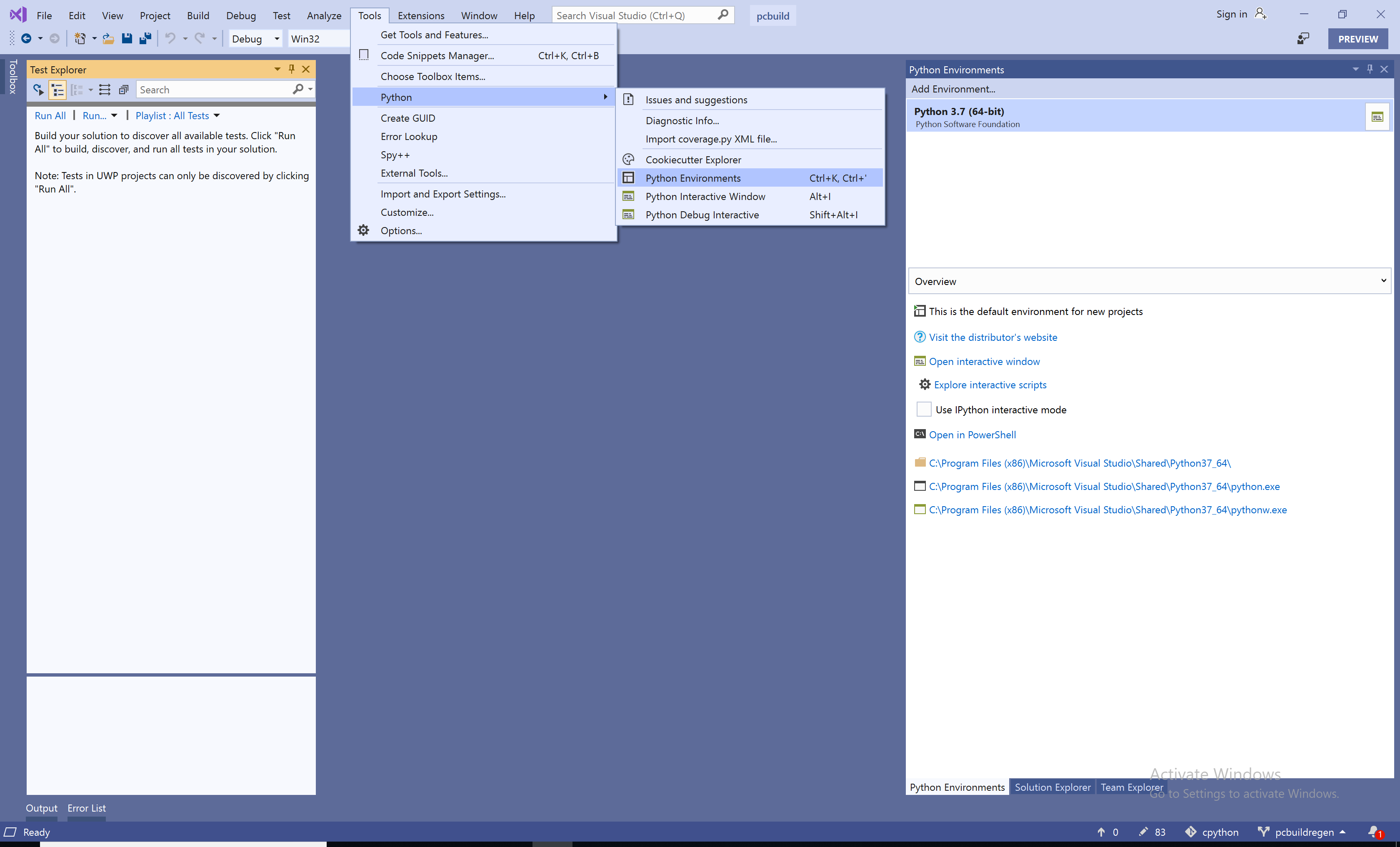
Затем нажмите Добавить среду, а затем выберите двоичный файл для отладки или выпуска. Двоичный файл отладки будет заканчиваться на
_d.exe, например,python_d.exeиpythonw_d.exe. Скорее всего, вы захотите использовать двоичный файл debug, поскольку он поставляется с поддержкой отладки в Visual Studio и будет полезен для этого руководства.В окне Добавления среды выберите файл
python_d.exeв качестве интерпретатора внутриPCBuild/win32, а файлpythonw_d.exe- в качестве оконного интерпретатора: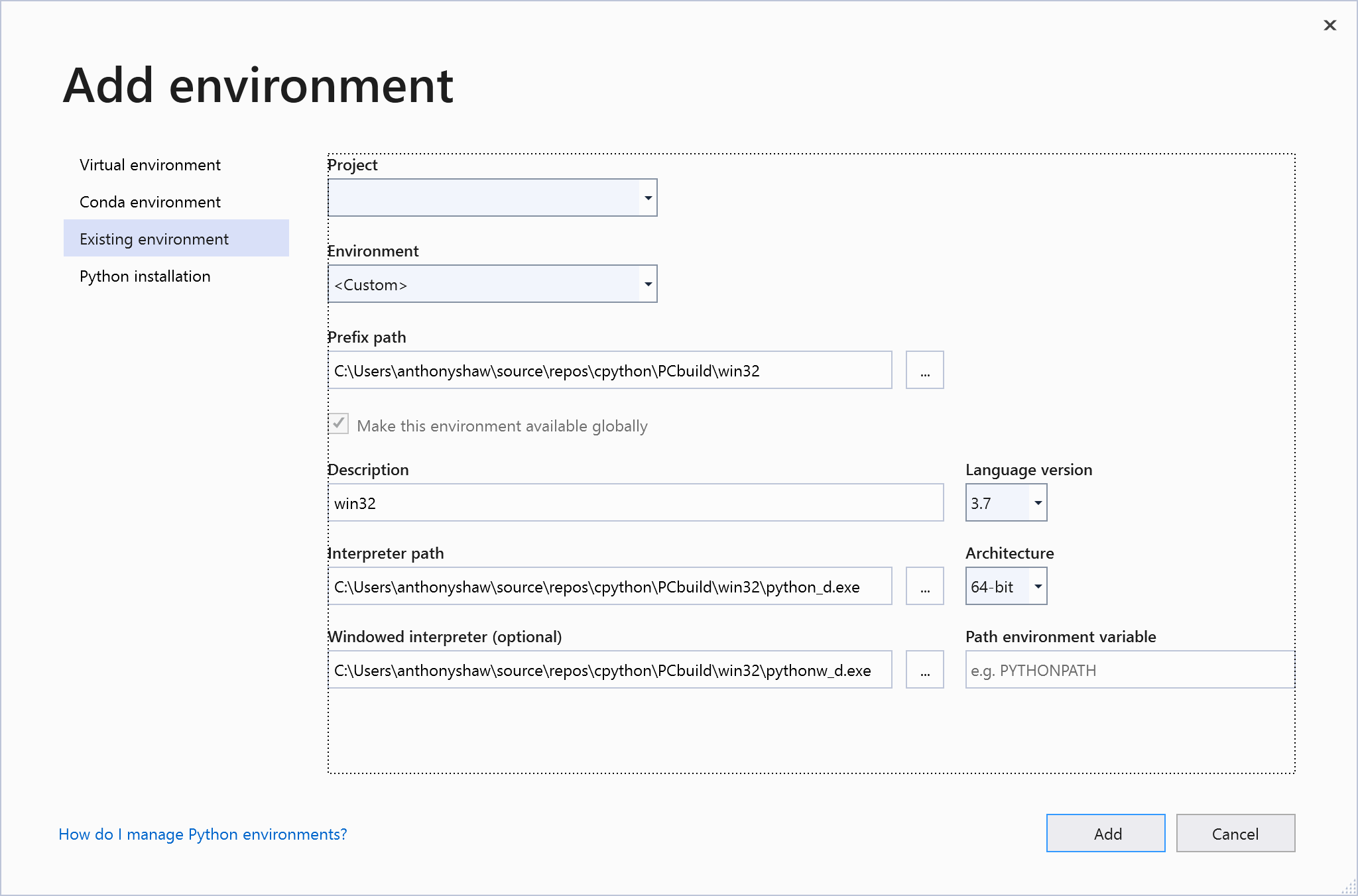
Теперь вы можете начать сеанс REPL, нажав Открыть интерактивное окно в окне Среды Python, и вы увидите REPL для скомпилированной версии Python:
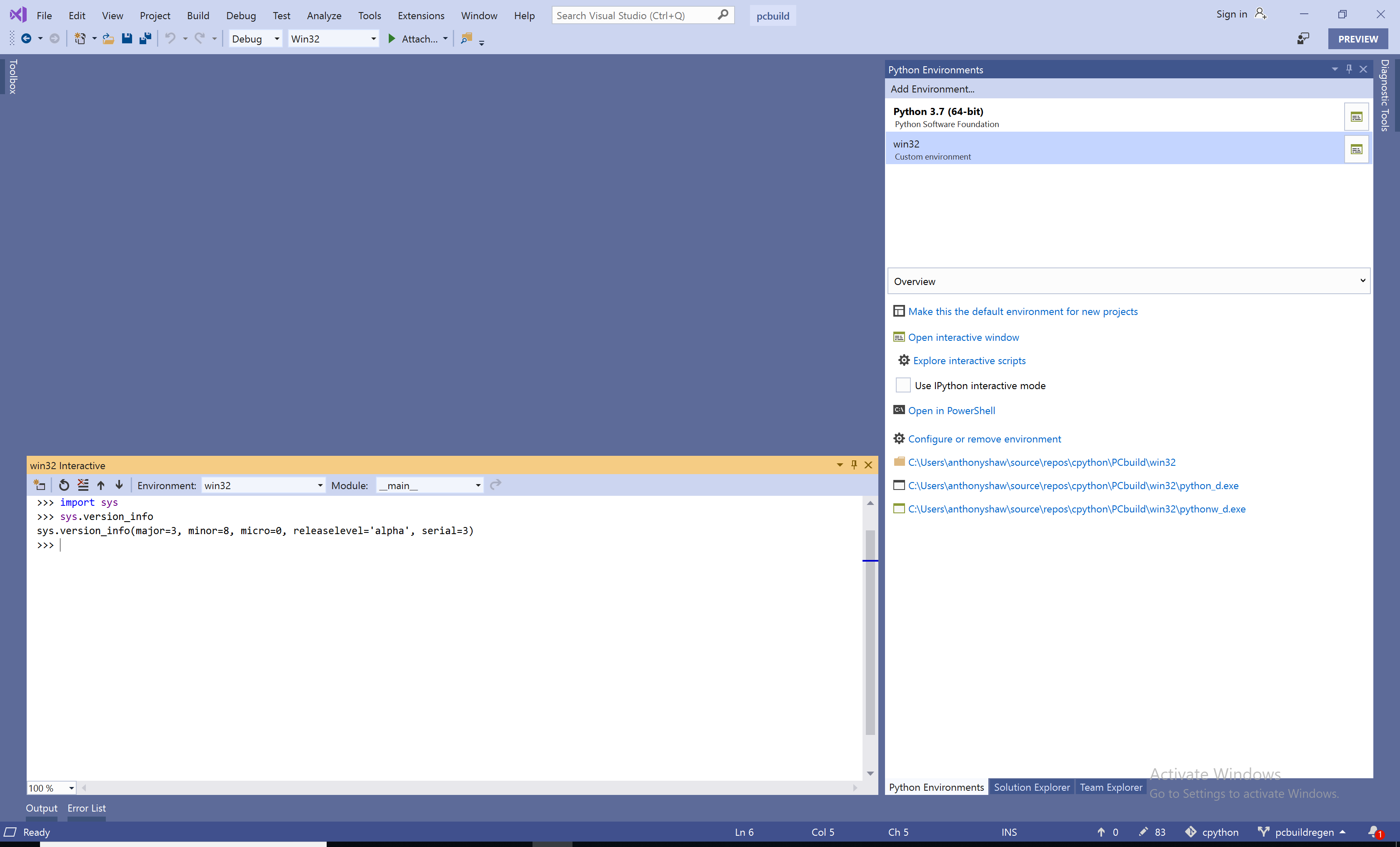
В ходе этого урока будут показаны сеансы REPL с примерами команд. Я рекомендую вам использовать двоичный файл Debug для запуска этих сеансов REPL на случай, если вы захотите установить какие-либо точки останова в коде.
И, наконец, чтобы упростить навигацию по коду, в режиме просмотра решения нажмите на кнопку переключения рядом со значком "Главная", чтобы переключиться в режим просмотра папок:
Теперь, когда версия CPython скомпилирована и готова к работе, давайте выясним, как работает компилятор CPython.
Что делает компилятор?
Цель компилятора - преобразовать один язык в другой. Представьте себе компилятор как переводчик. Вы могли бы нанять переводчика, который слушал бы вашу речь по-английски, а затем говорил бы по-японски:

Некоторые компиляторы компилируются в низкоуровневый машинный код, который может быть выполнен непосредственно в системе. Другие компиляторы компилируются в промежуточный язык, который будет выполняться виртуальной машиной.
Одним из важных решений, которое необходимо принять при выборе компилятора, являются требования к переносимости системы. Java и .NET CLR будут компилироваться в промежуточный язык. таким образом, скомпилированный код может быть переносим на несколько системных архитектур. C, Go, C++ и Pascal будут скомпилированы в низкоуровневый исполняемый файл, который будет работать только в системах, аналогичных той, в которой он был скомпилирован.
Поскольку приложения на Python обычно распространяются в виде исходного кода, роль среды выполнения на Python заключается в преобразовании исходного кода на Python и его выполнении за один шаг. Внутренняя среда выполнения CPython выполняет компиляцию вашего кода. Распространенным заблуждением является то, что Python - это интерпретируемый язык. На самом деле он компилируется.
Код на Python не компилируется в машинный код. Он компилируется в специальный низкоуровневый промежуточный язык, называемый байт-код, который понимает только CPython. Этот код хранится в
.pycфайлах в скрытом каталоге и кэшируется для выполнения. Если вы дважды запустите одно и то же приложение на Python без изменения исходного кода, во второй раз это всегда будет намного быстрее. Это происходит потому, что он загружает скомпилированный байт-код и выполняет его напрямую.Почему CPython написан на C, а не на Python?
C в CPython является ссылкой на язык программирования C, подразумевая, что этот дистрибутив Python написан на языке C.
Это утверждение во многом верно: компилятор в CPython написан на чистом C. Однако многие модули стандартной библиотеки написаны на чистом Python или на комбинации C и Python.
Так почему же CPython написан на C, а не на Python?
Ответ находится в разделе "Как работают компиляторы". Существует два типа компиляторов:
- Автономные компиляторы это компиляторы, написанные на языке, который они компилируют, например, компилятор Go.
- Компиляторы с исходным кодом это компиляторы, написанные на другом языке, у которых уже есть компилятор.
Если вы пишете новый язык программирования с нуля, вам понадобится исполняемое приложение для компиляции вашего компилятора! Для выполнения чего-либо требуется компилятор, поэтому, когда разрабатываются новые языки, они часто сначала пишутся на более старом, устоявшемся языке.
Хорошим примером может служить язык программирования Go. Первый компилятор Go был написан на C, затем, как только появилась возможность скомпилировать Go, компилятор был переписан на Go.
CPython сохранил наследие языка Си: многие модули стандартной библиотеки, такие как модуль
sslили модульsockets, написаны на языке Си для доступа к низкоуровневым API операционной системы. API-интерфейсы в ядрах Windows и Linux для создания сетевых сокетов, работы с файловой системой или взаимодействия с дисплеем написаны на C. Было разумно, чтобы уровень расширяемости Python был сосредоточен на языке C. Далее в этой статье мы рассмотрим стандартную библиотеку Python и модули C.Существует компилятор Python, написанный на Python, который называется PyPy. Логотипом PyPy является Уроборос, который символизирует автономный характер компилятора.
Другим примером кросс-компилятора для Python является Jython. Jython написан на Java и компилируется из исходного кода Python в байт-код Java. Точно так же, как CPython упрощает импорт библиотек C и их использование из Python, Jython упрощает импорт модулей и классов Java и ссылки на них.
Спецификация языка Python
В исходном коде CPython содержится определение языка Python. Это справочная спецификация, используемая всеми интерпретаторами Python.
Спецификация представлена как в удобочитаемом, так и в машиночитаемом формате. В документации содержится подробное объяснение языка Python, того, что разрешено, и как должен вести себя каждый оператор.
Документация
Внутри
Doc/referenceкаталога расположены reStructuredText пояснения к каждой из функций языка Python. Это официальное справочное руководство по Python на docs.python.org.Внутри каталога находятся файлы, необходимые для понимания всего языка, структуры и ключевых слов:
cpython/Doc/reference | ├── compound_stmts.rst ├── datamodel.rst ├── executionmodel.rst ├── expressions.rst ├── grammar.rst ├── import.rst ├── index.rst ├── introduction.rst ├── lexical_analysis.rst ├── simple_stmts.rst └── toplevel_components.rstв
compound_stmts.rstдокументация на составные операторы, вы можете увидеть простой пример определениеwithзаявление.Оператор
withв Python может использоваться несколькими способами, простейшим из которых является создание экземпляра контекстного менеджера и вложенного блока кода:with x(): ...Вы можете присвоить результат переменной, используя ключевое слово
as:with x() as y: ...Вы также можете объединить контекстные менеджеры в цепочку через запятую:
with x() as y, z() as jk: ...Далее мы рассмотрим машиночитаемую документацию по языку Python.
Грамматика
Документация содержит удобочитаемую спецификацию языка, а машиночитаемая спецификация размещена в одном файле,
Grammar/Grammar.Файл грамматики записан в контекстной нотации, которая называется Форма Бэкуса-Наура (BNF). BNF не является специфичным для Python и часто используется в качестве обозначения грамматик во многих других языках.
Концепция грамматической структуры в языке программирования вдохновлена Работой Ноама Хомского о синтаксических структурах, выполненной в 1950-х годах!
В файле грамматики Python используется спецификация расширенного языка BNF (EBNF) с синтаксисом регулярных выражений. Итак, в файле грамматики вы можете использовать:
*для повторения+для повторения хотя бы один раз[]для дополнительных деталей|в поисках альтернативных вариантов()для группировкиЕсли вы выполните поиск по выражению
withв файле grammar, примерно в строке 80 вы увидите определения для выраженияwith:with_stmt: 'with' with_item (',' with_item)* ':' suite with_item: test ['as' expr]Все, что заключено в кавычки, является строковым литералом, именно так определяются ключевые слова. Таким образом,
with_stmtуказывается как:
- Начиная со слова
with- , за которым следует
with_item, то естьtestи (необязательно) словоasи выражение- После одного или нескольких пунктов, каждый из которых разделен запятой
- , заканчивающийся символом
:- За которым следует
suiteВ этих двух строках есть ссылки на некоторые другие определения:
suiteотносится к блоку кода с одним или несколькими операторамиtestотносится к простому оператору, который вычисляетсяexprотносится к простому выражениюЕсли вы хотите изучить их более подробно, вся грамматика Python определена в этом единственном файле.
Если вы хотите увидеть свежий пример использования грамматики, то в PEP 572 оператор двоеточие равно был добавлен в файл грамматики в этом Git-коммите..
Используя
pgenСам файл грамматики никогда не используется компилятором Python. Вместо этого используется таблица синтаксического анализа, созданная с помощью инструмента под названием
pgen.pgenсчитывает файл грамматики и преобразует его в таблицу синтаксического анализа. Если вы вносите изменения в файл grammar, вы должны заново создать таблицу синтаксического анализа и перекомпилировать Python.Примечание: Приложение
pgenбыло переписано на Python 3.8 с C на чистый Python.Чтобы увидеть
pgenв действии, давайте изменим часть грамматики Python. По строке 51 вы увидите определениеpassзаявление:pass_stmt: 'pass'Измените эту строку, чтобы принять ключевое слово
'pass'или'proceed'в качестве ключевых слов:pass_stmt: 'pass' | 'proceed'Теперь вам нужно перестроить файлы грамматики. В macOS и Linux запустите
make regen-grammar, чтобы запуститьpgenповерх измененного файла грамматики. В Windows запуститеbuild.bat --regenиз каталогаPCBuild.Вы должны увидеть результат, похожий на этот, показывающий, что были созданы новые файлы
Include/graminit.hиPython/graminit.c:# Regenerate Doc/library/token-list.inc from Grammar/Tokens # using Tools/scripts/generate_token.py ... python3 ./Tools/scripts/update_file.py ./Include/graminit.h ./Include/graminit.h.new python3 ./Tools/scripts/update_file.py ./Python/graminit.c ./Python/graminit.c.newПримечание:
pgenработает путем преобразования инструкций EBNF в Недетерминированный конечный автомат (NFA), который затем превращается в Детерминированный конечный автомат (DFA). DFA используются синтаксическим анализатором в качестве таблиц синтаксического анализа особым образом, уникальным для CPython. Этот метод был разработан в Стэнфордском университете и разработан в 1980-х годах, незадолго до появления Python.При использовании обновленных таблиц синтаксического анализа вам необходимо перекомпилировать CPython, чтобы увидеть новый синтаксис. Используйте те же шаги компиляции, которые вы использовали ранее для своей операционной системы.
Если код скомпилирован успешно, вы можете запустить свой новый двоичный файл CPython и запустить REPL.
В REPL теперь вы можете попробовать определить функцию и вместо инструкции
passиспользовать альтернативное ключевое словоproceed, которое вы скомпилировали в грамматику Python:Python 3.8.0b4 (tags/v3.8.0b4:d93605de72, Aug 30 2019, 10:00:03) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> def example(): ... proceed ... >>> example()Молодец! Вы изменили синтаксис CPython и скомпилировали свою собственную версию CPython. Отправляйте ее!
Далее мы рассмотрим лексемы и их связь с грамматикой.
Токены
Рядом с файлом грамматики в папке
Grammarнаходится файлTokens, который содержит каждый из уникальных типов, найденных в качестве конечного узла в дереве синтаксического анализа . Позже мы подробно рассмотрим деревья синтаксического анализа. У каждого токена также есть имя и сгенерированный уникальный идентификатор. Имена используются для упрощения использования в токенизаторе.Примечание: Файл
Tokens- это новая функция в Python 3.8.Например, левая круглая скобка называется
LPAR, а точка с запятой -SEMI. Вы увидите эти символы позже в статье:LPAR '(' RPAR ')' LSQB '[' RSQB ']' COLON ':' COMMA ',' SEMI ';'Как и в случае с файлом
Grammar, при изменении файлаTokensнеобходимо снова запуститьpgen.Чтобы увидеть токены в действии, вы можете использовать модуль
tokenizeв CPython. Создайте простой скрипт на Python с именемtest_tokens.py:# Hello world! def my_function(): proceedВ оставшейся части этого руководства
./python.exeбудет использоваться скомпилированная версия CPython. Однако фактическая команда будет зависеть от вашей системы.Для Windows:
> python.exeДля Linux:
> ./pythonДля macOS:
> ./python.exeЗатем передайте этот файл через модуль, встроенный в стандартную библиотеку, который называется
tokenize. Вы увидите список токенов по строкам и символам. Используйте флаг-eдля вывода точного имени токена:$ ./python.exe -m tokenize -e test_tokens.py 0,0-0,0: ENCODING 'utf-8' 1,0-1,14: COMMENT '# Hello world!' 1,14-1,15: NL '\n' 2,0-2,3: NAME 'def' 2,4-2,15: NAME 'my_function' 2,15-2,16: LPAR '(' 2,16-2,17: RPAR ')' 2,17-2,18: COLON ':' 2,18-2,19: NEWLINE '\n' 3,0-3,3: INDENT ' ' 3,3-3,7: NAME 'proceed' 3,7-3,8: NEWLINE '\n' 4,0-4,0: DEDENT '' 4,0-4,0: ENDMARKER ''В выходных данных первый столбец - это диапазон координат строки/столбца, второй столбец - это имя токена, а последний столбец - это значение токена.
В выходных данных модуль
tokenizeсодержит некоторые токены, которых не было в файле. МаркерENCODINGдляutf-8и пустая строка в конце, указывающаяDEDENTдля закрытия объявления функции иENDMARKERдля завершения работы с файлом.Рекомендуется, чтобы в конце исходных файлов Python была пустая строка. Если вы ее пропустите, CPython добавит ее за вас с небольшим снижением производительности.
Модуль
tokenizeнаписан на чистом языке Python и расположен вLib/tokenize.pyв исходном коде CPython.Важно: В исходном коде CPython есть два токенизатора: один, написанный на Python, продемонстрированный здесь, и другой, написанный на C. Токенизатор, написанный на Python, предназначен как утилита, а токенизатор, написанный на C, используется компилятором Python. Они имеют идентичный вывод и поведение. Версия, написанная на C, предназначена для повышения производительности, а модуль на Python предназначен для отладки.
Чтобы увидеть подробное отображение токенизатора C, вы можете запустить Python с флагом
-d. Используяtest_tokens.pyскрипт, который вы создали ранее, запустите его следующим образом:$ ./python.exe -d test_tokens.py Token NAME/'def' ... It's a keyword DFA 'file_input', state 0: Push 'stmt' DFA 'stmt', state 0: Push 'compound_stmt' DFA 'compound_stmt', state 0: Push 'funcdef' DFA 'funcdef', state 0: Shift. Token NAME/'my_function' ... It's a token we know DFA 'funcdef', state 1: Shift. Token LPAR/'(' ... It's a token we know DFA 'funcdef', state 2: Push 'parameters' DFA 'parameters', state 0: Shift. Token RPAR/')' ... It's a token we know DFA 'parameters', state 1: Shift. DFA 'parameters', state 2: Direct pop. Token COLON/':' ... It's a token we know DFA 'funcdef', state 3: Shift. Token NEWLINE/'' ... It's a token we know DFA 'funcdef', state 5: [switch func_body_suite to suite] Push 'suite' DFA 'suite', state 0: Shift. Token INDENT/'' ... It's a token we know DFA 'suite', state 1: Shift. Token NAME/'proceed' ... It's a keyword DFA 'suite', state 3: Push 'stmt' ... ACCEPT.В выходных данных вы можете видеть, что в качестве ключевого слова выделено
proceed. В следующей главе мы увидим, как выполнение двоичного кода Python попадает в токенизатор и что происходит после этого для выполнения вашего кода.Теперь, когда у вас есть общее представление о грамматике Python и взаимосвязи между токенами и операторами, есть способ преобразовать выходные данные
pgenв интерактивный график.Вот скриншот грамматики Python 3.8a2:
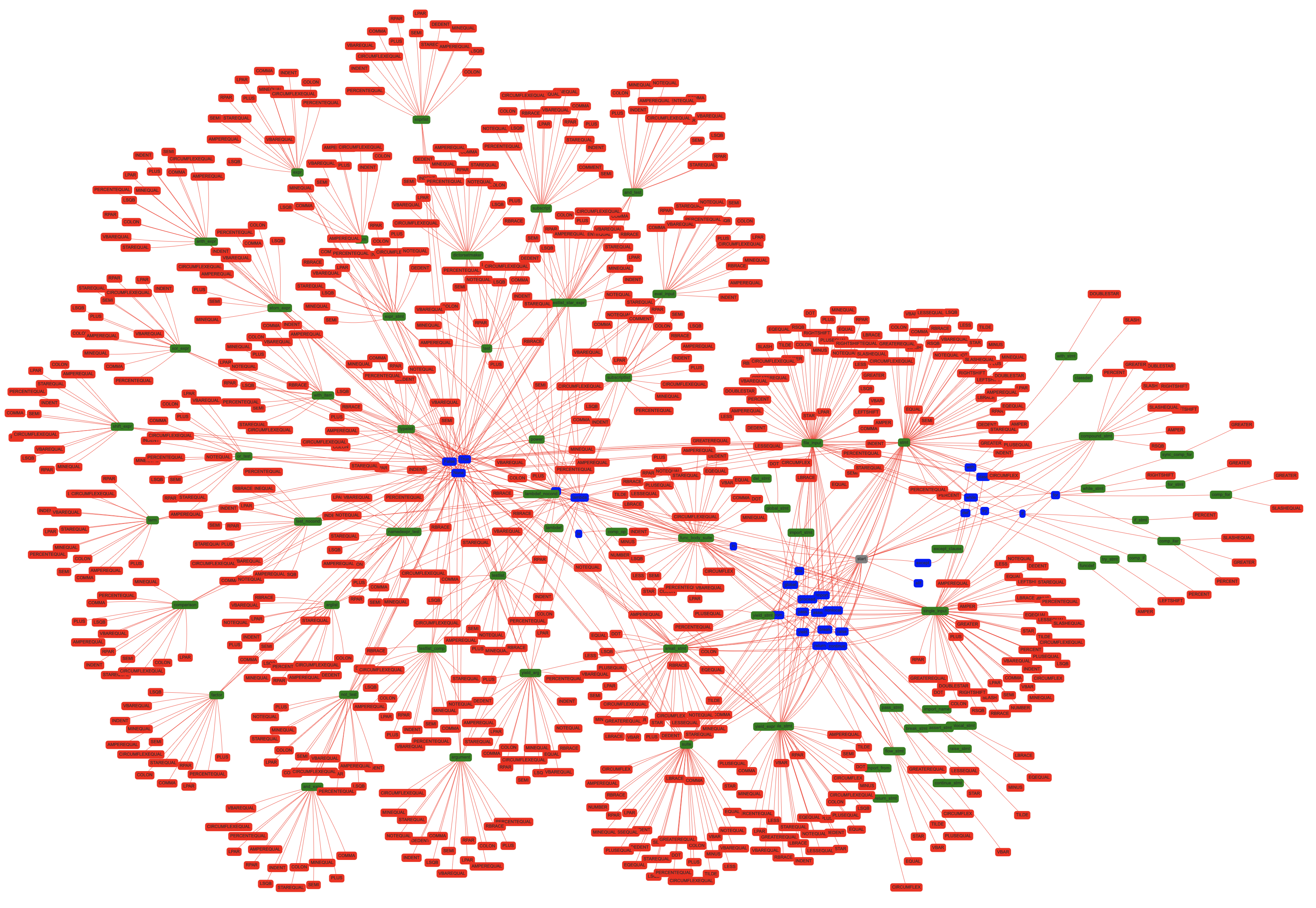
Пакет Python, используемый для создания этого графика,
instaviz, будет рассмотрен в следующей главе.Управление памятью в CPython
В этой статье вы увидите ссылки на объект
PyArena. Arena - это одна из структур управления памятью в CPython. Код находится в пределахPython/pyarena.cи содержит оболочку для функций выделения и освобождения памяти в C.В традиционно написанной программе на C разработчик должен выделить память для структур данных перед записью в эти данные. Это выделение помечает память как принадлежащую процессу с операционной системой.
Разработчик также может освободить выделенную память, когда она больше не используется, и вернуть ее в таблицу блоков свободной памяти операционной системы. Если процесс выделяет память для переменной, скажем, внутри функции или цикла, то по завершении выполнения этой функции память автоматически не возвращается операционной системе в C. Таким образом, если она не была явно освобождена в коде C, это приводит к утечке памяти. Процесс будет продолжать занимать больше памяти при каждом запуске этой функции, пока, в конце концов, в системе не закончится память и не произойдет сбой!
Python снимает эту ответственность с программиста и использует два алгоритма: счетчик ссылок и сборщик мусора.
Всякий раз, когда создается экземпляр интерпретатора, создается
PyArenaи к нему присоединяется одно из полей в интерпретаторе. В течение жизненного цикла интерпретатора CPython может быть выделено множество областей. Они связаны связанным списком. В arena хранится список указателей на объекты Python в видеPyListObject. Всякий раз, когда создается новый объект Python, указатель на него добавляется с помощьюPyArena_AddPyObject(). Этот вызов функции сохраняет указатель в списке арены,a_objects.Несмотря на то, что в Python нет указателей, существует несколько интересных методов для имитации поведения указателей.
PyArenaвыполняет вторую функцию, которая заключается в выделении списка необработанных блоков памяти и обращении к нему. Например, дляPyListпотребуется дополнительная память, если вы добавите тысячи дополнительных значений. C-код объектаPyListне выделяет память напрямую. Объект получает необработанные блоки памяти изPyArena, вызываяPyArena_Malloc()изPyObjectс требуемым объемом памяти. Эта задача выполняется с помощью другой абстракции вObjects/obmalloc.c. В модуле выделения объектов память может быть выделена, освобождена и перераспределена для объекта Python.Связанный список выделенных блоков хранится внутри arena, так что при остановке интерпретатора все блоки управляемой памяти могут быть освобождены за один раз с помощью
PyArena_Free().Возьмем, к примеру,
PyListObject. Если бы вы должны были.append()если объект находится в конце списка Python, вам не нужно заранее перераспределять память, используемую в существующем списке. Вызывается метод.append()list_resize(), который управляет распределением памяти для списков. Каждый объект list содержит список выделенного объема памяти. Если добавляемый элемент помещается в имеющуюся свободную память, он просто добавляется. Если для списка требуется больше места в памяти, он расширяется. Списки расширяются по длине по мере 0, 4, 8, 16, 25, 35, 46, 58, 72, 88.
PyMem_Realloc()вызывается для расширения памяти, выделенной в списке.PyMem_Realloc()является API-оболочкой дляpymalloc_realloc().В Python также есть специальная оболочка для вызова C
malloc(), которая устанавливает максимальный размер выделяемой памяти, чтобы предотвратить ошибки переполнения буфера (см.PyMem_RawMalloc()).В итоге:
- Выделение необработанных блоков памяти осуществляется с помощью
PyMem_RawAlloc().- Указатели на объекты Python хранятся в
PyArena.PyArenaтакже хранится связанный список выделенных блоков памяти.Более подробная информация об API приведена в документации по CPython .
Подсчет ссылок
Чтобы создать переменную в Python, вы должны присвоить значение переменной с уникальным именем:
my_variable = 180392Всякий раз, когда переменной присваивается значение в Python, имя переменной проверяется в области локальных и глобальных переменных, чтобы убедиться, что она уже существует.
Поскольку
my_variableеще не находится в словареlocals()илиglobals(), создается этот новый объект, и значение присваивается как числовая константа180392.Теперь имеется одна ссылка на
my_variable, поэтому счетчик ссылок дляmy_variableувеличивается на 1.Вы увидите вызовы функций
Py_INCREF()иPy_DECREF()по всему исходному коду C для CPython. Эти функции увеличивают и уменьшают количество ссылок на этот объект.Количество ссылок на объект уменьшается, когда переменная выходит за пределы области, в которой она была объявлена. Область видимости в Python может относиться к функции или методу, пониманию или лямбда-функции. Это некоторые из наиболее буквальных областей, но есть много других неявных областей, таких как передача переменных в вызов функции.
Обработка увеличивающихся и уменьшающихся ссылок на основе языка встроена в компилятор CPython и основной цикл выполнения,
ceval.c, который мы подробно рассмотрим позже в этой статье.Всякий раз, когда вызывается
Py_DECREF()и счетчик становится равным 0, вызывается функцияPyObject_Free(). Для этого объектаPyArena_Free()вызывается для всей выделенной памяти.Сборка мусора
Как часто у вас собирают мусор? Еженедельно или раз в две недели?
Когда вы заканчиваете с чем-то, вы выбрасываете это в мусорное ведро. Но этот мусор не будет собран сразу. Вам нужно подождать, пока приедут мусоровозы и заберут его.
CPython работает по тому же принципу, используя алгоритм сбора мусора. Сборщик мусора CPython включен по умолчанию, работает в фоновом режиме и освобождает память, которая использовалась для объектов, которые больше не используются.
Поскольку алгоритм сбора мусора намного сложнее, чем счетчик ссылок, это происходит не всегда, иначе это потребляло бы огромное количество ресурсов процессора. Это происходит периодически, после определенного количества операций.
Стандартная библиотека CPython поставляется с модулем Python для взаимодействия с arena и сборщиком мусора, модулем
gc. Вот как использовать модульgcв режиме отладки:>>> import gc >>> gc.set_debug(gc.DEBUG_STATS)При этом статистика будет выводиться всякий раз, когда запускается сборщик мусора.
Вы можете получить пороговое значение, после которого запускается сборщик мусора, вызвав
get_threshold():>>> gc.get_threshold() (700, 10, 10)Вы также можете получить текущие пороговые значения:
>>> gc.get_count() (688, 1, 1)Наконец, вы можете запустить алгоритм сбора вручную:
>>> gc.collect() 24При этом будет вызван
collect()внутри файлаModules/gcmodule.c, который содержит реализацию алгоритма сбора мусора.Заключение
В части 1 вы рассмотрели структуру хранилища исходного кода, способы компиляции из исходного кода и спецификацию языка Python. Эти основные понятия будут иметь решающее значение в части 2, когда вы углубитесь в процесс интерпретации Python.
Часть 2: Процесс работы интерпретатора Python
Теперь, когда вы ознакомились с грамматикой Python и управлением памятью, вы можете проследить за процессом от ввода
pythonдо той части, где выполняется ваш код.Существует пять способов вызова двоичного файла
python:
- Для выполнения одной команды с помощью
-cи команды Python- Для запуска модуля с
-mи именем модуля- Для запуска файла с именем файла
- Для запуска
stdinввода с помощью канала shell- Для запуска REPL и выполнения команд по одной за раз
В Python так много способов выполнения скриптов, что это может быть немного утомительно. Даррен Джонс составил отличный курс по запуску скриптов на Python, если вы хотите узнать больше.
Чтобы увидеть этот процесс, вам необходимо просмотреть три исходных файла:
Programs/python.cэто простая точка входа.Modules/main.cсодержит код, объединяющий весь процесс, включая загрузку конфигурации, выполнение кода и очистку памяти.Python/initconfig.cзагружает конфигурацию из системного окружения и объединяет ее с любыми флагами командной строки.На этой диаграмме показано, как вызывается каждая из этих функций:
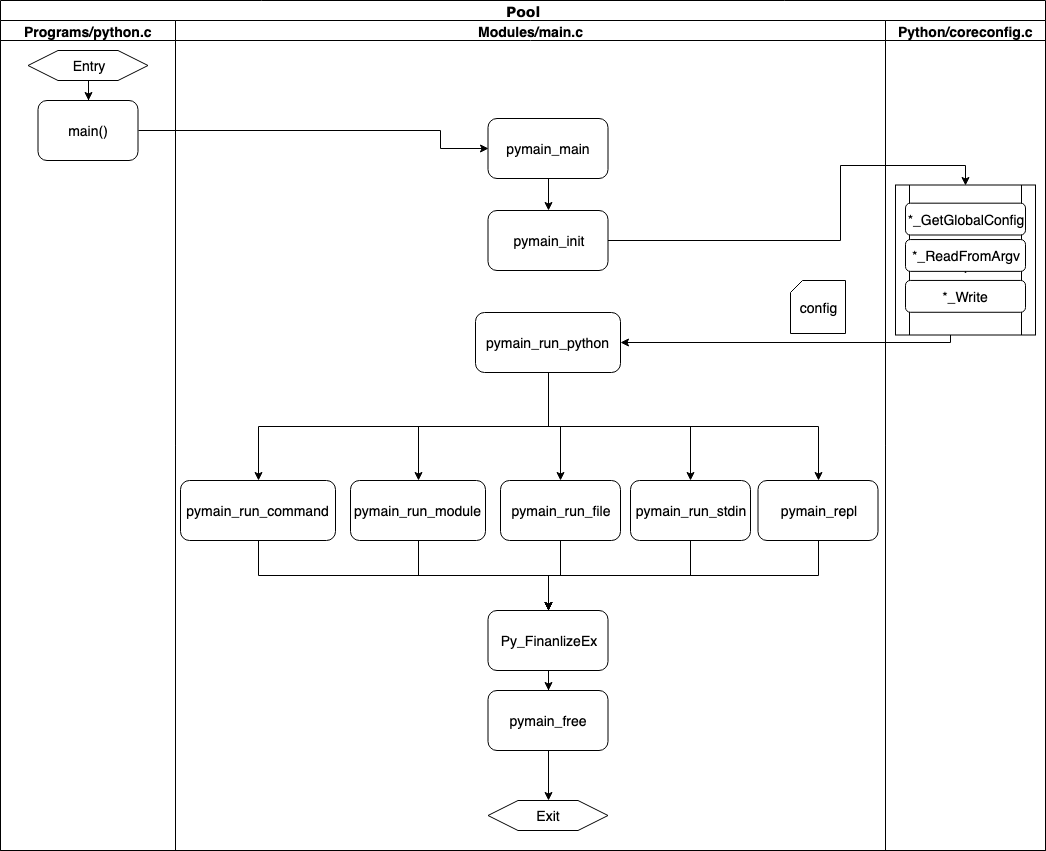
Режим выполнения определяется из конфигурации.
Стиль исходного кода CPython:
Аналогично руководству по стилю PEP8 для кода на Python, существует официальное руководство по стилю для кода на CPython C, первоначально разработанное на 2001 и обновлен для современных версий.
Существуют некоторые стандарты именования, которые помогают при навигации по исходному коду:
Используйте префикс
Pyдля общедоступных функций, но никогда для статических функций. ПрефиксPy_зарезервирован для глобальных служебных процедур, таких какPy_FatalError. Определенные группы процедур (например, API-интерфейсы определенного типа объектов) используют более длинный префикс, напримерPyString_для строковых функций.Общедоступные функции и переменные используют смешанный регистр со знаками подчеркивания, например, так:
PyObject_GetAttr,Py_BuildValue,PyExc_TypeError.Иногда “внутренняя” функция должна быть видна загрузчику. Например, для этого мы используем префикс
_Py,_PyObject_Dump.Макросы должны иметь префикс mixedCase, а затем использовать верхний регистр, например
PyString_AS_STRING,Py_PRINT_RAW.Настройка конфигурации среды выполнения
На графиках вы можете видеть, что перед выполнением любого кода на Python среда выполнения сначала устанавливает конфигурацию. Конфигурация среды выполнения представляет собой структуру данных, определенную в
Include/cpython/initconfig.hс именемPyConfig.Структура конфигурационных данных включает в себя такие элементы, как:
- Флаги времени выполнения для различных режимов, таких как режим отладки и оптимизированный режим
- Режим выполнения, например, было ли передано имя файла,
stdinили указано имя модуля- Расширенный параметр, указанный с помощью
-X <option>- Переменных среды для настроек среды выполнения
Данные конфигурации в основном используются средой выполнения CPython для включения и отключения различных функций.
Python также поставляется с несколькими параметрами интерфейса командной строки. В Python вы можете включить подробный режим с помощью флага
-v. В подробном режиме Python будет выводить сообщения на экран при загрузке модулей:$ ./python.exe -v -c "print('hello world')" # installing zipimport hook import zipimport # builtin # installed zipimport hook ...Вы увидите сотню или более строк со всеми данными об импорте пакетов вашего пользовательского сайта и всего остального в системной среде.
Вы можете увидеть определение этого флага в
Include/cpython/initconfig.hвнутриstructдляPyConfig:/* --- PyConfig ---------------------------------------------- */ typedef struct { int _config_version; /* Internal configuration version, used for ABI compatibility */ int _config_init; /* _PyConfigInitEnum value */ ... /* If greater than 0, enable the verbose mode: print a message each time a module is initialized, showing the place (filename or built-in module) from which it is loaded. If greater or equal to 2, print a message for each file that is checked for when searching for a module. Also provides information on module cleanup at exit. Incremented by the -v option. Set by the PYTHONVERBOSE environment variable. If set to -1 (default), inherit Py_VerboseFlag value. */ int verbose;В
Python/initconfig.cустановлена логика для считывания настроек из переменных среды и флагов командной строки времени выполнения.В функции
config_read_env_varsсчитываются переменные среды и используются для присвоения значений параметрам конфигурации:static PyStatus config_read_env_vars(PyConfig *config) { PyStatus status; int use_env = config->use_environment; /* Get environment variables */ _Py_get_env_flag(use_env, &config->parser_debug, "PYTHONDEBUG"); _Py_get_env_flag(use_env, &config->verbose, "PYTHONVERBOSE"); _Py_get_env_flag(use_env, &config->optimization_level, "PYTHONOPTIMIZE"); _Py_get_env_flag(use_env, &config->inspect, "PYTHONINSPECT");Что касается подробной настройки, вы можете видеть, что значение
PYTHONVERBOSEиспользуется для установки значения&config->verbose, если найдено значениеPYTHONVERBOSE. Если переменная окружения не существует, то останется значение по умолчанию-1.Затем в
config_parse_cmdlineв пределахinitconfig.cснова используется флаг командной строки для установки значения, если оно указано:static PyStatus config_parse_cmdline(PyConfig *config, PyWideStringList *warnoptions, Py_ssize_t *opt_index) { ... switch (c) { ... case 'v': config->verbose++; break; ... /* This space reserved for other options */ default: /* unknown argument: parsing failed */ config_usage(1, program); return _PyStatus_EXIT(2); } } while (1);Это значение позже копируется в глобальную переменную
Py_VerboseFlagс помощью функции_Py_GetGlobalVariablesAsDict.В рамках сеанса Python вы можете получить доступ к флагам среды выполнения, таким как подробный режим, тихий режим, используя именованный кортеж
sys.flags. Все флаги-Xдоступны в словареsys._xoptions:$ ./python.exe -X dev -q >>> import sys >>> sys.flags sys.flags(debug=0, inspect=0, interactive=0, optimize=0, dont_write_bytecode=0, no_user_site=0, no_site=0, ignore_environment=0, verbose=0, bytes_warning=0, quiet=1, hash_randomization=1, isolated=0, dev_mode=True, utf8_mode=0) >>> sys._xoptions {'dev': True}Помимо конфигурации среды выполнения в
initconfig.h, существует также конфигурация сборки, которая находится внутриpyconfig.hв корневой папке. Этот файл создается динамически наconfigureшаге процесса сборки или с помощью Visual Studio для систем Windows.Вы можете просмотреть конфигурацию сборки, выполнив команду:
$ ./python.exe -m sysconfigЧтение файлов/Ввод данных
Как только CPython получит конфигурацию среды выполнения и аргументы командной строки, он сможет определить, что ему нужно для выполнения.
Эта задача выполняется функцией
pymain_mainвнутриModules/main.c. В зависимости от вновь созданного экземпляраconfigCPython теперь будет выполнять код, предоставленный с помощью нескольких опций.Ввод через
-cСамым простым является предоставление CPython команды с параметром
-cи программы на Python в кавычках.Например:
$ ./python.exe -c "print('hi')" hiВот полная блок-схема того, как это происходит:
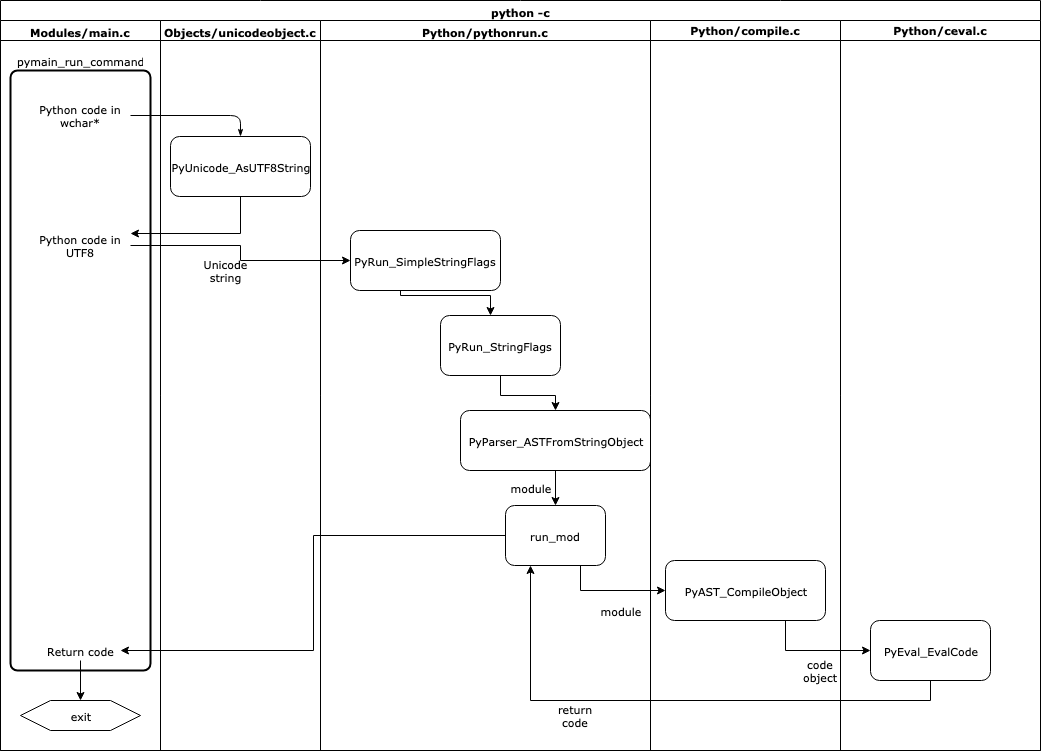
Сначала функция
pymain_run_command()выполняется внутриModules/main.c, принимая команду, переданную в-cв качестве аргумента в C введитеwchar_t*. Типwchar_t*часто используется в качестве низкоуровневого хранилища для данных в Юникоде в CPython, поскольку размер этого типа позволяет хранить символы UTF8.При преобразовании
wchar_t*в строку Python файлObjects/unicodeobject.cимеет вспомогательную функциюPyUnicode_FromWideChar(), которая возвращаетPyObjectтипаstr. Кодировка в UTF-8 затем выполняется с помощьюPyUnicode_AsUTF8String()для объекта Pythonstr, чтобы преобразовать его в Pythonbytesobject.Как только это будет завершено,
pymain_run_command()затем мы передадим объект PythonbytesвPyRun_SimpleStringFlags()для выполнения, но сначала снова преобразуемbytesвstrтипа:static int pymain_run_command(wchar_t *command, PyCompilerFlags *cf) { PyObject *unicode, *bytes; int ret; unicode = PyUnicode_FromWideChar(command, -1); if (unicode == NULL) { goto error; } if (PySys_Audit("cpython.run_command", "O", unicode) < 0) { return pymain_exit_err_print(); } bytes = PyUnicode_AsUTF8String(unicode); Py_DECREF(unicode); if (bytes == NULL) { goto error; } ret = PyRun_SimpleStringFlags(PyBytes_AsString(bytes), cf); Py_DECREF(bytes); return (ret != 0); error: PySys_WriteStderr("Unable to decode the command from the command line:\n"); return pymain_exit_err_print(); }Преобразование
wchar_t*в Юникод, байты, а затем в строку примерно эквивалентно следующему:unicode = str(command) bytes_ = bytes(unicode.encode('utf8')) # call PyRun_SimpleStringFlags with bytes_Функция
PyRun_SimpleStringFlags()является частьюPython/pythonrun.c. Его цель состоит в том, чтобы преобразовать эту простую команду в модуль Python и затем отправить ее на выполнение. Поскольку модуль Python должен иметь__main__для выполнения в качестве отдельного модуля, он создает его автоматически:int PyRun_SimpleStringFlags(const char *command, PyCompilerFlags *flags) { PyObject *m, *d, *v; m = PyImport_AddModule("__main__"); if (m == NULL) return -1; d = PyModule_GetDict(m); v = PyRun_StringFlags(command, Py_file_input, d, d, flags); if (v == NULL) { PyErr_Print(); return -1; } Py_DECREF(v); return 0; }Как только
PyRun_SimpleStringFlags()создает модуль и словарь, он вызываетPyRun_StringFlags(), который создает поддельное имя файла, а затем вызывает синтаксический анализатор Python для создания AST из строки и возврата модуля,mod:PyObject * PyRun_StringFlags(const char *str, int start, PyObject *globals, PyObject *locals, PyCompilerFlags *flags) { ... mod = PyParser_ASTFromStringObject(str, filename, start, flags, arena); if (mod != NULL) ret = run_mod(mod, filename, globals, locals, flags, arena); PyArena_Free(arena); return ret;В следующем разделе вы познакомитесь с AST-кодом и кодом синтаксического анализа.
Ввод через
-mДругим способом выполнения команд Python является использование параметра
-mс именем модуля. Типичным примером являетсяpython -m unittestзапуск модуля unittest в стандартной библиотеке.Возможность выполнения модулей в виде сценариев была первоначально предложена в PEP 338, а затем в стандарте для явного относительного импорта, определенном в PEP366.
Использование флага
-mподразумевает, что в рамках пакета модуля вы хотите выполнить все, что находится внутри__main__. Это также подразумевает, что вы хотите выполнить поискsys.pathдля именованного модуля.Именно благодаря этому механизму поиска вам не нужно запоминать, где в вашей файловой системе хранится модуль
unittest.Внутри
Modules/main.cесть функция, вызываемая при запуске командной строки с флагом-m. Имя модуля передается в качестве аргументаmodname.Затем CPython импортирует стандартный библиотечный модуль,
runpyи запустит его с помощьюPyObject_Call(). Импорт осуществляется с помощью функции C APIPyImport_ImportModule(), найденной в файлеPython/import.c:static int pymain_run_module(const wchar_t *modname, int set_argv0) { PyObject *module, *runpy, *runmodule, *runargs, *result; runpy = PyImport_ImportModule("runpy"); ... runmodule = PyObject_GetAttrString(runpy, "_run_module_as_main"); ... module = PyUnicode_FromWideChar(modname, wcslen(modname)); ... runargs = Py_BuildValue("(Oi)", module, set_argv0); ... result = PyObject_Call(runmodule, runargs, NULL); ... if (result == NULL) { return pymain_exit_err_print(); } Py_DECREF(result); return 0; }В этой функции вы также увидите 2 другие функции C API:
PyObject_Call()иPyObject_GetAttrString(). ПосколькуPyImport_ImportModule()возвращаетPyObject*, основной тип объекта, вам необходимо вызвать специальные функции, чтобы получить атрибуты и вызвать его.В Python, если у вас есть объект и вы хотите получить атрибут, вы можете вызвать
getattr(). В C API этот вызов называетсяPyObject_GetAttrString(),, который находится вObjects/object.c. Если бы вы хотели запустить вызываемый объект, вы бы заключили его в круглые скобки, или вы можете запустить свойство__call__()для любого объекта Python. Метод__call__()реализован внутриObjects/object.c:hi = "hi!" hi.upper() == hi.upper.__call__() # this is the sameМодуль
runpyнаписан на чистом Python и расположен вLib/runpy.py.Выполнение
python -m <module>эквивалентно выполнениюpython -m runpy <module>. Модульrunpyбыл создан для абстрагирования процесса поиска и выполнения модулей в операционной системе.
runpyвыполняет несколько действий для запуска целевого модуля:
- Вызывает
__import__()указанное вами имя модуля- Устанавливает
__name__(имя модуля) в пространство имен, называемое__main__- Выполняет модуль в пространстве имен
__main__Модуль
runpyтакже поддерживает выполнение каталогов и zip-файлов.Ввод через имя файла
Если первым аргументом
pythonбыло имя файла, напримерpython test.py, то CPython откроет дескриптор файла, аналогичный использованиюopen()в Python, и передаст дескриптор вPyRun_SimpleFileExFlags()внутриPython/pythonrun.c.Есть 3 пути, которые может использовать эта функция:
- Если путь к файлу равен
.pyc, то будет вызванrun_pyc_file().- Если путь к файлу указан как файл сценария (
.py), то он будет запущенPyRun_FileExFlags().- Если путь к файлу равен
stdin, потому что пользователь запустилcommand | python, то обработайтеstdinкак дескриптор файла и запуститеPyRun_FileExFlags().int PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) { ... m = PyImport_AddModule("__main__"); ... if (maybe_pyc_file(fp, filename, ext, closeit)) { ... v = run_pyc_file(pyc_fp, filename, d, d, flags); } else { /* When running from stdin, leave __main__.__loader__ alone */ if (strcmp(filename, "<stdin>") != 0 && set_main_loader(d, filename, "SourceFileLoader") < 0) { fprintf(stderr, "python: failed to set __main__.__loader__\n"); ret = -1; goto done; } v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d, closeit, flags); } ... return ret; }Ввод через файл с
PyRun_FileExFlags()Для файлов
stdinи базовых скриптов CPython передаст дескриптор файла вPyRun_FileExFlags(), расположенный в файлеpythonrun.c.Назначение параметра
PyRun_FileExFlags()аналогично назначению параметраPyRun_SimpleStringFlags(), используемого для ввода-c. CPython загрузит дескриптор файла вPyParser_ASTFromFileObject(). В следующем разделе мы рассмотрим модули синтаксического анализа и AST. Поскольку это полноценный сценарий, для него не требуется шагPyImport_AddModule("__main__");, используемый-c:PyObject * PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals, PyObject *locals, int closeit, PyCompilerFlags *flags) { ... mod = PyParser_ASTFromFileObject(fp, filename, NULL, start, 0, 0, flags, NULL, arena); ... ret = run_mod(mod, filename, globals, locals, flags, arena); }Аналогично
PyRun_SimpleStringFlags(), как толькоPyRun_FileExFlags()создал модуль Python из файла , он отправил его наrun_mod()для выполнения.
run_mod()находится внутриPython/pythonrun.cи отправляет модуль в AST для компиляции в объект кода. Объекты кода - это формат, используемый для хранения операций с байт-кодом, и формат, сохраняемый в файлах.pyc:static PyObject * run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags, PyArena *arena) { PyCodeObject *co; PyObject *v; co = PyAST_CompileObject(mod, filename, flags, -1, arena); if (co == NULL) return NULL; if (PySys_Audit("exec", "O", co) < 0) { Py_DECREF(co); return NULL; } v = run_eval_code_obj(co, globals, locals); Py_DECREF(co); return v; }В следующем разделе мы рассмотрим компилятор CPython и байт-коды. Вызов
run_eval_code_obj()- это простая функция-оболочка, которая вызываетPyEval_EvalCode()в файлеPython/eval.c. ФункцияPyEval_EvalCode()является основным вычислительным циклом для CPython, она выполняет итерацию по каждому оператору байт-кода и выполняет его на вашем локальном компьютере.Ввод с помощью скомпилированного байт-кода с
run_pyc_file()В
PyRun_SimpleFileExFlags()было предложение для пользователя, предоставляющего путь к файлу.pyc. Если путь к файлу заканчивается на.pyc, то вместо загрузки файла в виде обычного текстового файла и его синтаксического анализа предполагается, что файл.pycсодержит объект кода, записанный на диск.Функция
run_pyc_file()внутриPython/pythonrun.cзатем выполняет маршалинг объекта code из файла.pycс помощью дескриптора файла. Маршалинг - это технический термин, обозначающий копирование содержимого файла в память и преобразование его в определенную структуру данных. Структура данных объекта code на диске - это способ кэширования компилятором CPython скомпилированного кода, так что ему не нужно разбирать его каждый раз при вызове скрипта:static PyObject * run_pyc_file(FILE *fp, const char *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags) { PyCodeObject *co; PyObject *v; ... v = PyMarshal_ReadLastObjectFromFile(fp); ... if (v == NULL || !PyCode_Check(v)) { Py_XDECREF(v); PyErr_SetString(PyExc_RuntimeError, "Bad code object in .pyc file"); goto error; } fclose(fp); co = (PyCodeObject *)v; v = run_eval_code_obj(co, globals, locals); if (v && flags) flags->cf_flags |= (co->co_flags & PyCF_MASK); Py_DECREF(co); return v; }После того, как объект кода был упорядочен в памяти, он отправляется в
run_eval_code_obj(),, который вызываетPython/ceval.cдля выполнения кода.Лексический анализ
Изучая чтение и выполнение файлов на Python, мы углубились в изучение синтаксического анализатора и AST-модулей, используя вызовы функций для
PyParser_ASTFromFileObject().Оставаясь в пределах
Python/pythonrun.c, функцияPyParser_ASTFromFileObject()возьмет дескриптор файла, флаги компилятора и экземплярPyArenaи преобразует файловый объект в объект node, используяPyParser_ParseFileObject().Используя объект node, он затем преобразует его в модуль с помощью функции AST
PyAST_FromNodeObject():mod_ty PyParser_ASTFromFileObject(FILE *fp, PyObject *filename, const char* enc, int start, const char *ps1, const char *ps2, PyCompilerFlags *flags, int *errcode, PyArena *arena) { ... node *n = PyParser_ParseFileObject(fp, filename, enc, &_PyParser_Grammar, start, ps1, ps2, &err, &iflags); ... if (n) { flags->cf_flags |= iflags & PyCF_MASK; mod = PyAST_FromNodeObject(n, flags, filename, arena); PyNode_Free(n); ... return mod; }Для
PyParser_ParseFileObject()мы переходим кParser/parsetok.cи этапу синтаксического анализа-токенизации интерпретатора CPython. Эта функция выполняет две важные задачи:
- Создать экземпляр состояния токенизатора
tok_stateиспользуяPyTokenizer_FromFile()вParser/tokenizer.c- Преобразуйте токены в конкретное дерево синтаксического анализа (список из
node), используяparsetok()inParser/parsetok.cnode * PyParser_ParseFileObject(FILE *fp, PyObject *filename, const char *enc, grammar *g, int start, const char *ps1, const char *ps2, perrdetail *err_ret, int *flags) { struct tok_state *tok; ... if ((tok = PyTokenizer_FromFile(fp, enc, ps1, ps2)) == NULL) { err_ret->error = E_NOMEM; return NULL; } ... return parsetok(tok, g, start, err_ret, flags); }
tok_state( определено вParser/tokenizer.h) - это структура данных для хранения всех временных данных, сгенерированных токенизатором. Он возвращается синтаксическому анализатору-токенизатору, поскольку структура данных требуетсяparsetok()для разработки конкретного синтаксического дерева.Внутри
parsetok(), он будет использовать структуруtok_stateи выполнять вызовы вtok_get()в цикле до тех пор, пока файл не будет исчерпан и больше не будет найдено токенов.
tok_get(), определенный вParser/tokenizer.cведет себя как итератор. Он будет продолжать возвращать следующий токен в дереве синтаксического анализа.
tok_get()это одна из самых сложных функций во всей кодовой базе CPython. Он содержит более 640 строк и включает в себя многолетнее наследие с расширенными вариантами, новыми языковыми возможностями и синтаксисом.Одним из более простых примеров может быть часть, которая преобразует символ перевода строки в символ НОВОЙ СТРОКИ:
static int tok_get(struct tok_state *tok, char **p_start, char **p_end) { ... /* Newline */ if (c == '\n') { tok->atbol = 1; if (blankline || tok->level > 0) { goto nextline; } *p_start = tok->start; *p_end = tok->cur - 1; /* Leave '\n' out of the string */ tok->cont_line = 0; if (tok->async_def) { /* We're somewhere inside an 'async def' function, and we've encountered a NEWLINE after its signature. */ tok->async_def_nl = 1; } return NEWLINE; } ... }В данном случае
NEWLINE- это токен, значение которого определено вInclude/token.h. Все токены являются постоянными значениямиint, а файлInclude/token.hбыл сгенерирован ранее, когда мы запускалиmake regen-grammar.Тип
node, возвращаемый параметромPyParser_ParseFileObject(), будет необходим для следующего этапа преобразования дерева синтаксического анализа в абстрактное синтаксическое дерево (AST):typedef struct _node { short n_type; char *n_str; int n_lineno; int n_col_offset; int n_nchildren; struct _node *n_child; int n_end_lineno; int n_end_col_offset; } node;Поскольку CST представляет собой дерево синтаксиса, идентификаторов токенов и символов, компилятору было бы сложно быстро принимать решения на основе языка Python.
Вот почему следующим этапом является преобразование CST в AST, структуру гораздо более высокого уровня. Эта задача выполняется модулем
Python/ast.c, который имеет как C, так и Python API.Прежде чем перейти к AST, есть способ получить доступ к выводам на этапе синтаксического анализа. В CPython есть стандартный библиотечный модуль
parser, который предоставляет функции C с помощью API Python.Модуль задокументирован как деталь реализации CPython, поэтому вы не увидите его в других интерпретаторах Python. Кроме того, выходные данные функций не так легко читать.
Выходные данные будут представлены в числовой форме с использованием номеров токенов и символов, сгенерированных на этапе
make regen-grammarи сохраненных вInclude/token.h:>>> from pprint import pprint >>> import parser >>> st = parser.expr('a + 1') >>> pprint(parser.st2list(st)) [258, [332, [306, [310, [311, [312, [313, [316, [317, [318, [319, [320, [321, [322, [323, [324, [325, [1, 'a']]]]]], [14, '+'], [321, [322, [323, [324, [325, [2, '1']]]]]]]]]]]]]]]]], [4, ''], [0, '']]Чтобы было проще понять, вы можете взять все числа из модулей
symbolиtoken, поместить их в словарь и рекурсивно замените значения в выходных данныхparser.st2list()на имена:import symbol import token import parser def lex(expression): symbols = {v: k for k, v in symbol.__dict__.items() if isinstance(v, int)} tokens = {v: k for k, v in token.__dict__.items() if isinstance(v, int)} lexicon = {**symbols, **tokens} st = parser.expr(expression) st_list = parser.st2list(st) def replace(l: list): r = [] for i in l: if isinstance(i, list): r.append(replace(i)) else: if i in lexicon: r.append(lexicon[i]) else: r.append(i) return r return replace(st_list)Вы можете запустить
lex()с помощью простого выражения, напримерa + 1, чтобы увидеть, как это представляется в виде дерева синтаксического анализа:>>> from pprint import pprint >>> pprint(lex('a + 1')) ['eval_input', ['testlist', ['test', ['or_test', ['and_test', ['not_test', ['comparison', ['expr', ['xor_expr', ['and_expr', ['shift_expr', ['arith_expr', ['term', ['factor', ['power', ['atom_expr', ['atom', ['NAME', 'a']]]]]], ['PLUS', '+'], ['term', ['factor', ['power', ['atom_expr', ['atom', ['NUMBER', '1']]]]]]]]]]]]]]]]], ['NEWLINE', ''], ['ENDMARKER', '']]В выходных данных вы можете увидеть символы в нижнем регистре, такие как
'test', и токены в верхнем регистре, такие как'NUMBER'.Абстрактные синтаксические деревья
Абстрактные синтаксические деревья
Абстрактные синтаксические деревья
astАбстрактные синтаксические деревья
Абстрактные синтаксические деревья
instavizАбстрактные синтаксические деревья
instaviz$ pip install instavizЗатем откройте REPL, запустив
pythonв командной строке без аргументов:>>> import instaviz >>> def example(): a = 1 b = a + 1 return b >>> instaviz.show(example)Затем откройте REPL, запустив в командной строке без аргументов:Затем откройте REPL, запустив
>8080в командной строке без аргументов:<<<2>>Затем откройте REPL, запустив
в командной строке без аргументов: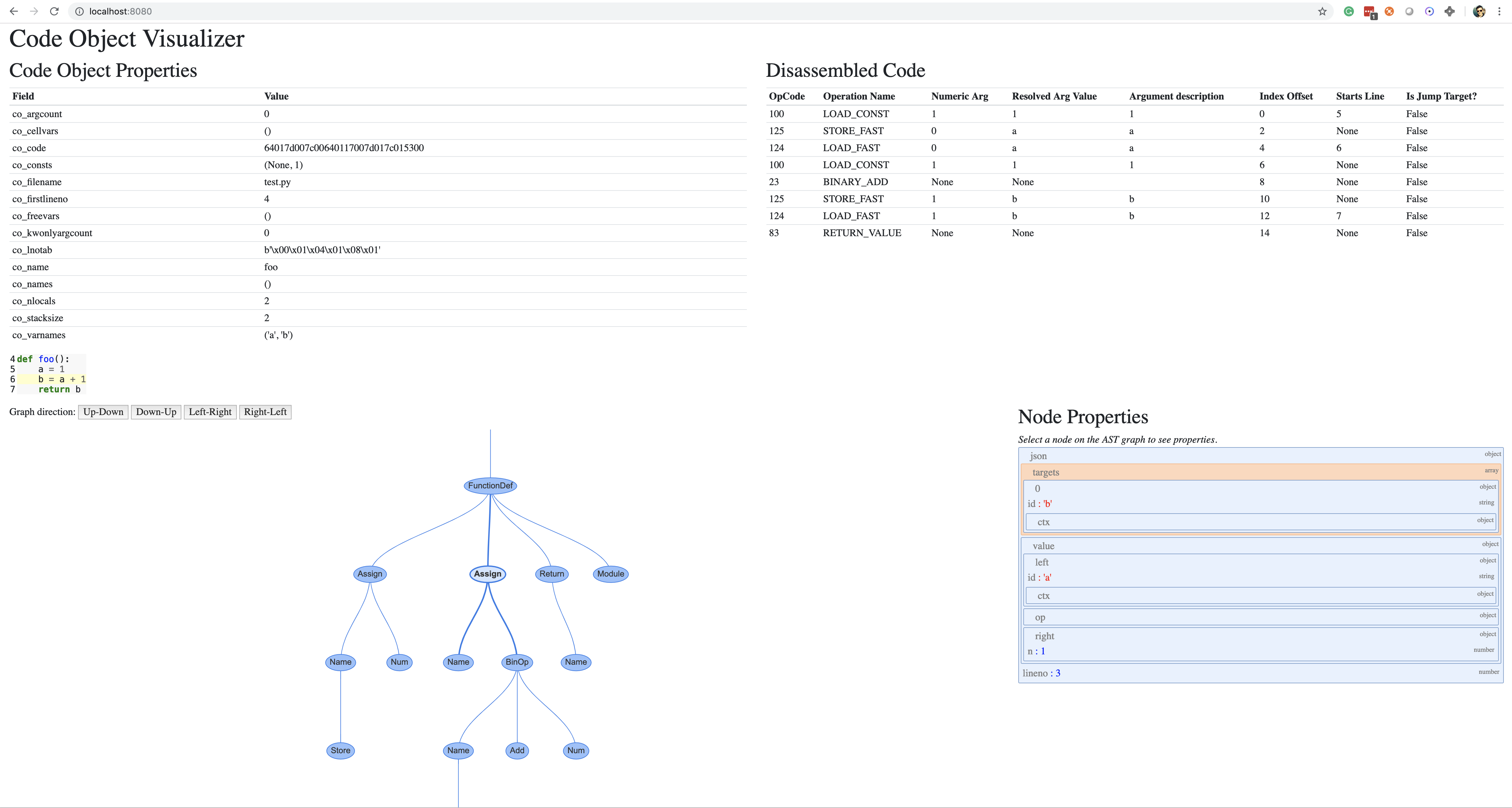
>
ast<<<2>>
b = a + 1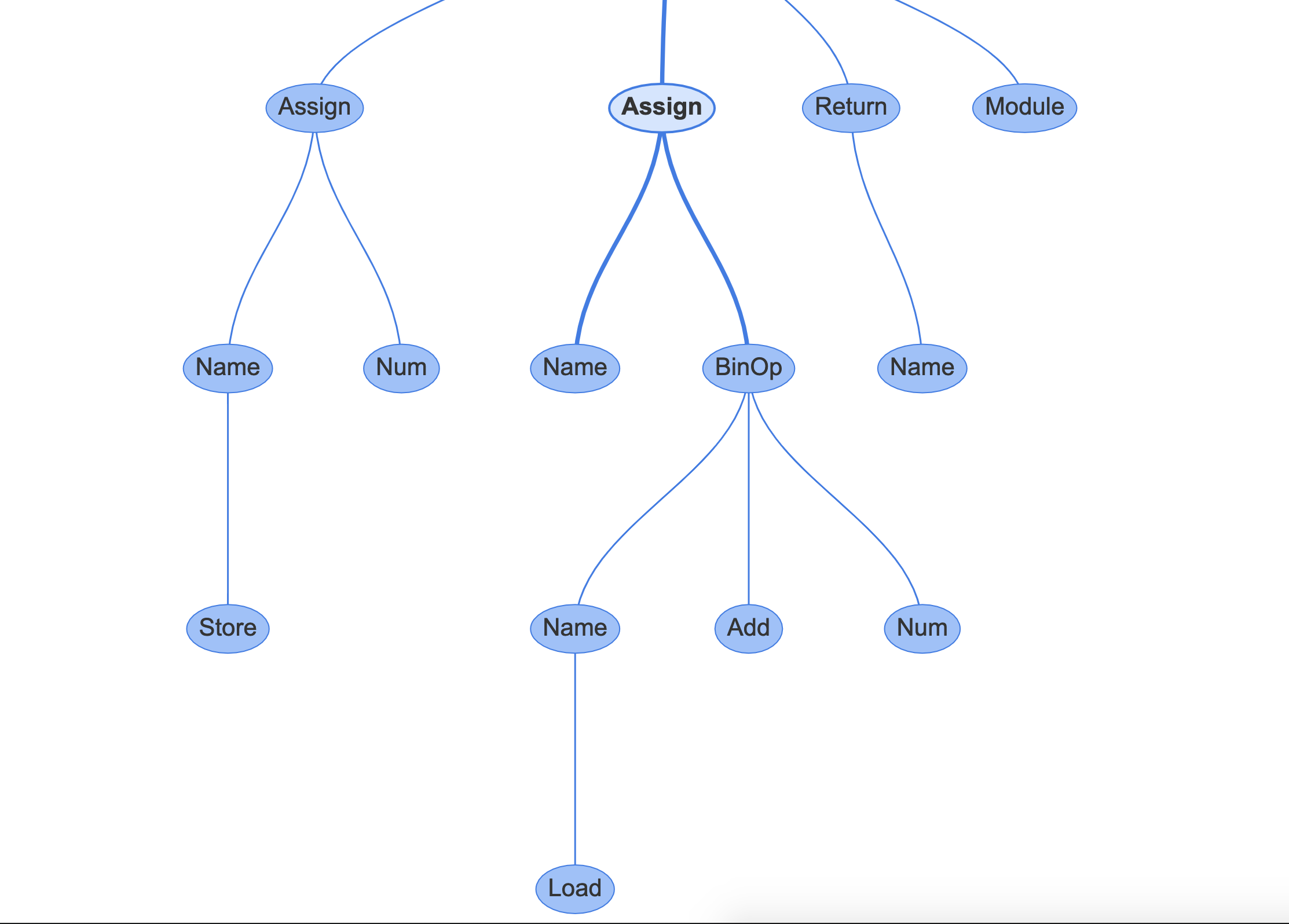
>
- <<<2>>
targetsvalueBinOpa + 1Если вы нажмете на оператор
BinOp, он покажет свойства релевантности:
left: узел слева от оператораop: оператор, в данном случае, представляет собой узелAdd(+) для добавленияright: узел справа от оператора
Компиляция AST на C не является простой задачей, поэтому модуль
Python/ast.cсодержит более 5000 строк кода.Существует несколько точек входа, составляющих часть общедоступного API AST. В последнем разделе, посвященном лексическому и синтаксическому анализу, вы остановились, когда дошли до вызова
PyAST_FromNodeObject(). К этому моменту процесс интерпретатора Python создал CST в форматеnode *дерева.Существует несколько точек входа, составляющих часть общедоступного API AST. В последнем разделе, посвященном лексическому и синтаксическому анализу, вы остановились, когда дошли до вызова
>PyAST_FromNodeObject(). К этому моменту процесс интерпретатора Python создал CST в форматеPython/ast.cдерева.<<<5>>PyArenaСуществует несколько точек входа, составляющих часть общедоступного API AST. В последнем разделе, посвященном лексическому и синтаксическому анализу, вы остановились, когда дошли до вызова
>mod_ty. К этому моменту процесс интерпретатора Python создал CST в форматеInclude/Python-ast.hдерева.<<<5>>Существует несколько точек входа, составляющих часть общедоступного API AST. В последнем разделе, посвященном лексическому и синтаксическому анализу, вы остановились, когда дошли до вызова
>- . К этому моменту процесс интерпретатора Python создал CST в формате
Module- дерева.<<<5>>
ExpressionFunctionTypeSuiteСуществует несколько точек входа, составляющих часть общедоступного API AST. В последнем разделе, посвященном лексическому и синтаксическому анализу, вы остановились, когда дошли до вызова
>Include/Python-ast.hExpressionbody. К этому моменту процесс интерпретатора Python создал CST в форматеexpr_tyдерева.<<<5>>Include/Python-ast.henum _mod_kind {Module_kind=1, Interactive_kind=2, Expression_kind=3, FunctionType_kind=4, Suite_kind=5}; struct _mod { enum _mod_kind kind; union { struct { asdl_seq *body; asdl_seq *type_ignores; } Module; struct { asdl_seq *body; } Interactive; struct { expr_ty body; } Expression; struct { asdl_seq *argtypes; expr_ty returns; } FunctionType; struct { asdl_seq *body; } Suite; } v; };Все типы AST перечислены в
Parser/Python.asdl. Вы увидите все перечисленные типы модулей, типы инструкций, типы выражений, операторы и варианты их понимания. Названия типов в этом документе относятся к классам, сгенерированным AST, и к тем же классам, которые указаны в библиотеке стандартных модулейast.Параметры и названия, указанные в
Include/Python-ast.h, непосредственно соответствуют параметрам и названиям, указанным вParser/Python.asdl:-- ASDL's 5 builtin types are: -- identifier, int, string, object, constant module Python { mod = Module(stmt* body, type_ignore *type_ignores) | Interactive(stmt* body) | Expression(expr body) | FunctionType(expr* argtypes, expr returns)Заголовочный файл на языке Си и структуры находятся там, чтобы программа
Python/ast.cмогла быстро генерировать структуры с указателями на соответствующие данные.Глядя на
PyAST_FromNodeObject()вы можете видеть, что это, по сути, операторswitch, основанный на результате изTYPE(n).TYPE()- это одна из основных функций, используемых AST для определения типа узла в конкретном синтаксическом дереве. В случаеPyAST_FromNodeObject()это просто просмотр первого узла, поэтому это может быть только один из типов модулей, определенных какModule,Interactive,Expression,FunctionType.Результатом
TYPE()будет либо символ, либо тип токена, с которым мы уже хорошо знакомы на этом этапе.Для
file_inputрезультатом должно бытьModule. Модули представляют собой набор инструкций, которые бывают нескольких типов. Логика для обхода дочерних элементовnи создания узлов оператора находится внутриast_for_stmt(). Эта функция вызывается либо один раз, если в модуле есть только 1 оператор, либо в цикле, если их много. Затем возвращается результирующее значениеModuleсPyArena.Для
eval_inputрезультатом должно бытьExpression. Результат изCHILD(n ,0), который является первым дочерним элементомn, передается вast_for_testlist(), который возвращает типexpr_ty. Этоexpr_tyотправляется вExpression()с помощью PyArena для создания узла выражения, а затем передается обратно в виде результата:mod_ty PyAST_FromNodeObject(const node *n, PyCompilerFlags *flags, PyObject *filename, PyArena *arena) { ... switch (TYPE(n)) { case file_input: stmts = _Py_asdl_seq_new(num_stmts(n), arena); if (!stmts) goto out; for (i = 0; i < NCH(n) - 1; i++) { ch = CHILD(n, i); if (TYPE(ch) == NEWLINE) continue; REQ(ch, stmt); num = num_stmts(ch); if (num == 1) { s = ast_for_stmt(&c, ch); if (!s) goto out; asdl_seq_SET(stmts, k++, s); } else { ch = CHILD(ch, 0); REQ(ch, simple_stmt); for (j = 0; j < num; j++) { s = ast_for_stmt(&c, CHILD(ch, j * 2)); if (!s) goto out; asdl_seq_SET(stmts, k++, s); } } } /* Type ignores are stored under the ENDMARKER in file_input. */ ... res = Module(stmts, type_ignores, arena); break; case eval_input: { expr_ty testlist_ast; /* XXX Why not comp_for here? */ testlist_ast = ast_for_testlist(&c, CHILD(n, 0)); if (!testlist_ast) goto out; res = Expression(testlist_ast, arena); break; } case single_input: ... break; case func_type_input: ... ... return res; }Внутри функции
ast_for_stmt()есть еще один операторswitchдля каждого возможного типа оператора (simple_stmt,compound_stmtи так далее) и код для определения аргументов класса node.Одна из самых простых функций предназначена для выражения степени, т.е.
2**4равно 2 в степени 4. Эта функция начинается с получения значенияast_for_atom_expr(),, которое в нашем примере является числом2, затем, если оно имеет один дочерний элемент, оно возвращает атомарное выражение. Если у него более одного дочернего элемента, он получит значение справа (число4) и вернет значениеBinOp(двоичная операция) с оператором в видеPow(степень), слева отe(2), и правая рука этогоf(4):static expr_ty ast_for_power(struct compiling *c, const node *n) { /* power: atom trailer* ('**' factor)* */ expr_ty e; REQ(n, power); e = ast_for_atom_expr(c, CHILD(n, 0)); if (!e) return NULL; if (NCH(n) == 1) return e; if (TYPE(CHILD(n, NCH(n) - 1)) == factor) { expr_ty f = ast_for_expr(c, CHILD(n, NCH(n) - 1)); if (!f) return NULL; e = BinOp(e, Pow, f, LINENO(n), n->n_col_offset, n->n_end_lineno, n->n_end_col_offset, c->c_arena); } return e; }Вы можете увидеть результат этого, если отправите короткую функцию в модуль
instaviz:>>> def foo(): 2**4 >>> import instaviz >>> instaviz.show(foo)
В пользовательском интерфейсе вы также можете увидеть соответствующие свойства:

Таким образом, каждому типу инструкции и выражению соответствует
ast_for_*()функция для его создания. Аргументы определены вParser/Python.asdlи доступны через модульastв стандартной библиотеке. Если у выражения или инструкции есть дочерние элементы, то при обходе в глубину будет вызвана соответствующая дочерняя функцияast_for_*.Заключение
Универсальность CPython и низкоуровневый API выполнения делают его идеальным кандидатом для встроенного скриптового движка. Вы увидите, что CPython используется во многих приложениях с пользовательским интерфейсом, таких как дизайн игр, 3D-графика и автоматизация систем.
Процесс интерпретации является гибким и эффективным, и теперь, когда у вас есть представление о том, как он работает, вы готовы разобраться с компилятором.
Часть 3: Компилятор CPython и цикл выполнения
Часть 3: Компилятор CPython и цикл выполнения
Часть 3: Компилятор CPython и цикл выполнения
Часть 3: Компилятор CPython и цикл выполнения
Часть 3: Компилятор CPython и цикл выполнения
Часть 3: Компилятор CPython и цикл выполнения<<<3>>
>Ранее мы рассматривали, как выполняются файлы, и функцию
PyRun_FileExFlags()вPython/pythonrun.c. Внутри этой функции мы преобразовали дескрипторFILEв дескрипторmodтипаmod_ty. Эта задача была выполнена с помощьюPyParser_ASTFromFileObject(),, которая, в свою очередь, вызываетtokenizer,parser-tokenizer, а затем AST:PyObject * PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals, PyObject *locals, int closeit, PyCompilerFlags *flags) { ... mod = PyParser_ASTFromFileObject(fp, filename, NULL, start, 0, 0, ... ret = run_mod(mod, filename, globals, locals, flags, arena); }Результирующий модуль из вызова to отправляется в
run_mod()все еще находится вPython/pythonrun.c. Это небольшая функция, которая получаетPyCodeObjectизPyAST_CompileObject()и отправляет его вrun_eval_code_obj(). Вы разберетесь сrun_eval_code_obj()в следующем разделе:static PyObject * run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags, PyArena *arena) { PyCodeObject *co; PyObject *v; co = PyAST_CompileObject(mod, filename, flags, -1, arena); if (co == NULL) return NULL; if (PySys_Audit("exec", "O", co) < 0) { Py_DECREF(co); return NULL; } v = run_eval_code_obj(co, globals, locals); Py_DECREF(co); return v; }Функция
PyAST_CompileObject()является основной точкой входа в компилятор CPython. Он принимает модуль Python в качестве основного аргумента, а также имя файла, глобальные параметры, локальные значения иPyArena, созданные ранее в процессе интерпретатора.Сейчас мы начинаем разбираться во внутренностях компилятора CPython, за которым стоят десятилетия разработок и теория компьютерных наук. Пусть вас не пугает этот язык. Как только мы разобьем компилятор на логические этапы, это обретет смысл.
Перед запуском компилятора создается глобальное состояние компилятора. Этот тип,
compiler, определен вPython/compile.cи содержит свойства, используемые компилятором для запоминания флагов компилятора, стека иPyArena:struct compiler { PyObject *c_filename; struct symtable *c_st; PyFutureFeatures *c_future; /* pointer to module's __future__ */ PyCompilerFlags *c_flags; int c_optimize; /* optimization level */ int c_interactive; /* true if in interactive mode */ int c_nestlevel; int c_do_not_emit_bytecode; /* The compiler won't emit any bytecode if this value is different from zero. This can be used to temporarily visit nodes without emitting bytecode to check only errors. */ PyObject *c_const_cache; /* Python dict holding all constants, including names tuple */ struct compiler_unit *u; /* compiler state for current block */ PyObject *c_stack; /* Python list holding compiler_unit ptrs */ PyArena *c_arena; /* pointer to memory allocation arena */ };Внутри
PyAST_CompileObject(), выполняется 11 основных шагов:
- Создайте пустое свойство
__doc__для модуля, если оно не существует.- Создайте пустое свойство
__annotations__для модуля, если оно не существует.- В качестве аргумента filename задайте имя файла глобального состояния компилятора.
- Установите для компилятора режим выделения памяти, который используется интерпретатором.
- Скопируйте все
__future__флаги в модуле в будущие флаги в компиляторе.- Объедините флаги среды выполнения, предоставляемые командной строкой или переменными среды.
- Включите все
__future__функции компилятора.- Установите уровень оптимизации равным указанному аргументу или по умолчанию.
- Создайте таблицу символов из объекта module.
- Запустите компилятор с состоянием компилятора и верните объект code.
- Освободите всю выделенную память компилятором.
PyCodeObject * PyAST_CompileObject(mod_ty mod, PyObject *filename, PyCompilerFlags *flags, int optimize, PyArena *arena) { struct compiler c; PyCodeObject *co = NULL; PyCompilerFlags local_flags = _PyCompilerFlags_INIT; int merged; PyConfig *config = &_PyInterpreterState_GET_UNSAFE()->config; if (!__doc__) { __doc__ = PyUnicode_InternFromString("__doc__"); if (!__doc__) return NULL; } if (!__annotations__) { __annotations__ = PyUnicode_InternFromString("__annotations__"); if (!__annotations__) return NULL; } if (!compiler_init(&c)) return NULL; Py_INCREF(filename); c.c_filename = filename; c.c_arena = arena; c.c_future = PyFuture_FromASTObject(mod, filename); if (c.c_future == NULL) goto finally; if (!flags) { flags = &local_flags; } merged = c.c_future->ff_features | flags->cf_flags; c.c_future->ff_features = merged; flags->cf_flags = merged; c.c_flags = flags; c.c_optimize = (optimize == -1) ? config->optimization_level : optimize; c.c_nestlevel = 0; c.c_do_not_emit_bytecode = 0; if (!_PyAST_Optimize(mod, arena, c.c_optimize)) { goto finally; } c.c_st = PySymtable_BuildObject(mod, filename, c.c_future); if (c.c_st == NULL) { if (!PyErr_Occurred()) PyErr_SetString(PyExc_SystemError, "no symtable"); goto finally; } co = compiler_mod(&c, mod); finally: compiler_free(&c); assert(co || PyErr_Occurred()); return co; }Будущие флаги и флаги компилятора
Перед запуском компилятора есть два типа флагов для переключения функций внутри компилятора. Они получены из двух источников:
- Состояние интерпретатора, которое могло быть параметрами командной строки, заданными в
pyconfig.hили с помощью переменных окружения- Использование
__future__инструкций внутри фактического исходного кода модуляЧтобы различать два типа флагов, подумайте, что флаги
__future__требуются из-за синтаксиса или функций этого конкретного модуля. Например, в Python 3.7 введена отложенная оценка подсказок по типу с помощью флагаannotationsfuture:from __future__ import annotationsВ коде после этой инструкции могут использоваться подсказки о неразрешенных типах, поэтому требуется инструкция
__future__. В противном случае модуль не смог бы выполнить импорт. Было бы невозможно вручную запросить, чтобы пользователь, импортирующий модуль, включил этот конкретный флаг компилятора.Другие флаги компилятора зависят от среды, поэтому они могут изменять способ выполнения кода или способ работы компилятора, но они не должны ссылаться на исходный код так же, как это делают операторы
__future__.Одним из примеров флага компилятора может быть
-Oфлаг для оптимизации использованияassertинструкций. Этот флаг отключает любые инструкцииassert, которые могли быть введены в код для целей отладки. Его также можно включить с помощью параметраPYTHONOPTIMIZE=1переменной окружения.Таблицы символов
В
PyAST_CompileObject()была ссылка наsymtableи вызовPySymtable_BuildObject()с модулем, который должен быть выполнен.Цель таблицы символов - предоставить список пространств имен, глобальных и локальных переменных, которые компилятор может использовать для ссылок и разрешения областей.
Структура
symtableвInclude/symtable.hхорошо документирована, поэтому ясно, для чего предназначено каждое из полей. Для компилятора должен быть один экземпляр symtable, поэтому пространство имен становится необходимым.Если вы создаете функцию с именем
resolve_names()в одном модуле и объявляете другую функцию с таким же именем в другом модуле, вы хотите быть уверены, какая из них вызывается. Symtable служит этой цели, а также гарантирует, что переменные, объявленные в узкой области видимости, автоматически не станут глобальными (в конце концов, это не JavaScript):struct symtable { PyObject *st_filename; /* name of file being compiled, decoded from the filesystem encoding */ struct _symtable_entry *st_cur; /* current symbol table entry */ struct _symtable_entry *st_top; /* symbol table entry for module */ PyObject *st_blocks; /* dict: map AST node addresses * to symbol table entries */ PyObject *st_stack; /* list: stack of namespace info */ PyObject *st_global; /* borrowed ref to st_top->ste_symbols */ int st_nblocks; /* number of blocks used. kept for consistency with the corresponding compiler structure */ PyObject *st_private; /* name of current class or NULL */ PyFutureFeatures *st_future; /* module's future features that affect the symbol table */ int recursion_depth; /* current recursion depth */ int recursion_limit; /* recursion limit */ };Часть API таблицы символов доступна через модуль
symtableв стандартной библиотеке. Вы можете предоставить выражение или модуль и получить экземплярsymtable.SymbolTable.Вы можете предоставить строку с выражением Python и
compile_typeиз"eval", или модуль, функцию или класс, иcompile_modeиз"exec", чтобы получите таблицу символов.Просматривая элементы таблицы, мы можем увидеть некоторые открытые и закрытые поля и их типы:
>>> import symtable >>> s = symtable.symtable('b + 1', filename='test.py', compile_type='eval') >>> [symbol.__dict__ for symbol in s.get_symbols()] [{'_Symbol__name': 'b', '_Symbol__flags': 6160, '_Symbol__scope': 3, '_Symbol__namespaces': ()}]Весь код на C, лежащий в основе этого, находится в
Python/symtable.c, а основным интерфейсом является функцияPySymtable_BuildObject().Аналогично функции AST верхнего уровня, которую мы рассматривали ранее, функция
PySymtable_BuildObject()переключается междуmod_tyвозможными типами (Модуль, Выражение, Интерактивный, Suite, FunctionType) и просматривает все операторы внутри них.Помните, что
mod_tyявляется экземпляром AST, поэтому теперь будет рекурсивно исследовать узлы и ветви дерева и добавлять записи в таблицу символов:struct symtable * PySymtable_BuildObject(mod_ty mod, PyObject *filename, PyFutureFeatures *future) { struct symtable *st = symtable_new(); asdl_seq *seq; int i; PyThreadState *tstate; int recursion_limit = Py_GetRecursionLimit(); ... st->st_top = st->st_cur; switch (mod->kind) { case Module_kind: seq = mod->v.Module.body; for (i = 0; i < asdl_seq_LEN(seq); i++) if (!symtable_visit_stmt(st, (stmt_ty)asdl_seq_GET(seq, i))) goto error; break; case Expression_kind: ... case Interactive_kind: ... case Suite_kind: ... case FunctionType_kind: ... } ... }Таким образом, для модуля,
PySymtable_BuildObject()будет выполняться цикл по каждому оператору в модуле и вызыватьсяsymtable_visit_stmt().symtable_visit_stmt()это огромная инструкцияswitchс регистром для каждого типа инструкции (определенного вParser/Python.asdl).Для каждого типа инструкции существует определенная логика для этого типа инструкции. Например, определение функции имеет определенную логику для:
- Если глубина рекурсии превышает допустимое значение, возникает ошибка глубины рекурсии
- Имя функции, которая будет добавлена в качестве локальной переменной
- Значения по умолчанию для последовательных аргументов, которые будут разрешены
- Значения по умолчанию для аргументов ключевых слов, которые должны быть разрешены
- Все примечания к аргументам или типу возвращаемого значения разрешены
- Все декораторы функций разрешены
- Блок кода с содержимым функции просматривается в
symtable_enter_block()- Просматриваются аргументы
- Просматривается тело функции
Примечание: Если вы когда-нибудь задавались вопросом, почему аргументы Python по умолчанию изменяемы, причина кроется в этой функции. Вы можете видеть, что они являются указателями на переменную в symtable. Для копирования любых значений в неизменяемый тип не требуется выполнять никаких дополнительных действий.
static int symtable_visit_stmt(struct symtable *st, stmt_ty s) { if (++st->recursion_depth > st->recursion_limit) { // 1. PyErr_SetString(PyExc_RecursionError, "maximum recursion depth exceeded during compilation"); VISIT_QUIT(st, 0); } switch (s->kind) { case FunctionDef_kind: if (!symtable_add_def(st, s->v.FunctionDef.name, DEF_LOCAL)) // 2. VISIT_QUIT(st, 0); if (s->v.FunctionDef.args->defaults) // 3. VISIT_SEQ(st, expr, s->v.FunctionDef.args->defaults); if (s->v.FunctionDef.args->kw_defaults) // 4. VISIT_SEQ_WITH_NULL(st, expr, s->v.FunctionDef.args->kw_defaults); if (!symtable_visit_annotations(st, s, s->v.FunctionDef.args, // 5. s->v.FunctionDef.returns)) VISIT_QUIT(st, 0); if (s->v.FunctionDef.decorator_list) // 6. VISIT_SEQ(st, expr, s->v.FunctionDef.decorator_list); if (!symtable_enter_block(st, s->v.FunctionDef.name, // 7. FunctionBlock, (void *)s, s->lineno, s->col_offset)) VISIT_QUIT(st, 0); VISIT(st, arguments, s->v.FunctionDef.args); // 8. VISIT_SEQ(st, stmt, s->v.FunctionDef.body); // 9. if (!symtable_exit_block(st, s)) VISIT_QUIT(st, 0); break; case ClassDef_kind: { ... } case Return_kind: ... case Delete_kind: ... case Assign_kind: ... case AnnAssign_kind: ...Как только результирующая таблица символов создана, она отправляется обратно для использования компилятором.
Основной процесс компиляции
Теперь, когда
PyAST_CompileObject()имеет состояние компилятора, таблицу символов и модуль в виде AST, можно начинать собственно компиляцию.Назначение основного компилятора состоит в том, чтобы:
- Преобразовать состояние, таблицу символов и AST в График потока управления (CFG)
- Защитите этап выполнения от исключений среды выполнения, перехватывая любые логические ошибки и ошибки кода и отображая их здесь
Вы можете вызвать компилятор CPython в коде Python, вызвав встроенную функцию
compile(). Она возвращает экземплярcode object:>>> compile('b+1', 'test.py', mode='eval') <code object <module> at 0x10f222780, file "test.py", line 1>Как и в случае с функцией
symtable(), простое выражение должно иметь значение'eval', а модуль, функция или класс должны иметь значение'exec'.Скомпилированный код можно найти в свойстве
co_codeобъекта code:>>> co.co_code b'e\x00d\x00\x17\x00S\x00'В стандартной библиотеке также есть модуль
dis, который разбирает инструкции байт-кода и может распечатать их на экране или выдать вам список экземпляровInstruction.Если вы импортируете
disи присваиваете функцииdis()свойствоco_codeобъекта кода, она разбирает его и печатает инструкции в REPL:>>> import dis >>> dis.dis(co.co_code) 0 LOAD_NAME 0 (0) 2 LOAD_CONST 0 (0) 4 BINARY_ADD 6 RETURN_VALUE
LOAD_NAME,LOAD_CONST,BINARY_ADD, иRETURN_VALUE- это все инструкции байт-кода. Они называются байт-кодом, потому что в двоичном виде они были длиной в байт. Однако, начиная с версии Python 3.6, формат хранения был изменен наword, так что теперь это технически текстовый код, а не байт-код.Полный список инструкций байт-кода доступен для каждой версии Python, и он меняется в зависимости от версии. Например, в Python 3.7 были введены некоторые новые инструкции байт-кода для ускорения выполнения определенных вызовов методов.
В предыдущем разделе мы рассматривали пакет
instaviz. Он включал визуализацию типа объекта кода с помощью запуска компилятора. Он также отображает операции с байт-кодом внутри объектов кода.Снова запустите instaviz, чтобы увидеть объект code и байт-код для функции, определенной в REPL:
>>> import instaviz >>> def example(): a = 1 b = a + 1 return b >>> instaviz.show(example)Если мы сейчас перейдем к
compiler_mod(), функция, используемая для переключения на различные функции компилятора в зависимости от типа модуля. Мы будем считать, чтоmod- этоModule. Модуль компилируется в состояние компилятора, а затемassemble()запускается для созданияPyCodeObject.Новый объект кода возвращается обратно в
PyAST_CompileObject()и отправляется на выполнение:static PyCodeObject * compiler_mod(struct compiler *c, mod_ty mod) { PyCodeObject *co; int addNone = 1; static PyObject *module; ... switch (mod->kind) { case Module_kind: if (!compiler_body(c, mod->v.Module.body)) { compiler_exit_scope(c); return 0; } break; case Interactive_kind: ... case Expression_kind: ... case Suite_kind: ... ... co = assemble(c, addNone); compiler_exit_scope(c); return co; }Функция
compiler_body()имеет некоторые флаги оптимизации, а затем выполняет цикл по каждому оператору в модуле и обращается к нему, аналогично тому, как работали функцииsymtable:static int compiler_body(struct compiler *c, asdl_seq *stmts) { int i = 0; stmt_ty st; PyObject *docstring; ... for (; i < asdl_seq_LEN(stmts); i++) VISIT(c, stmt, (stmt_ty)asdl_seq_GET(stmts, i)); return 1; }Тип инструкции определяется с помощью вызова функции
asdl_seq_GET(), которая определяет тип узла AST.С помощью некоторых интеллектуальных макросов
VISITвызывает функцию вPython/compile.cдля каждого типа инструкции:#define VISIT(C, TYPE, V) {\ if (!compiler_visit_ ## TYPE((C), (V))) \ return 0; \ }Для
stmt(категория для оператора) компилятор затем перейдет вcompiler_visit_stmt()и переключится на все возможные типы операторов, найденные вParser/Python.asdl:static int compiler_visit_stmt(struct compiler *c, stmt_ty s) { Py_ssize_t i, n; /* Always assign a lineno to the next instruction for a stmt. */ c->u->u_lineno = s->lineno; c->u->u_col_offset = s->col_offset; c->u->u_lineno_set = 0; switch (s->kind) { case FunctionDef_kind: return compiler_function(c, s, 0); case ClassDef_kind: return compiler_class(c, s); ... case For_kind: return compiler_for(c, s); ... } return 1; }В качестве примера давайте сосредоточимся на выражении
For, которое в Python выглядит так:for i in iterable: # block else: # optional if iterable is False # blockЕсли оператор имеет тип
For, он вызываетcompiler_for(). Существует эквивалентная функцияcompiler_*()для всех типов операторов и выражений. Более простые типы создают встроенные инструкции байт-кода, некоторые из более сложных типов операторов вызывают другие функции.Многие операторы могут иметь вложенные операторы. Цикл
forимеет тело, но вы также можете использовать сложные выражения в присваивании и итераторе.Инструкции компилятора
compiler_отправляют блоки в состояние компилятора. Эти блоки содержат инструкции, структура данных инструкции вPython/compile.cсодержит код операции, любые аргументы и целевой блок (если это инструкция перехода), он также содержит номер строки.Операторы перехода могут быть как абсолютными, так и относительными. Операторы перехода используются для “перехода” от одной операции к другой. Операторы абсолютного перехода указывают точный номер операции в скомпилированном объекте кода, тогда как операторы относительного перехода указывают цель перехода относительно другой операции:
struct instr { unsigned i_jabs : 1; unsigned i_jrel : 1; unsigned char i_opcode; int i_oparg; struct basicblock_ *i_target; /* target block (if jump instruction) */ int i_lineno; };Таким образом, блок фрейма (типа
basicblock) содержит следующие поля:
- Указатель
b_list, ссылка на список блоков для состояния компилятора- Список инструкций
b_instr, как с выделенным размером спискаb_ialloc, так и с используемым количествомb_iused- Следующий блок после этого
b_next- Был ли блок “замечен” ассемблером при прохождении в глубину
- Если в этом блоке есть
RETURN_VALUEкод операции (b_return)- Глубина стека на момент ввода этого блока (
b_startdepth)- Смещение инструкции для ассемблера
typedef struct basicblock_ { /* Each basicblock in a compilation unit is linked via b_list in the reverse order that the block are allocated. b_list points to the next block, not to be confused with b_next, which is next by control flow. */ struct basicblock_ *b_list; /* number of instructions used */ int b_iused; /* length of instruction array (b_instr) */ int b_ialloc; /* pointer to an array of instructions, initially NULL */ struct instr *b_instr; /* If b_next is non-NULL, it is a pointer to the next block reached by normal control flow. */ struct basicblock_ *b_next; /* b_seen is used to perform a DFS of basicblocks. */ unsigned b_seen : 1; /* b_return is true if a RETURN_VALUE opcode is inserted. */ unsigned b_return : 1; /* depth of stack upon entry of block, computed by stackdepth() */ int b_startdepth; /* instruction offset for block, computed by assemble_jump_offsets() */ int b_offset; } basicblock;Оператор
Forнаходится где-то посередине с точки зрения сложности. Компиляция инструкцииForс синтаксисомfor <target> in <iterator>:состоит из 15 шагов:
- Создаем новый блок кода с именем
start, при этом выделяется память и создается указательbasicblock- Создайте новый блок кода с именем
cleanup- Создайте новый блок кода с именем
end- Поместите блок фрейма типа
FOR_LOOPв стек сstartв качестве входного блока иendв качестве выходного блока- Перейдите к выражению итератора, которое добавляет любые операции для итератора
- Добавьте операцию
GET_ITERв состояние компилятора- Переключиться на
startблок- Вызов
ADDOP_JREL, который вызываетcompiler_addop_j()для добавления операцииFOR_ITERс аргументомcleanupблок- Зайдите в
targetи добавьте любой специальный код, например, распаковку кортежей, вstartблок- Просмотрите каждый оператор в теле цикла for
- Вызов
ADDOP_JABS, который вызываетcompiler_addop_j()для добавления операцииJUMP_ABSOLUTE, которая указывает, что после выполнения тела выполняется переход обратно к началу цикла- Перейти к блоку
cleanup- Удалить блок
FOR_LOOPфреймов из стека- Ознакомьтесь с инструкциями в разделе
elseцикла for- Используйте блок
endВозвращаясь к структуре
basicblock. Вы можете видеть, как при компиляции инструкции for создаются различные блоки и помещаются в блок фрейма и стек компилятора:static int compiler_for(struct compiler *c, stmt_ty s) { basicblock *start, *cleanup, *end; start = compiler_new_block(c); // 1. cleanup = compiler_new_block(c); // 2. end = compiler_new_block(c); // 3. if (start == NULL || end == NULL || cleanup == NULL) return 0; if (!compiler_push_fblock(c, FOR_LOOP, start, end)) // 4. return 0; VISIT(c, expr, s->v.For.iter); // 5. ADDOP(c, GET_ITER); // 6. compiler_use_next_block(c, start); // 7. ADDOP_JREL(c, FOR_ITER, cleanup); // 8. VISIT(c, expr, s->v.For.target); // 9. VISIT_SEQ(c, stmt, s->v.For.body); // 10. ADDOP_JABS(c, JUMP_ABSOLUTE, start); // 11. compiler_use_next_block(c, cleanup); // 12. compiler_pop_fblock(c, FOR_LOOP, start); // 13. VISIT_SEQ(c, stmt, s->v.For.orelse); // 14. compiler_use_next_block(c, end); // 15. return 1; }В зависимости от типа операции требуются различные аргументы. Например, здесь мы использовали
ADDOP_JABSиADDOP_JREL, которые относятся к “ДОБАВИТЬ O соединение с Jпереместить в относительнуюисходную позицию” и “ДОБАВИТЬ Oпереключение с Jна ABSв исходное положение”. Это относится к макросамAPPOP_JRELиADDOP_JABS, которые вызываютcompiler_addop_j(struct compiler *c, int opcode, basicblock *b, int absolute)и присваивают аргументуabsoluteзначения 0 и 1 соответственно.Есть некоторые другие макросы, как
ADDOP_Iзвонкиcompiler_addop_i()что добавить операцию с целочисленным аргументом, илиADDOP_Oзвонкиcompiler_addop_o()что добавляет работы сPyObjectаргумент.После завершения этих этапов компилятор получает список блоков фреймов, каждый из которых содержит список инструкций и указатель на следующий блок.
Сборка
В состоянии компилятора ассемблер выполняет “поиск в глубину” блоков и объединяет инструкции в единую последовательность байт-кода. Состояние ассемблера объявляется в
Python/compile.c:struct assembler { PyObject *a_bytecode; /* string containing bytecode */ int a_offset; /* offset into bytecode */ int a_nblocks; /* number of reachable blocks */ basicblock **a_postorder; /* list of blocks in dfs postorder */ PyObject *a_lnotab; /* string containing lnotab */ int a_lnotab_off; /* offset into lnotab */ int a_lineno; /* last lineno of emitted instruction */ int a_lineno_off; /* bytecode offset of last lineno */ };Функция
assemble()выполняет несколько задач:
- Вычислить количество блоков для выделения памяти
- Убедитесь, что каждый блок, который выпадает из конца, возвращает
None, вот почему каждая функция возвращаетNone, независимо от того, существует ли операторreturn- Разрешить все смещения операторов перехода, которые были помечены как относительные
- Вызовите
dfs(), чтобы выполнить поиск в глубину блоков- Передайте все инструкции компилятору
- Вызовите
makecode()с состоянием компилятора для генерацииPyCodeObjectstatic PyCodeObject * assemble(struct compiler *c, int addNone) { basicblock *b, *entryblock; struct assembler a; int i, j, nblocks; PyCodeObject *co = NULL; /* Make sure every block that falls off the end returns None. XXX NEXT_BLOCK() isn't quite right, because if the last block ends with a jump or return b_next shouldn't set. */ if (!c->u->u_curblock->b_return) { NEXT_BLOCK(c); if (addNone) ADDOP_LOAD_CONST(c, Py_None); ADDOP(c, RETURN_VALUE); } ... dfs(c, entryblock, &a, nblocks); /* Can't modify the bytecode after computing jump offsets. */ assemble_jump_offsets(&a, c); /* Emit code in reverse postorder from dfs. */ for (i = a.a_nblocks - 1; i >= 0; i--) { b = a.a_postorder[i]; for (j = 0; j < b->b_iused; j++) if (!assemble_emit(&a, &b->b_instr[j])) goto error; } ... co = makecode(c, &a); error: assemble_free(&a); return co; }Поиск в глубину выполняется функцией
dfs()вPython/compile.c, которая следует за указателямиb_nextв каждом из блоков помечает их как видимые, переключаяb_seen, а затем добавляет их в список ассемблеров**a_postorderв обратном порядке.Функция выполняет обратный цикл по списку последующих заказов ассемблера и для каждого блока, если в нем есть операция перехода, рекурсивно вызывает
dfs()для этого перехода:static void dfs(struct compiler *c, basicblock *b, struct assembler *a, int end) { int i, j; /* Get rid of recursion for normal control flow. Since the number of blocks is limited, unused space in a_postorder (from a_nblocks to end) can be used as a stack for still not ordered blocks. */ for (j = end; b && !b->b_seen; b = b->b_next) { b->b_seen = 1; assert(a->a_nblocks < j); a->a_postorder[--j] = b; } while (j < end) { b = a->a_postorder[j++]; for (i = 0; i < b->b_iused; i++) { struct instr *instr = &b->b_instr[i]; if (instr->i_jrel || instr->i_jabs) dfs(c, instr->i_target, a, j); } assert(a->a_nblocks < j); a->a_postorder[a->a_nblocks++] = b; } }Создание объекта кода
Задача
makecode()состоит в том, чтобы просмотреть состояние компилятора, некоторые свойства ассемблера и преобразовать их вPyCodeObject, вызвавPyCode_New():
Имена переменных, константы присваиваются объекту кода в качестве свойств:
static PyCodeObject * makecode(struct compiler *c, struct assembler *a) { ... consts = consts_dict_keys_inorder(c->u->u_consts); names = dict_keys_inorder(c->u->u_names, 0); varnames = dict_keys_inorder(c->u->u_varnames, 0); ... cellvars = dict_keys_inorder(c->u->u_cellvars, 0); ... freevars = dict_keys_inorder(c->u->u_freevars, PyTuple_GET_SIZE(cellvars)); ... flags = compute_code_flags(c); if (flags < 0) goto error; bytecode = PyCode_Optimize(a->a_bytecode, consts, names, a->a_lnotab); ... co = PyCode_NewWithPosOnlyArgs(posonlyargcount+posorkeywordargcount, posonlyargcount, kwonlyargcount, nlocals_int, maxdepth, flags, bytecode, consts, names, varnames, freevars, cellvars, c->c_filename, c->u->u_name, c->u->u_firstlineno, a->a_lnotab); ... return co; }Вы также можете заметить, что байт-код отправляется на
PyCode_Optimize(), прежде чем он будет отправлен наPyCode_NewWithPosOnlyArgs(). Эта функция является частью процесса оптимизации байт-кода вPython/peephole.c.Оптимизатор peephole выполняет инструкции байт-кода и в определенных сценариях заменяет их другими инструкциями. Например, существует оптимизатор под названием “constant unfolding”, поэтому, если вы введете в свой скрипт следующую инструкцию:
a = 1 + 5Это оптимизирует его до:
a = 6Поскольку 1 и 5 являются постоянными значениями, результат всегда должен быть одинаковым.
Заключение
Мы можем объединить все эти этапы с помощью модуля instaviz:
import instaviz def foo(): a = 2**4 b = 1 + 5 c = [1, 4, 6] for i in c: print(i) else: print(a) return c instaviz.show(foo)Создаст AST-график:
С последовательными инструкциями байт-кода:
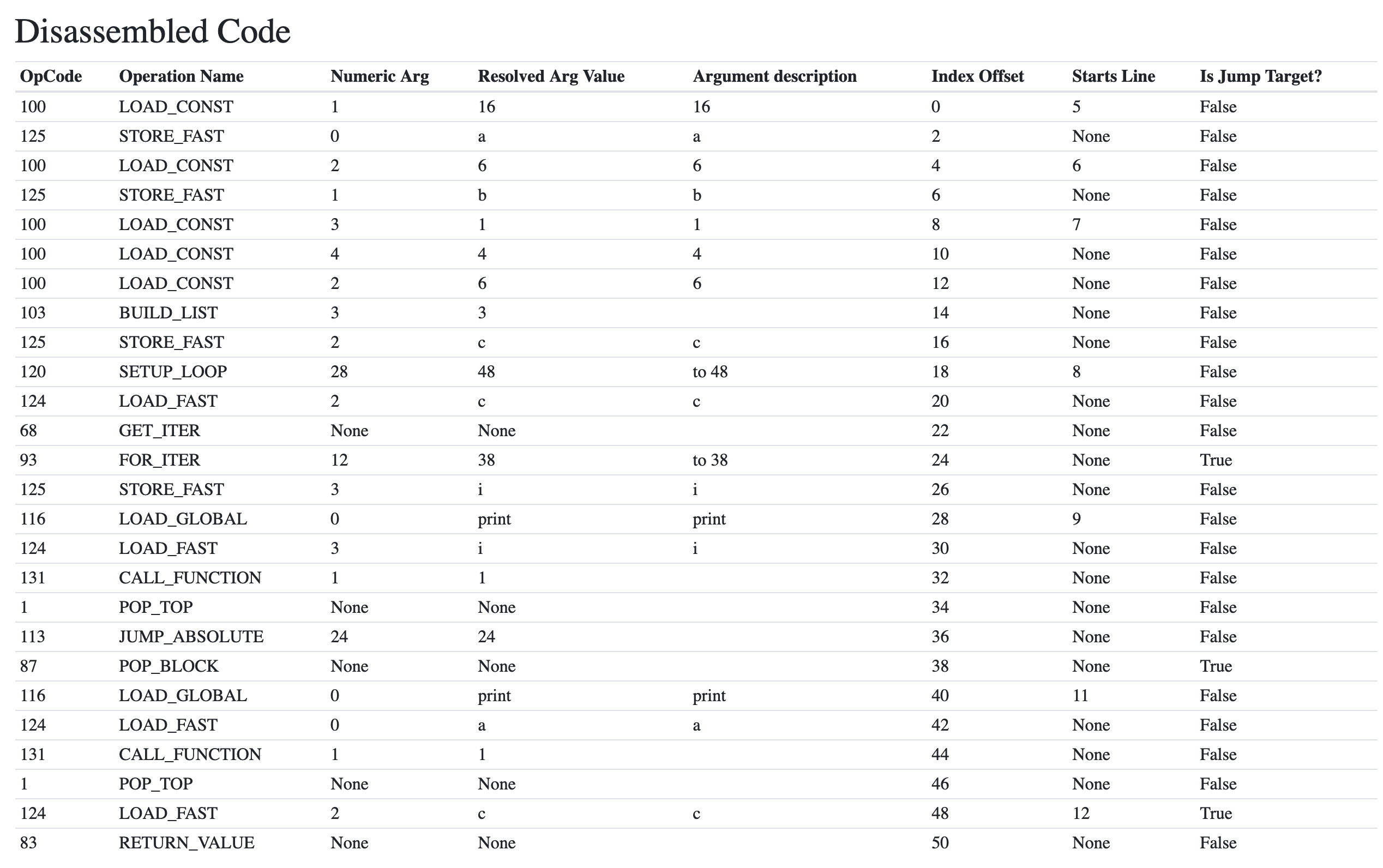
Кроме того, объект кода с именами переменных, константами и двоичным кодом
co_code:
Выполнение
В
Python/pythonrun.cмы вырвались как раз перед звонком вrun_eval_code_obj().Этот вызов принимает объект кода, либо извлеченный из маршалированного файла
.pyc, либо скомпилированный на этапах AST и компиляции.
run_eval_code_obj()будут переданы глобальные значения, локальные значения,PyArenaи скомпилированныеPyCodeObjectвPyEval_EvalCode()вPython/ceval.c.Этот этап формирует компонент выполнения CPython. Каждая из операций с байт-кодом берется и выполняется с использованием системы, основанной на “стековом фрейме”..
Что такое стековый фрейм?
Стековые фреймы - это тип данных, используемый во многих средах выполнения, не только в Python, который позволяет вызывать функции и возвращать переменные между функциями. Стековые фреймы также содержат аргументы, локальные переменные и другую информацию о состоянии.
Обычно для каждого вызова функции существует стек фреймов, и они складываются последовательно. Вы можете видеть стек фреймов CPython в любое время, когда исключение не обрабатывается и стек выводится на экран.
PyEval_EvalCode()это общедоступный API для оценки объекта кода. Логика для вычисления разделена между_PyEval_EvalCodeWithName()и_PyEval_EvalFrameDefault(),, которые оба находятся вceval.c.Общедоступный API
PyEval_EvalCode()создаст фрейм выполнения из верхней части стека, вызвав_PyEval_EvalCodeWithName().Построение первого фрейма выполнения состоит из нескольких этапов:
- Ключевые слова и позиционные аргументы разрешены.
- Использование символов
*argsи**kwargsв определениях функций разрешено.- Аргументы добавляются в область видимости в виде локальных переменных.
- Создаются совместные программы и Генераторы, включая асинхронные генераторы.
Объект frame выглядит следующим образом:

Давайте пройдемся по этим последовательностям.
1. Построение состояния потока
Прежде чем фрейм может быть выполнен, на него должна быть ссылка из потока. В CPython может одновременно выполняться множество потоков в рамках одного интерпретатора. Состояние интерпретатора включает список этих потоков в виде связанного списка. Структура thread называется
PyThreadState, и на нее имеется множество ссылокceval.c.Вот структура объекта состояния потока:

2. Построение фреймов
Входные данные для
PyEval_EvalCode()и, следовательно,_PyEval_EvalCodeWithName()содержат аргументы для:
_co: аPyCodeObjectglobals: aPyDictс именами переменных в качестве ключей и их значениямиlocals: aPyDictс именами переменных в качестве ключей и их значениямиОстальные аргументы являются необязательными и не используются для базового API:
args: aPyTupleсо значениями позиционных аргументов по порядку иargcountдля количества значенийkwnames: список имен аргументов ключевых словkwargs: список значений аргумента ключевого слова иkwcountдля их количестваdefs: список значений по умолчанию для позиционных аргументов иdefcountдля длиныkwdefs: словарь со значениями по умолчанию для аргументов ключевых словclosure: кортеж со строками для объединения в поле объекты кодаco_freevarsname: имя для этого вычислительного оператора в виде строкиqualname: полное имя для этого вычислительного оператора в виде строкиPyObject * _PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals, PyObject *const *args, Py_ssize_t argcount, PyObject *const *kwnames, PyObject *const *kwargs, Py_ssize_t kwcount, int kwstep, PyObject *const *defs, Py_ssize_t defcount, PyObject *kwdefs, PyObject *closure, PyObject *name, PyObject *qualname) { ... PyThreadState *tstate = _PyThreadState_GET(); assert(tstate != NULL); if (globals == NULL) { _PyErr_SetString(tstate, PyExc_SystemError, "PyEval_EvalCodeEx: NULL globals"); return NULL; } /* Create the frame */ f = _PyFrame_New_NoTrack(tstate, co, globals, locals); if (f == NULL) { return NULL; } fastlocals = f->f_localsplus; freevars = f->f_localsplus + co->co_nlocals;3. Преобразование параметров ключевых слов в словарь
Если определение функции содержит общий стиль
**kwargsдля аргументов ключевого слова, то создается новый словарь, и значения копируются в него. Затем имяkwargsустанавливается в качестве переменной, как в этом примере:def example(arg, arg2=None, **kwargs): print(kwargs['extra']) # this would resolve to a dictionary keyЛогика создания словаря аргументов ключевых слов приведена в следующей части _PyEval_EvalCodeWithName():
/* Create a dictionary for keyword parameters (**kwargs) */ if (co->co_flags & CO_VARKEYWORDS) { kwdict = PyDict_New(); if (kwdict == NULL) goto fail; i = total_args; if (co->co_flags & CO_VARARGS) { i++; } SETLOCAL(i, kwdict); } else { kwdict = NULL; }Переменная
kwdictбудет ссылаться наPyDictObject, если были найдены какие-либо аргументы ключевого слова.4. Преобразование Позиционных Аргументов В Переменные
Далее каждый из позиционных аргументов (если он указан) задается как локальная переменная:
/* Copy all positional arguments into local variables */ if (argcount > co->co_argcount) { n = co->co_argcount; } else { n = argcount; } for (j = 0; j < n; j++) { x = args[j]; Py_INCREF(x); SETLOCAL(j, x); }В конце цикла вы увидите вызов функции
SETLOCAL()со значением, поэтому, если позиционный аргумент определен со значением, которое доступно в пределах этой области:def example(arg1, arg2): print(arg1, arg2) # both args are already local variables.Кроме того, счетчик ссылок для этих переменных увеличивается, поэтому сборщик мусора не удалит их до тех пор, пока фрейм не будет обработан.
5. Упаковка Позиционных Аргументов в
*argsАналогично
**kwargs, аргумент функции, перед которым стоит*, может быть настроен так, чтобы перехватывать все остальные позиционные аргументы. Этот аргумент представляет собой кортеж, а имя*argsзадается как локальная переменная:/* Pack other positional arguments into the *args argument */ if (co->co_flags & CO_VARARGS) { u = _PyTuple_FromArray(args + n, argcount - n); if (u == NULL) { goto fail; } SETLOCAL(total_args, u); }6. Загрузка аргументов ключевого слова
Если функция была вызвана с аргументами и значениями по ключевым словам, словарь
kwdict, созданный на шаге 4, теперь заполняется всеми оставшимися аргументами по ключевым словам, переданными вызывающей стороной, которые не преобразуются в именованные аргументы или позиционные аргументы.Например, аргумент
eне был ни позиционным, ни именованным, поэтому он добавляется в**remaining:>>> def my_function(a, b, c=None, d=None, **remaining): print(a, b, c, d, remaining) >>> my_function(a=1, b=2, c=3, d=4, e=5) (1, 2, 3, 4, {'e': 5})Позиционные аргументы - это новая функция в Python 3.8. Введенная в PEP570, позиционные аргументы являются способом остановки пользователям вашего API запрещается использовать позиционные аргументы с синтаксисом ключевых слов.
Например, эта простая функция преобразует градус Фаренгейта в градус Цельсия. Обратите внимание, что использование
/в качестве специального аргумента отделяет аргументы, относящиеся только к позиции, от других аргументов.def to_celcius(farenheit, /, options=None): return (farenheit-31)*5/9Все аргументы слева от
/должны вызываться только как позиционные аргументы, а аргументы справа могут вызываться как позиционные аргументы, так и аргументы ключевого слова:>>> to_celcius(110)Вызов функции с использованием аргумента ключевого слова для аргумента, содержащего только позиционные значения, вызовет
TypeError:>>> to_celcius(farenheit=110) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: to_celcius() got some positional-only arguments passed as keyword arguments: 'farenheit'Определение значений словаря аргументов ключевого слова выполняется после распаковки всех остальных аргументов. Аргументы PEP570, содержащие только позиционные значения, отображаются при запуске цикла аргументов ключевого слова с
co_posonlyargcount. Если бы в третьем аргументе использовался символ/, значениеco_posonlyargcountбыло бы2.PyDict_SetItem()вызывается для каждого оставшегося аргумента, чтобы добавить его в словарьlocals, поэтому при выполнении каждый из аргументов ключевого слова является локальной переменной с областью действия:for (i = 0; i < kwcount; i += kwstep) { PyObject **co_varnames; PyObject *keyword = kwnames[i]; PyObject *value = kwargs[i]; ... /* Speed hack: do raw pointer compares. As names are normally interned this should almost always hit. */ co_varnames = ((PyTupleObject *)(co->co_varnames))->ob_item; for (j = co->co_posonlyargcount; j < total_args; j++) { PyObject *name = co_varnames[j]; if (name == keyword) { goto kw_found; } } if (kwdict == NULL) { if (co->co_posonlyargcount && positional_only_passed_as_keyword(tstate, co, kwcount, kwnames)) { goto fail; } _PyErr_Format(tstate, PyExc_TypeError, "%U() got an unexpected keyword argument '%S'", co->co_name, keyword); goto fail; } if (PyDict_SetItem(kwdict, keyword, value) == -1) { goto fail; } continue; kw_found: ... Py_INCREF(value); SETLOCAL(j, value); } ...В конце цикла вы увидите вызов функции
SETLOCAL()со значением. Если аргумент ключевого слова определен со значением, которое доступно в этой области:def example(arg1, arg2, example_kwarg=None): print(example_kwarg) # example_kwarg is already a local variable.7. Добавление пропущенных позиционных аргументов
Любые позиционные аргументы, предоставленные для вызова функции, которых нет в списке позиционных аргументов, добавляются в кортеж
*argsесли этот кортеж не существует, возникает ошибка:/* Add missing positional arguments (copy default values from defs) */ if (argcount < co->co_argcount) { Py_ssize_t m = co->co_argcount - defcount; Py_ssize_t missing = 0; for (i = argcount; i < m; i++) { if (GETLOCAL(i) == NULL) { missing++; } } if (missing) { missing_arguments(co, missing, defcount, fastlocals); goto fail; } if (n > m) i = n - m; else i = 0; for (; i < defcount; i++) { if (GETLOCAL(m+i) == NULL) { PyObject *def = defs[i]; Py_INCREF(def); SETLOCAL(m+i, def); } } }8. Добавление пропущенных аргументов ключевого слова
Все аргументы ключевого слова, предоставленные для вызова функции, которых нет в списке именованных аргументов ключевого слова, добавляются в словарь
**kwargsесли этот словарь не существует, возникает ошибка:/* Add missing keyword arguments (copy default values from kwdefs) */ if (co->co_kwonlyargcount > 0) { Py_ssize_t missing = 0; for (i = co->co_argcount; i < total_args; i++) { PyObject *name; if (GETLOCAL(i) != NULL) continue; name = PyTuple_GET_ITEM(co->co_varnames, i); if (kwdefs != NULL) { PyObject *def = PyDict_GetItemWithError(kwdefs, name); ... } missing++; } ... }9. Сворачивающиеся затворы
Любые имена замыканий добавляются в список свободных имен переменных объекта code:
/* Copy closure variables to free variables */ for (i = 0; i < PyTuple_GET_SIZE(co->co_freevars); ++i) { PyObject *o = PyTuple_GET_ITEM(closure, i); Py_INCREF(o); freevars[PyTuple_GET_SIZE(co->co_cellvars) + i] = o; }10. Создание генераторов, сопрограмм и асинхронных генераторов
Если вычисляемый объект кода имеет флаг, указывающий на то, что он является генератором, сопрограммой или асинхронным генератором, то новый фрейм создается с использованием одного из уникальных методов в библиотеке генератора, сопрограммы или асинхронной библиотеки и текущий кадр добавляется как свойство.
Затем возвращается новый кадр, а исходный кадр не вычисляется. Кадр вычисляется только тогда, когда вызывается генератор/сопрограмма/асинхронный метод для выполнения своей цели:
/* Handle generator/coroutine/asynchronous generator */ if (co->co_flags & (CO_GENERATOR | CO_COROUTINE | CO_ASYNC_GENERATOR)) { ... /* Create a new generator that owns the ready to run frame * and return that as the value. */ if (is_coro) { gen = PyCoro_New(f, name, qualname); } else if (co->co_flags & CO_ASYNC_GENERATOR) { gen = PyAsyncGen_New(f, name, qualname); } else { gen = PyGen_NewWithQualName(f, name, qualname); } ... return gen; }Наконец,
PyEval_EvalFrameEx()вызывается с новым фреймом:retval = PyEval_EvalFrameEx(f,0); ... }Выполнение кадра
Как уже говорилось ранее в главах о компиляторе и AST, объект code содержит двоичную кодировку байт-кода, который должен быть выполнен. Он также содержит список переменных и таблицу символов.
Локальные и глобальные переменные определяются во время выполнения на основе того, как была вызвана данная функция, модуль или блок. Эта информация добавляется во фрейм с помощью функции
_PyEval_EvalCodeWithName(). Существуют и другие способы использования фреймов, например, сопрограмма decorator, которая динамически генерирует фрейм с целью в качестве переменной.Общедоступный API,
PyEval_EvalFrameEx()вызывает настроенную интерпретатором функцию оценки фреймов в свойствеeval_frame. Оценка фреймов была доступна для подключения в Python 3.7 с помощью PEP 523.
_PyEval_EvalFrameDefault()это функция по умолчанию, и использовать что-либо, кроме нее, необычно.Фреймы выполняются в основном цикле выполнения внутри
_PyEval_EvalFrameDefault(). Эта функция является центральной функцией, которая объединяет все вместе и оживляет ваш код. В нем содержатся результаты многолетней оптимизации, поскольку даже одна строка кода может оказать значительное влияние на производительность всего CPython.Все, что выполняется в CPython, проходит через эту функцию.
Примечание: При чтении
ceval.cвы можете заметить, сколько раз использовались макросы на языке Си. Макросы C - это способ создания кода, совместимого с DRY, без дополнительных затрат на выполнение вызовов функций. Компилятор преобразует макросы в код C и затем компилирует сгенерированный код.Если вы хотите увидеть расширенный код, вы можете запустить
gcc -Eв Linux и macOS:$ gcc -E Python/ceval.cКроме того, Visual Studio Code может выполнять встроенное расширение макроса после установки официального расширения C/C++:
Мы можем пошагово выполнить выполнение фрейма в Python 3.7 и более поздних версиях, включив атрибут трассировки в текущем потоке.
В этом примере кода функция глобальной трассировки преобразуется в функцию с именем
trace(), которая получает стек из текущего кадра, выводит на экран разобранные коды операций и некоторую дополнительную информацию для отладки:import sys import dis import traceback import io def trace(frame, event, args): frame.f_trace_opcodes = True stack = traceback.extract_stack(frame) pad = " "*len(stack) + "|" if event == 'opcode': with io.StringIO() as out: dis.disco(frame.f_code, frame.f_lasti, file=out) lines = out.getvalue().split('\n') [print(f"{pad}{l}") for l in lines] elif event == 'call': print(f"{pad}Calling {frame.f_code}") elif event == 'return': print(f"{pad}Returning {args}") elif event == 'line': print(f"{pad}Changing line to {frame.f_lineno}") else: print(f"{pad}{frame} ({event} - {args})") print(f"{pad}----------------------------------") return trace sys.settrace(trace) # Run some code for a demo eval('"-".join([letter for letter in "hello"])')При этом выводится код внутри каждого стека, который указывает на следующую операцию перед ее выполнением. Когда фрейм возвращает значение, выводится оператор return:
Полный список инструкций доступен в документации по модулю
dis.Стек значений
Внутри основного цикла вычисления создается стек значений. Этот стек представляет собой список указателей на последовательные экземпляры
PyObject.Можно представить себе набор значений как деревянный столбик, на который можно складывать цилиндры. Вы можете добавлять или удалять только один элемент за раз. Это делается с помощью макроса
PUSH(a), гдеa- указатель наPyObject.Например, если вы создали
PyLongсо значением 10 и поместили его в стек значений:PyObject *a = PyLong_FromLong(10); PUSH(a);Это действие привело бы к следующему результату:
В следующей операции, чтобы извлечь это значение, вы должны использовать макрос
POP(), чтобы взять верхнее значение из стека:PyObject *a = POP(); // a is PyLongObject with a value of 10Это действие вернет верхнее значение и приведет к пустому стеку значений:
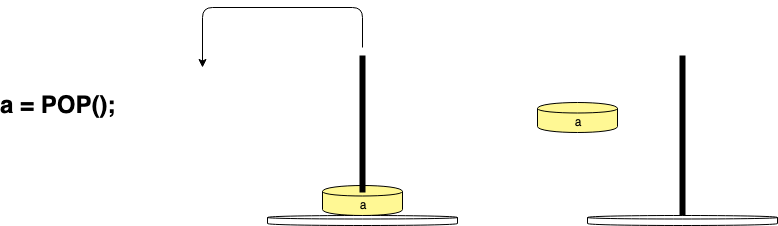
Если бы вы добавили в стек 2 значения:
PyObject *a = PyLong_FromLong(10); PyObject *b = PyLong_FromLong(20); PUSH(a); PUSH(b);Они будут располагаться в том порядке, в котором они были добавлены, поэтому
aбудет перемещен на вторую позицию в стеке: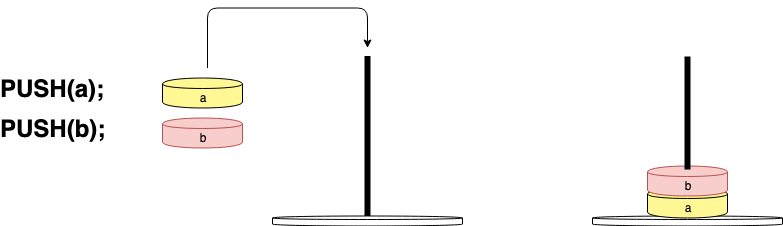
Если бы вам нужно было получить верхнее значение в стеке, вы бы получили указатель на
b, потому что оно находится вверху: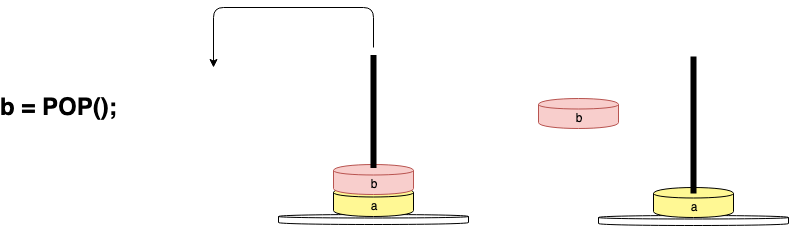
Если вам нужно извлечь указатель на верхнее значение в стеке, не извлекая его, вы можете использовать операцию
PEEK(v), гдеv- это позиция в стеке:PyObject *first = PEEK(0);0 представляет собой вершину стека, 1 будет второй позицией:
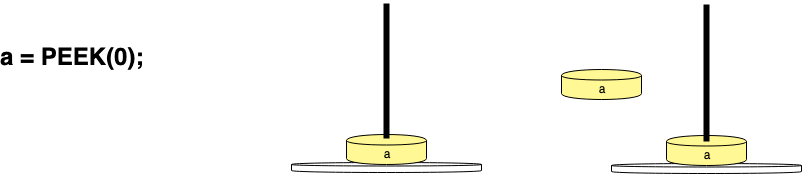
Чтобы клонировать значение в верхней части стека, можно использовать макрос
DUP_TWO()или использовать код операцииDUP_TWO:DUP_TOP();Это действие скопирует значение вверху, чтобы сформировать 2 указателя на один и тот же объект:

Существует макрос поворота
ROT_TWO, который меняет местами первое и второе значения:
Каждый из кодов операции имеет предопределенный “эффект стека”, вычисляемый с помощью функции
stack_effect()внутриPython/compile.c. Эта функция возвращает разницу в количестве значений внутри стека для каждого кода операции.Пример: Добавление элемента в список
В Python, когда вы создаете список, для объекта list доступен метод
.append():my_list = [] my_list.append(obj)Где
obj- это объект, который вы хотите добавить в конец списка.В этой операции участвуют 2 операции.
LOAD_FAST, чтобы загрузить объектobjв верхнюю часть стека значений из спискаlocalsво фрейме, иLIST_APPENDчтобы добавить объект.Первое знакомство с
LOAD_FASTсостоит из 5 шагов:
Указатель на
objзагружается изGETLOCAL(), где загружаемая переменная является аргументом операции. Список указателей на переменные хранится вfastlocals, который является копией атрибута PyFramef_localsplus. Аргументом операции является число, указывающее на индекс в указателе массиваfastlocals. Это означает, что загрузка локального файла - это просто копия указателя вместо того, чтобы искать имя переменной.Если переменная больше не существует, возникает ошибка несвязанной локальной переменной.
Значение счетчика ссылок для
value(в нашем случае,obj) увеличивается на 1.Указатель на
objперемещается в верхнюю часть стека значений.Вызывается макрос
FAST_DISPATCH, если трассировка включена, цикл повторяется снова (со всей трассировкой), если трассировка не включена, вызываетсяgotoдляfast_next_opcode, который возвращается к началу цикла для выполнения следующей инструкции.... case TARGET(LOAD_FAST): { PyObject *value = GETLOCAL(oparg); // 1. if (value == NULL) { format_exc_check_arg( PyExc_UnboundLocalError, UNBOUNDLOCAL_ERROR_MSG, PyTuple_GetItem(co->co_varnames, oparg)); goto error; // 2. } Py_INCREF(value); // 3. PUSH(value); // 4. FAST_DISPATCH(); // 5. } ...Теперь указатель на
objнаходится в верхней части стека значений. Выполняется следующая командаLIST_APPEND.Многие операции с байт-кодом ссылаются на базовые типы, такие как PyUnicode, PyNumber. Например,
LIST_APPENDдобавляет объект в конец списка. Для достижения этой цели он извлекает указатель из стека значений и возвращает указатель на последний объект в стеке. Макрос является сокращением для:PyObject *v = (*--stack_pointer);Теперь указатель на
objсохраняется какv. Указатель на список загружается изPEEK(oparg).Затем вызывается C API для списков Python для
listиv. Код для этого находится внутриObjects/listobject.c, к которому мы перейдем в следующей главе.Выполняется вызов
PREDICT, который предполагает, что следующей операцией будетJUMP_ABSOLUTE. МакросPREDICTсодержит сгенерированные компиляторомgotoинструкции для каждой изcaseинструкций потенциальных операций. Это означает, что центральный процессор может перейти к этой инструкции и ему не придется снова проходить цикл:... case TARGET(LIST_APPEND): { PyObject *v = POP(); PyObject *list = PEEK(oparg); int err; err = PyList_Append(list, v); Py_DECREF(v); if (err != 0) goto error; PREDICT(JUMP_ABSOLUTE); DISPATCH(); } ...Предсказания кода операции: Некоторые коды операций, как правило, выполняются парами, что позволяет предсказать второй код при запуске первого. Например, за
COMPARE_OPчасто следуетPOP_JUMP_IF_FALSEилиPOP_JUMP_IF_TRUE.“Проверка предсказания требует однократной высокоскоростной проверки регистровой переменной на соответствие константе. Если сопряжение было выполнено правильно, то с высокой вероятностью успеха предикция собственной внутренней ветви процессора имеет высокую вероятность успеха, что приводит к переходу к следующему коду операции практически без дополнительных затрат. Успешное предсказание избавляет от необходимости проходить цикл eval, включая его непредсказуемую ветвь переключения. В сочетании с внутренним предсказанием ветвлений процессора успешное предсказание приводит к тому, что два кода операции выполняются так, как если бы они были одним новым кодом операции с объединенными элементами”.
При сборе статистики по кодам операций у вас есть два варианта:
- Сохраняйте предсказания включенными и интерпретируйте результаты так, как если бы некоторые коды операций были объединены
- Отключите предсказания, чтобы счетчик частоты кодов операций обновлялся для обоих кодов операций
Предсказание кода операции отключено в потоковом коде, поскольку последний позволяет процессору записывать отдельную информацию о предсказании ветвления для каждого кода операции.
Некоторые операции, такие как
CALL_FUNCTION,CALL_METHOD,, содержат аргумент operation, ссылающийся на другую скомпилированную функцию. В этих случаях другой кадр помещается в стек кадров в потоке, и цикл вычисления выполняется для этой функции до тех пор, пока функция не завершится. Каждый раз, когда создается новый кадр и помещается в стек, значениеf_backэтого кадра устанавливается равным текущему кадру перед созданием нового.Это вложение фреймов становится очевидным, когда вы видите трассировку стека, возьмем этот пример сценария:
def function2(): raise RuntimeError def function1(): function2() if __name__ == '__main__': function1()Вызов этого параметра в командной строке даст вам:
$ ./python.exe example_stack.py Traceback (most recent call last): File "example_stack.py", line 8, in <module> function1() File "example_stack.py", line 5, in function1 function2() File "example_stack.py", line 2, in function2 raise RuntimeError RuntimeErrorВ
traceback.pyфункцияwalk_stack(), используемая для печати обратной трассировки:def walk_stack(f): """Walk a stack yielding the frame and line number for each frame. This will follow f.f_back from the given frame. If no frame is given, the current stack is used. Usually used with StackSummary.extract. """ if f is None: f = sys._getframe().f_back.f_back while f is not None: yield f, f.f_lineno f = f.f_backЗдесь вы можете видеть, что текущий кадр, выбранный при вызове
sys._getframe(), и родительский элемент родительского элемента устанавливается в качестве кадра, потому что вы не хотите видеть вызовwalk_stack()илиprint_trace()при обратной трассировке, таким образом, эти функциональные фреймы пропускаются.Затем указатель
f_backперемещается наверх.
sys._getframe()это API Python для получения атрибутаframeтекущего потока.Вот как этот стек кадров будет выглядеть визуально, с 3 кадрами, каждый со своим объектом кода и состоянием потока, указывающим на текущий кадр:
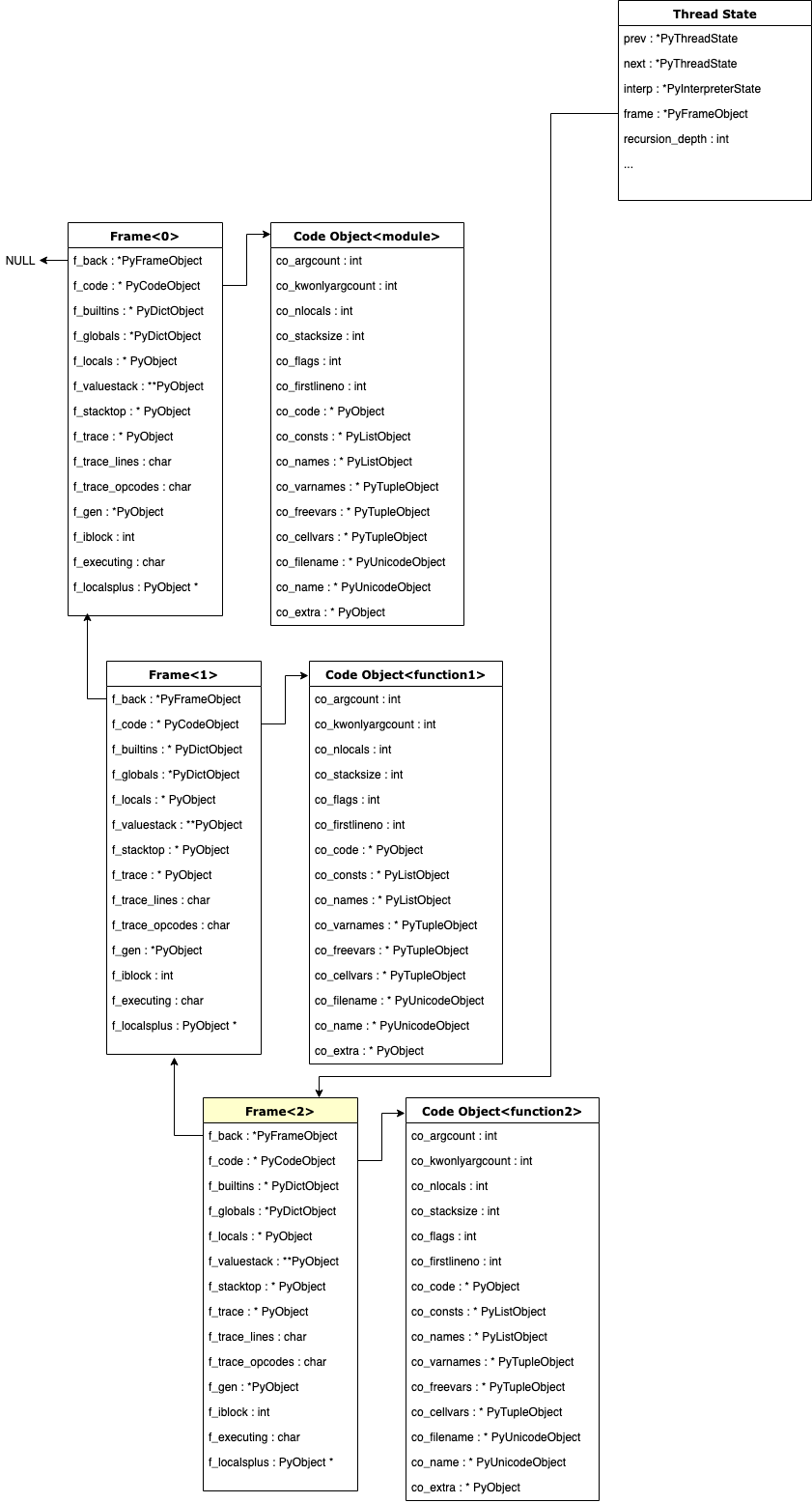
Заключение
В этой части вы изучили самый сложный элемент CPython: компилятор. Первоначальный автор Python, Гвидо ван Россум, сделал заявление, что компилятор CPython должен быть “тупым”, чтобы люди могли его понять.
Разбив процесс компиляции на небольшие логические этапы, его гораздо легче понять.
В следующей главе мы свяжем процесс компиляции с основой всего кода на Python, с
object.Часть 4: Объекты в CPython
CPython поставляется с набором базовых типов, таких как строки, списки, кортежи, словари и объекты.
Все эти типы являются встроенными. Вам не нужно импортировать какие-либо библиотеки, даже из стандартной библиотеки. Кроме того, для создания экземпляров этих встроенных типов есть несколько удобных ярлыков.
Например, чтобы создать новый список, вы можете вызвать:
lst = list()Или вы можете использовать квадратные скобки:
lst = []Строки могут быть созданы из строкового литерала с помощью двойных или одинарных кавычек. Ранее мы рассмотрели определения грамматики, которые заставляют компилятор интерпретировать двойные кавычки как строковый литерал.
Все типы в Python наследуются от
object, встроенного базового типа. Даже строки, кортежи и списки наследуются отobject. Во время ознакомления с кодом на C вы прочитали множество ссылок наPyObject*, структуру C-API дляobject.Поскольку C не является объектно-ориентированным , как Python, объекты в C не наследуются друг от друга.
PyObject- это структура данных для начала описания объекта Python. память.Большая часть API базового объекта объявлена в
Objects/object.c, как и функцияPyObject_Repr,, которая является встроенной функциейrepr(). Вы также найдетеPyObject_Hash()и другие API-интерфейсы.Все эти функции могут быть переопределены в пользовательском объекте путем реализации методов “dunder” в объекте Python:
class MyObject(object): def __init__(self, id, name): self.id = id self.name = name def __repr__(self): return "<{0} id={1}>".format(self.name, self.id)Этот код реализован в
PyObject_Repr(), insideObjects/object.c. Тип целевого объектаvбудет определен с помощью вызова функцииPy_TYPE(), и если задано полеtp_repr, то вызывается указатель на функцию . Если полеtp_reprне задано, т.е. объект не объявляет пользовательский метод__repr__, то выполняется поведение по умолчанию, которое заключается в возврате"<%s object at %p>"с именем типа и идентификатором:PyObject * PyObject_Repr(PyObject *v) { PyObject *res; if (PyErr_CheckSignals()) return NULL; ... if (v == NULL) return PyUnicode_FromString("<NULL>"); if (Py_TYPE(v)->tp_repr == NULL) return PyUnicode_FromFormat("<%s object at %p>", v->ob_type->tp_name, v); ... }Поле ob_type для данного
PyObject*будет указывать на структуру данныхPyTypeObject, определенную вInclude/cpython/object.h. В этой структуре данных перечислены все встроенные функции в виде полей и аргументов, которые они должны получать.Возьмем
tp_reprв качестве примера:typedef struct _typeobject { PyObject_VAR_HEAD const char *tp_name; /* For printing, in format "<module>.<name>" */ Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation */ /* Methods to implement standard operations */ ... reprfunc tp_repr;, где
reprfunc- этоtypedefдляPyObject *(*reprfunc)(PyObject *);, функция, которая принимает 1 указатель наPyObject(self).Некоторые API-интерфейсы dunder являются необязательными, поскольку они применяются только к определенным типам, таким как numbers:
/* Method suites for standard classes */ PyNumberMethods *tp_as_number; PySequenceMethods *tp_as_sequence; PyMappingMethods *tp_as_mapping;Последовательность, подобная списку, могла бы реализовывать следующие методы:
typedef struct { lenfunc sq_length; // len(v) binaryfunc sq_concat; // v + x ssizeargfunc sq_repeat; // for x in v ssizeargfunc sq_item; // v[x] void *was_sq_slice; // v[x:y:z] ssizeobjargproc sq_ass_item; // v[x] = z void *was_sq_ass_slice; // v[x:y] = z objobjproc sq_contains; // x in v binaryfunc sq_inplace_concat; ssizeargfunc sq_inplace_repeat; } PySequenceMethods;Все эти встроенные функции называются Моделью данных Python. Одним из замечательных источников по модели данных Python является “Fluent Python” Лучано Рамальо.
Базовый тип объекта
В
Objects/object.cбазовая реализация типаobjectнаписана в виде чистого кода на C. Есть несколько конкретных реализаций базовой логики, таких как поверхностные сравнения.Не все методы в объекте Python являются частью модели данных, поэтому объект Python может содержать атрибуты (атрибуты класса или экземпляра) и методы.
Простой способ представить объект Python состоит из 2 элементов:
- Основная модель данных с указателями на скомпилированные функции
- Словарь с любыми пользовательскими атрибутами и методами
Основная модель данных определена в
PyTypeObject, а функции определены в:
Objects/object.cдля встроенных методовObjects/boolobject.cдляboolвведитеObjects/bytearrayobject.cдляbyte[]введитеObjects/bytesobjects.cдляbytesвведитеObjects/cellobject.cдляcellвведитеObjects/classobject.cдля абстрактного типаclass, используемого в метапрограммированииObjects/codeobject.cиспользуется для встроенногоcodeобъекта типаObjects/complexobject.cдля сложного числового типаObjects/iterobject.cдля итератораObjects/listobject.cдляlistвведитеObjects/longobject.cдляlongчислового типаObjects/memoryobject.cдля базового типа памятиObjects/methodobject.cдля метода классаObjects/moduleobject.cдля типа модуляObjects/namespaceobject.cдля типа пространства именObjects/odictobject.cдля упорядоченного словаря введитеObjects/rangeobject.cдля генератора диапазоновObjects/setobject.cдля типаsetObjects/sliceobject.cдля ссылочного типа фрагментаObjects/structseq.cдля параметраstruct.StructвведитеObjects/tupleobject.cдляtupleвведитеObjects/typeobject.cдляtypeвведитеObjects/unicodeobject.cдляstrвведитеObjects/weakrefobject.cдляweakrefобъектМы собираемся рассмотреть 3 из этих типов:
- Логические значения
- Целые числа
- Генераторы
Логические значения и целые числа имеют много общего, поэтому мы рассмотрим их в первую очередь.
Типы Bool и Long Integer
Тип
boolявляется наиболее простой реализацией встроенных типов. Он наследуется отlongи имеет предопределенные константы,Py_TrueиPy_False. Эти константы являются неизменяемыми экземплярами, созданными при создании экземпляра интерпретатора Python.Внутри
Objects/boolobject.cвы можете увидеть вспомогательную функцию для создания экземпляраboolиз числа:PyObject *PyBool_FromLong(long ok) { PyObject *result; if (ok) result = Py_True; else result = Py_False; Py_INCREF(result); return result; }Эта функция использует вычисление числового типа на языке Си для присвоения
Py_TrueилиPy_Falseрезультату и увеличения значений счетчиков ссылок.Реализованы числовые функции для
and,xor, иor, но сложение, вычитание и деление разыменованы из базового типа long, поскольку не имеет смысла делить два логических значения.Реализация
andдля значенияboolпроверяет, являются лиaиbлогическими значениями, затем проверяет их ссылки наPy_True, в противном случае они преобразуются в числа, и операцияandвыполняется над двумя числами:static PyObject * bool_and(PyObject *a, PyObject *b) { if (!PyBool_Check(a) || !PyBool_Check(b)) return PyLong_Type.tp_as_number->nb_and(a, b); return PyBool_FromLong((a == Py_True) & (b == Py_True)); }Тип
longнемного сложнее, так как требования к памяти очень велики. При переходе с Python 2 на 3 CPython отказался от поддержки типаintи вместо этого использовал типlongв качестве основного целочисленного типа. Типlongв Python отличается тем, что он может хранить числа переменной длины. Максимальная длина задается в скомпилированном двоичном коде.Структура данных в Python
longсостоит из заголовкаPyObjectи списка цифр. Список цифрob_digitизначально состоит из одной цифры, но позже при инициализации он стал длиннее:struct _longobject { PyObject_VAR_HEAD digit ob_digit[1]; };Память выделяется новому
longпосредством_PyLong_New(). Эта функция принимает фиксированную длину и следит за тем, чтобы она была меньше, чемMAX_LONG_DIGITS. Затем она перераспределяет память дляob_digitв соответствии с длиной.Чтобы преобразовать тип C
longв тип Pythonlong,longпреобразуется в список цифр, память для Pythonlongравна присваивается, а затем устанавливается каждая из цифр. Посколькуlongинициализируется с помощьюob_digit, длина которого уже равна 1, если число меньше 10, то значение устанавливается без выделения памяти:PyObject * PyLong_FromLong(long ival) { PyLongObject *v; unsigned long abs_ival; unsigned long t; /* unsigned so >> doesn't propagate sign bit */ int ndigits = 0; int sign; CHECK_SMALL_INT(ival); ... /* Fast path for single-digit ints */ if (!(abs_ival >> PyLong_SHIFT)) { v = _PyLong_New(1); if (v) { Py_SIZE(v) = sign; v->ob_digit[0] = Py_SAFE_DOWNCAST( abs_ival, unsigned long, digit); } return (PyObject*)v; } ... /* Larger numbers: loop to determine number of digits */ t = abs_ival; while (t) { ++ndigits; t >>= PyLong_SHIFT; } v = _PyLong_New(ndigits); if (v != NULL) { digit *p = v->ob_digit; Py_SIZE(v) = ndigits*sign; t = abs_ival; while (t) { *p++ = Py_SAFE_DOWNCAST( t & PyLong_MASK, unsigned long, digit); t >>= PyLong_SHIFT; } } return (PyObject *)v; }Чтобы преобразовать двоичное число с плавающей запятой в Python
long,PyLong_FromDouble()посчитаем за вас:PyObject * PyLong_FromDouble(double dval) { PyLongObject *v; double frac; int i, ndig, expo, neg; neg = 0; if (Py_IS_INFINITY(dval)) { PyErr_SetString(PyExc_OverflowError, "cannot convert float infinity to integer"); return NULL; } if (Py_IS_NAN(dval)) { PyErr_SetString(PyExc_ValueError, "cannot convert float NaN to integer"); return NULL; } if (dval < 0.0) { neg = 1; dval = -dval; } frac = frexp(dval, &expo); /* dval = frac*2**expo; 0.0 <= frac < 1.0 */ if (expo <= 0) return PyLong_FromLong(0L); ndig = (expo-1) / PyLong_SHIFT + 1; /* Number of 'digits' in result */ v = _PyLong_New(ndig); if (v == NULL) return NULL; frac = ldexp(frac, (expo-1) % PyLong_SHIFT + 1); for (i = ndig; --i >= 0; ) { digit bits = (digit)frac; v->ob_digit[i] = bits; frac = frac - (double)bits; frac = ldexp(frac, PyLong_SHIFT); } if (neg) Py_SIZE(v) = -(Py_SIZE(v)); return (PyObject *)v; }Остальные функции реализации в
longobject.cсодержат утилиты, такие как преобразование строки в Юникоде в число сPyLong_FromUnicodeObject().Обзор типа генератора
Генераторы Python - это функции, которые возвращают оператор
yieldи могут вызываться непрерывно для генерации дополнительных значений.Обычно они используются как более экономичный с точки зрения памяти способ циклического просмотра значений в большом блоке данных, таком как файл, база данных или сеть.
Объекты генератора возвращаются вместо значения, когда вместо
returnиспользуетсяyield. Объект generator создается из инструкцииyieldи возвращается вызывающей стороне.Давайте создадим простой генератор со списком из 4 постоянных значений:
>>> def example(): ... lst = [1,2,3,4] ... for i in lst: ... yield i ... >>> gen = example() >>> gen <generator object example at 0x100bcc480>Если вы изучите содержимое объекта generator, то сможете увидеть некоторые поля, начинающиеся с
gi_:>>> dir(gen) [ ... 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw']Тип
PyGenObjectопределен вInclude/genobject.hи существует 3 варианта:
- Объекты-генераторы
- Объекты сопрограммы
- Объекты асинхронного генератора
Все 3 используют одно и то же подмножество полей, используемых в генераторах, и имеют схожее поведение:
Сначала сосредоточив внимание на генераторах, вы можете увидеть поля:
gi_frameссылка наPyFrameObjectчто касается генератора, то ранее в главе "Выполнение" мы исследовали использование локальных и глобальных переменных внутри стека значений фрейма. Именно так генераторы запоминают последнее значение локальных переменных, поскольку кадр сохраняется между вызовамиgi_runningустановите значение 0 или 1, если генератор запущен в данный моментgi_codeпривязка кPyCodeObjectс помощью скомпилированной функции, которая выдала генератор, чтобы его можно было вызвать сноваgi_weakreflistссылка на список слабых ссылок на объекты внутри функции генератораgi_nameкак имя генератораgi_qualnameкак полное имя генератораgi_exc_stateв виде кортежа исключительных данных, если вызов генератора вызывает исключениеСопрограмма и Асинхронные генераторы имеют одинаковые поля, но перед ними начинаются
crиagсоответственно.Если вы вызываете
__next__()для объекта generator, выдается следующее значение, пока в конечном итоге не будет полученоStopIteration:>>> gen.__next__() 1 >>> gen.__next__() 2 >>> gen.__next__() 3 >>> gen.__next__() 4 >>> gen.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIterationПри каждом вызове
__next__()объект кода внутри поля generatorsgi_codeвыполняется как новый кадр, а возвращаемое значение помещается в стек значений.Вы также можете увидеть, что
gi_codeявляется объектом скомпилированного кода для функции генератора, импортировав модульdisи разобрав байт-код внутри:>>> gen = example() >>> import dis >>> dis.disco(gen.gi_code) 2 0 LOAD_CONST 1 (1) 2 LOAD_CONST 2 (2) 4 LOAD_CONST 3 (3) 6 LOAD_CONST 4 (4) 8 BUILD_LIST 4 10 STORE_FAST 0 (l) 3 12 SETUP_LOOP 18 (to 32) 14 LOAD_FAST 0 (l) 16 GET_ITER >> 18 FOR_ITER 10 (to 30) 20 STORE_FAST 1 (i) 4 22 LOAD_FAST 1 (i) 24 YIELD_VALUE 26 POP_TOP 28 JUMP_ABSOLUTE 18 >> 30 POP_BLOCK >> 32 LOAD_CONST 0 (None) 34 RETURN_VALUEВсякий раз, когда
__next__()вызывается для объекта generator,gen_iternext()вызывается с помощью экземпляра generator, который немедленно вызываетgen_send_ex()внутриObjects/genobject.c.
gen_send_ex()это функция, которая преобразует объект generator в следующий полученный результат. Вы увидите много общего с тем, как создаются фреймы вPython/ceval.cиз объекта code, поскольку у этих функций схожие задачи.Функция
gen_send_ex()используется совместно с генераторами, сопрограммами и асинхронными генераторами и состоит из следующих этапов:
Получено текущее состояние потока
Извлекается объект frame из объекта generator
Если генератор запущен при вызове
__next__(), вызовитеValueErrorЕсли кадр внутри генератора находится на вершине стека:
- В случае сопрограммы, если она еще не помечена как закрывающаяся, генерируется
RuntimeError- Если это асинхронный генератор, вызовите
StopAsyncIteration- Для стандартного генератора генерируется
StopIteration.Если последняя команда во фрейме (
f->f_lasti) все еще равна -1, потому что она только что была запущена, и это сопрограмма или асинхронный генератор, то значение, отличное от None, не может быть передано в качестве аргумента, поэтому создается исключение поднятоВ противном случае, это первый раз, когда он вызывается, и аргументы разрешены. Значение аргумента помещается в стек значений фрейма
Поле
f_backфрейма является вызывающим элементом, которому отправляются возвращаемые значения, поэтому оно устанавливается на текущий фрейм в потоке. Это означает, что возвращаемое значение отправляется вызывающей стороне, а не создателю генератораГенератор помечен как запущенный
Последнее исключение в информации об исключении генератора копируется из последнего исключения в состоянии потока
Информация об исключении состояния потока устанавливается на адрес информации об исключении генератора. Это означает, что если вызывающий объект вводит точку останова во время выполнения генератора, трассировка стека проходит через генератор, и нарушающий код очищается
Кадр внутри генератора выполняется в рамках
Python/ceval.cосновного цикла выполнения, и возвращается значениеПоследнее исключение состояния потока сбрасывается до значения, существовавшего до вызова фрейма
Генератор помечен как не работающий
Следующие случаи затем соответствуют возвращаемому значению и любым исключениям, генерируемым вызовом генератора. Помните, что генераторы должны генерировать
StopIteration, когда они исчерпаны, либо вручную, либо не выдавая значения. Сопрограммы и асинхронные генераторы не должны:
- Если результат не был возвращен из фрейма, создайте
StopIterationдля генераторов иStopAsyncIterationдля асинхронных генераторов- Если
StopIterationбыл задан явно, но это сопрограмма или асинхронный генератор, задайтеRuntimeError, поскольку это запрещено- Если
StopAsyncIterationбыл явно задан и это асинхронный генератор, задайтеRuntimeError, так как это запрещеноНаконец, результат возвращается обратно вызывающей стороне
__next__()static PyObject * gen_send_ex(PyGenObject *gen, PyObject *arg, int exc, int closing) { PyThreadState *tstate = _PyThreadState_GET(); // 1. PyFrameObject *f = gen->gi_frame; // 2. PyObject *result; if (gen->gi_running) { // 3. const char *msg = "generator already executing"; if (PyCoro_CheckExact(gen)) { msg = "coroutine already executing"; } else if (PyAsyncGen_CheckExact(gen)) { msg = "async generator already executing"; } PyErr_SetString(PyExc_ValueError, msg); return NULL; } if (f == NULL || f->f_stacktop == NULL) { // 4. if (PyCoro_CheckExact(gen) && !closing) { /* `gen` is an exhausted coroutine: raise an error, except when called from gen_close(), which should always be a silent method. */ PyErr_SetString( PyExc_RuntimeError, "cannot reuse already awaited coroutine"); // 4a. } else if (arg && !exc) { /* `gen` is an exhausted generator: only set exception if called from send(). */ if (PyAsyncGen_CheckExact(gen)) { PyErr_SetNone(PyExc_StopAsyncIteration); // 4b. } else { PyErr_SetNone(PyExc_StopIteration); // 4c. } } return NULL; } if (f->f_lasti == -1) { if (arg && arg != Py_None) { // 5. const char *msg = "can't send non-None value to a " "just-started generator"; if (PyCoro_CheckExact(gen)) { msg = NON_INIT_CORO_MSG; } else if (PyAsyncGen_CheckExact(gen)) { msg = "can't send non-None value to a " "just-started async generator"; } PyErr_SetString(PyExc_TypeError, msg); return NULL; } } else { // 6. /* Push arg onto the frame's value stack */ result = arg ? arg : Py_None; Py_INCREF(result); *(f->f_stacktop++) = result; } /* Generators always return to their most recent caller, not * necessarily their creator. */ Py_XINCREF(tstate->frame); assert(f->f_back == NULL); f->f_back = tstate->frame; // 7. gen->gi_running = 1; // 8. gen->gi_exc_state.previous_item = tstate->exc_info; // 9. tstate->exc_info = &gen->gi_exc_state; // 10. result = PyEval_EvalFrameEx(f, exc); // 11. tstate->exc_info = gen->gi_exc_state.previous_item; // 12. gen->gi_exc_state.previous_item = NULL; gen->gi_running = 0; // 13. /* Don't keep the reference to f_back any longer than necessary. It * may keep a chain of frames alive or it could create a reference * cycle. */ assert(f->f_back == tstate->frame); Py_CLEAR(f->f_back); /* If the generator just returned (as opposed to yielding), signal * that the generator is exhausted. */ if (result && f->f_stacktop == NULL) { // 14a. if (result == Py_None) { /* Delay exception instantiation if we can */ if (PyAsyncGen_CheckExact(gen)) { PyErr_SetNone(PyExc_StopAsyncIteration); } else { PyErr_SetNone(PyExc_StopIteration); } } else { /* Async generators cannot return anything but None */ assert(!PyAsyncGen_CheckExact(gen)); _PyGen_SetStopIterationValue(result); } Py_CLEAR(result); } else if (!result && PyErr_ExceptionMatches(PyExc_StopIteration)) { // 14b. const char *msg = "generator raised StopIteration"; if (PyCoro_CheckExact(gen)) { msg = "coroutine raised StopIteration"; } else if PyAsyncGen_CheckExact(gen) { msg = "async generator raised StopIteration"; } _PyErr_FormatFromCause(PyExc_RuntimeError, "%s", msg); } else if (!result && PyAsyncGen_CheckExact(gen) && PyErr_ExceptionMatches(PyExc_StopAsyncIteration)) // 14c. { /* code in `gen` raised a StopAsyncIteration error: raise a RuntimeError. */ const char *msg = "async generator raised StopAsyncIteration"; _PyErr_FormatFromCause(PyExc_RuntimeError, "%s", msg); } ... return result; // 15. }Возвращаясь к вычислению объектов кода всякий раз, когда вызывается функция или модуль, в этом случае был особый случай для генераторов, сопрограмм и асинхронных генераторов.
_PyEval_EvalCodeWithName(). Эта функция проверяет наличие флаговCO_GENERATOR,CO_COROUTINE, иCO_ASYNC_GENERATORв объекте code.При создании новой сопрограммы с помощью
PyCoro_New(), создается новый асинхронный генератор с помощьюPyAsyncGen_New()или генератор с помощьюPyGen_NewWithQualName(). Эти объекты возвращаются заблаговременно, вместо того чтобы возвращать вычисленный кадр, вот почему вы получаете объект generator после вызова функции с инструкцией yield:PyObject * _PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals, ... ... /* Handle generator/coroutine/asynchronous generator */ if (co->co_flags & (CO_GENERATOR | CO_COROUTINE | CO_ASYNC_GENERATOR)) { PyObject *gen; PyObject *coro_wrapper = tstate->coroutine_wrapper; int is_coro = co->co_flags & CO_COROUTINE; ... /* Create a new generator that owns the ready to run frame * and return that as the value. */ if (is_coro) { gen = PyCoro_New(f, name, qualname); } else if (co->co_flags & CO_ASYNC_GENERATOR) { gen = PyAsyncGen_New(f, name, qualname); } else { gen = PyGen_NewWithQualName(f, name, qualname); } ... return gen; } ...Флаги в объект code были введены компилятором после прохождения AST и просмотра инструкций
yieldилиyield fromили просмотра декоратораcoroutine.
PyGen_NewWithQualName()вызоветgen_new_with_qualname()с сгенерированным фреймом, а затем создастPyGenObjectсо значениямиNULLи скомпилированным объектом кода:static PyObject * gen_new_with_qualname(PyTypeObject *type, PyFrameObject *f, PyObject *name, PyObject *qualname) { PyGenObject *gen = PyObject_GC_New(PyGenObject, type); if (gen == NULL) { Py_DECREF(f); return NULL; } gen->gi_frame = f; f->f_gen = (PyObject *) gen; Py_INCREF(f->f_code); gen->gi_code = (PyObject *)(f->f_code); gen->gi_running = 0; gen->gi_weakreflist = NULL; gen->gi_exc_state.exc_type = NULL; gen->gi_exc_state.exc_value = NULL; gen->gi_exc_state.exc_traceback = NULL; gen->gi_exc_state.previous_item = NULL; if (name != NULL) gen->gi_name = name; else gen->gi_name = ((PyCodeObject *)gen->gi_code)->co_name; Py_INCREF(gen->gi_name); if (qualname != NULL) gen->gi_qualname = qualname; else gen->gi_qualname = gen->gi_name; Py_INCREF(gen->gi_qualname); _PyObject_GC_TRACK(gen); return (PyObject *)gen; }Сводя все это воедино, вы можете увидеть, что выражение generator представляет собой мощный синтаксис, в котором одно ключевое слово
yieldзапускает целый поток для создания уникального объекта, копирования объекта скомпилированного кода в качестве свойства, установки фрейма и сохранения список переменных в локальной области видимости.Пользователю генераторного выражения все это кажется волшебством, но на самом деле это не так сложно.
Заключение
Теперь, когда вы понимаете, как работают некоторые встроенные типы, вы можете изучить другие типы.
При изучении классов Python важно помнить, что существуют встроенные типы, написанные на C, и наследуемые от них классы, написанные на Python или C.
В некоторых библиотеках типы написаны на C вместо того, чтобы наследоваться от встроенных типов. Одним из примеров является
numpy, библиотека для числовых массивов. Типnparrayнаписан на языке Си, отличается высокой эффективностью и быстродействием.В следующей части мы рассмотрим классы и функции, определенные в стандартной библиотеке.
Часть 5: Стандартная библиотека CPython
Python всегда поставляется с “батарейками в комплекте”. Это утверждение означает, что в стандартном дистрибутиве CPython есть библиотеки для работы с файлами, потоками, сетями, веб-сайтами, музыкой, клавиатурами, экранами, текстом и целым рядом утилит.
Некоторые элементы питания, поставляемые с CPython, больше похожи на батарейки типа АА. Они полезны для всего, например, для модулей
collectionsиsys. Некоторые из них более малоизвестны, например, маленькая батарейка для часов, о которой никогда не знаешь, когда она может пригодиться.В стандартной библиотеке CPython есть 2 типа модулей:
- Те, которые написаны на чистом Python и предоставляют утилиту
- Те, которые написаны на C с использованием оболочек Python
Мы рассмотрим оба типа.
Модули Python
Все модули, написанные на чистом Python, расположены в каталоге
Lib/в исходном коде. Некоторые из более крупных модулей имеют подмодули в подпапках, например, модульСамым простым модулем для просмотра был бы модуль
colorsys. Это всего лишь несколько сотен строк кода на Python. Возможно, вы не сталкивались с ним раньше. Модульcolorsysимеет несколько полезных функций для преобразования цветовых гамм.Когда вы устанавливаете дистрибутив Python из исходного кода, модули стандартной библиотеки копируются из папки
Libв папку дистрибутива. Эта папка всегда является частью вашего пути при запуске Python, поэтому вы можетеimportиспользовать модули, не беспокоясь о том, где они расположены.Например:
>>> import colorsys >>> colorsys <module 'colorsys' from '/usr/shared/lib/python3.7/colorsys.py'> >>> colorsys.rgb_to_hls(255,0,0) (0.0, 127.5, -1.007905138339921)Мы можем видеть исходный код
rgb_to_hls()внутриLib/colorsys.py:# HLS: Hue, Luminance, Saturation # H: position in the spectrum # L: color lightness # S: color saturation def rgb_to_hls(r, g, b): maxc = max(r, g, b) minc = min(r, g, b) # XXX Can optimize (maxc+minc) and (maxc-minc) l = (minc+maxc)/2.0 if minc == maxc: return 0.0, l, 0.0 if l <= 0.5: s = (maxc-minc) / (maxc+minc) else: s = (maxc-minc) / (2.0-maxc-minc) rc = (maxc-r) / (maxc-minc) gc = (maxc-g) / (maxc-minc) bc = (maxc-b) / (maxc-minc) if r == maxc: h = bc-gc elif g == maxc: h = 2.0+rc-bc else: h = 4.0+gc-rc h = (h/6.0) % 1.0 return h, l, sВ этой функции нет ничего особенного, это просто стандартный Python. Вы найдете похожие функции во всех модулях стандартной библиотеки Python. Они просто написаны на обычном Python, хорошо структурированы и просты для понимания. Вы даже можете обнаружить улучшения или ошибки, чтобы внести в них изменения и добавить их в дистрибутив Python. Мы рассмотрим это в конце этой статьи.
Модули Python и C
Остальные модули написаны на C или на комбинации Python и C. Исходный код для них находится в
Lib/для компонента Python иModules/для компонента C. Из этого правила есть два исключения: модульsys, который находится вPython/sysmodule.c, и модуль__builtins__, который находится вPython/bltinmodule.c.Python будет
import * from __builtins__при создании экземпляра интерпретатора, поэтому все функции, такие какprint(),chr(),format(), и т.д., находятся внутриPython/bltinmodule.c.Поскольку модуль
sysнастолько специфичен для интерпретатора и внутренних компонентов CPython, что находится непосредственно внутриPython. Он также помечен как “деталь реализации” CPython и не встречается в других дистрибутивах.Встроенная функция
print(), вероятно, была первым, что вы научились делать в Python. Итак, что происходит, когда вы вводитеprint("hello world!")?
- Аргумент
"hello world"был преобразован из строковой константы вPyUnicodeObjectкомпиляторомbuiltin_print()был выполнен с 1 аргументом и NULLkwnames- Переменной
fileприсвоено значениеPyId_stdout, системныйstdoutдескриптор- Каждый аргумент отправляется в
file- Разрыв строки,
\nотправляется вfilestatic PyObject * builtin_print(PyObject *self, PyObject *const *args, Py_ssize_t nargs, PyObject *kwnames) { ... if (file == NULL || file == Py_None) { file = _PySys_GetObjectId(&PyId_stdout); ... } ... for (i = 0; i < nargs; i++) { if (i > 0) { if (sep == NULL) err = PyFile_WriteString(" ", file); else err = PyFile_WriteObject(sep, file, Py_PRINT_RAW); if (err) return NULL; } err = PyFile_WriteObject(args[i], file, Py_PRINT_RAW); if (err) return NULL; } if (end == NULL) err = PyFile_WriteString("\n", file); else err = PyFile_WriteObject(end, file, Py_PRINT_RAW); ... Py_RETURN_NONE; }Содержимое некоторых модулей, написанных на C, предоставляет доступ к функциям операционной системы. Поскольку исходный код CPython необходимо компилировать для macOS, Windows, Linux и других операционных систем на базе *nix, существуют некоторые особые случаи.
Хорошим примером является модуль
time. Способ, которым Windows сохраняет время в операционной системе, принципиально отличается от Linux и macOS. Это одна из причин, по которой точность работы функций часов отличается в разных операционных системах.В
Modules/timemodule.cфункции времени операционной системы для систем на базе Unix импортируются из<sys/times.h>:#ifdef HAVE_SYS_TIMES_H #include <sys/times.h> #endif ... #ifdef MS_WINDOWS #define WIN32_LEAN_AND_MEAN #include <windows.h> #include "pythread.h" #endif /* MS_WINDOWS */ ...Далее в файле
time_process_time_ns()определяется как оболочка для_PyTime_GetProcessTimeWithInfo():static PyObject * time_process_time_ns(PyObject *self, PyObject *unused) { _PyTime_t t; if (_PyTime_GetProcessTimeWithInfo(&t, NULL) < 0) { return NULL; } return _PyTime_AsNanosecondsObject(t); }
_PyTime_GetProcessTimeWithInfo()это реализовано несколькими различными способами в исходном коде, но только определенные части компилируются в двоичный файл для модуля, в зависимости от операционной системы. Системы Windows вызовутGetProcessTimes(), а системы Unix вызовутclock_gettime().Другими модулями, имеющими несколько реализаций для одного и того же API, являются модуль потоковой передачи данных, модуль файловой системы и сетевые модули. Поскольку операционные системы ведут себя по-разному, исходный код CPython максимально точно реализует одно и то же поведение и предоставляет его с помощью согласованного абстрактного API.
Набор регрессионных тестов CPython
CPython обладает надежным и обширным набором тестов, охватывающим базовый интерпретатор, стандартную библиотеку, инструментарий и дистрибутив как для Windows, так и для Linux/macOS.
Набор тестов находится в
Lib/testи почти полностью написан на Python.Полный набор тестов представляет собой пакет Python, поэтому может быть запущен с помощью скомпилированного вами интерпретатора Python. Измените каталог на
Libи запуститеpython -m test -j2, гдеj2означает использование 2 процессоров.В Windows используйте скрипт
rt.batв папке PCBuild, предварительно создав конфигурацию выпуска из Visual Studio:$ cd PCbuild $ rt.bat -q C:\repos\cpython\PCbuild>"C:\repos\cpython\PCbuild\win32\python.exe" -u -Wd -E -bb -m test == CPython 3.8.0b4 == Windows-10-10.0.17134-SP0 little-endian == cwd: C:\repos\cpython\build\test_python_2784 == CPU count: 2 == encodings: locale=cp1252, FS=utf-8 Run tests sequentially 0:00:00 [ 1/420] test_grammar 0:00:00 [ 2/420] test_opcodes 0:00:00 [ 3/420] test_dict 0:00:00 [ 4/420] test_builtin ...В Linux:
$ cd Lib $ ../python -m test -j2 == CPython 3.8.0b4 == macOS-10.14.3-x86_64-i386-64bit little-endian == cwd: /Users/anthonyshaw/cpython/build/test_python_23399 == CPU count: 4 == encodings: locale=UTF-8, FS=utf-8 Run tests in parallel using 2 child processes 0:00:00 load avg: 2.14 [ 1/420] test_opcodes passed 0:00:00 load avg: 2.14 [ 2/420] test_grammar passed ...На macOS:
$ cd Lib $ ../python.exe -m test -j2 == CPython 3.8.0b4 == macOS-10.14.3-x86_64-i386-64bit little-endian == cwd: /Users/anthonyshaw/cpython/build/test_python_23399 == CPU count: 4 == encodings: locale=UTF-8, FS=utf-8 Run tests in parallel using 2 child processes 0:00:00 load avg: 2.14 [ 1/420] test_opcodes passed 0:00:00 load avg: 2.14 [ 2/420] test_grammar passed ...Для некоторых тестов требуются определенные флаги; в противном случае они пропускаются. Например, для многих тестов в режиме ожидания требуется графический интерфейс пользователя.
Чтобы просмотреть список наборов тестов в конфигурации, используйте флаг
--list-tests:$ ../python.exe -m test --list-tests test_grammar test_opcodes test_dict test_builtin test_exceptions ...Вы можете запускать определенные тесты, указав набор тестов в качестве первого аргумента:
$ ../python.exe -m test test_webbrowser Run tests sequentially 0:00:00 load avg: 2.74 [1/1] test_webbrowser == Tests result: SUCCESS == 1 test OK. Total duration: 117 ms Tests result: SUCCESSВы также можете просмотреть подробный список тестов, которые были выполнены с результатом, используя аргумент
-v:$ ../python.exe -m test test_webbrowser -v == CPython 3.8.0b4 == macOS-10.14.3-x86_64-i386-64bit little-endian == cwd: /Users/anthonyshaw/cpython/build/test_python_24562 == CPU count: 4 == encodings: locale=UTF-8, FS=utf-8 Run tests sequentially 0:00:00 load avg: 2.36 [1/1] test_webbrowser test_open (test.test_webbrowser.BackgroundBrowserCommandTest) ... ok test_register (test.test_webbrowser.BrowserRegistrationTest) ... ok test_register_default (test.test_webbrowser.BrowserRegistrationTest) ... ok test_register_preferred (test.test_webbrowser.BrowserRegistrationTest) ... ok test_open (test.test_webbrowser.ChromeCommandTest) ... ok test_open_new (test.test_webbrowser.ChromeCommandTest) ... ok ... test_open_with_autoraise_false (test.test_webbrowser.OperaCommandTest) ... ok ---------------------------------------------------------------------- Ran 34 tests in 0.056s OK (skipped=2) == Tests result: SUCCESS == 1 test OK. Total duration: 134 ms Tests result: SUCCESSПонимание того, как использовать набор тестов, и проверка состояния скомпилированной версии очень важны, если вы хотите внести изменения в CPython. Прежде чем приступить к внесению изменений, вам следует запустить весь набор тестов и убедиться, что все проходит успешно.
Установка пользовательской версии
Если вы довольны внесенными изменениями и хотите использовать их в своей системе из своего репозитория исходных текстов, вы можете установить его как пользовательскую версию.
Для macOS и Linux вы можете использовать команду
altinstall, которая не будет создавать символические ссылки дляpython3и установить автономную версию:$ make altinstallВ Windows вам необходимо изменить конфигурацию сборки с
DebugнаRelease, затем скопировать упакованные двоичные файлы в каталог на вашем компьютере, который является частью системного пути.Исходный код CPython: Заключение
Поздравляю, у тебя получилось! Твой чай остыл? Налей себе еще чашечку. Ты это заслужил.
Теперь, когда вы ознакомились с исходным кодом CPython, модулями, компилятором и инструментарием, возможно, вы захотите внести некоторые изменения и внести их обратно в экосистему Python.
Официальное руководство разработчика содержит множество ресурсов для начинающих. Вы уже сделали первый шаг к пониманию исходного кода, зная, как изменять, компилировать и тестировать приложения на CPython.
Вспомните все, что вы узнали о CPython из этой статьи. Все элементы магии, секреты которых вы узнали. На этом путешествие не заканчивается.
Возможно, сейчас самое подходящее время узнать больше о Python и C. Кто знает, может быть, вы будете вносить все больший и больший вклад в проект CPython! Также обязательно ознакомьтесь с новой книгой по внутренностям CPython, доступной здесь на реальном Python:
Скачайте бесплатно: Ознакомьтесь с примером главы из CPython Internals: Ваше руководство по интерпретатору Python 3, в которой показано, как разблокировать внутреннюю ознакомьтесь с работой языка Python, скомпилируйте интерпретатор Python из исходного кода и примите участие в разработке CPython.
<завершенный статус статьи-slug=" cpython-руководство по исходному коду "класс=" btn-group mb-0"data-api-article-bookmark-url="/api/v1/статьи/cpython-руководство по исходному коду/закладка/ " data-api-URL-адрес статуса завершения статьи="/api/v1/статьи / cpython-руководство по исходному коду/completion_status/ " > < / статус завершения> <кнопка поделиться bluesky-text="Интересная статья на #Python от @realpython.com :" email-body="Ознакомьтесь с этой статьей о Python:%0A%0 - Ваше руководство по исходному коду CPython" email-subject="Статья о Python для вас" twitter-text="Интересная статья о #Python от @realpython:" url="https://realpython.com/cpython-source-code-guide /" url-title="Ваше руководство по исходному коду CPython"> Back to Top