Использование генератора случайных чисел NumPy
Оглавление
- Понимание работы генератора псевдослучайных чисел NumPy
- Генерация случайных данных с помощью генератора случайных чисел NumPy
- Рандомизация существующих массивов NumPy
- Выбор случайных пуассоновских выборок
- Заключение
Случайные числа являются очень полезной функцией во многих различных типах программ, от математики и анализа данных до компьютерных игр и приложений для шифрования. Возможно, вы удивитесь, узнав, что на самом деле довольно сложно заставить компьютер генерировать действительно случайные числа. Однако, если вы будете осторожны, генератор случайных чисел NumPy может генерировать достаточно случайные числа для повседневных целей.
Возможно, вы уже работали с случайно сгенерированными данными в Python. В то время как модули, подобные random являются отличными вариантами для создания случайных скаляров, используя numpy.random модуль откроет еще больше возможностей возможности для вас.
В этом руководстве вы узнаете, как:
- Генерировать числовые массивы из случайных чисел
- Рандомизировать Числовые массивы
- Случайным образом выберите части из массивов NumPy
- Возьмите случайные выборки из статистических распределений
Перед началом этого урока вы должны ознакомиться с основами NumPy-массивов. Получив эти знания, вы готовы погрузиться в работу.
Бесплатный бонус: Нажмите здесь, чтобы загрузить пример кода, который показывает, как получать случайные числа с помощью NumPy.
Что такое генератор псевдослучайных чисел NumPy
Когда вы просите компьютер выполнить за вас какую-либо задачу, он выполняет ее, следуя набору инструкций, определенных алгоритмом. Когда вам нужно сгенерировать случайные числа, компьютер использует алгоритм генератора псевдослучайных чисел (PRNG). Существует несколько таких алгоритмов, некоторые из которых лучше, чем другие.
Для генерации случайных чисел в Python используется random модуль, который генерирует числа с помощью алгоритма Мерсенна твистера. Хотя это все еще широко используется в коде на Python, можно предсказать числа, которые оно генерирует, и это требует значительных вычислительных мощностей.
Начиная с версии 1.17, NumPy использует более эффективный алгоритм перестановочный конгруэнтный генератор-64 (PCG64). Это приводит к менее предсказуемым результатам, о чем свидетельствует его производительность в стандартном для отрасли статистическом тестировании TestU01. PCG64 также работает быстрее и требует меньше ресурсов для работы.
Примечание: Хотя алгоритм PCG64, безусловно, является улучшением алгоритма Мерсенна Твистера, у него все еще есть некоторые статистические недостатки. В обновленной версии, PCG64DXSM, устранены эти проблемы. Это станет стандартом по умолчанию в будущих версиях NumPy. На практике вы не заметите никакой разницы, но если хотите узнать больше, смотрите раздел Обновление PCG64 с помощью PCG64DXSM в документации NumPy.
В большинстве примеров, приведенных в этом руководстве, вы будете использовать алгоритм PCG64 по умолчанию, хотя вы также попробуете свои силы в использовании обновленного алгоритма PCG64DXSM.
Если вам интересно узнать больше о различных типах алгоритмов PRNG и о том, как алгоритмы PCG сравниваются с другими, то вам следует прочитать PCG, семейство улучшенных генераторов случайных чисел от разработчика из PCG.
PRNG называются псевдослучайными, потому что они не случайные! PRNG являются детерминированными, что означает, что они генерируют последовательности чисел, которые можно воспроизводить. PRNG требуют начального числа для инициализации генерации чисел. PRNG, использующие одно и то же начальное значение, будут генерировать одинаковые числа.
У PRNG также есть свойство период, которое представляет собой количество итераций, которые они проходят, прежде чем начать повторяться. Поскольку сгенерированные числа зависят от начального значения, они не являются по-настоящему случайными, а являются псевдослучайными.
Поскольку начальные значения должны быть случайными, вам нужно, чтобы одно случайное число генерировало другое. Для этой цели в качестве начальных значений по умолчанию используются аппаратные часы компьютера. Это значение измеряется с точностью до наносекунды, поэтому последовательный запуск генераторов чисел приводит к различным начальным значениям и, следовательно, к различным последовательностям случайных чисел. NumPy использует метод хэширования, чтобы гарантировать, что начальное значение имеет длину 128 бит, даже если вы вводите только 64-разрядное целое число.
Период означает, что те же числа могут появиться снова. На практике это не вызывает беспокойства, поскольку продолжительность периода огромна. Период PCG64, например, примерно в 50 миллиардов раз превышает количество атомов, существующих внутри вас!
Примечание: Если вы хотите узнать больше о том, насколько случайными на самом деле являются случайно сгенерированные числа, ознакомьтесь с руководством Насколько случайным является Random?
Основой генерации чисел в NumPy является класс BitGenerator. Этот класс позволяет задать алгоритм и начальное значение. Чтобы получить доступ к случайным числам, BitGenerator передается в отдельный объект Generator. У генераторов есть методы, которые позволяют вам получить доступ к диапазону случайных чисел и выполнить несколько операций рандомизации. Модуль numpy.random предоставляет эту возможность.
Возможно, вы заметили, что документация NumPy.random также содержит информацию о классе RandomState. Это контейнерный класс для более медленного PRNG Mersenne twister. Более современный класс Generator теперь заменил RandomState, который вам больше не следует использовать в новом коде. Однако RandomState по-прежнему используется для существующих устаревших приложений.
Прежде чем вы продолжите, имейте в виду, что NumPy PRNG-файлы не подходят для криптографических целей. Они подходят только для задач анализа данных. Если вам нужны случайные числа для криптографических целей, то вам нужен криптографически защищенный генератор псевдослучайных чисел (CSPRNG).
Генерация случайных данных с помощью генератора случайных чисел NumPy
Теперь, когда вы понимаете возможности компьютера по генерации случайных чисел, в этом разделе вы узнаете, как генерировать как числа с плавающей запятой, так и целые числа случайным образом с помощью NumPy. После генерации отдельных чисел вы узнаете, как генерировать массивы случайных чисел NumPy.
Случайные числа
Если вы не возражаете против того, чтобы NumPy выполнял всю работу по генерации случайных чисел за вас, вы можете использовать его значения по умолчанию. Другими словами, ваш BitGenerator будет использовать PCG64 с начальным значением из часов компьютера. Чтобы упростить настройки по умолчанию, NumPy предоставляет очень удобную функцию default_rng(). Это настраивает все за вас и возвращает ссылку на объект Generator, который вы можете использовать для получения случайных чисел с помощью ряда мощных методов.
Начнем с того, что этот код генерирует число с плавающей запятой, используя значения NumPy по умолчанию:
>>> import numpy as np
>>> default_rng = np.random.default_rng()
>>> default_rng
'Generator(PCG64) at 0x1E9F2ABBF20'
>>> default_rng.random()
0.47418635476614734
Как вы можете видеть, BitGenerator использует PCG64. Чтобы на самом деле сгенерировать псевдослучайное число, вы вызываете метод генератора .random(). Чтобы убедиться, что код действительно генерирует случайное число, запустите его несколько раз и обратите внимание, что каждый раз вы получаете другое число. Помните, это потому, что переданное начальное значение будет другим.
По умолчанию Generator.random() возвращает 64-разрядное значение с плавающей точкой в полуоткрытом интервале [0.0, 1.0). Это обозначение используется для определения диапазона чисел. [ является параметром закрыто и указывает на всеохватность. В этом примере 0.0 может быть одним из случайно сгенерированных чисел. Параметр ) является параметром открыть и указывает, что значение 1.0 находится за пределами того, что можно было бы сгенерировать. Другими словами, [0.0, 1.0) определяет диапазон 0.0 ≤ x < 1.0.
Примечание:: Если вам действительно нужен более мощный алгоритм PCG64DXSM, применить его довольно просто:
>>> from numpy.random import Generator, PCG64DXSM
>>> pcg64dxsm_rng = Generator(PCG64DXSM())
>>> pcg64dxsm_rng.random()
0.3472568589560456
Сначала вы явно создаете объект Generator, и на этот раз вы передаете ему следующее PCG64DXSM BitGenerator. Когда вы вызываете метод .random(), вы снова генерируете случайное число, но на этот раз метод PCG64DXSM гарантирует менее предсказуемый результат, чем стандартный метод PCG64 BitGenerator. Конечно, по одному образцу этого не скажешь, но доверьтесь математикам. Приведенные выше цифры менее предсказуемы.
Ранее вы узнали, как передача начального значения определяет последовательность генерируемых случайных чисел. Напомним, что передача идентичных начальных значений в отдельные объекты BitGenerator приводит к получению одинакового результата. В следующем примере вы сами в этом убедитесь.
В приведенном ниже фрагменте кода вы вводите два отдельных идентичных объекта Generator, оба с начальным значением, равным 100:
>>> rng1 = np.random.default_rng(seed=100)
>>> rng1.random()
0.7852902058808499
>>> rng1.random()
0.7142492625022044
>>> rng2 = np.random.default_rng(seed=100)
>>> rng2.random()
0.7852902058808499
>>> rng2.random()
0.7142492625022044
Как и ожидалось, каждое Generator сгенерировало два числа, но на самом деле это псевдослучайные числа! Как вы можете видеть, результаты вызывают у вас ощущение дежавю. При одинаковом наборе Generator объектов всегда получаются одинаковые результаты! Не имеет значения, используют ли они оба PCG64 по умолчанию или обновленный PCG64DXSM. Результаты все равно будут идентичными.
Метод random() также включает параметр dtype, который используется редко. По умолчанию для этого параметра задано значение np.float64, что генерирует 64-разрядные значения с плавающей запятой. Если вы установите для этого параметра значение np.float32, вы сможете генерировать 32-разрядные значения с плавающей запятой.
Случайные числа с плавающей запятой
Вы уже знаете, что метод .random() успешно генерирует случайные числа с плавающей запятой в диапазоне [0.0, 1.0). Предположим, вы хотите указать свой собственный диапазон. К сожалению, напрямую это невозможно с помощью .random(), если только вы не начнете добавлять некоторую арифметику к его выходным данным. Чтобы задать диапазон значений с плавающей запятой, вы можете использовать метод .uniform().
Как вы, вероятно, можете догадаться из сигнатуры метода .uniform(), по умолчанию он генерирует число с плавающей запятой таким же образом, как и .random(). делает. Однако, в отличие от .random(), вы можете дополнительно указать свои собственные параметры low и high. Метод .uniform() также содержит параметр size. Вы узнаете больше об этом, когда научитесь генерировать случайных числовых массивов позже.
В самом простом виде вы можете вызвать метод .uniform() без параметров:
>>> import numpy as np
>>> rng = np.random.default_rng()
>>> rng.uniform()
0.5425301829704396
Когда вы запустите приведенный выше код, .uniform() сгенерирует одно случайное число с плавающей запятой в диапазоне [0, 1). Другими словами, наименьшее число будет равно 0, в то время как наибольшее число будет чуть меньше 1. Например, если вам нужно число от 0 до числа, предшествующего 10, вам нужно умножить результат на 10. Однако это ограничено, поскольку нижняя граница всегда будет равна нулю, а кодировка неясна.
Гораздо лучший способ - использовать реальную мощь .uniform(), передав его параметры low и high:
>>> rng.uniform(low=3.4, high=5.6)
4.656018709365851
Здесь, поскольку вы устанавливаете low=3.4 и high=5.6, метод .uniform() генерирует еще одно значение с плавающей точкой, но на этот раз в диапазоне [3.4, 5.6). Опять же, помните, что версия 3.4 является всеобъемлющей, в то время как версия 5.6 является эксклюзивной.
Вы можете задаться вопросом, почему вызывается метод, используемый для генерации чисел с плавающей точкой .uniform(). Метод .uniform() выбирает свои числа случайным образом из равномерного распределения вероятностей. Равномерное распределение вероятностей означает, что каждое из значений в указанном диапазоне (низкое, высокое) имеет равные шансы быть выбранным. Позже вы увидите, что это не единственный тип распределения вероятностей, который поддерживает NumPy.
Случайные целые числа
При необходимости вы также можете генерировать случайные целые числа. Для этого используется метод .integers() объекта Generator.
В самом простом варианте вы используете .integers() с одним обязательным параметром:
>>> import numpy as np
>>> rng = np.random.default_rng()
>>> for i in range(5):
... rng.integers(3)
...
1
2
0
1
2
Когда вы вызываете .integers() с одним параметром, этот параметр определяет верхнюю исключительную границу сгенерированных чисел. В этом примере, поскольку вы ввели 3, возможные выходные данные находятся в диапазоне [0, 3). Другими словами, вы можете получить 0, 1 или 2.
Если вы вызовете .integers() пять раз, используя цикл for и функцию range(), то она выдаст пять значений.
Хотя приведенный выше пример может показаться вам наиболее распространенным способом использования .integers(), на самом деле этот метод гораздо более гибкий. К сожалению, он также немного запутывает. Сигнатура метода .integers() включает в себя три параметра для определения диапазона чисел, из которых метод будет генерировать ваши случайные числа: low, high, и endpoint. К сожалению, они не так интуитивно понятны в использовании, как следует из их названий.
Параметр low является единственным обязательным. Хотя его название предполагает, что его значение будет определять наименьшее целое число, которое может выбрать функция .integers(), на самом деле это верно только в том случае, если вы также указываете значение для параметра high. Таким образом, если вы установите low=1 и high=4, то метод .integers() выберет случайное число в диапазоне [1, 4):
>>> for count in range(5):
... rng.integers(low=1, high=4)
...
3
2
3
1
2
Здесь вы сгенерировали только числа 1, 2 и 3. Опять же, в то время как low возможно, high нет.
Вот тут-то и может возникнуть путаница. Если вы передадите только аргумент low и примете значение high по умолчанию, равное None, то .integers() присваивает своему параметру low значение 0 и используйте указанное вами значение для верхнего предела. Так, например, если вы вызываете .integers(low=7) или .integers(7), хотя 7 является параметром low, метод вернет значение в диапазоне [0, 7):
>>> for count in range(5):
... rng.integers(low=7)
...
3
4
2
6
0
В приведенном выше коде вы генерируете целые числа в диапазоне от 0 до 6. Присвоение имени low здесь вводит в заблуждение. Вместо этого вам следует вызвать rng.integers(7) или использовать более явный rng.integers(low=0, high=7), чтобы сделать то же самое. В общем, вы всегда должны включать high, если вы передаете low в качестве аргумента ключевого слова.
Третьим параметром, определяющим диапазон, является параметр endpoint, который определяет, включает ли интервал значение high. Помните, что по умолчанию используется полуоткрытый интервал? Это потому, что endpoint по умолчанию равно False, что означает, что интервал выборки равен [низкий, высокий). Однако, если вы установите значение True, то интервал станет включающим в себя оба конца, [низкий, высокий]. Зная это, теперь вы можете записать включающий интервал:
>>> for count in range(5):
... rng.integers(low=1, high=4, endpoint=True)
...
1
4
4
3
2
>>> for count in range(5):
... rng.integers(7, endpoint=True)
...
5
7
6
2
0
На этот раз первый цикл сгенерирует значения 1, 2, 3 или 4. Второй цикл сгенерирует числа в диапазоне от 0 до 7 включительно. Установка endpoint=True может сделать ваши целочисленные интервалы более интуитивно понятными.
Метод .integers() по умолчанию выдает 64-разрядные целые числа. Это происходит потому, что для его параметра dtype задано значение np.int64. Если вы установите для dtype значение np.int32, то вместо этого получите 32-разрядные целые числа.
Случайные числовые массивы
При работе с NumPy вы можете захотеть создать массив NumPy, содержащий случайные числа. Для этого используется параметр size либо в методе .random(), .uniform(),, либо в методе .integers() объекта Generator. Во всех трех методах значением по умолчанию size является None, что приводит к генерации единственного числа. Однако, если вы назначите кортежу значение size, то вы сгенерируете массив.
В приведенном ниже примере вы генерируете множество массивов NumPy, используя кортежи разного размера:
>>> import numpy as np
>>> rng = np.random.default_rng()
>>> rng.random(size=(5,))
array([0.18097689, 0.19402707, 0.82936953, 0.29470017, 0.73697751])
>>> rng.random(size=(5, 3))
array([[0.85815152, 0.44158512, 0.49992378],
[0.99656444, 0.40376014, 0.93886646],
[0.31424733, 0.23561498, 0.43465744],
[0.02478389, 0.60644643, 0.52940267],
[0.54349223, 0.77175087, 0.2834884 ]])
>>> rng.random(size=(3, 4, 2))
array([[[0.78538958, 0.93149463],
[0.73405027, 0.32193268],
[0.14362809, 0.59825765],
[0.07675847, 0.0434828 ]],
[[0.28681395, 0.66925531],
[0.59575724, 0.18366003],
[0.54722312, 0.02620217],
[0.06019602, 0.48735061]],
[[0.40764258, 0.00756601],
[0.32556725, 0.44165999],
[0.05679186, 0.01690106],
[0.87091753, 0.46327738]]])
Если вы хотите создать одномерный массив, то вы устанавливаете для параметра size значение целого числа или кортежа с одним элементом. Либо size=x, либо size=(x, ) позволяет сгенерировать одномерный массив с x элементами.
Аналогично, если вы хотите создать двумерный массив с x строками и y столбцами, то вы используете size=(x, y)., устанавливая для параметра size значение кортеж с элементами (x, y, z) позволяет сгенерировать трехмерный массив с x наборами из y строк и z столбцов.
В следующем примере вы случайным образом генерируете два массива, но на этот раз вы указываете допустимые диапазоны чисел:
>>> rng = np.random.default_rng()
>>> rng.integers(size=(2, 3), low=1, high=5)
array([[4, 2, 3],
[1, 1, 2]], dtype=int64)
>>> rng.uniform(size=(2, 3), low=1, high=5)
array([[4.97441068, 1.02042664, 1.43584549],
[2.87965746, 1.99063036, 2.86212453]])
Как вы можете видеть, первый массив содержит целые числа, а второй - числа с плавающей запятой. Оба массива находятся в диапазоне [1, 5).
Теперь, когда вы научились создавать случайные целые числа и числа с плавающей точкой, как по отдельности, так и в массивах NumPy, вы увидите, как можно рандомизировать сами массивы NumPy.
Рандомизация существующих массивов NumPy
Когда у вас есть массив NumPy, независимо от того, сгенерировали ли вы его случайным образом или получили из более упорядоченного источника, могут возникнуть ситуации, когда вам потребуется случайным образом выбрать элементы из него или изменить порядок в его структуре. Далее вы узнаете, как это сделать.
Произвольный выбор элементов массива
Предположим, у вас есть небольшой массив данных, собранных в ходе опроса, и вы хотите использовать случайную выборку его элементов для анализа. Метод объекта Generator .choice() позволяет вам выбирать случайные выборки из заданного массива различными способами. Вы подробно расскажете об этом в следующих нескольких примерах:
>>> import numpy as np
>>> rng = np.random.default_rng()
>>> input_array_1d = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
>>> rng.choice(input_array_1d, size=3, replace=False)
array([ 6, 12, 10])
>>> rng.choice(input_array_1d, size=(2, 3), replace=False)
array([[ 8, 12, 11],
[10, 7, 5]])
В этом примере вы анализируете одномерный массив NumPy. Первый вызов .choice() создает одномерный массив, содержащий три элемента, выбранных случайным образом из исходного массива. Второй вызов .choice() создает массив размером два на три из шести случайных элементов из исходных данных.
В предыдущем коде использовался параметр replace. Если вы установите для replace значение False, то вы не сможете выбрать один и тот же элемент более одного раза. По умолчанию установлено значение True, что означает, что один и тот же элемент может быть выбран несколько раз. Это аналогично тому, как вы выбираете мяч из мешка, заменяете его, а затем выбираете снова. Если вам нужно избежать дублирования, вам следует установить для replace значение False.
Следует отметить, что метод .choice() выбирает элементы на основе их положения в исходном массиве. Если одно и то же значение дважды появится в исходных данных, у вас могут быть выбраны оба значения независимо от того, какой параметр replace вы используете.
Произвольный выбор строк и столбцов
Предположим, вы хотите случайным образом выбрать одну или несколько целых строк или столбцов из массива. Метод .choice() позволяет это с помощью параметра axis. Параметр axis позволяет вам указать направление, в котором вы хотите проводить анализ. Для двумерного массива значение axis=0, которое используется по умолчанию, означает, что вы будете анализировать по строкам, в то время как значение axis=1 означает, что вы будете анализировать по столбцам.
Вот несколько примеров случайного выбора в обоих направлениях:
>>> import numpy as np
>>> rng = np.random.default_rng()
>>> input_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
>>> rng.choice(input_array, size=2)
array([[10, 11, 12],
[10, 11, 12]])
>>> rng.choice(input_array, size=2, axis=1)
array([[ 2, 1],
[ 5, 4],
[ 8, 7],
[11, 10]])
Вы используете исходный массив NumPy с четырьмя строками и тремя столбцами. При первом анализе случайным образом будут выбраны две уникальные строки. В этом случае одна и та же строка была выбрана дважды, но так будет не всегда. Как и следовало ожидать, на выходе получается массив NumPy размером два на три. При втором анализе случайным образом выбираются два столбца. Опять же, при запуске кода могут возникать дубликаты, но в данном случае вы их не получили.
Примечание: В примерах, связанных с массивами NumPy, вы для краткости ограничиваете размер двумерным массивом. Те же принципы применимы к массивам с большим числом измерений. Вы просто устанавливаете для axis значение 2, 3, или какое-то большее значение n.
Чтобы исключить возможность многократного выбора одной и той же строки или столбца, вы устанавливаете для параметра replace, равного .choice(), значение False вместо значения по умолчанию True:
>>> rng.choice(input_array, size=3, replace=False)
array([[10, 11, 12],
[ 1, 2, 3],
[ 4, 5, 6]])
Вы можете запускать приведенный выше код столько раз, сколько пожелаете, и вы никогда не увидите ни одной строки или столбца, если для axis было задано значение 1более одного раза!
Метод .choice() также содержит параметр shuffle, который добавляет дополнительный уровень случайности. Это позволяет всем строкам — или столбцам, если axis=1 — быть переупорядоченными после их первоначального случайного выбора. Порядок расположения отдельных элементов в каждой строке или столбце останется неизменным.
Чтобы shuffle подействовал, вы должны сначала установить для replace значение False. Это фактически делает операцию перетасовки доступной, но только в том случае, если значение shuffle по умолчанию равно True. Если вы установите для shuffle значение False или для replace значение True, то дополнительная операция перетасовки не выполняется. В следующих нескольких примерах вы изучите последствия изменения replace и shuffle. Обратите особое внимание на выходные данные и их порядок:
>>> rng = np.random.default_rng(seed=100)
>>> rng.choice(input_array, size=3, replace=False, shuffle=False)
array([[4, 5, 6],
[7, 8, 9],
[1, 2, 3]])
Как видно из приведенных выше выходных данных, вы выбрали три строки из массива. Они были отображены в выбранном порядке. Установка shuffle на False устраняет дополнительную операцию перетасовки, которую NumPy в противном случае выполняет по умолчанию, так что вы ускорили свой код. Хотя replace допускал перетасовку, установка shuffle на False предотвратила это.
Чтобы добавить больше рандомизации, вы можете оставить значение по умолчанию, опустив shuffle, или явно установить для shuffle значение True:
>>> rng = np.random.default_rng(seed=100)
>>> rng.choice(input_array, size=3, replace=False, shuffle=True)
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
На этот раз были выбраны те же самые три строки, поскольку использовалось одно и то же начальное значение, но параметр shuffle изменил их порядок. Установив для shuffle значение True, вы перетасовали выходные данные.
Попробуйте повторно запустить предыдущий код, и вы обнаружите, что результат каждый раз одинаков. Псевдослучайным является не только исходный выбор строк, но и последующая перетасовка! Оба они основаны на начальном этапе.
Теперь, если вы установите replace на True, фактически отключив shuffle, вас ждет сюрприз:
>>> rng = np.random.default_rng(seed=100)
>>> rng.choice(input_array, size=3, replace=True, shuffle=False)
array([[10, 11, 12],
[10, 11, 12],
[ 1, 2, 3]])
>>> rng = np.random.default_rng(seed=100)
>>> rng.choice(input_array, size=3, replace=True, shuffle=True)
array([[10, 11, 12],
[10, 11, 12],
[ 1, 2, 3]])
Когда вы запускаете код на этот раз, оба выходных значения идентичны. Это связано с тем, что оба начальных значения идентичны, и shuffle действует только в том случае, если для replace установлено значение False. Однако выбранные строки отличаются от тех, которые были выбраны в предыдущем коде, несмотря на то, что начальные значения остались прежними.
Помните, что начальное значение, которое вы явно указываете PRNG, на самом деле является только числом, которое оно использует для вычисления своего реального начального значения. В этом случае значение параметра replace участвует в вычислении.
Случайное перетасовывание массивов
Вы можете рандомизировать порядок элементов в массиве NumPy, используя метод Generator объекта .shuffle(). Хотя вы можете воспользоваться им в нескольких вариантах использования, очень распространенным приложением является симулятор карточной игры.
Для начала вы создаете функцию, которая создает массив NumPy из связанных строк, представляющих различные карты в колоде, хотя без джокеров:
>>> import numpy as np
>>> def create_deck():
... RANKS = "2 3 4 5 6 7 8 9 10 J Q K A".split()
... SUITS = "♣ ♢ ♡ ♠".split()
... return np.array([r + s for s in SUITS for r in RANKS])
...
>>> create_deck()
array(['2♣', '3♣', '4♣', '5♣', '6♣', '7♣', '8♣', '9♣', '10♣', 'J♣', 'Q♣',
'K♣', 'A♣', '2♢', '3♢', '4♢', '5♢', '6♢', '7♢', ...,
'7♠', '8♠', '9♠', '10♠', 'J♠', 'Q♠', 'K♠', 'A♠'], dtype='<U3')
Функция create_deck() возвращает массив NumPy, содержащий такие строки, как "2♣", "3♢", "8♡", и "K♠". Как вы можете видеть, он делает это, определяя две константы, содержащие ранги карт и их масти, а затем использует список значений для создания Python список, который затем преобразуется в массив NumPy.
Теперь предположим, что вы хотите случайным образом взять три карты из колоды после перетасовки. Метод .shuffle() позволяет изменять массив на месте, перетасовывая его содержимое. Выполняя перетасовку на месте, вы экономите ценное пространство в памяти:
>>> rng = np.random.default_rng()
>>> deck_of_cards = create_deck()
>>> rng.shuffle(deck_of_cards)
>>> deck_of_cards[0:3]
array(['4♡', '6♠', '2♠'], dtype='<U3')
>>> rng.shuffle(deck_of_cards)
>>> deck_of_cards[0:3]
array(['K♠', '2♣', '6♠'], dtype='<U3')
Ваш код перетасовывает колоду карт Numpy array, а затем отображает первые три элемента, то есть три верхние карты, из перетасованной версии. Затем вы перетасовываете колоду и снова берете три верхние карты. Молодец, если ты заметил, что оба раза перетасовал всю колоду!
Хотя для выбора карточек вы могли бы использовать метод .choice(), о котором вы узнали ранее, метод .shuffle() является лучшим вариантом, поскольку он фактически рандомизирует элементы массива на месте. Это экономит память.
Произвольное изменение порядка в массивах
Ранее вы узнали, как случайным образом выбирать целые строки или столбцы массива NumPy. Теперь предположим, что вы хотите рандомизировать элементы многомерного массива. Генератор предлагает .shuffle(), которые вы уже видели, а также методы .permutation() и .permuted() для этой цели.
Метод .permutation() случайным образом перестраивает целые строки или столбцы. Другими словами, элементы внутри каждой строки или столбца останутся в этих строках и столбцах, но их порядок будет изменен.
Чтобы проиллюстрировать эти методы, вы будете использовать измененную версию вашей функции create_deck():
>>> import numpy as np
>>> def create_high_cards():
... HIGH_CARDS = "10 J Q K A".split()
... SUITS = "♣ ♢ ♡ ♠".split()
... return np.array([r + s for s in SUITS for r in HIGH_CARDS])
...
На этот раз вы создадите колоду, содержащую только десятки, тузы и грани. Это облегчит вам просмотр результатов следующих нескольких примеров.
Начальная колода выглядит следующим образом:
>>> NUMBER_OF_SUITS = 4
>>> NUMBER_OF_RANKS = 5
>>> high_deck = create_high_cards().reshape((NUMBER_OF_SUITS, NUMBER_OF_RANKS))
>>> high_deck
array([['10♣', 'J♣', 'Q♣', 'K♣', 'A♣'],
['10♢', 'J♢', 'Q♢', 'K♢', 'A♢'],
['10♡', 'J♡', 'Q♡', 'K♡', 'A♡'],
['10♠', 'J♠', 'Q♠', 'K♠', 'A♠']], dtype='<U3')
Как вы можете видеть, масти расположены в порядке возрастания от десятки до туза.
Теперь вы хотите расположить карты каждой масти в случайном порядке. Для этого вы рандомизируете расположение строк в массиве:
>>> NUMBER_OF_SUITS = 4
>>> NUMBER_OF_RANKS = 5
>>> high_deck = create_high_cards().reshape((NUMBER_OF_SUITS, NUMBER_OF_RANKS))
>>> rng = np.random.default_rng()
>>> rng.permutation(high_deck, axis=0)
array([['10♡', 'J♡', 'Q♡', 'K♡', 'A♡'],
['10♢', 'J♢', 'Q♢', 'K♢', 'A♢'],
['10♣', 'J♣', 'Q♣', 'K♣', 'A♣'],
['10♠', 'J♠', 'Q♠', 'K♠', 'A♠']], dtype='<U3')
>>> rng.permutation(high_deck, axis=0)
array([['10♢', 'J♢', 'Q♢', 'K♢', 'A♢'],
['10♠', 'J♠', 'Q♠', 'K♠', 'A♠'],
['10♡', 'J♡', 'Q♡', 'K♡', 'A♡'],
['10♣', 'J♣', 'Q♣', 'K♣', 'A♣']], dtype='<U3')
Вы заполняете исходный массив, используя свою новую функцию create_high_deck(). На этот раз вы преобразуете массив в четыре ряда мастей и пять столбцов рангов карт. Тогда метод .permutation() работает по строкам, потому что axis=0. Он рандомизирует положение каждой строки, но содержимое каждой строки остается в исходном порядке.
Также обратите внимание, что оригинал high_deck не тронут. Предыдущие операции рандомизировали копии колоды:
>>> high_deck
array([['10♣', 'J♣', 'Q♣', 'K♣', 'A♣'],
['10♢', 'J♢', 'Q♢', 'K♢', 'A♢'],
['10♡', 'J♡', 'Q♡', 'K♡', 'A♡'],
['10♠', 'J♠', 'Q♠', 'K♠', 'A♠']], dtype='<U3')
Масти по-прежнему расположены в первоначальном порядке. Теперь предположим, что вы хотите расположить карты каждого достоинства в случайном порядке. Для этого вы рандомизируете расположение столбцов:
>>> rng.permutation(high_deck, axis=1)
array([['10♣', 'Q♣', 'A♣', 'J♣', 'K♣'],
['10♢', 'Q♢', 'A♢', 'J♢', 'K♢'],
['10♡', 'Q♡', 'A♡', 'J♡', 'K♡'],
['10♠', 'Q♠', 'A♠', 'J♠', 'K♠']], dtype='<U3')
>>> rng.permutation(high_deck, axis=1)
array([['Q♣', 'K♣', 'J♣', 'A♣', '10♣'],
['Q♢', 'K♢', 'J♢', 'A♢', '10♢'],
['Q♡', 'K♡', 'J♡', 'A♡', '10♡'],
['Q♠', 'K♠', 'J♠', 'A♠', '10♠']], dtype='<U3')
В приведенном выше коде метод .permutation() работает по столбцам, потому что axis=1. На этот раз вы произвольно расположили каждый столбец с помощью .permutation(), но содержимое каждого столбца осталось в первоначальном порядке. Как вы можете видеть, дамы заняли место десятого ряда в первом столбце, но вы заметите, что масти расположены в том же первоначальном порядке. Это потому, что вы переставили столбцы, но сохранили строки нетронутыми.
Легко запутаться при сравнении результатов этого нового метода .permutation() и вашего предыдущего метода .shuffle(). Оба метода переупорядочивают элементы массива одинаковым образом. Разница в том, что метод .permutation() создает новый массив результатов, в то время как .shuffle() обновляет исходный массив.
В примерах, которые вы только что закодировали, метод .permutation() рандомизировал исходный массив. Каждый вызов .permutation() приводил к созданию рандомизированной копии исходного массива.
Используя метод .shuffle(), вы бы заменили исходный массив на рандомизированную версию.
Как и прежде, вы начинаете с создания колоды старших карт:
>>> NUMBER_OF_SUITS = 4
>>> NUMBER_OF_RANKS = 5
>>> high_deck = create_high_cards().reshape((NUMBER_OF_SUITS, NUMBER_OF_RANKS))
Как вы можете видеть, в этой мини-колоде есть старшие карты четырех мастей. Обратите внимание на порядок расположения карточек и на тот факт, что вы ссылаетесь на них через переменную с именем high_cards.
Далее вы перетасовываете карты:
>>> rng = np.random.default_rng()
>>> rng.shuffle(high_deck, axis=0)
>>> high_deck
array([['10♢', 'J♢', 'Q♢', 'K♢', 'A♢'],
['10♠', 'J♠', 'Q♠', 'K♠', 'A♠'],
['10♡', 'J♡', 'Q♡', 'K♡', 'A♡'],
['10♣', 'J♣', 'Q♣', 'K♣', 'A♣']], dtype='<U3')
Как вы можете видеть, установка для параметра axis значения 0 привела к рандомизации порядка строк. Однако содержимое каждой строки остается неизменным.
Теперь внимательно следите за тем, что произойдет, когда вы вызовете .shuffle() во второй раз:
>>> rng.shuffle(high_deck, axis=1)
>>> high_deck
array([['J♢', 'A♢', 'K♢', '10♢', 'Q♢'],
['J♠', 'A♠', 'K♠', '10♠', 'Q♠'],
['J♡', 'A♡', 'K♡', '10♡', 'Q♡'],
['J♣', 'A♣', 'K♣', '10♣', 'Q♣']], dtype='<U3')
Опять же, как и ожидалось, поскольку вы установили для axis значение 1, порядок столбцов выбран случайным образом. Однако содержимое каждого столбца остается неизменным. Это связано с тем, что .shuffle() рандомизировал ранее рандомизированную колоду карт. В отличие от этого, .permutation() не стал бы этого делать, потому что это рандомизировало бы исходную, нерандомизированную версию колоды.
В заключение, вы можете заставить и .permutation(), и .shuffle() выполнять одно и то же действие. Для этого вы могли бы использовать high_cards=rng.permutation(high_cards, axis=0) или rng.shuffle(high_cards, axis=0). Однако помните, что ваши результаты, вероятно, будут отличаться из-за эффекта рандомизации.
Метод .permuted() рандомизирует элементы строк или столбцов независимо от других строк или столбцов и помещает результат в новый массив. Лучше всего это видно на примере.
Предположим, вы хотите перепутать строки:
>>> NUMBER_OF_SUITS = 4
>>> NUMBER_OF_RANKS = 5
>>> high_deck = create_high_cards().reshape((NUMBER_OF_SUITS, NUMBER_OF_RANKS))
>>> rng = np.random.default_rng()
>>> rng.permuted(high_deck, axis=0)
array([['10♡', 'J♠', 'Q♠', 'K♠', 'A♠'],
['10♢', 'J♣', 'Q♡', 'K♣', 'A♣'],
['10♣', 'J♡', 'Q♣', 'K♢', 'A♡'],
['10♠', 'J♢', 'Q♢', 'K♡', 'A♢']], dtype='<U3')
Метод .permuted() работает с исходным массивом по строкам (axis=0). Другими словами, он изменяет содержимое каждой строки независимо от других строк. На практике это означает, что в каждом столбце случайным образом переставляются элементы. В каждом столбце по-прежнему содержатся одни и те же карты, но их порядок выбран случайным образом. В результате в строках будут разные масти. Другими словами, вы случайным образом перетасовали все карты номиналов.
Как вы, наверное, догадались, вы также можете перепутать столбцы:
>>> rng.permuted(high_deck, axis=1)
array([['J♣', 'A♣', '10♣', 'Q♣', 'K♣'],
['K♢', 'A♢', 'J♢', 'Q♢', '10♢'],
['J♡', 'K♡', '10♡', 'Q♡', 'A♡'],
['J♠', 'Q♠', 'A♠', '10♠', 'K♠']], dtype='<U3')
На этот раз вы работаете с исходным массивом по столбцам (axis=1). Теперь вы меняете содержимое каждого столбца независимо от других столбцов. Практически вы произвольно переставляете элементы в каждой строке. В каждом ряду по-прежнему одни и те же карты, но их порядок изменен случайным образом. В результате в столбцах отображаются карты разных мастей. Другими словами, вы случайным образом перетасовали карты одинаковой масти.
Наконец, предположим, что вы хотите полностью рандомизировать колоду:
>>> rng.permuted(rng.permuted(high_deck, axis=1), axis=0)
array([['A♡', 'Q♡', 'A♢', 'K♡', 'J♡'],
['Q♢', 'Q♠', '10♡', 'J♠', 'K♣'],
['10♠', 'J♣', 'K♠', 'A♣', 'K♢'],
['Q♣', 'J♢', '10♣', '10♢', 'A♠']], dtype='<U3')
Чтобы выполнить полную перетасовку, вы вызываете метод .permuted() дважды — сначала по строкам, а затем по столбцам. В результате вы произвольно распределили все элементы. На этот раз вы перетасовали всю колоду, так что она готова к раздаче. Также обратите внимание, что в качестве альтернативы вы можете использовать rng.permuted(rng.permuted(high_cards, axis=0), axis=1). Это все равно приведет к рандомизации всей колоды до одинакового уровня.
Выбор случайных выборок Пуассона
Распределение Пуассона - это популярное распределение вероятностей, которое вы можете использовать для определения вероятности того, что произойдет определенное количество событий, предполагая, что вам известно среднее число таких событий. Обычно это измеряется в течение определенного периода времени.
В качестве примера проблем, которые может помочь вам решить статистическое распределение Пуассона, рассмотрим следующее. Предположим, школьный отдел безопасности хочет изучить ситуацию с дорожным движением возле школы. Они знают, что в среднем один автомобиль проезжает мимо школы каждые пятнадцать секунд. Отдел безопасности хочет знать вероятность каждого из следующих событий:
- Ни одна машина не проедет мимо в данную минуту.
- В любую минуту могут проехать четыре машины.
- В любую минуту могут проехать восемь машин.
Чтобы вычислить это, вы используете массовую функцию вероятности Пуассона (PMF).
Вероятность того, что некоторая случайная величина, X, примет некоторое дискретное значение, k, определяется следующим образом:

Здесь λ - это среднее число событий, которые, как вы ожидаете, произойдут в рассматриваемом масштабе времени, e - это Постоянная Эйлера (2,72), а k - это число событий, вероятность которых вы хотите определить.
Оглядываясь на пример с автомобилями, вы можете предположить, что ответы соответствуют распределению Пуассона. В примере предлагается определить вероятности проезда нулевого, четырех и восьми автомобилей в течение одной минуты. Первое значение, которое вам нужно определить, - это λ. Вы знаете, что один автомобиль проезжает в среднем каждые пятнадцать секунд, поэтому среднее количество автомобилей, проезжающих в минуту, равно четырем. Это означает, что λ равно четырем.
Затем вам нужно использовать приведенную выше формулу для вычисления вероятностей. Вы можете сделать это с помощью следующего кода:
>>> import math
>>> lam = 4
>>> cars_per_minute = [0, 4, 8]
>>> for cars in cars_per_minute:
... probability = lam**cars * math.exp(-lam) / math.factorial(cars)
... print(f"P({cars}) = {probability:.1%}")
...
'P(0) = 1.8%'
'P(4) = 19.5%'
'P(8) = 3.0%'
Вы установили значение лямбда-параметра lam равным четырем и добавили в список желаемый набор из k значений, cars_per_minute. Вы ввели каждый элемент списка в формулу и распечатали результаты.
Главное, что вам следует извлечь из его примера, это то, что все три ответа — 1,8, 19,5 и 3,0 процента — соответствуют распределению вероятностей Пуассона.
Чтобы вы могли наглядно представить это, вы могли бы снова выполнить предыдущий расчет с большим количеством значений и построить их график. Один из способов сделать это - воспользоваться возможностями векторизации в NumPy:
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import factorial
lam = 4
k_values = np.arange(0, 30)
probabilities = np.power(lam, k_values) * np.exp(-lam) / factorial(k_values)
plt.plot(k_values, probabilities, "ro")
plt.title("Sample Poisson Distribution.")
plt.xlabel("k")
plt.ylabel("P(k)")
plt.show()
Для создания графика необходимо установить и импортировать две дополнительные библиотеки. Библиотека matplotlib.pyplot позволяет создавать визуализацию данных. Библиотека scipy.special содержит функцию factorial(), которая может работать с каждым элементом массива NumPy.
В коде снова предполагается, что лямбда-значение равно четырем, но на этот раз вычисляется вероятность тридцати k значений, начинающихся с нуля. Это достигается путем передачи в функцию scipy.special.factorial() массива NumPy из тридцати чисел, от 0 до 29. Полученный график представляет собой форму кривой распределения Пуассона:

Форма этой кривой показывает, что данные соответствуют распределению Пуассона. Она показывает, что наиболее вероятным событием является 20-процентный, или 0,2-процентный шанс того, что четыре автомобиля проедут мимо школы в любую выбранную минуту. Вероятность этого резко возрастает до четырех автомобилей, а затем снова быстро снижается. Например, крайне маловероятно, что десять или более автомобилей проедут мимо школы в любую выбранную минуту.
Как вы сейчас увидите, можно сгенерировать ряд данных случайной выборки, которые соответствуют распределению Пуассона. Чтобы достичь этого, вы вызываете метод .poisson() объекта Generator.
Метод poisson() принимает два параметра: lam и size. Параметр lam принимает известное лямбда-значение для рассматриваемых данных. В предыдущем примере это было бы 4. Параметр size определяет количество и формат создаваемых данных.
Прежде чем вы увидите несколько примеров этого в действии, имейте в виду, что вы генерируете случайные значения, соответствующие распределению Пуассона. Существует несколько контекстов, в которых вы могли бы это сделать. Сгенерированные числа могут, например, относиться к современному примеру, когда автомобили проезжают мимо школы за определенную минуту, к историческим событиям, таким как случайная гибель солдат в прусской армии от удара лошади, или к чему угодно еще.
Можно сгенерировать одно число, массив чисел или многомерный массив чисел, все из которых относятся к распределению Пуассона:
>>> import numpy as np
>>> rng = np.random.default_rng()
>>> scalar = rng.poisson(lam=5)
>>> scalar
4
>>> sample_1d_array = rng.poisson(lam=5, size=4)
>>> sample_1d_array
array([4, 9, 6, 3], dtype=int64)
>>> sample_2d_array = rng.poisson(lam=5, size=(2, 3))
>>> sample_2d_array
array([[6, 6, 6],
[4, 1, 7]], dtype=int64)
Первая выборка, scalar, содержит одно число. Вы ничего не можете сказать о выборочном распределении одного числа, но повторный вызов rng.poisson() приведет к набору чисел, которые соответствуют распределению Пуассона.
Вторая выборка, sample_1d_array, содержит одномерный массив из четырех чисел Пуассона. Последняя выборка, sample_2d_array, содержит массив пуассоновских переменных, распределенных случайным образом, размером два на три. Вы можете взять столько образцов, сколько захотите, в любом количестве измерений, которое вам нравится.
Чтобы показать, что данные из .poisson() соответствуют распределению Пуассона, вы можете построить график выходных данных метода:
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng()
samples = rng.poisson(lam=5, size=10_000)
values, frequency = np.unique(samples, return_counts=True)
plt.title("Random Poisson Distribution.")
plt.xlabel("Values")
plt.ylabel("Frequency")
plt.plot(values, frequency, "ro")
plt.show()
С помощью этого кода вы создаете следующий график:
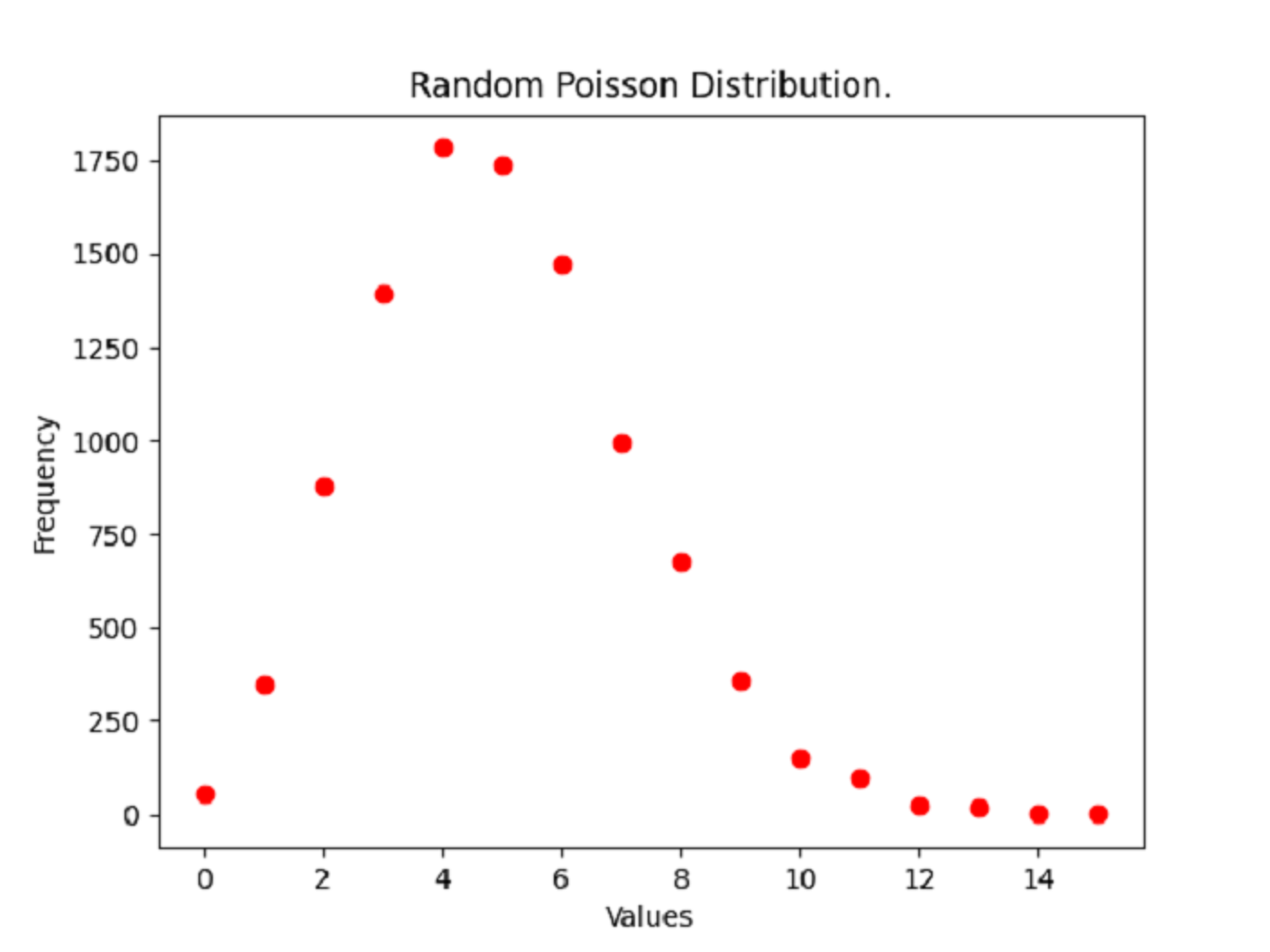
Сначала вы генерируете массив NumPy из десяти тысяч случайных значений samples из распределения Пуассона, значение которого λ равно 5. Функция NumPy unique() затем создает частотное распределение путем подсчета каждого уникального значения sample. Затем вы строите график частоты каждого отдельного значения, и форма графика доказывает, что десять тысяч случайных значений samples соответствуют распределению Пуассона.
Заключение
Теперь вы знакомы с тем, как работает генерация псевдослучайных чисел и какие функции генерации случайных чисел предлагает NumPy. Вы можете использовать свои новые навыки для генерации случайных чисел как по отдельности, так и в виде массивов NumPy. Вы знаете, как выбирать случайные элементы, строки и столбцы из массива и как их рандомизировать. Наконец, вы получили представление о том, как NumPy поддерживает случайный выбор из статистических распределений.
В этом уроке вы узнали:
- Как компьютеры выполняют генерацию псевдослучайных чисел
- Как генерировать числовые массивы случайных чисел
- Как рандомизировать массивы NumPy
- Как случайным образом выбирать элементы, строки и столбцы из массива NumPy
- Как выбрать случайные выборки из Статистического распределения Пуассона
Если вы хотите продолжить изучение возможностей NumPy, то вашим следующим шагом может стать изучение получения нормально распределенных случайных чисел. Если вам нужно еще больше, то вы можете ознакомиться с диапазоном статистических методов объекта Generator в документации NumPy.
Есть ли у вас интересный пример использования случайных чисел? Возможно, у вас есть карточный фокус, которым вы можете развлечь своих коллег-программистов, или лотерейный предсказатель, который может сделать всех нас богатыми. Поделитесь своими идеями с сообществом в комментариях ниже.
Бесплатный бонус: Нажмите здесь, чтобы загрузить пример кода, который показывает, как получать случайные числа с помощью NumPy.
<статус завершения статьи-slug="numpy-генератор случайных чисел" class="btn-group mb-0" data-api-статья-закладка-url="/api/v1/articles/генератор случайных чисел/закладка/" data-api-article-completion-status-url="/api/v1/articles/numpy-random-number-generator/completion_status/"> <кнопка поделиться bluesky-text="Интересная статья о #Python от @realpython.com:" электронная почта-body="Ознакомьтесь с этой статьей о Python:%0A%0 Приостановка работы генератора случайных чисел NumPy" email-subject="Статья о Python для вас" twitter-text="Интересная статья о Python от @realpython:" url="https://realpython.com/numpy-генератор случайных чисел/" url-title="С помощью генератора случайных чисел NumPy">
Back to Top