Использование pandas и Python для изучения вашего набора данных
Оглавление
- Настройка Вашей среды
- Использование библиотеки Python pandas
- Знакомство с Вашими данными
- Знакомство со структурами данных pandas
- Доступ к элементам серии
- Доступ к элементам фрейма данных
- Запрос к Вашему набору данных
- Группировка и обобщение Ваших данных
- Манипулирование столбцами
- Указание типов данных
- Очистка данных
- Объединение нескольких наборов данных
- Визуализация вашего фрейма данных pandas
- Заключение
У вас есть большой набор данных, полный интересных идей, но вы не уверены, с чего начать их изучение? Просил ли вас ваш начальник сгенерировать из него какую-нибудь статистику, но извлечь ее не так-то просто? Это как раз те варианты использования, в которых вам могут помочь pandas и Python! С помощью этих инструментов вы сможете разделить большой набор данных на управляемые части и извлечь из этой информации полезную информацию.
В этом руководстве вы узнаете, как:
- Рассчитайте показатели ваших данных
- Выполнение основных запросов и агрегаций
- Обнаруживайте и обрабатывайте неверные данные, несоответствия и пропущенные значения
- Визуализируйте свои данные с помощью графиков
Вы также узнаете о различиях между основными структурами данных, которые используют pandas и Python.
Настройка Вашей среды
Есть несколько вещей, которые вам понадобятся, чтобы начать работу с этим руководством. Во-первых, это знакомство со встроенными структурами данных Python, особенно со списками и словарями. Для получения дополнительной информации ознакомьтесь с Списками и кортежами в Python и Словарями в Python.
Второе, что вам понадобится, - это рабочая среда Python . Вы можете использовать любой терминал, на котором установлен Python 3. Если вы хотите получить более качественный результат, особенно для большого набора данных NBA, с которым вы будете работать, то, возможно, вам захочется запустить примеры в записной книжке Jupyter.
Последнее, что вам понадобится, это pandas и другие библиотеки Python, которые вы можете установить с помощью pip:
$ python3 -m pip install requests pandas matplotlib
Вы также можете использовать Conda менеджер пакетов:
$ conda install requests pandas matplotlib
Если вы используете дистрибутив Anaconda, то все готово! Anaconda уже поставляется с установленной библиотекой pandas Python.
Примечание: Слышали ли вы, что в мире Python существует несколько менеджеров пакетов, и вы несколько запутались, какой из них выбрать? pip и conda - отличные варианты, и у каждого из них есть свои преимущества.
Если вы собираетесь использовать Python в основном для работы с данными, то, возможно, лучшим выбором будет conda. В экосистеме conda у вас есть две основные альтернативы:
- Если вы хотите быстро запустить стабильную среду обработки данных и не возражаете против загрузки 500 МБ данных, ознакомьтесь с дистрибутивом Anaconda.
- Если вы предпочитаете более минималистичную настройку, ознакомьтесь с разделом об установке Miniconda в Настройка Python для машинного обучения в Windows.
Примеры в этом руководстве были протестированы с Python 3.7 и pandas 0.25.0, но они также должны работать в более старых версиях. Вы можете ознакомиться со всеми примерами кода, которые увидите в этом руководстве, в записной книжке Jupyter, перейдя по ссылке ниже:
Получите записную книжку Jupyter: Нажмите здесь, чтобы получить записную книжку Jupyter, которую вы будете использовать для изучения данных с помощью Pandas в этом руководстве.
Давайте начнем!
Использование библиотеки Python pandas
Теперь, когда вы установили pandas, пришло время взглянуть на набор данных. В этом руководстве вы проанализируете результаты NBA, предоставленные FiveThirtyEight в CSV-файле размером 17 МБ . Создайте скрипт download_nba_all_elo.py для загрузки данных:
import requests
download_url = "https://raw.githubusercontent.com/fivethirtyeight/data/master/nba-elo/nbaallelo.csv"
target_csv_path = "nba_all_elo.csv"
response = requests.get(download_url)
response.raise_for_status() # Check that the request was successful
with open(target_csv_path, "wb") as f:
f.write(response.content)
print("Download ready.")
Когда вы запустите скрипт, он сохранит файл nba_all_elo.csv в вашем текущем рабочем каталоге.
Примечание: Вы также можете использовать свой веб-браузер для загрузки CSV-файла.
Однако наличие скрипта загрузки имеет ряд преимуществ:
- Вы можете указать, откуда у вас данные.
- Вы можете повторить загрузку в любое время! Это особенно удобно, если данные часто обновляются.
- Вам не нужно делиться CSV-файлом размером 17 МБ со своими коллегами. Обычно этого достаточно, чтобы поделиться скриптом загрузки.
Теперь вы можете использовать библиотеку pandas Python, чтобы просмотреть свои данные:
>>> import pandas as pd
>>> nba = pd.read_csv("nba_all_elo.csv")
>>> type(nba)
<class 'pandas.core.frame.DataFrame'>
Здесь вы следуете соглашению об импорте pandas в Python с псевдонимом pd. Затем вы используете .read_csv() для чтения в вашем наборе данных и сохраняете его как DataFrame объект в переменной nba.
Примечание: Ваши данные не в формате CSV? Не беспокойтесь! Библиотека Python pandas предоставляет несколько похожих функций, таких как read_json(), read_html(), и read_sql_table(). Чтобы узнать, как работать с этими форматами файлов, ознакомьтесь с Чтение и запись файлов с помощью pandas или обратитесь к документации .
Вы можете увидеть, сколько данных содержит nba:
>>> len(nba)
126314
>>> nba.shape
(126314, 23)
Вы используете встроенную функцию Python len() для определения количества строк. Вы также можете использовать атрибут .shape для DataFrame, чтобы увидеть его размерность . Результатом будет кортеж, содержащий количество строк и столбцов.
Теперь вы знаете, что в вашем наборе данных 126 314 строк и 23 столбца. Но как вы можете быть уверены, что набор данных действительно содержит статистику по баскетболу? Вы можете взглянуть на первые пять строк с помощью .head():
>>> nba.head()
Если вы используете Jupyter notebook, то увидите примерно такой результат:
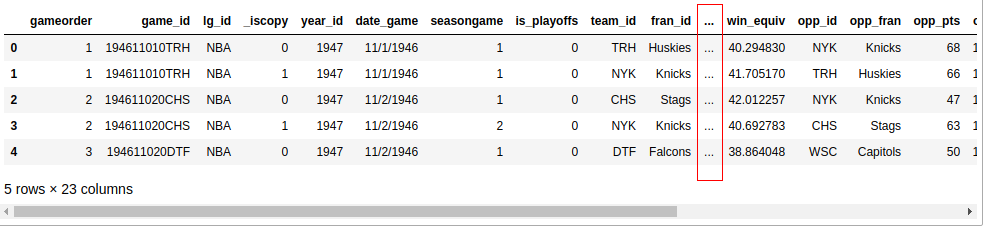
Если у вас экран не очень большой, то, скорее всего, в выходных данных не будут отображаться все 23 столбца. Где-то посередине вы увидите столбец с многоточиями (...), указывающий на недостающие данные. Если вы работаете в терминале, то это, вероятно, удобнее для чтения, чем обводить длинные строки. Однако Jupyter notebooks позволит вам выполнять прокрутку. Вы можете настроить pandas так, чтобы все 23 столбца отображались следующим образом:
>>> pd.set_option("display.max.columns", None)
Хотя удобно просматривать все столбцы, вам, вероятно, не понадобятся шесть знаков после запятой! Замените их на два:
>>> pd.set_option("display.precision", 2)
Чтобы убедиться, что вы успешно изменили параметры, вы можете снова выполнить .head() или отобразить последние пять строк с помощью .tail() вместо этого:
>>> nba.tail()
Теперь вы должны увидеть все столбцы, и ваши данные должны содержать два знака после запятой:

Вы можете открыть для себя некоторые дополнительные возможности .head() и .tail(), выполнив небольшое упражнение. Можете ли вы напечатать последние три строки вашего DataFrame? Разверните блок кода ниже, чтобы увидеть решение:
Вот как напечатать последние три строки nba:
>>> nba.tail(3)
Ваши выходные данные должны выглядеть примерно так:
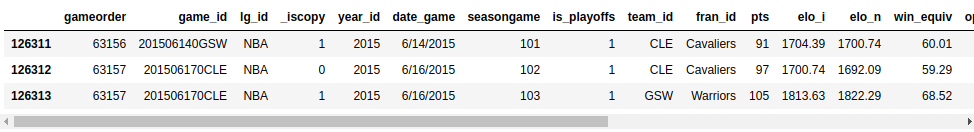
Вы можете просмотреть последние три строки вашего набора данных с параметрами, указанными выше.
Как и в стандартной библиотеке Python, функции в pandas также имеют несколько необязательных параметров. Всякий раз, когда вы сталкиваетесь с примером, который выглядит уместным, но немного отличается от вашего варианта использования, ознакомьтесь с официальной документацией. Велика вероятность, что вы найдете решение, изменив некоторые необязательные параметры!
Знакомство с Вашими данными
Вы импортировали CSV-файл с помощью библиотеки pandas Python и впервые ознакомились с содержимым вашего набора данных. Пока что вы видели только размер вашего набора данных и несколько его первых и последних строк. Далее вы узнаете, как анализировать свои данные более систематично.
Отображение типов данных
Первым шагом к знакомству с вашими данными является знакомство с различными типами данных, которые они содержат. В список можно поместить все, что угодно, но столбцы DataFrame содержат значения определенного типа данных. Сравнивая структуры данных pandas и Python, вы увидите, что такое поведение позволяет pandas работать намного быстрее!
Вы можете отобразить все столбцы и их типы данных с помощью .info():
>>> nba.info()
Это приведет к следующему результату:
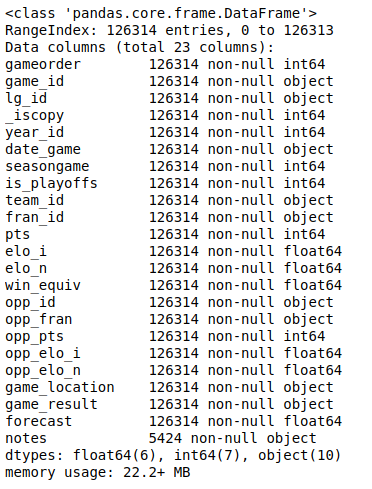
Вы увидите список всех столбцов в вашем наборе данных и тип данных, содержащихся в каждом столбце. Здесь вы можете увидеть типы данных int64, float64, и object. Для работы с этими типами pandas использует библиотеку NumPy. Позже вы познакомитесь с более сложным типом данных categorical, который реализован в библиотеке Python pandas самостоятельно.
Тип данных object является особым типом данных. Согласно кулинарной книге pandas, тип данных object - это “универсальный тип для столбцов, который pandas не распознает как какой-либо другой определенный тип.” На практике это часто означает, что все значения в столбце являются строками.
Хотя вы можете хранить произвольные объекты Python в типе данных object, вы должны знать о недостатках этого способа. Странные значения в столбце object могут ухудшить производительность pandas и его совместимость с другими библиотеками. Для получения дополнительной информации ознакомьтесь с официальным руководством по началу работы .
Отображение базовой статистики
Теперь, когда вы увидели, какие типы данных есть в вашем наборе данных, пришло время получить общее представление о значениях, содержащихся в каждом столбце. Вы можете сделать это с помощью .describe():
>>> nba.describe()
Эта функция показывает вам некоторую базовую описательную статистику для всех числовых столбцов:
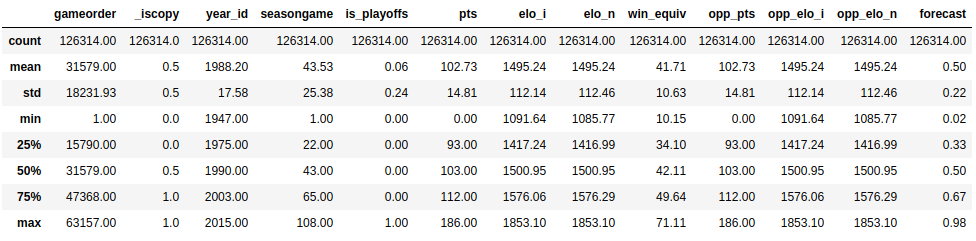
.describe() по умолчанию анализируются только числовые столбцы, но вы можете указать другие типы данных, если используете параметр include:
>>> import numpy as np
>>> nba.describe(include=object)
.describe() не будем пытаться вычислить среднее значение или стандартное отклонение для столбцов object, поскольку они в основном содержат текстовые строки. Однако некоторые описательные статистические данные все равно будут отображаться:

Взгляните на столбцы team_id и fran_id. Ваш набор данных содержит 104 различных идентификатора команды, но только 53 различных идентификатора франшизы. Кроме того, наиболее часто используемый идентификатор команды - BOS, а наиболее часто используемый идентификатор франшизы - Lakers. Как это возможно? Чтобы ответить на этот вопрос, вам нужно немного подробнее изучить свой набор данных.
Изучение вашего набора данных
Предварительный анализ данных может помочь вам ответить на вопросы о вашем наборе данных. Например, вы можете проверить, как часто определенные значения встречаются в столбце:
>>> nba["team_id"].value_counts()
BOS 5997
NYK 5769
LAL 5078
...
SDS 11
>>> nba["fran_id"].value_counts()
Name: team_id, Length: 104, dtype: int64
Lakers 6024
Celtics 5997
Knicks 5769
...
Huskies 60
Name: fran_id, dtype: int64
Похоже, что команда под названием "Lakers" провела 6024 матча, но только 5078 из них были сыграны "Лос-Анджелес Лейкерс". Узнайте, кто входит в другую команду "Lakers":
>>> nba.loc[nba["fran_id"] == "Lakers", "team_id"].value_counts()
LAL 5078
MNL 946
Name: team_id, dtype: int64
Действительно, "Миннеаполис Лейкерс" ("MNL") сыграли 946 матчей. Вы даже можете узнать, когда они играли в этих матчах. Для этого вы сначала определите столбец, который преобразует значение date_game в тип данных datetime. Затем вы можете использовать агрегатные функции min и max, чтобы найти первую и последнюю игры Minneapolis Lakers:
>>> nba["date_played"] = pd.to_datetime(nba["date_game"])
>>> nba.loc[nba["team_id"] == "MNL", "date_played"].min()
Timestamp('1948-11-04 00:00:00')
>>> nba.loc[nba['team_id'] == 'MNL', 'date_played'].max()
Timestamp('1960-03-26 00:00:00')
>>> nba.loc[nba["team_id"] == "MNL", "date_played"].agg(("min", "max"))
min 1948-11-04
max 1960-03-26
Name: date_played, dtype: datetime64[ns]
Похоже, что "Миннеаполис Лейкерс" играли между 1948 и 1960 годами. Это объясняет, почему вы можете не узнать эту команду!
Вы также узнали, почему команда "Бостон Селтикс" "BOS" провела больше всего матчей в наборе данных. Давайте также немного проанализируем их историю. Узнайте, сколько очков набрал "Бостон Селтикс" во всех матчах, содержащихся в этом наборе данных. Раскройте приведенный ниже блок кода для решения:
Аналогично агрегатным функциям .min() и .max(), вы также можете использовать .sum():
>>> nba.loc[nba["team_id"] == "BOS", "pts"].sum()
626484
"Бостон Селтикс" набрал в общей сложности 626 484 очка.
Вы уже оценили возможности pandas DataFrame. В следующих разделах вы подробно расскажете о методах, которые только что использовали, но сначала вы увеличите масштаб и узнаете, как работает эта мощная структура данных.
Знакомство со структурами данных pandas
В то время как DataFrame предоставляет функции, которые могут показаться довольно интуитивно понятными, базовые концепции немного сложнее для понимания. По этой причине вы отложите в сторону огромный NBA DataFrame и создадите несколько небольших объектов pandas с нуля.
Понимание объектов серии
Самой базовой структурой данных в Python является список, который также является хорошей отправной точкой для знакомства с объектами. pandas.Series Создайте новый Series объект на основе списка:
>>> revenues = pd.Series([5555, 7000, 1980])
>>> revenues
0 5555
1 7000
2 1980
dtype: int64
Вы использовали список [5555, 7000, 1980] для создания Series объекта с именем revenues. Объект Series содержит два компонента:
- Последовательность значений
- Последовательность идентификаторов, которая является индексом
Вы можете получить доступ к этим компонентам с помощью .values и .index соответственно:
>>> revenues.values
array([5555, 7000, 1980])
>>> revenues.index
RangeIndex(start=0, stop=3, step=1)
revenues.values возвращает значения в Series, тогда как revenues.index возвращает позиционный индекс.
Примечание: Если вы знакомы с NumPy, то вам, возможно, будет интересно отметить, что значения Series объекты на самом деле являются n-мерными массивами:
>>> type(revenues.values)
<class 'numpy.ndarray'>
Если вы не знакомы с NumPy, то беспокоиться не о чем! Вы можете изучить все тонкости своего набора данных, используя только библиотеку pandas Python. Однако, если вам интересно, что pandas делает за кулисами, ознакомьтесь с Смотри, Мама, без for Циклов: Программирование массивов с помощью NumPy.
В то время как pandas основан на NumPy, существенная разница заключается в их индексации. Так же, как и массив NumPy, pandas Series также имеет неявно определенный целочисленный индекс. Этот неявный индекс указывает позицию элемента в Series.
Однако Series также может иметь индекс произвольного типа. Вы можете рассматривать этот явный индекс как метки для определенной строки:
>>> city_revenues = pd.Series(
... [4200, 8000, 6500],
... index=["Amsterdam", "Toronto", "Tokyo"]
... )
>>> city_revenues
Amsterdam 4200
Toronto 8000
Tokyo 6500
dtype: int64
Здесь индекс представляет собой список названий городов, представленных строками. Возможно, вы заметили, что словари Python также используют строковые индексы, и это удобная аналогия, о которой стоит помнить! Вы можете использовать приведенные выше блоки кода, чтобы различать два типа Series:
revenues: ЭтотSeriesведет себя как список Python, потому что у него есть только позиционный индекс.city_revenues: ЭтотSeriesдействует как словарь Python, поскольку содержит как позиционный, так и метрический индекс.
Вот как создать Series с индексом метки из словаря Python:
>>> city_employee_count = pd.Series({"Amsterdam": 5, "Tokyo": 8})
>>> city_employee_count
Amsterdam 5
Tokyo 8
dtype: int64
Ключи словаря становятся индексом, а значения словаря - значениями Series.
так же, как словари, Series также поддерживает .keys() и in сайта:
>>> city_employee_count.keys()
Index(['Amsterdam', 'Tokyo'], dtype='object')
>>> "Tokyo" in city_employee_count
True
>>> "New York" in city_employee_count
False
Вы можете использовать эти методы, чтобы быстро ответить на вопросы о вашем наборе данных.
Понимание объектов фрейма данных
Хотя Series является довольно мощной структурой данных, у нее есть свои ограничения. Например, вы можете хранить только один атрибут для каждого ключа. Как вы видели на примере набора данных nba, который содержит 23 столбца, библиотека Python pandas может предложить больше благодаря своей DataFrame. Эта структура данных представляет собой последовательность Series объектов, которые имеют один и тот же индекс.
Если вы следовали всем Series примерам, то у вас уже должны быть два Series объекта с городами в качестве ключей:
city_revenuescity_employee_count
Вы можете объединить эти объекты в DataFrame, указав словарь в конструкторе. Ключи словаря станут именами столбцов, а значения должны содержать объекты Series:
>>> city_data = pd.DataFrame({
... "revenue": city_revenues,
... "employee_count": city_employee_count
... })
>>> city_data
revenue employee_count
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN
Обратите внимание, как pandas заменил отсутствующее значение employee_count для Toronto на NaN.
Новый индекс DataFrame является объединением двух индексов Series:
>>> city_data.index
Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object')
Так же, как и Series, DataFrame также хранит свои значения в массиве NumPy:
>>> city_data.values
array([[4.2e+03, 5.0e+00],
[6.5e+03, 8.0e+00],
[8.0e+03, nan]])
Вы также можете ссылаться на 2 измерения DataFrame как на оси:
>>> city_data.axes
[Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object'),
Index(['revenue', 'employee_count'], dtype='object')]
>>> city_data.axes[0]
Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object')
>>> city_data.axes[1]
Index(['revenue', 'employee_count'], dtype='object')
Ось, отмеченная 0, соответствует индексу строки, а ось, отмеченная 1, соответствует индексу столбца. Важно знать эту терминологию, потому что вы столкнетесь с несколькими DataFrame методами, которые принимают параметр axis.
A DataFrame также является словарной структурой данных, поэтому она также поддерживает .keys() и ключевое слово in. Однако для DataFrame они относятся не к индексу, а к столбцам:
>>> city_data.keys()
Index(['revenue', 'employee_count'], dtype='object')
>>> "Amsterdam" in city_data
False
>>> "revenue" in city_data
True
Вы можете увидеть эти концепции в действии на примере более крупного набора данных NBA. Содержит ли он столбец с именем "points" или он назывался "pts"? Чтобы ответить на этот вопрос, выведите индекс и оси набора данных nba, затем разверните приведенный ниже блок кода для решения:
Поскольку вы не указали столбец индекса при чтении в CSV-файле, pandas присвоил RangeIndex столбцу DataFrame:
>>> nba.index
RangeIndex(start=0, stop=126314, step=1)
nba, как и все объекты DataFrame, имеет две оси:
>>> nba.axes
[RangeIndex(start=0, stop=126314, step=1),
Index(['gameorder', 'game_id', 'lg_id', '_iscopy', 'year_id', 'date_game',
'seasongame', 'is_playoffs', 'team_id', 'fran_id', 'pts', 'elo_i',
'elo_n', 'win_equiv', 'opp_id', 'opp_fran', 'opp_pts', 'opp_elo_i',
'opp_elo_n', 'game_location', 'game_result', 'forecast', 'notes'],
dtype='object')]
Вы можете проверить существование столбца с помощью .keys():
>>> "points" in nba.keys()
False
>>> "pts" in nba.keys()
True
Столбец называется "pts", а не "points".
Когда вы будете использовать эти методы для ответа на вопросы о вашем наборе данных, обязательно учитывайте, работаете ли вы с Series или с DataFrame, чтобы ваша интерпретация была точной.
Доступ к элементам серии
В предыдущем разделе вы создали pandas Series на основе списка Python и сравнили две структуры данных. Вы видели, что объект Series во многом похож на списки и словари. Еще одно сходство заключается в том, что вы можете использовать оператор индексации ([]) и для Series.
Вы также узнаете, как использовать два метода доступа, специфичных для pandas :
.loc.iloc
Вы увидите, что эти методы доступа к данным могут быть гораздо более удобочитаемыми, чем оператор индексирования.
С помощью оператора индексации
Напомним, что Series имеет два индекса:
- Позиционный или неявный индекс, который всегда является
RangeIndex - Метка или явный индекс, который может содержать любые хэшируемые объекты
Затем вернитесь к объекту city_revenues:
>>> city_revenues
Amsterdam 4200
Toronto 8000
Tokyo 6500
dtype: int64
Вы можете легко получить доступ к значениям в Series как с помощью меток, так и с помощью позиционных индексов:
>>> city_revenues["Toronto"]
8000
>>> city_revenues[1]
8000
Вы также можете использовать отрицательные индексы и срезы, как и для списка:
>>> city_revenues[-1]
6500
>>> city_revenues[1:]
Toronto 8000
Tokyo 6500
dtype: int64
>>> city_revenues["Toronto":]
Toronto 8000
Tokyo 6500
dtype: int64
Если вы хотите узнать больше о возможностях оператора индексирования, ознакомьтесь с Списками и кортежами в Python.
Используя .loc и .iloc
Оператор индексации ([]) удобен, но есть один нюанс. Что, если метки также являются числами? Допустим, вам нужно работать с Series объектом, подобным этому:
>>> colors = pd.Series(
... ["red", "purple", "blue", "green", "yellow"],
... index=[1, 2, 3, 5, 8]
... )
>>> colors
1 red
2 purple
3 blue
5 green
8 yellow
dtype: object
Что вернет colors[1]? Для позиционного индекса colors[1] равно "purple". Однако, если вы ориентируетесь по индексу метки, то colors[1] относится к "red".
Хорошая новость в том, что вам не нужно в этом разбираться! Вместо этого, чтобы избежать путаницы, библиотека Python pandas предоставляет два метода доступа к данным:
.locотносится к индексу метки ..ilocотносится к позиционному индексу .
Эти методы доступа к данным гораздо более удобочитаемы:
>>> colors.loc[1]
'red'
>>> colors.iloc[1]
'purple'
colors.loc[1] возвращено "red", элемент с меткой 1. colors.iloc[1] возвращено "purple", элемент с индексом 1.
На следующем рисунке показано, к каким элементам относятся .loc и .iloc:
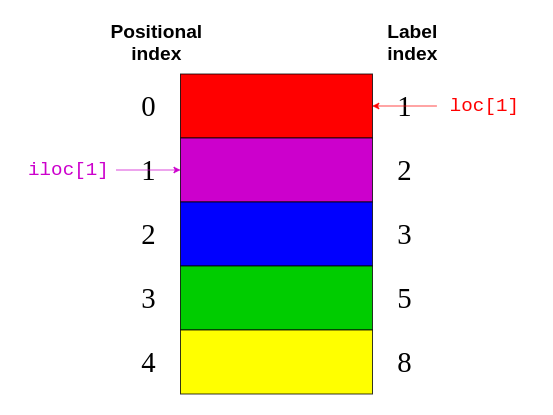
Опять же, .loc указывает на индекс метки в правой части изображения. Между тем, .iloc указывает на позиционный индекс в левой части рисунка.
Проще помнить о различии между .loc и .iloc, чем вычислять, что вернет оператор индексации. Даже если вы знакомы со всеми особенностями оператора индексации, может быть опасно предполагать, что все, кто читает ваш код, также усвоили эти правила!
Примечание: Помимо того, что оператор индексирования Python сбивает с толку Series числовыми метками, он имеет некоторые недостатки в производительности. Его вполне можно использовать в интерактивных сессиях для специального анализа, но для производственного кода предпочтительнее методы доступа к данным .loc и .iloc. Для получения более подробной информации ознакомьтесь с разделом Руководства пользователя pandas, посвященным индексированию и выбору данных.
.loc и .iloc также поддерживают функции, которые вы ожидаете от операторов индексации, такие как нарезка. Однако эти методы доступа к данным имеют важное отличие. В то время как .iloc исключает закрывающий элемент, .loc включает его. Взгляните на этот блок кода:
>>> # Return the elements with the implicit index: 1, 2
>>> colors.iloc[1:3]
2 purple
3 blue
dtype: object
Если вы сравните этот код с изображением выше, то увидите, что colors.iloc[1:3] возвращает элементы с позиционными индексами из 1 и 2. Закрывающий элемент "green" с позиционным индексом 3 исключен.
С другой стороны, .loc содержит закрывающий элемент:
>>> # Return the elements with the explicit index between 3 and 8
>>> colors.loc[3:8]
3 blue
5 green
8 yellow
dtype: object
В этом блоке кода указано возвращать все элементы с индексом метки между 3 и 8. Здесь закрывающий элемент "yellow" имеет индекс метки 8 и включен в выходные данные.
Вы также можете передать отрицательный позиционный индекс в .iloc:
>>> colors.iloc[-2]
'green'
Вы начинаете с конца Series и возвращаете второй элемент.
Примечание: Раньше существовал .ix индексатор, который пытался угадать, следует ли ему применять позиционную индексацию или индексацию меток в зависимости от типа данных индекса. Поскольку это вызвало много путаницы, оно было признано устаревшим начиная с версии pandas 0.20.0.
Настоятельно рекомендуется не использовать .ix для индексации. Вместо этого всегда используйте .loc для индексации меток и .iloc для позиционной индексации. Для получения более подробной информации ознакомьтесь с Руководством пользователя pandas.
Вы можете использовать приведенные выше блоки кода, чтобы различать два варианта поведения Series:
- Вы можете использовать
.ilocв спискеSeriesаналогично использованию[]в списке . - Вы можете использовать
.locв словареSeriesаналогично использованию[]в словаре .
Обязательно учитывайте эти различия при доступе к элементам ваших объектов Series.
Доступ к элементам фрейма данных
Поскольку DataFrame состоит из Series объектов, вы можете использовать те же самые инструменты для доступа к его элементам. Принципиальным отличием является дополнительное измерение от DataFrame. Вы будете использовать оператор индексации для столбцов и методы доступа .loc и .iloc для строк.
С помощью оператора индексации
Если вы рассматриваете DataFrame как словарь, значения которого равны Series, то имеет смысл, что вы можете получить доступ к его столбцам с помощью оператора индексации:
>>> city_data["revenue"]
Amsterdam 4200
Tokyo 6500
Toronto 8000
Name: revenue, dtype: int64
>>> type(city_data["revenue"])
pandas.core.series.Series
Здесь вы используете оператор индексации, чтобы выбрать столбец с надписью "revenue".
Если имя столбца является строкой, то вы также можете использовать доступ в атрибутивном стиле с точечной нотацией:
>>> city_data.revenue
Amsterdam 4200
Tokyo 6500
Toronto 8000
Name: revenue, dtype: int64
city_data["revenue"] и city_data.revenue возвращает тот же результат.
Есть одна ситуация, когда доступ к элементам DataFrame с точечной нотацией может не сработать или привести к неожиданностям. Это когда имя столбца совпадает с атрибутом DataFrame или именем метода:
>>> toys = pd.DataFrame([
... {"name": "ball", "shape": "sphere"},
... {"name": "Rubik's cube", "shape": "cube"}
... ])
>>> toys["shape"]
0 sphere
1 cube
Name: shape, dtype: object
>>> toys.shape
(2, 2)
Операция индексирования toys["shape"] возвращает правильные данные, но операция в стиле атрибута toys.shape по-прежнему возвращает форму DataFrame. Вы должны использовать доступ в стиле атрибутов только в интерактивных сеансах или для операций чтения. Вы не должны использовать его для производственного кода или для манипулирования данными (например, для определения новых столбцов).
Используя .loc и .iloc
Аналогично Series, DataFrame также предоставляет .loc и .iloc методы доступа к данным. Помните, что в .loc используется метка, а в .iloc позиционный индекс:
>>> city_data.loc["Amsterdam"]
revenue 4200.0
employee_count 5.0
Name: Amsterdam, dtype: float64
>>> city_data.loc["Tokyo": "Toronto"]
revenue employee_count
Tokyo 6500 8.0
Toronto 8000 NaN
>>> city_data.iloc[1]
revenue 6500.0
employee_count 8.0
Name: Tokyo, dtype: float64
Каждая строка кода выбирает другую строку из city_data:
city_data.loc["Amsterdam"]выбирает строку с индексом метки"Amsterdam".city_data.loc["Tokyo": "Toronto"]выбирает строки с индексами меток от"Tokyo"до"Toronto". Помните, что.locявляется включающим.city_data.iloc[1]выбирает строку с позиционным индексом1, который является"Tokyo".
Итак, вы использовали .loc и .iloc для небольших структур данных. Теперь пришло время попрактиковаться с чем-то большим! Используйте метод доступа к данным для отображения предпоследней строки набора данных nba. Затем разверните приведенный ниже блок кода, чтобы увидеть решение:
Предпоследняя строка - это строка с позиционным индексом из -2. Вы можете отобразить его с помощью .iloc:
>>> nba.iloc[-2]
gameorder 63157
game_id 201506170CLE
lg_id NBA
_iscopy 0
year_id 2015
date_game 6/16/2015
seasongame 102
is_playoffs 1
team_id CLE
fran_id Cavaliers
pts 97
elo_i 1700.74
elo_n 1692.09
win_equiv 59.29
opp_id GSW
opp_fran Warriors
opp_pts 105
opp_elo_i 1813.63
opp_elo_n 1822.29
game_location H
game_result L
forecast 0.48
notes NaN
date_played 2015-06-16 00:00:00
Name: 126312, dtype: object
Вы увидите выходные данные в виде объекта Series.
Для DataFrame методы доступа к данным .loc и .iloc также принимают второй параметр. В то время как первый параметр выбирает строки на основе индексов, второй параметр выбирает столбцы. Вы можете использовать эти параметры вместе, чтобы выбрать подмножество строк и столбцов из вашего DataFrame:
>>> city_data.loc["Amsterdam": "Tokyo", "revenue"]
Amsterdam 4200
Tokyo 6500
Name: revenue, dtype: int64
Обратите внимание, что параметры следует разделять запятой (,). Первый параметр, "Amsterdam" : "Tokyo,", указывает на выделение всех строк между этими двумя метками. Второй параметр вводится после запятой и содержит указание выбрать столбец "revenue".
Пришло время увидеть ту же конструкцию в действии с большим набором данных nba. Выберите все игры между метками 5555 и 5559. Вас интересуют только названия команд и результаты, поэтому выберите и эти элементы. Разверните блок кода ниже, чтобы увидеть решение:
Сначала определите, какие строки вы хотите видеть, затем перечислите соответствующие столбцы:
>>> nba.loc[5555:5559, ["fran_id", "opp_fran", "pts", "opp_pts"]]
Вы используете .loc для обозначения индекса метки и запятую (,) для разделения двух ваших параметров.
Вы должны увидеть небольшую часть вашего довольно огромного набора данных:
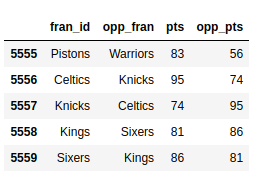
Вывод намного проще для чтения!
Используя такие методы доступа к данным, как .loc и .iloc, вы можете выбрать только нужное подмножество ваших DataFrame, которые помогут вам ответить на вопросы о вашем наборе данных.
Запрос к Вашему набору данных
Вы видели, как получить доступ к подмножествам огромного набора данных на основе его индексов. Теперь вы будете выбирать строки на основе значений в столбцах вашего набора данных для запроса ваших данных. Например, вы можете создать новый DataFrame, содержащий только игры, сыгранные после 2010 года:
>>> current_decade = nba[nba["year_id"] > 2010]
>>> current_decade.shape
(12658, 24)
Теперь у вас есть 24 столбца, но ваш новый DataFrame состоит только из строк, в которых значение в столбце "year_id" больше, чем 2010.
Вы также можете выбрать строки, в которых определенное поле не равно null:
>>> games_with_notes = nba[nba["notes"].notnull()]
>>> games_with_notes.shape
(5424, 24)
Это может быть полезно, если вы хотите избежать пропусков значений в столбце. Вы также можете использовать .notna() для достижения той же цели.
Вы даже можете обращаться к значениям типа данных object как к str и выполнять для них строковые методы:
>>> ers = nba[nba["fran_id"].str.endswith("ers")]
>>> ers.shape
(27797, 24)
Вы используете .str.endswith(), чтобы отфильтровать свой набор данных и найти все игры, в которых название домашней команды заканчивается на "ers".
Вы также можете комбинировать несколько критериев и запрашивать свой набор данных. Для этого обязательно заключите каждое из них в круглые скобки и используйте логические операторы | и &, чтобы разделить их.
Примечание: Операторы and, or, &&, и || здесь работать не будут . Если вам интересно, почему, то ознакомьтесь с разделом о том, как библиотека Python pandas использует логические операторы в Python pandas: хитрости и возможности, о которых вы, возможно, не знаете.
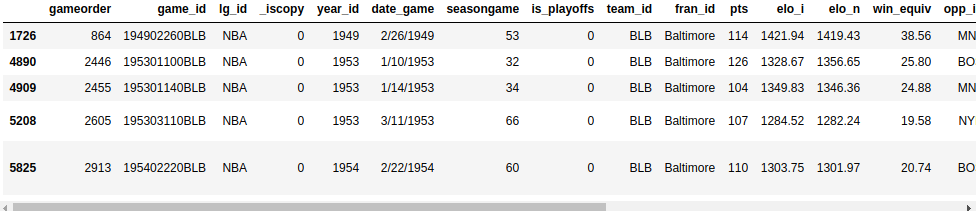
Выполните поиск игр в Балтиморе, в которых обе команды набрали более 100 очков. Чтобы просмотреть каждую игру только один раз, вам нужно исключить повторения:
>>> nba[
... (nba["_iscopy"] == 0) &
... (nba["pts"] > 100) &
... (nba["opp_pts"] > 100) &
... (nba["team_id"] == "BLB")
... ]
Здесь вы используете nba["_iscopy"] == 0, чтобы включить только те записи, которые не являются копиями.
Ваш результат должен содержать пять насыщенных событиями игр:
Попробуйте создать другой запрос с несколькими критериями. Весной 1992 года обеим командам из Лос-Анджелеса пришлось играть домашний матч на другом корте. Запросите свой набор данных, чтобы найти эти две игры. У обеих команд есть идентификаторы, начинающиеся с "LA". Разверните блок кода ниже, чтобы увидеть решение:
Вы можете использовать .str, чтобы найти идентификаторы команд, которые начинаются с "LA", и вы можете предположить, что в такой необычной игре должны быть некоторые примечания:
>>> nba[
... (nba["_iscopy"] == 0) &
... (nba["team_id"].str.startswith("LA")) &
... (nba["year_id"]==1992) &
... (nba["notes"].notnull())
... ]
В ваших выходных данных должны быть показаны две игры за день 3.05.1992:
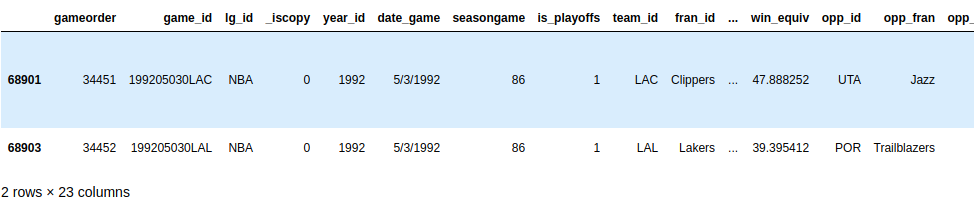
Отличная находка!
Когда вы научитесь запрашивать свой набор данных по нескольким критериям, вы сможете ответить на более конкретные вопросы о вашем наборе данных.
Группировка и обобщение Ваших данных
Возможно, вы также захотите изучить другие характеристики вашего набора данных, такие как сумма, среднее значение или усредненная величина группы элементов. К счастью, библиотека Python pandas предлагает функции группировки и агрегирования, которые помогут вам выполнить эту задачу.
В Series существует более двадцати различных методов расчета описательной статистики. Вот несколько примеров:
>>> city_revenues.sum()
18700
>>> city_revenues.max()
8000
Первый метод возвращает общее значение city_revenues, в то время как второй возвращает максимальное значение. Есть и другие методы, которые вы можете использовать, например .min() и .mean().
Помните, что столбец DataFrame на самом деле является объектом Series. По этой причине вы можете использовать те же функции для столбцов nba:
>>> points = nba["pts"]
>>> type(points)
<class 'pandas.core.series.Series'>
>>> points.sum()
12976235
В DataFrame может быть несколько столбцов, что открывает новые возможности для агрегирования, такие как группировка :
>>> nba.groupby("fran_id", sort=False)["pts"].sum()
fran_id
Huskies 3995
Knicks 582497
Stags 20398
Falcons 3797
Capitols 22387
...
По умолчанию pandas сортирует ключи группы во время вызова по .groupby(). Если вы не хотите выполнять сортировку, то передайте sort=False. Этот параметр может привести к повышению производительности.
Вы также можете сгруппировать по нескольким столбцам:
>>> nba[
... (nba["fran_id"] == "Spurs") &
... (nba["year_id"] > 2010)
... ].groupby(["year_id", "game_result"])["game_id"].count()
year_id game_result
2011 L 25
W 63
2012 L 20
W 60
2013 L 30
W 73
2014 L 27
W 78
2015 L 31
W 58
Name: game_id, dtype: int64
Вы можете попрактиковаться в этих основах с помощью упражнений. Взгляните на сезон "Голден Стэйт Уорриорз" 2014/15 годов (year_id: 2015). Сколько побед и поражений они одержали в регулярном чемпионате и плей-офф? Разверните приведенный ниже блок кода для решения:
Сначала вы можете сгруппировать по полю "is_playoffs", затем по результату:
>>> nba[
... (nba["fran_id"] == "Warriors") &
... (nba["year_id"] == 2015)
... ].groupby(["is_playoffs", "game_result"])["game_id"].count()
is_playoffs game_result
0 L 15
W 67
1 L 5
W 16
is_playoffs=0 показывает результаты регулярного чемпионата и is_playoffs=1 показывает результаты плей-офф.
В приведенных выше примерах вы лишь поверхностно ознакомились с функциями агрегирования, которые доступны вам в библиотеке Python pandas. Чтобы увидеть больше примеров их использования, ознакомьтесь с pandas GroupBy: Ваше руководство по группировке данных в Python.
Манипулирование столбцами
Вам необходимо знать, как манипулировать столбцами вашего набора данных на разных этапах процесса анализа данных. Вы можете добавлять и удалять столбцы на начальном этапе очистки данных или позже, основываясь на результатах вашего анализа.
Создайте копию вашего оригинала DataFrame для работы с:
>>> df = nba.copy()
>>> df.shape
(126314, 24)
Вы можете определить новые столбцы на основе существующих:
>>> df["difference"] = df.pts - df.opp_pts
>>> df.shape
(126314, 25)
Здесь вы использовали столбцы "pts" и "opp_pts" для создания нового столбца с именем "difference". Этот новый столбец выполняет те же функции, что и старые:
>>> df["difference"].max()
68
Здесь вы использовали функцию агрегирования .max(), чтобы найти наибольшее значение вашего нового столбца.
Вы также можете переименовать столбцы вашего набора данных. Кажется, что "game_result" и "game_location" слишком многословны, поэтому переименуйте их прямо сейчас:
>>> renamed_df = df.rename(
... columns={"game_result": "result", "game_location": "location"}
... )
>>> renamed_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 126314 entries, 0 to 126313
Data columns (total 25 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gameorder 126314 non-null int64
...
19 location 126314 non-null object
20 result 126314 non-null object
21 forecast 126314 non-null float64
22 notes 5424 non-null object
23 date_played 126314 non-null datetime64[ns]
24 difference 126314 non-null int64
dtypes: datetime64[ns](1), float64(6), int64(8), object(10)
memory usage: 24.1+ MB
Обратите внимание, что появился новый объект renamed_df. Как и некоторые другие методы обработки данных, .rename() по умолчанию возвращает новый DataFrame. Если вы хотите напрямую манипулировать исходным DataFrame, то .rename() также предоставляет параметр inplace, который вы можете задать равным True.
Ваш набор данных может содержать столбцы, которые вам не нужны. Например, Рейтинги Elo могут показаться кому-то интересными, но в этом руководстве вы не будете их анализировать. Вы можете удалить четыре столбца, относящиеся к Elo:
>>> df.shape
(126314, 25)
>>> elo_columns = ["elo_i", "elo_n", "opp_elo_i", "opp_elo_n"]
>>> df.drop(elo_columns, inplace=True, axis=1)
>>> df.shape
(126314, 21)
Помните, что в предыдущем примере вы добавили новый столбец "difference", в результате чего общее количество столбцов достигло 25. При удалении четырех столбцов Elo общее количество столбцов уменьшается до 21.
Указание типов данных
Когда вы создаете новый DataFrame, либо вызывая конструктор, либо считывая CSV-файл, pandas присваивает тип данных каждому столбцу на основе его значений. Хотя он выполняет довольно хорошую работу, он не идеален. Если вы заранее выберете правильный тип данных для своих столбцов, то сможете значительно повысить производительность своего кода.
Взгляните еще раз на столбцы набора данных nba:
>>> df.info()
Вы увидите тот же результат, что и раньше:
Десять ваших столбцов имеют тип данных object. Большинство из этих столбцов object содержат произвольный текст, но есть также несколько кандидатов для преобразования типа данных в. Например, взгляните на столбец date_game:
>>> df["date_game"] = pd.to_datetime(df["date_game"])
Здесь вы используете .to_datetime(), чтобы указать все даты игр в виде объектов datetime.
Другие столбцы содержат текст, который немного более структурирован. Столбец game_location может содержать только три разных значения:
>>> df["game_location"].nunique()
3
>>> df["game_location"].value_counts()
A 63138
H 63138
N 38
Name: game_location, dtype: int64
Какой тип данных вы бы использовали в реляционной базе данных для такого столбца? Вероятно, вы бы использовали не тип varchar, а тип enum. pandas предоставляет тип данных categorical для той же цели:
>>> df["game_location"] = pd.Categorical(df["game_location"])
>>> df["game_location"].dtype
CategoricalDtype(categories=['A', 'H', 'N'], ordered=False)
categorical данные имеют ряд преимуществ перед неструктурированным текстом. Если вы укажете тип данных categorical, вы упростите проверку и сэкономите массу памяти, поскольку pandas будет использовать только уникальные значения для внутреннего использования. Чем выше отношение общих значений к уникальным, тем больше места вы сэкономите.
Запустите df.info() еще раз. Вы должны увидеть, что изменение типа данных game_location с object на categorical привело к уменьшению использования памяти.
Примечание: Тип данных categorical также предоставляет вам доступ к дополнительным методам с помощью средства доступа .cat. Чтобы узнать больше, ознакомьтесь с официальными документами .
Вы часто будете сталкиваться с наборами данных, в которых слишком много текстовых столбцов. Важным навыком для специалистов по обработке данных является умение определять, какие столбцы они могут преобразовать в более производительный тип данных.
Потренируйтесь в этом прямо сейчас. Найдите другой столбец в наборе данных nba, который имеет общий тип данных, и преобразуйте его в более конкретный. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть одно из возможных решений:
game_result может принимать только два разных значения:
>>> df["game_result"].nunique()
2
>>> df["game_result"].value_counts()
L 63157
W 63157
Для повышения производительности вы можете преобразовать его в столбец categorical:
>>> df["game_result"] = pd.Categorical(df["game_result"])
Вы можете использовать df.info() для проверки использования памяти.
При работе с более массивными наборами данных экономия памяти становится особенно важной. При дальнейшем изучении наборов данных обязательно учитывайте производительность .
Данные для очистки
Возможно, вы удивитесь, обнаружив этот раздел в конце руководства! Обычно, прежде чем перейти к более сложному анализу, вы критически оцениваете свой набор данных, чтобы устранить любые проблемы. Однако в этом руководстве вы будете использовать методы, которые изучили в предыдущих разделах, для очистки вашего набора данных.
Пропущенные значения
Вы когда-нибудь задумывались, почему .info() показывает, сколько ненулевых значений содержит столбец? Причина в том, что это жизненно важная информация. Пустые значения часто указывают на проблему в процессе сбора данных. Они могут сделать несколько методов анализа, таких как различные типы машинного обучения, трудными или даже невозможными.
Когда вы проверите набор данных nba с помощью nba.info(), вы увидите, что он довольно аккуратный. Только столбец notes содержит нулевые значения для большинства своих строк:
Этот вывод показывает, что столбец notes содержит только 5424 ненулевых значения. Это означает, что более 120 000 строк вашего набора данных имеют нулевые значения в этом столбце.
Иногда самый простой способ справиться с записями, содержащими пропущенные значения, - это игнорировать их. Вы можете удалить все строки с пропущенными значениями, используя .dropna():
>>> rows_without_missing_data = nba.dropna()
>>> rows_without_missing_data.shape
(5424, 24)
Конечно, такого рода очистка данных не имеет смысла для вашего набора данных nba, потому что отсутствие заметок не является проблемой для игры. Но если ваш набор данных содержит миллион допустимых записей и сотню таких, в которых отсутствуют соответствующие данные, то удаление неполных записей может быть разумным решением.
Вы также можете удалить проблемные столбцы, если они не подходят для вашего анализа. Для этого снова используйте .dropna() и укажите параметр axis=1:
>>> data_without_missing_columns = nba.dropna(axis=1)
>>> data_without_missing_columns.shape
(126314, 23)
Теперь результирующий DataFrame содержит все 126 314 игр, но не содержит иногда пустой столбец notes.
Если для вашего варианта использования существует значимое значение по умолчанию, вы также можете заменить отсутствующие значения следующим образом:
>>> data_with_default_notes = nba.copy()
>>> data_with_default_notes["notes"].fillna(
... value="no notes at all",
... inplace=True
... )
>>> data_with_default_notes["notes"].describe()
count 126314
unique 232
top no notes at all
freq 120890
Name: notes, dtype: object
Здесь вы заполняете пустые строки notes строкой "no notes at all".
Недопустимые значения
Недопустимые значения могут быть еще более опасными, чем пропущенные значения. Часто вы можете выполнить анализ данных должным образом, но результаты, которые вы получаете, отличаются от ожидаемых. Это особенно важно, если ваш набор данных огромен или вы используете ручной ввод. Недопустимые значения часто сложнее обнаружить, но вы можете выполнить некоторые проверки на корректность с помощью запросов и статистических данных.
Единственное, что вы можете сделать, это проверить диапазоны ваших данных. Для этого очень удобен .describe(). Напомним, что он возвращает следующий результат:
Число year_id колеблется между 1947 и 2015 годами. Это звучит правдоподобно.
А как насчет pts? Каким может быть минимальное значение 0? Давайте посмотрим на эти игры:
>>> nba[nba["pts"] == 0]
Этот запрос возвращает одну строку:

Похоже, что игра была аннулирована. В зависимости от результатов вашего анализа, вы можете захотеть удалить ее из набора данных.
Несогласованные значения
Иногда значение само по себе может быть вполне реалистичным, но оно не согласуется со значениями в других столбцах. Вы можете определить некоторые взаимоисключающие критерии запроса и убедиться, что они не совпадают.
В наборе данных NBA значения полей pts, opp_pts и game_result должны соответствовать друг другу. Вы можете проверить это, используя атрибут .empty:
>>> nba[(nba["pts"] > nba["opp_pts"]) & (nba["game_result"] != 'W')].empty
True
>>> nba[(nba["pts"] < nba["opp_pts"]) & (nba["game_result"] != 'L')].empty
True
К счастью, оба этих запроса возвращают пустой DataFrame.
Будьте готовы к неожиданностям всякий раз, когда вы работаете с необработанными наборами данных, особенно если они были собраны из разных источников или с помощью сложного конвейера. Вы можете увидеть строки, в которых команда набрала больше очков, чем ее соперник, но все равно не выиграла — по крайней мере, согласно вашему набору данных! Чтобы избежать подобных ситуаций, обязательно добавьте дополнительные методы очистки данных в свой арсенал pandas и Python.
Объединение нескольких наборов данных
В предыдущем разделе вы узнали, как очистить беспорядочный набор данных. Другой аспект реальных данных заключается в том, что они часто состоят из нескольких частей. В этом разделе вы узнаете, как собрать эти фрагменты и объединить их в один набор данных, готовый для анализа.
Ранее вы объединили два Series объекта в DataFrame на основе их индексов. Теперь вы сделаете еще один шаг вперед и с помощью .concat() объедините city_data с другим DataFrame. Допустим, вам удалось собрать данные еще по двум городам:
>>> further_city_data = pd.DataFrame(
... {"revenue": [7000, 3400], "employee_count":[2, 2]},
... index=["New York", "Barcelona"]
... )
Этот второй DataFrame содержит информацию о городах "New York" и "Barcelona".
Вы можете добавить эти города в city_data, используя .concat():
>>> all_city_data = pd.concat([city_data, further_city_data], sort=False)
>>> all_city_data
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN
New York 7000 2.0
Barcelona 3400 2.0
Теперь новая переменная all_city_data содержит значения из обоих объектов DataFrame.
Примечание: Начиная с версии pandas 0.25.0, значение параметра sort по умолчанию равно True, но вскоре оно изменится на False. Рекомендуется указывать явное значение этого параметра, чтобы гарантировать согласованную работу вашего кода в разных версиях pandas и Python. Для получения дополнительной информации обратитесь к Руководству пользователя pandas.
По умолчанию concat() объединяется с axis=0. Другими словами, он добавляет строки. Вы также можете использовать его для добавления столбцов, указав параметр axis=1:
>>> city_countries = pd.DataFrame({
... "country": ["Holland", "Japan", "Holland", "Canada", "Spain"],
... "capital": [1, 1, 0, 0, 0]},
... index=["Amsterdam", "Tokyo", "Rotterdam", "Toronto", "Barcelona"]
... )
>>> cities = pd.concat([all_city_data, city_countries], axis=1, sort=False)
>>> cities
revenue employee_count country capital
Amsterdam 4200.0 5.0 Holland 1.0
Tokyo 6500.0 8.0 Japan 1.0
Toronto 8000.0 NaN Canada 0.0
New York 7000.0 2.0 NaN NaN
Barcelona 3400.0 2.0 Spain 0.0
Rotterdam NaN NaN Holland 0.0
Обратите внимание, что pandas добавил NaN для недостающих значений. Если вы хотите объединить только те города, которые отображаются в обоих объектах DataFrame, то вы можете задать параметру join значение inner:
>>> pd.concat([all_city_data, city_countries], axis=1, join="inner")
revenue employee_count country capital
Amsterdam 4200 5.0 Holland 1
Tokyo 6500 8.0 Japan 1
Toronto 8000 NaN Canada 0
Barcelona 3400 2.0 Spain 0
Хотя объединить данные на основе индекса проще всего, это не единственная возможность. Вы можете использовать .merge() для реализации операции объединения, аналогичной операции из SQL:
>>> countries = pd.DataFrame({
... "population_millions": [17, 127, 37],
... "continent": ["Europe", "Asia", "North America"]
... }, index= ["Holland", "Japan", "Canada"])
>>> pd.merge(cities, countries, left_on="country", right_index=True)
Здесь вы передаете параметр left_on="country" в .merge(), чтобы указать, к какому столбцу вы хотите присоединиться. В результате получается таблица большего размера DataFrame, содержащая не только данные о городах, но и о населении и континентах соответствующих стран:
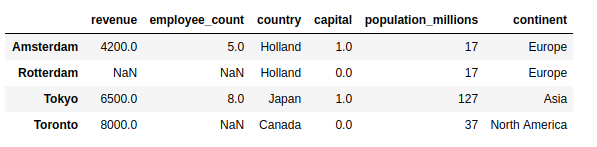
Обратите внимание, что результат содержит только города, в которых известна страна, и отображается в объединенном списке. DataFrame.
.merge() по умолчанию выполняется внутреннее объединение. Если вы хотите включить в результат все города, вам необходимо указать параметр how:
>>> pd.merge(
... cities,
... countries,
... left_on="country",
... right_index=True,
... how="left"
... )
С помощью этой left регистрации вы увидите все города, включая те, в которых нет данных о стране:
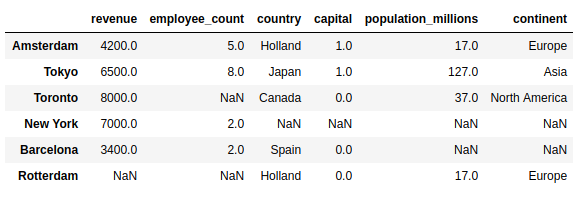
Добро пожаловать обратно, Нью-Йорк и Барселона!
Визуализация вашего фрейма данных pandas
Визуализация данных - это одна из тех вещей, которая гораздо лучше работает в ноутбуке Jupyter, чем в терминале, так что смело запускайте ее. Если вам нужна помощь в начале работы, ознакомьтесь с Jupyter Notebook: Введение. Вы также можете получить доступ к Jupyter notebook, содержащему примеры из этого руководства, перейдя по ссылке ниже:
Получите записную книжку Jupyter: Нажмите здесь, чтобы получить записную книжку Jupyter, которую вы будете использовать для изучения данных с помощью Pandas в этом руководстве.
Включите эту строку, чтобы отобразить графики непосредственно в записной книжке:
>>> %matplotlib inline
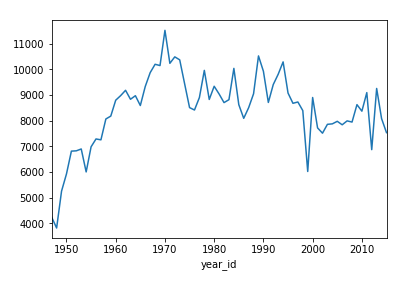
Оба объекта Series и DataFrame имеют .plot() метод, который является оболочкой для matplotlib.pyplot.plot(). По умолчанию он создает линейный график . Представьте, сколько очков "Никс" набрали за сезон:
>>> nba[nba["fran_id"] == "Knicks"].groupby("year_id")["pts"].sum().plot()
Здесь показан линейный график с несколькими пиками и двумя заметными впадинами, относящимися к 2000 и 2010 годам:
Вы также можете создавать графики других типов, например, линейчатый график :
>>> nba["fran_id"].value_counts().head(10).plot(kind="bar")
Здесь будут показаны франшизы с наибольшим количеством сыгранных игр:
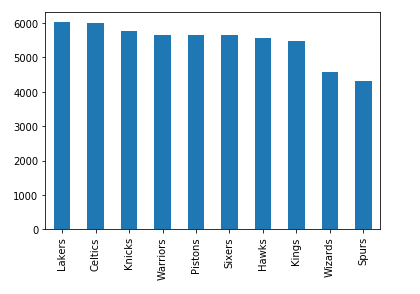
"Лейкерс" опережают "Селтикс" с минимальным преимуществом, и есть еще шесть команд с количеством игр выше 5000.
Теперь попробуйте более сложное упражнение. В 2013 году "Майами Хит" выиграли чемпионат. Создайте круговую диаграмму, показывающую количество их побед и поражений за этот сезон. Затем разверните блок кода, чтобы увидеть решение:
Сначала вы определяете критерии, по которым должны быть включены только игры The Heat 2013 года. Затем вы создаете сюжет таким же образом, как вы видели выше:
>>> nba[
... (nba["fran_id"] == "Heat") &
... (nba["year_id"] == 2013)
... ]["game_result"].value_counts().plot(kind="pie")
Вот как выглядит пирог-чемпион:
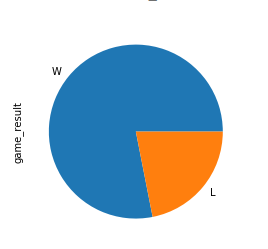
Доля выигрышей значительно больше, чем доля проигрышей!
Иногда цифры говорят сами за себя, но часто диаграмма очень помогает донести ваши идеи. Чтобы узнать больше о визуализации ваших данных, ознакомьтесь с Интерактивной визуализацией данных в Python с помощью Bokeh.
Заключение
В этом руководстве вы узнали, как начать изучение набора данных с помощью библиотеки Python pandas. Вы увидели, как можно получить доступ к определенным строкам и столбцам, чтобы управлять даже самыми большими наборами данных. Говоря об укрощении, вы также ознакомились с различными методами подготовки и очистки ваших данных, такими как указание типа данных в столбцах, устранение пропущенных значений и многое другое. Вы даже создавали запросы, агрегации и графики на их основе.
Теперь вы можете:
- Работа с
SeriesиDataFrameобъектами - Подмножество ваших данных с помощью
.loc,.iloc, и оператора индексации - Отвечайте на вопросы с помощью запросов, группировки и агрегирования
- Обрабатывайте отсутствующие, недопустимые и несогласованные данные
- Визуализируйте свой набор данных в записной книжке Jupyter
Это путешествие с использованием статистики NBA лишь поверхностно показывает, что вы можете сделать с библиотекой pandas Python. Вы можете усовершенствовать свой проект с помощью трюков с pandas, изучить методы, позволяющие ускорить работу с pandas в Python, и даже углубиться в изучение как pandas работает за кулисами. Вам предстоит открыть для себя еще много возможностей, так что приступайте к работе с этими наборами данных!
Back to Top