Фрейм данных pandas: Сделайте Работу с Данными приятной
Оглавление
- Представляем фрейм данных pandas
- Создание фрейма данных pandas
- Извлечение меток и данных
- Доступ к данным и их изменение
- Вставка и удаление данных
- Применение арифметических операций
- Применение функций NumPy и SciPy
- Сортировка фрейма данных pandas
- Фильтрация данных
- Определение статистики данных
- Обработка недостающих данных
- Повторение по фреймворку данных pandas
- Работа с Временными Рядами
- Построение графиков с помощью фреймов данных pandas
- Читать далее
- Заключение
Смотрите сейчас, к этому уроку прилагается соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Фрейм данных pandas: эффективная работа с данными
Фрейм данных pandas представляет собой структуру, которая содержит двумерные данные и соответствующие им метки. Фреймы данных широко используются в науке о данных, машинном обучении, научных вычислениях и многих других областях, требующих большого объема данных.
Фреймы данных аналогичны таблицам SQL или электронным таблицам, с которыми вы работаете в Excel или Calc. Во многих случаях фреймы данных быстрее, проще в использовании и более эффективны, чем таблицы или электронные таблицы, поскольку они являются неотъемлемой частью экосистем Python и NumPy.
В этом уроке вы узнаете:
- Что такое фрейм данных pandas и как его создать
- Как получать доступ, изменять, добавлять, сортировать, фильтровать и удалять данные
- Как обрабатывать пропущенные значения
- Как работать с данными временных рядов
- Как быстро визуализировать данные
Пришло время приступить к работе с фреймворками данных pandas!
Бесплатный бонус: 5 Размышления о мастерстве владения Python, бесплатный курс для разработчиков Python, который показывает вам план действий и мышление, с которым вы будете работать. вам нужно поднять свои навыки работы с Python на новый уровень.
Представляем фрейм данных pandas
фреймы данных pandas - это структуры данных, которые содержат:
- Данные организованы в двух измерениях, в строках и столбцах
- Метки, соответствующие строкам и столбцам
Вы можете начать работать с фреймами данных, импортировав панды:
>>> import pandas as pdТеперь, когда вы импортировали pandas, вы можете работать с фреймами данных.
Представьте, что вы используете pandas для анализа данных о кандидатах на должность разработчика веб-приложений на Python. Допустим, вас интересуют имена кандидатов, их города, возраст и результаты теста по программированию на Python, или
py-score:
name |
city |
age |
py-score |
|
|---|---|---|---|---|
101 |
Xavier |
Mexico City |
41 |
88.0 |
102 |
Ann |
Toronto |
28 |
79.0 |
103 |
Jana |
Prague |
33 |
81.0 |
104 |
Yi |
Shanghai |
34 |
80.0 |
105 |
Robin |
Manchester |
38 |
68.0 |
106 |
Amal |
Cairo |
31 |
61.0 |
107 |
Nori |
Osaka |
37 |
84.0 |
В этой таблице первая строка содержит метки столбцов (name, city, age, и py-score). В первом столбце содержатся метки строк (101, 102, и так далее). Все остальные ячейки заполняются значениями данных .
Теперь у вас есть все необходимое для создания фрейма данных pandas.
Существует несколько способов создать фрейм данных pandas. В большинстве случаев вы будете использовать конструктор DataFrame и предоставите данные, метки и другую информацию. Вы можете передать данные в виде двумерного списка, кортежа, или числового массива. Вы также можете передать его как словарь или панды Series например, или как один из нескольких других типов данных, не рассмотренных в этом руководстве.
В этом примере предположим, что вы используете словарь для передачи данных:
>>> data = { ... 'name': ['Xavier', 'Ann', 'Jana', 'Yi', 'Robin', 'Amal', 'Nori'], ... 'city': ['Mexico City', 'Toronto', 'Prague', 'Shanghai', ... 'Manchester', 'Cairo', 'Osaka'], ... 'age': [41, 28, 33, 34, 38, 31, 37], ... 'py-score': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0] ... } >>> row_labels = [101, 102, 103, 104, 105, 106, 107]
dataэто переменная Python, которая ссылается на словарь, содержащий ваши данные-кандидаты. Она также содержит метки столбцов:
'name''city''age''py-score'
Наконец, row_labels ссылается на список, содержащий метки строк, которые представляют собой числа в диапазоне от 101 до 107.
Теперь вы готовы к созданию фрейма данных pandas:
>>> df = pd.DataFrame(data=data, index=row_labels) >>> df name city age py-score 101 Xavier Mexico City 41 88.0 102 Ann Toronto 28 79.0 103 Jana Prague 33 81.0 104 Yi Shanghai 34 80.0 105 Robin Manchester 38 68.0 106 Amal Cairo 31 61.0 107 Nori Osaka 37 84.0Вот и все!
df- это переменная, которая содержит ссылку на ваш фрейм данных pandas. Этот фрейм данных pandas выглядит точно так же, как таблица-кандидат, приведенная выше, и имеет следующие особенности:
- Метки строк от
101до107 - Метки столбцов, такие как
'name','city','age', и'py-score' - Данные, такие как имена кандидатов, города, возраст и результаты тестов на Python
На этом рисунке показаны надписи и данные из df:

Метки строк выделены синим цветом, метки столбцов - красным, а значения данных - фиолетовым.
Фреймы данных pandas иногда могут быть очень большими, что делает непрактичным просмотр всех строк сразу. Вы можете использовать .head() для отображения первых нескольких элементов и .tail() для отображения последних нескольких элементов:
>>> df.head(n=2) name city age py-score 101 Xavier Mexico City 41 88.0 102 Ann Toronto 28 79.0 >>> df.tail(n=2) name city age py-score 106 Amal Cairo 31 61.0 107 Nori Osaka 37 84.0Таким образом, вы можете отобразить только начало или конец фрейма данных pandas. Параметр
nуказывает количество отображаемых строк.Примечание: Возможно, будет полезно представить фрейм данных pandas как словарь столбцов, или серию данных pandas, с множеством дополнительных функций.
Вы можете получить доступ к столбцу во фрейме данных pandas таким же образом, как и к значению из словаря:
>>> cities = df['city'] >>> cities 101 Mexico City 102 Toronto 103 Prague 104 Shanghai 105 Manchester 106 Cairo 107 Osaka Name: city, dtype: objectЭто самый удобный способ получить столбец из фрейма данных pandas.
Если имя столбца представляет собой строку, которая является допустимым идентификатором Python, то для доступа к нему можно использовать точечную запись. То есть вы можете получить доступ к столбцу так же, как получили бы атрибут экземпляра класса:
>>> df.city 101 Mexico City 102 Toronto 103 Prague 104 Shanghai 105 Manchester 106 Cairo 107 Osaka Name: city, dtype: objectТаким образом вы получаете определенный столбец. Вы извлекли столбец, соответствующий метке
'city', в котором указаны местоположения всех ваших кандидатов на работу.Важно отметить, что вы извлекли как данные, так и соответствующие метки строк:
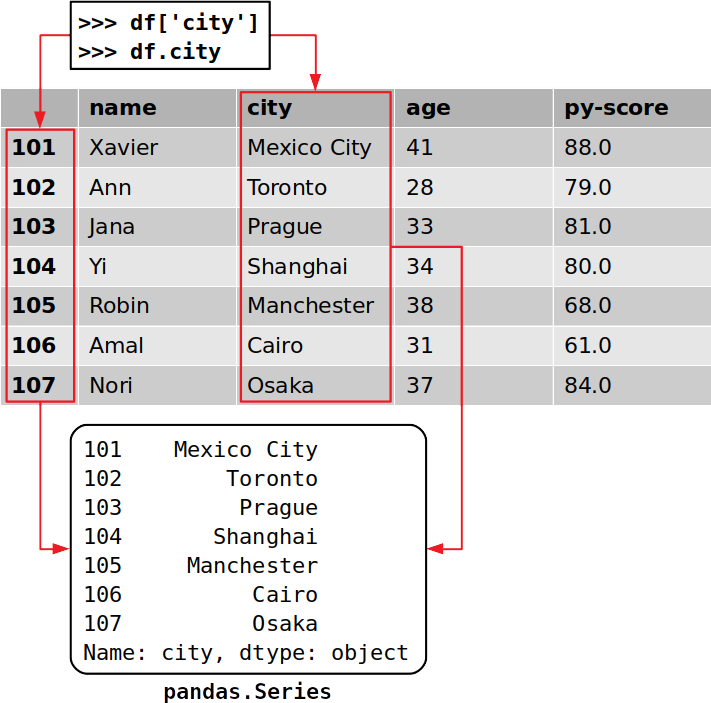
Каждый столбец фрейма данных pandas является экземпляром
pandas.Series, структуры, которая содержит одномерные данные и их метки. Вы можете получить отдельный элемент объектаSeriesтак же, как и в случае со словарем, используя его метку в качестве ключа:>>> cities[102] 'Toronto'В данном случае
'Toronto'- это значение данных, а102- соответствующая метка. Как вы увидите в более позднем разделе, существуют и другие способы получить определенный элемент во фрейме данных pandas.Вы также можете получить доступ ко всей строке с помощью средства доступа
.loc[]:>>> df.loc[103] name Jana city Prague age 33 py-score 81 Name: 103, dtype: objectНа этот раз вы извлекли строку, соответствующую метке
103, которая содержит данные для кандидата с именемJana. В дополнение к значениям данных из этой строки вы извлекли метки соответствующих столбцов: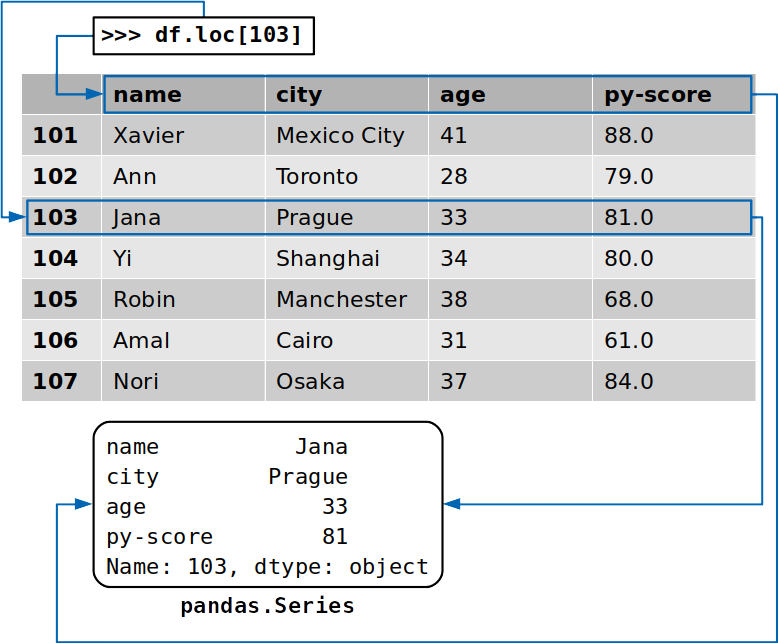
Возвращаемая строка также является экземпляром
pandas.Series.Создание фрейма данных pandas
Как уже упоминалось, существует несколько способов создания фрейма данных pandas. В этом разделе вы узнаете, как это сделать, используя конструктор
DataFrame, а также:
- Словари Python
- Списки Python
- Двумерные массивы NumPy
- Файлы
Существуют и другие методы, о которых вы можете узнать из официальной документации .
Вы можете начать с импорта pandas вместе с NumPy, который вы будете использовать в следующих примерах:
>>> import numpy as np >>> import pandas as pdВот и все. Теперь вы готовы создать несколько фреймворков данных.
Создание фрейма данных pandas со словарями
Как вы уже видели, вы можете создать фрейм данных pandas со словарем Python:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100} >>> pd.DataFrame(d) x y z 0 1 2 100 1 2 4 100 2 3 8 100Ключами словаря являются метки столбцов фрейма данных, а значениями словаря - значения данных в соответствующих столбцах фрейма данных. Значения могут содержаться в виде кортежа, списка, одномерного массива NumPy, pandas
Seriesобъект или один из нескольких других типов данных. Вы также можете указать одно значение, которое будет скопировано по всему столбцу.Можно управлять порядком расположения столбцов с помощью параметра
columns, а метками строк - с помощьюindex:>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x']) z y x 100 100 2 1 200 100 4 2 300 100 8 3Как вы можете видеть, вы указали метки строк
100,200, и300. Вы также изменили порядок следования столбцов:z,y,x.Создание фрейма данных pandas со списками
Другой способ создать фрейм данных pandas - использовать список словарей:
>>> l = [{'x': 1, 'y': 2, 'z': 100}, ... {'x': 2, 'y': 4, 'z': 100}, ... {'x': 3, 'y': 8, 'z': 100}] >>> pd.DataFrame(l) x y z 0 1 2 100 1 2 4 100 2 3 8 100Опять же, ключи словаря - это метки столбцов, а значения словаря - это значения данных во фрейме данных.
Вы также можете использовать вложенный список или список списков в качестве значений данных. Если вы это сделаете, то будет разумно явно указать метки столбцов, строк или того и другого при создании фрейма данных:
>>> l = [[1, 2, 100], ... [2, 4, 100], ... [3, 8, 100]] >>> pd.DataFrame(l, columns=['x', 'y', 'z']) x y z 0 1 2 100 1 2 4 100 2 3 8 100Вот как вы можете использовать вложенный список для создания фрейма данных pandas. Таким же образом вы можете использовать список кортежей. Для этого просто замените вложенные списки в примере выше на кортежи.
Создание фрейма данных pandas с массивами NumPy
Вы можете передать двумерный массив NumPy в конструктор
DataFrameточно так же, как вы делаете это со списком:>>> arr = np.array([[1, 2, 100], ... [2, 4, 100], ... [3, 8, 100]]) >>> df_ = pd.DataFrame(arr, columns=['x', 'y', 'z']) >>> df_ x y z 0 1 2 100 1 2 4 100 2 3 8 100Хотя этот пример выглядит почти так же, как реализация вложенного списка, описанная выше, у него есть одно преимущество: вы можете указать необязательный параметр
copy.Если для параметра
copyустановлено значениеFalse(значение по умолчанию), данные из массива NumPy не копируются. Это означает, что исходные данные из массива присваиваются фрейму данных pandas. Если вы измените массив, то ваш фрейм данных тоже изменится:>>> arr[0, 0] = 1000 >>> df_ x y z 0 1000 2 100 1 2 4 100 2 3 8 100Как вы можете видеть, когда вы меняете первый элемент
arr, вы также изменяетеdf_.Примечание: Отказ от копирования значений данных может значительно сэкономить время и вычислительную мощность при работе с большими наборами данных.
Если такое поведение вам не нравится, то вам следует указать
copy=Trueв конструктореDataFrame. Таким образом,df_будет создан с копией значений изarrвместо фактических значений.Создание фрейма данных pandas из файлов
Вы можете сохранять и загружать данные и метки из фрейма данных pandas в файлы различных типов, включая CSV, Excel, SQL, JSON и другие. Это очень мощная функция.
Вы можете сохранить данные о кандидате на работу в CSV-файл с помощью
.to_csv():>>> df.to_csv('data.csv')Приведенная выше инструкция создаст CSV-файл с именем
data.csvв вашем рабочем каталоге:,name,city,age,py-score 101,Xavier,Mexico City,41,88.0 102,Ann,Toronto,28,79.0 103,Jana,Prague,33,81.0 104,Yi,Shanghai,34,80.0 105,Robin,Manchester,38,68.0 106,Amal,Cairo,31,61.0 107,Nori,Osaka,37,84.0Теперь, когда у вас есть CSV-файл с данными, вы можете загрузить его с помощью
read_csv():>>> pd.read_csv('data.csv', index_col=0) name city age py-score 101 Xavier Mexico City 41 88.0 102 Ann Toronto 28 79.0 103 Jana Prague 33 81.0 104 Yi Shanghai 34 80.0 105 Robin Manchester 38 68.0 106 Amal Cairo 31 61.0 107 Nori Osaka 37 84.0Вот как вы получаете фрейм данных pandas из файла. В этом случае
index_col=0указывает, что метки строк расположены в первом столбце CSV-файла.Извлечение меток и данных
Теперь, когда вы создали свой фрейм данных, вы можете начать извлекать из него информацию. С помощью pandas вы можете выполнить следующие действия:
- Извлекать и изменять метки строк и столбцов в виде последовательностей
- Представлять данные в виде числовых массивов
- Проверьте и отрегулируйте типы данных
- Проанализируйте размер
DataFrameобъектовметки фреймов данных pandas в виде последовательностей
Вы можете получить метки строк фрейма данных с помощью
.indexи его метки столбцов с помощью.columns:>>> df.index Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64') >>> df.columns Index(['name', 'city', 'age', 'py-score'], dtype='object')Теперь у вас есть метки строк и столбцов в виде специальных последовательностей. Как и в случае с любой другой последовательностью Python, вы можете получить один элемент:
>>> df.columns[1] 'city'Помимо извлечения определенного элемента, вы можете применить другие операции с последовательностью, включая итерацию по меткам строк или столбцов. Однако это редко бывает необходимо, поскольку pandas предлагает другие способы перебора фреймов данных, которые вы увидите в более позднем разделе.
Вы также можете использовать этот подход для изменения меток:
>>> df.index = np.arange(10, 17) >>> df.index Int64Index([10, 11, 12, 13, 14, 15, 16], dtype='int64') >>> df name city age py-score 10 Xavier Mexico City 41 88.0 11 Ann Toronto 28 79.0 12 Jana Prague 33 81.0 13 Yi Shanghai 34 80.0 14 Robin Manchester 38 68.0 15 Amal Cairo 31 61.0 16 Nori Osaka 37 84.0В этом примере вы используете
numpy.arange()для создания новой последовательности меток строк, которая содержит целые числа от10до16. Чтобы узнать больше оarange(), ознакомьтесь с NumPy arange(): Как использовать np.arange().Имейте в виду, что если вы попытаетесь изменить определенный элемент из
.indexили.columns, то получитеTypeError.Данные в виде числовых массивов
Иногда вам может потребоваться извлечь данные из фрейма данных pandas без его меток. Чтобы получить массив NumPy с немаркированными данными, вы можете использовать либо
.to_numpy(), либо.values:>>> df.to_numpy() array([['Xavier', 'Mexico City', 41, 88.0], ['Ann', 'Toronto', 28, 79.0], ['Jana', 'Prague', 33, 81.0], ['Yi', 'Shanghai', 34, 80.0], ['Robin', 'Manchester', 38, 68.0], ['Amal', 'Cairo', 31, 61.0], ['Nori', 'Osaka', 37, 84.0]], dtype=object)И
.to_numpy(), и.valuesработают аналогично, и оба они возвращают массив NumPy с данными из фрейма данных pandas: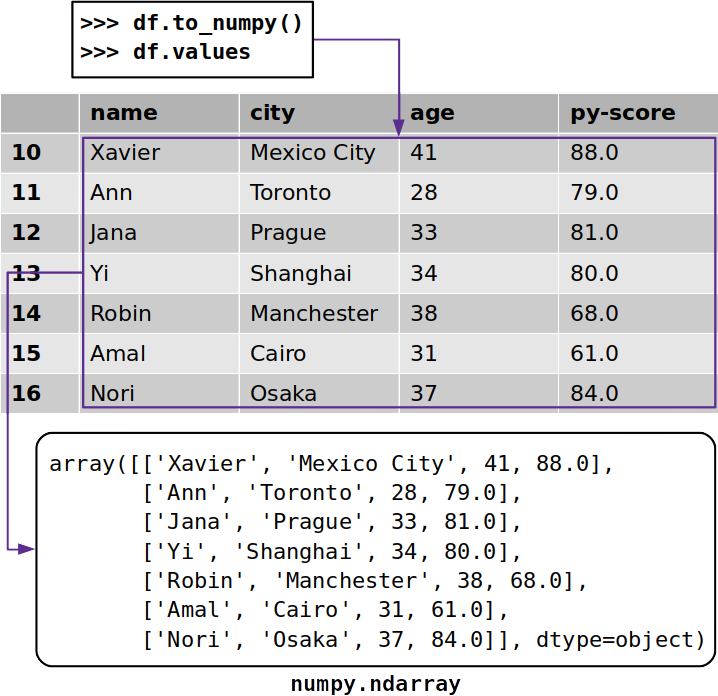
В документации pandas предлагается использовать
.to_numpy()из-за гибкости, обеспечиваемой двумя необязательными параметрами:
dtype: Используйте этот параметр, чтобы указать тип данных результирующего массива. По умолчанию это значение равноNone.copy: Установите для этого параметра значениеFalse, если вы хотите использовать исходные данные из фрейма данных. Установите значениеTrue, если вы хотите скопировать данные.Однако
.valuesсуществует гораздо дольше, чем.to_numpy(), который был представлен в версии pandas 0.24.0. Это означает, что вы, вероятно, будете чаще видеть.values, особенно в старом коде.Типы данных
Типы значений данных, также называемые типами данных или типами данных, важны, поскольку они определяют объем памяти, который использует ваш фрейм данных, а также скорость его вычисления и уровень точности.
pandas в значительной степени полагается на типы данных NumPy. Однако в pandas 1.0 появилось несколько дополнительных типов:
BooleanDtypeиBooleanArrayподдерживает пропущенные логические значения и трехзначную логику Клини.StringDtypeиStringArrayпредставляют собой выделенный строковый тип.Вы можете получить типы данных для каждого столбца фрейма данных pandas с помощью
.dtypes:>>> df.dtypes name object city object age int64 py-score float64 dtype: objectКак вы можете видеть,
.dtypesвозвращает объектSeriesс именами столбцов в качестве меток и соответствующими типами данных в качестве значений.Если вы хотите изменить тип данных одного или нескольких столбцов, вы можете использовать
.astype():>>> df_ = df.astype(dtype={'age': np.int32, 'py-score': np.float32}) >>> df_.dtypes name object city object age int32 py-score float32 dtype: objectНаиболее важным и единственным обязательным параметром
.astype()являетсяdtype. Он предполагает наличие типа данных или словаря. Если вы передаете словарь, то ключами являются имена столбцов, а значениями - нужные вам соответствующие типы данных.Как вы можете видеть, типы данных для столбцов
ageиpy-scoreв DataFramedfоба являютсяint64, что соответствует 64-разрядному (или 8-байтовые) целые числа. Однакоdf_также предлагает меньший 32-разрядный (4-байтовый) целочисленный тип данных, называемыйint32.размер фрейма данных pandas
Атрибуты
.ndim,.shape, и.sizeвозвращают количество измерений, количество значений данных в каждом измерении и общее количество значений данных соответственно:>>> df_.ndim 2 >>> df_.shape (7, 4) >>> df_.size 28
DataFrameэкземпляры имеют два измерения (строки и столбцы), поэтому.ndimвозвращает2. ОбъектSeries, с другой стороны, имеет только одно измерение , поэтому в этом случае.ndimвернет1.Атрибут
.shapeвозвращает кортеж с количеством строк (в данном случае7) и количеством столбцов (4). Наконец,.sizeвозвращает целое число, равное количеству значений во фрейме данных (28).Вы даже можете проверить объем памяти, используемый каждым столбцом, с помощью
.memory_usage():>>> df_.memory_usage() Index 56 name 56 city 56 age 28 py-score 28 dtype: int64Как вы можете видеть,
.memory_usage()возвращает последовательность с именами столбцов в качестве меток и использованием памяти в байтах в качестве значений данных. Если вы хотите исключить использование памяти столбцом, содержащим метки строк, передайте необязательный аргументindex=False.В приведенном выше примере последние два столбца,
ageиpy-score, занимают по 28 байт памяти каждый. Это связано с тем, что в этих столбцах содержится семь значений, каждое из которых представляет собой целое число, занимающее 32 бита, или 4 байта. Семь целых чисел, умноженных на 4 байта каждое, в общей сложности занимают 28 байт памяти.Доступ к данным и их изменение
Вы уже узнали, как получить определенную строку или столбец фрейма данных pandas в виде
Seriesобъекта:>>> df['name'] 10 Xavier 11 Ann 12 Jana 13 Yi 14 Robin 15 Amal 16 Nori Name: name, dtype: object >>> df.loc[10] name Xavier city Mexico City age 41 py-score 88 Name: 10, dtype: objectВ первом примере вы получаете доступ к столбцу
nameтак же, как к элементу из словаря, используя его метку в качестве ключа. Если метка столбца является допустимым идентификатором Python, то вы также можете использовать точечную нотацию для доступа к столбцу. Во втором примере вы используете.loc[], чтобы получить строку по ее метке,10.Получение данных С Помощью средств Доступа
В дополнение к методу доступа
.loc[], который вы можете использовать для получения строк или столбцов по их меткам, pandas предлагает метод доступа.iloc[],, который извлекает строку или столбец по их целочисленному индексу. В большинстве случаев вы можете использовать любой из двух вариантов:>>> df.loc[10] name Xavier city Mexico City age 41 py-score 88 Name: 10, dtype: object >>> df.iloc[0] name Xavier city Mexico City age 41 py-score 88 Name: 10, dtype: object
df.loc[10]возвращает строку с меткой10. Аналогично,df.iloc[0]возвращает строку с нулевым индексом0, которая является первой строкой. Как вы можете видеть, оба оператора возвращают ту же строку, что и объектSeries.всего у pandas есть четыре средства доступа:
.loc[]принимает метки строк и столбцов и возвращает ряды или фреймы данных. Вы можете использовать его для получения целых строк или столбцов, а также их частей.
.iloc[]принимает основанные на нуле индексы строк и столбцов и возвращает ряды или фреймы данных. Вы можете использовать его для получения целых строк или столбцов или их частей.
.at[]принимает метки строк и столбцов и возвращает одно значение данных.
.iat[]принимает основанные на нуле индексы строк и столбцов и возвращает одно значение данных.Из них
.loc[]и.iloc[]являются особенно мощными. Они поддерживают нарезку и Индексацию в стиле NumPy. Вы можете использовать их для доступа к столбцу:>>> df.loc[:, 'city'] 10 Mexico City 11 Toronto 12 Prague 13 Shanghai 14 Manchester 15 Cairo 16 Osaka Name: city, dtype: object >>> df.iloc[:, 1] 10 Mexico City 11 Toronto 12 Prague 13 Shanghai 14 Manchester 15 Cairo 16 Osaka Name: city, dtype: object
df.loc[:, 'city']возвращает столбецcity. Конструкция срез (:) в метке строки означает, что должны быть включены все строки.df.iloc[:, 1]возвращает один и тот же столбец, поскольку индекс, основанный на нуле1относится ко второму столбцу,city.Точно так же, как вы можете использовать NumPy, вы можете использовать срезы вместе со списками или массивами вместо индексов, чтобы получить несколько строк или столбцов:
>>> df.loc[11:15, ['name', 'city']] name city 11 Ann Toronto 12 Jana Prague 13 Yi Shanghai 14 Robin Manchester 15 Amal Cairo >>> df.iloc[1:6, [0, 1]] name city 11 Ann Toronto 12 Jana Prague 13 Yi Shanghai 14 Robin Manchester 15 Amal CairoПримечание: Не используйте кортежи вместо списков или целочисленных массивов для получения обычных строк или столбцов. Кортежи зарезервированы для , представляющих несколько измерений в NumPy и pandas, а также для иерархической или многоуровневой индексации в pandas.
В этом примере вы используете:
- Срезы, чтобы получить строки с метками от
11до15, которые эквивалентны индексам от1до5- Перечисляет, чтобы получить столбцы
nameиcity, которые эквивалентны индексам0и1Оба оператора возвращают фрейм данных pandas с пересечением нужных пяти строк и двух столбцов.
Это приводит к очень важному различию между
.loc[]и.iloc[]. Как вы можете видеть из предыдущего примера, когда вы передаете метки строк от11:15к.loc[], вы получаете строки от11до15. Однако, когда вы передаете индексы строк1:6в.iloc[], вы получаете только строки с индексами1через5.Причина, по которой вы получаете индексы только от
1до5, заключается в том, что при.iloc[]индекс остановки фрагмента является эксклюзивным, что означает, что оно исключено из возвращаемых значений. Это согласуется с последовательностями Python и массивами NumPy. Однако при.loc[]оба индекса start и stop являются включительно, что означает, что они включены в возвращаемые значения.Вы можете пропускать строки и столбцы с помощью
.iloc[]точно так же, как при разбиении кортежей, списков и массивов NumPy:>>> df.iloc[1:6:2, 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: objectВ этом примере вы указываете нужные индексы строк с помощью фрагмента
1:6:2. Это означает, что вы начинаете со строки с индексом1(вторая строка), останавливаетесь перед строкой с индексом6(седьмая строка) и пропускаете каждую вторую строку.Вместо использования конструкции slicing вы могли бы также использовать встроенный класс Python
slice(), а такжеnumpy.s_[]илиpd.IndexSlice[]:>>> df.iloc[slice(1, 6, 2), 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: object >>> df.iloc[np.s_[1:6:2], 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: object >>> df.iloc[pd.IndexSlice[1:6:2], 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: objectВозможно, один из этих подходов покажется вам более удобным, чем другие, в зависимости от вашей ситуации.
Можно использовать
.loc[]и.iloc[]для получения определенных значений данных. Однако, когда вам нужно только одно значение, pandas рекомендует использовать специализированные средства доступа.at[]и.iat[]:>>> df.at[12, 'name'] 'Jana' >>> df.iat[2, 0] 'Jana'Здесь вы использовали
.at[], чтобы получить имя одного кандидата, используя соответствующие метки столбцов и строк. Вы также использовали.iat[], чтобы получить то же имя, используя индексы столбцов и строк.Настройка данных С Помощью средств Доступа
Вы можете использовать методы доступа для изменения частей фрейма данных pandas, передавая последовательность Python, массив NumPy или одно значение:
>>> df.loc[:, 'py-score'] 10 88.0 11 79.0 12 81.0 13 80.0 14 68.0 15 61.0 16 84.0 Name: py-score, dtype: float64 >>> df.loc[:13, 'py-score'] = [40, 50, 60, 70] >>> df.loc[14:, 'py-score'] = 0 >>> df['py-score'] 10 40.0 11 50.0 12 60.0 13 70.0 14 0.0 15 0.0 16 0.0 Name: py-score, dtype: float64Инструкция
df.loc[:13, 'py-score'] = [40, 50, 60, 70]изменяет первые четыре элемента (строки с10по13) в столбцеpy-score, используя значения из предоставленного вами списка. Использованиеdf.loc[14:, 'py-score'] = 0устанавливает остальные значения в этом столбце равными0.В следующем примере показано, что вы можете использовать отрицательные индексы с
.iloc[]для доступа к данным или их изменения:>>> df.iloc[:, -1] = np.array([88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]) >>> df['py-score'] 10 88.0 11 79.0 12 81.0 13 80.0 14 68.0 15 61.0 16 84.0 Name: py-score, dtype: float64В этом примере вы получили доступ к последнему столбцу и изменили его (
'py-score'),, который соответствует целочисленному индексу столбца-1. Такое поведение согласуется с последовательностями Python и массивами NumPy.Вставка и удаление данных
pandas предоставляет несколько удобных методов вставки и удаления строк или столбцов. Вы можете выбрать один из них в зависимости от вашей ситуации и потребностей.
Вставка и удаление строк
Представьте, что вы хотите добавить нового человека в свой список кандидатов на работу. Вы можете начать с создания нового
Seriesобъекта, который представляет этого нового кандидата:>>> john = pd.Series(data=['John', 'Boston', 34, 79], ... index=df.columns, name=17) >>> john name John city Boston age 34 py-score 79 Name: 17, dtype: object >>> john.name 17У нового объекта есть метки, соответствующие меткам столбцов из
df. Вот почему вам нужноindex=df.columns.Вы можете добавить
johnв качестве новой строки в конецdfс помощью.append():>>> df = df.append(john) >>> df name city age py-score 10 Xavier Mexico City 41 88.0 11 Ann Toronto 28 79.0 12 Jana Prague 33 81.0 13 Yi Shanghai 34 80.0 14 Robin Manchester 38 68.0 15 Amal Cairo 31 61.0 16 Nori Osaka 37 84.0 17 John Boston 34 79.0Здесь
.append()возвращает фрейм данных pandas с добавленной новой строкой. Обратите внимание, что pandas использует атрибутjohn.name, который является значением17, чтобы указать метку для новой строки.Вы добавили новую строку с помощью одного вызова
.append(), и вы можете удалить ее с помощью одного вызова.drop():>>> df = df.drop(labels=[17]) >>> df name city age py-score 10 Xavier Mexico City 41 88.0 11 Ann Toronto 28 79.0 12 Jana Prague 33 81.0 13 Yi Shanghai 34 80.0 14 Robin Manchester 38 68.0 15 Amal Cairo 31 61.0 16 Nori Osaka 37 84.0Здесь
.drop()удаляет строки, указанные с помощью параметраlabels. По умолчанию возвращается фрейм данных pandas с удаленными указанными строками. Если вы передадитеinplace=True, то исходный фрейм данных будет изменен, и вы получитеNoneв качестве возвращаемого значения.Вставка и удаление столбцов
Самый простой способ вставить столбец во фрейм данных pandas - это выполнить ту же процедуру, которую вы используете при добавлении элемента в словарь. Вот как вы можете добавить столбец с оценками ваших кандидатов в тест JavaScript:
>>> df['js-score'] = np.array([71.0, 95.0, 88.0, 79.0, 91.0, 91.0, 80.0]) >>> df name city age py-score js-score 10 Xavier Mexico City 41 88.0 71.0 11 Ann Toronto 28 79.0 95.0 12 Jana Prague 33 81.0 88.0 13 Yi Shanghai 34 80.0 79.0 14 Robin Manchester 38 68.0 91.0 15 Amal Cairo 31 61.0 91.0 16 Nori Osaka 37 84.0 80.0Теперь в исходном фрейме данных есть еще один столбец,
js-score, в конце.Вам не обязательно указывать полную последовательность значений. Вы можете добавить новый столбец с одним значением:
>>> df['total-score'] = 0.0 >>> df name city age py-score js-score total-score 10 Xavier Mexico City 41 88.0 71.0 0.0 11 Ann Toronto 28 79.0 95.0 0.0 12 Jana Prague 33 81.0 88.0 0.0 13 Yi Shanghai 34 80.0 79.0 0.0 14 Robin Manchester 38 68.0 91.0 0.0 15 Amal Cairo 31 61.0 91.0 0.0 16 Nori Osaka 37 84.0 80.0 0.0Во фрейме данных
dfтеперь есть дополнительный столбец, заполненный нулями.Если вы раньше пользовались словарями, то этот способ вставки столбцов может быть вам знаком. Однако он не позволяет указать местоположение нового столбца. Если расположение нового столбца важно, то вы можете использовать
.insert()вместо этого:>>> df.insert(loc=4, column='django-score', ... value=np.array([86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0])) >>> df name city age py-score django-score js-score total-score 10 Xavier Mexico City 41 88.0 86.0 71.0 0.0 11 Ann Toronto 28 79.0 81.0 95.0 0.0 12 Jana Prague 33 81.0 78.0 88.0 0.0 13 Yi Shanghai 34 80.0 88.0 79.0 0.0 14 Robin Manchester 38 68.0 74.0 91.0 0.0 15 Amal Cairo 31 61.0 70.0 91.0 0.0 16 Nori Osaka 37 84.0 81.0 80.0 0.0Вы только что вставили еще один столбец с оценкой теста Django. Параметр
locопределяет местоположение или нулевой индекс нового столбца во фрейме данных pandas.columnзадает метку нового столбца, аvalueуказывает значения данных для вставки.Вы можете удалить один или несколько столбцов из фрейма данных pandas так же, как и из обычного словаря Python, используя инструкцию
del:>>> del df['total-score'] >>> df name city age py-score django-score js-score 10 Xavier Mexico City 41 88.0 86.0 71.0 11 Ann Toronto 28 79.0 81.0 95.0 12 Jana Prague 33 81.0 78.0 88.0 13 Yi Shanghai 34 80.0 88.0 79.0 14 Robin Manchester 38 68.0 74.0 91.0 15 Amal Cairo 31 61.0 70.0 91.0 16 Nori Osaka 37 84.0 81.0 80.0Теперь у вас есть
dfбез столбцаtotal-score. Еще одним сходством со словарями является возможность использовать.pop(),, который удаляет указанный столбец и возвращает его обратно. Это означает, что вы могли бы сделать что-то вродеdf.pop('total-score')вместо использованияdel.Вы также можете удалить один или несколько столбцов с помощью
.drop(), как вы делали ранее со строками. И снова вам нужно указать метки нужных столбцов с помощьюlabels. Кроме того, если вы хотите удалить столбцы, вам необходимо указать аргументaxis=1:>>> df = df.drop(labels='age', axis=1) >>> df name city py-score django-score js-score 10 Xavier Mexico City 88.0 86.0 71.0 11 Ann Toronto 79.0 81.0 95.0 12 Jana Prague 81.0 78.0 88.0 13 Yi Shanghai 80.0 88.0 79.0 14 Robin Manchester 68.0 74.0 91.0 15 Amal Cairo 61.0 70.0 91.0 16 Nori Osaka 84.0 81.0 80.0Вы удалили столбец
ageиз вашего фрейма данных.По умолчанию
.drop()возвращает фрейм данных без указанных столбцов, если только вы не передадитеinplace=True.Применение арифметических операций
Вы можете применять основные арифметические операции, такие как сложение, вычитание, умножение и деление, к объектам pandas
SeriesиDataFrameтак же, как и к массивам NumPy:>>> df['py-score'] + df['js-score'] 10 159.0 11 174.0 12 169.0 13 159.0 14 159.0 15 152.0 16 164.0 dtype: float64 >>> df['py-score'] / 100 10 0.88 11 0.79 12 0.81 13 0.80 14 0.68 15 0.61 16 0.84 Name: py-score, dtype: float64Вы можете использовать этот метод для вставки нового столбца во фрейм данных pandas. Например, попробуйте рассчитать
totalбалл как линейную комбинацию баллов ваших кандидатов по Python, Django и JavaScript:>>> df['total'] =\ ... 0.4 * df['py-score'] + 0.3 * df['django-score'] + 0.3 * df['js-score'] >>> df name city py-score django-score js-score total 10 Xavier Mexico City 88.0 86.0 71.0 82.3 11 Ann Toronto 79.0 81.0 95.0 84.4 12 Jana Prague 81.0 78.0 88.0 82.2 13 Yi Shanghai 80.0 88.0 79.0 82.1 14 Robin Manchester 68.0 74.0 91.0 76.7 15 Amal Cairo 61.0 70.0 91.0 72.7 16 Nori Osaka 84.0 81.0 80.0 81.9Теперь в вашем фрейме данных есть столбец с оценкой
total, рассчитанной на основе индивидуальных результатов тестирования ваших кандидатов. Что еще лучше, вы добились этого всего с помощью одного утверждения!Применение функций NumPy и SciPy
Большинство процедур NumPy и SciPy могут быть применены к объектам pandas
SeriesилиDataFrameв качестве аргументов, а не в качестве массивов NumPy. Чтобы проиллюстрировать это, вы можете рассчитать общие результаты тестов кандидатов, используя процедуру NumPynumpy.average().Вместо того, чтобы передавать массив NumPy в
numpy.average(), вы передадите часть вашего фрейма данных pandas:>>> import numpy as np >>> score = df.iloc[:, 2:5] >>> score py-score django-score js-score 10 88.0 86.0 71.0 11 79.0 81.0 95.0 12 81.0 78.0 88.0 13 80.0 88.0 79.0 14 68.0 74.0 91.0 15 61.0 70.0 91.0 16 84.0 81.0 80.0 >>> np.average(score, axis=1, ... weights=[0.4, 0.3, 0.3]) array([82.3, 84.4, 82.2, 82.1, 76.7, 72.7, 81.9])Переменная
scoreтеперь ссылается на фрейм данных с оценками Python, Django и JavaScript. Вы можете использоватьscoreв качестве аргументаnumpy.average()и получить линейную комбинацию столбцов с указанными весами.Но это еще не все! Вы можете использовать массив NumPy, возвращаемый
average(), в качестве нового столбцаdf. Сначала удалите существующий столбецtotalизdf, а затем добавьте новый, используяaverage():>>> del df['total'] >>> df name city py-score django-score js-score 10 Xavier Mexico City 88.0 86.0 71.0 11 Ann Toronto 79.0 81.0 95.0 12 Jana Prague 81.0 78.0 88.0 13 Yi Shanghai 80.0 88.0 79.0 14 Robin Manchester 68.0 74.0 91.0 15 Amal Cairo 61.0 70.0 91.0 16 Nori Osaka 84.0 81.0 80.0 >>> df['total'] = np.average(df.iloc[:, 2:5], axis=1, ... weights=[0.4, 0.3, 0.3]) >>> df name city py-score django-score js-score total 10 Xavier Mexico City 88.0 86.0 71.0 82.3 11 Ann Toronto 79.0 81.0 95.0 84.4 12 Jana Prague 81.0 78.0 88.0 82.2 13 Yi Shanghai 80.0 88.0 79.0 82.1 14 Robin Manchester 68.0 74.0 91.0 76.7 15 Amal Cairo 61.0 70.0 91.0 72.7 16 Nori Osaka 84.0 81.0 80.0 81.9Результат тот же, что и в предыдущем примере, но здесь вы использовали существующую функцию NumPy вместо написания собственного кода.
Сортировка фрейма данных pandas
Вы можете отсортировать фрейм данных pandas с помощью
.sort_values():>>> df.sort_values(by='js-score', ascending=False) name city py-score django-score js-score total 11 Ann Toronto 79.0 81.0 95.0 84.4 14 Robin Manchester 68.0 74.0 91.0 76.7 15 Amal Cairo 61.0 70.0 91.0 72.7 12 Jana Prague 81.0 78.0 88.0 82.2 16 Nori Osaka 84.0 81.0 80.0 81.9 13 Yi Shanghai 80.0 88.0 79.0 82.1 10 Xavier Mexico City 88.0 86.0 71.0 82.3В этом примере ваш фрейм данных сортируется по значениям в столбце
js-score. Параметрbyзадает метку строки или столбца, по которой выполняется сортировка.ascendingуказывает, хотите ли вы выполнить сортировку по возрастанию (True) или по убыванию (False), причем последнее это настройка по умолчанию. Вы можете ввестиaxis, чтобы выбрать, хотите ли вы сортировать строки (axis=0) или столбцы (axis=1).Если вы хотите выполнить сортировку по нескольким столбцам, то просто передайте списки в качестве аргументов для
byиascending:>>> df.sort_values(by=['total', 'py-score'], ascending=[False, False]) name city py-score django-score js-score total 11 Ann Toronto 79.0 81.0 95.0 84.4 10 Xavier Mexico City 88.0 86.0 71.0 82.3 12 Jana Prague 81.0 78.0 88.0 82.2 13 Yi Shanghai 80.0 88.0 79.0 82.1 16 Nori Osaka 84.0 81.0 80.0 81.9 14 Robin Manchester 68.0 74.0 91.0 76.7 15 Amal Cairo 61.0 70.0 91.0 72.7В этом случае фрейм данных сортируется по столбцу
total, но если два значения совпадают, то их порядок определяется значениями из столбцаpy-score.Необязательный параметр
inplaceтакже можно использовать с.sort_values(). По умолчанию для него установлено значениеFalse, что гарантирует, что.sort_values()возвращает новый фрейм данных pandas. Когда вы установитеinplace=True, существующий фрейм данных будет изменен и.sort_values()вернетNone.Если вы когда-либо пробовали сортировать значения в Excel, то, возможно, подход pandas покажется вам гораздо более эффективным и удобным. Когда у вас есть большие объемы данных, pandas может значительно превзойти Excel.
Для получения дополнительной информации о сортировке в pandas ознакомьтесь с Сортировка в pandas: руководство по сортировке данных в Python.
Фильтрация данных
Фильтрация данных - еще одна мощная функция pandas. Она работает аналогично индексации с помощью логических массивов в NumPy.
Если вы примените некоторую логическую операцию к объекту
Series, то вы получите другой ряд с логическими значениямиTrueиFalse:>>> filter_ = df['django-score'] >= 80 >>> filter_ 10 True 11 True 12 False 13 True 14 False 15 False 16 True Name: django-score, dtype: boolВ этом случае
df['django-score'] >= 80возвращаетTrueдля тех строк, в которых оценка Django больше или равна 80. Он возвращаетFalseдля строк с оценкой Django менее 80.Теперь у вас есть ряд
filter_, заполненный логическими данными. Выражениеdf[filter_]возвращает фрейм данных pandas со строками изdf, которые соответствуютTrueвfilter_:>>> df[filter_] name city py-score django-score js-score total 10 Xavier Mexico City 88.0 86.0 71.0 82.3 11 Ann Toronto 79.0 81.0 95.0 84.4 13 Yi Shanghai 80.0 88.0 79.0 82.1 16 Nori Osaka 84.0 81.0 80.0 81.9Как вы можете видеть,
filter_[10],filter_[11],filter_[13], иfilter_[16]равныTrue, поэтомуdf[filter_]содержит строки с этими метками. С другой стороны,,filter_[12],filter_[14], иfilter_[15]являютсяFalse, поэтому соответствующие строки не отображаются вdf[filter_].Вы можете создавать очень мощные и сложные выражения, комбинируя логические операции со следующими операторами:
NOT(~)AND(&)OR(|)XOR(^)Например, вы можете получить фрейм данных с кандидатами, у которых
py-scoreиjs-scoreбольше или равны 80:>>> df[(df['py-score'] >= 80) & (df['js-score'] >= 80)] name city py-score django-score js-score total 12 Jana Prague 81.0 78.0 88.0 82.2 16 Nori Osaka 84.0 81.0 80.0 81.9Выражение
(df['py-score'] >= 80) & (df['js-score'] >= 80)возвращает ряд сTrueв строках, для которых значенияpy-scoreиjs-scoreбольше или равны 80 иFalseв остальных. В этом случае только строки с метками12и16удовлетворяют обоим условиям.Вы также можете применить логические процедуры NumPy вместо операторов.
Для некоторых операций, требующих фильтрации данных, удобнее использовать
.where(). Он заменяет значения в тех позициях, где указанное условие не выполняется:>>> df['django-score'].where(cond=df['django-score'] >= 80, other=0.0) 10 86.0 11 81.0 12 0.0 13 88.0 14 0.0 15 0.0 16 81.0 Name: django-score, dtype: float64В этом примере условием является
df['django-score'] >= 80. Значения фрейма данных или серии, вызывающей.where(), останутся теми же, где условие равноTrue, и будут заменены значениемother(в данном случае0.0), где условие равно условием являетсяFalse.Определение статистики данных
pandas предоставляет множество статистических методов для фреймов данных. Вы можете получить базовую статистику для числовых столбцов фрейма данных pandas с помощью
.describe():>>> df.describe() py-score django-score js-score total count 7.000000 7.000000 7.000000 7.000000 mean 77.285714 79.714286 85.000000 80.328571 std 9.446592 6.343350 8.544004 4.101510 min 61.000000 70.000000 71.000000 72.700000 25% 73.500000 76.000000 79.500000 79.300000 50% 80.000000 81.000000 88.000000 82.100000 75% 82.500000 83.500000 91.000000 82.250000 max 88.000000 88.000000 95.000000 84.400000Здесь
.describe()возвращает новый фрейм данных с количеством строк, указанным какcount, а также среднее значение, стандартное отклонение, минимум, максимум и квартили столбцов.Если вы хотите получить определенную статистику для некоторых или всех ваших столбцов, вы можете вызвать такие методы, как
.mean()или.std():>>> df.mean() py-score 77.285714 django-score 79.714286 js-score 85.000000 total 80.328571 dtype: float64 >>> df['py-score'].mean() 77.28571428571429 >>> df.std() py-score 9.446592 django-score 6.343350 js-score 8.544004 total 4.101510 dtype: float64 >>> df['py-score'].std() 9.446591726019244При применении к фрейму данных pandas эти методы возвращают ряды с результатами для каждого столбца. При применении к объекту
Seriesили к одному столбцу фрейма данных методы возвращают скаляры .Чтобы узнать больше о статистических расчетах с помощью pandas, ознакомьтесь с Описательной статистикой с помощью Python и NumPy, SciPy и pandas: корреляция с Python.
Обработка недостающих данных
Недостающие данные очень часто встречаются в науке о данных и машинном обучении. Но не бойтесь! pandas обладает очень мощными функциями для работы с недостающими данными. Фактически, в его документации есть целый раздел, посвященный работе с отсутствующими данными.
pandas обычно представляет отсутствующие данные с помощью значений NaN (не числа). В Python вы можете получить NaN с помощью
float('nan'),math.nan, илиnumpy.nan. Начиная с pandas 1.0, новые типы, такие какBooleanDtype,Int8Dtype,Int16Dtype,Int32Dtype, иInt64Dtype, используютpandas.NAв качестве пропущенного значения.Вот пример фрейма данных pandas с пропущенным значением:
>>> df_ = pd.DataFrame({'x': [1, 2, np.nan, 4]}) >>> df_ x 0 1.0 1 2.0 2 NaN 3 4.0Переменная
df_ссылается на фрейм данных с одним столбцомxи четырьмя значениями. Третье значениеnanпо умолчанию считается отсутствующим.Вычисление с пропущенными Данными
Многие методы pandas пропускают значения
nanпри выполнении вычислений, если им явно не указано не:>>> df_.mean() x 2.333333 dtype: float64 >>> df_.mean(skipna=False) x NaN dtype: float64В первом примере
df_.mean()вычисляет среднее значение без учетаNaN(третье значение). Он просто принимает значения1.0,2.0, и4.0и возвращает их среднее значение, равное 2,33.Однако, если вы укажете
.mean()не пропускать значенияnanс помощьюskipna=False, то программа рассмотрит их и вернетnan, если среди них есть пропущенное значение. данные.Заполнение недостающих данных
в pandas есть несколько вариантов заполнения или замены пропущенных значений другими значениями. Одним из наиболее удобных методов является
.fillna(). Вы можете использовать его для замены пропущенных значений на:
- Указанные значения
- Значения, превышающие пропущенное значение
- Значения ниже пропущенного значения
Вот как вы можете применить упомянутые выше опции:
>>> df_.fillna(value=0) x 0 1.0 1 2.0 2 0.0 3 4.0 >>> df_.fillna(method='ffill') x 0 1.0 1 2.0 2 2.0 3 4.0 >>> df_.fillna(method='bfill') x 0 1.0 1 2.0 2 4.0 3 4.0В первом примере
.fillna(value=0)заменяет пропущенное значение на0.0, которое вы указали наvalue. Во втором примере.fillna(method='ffill')заменяет пропущенное значение значением над ним, которое равно2.0. В третьем примере.fillna(method='bfill')используется значение ниже пропущенного значения, которое является4.0.Другой популярный вариант - применить интерполяцию и заменить пропущенные значения интерполированными. Вы можете сделать это с помощью
.interpolate():>>> df_.interpolate() x 0 1.0 1 2.0 2 3.0 3 4.0Как вы можете видеть,
.interpolate()заменяет пропущенное значение интерполированным значением.Вы также можете использовать необязательный параметр
inplaceс.fillna(). При этом будет:
- Создайте и верните новый фрейм данных, когда
inplace=False- Измените существующий фрейм данных и верните
None, когдаinplace=TrueЗначение по умолчанию для
inplaceравноFalse. Однакоinplace=Trueможет быть очень полезно, когда вы работаете с большими объемами данных и хотите предотвратить ненужное и неэффективное копирование.Удаление строк и столбцов с отсутствующими данными
В определенных ситуациях может потребоваться удалить строки или даже столбцы, в которых отсутствуют значения. Это можно сделать с помощью
.dropna():>>> df_.dropna() x 0 1.0 1 2.0 3 4.0В этом случае
.dropna()просто удаляет строку сnan, включая ее метку. Он также имеет необязательный параметрinplace, который ведет себя так же, как и с.fillna()и.interpolate().Итерация по фреймворку данных pandas
Как вы узнали ранее, метки строк и столбцов фрейма данных могут быть получены в виде последовательностей с
.indexи.columns. Вы можете использовать эту функцию для перебора меток и получения или задания значений данных. Однако pandas предоставляет несколько более удобных методов для итерации:
.items()для перебора по столбцам.iteritems()для перебора по столбцам.iterrows()для перебора строк.itertuples()чтобы выполнить итерацию по строкам и получить именованных кортежейС помощью
.items()и.iteritems()вы выполняете итерацию по столбцам фрейма данных pandas. Каждая итерация приводит к получению кортежа с именем столбца и данными столбца в виде объектаSeries:>>> for col_label, col in df.iteritems(): ... print(col_label, col, sep='\n', end='\n\n') ... name 10 Xavier 11 Ann 12 Jana 13 Yi 14 Robin 15 Amal 16 Nori Name: name, dtype: object city 10 Mexico City 11 Toronto 12 Prague 13 Shanghai 14 Manchester 15 Cairo 16 Osaka Name: city, dtype: object py-score 10 88.0 11 79.0 12 81.0 13 80.0 14 68.0 15 61.0 16 84.0 Name: py-score, dtype: float64 django-score 10 86.0 11 81.0 12 78.0 13 88.0 14 74.0 15 70.0 16 81.0 Name: django-score, dtype: float64 js-score 10 71.0 11 95.0 12 88.0 13 79.0 14 91.0 15 91.0 16 80.0 Name: js-score, dtype: float64 total 10 82.3 11 84.4 12 82.2 13 82.1 14 76.7 15 72.7 16 81.9 Name: total, dtype: float64Вот как вы используете
.items()и.iteritems().С помощью
.iterrows()вы выполняете итерацию по строкам фрейма данных pandas. Каждая итерация приводит к получению кортежа с именем строки и данными строки в виде объектаSeries:>>> for row_label, row in df.iterrows(): ... print(row_label, row, sep='\n', end='\n\n') ... 10 name Xavier city Mexico City py-score 88 django-score 86 js-score 71 total 82.3 Name: 10, dtype: object 11 name Ann city Toronto py-score 79 django-score 81 js-score 95 total 84.4 Name: 11, dtype: object 12 name Jana city Prague py-score 81 django-score 78 js-score 88 total 82.2 Name: 12, dtype: object 13 name Yi city Shanghai py-score 80 django-score 88 js-score 79 total 82.1 Name: 13, dtype: object 14 name Robin city Manchester py-score 68 django-score 74 js-score 91 total 76.7 Name: 14, dtype: object 15 name Amal city Cairo py-score 61 django-score 70 js-score 91 total 72.7 Name: 15, dtype: object 16 name Nori city Osaka py-score 84 django-score 81 js-score 80 total 81.9 Name: 16, dtype: objectВот как вы используете
.iterrows().Аналогично,
.itertuples()выполняет итерацию по строкам и на каждой итерации выдает именованный кортеж с (необязательно) индексом и данными:>>> for row in df.loc[:, ['name', 'city', 'total']].itertuples(): ... print(row) ... pandas(Index=10, name='Xavier', city='Mexico City', total=82.3) pandas(Index=11, name='Ann', city='Toronto', total=84.4) pandas(Index=12, name='Jana', city='Prague', total=82.19999999999999) pandas(Index=13, name='Yi', city='Shanghai', total=82.1) pandas(Index=14, name='Robin', city='Manchester', total=76.7) pandas(Index=15, name='Amal', city='Cairo', total=72.7) pandas(Index=16, name='Nori', city='Osaka', total=81.9)Вы можете указать имя именованного кортежа с помощью параметра
name, который по умолчанию имеет значение'pandas'. Вы также можете указать, следует ли включать в метки строк значениеindex, которое по умолчанию равноTrue.Работа с Временными Рядами
pandas отлично справляется с обработкой временных рядов. Хотя эта функциональность частично основана на NumPy datetimes и timedeltas, pandas обеспечивает гораздо большую гибкость.
Создание фреймов данных с метками временных рядов
В этом разделе вы создадите фрейм данных pandas, используя почасовые данные о температуре за один день.
Вы можете начать с создания списка (или кортежа, числового массива или другого типа данных) со значениями данных, которые будут представлять собой почасовые значения температуры, указанные в градусах Цельсия:
>>> temp_c = [ 8.0, 7.1, 6.8, 6.4, 6.0, 5.4, 4.8, 5.0, ... 9.1, 12.8, 15.3, 19.1, 21.2, 22.1, 22.4, 23.1, ... 21.0, 17.9, 15.5, 14.4, 11.9, 11.0, 10.2, 9.1]Теперь у вас есть переменная
temp_c, которая ссылается на список значений температуры.Следующим шагом будет создание последовательности дат и времени. В pandas предусмотрена очень удобная функция,
date_range(), для этой цели:>>> dt = pd.date_range(start='2019-10-27 00:00:00.0', periods=24, ... freq='H') >>> dt DatetimeIndex(['2019-10-27 00:00:00', '2019-10-27 01:00:00', '2019-10-27 02:00:00', '2019-10-27 03:00:00', '2019-10-27 04:00:00', '2019-10-27 05:00:00', '2019-10-27 06:00:00', '2019-10-27 07:00:00', '2019-10-27 08:00:00', '2019-10-27 09:00:00', '2019-10-27 10:00:00', '2019-10-27 11:00:00', '2019-10-27 12:00:00', '2019-10-27 13:00:00', '2019-10-27 14:00:00', '2019-10-27 15:00:00', '2019-10-27 16:00:00', '2019-10-27 17:00:00', '2019-10-27 18:00:00', '2019-10-27 19:00:00', '2019-10-27 20:00:00', '2019-10-27 21:00:00', '2019-10-27 22:00:00', '2019-10-27 23:00:00'], dtype='datetime64[ns]', freq='H')
date_range()принимает аргументы, которые вы используете для указания начала или конца диапазона, количества периодов, частоты, часового пояса и многого другого.Примечание: Хотя доступны и другие опции, по умолчанию в pandas в основном используется формат даты и времени ISO 8601.
Теперь, когда у вас есть значения температуры и соответствующие даты и время, вы можете создать фрейм данных. Во многих случаях удобно использовать значения даты и времени в качестве меток строк:
>>> temp = pd.DataFrame(data={'temp_c': temp_c}, index=dt) >>> temp temp_c 2019-10-27 00:00:00 8.0 2019-10-27 01:00:00 7.1 2019-10-27 02:00:00 6.8 2019-10-27 03:00:00 6.4 2019-10-27 04:00:00 6.0 2019-10-27 05:00:00 5.4 2019-10-27 06:00:00 4.8 2019-10-27 07:00:00 5.0 2019-10-27 08:00:00 9.1 2019-10-27 09:00:00 12.8 2019-10-27 10:00:00 15.3 2019-10-27 11:00:00 19.1 2019-10-27 12:00:00 21.2 2019-10-27 13:00:00 22.1 2019-10-27 14:00:00 22.4 2019-10-27 15:00:00 23.1 2019-10-27 16:00:00 21.0 2019-10-27 17:00:00 17.9 2019-10-27 18:00:00 15.5 2019-10-27 19:00:00 14.4 2019-10-27 20:00:00 11.9 2019-10-27 21:00:00 11.0 2019-10-27 22:00:00 10.2 2019-10-27 23:00:00 9.1Вот и все! Вы создали фрейм данных с данными временных рядов и индексами строк даты и времени.
Индексирование и нарезка
Когда у вас есть фрейм данных pandas с данными временных рядов, вы можете удобно применить разбиение на фрагменты, чтобы получить только часть информации:
>>> temp['2019-10-27 05':'2019-10-27 14'] temp_c 2019-10-27 05:00:00 5.4 2019-10-27 06:00:00 4.8 2019-10-27 07:00:00 5.0 2019-10-27 08:00:00 9.1 2019-10-27 09:00:00 12.8 2019-10-27 10:00:00 15.3 2019-10-27 11:00:00 19.1 2019-10-27 12:00:00 21.2 2019-10-27 13:00:00 22.1 2019-10-27 14:00:00 22.4В этом примере показано, как извлечь значения температуры между 05:00 и 14:00 (5:00 и 14:00). Несмотря на то, что вы указали строки, pandas знает, что метки строк - это значения даты и времени, и интерпретирует строки как даты и время.
Повторная выборка и прокатка
Вы только что видели, как комбинировать метки строк даты и времени и использовать разбиение на части для получения необходимой информации из данных временных рядов. Это только начало. Дальше будет еще лучше!
Если вы хотите разделить день на четыре шестичасовых интервала и получить среднюю температуру для каждого интервала, то вам остается сделать всего одно действие. pandas предоставляет метод
.resample(), который вы можете комбинировать с другими методами, такими как.mean():>>> temp.resample(rule='6h').mean() temp_c 2019-10-27 00:00:00 6.616667 2019-10-27 06:00:00 11.016667 2019-10-27 12:00:00 21.283333 2019-10-27 18:00:00 12.016667Теперь у вас есть новый фрейм данных pandas с четырьмя строками. Каждая строка соответствует одному шестичасовому интервалу. Например, значение
6.616667- это среднее значение первых шести температур из фрейма данныхtemp, тогда как12.016667- это среднее значение последних шести температур.Вместо
.mean()вы можете применить.min()или.max(), чтобы получить минимальную и максимальную температуру для каждого интервала. Вы также можете использовать.sum()для получения суммы значений данных, хотя эта информация, вероятно, не пригодится при работе с температурами.Возможно, вам также потребуется выполнить некоторый анализ скользящего окна. Это включает в себя вычисление статистики для указанного количества смежных строк, которые составляют ваше окно данных. Вы можете “свернуть” окно, выбрав другой набор соседних строк для выполнения ваших вычислений.
Ваше первое окно начинается с первой строки в вашем фрейме данных и включает столько смежных строк, сколько вы укажете. Затем вы перемещаете окно на одну строку вниз, отбрасывая первую строку и добавляя строку, которая следует сразу за последней строкой, и снова вычисляете ту же статистику. Вы повторяете этот процесс, пока не дойдете до последней строки фрейма данных.
pandas предоставляет метод
.rolling()для этой цели:>>> temp.rolling(window=3).mean() temp_c 2019-10-27 00:00:00 NaN 2019-10-27 01:00:00 NaN 2019-10-27 02:00:00 7.300000 2019-10-27 03:00:00 6.766667 2019-10-27 04:00:00 6.400000 2019-10-27 05:00:00 5.933333 2019-10-27 06:00:00 5.400000 2019-10-27 07:00:00 5.066667 2019-10-27 08:00:00 6.300000 2019-10-27 09:00:00 8.966667 2019-10-27 10:00:00 12.400000 2019-10-27 11:00:00 15.733333 2019-10-27 12:00:00 18.533333 2019-10-27 13:00:00 20.800000 2019-10-27 14:00:00 21.900000 2019-10-27 15:00:00 22.533333 2019-10-27 16:00:00 22.166667 2019-10-27 17:00:00 20.666667 2019-10-27 18:00:00 18.133333 2019-10-27 19:00:00 15.933333 2019-10-27 20:00:00 13.933333 2019-10-27 21:00:00 12.433333 2019-10-27 22:00:00 11.033333 2019-10-27 23:00:00 10.100000Теперь у вас есть массив данных со средними температурами, рассчитанными для нескольких трехчасовых интервалов. Параметр
windowопределяет размер временного интервала перемещения.В приведенном выше примере третье значение (
7.3) - это средняя температура за первые три часа (00:00:00,01:00:00, и02:00:00). Четвертое значение - это средняя температура за данные часы02:00:00,03:00:00, и04:00:00. Последнее значение - это средняя температура за последние три часа,21:00:00,22:00:00, и23:00:00. Первые два значения отсутствуют, поскольку для их вычисления недостаточно данных.Построение графиков с использованием фреймов данных pandas
pandas позволяет вам визуализировать данные или создавать графики на основе фреймов данных. Он использует Matplotlib в фоновом режиме, поэтому использование возможностей построения графиков pandas очень похоже на работу с Matplotlib.
Если вы хотите отобразить графики, то сначала вам нужно импортировать
matplotlib.pyplot:>>> import matplotlib.pyplot as pltТеперь вы можете использовать
pandas.DataFrame.plot()для создания графика иplt.show()для отображения этого:>>> temp.plot() <matplotlib.axes._subplots.AxesSubplot object at 0x7f070cd9d950> >>> plt.show()Теперь
.plot()возвращаетplotобъект, который выглядит следующим образом: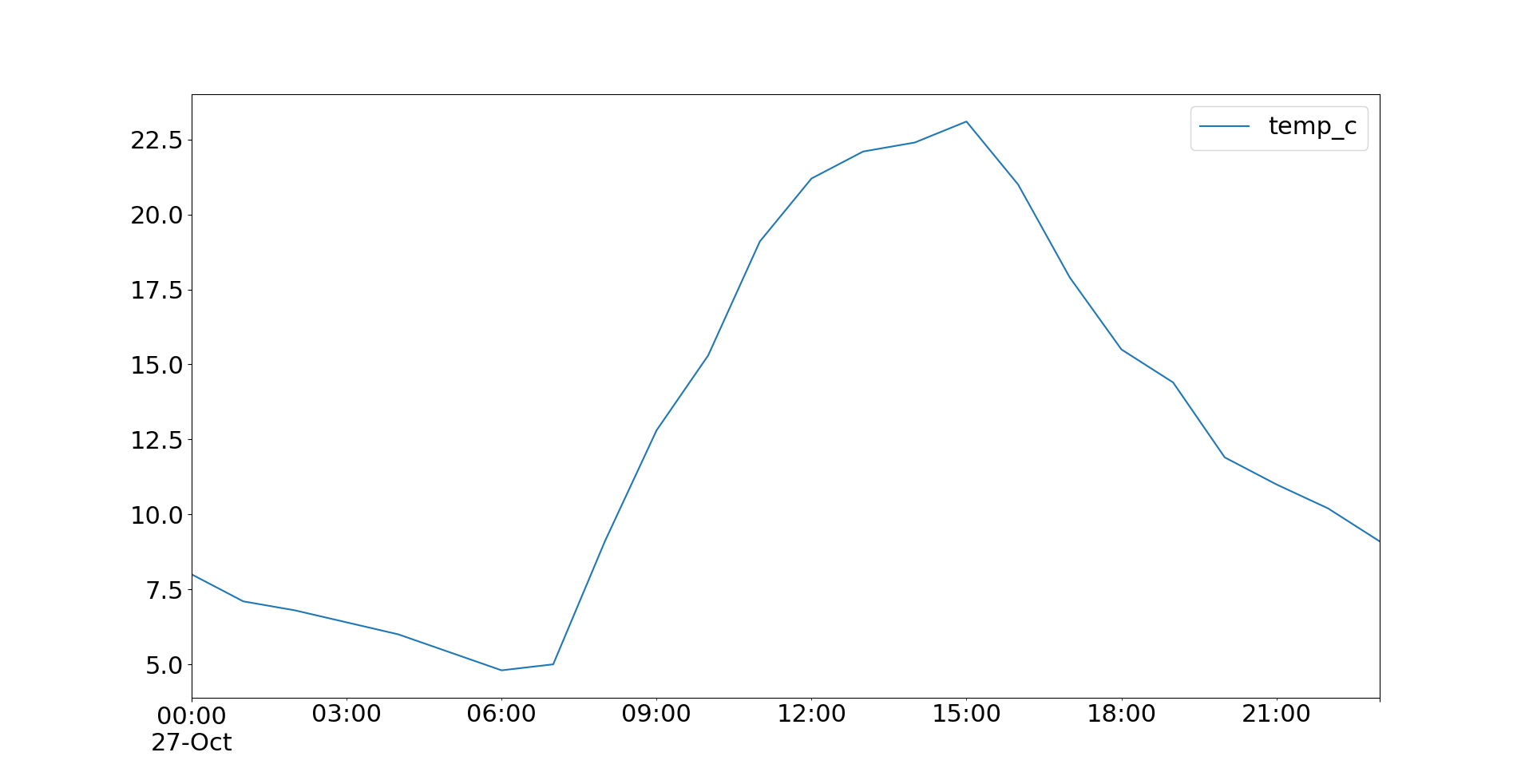
Вы также можете применить
.plot.line()и получить тот же результат. И.plot(), и.plot.line()имеют множество необязательных параметров, которые вы можете использовать для определения внешнего вида вашего графика. Некоторые из них передаются непосредственно в базовые методы Matplotlib.Вы можете сохранить свой рисунок, объединив методы
.get_figure()и.savefig():>>> temp.plot().get_figure().savefig('temperatures.png')Эта инструкция создает график и сохраняет его в виде файла с именем
'temperatures.png'в вашем рабочем каталоге.Вы можете получить другие типы графиков с помощью фрейма данных pandas. Например, вы можете представить свои предыдущие данные о кандидате на работу в виде гистограммы с
.plot.hist():>>> df.loc[:, ['py-score', 'total']].plot.hist(bins=5, alpha=0.4) <matplotlib.axes._subplots.AxesSubplot object at 0x7f070c69edd0> >>> plt.show()В этом примере вы извлекаете данные о результатах теста Python и общем количестве баллов и визуализируете их в виде гистограммы. Результирующий график выглядит следующим образом:
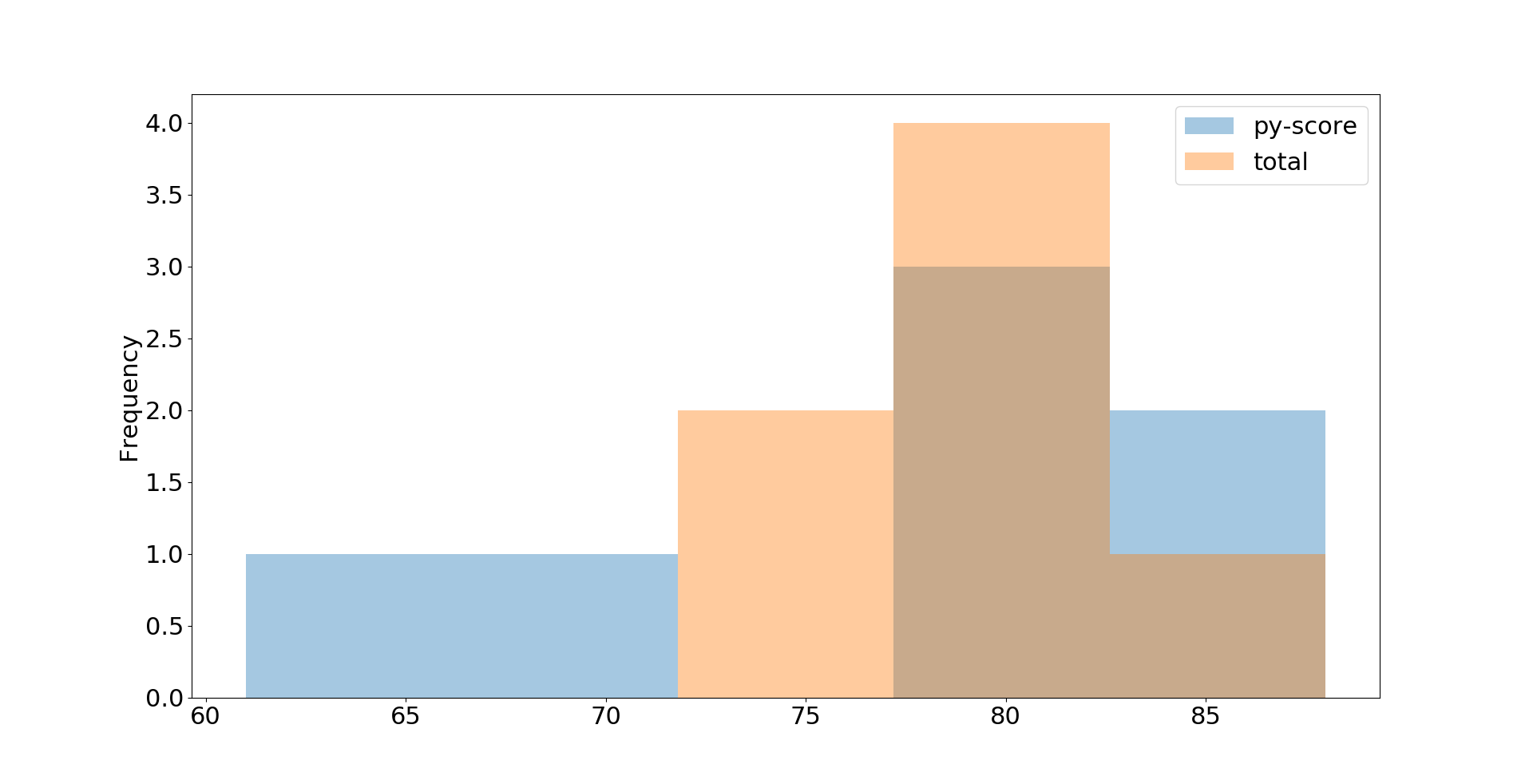
Это только базовый вид. Вы можете настроить детали с помощью дополнительных параметров, включая
.plot.hist(), Matplotlibplt.rcParams, и многие другие. Вы можете найти подробные объяснения в разделе Анатомия Matplotlib.Читать далее
Фреймы данных pandas - это очень сложные объекты, которые поддерживают множество операций, не упомянутых в этом руководстве. Некоторые из них включают:
- Иерархическая (многоуровневая) индексация
- Группировка
- Слияние, присоединение и конкатенация
- Работа с категориальными данными
В официальном руководстве по pandas подробно описаны некоторые из доступных опций. Если вы хотите узнать больше о pandas и фреймворках данных, то вы можете ознакомиться с этими руководствами:
- Очистка данных на Python с помощью pandas и NumPy
- фреймы данных pandas 101
- Знакомство с пандами и Винсентом
- Python pandas: Хитрости и возможности, о которых вы, возможно, не знаете
- Идиоматические панды: Хитрости и особенности, о которых вы, возможно, не знаете
- Чтение CSV-файлов с помощью pandas
- Написание CSV-файлов с помощью pandas
- Чтение и запись CSV-файлов на Python
- Чтение и запись CSV-файлов
- Использование pandas для чтения больших файлов Excel на Python
- Быстрый, гибкий, простой и интуитивно понятный: Как ускорить ваши проекты pandas
Вы узнали, что фреймы данных pandas обрабатывают двумерные данные. Если вам нужно работать с помеченными данными более чем в двух измерениях, вы можете ознакомиться с xarray, еще одной мощной библиотекой Python для обработки данных с функциями, очень похожими на pandas.
Если вы работаете с большими данными и хотите работать с фреймворками данных, то вы можете предоставить Даск получить шанс и использовать его DataFrame API. Dask DataFrame содержит множество фреймов данных pandas и выполняет вычисления в ленивой манере.
Заключение
Теперь вы знаете, что такое фрейм данных pandas, каковы некоторые его функции и как вы можете использовать его для эффективной работы с данными. Фреймы данных pandas - это мощные, удобные в использовании структуры данных, которые вы можете использовать для более глубокого изучения ваших наборов данных!
В этом уроке вы узнали:
- Что такое фрейм данных pandas и как его создать
- Как получать доступ, изменять, добавлять, сортировать, фильтровать и удалять данные
- Как использовать подпрограммы NumPy с фреймами данных
- Как обрабатывать пропущенные значения
- Как работать с данными временных рядов
- Как визуализировать данные, содержащиеся во фреймах данных
Вы узнали достаточно, чтобы разобраться в основах фреймворков данных. Если вы хотите углубиться в работу с данными в Python, ознакомьтесь с полным набором руководств по pandas.
Если у вас есть вопросы или комментарии, пожалуйста, задавайте их в разделе комментариев ниже.
<статус завершения article-slug="pandas-dataframe" class="btn-group mb-0" data-api-article-bookmark-url="/api/v1/articles/pandas-dataframe/bookmark/" статус завершения data-api-article-url="/api/v1/articles/pandas-фрейм данных/завершение_статуса/"> <кнопка поделиться bluesky-text="Интересная статья на #Python от @realpython.com :" email-body="Ознакомьтесь с этой статьей о Python:%0A%0фрейм данных pandas: делает работу с Данными приятной" email-subject="Статья о Python для вас" twitter-text="Интересная статья #Python статья от @realpython:" url="https://realpython.com/pandas-dataframe /" url-title="Фрейм данных pandas: делает работу с Данными приятной">Смотрите сейчас, к этому уроку прилагается соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Фрейм данных pandas: эффективная работа с данными
Back to Top