Счетчик Python: Питонический способ подсчета объектов
Оглавление
- Подсчет объектов в Python
- Начало работы со счетчиком Python
- Приведение Счетчика В Действие
- Использование экземпляров счетчиков в качестве мультимножеств
- Заключение
Смотрите сейчас, к этому уроку прилагается соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Подсчет с помощью счетчика Python
Подсчет нескольких повторяющихся объектов одновременно - распространенная проблема в программировании. Python предлагает множество инструментов и приемов, которые вы можете использовать для решения этой проблемы. Однако Python Counter from collections предоставляет чистое, эффективное и основанное на Python решение.
Этот подкласс словаря предоставляет эффективные возможности подсчета "из коробки". Понимание Counter и того, как эффективно его использовать, - это удобный навык для разработчика Python.
В этом руководстве вы узнаете, как:
- Подсчитайте сразу несколько повторяющихся объектов
- Создавайте счетчики с помощью Python
Counter - Извлеките наиболее распространенных объектов из счетчика
- Обновить количество объектов
- Используйте
Counterдля облегчения дальнейших вычислений
Вы также узнаете об основах использования Counter в качестве мультимножества, что является дополнительной функцией этого класса в Python.
Бесплатный бонус: 5 Размышления о мастерстве владения Python - бесплатный курс для разработчиков Python, который показывает вам план действий и мышление, с которым вы будете работать. вам нужно поднять свои навыки работы с Python на новый уровень.
Подсчет объектов в Python
Иногда вам нужно подсчитать объекты в данном источнике данных, чтобы узнать, как часто они встречаются. Другими словами, вам нужно определить их частоту. Например, вы можете захотеть узнать, как часто определенный элемент появляется в списке или последовательности значений. Если ваш список короткий, подсчет элементов может быть простым и быстрым. Однако, если у вас длинный список, подсчет элементов может быть более сложным.
Для подсчета объектов обычно используется счетчик, который представляет собой целочисленную переменную с начальным значением, равным нулю. Затем вы увеличиваете значение счетчика, чтобы отразить количество раз, когда данный объект появляется во входном источнике данных.
Когда вы подсчитываете вхождения одного объекта, вы можете использовать один счетчик. Однако, когда вам нужно подсчитать несколько разных объектов, вы должны создать столько счетчиков, сколько у вас уникальных объектов.
Чтобы подсчитать несколько разных объектов одновременно, вы можете использовать словарь Python. В словаре ключи будут храниться объекты, которые вы хотите подсчитать. В словаре значений будет указано количество повторений данного объекта или количество объектов .
Например, чтобы подсчитать объекты в последовательности с помощью словаря, вы можете выполнить цикл по последовательности, проверить, нет ли текущего объекта в словаре, чтобы инициализировать счетчик (пару ключ-значение), а затем соответствующим образом увеличить его количество.
Вот пример подсчета букв в слове “Миссисипи”:
>>> word = "mississippi" >>> counter = {} >>> for letter in word: ... if letter not in counter: ... counter[letter] = 0 ... counter[letter] += 1 ... >>> counter {'m': 1, 'i': 4, 's': 4, 'p': 2}
forЦикл выполняет итерацию по буквам вword. На каждой итерации условный оператор проверяет, не является ли данная буква ключом в словаре, который вы используете какcounter. Если это так, он создает новый ключ с буквой и обнуляет его количество. Последний шаг - увеличить количество на единицу. Когда вы открываетеcounter, вы видите, что буквы работают как ключи, а значения - как счетчики.Примечание: Когда вы подсчитываете несколько повторяющихся объектов с помощью словарей Python, имейте в виду, что они должны быть хэшируемыми, потому что они будут работать как ключи словаря. Быть хэшируемым означает, что ваши объекты должны иметь хэш-значение, которое никогда не меняется в течение их жизненного цикла. В Python неизменяемые объекты также доступны для хэширования.
Другой способ подсчета объектов со словарем - использовать
dict.get()с0в качестве значения по умолчанию:>>> word = "mississippi" >>> counter = {} >>> for letter in word: ... counter[letter] = counter.get(letter, 0) + 1 ... >>> counter {'m': 1, 'i': 4, 's': 4, 'p': 2}Когда вы вызываете
.get()таким образом, вы получаете текущее количество заданныхletterили0(по умолчанию), если буква отсутствует. Затем вы увеличиваете количество на1и сохраняете его под соответствующимletterв словаре.Вы также можете использовать
defaultdictfromcollectionsдля подсчета объектов внутри цикла:>>> from collections import defaultdict >>> word = "mississippi" >>> counter = defaultdict(int) >>> for letter in word: ... counter[letter] += 1 ... >>> counter defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})Это решение является более кратким и удобочитаемым. Сначала вы инициализируете
counter, используяdefaultdictс помощьюint()в качестве заводской функции по умолчанию. Таким образом, когда вы обращаетесь к ключу, которого нет в базовомdefaultdict, словарь автоматически создает ключ и инициализирует его значением, которое возвращает заводская функция.В этом примере, поскольку вы используете
int()в качестве заводской функции, начальным значением будет0, которое является результатом вызоваint()без аргументов.Как и во многих других часто встречающихся задачах программирования, Python предоставляет лучший способ решения задачи подсчета. В
collectionsвы найдете класс, специально разработанный для подсчета нескольких различных объектов за один раз. Этот класс удобно называетсяCounter.Начало работы с Python
Counter
Counterэто подклассdict, специально разработанный для подсчета хэшируемых объектов в Python. Это словарь, который хранит объекты как ключи и подсчитывает как значения. Для подсчета с помощьюCounterобычно в качестве аргумента конструктора класса указывается последовательность или повторяемых хэшируемых объектов.
Counterвыполняет внутреннюю итерацию по входной последовательности, подсчитывает количество раз, когда встречается данный объект, и сохраняет объекты как ключи, а значения - как значения. В следующем разделе вы узнаете о различных способах создания счетчиков.Построение счетчиков
Существует несколько способов создания
Counterэкземпляров. Однако, если ваша цель - подсчитать несколько объектов одновременно, вам нужно использовать последовательность или итерацию для инициализации счетчика. Например, вот как вы можете переписать пример с Миссисипи, используяCounter:>>> from collections import Counter >>> # Use a string as an argument >>> Counter("mississippi") Counter({'i': 4, 's': 4, 'p': 2, 'm': 1}) >>> # Use a list as an argument >>> Counter(list("mississippi")) Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
Counterвыполняет итерацию по"mississippi"и создает словарь с буквами в качестве ключей и их частотностью в качестве значений. В первом примере вы используете строку в качестве аргумента дляCounter. Вы также можете использовать списки, кортежи или любые повторяющиеся объекты с повторяющимися объектами, как вы видите во втором примере.Примечание: В
Counterвысоко оптимизированная функция C обеспечивает функциональность подсчета. Если эта функция по какой-либо причине недоступна, то класс использует эквивалентную, но менее эффективную функцию Python.Существуют и другие способы создания экземпляров
Counter. Однако они не предполагают строгого подсчета. Например, вы можете использовать словарь, содержащий ключи и значения, подобные этому:>>> from collections import Counter >>> Counter({"i": 4, "s": 4, "p": 2, "m": 1}) Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})У счетчика теперь есть начальная группа пар ключ-счетчик. Этот способ создания экземпляра
Counterполезен, когда вам нужно указать начальные значения для существующей группы объектов.Вы также можете получить аналогичные результаты, используя аргументы ключевого слова при вызове конструктора класса:
>>> from collections import Counter >>> Counter(i=4, s=4, p=2, m=1) Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})Опять же, вы можете использовать этот подход для создания
Counterобъекта с определенным начальным состоянием для его пар ключей и подсчетов.На практике, если вы используете
Counterдля подсчета данных с нуля, то вам не нужно инициализировать подсчеты, поскольку по умолчанию они имеют нулевое значение. Другой возможностью может быть инициализация значений1. В этом случае вы можете сделать что-то вроде этого:>>> from collections import Counter >>> Counter(set("mississippi")) Counter({'p': 1, 's': 1, 'm': 1, 'i': 1})Python устанавливает для хранения уникальных объектов, поэтому вызов
set()в этом примере выбрасывает повторяющиеся буквы. После этого вы получите по одному экземпляру каждой буквы в исходной итерационной таблице.
Counterнаследует интерфейс обычных словарей. Однако это не обеспечивает рабочей реализации.fromkeys()для предотвращения двусмысленностей, таких какCounter.fromkeys("mississippi", 2). В этом конкретном примере каждая буква будет иметь значение по умолчанию2, несмотря на текущее количество ее вхождений во входную итерацию.Нет никаких ограничений на объекты, которые вы можете хранить в ключах и значениях счетчика. Ключи могут хранить хэшируемые объекты, тогда как значения могут хранить любые объекты. Однако для работы в качестве счетчиков значения должны быть целыми числами, представляющими количество.
Вот пример экземпляра
Counter, который содержит отрицательные и нулевые значения:>>> from collections import Counter >>> inventory = Counter( ... apple=10, ... orange=15, ... banana=0, ... tomato=-15 ... )В этом примере вы можете спросить: “Почему у меня
-15помидор?” Что ж, это может быть внутренним соглашением, сигнализирующим о том, что у вас есть заказ клиента на15помидора, но в вашем текущем ассортименте их нет. Кто знает?Counterпозволяет вам это сделать, и вы, вероятно, сможете найти несколько вариантов использования этой функции.Обновление количества объектов
Как только у вас будет создан экземпляр
Counter, вы можете использовать.update(), чтобы обновить его новыми объектами и значениями. Вместо замены значений, подобных аналогуdict, реализация.update(), предоставленнаяCounter, суммирует существующие значения. При необходимости он также создает новые пары значений количества ключей.Вы можете использовать
.update(), используя в качестве аргументов как iterable, так и сопоставления counts. Если вы используете iterable, метод подсчитывает свои элементы и соответствующим образом обновляет счетчик:>>> from collections import Counter >>> letters = Counter({"i": 4, "s": 4, "p": 2, "m": 1}) >>> letters.update("missouri") >>> letters Counter({'i': 6, 's': 6, 'p': 2, 'm': 2, 'o': 1, 'u': 1, 'r': 1})Теперь у вас есть
6экземплярыi,6экземплярыsи так далее. У вас также есть несколько новых пар "количество ключей", таких как'o': 1,'u': 1, и'r': 1. Обратите внимание, что повторяемость должна представлять собой последовательность элементов, а не последовательность из(key, count)пар.Примечание: Как вы уже знаете, нет никаких ограничений на значения (количества), которые вы можете сохранять в счетчике.
Использование объектов, отличных от целых чисел, для подсчета нарушает общие функции счетчика:
>>> from collections import Counter >>> letters = Counter({"i": "4", "s": "4", "p": "2", "m": "1"}) >>> letters.update("missouri") Traceback (most recent call last): ... TypeError: can only concatenate str (not "int") to strВ этом примере количество букв является строками, а не целыми значениями. Это приводит к разрыву
.update(), что приводит кTypeError.Второй способ использования
.update()- это предоставить другой счетчик или отображение значений в качестве аргумента. В этом случае вы можете сделать что-то вроде этого:>>> from collections import Counter >>> sales = Counter(apple=25, orange=15, banana=12) >>> # Use a counter >>> monday_sales = Counter(apple=10, orange=8, banana=3) >>> sales.update(monday_sales) >>> sales Counter({'apple': 35, 'orange': 23, 'banana': 15}) >>> # Use a dictionary of counts >>> tuesday_sales = {"apple": 4, "orange": 7, "tomato": 4} >>> sales.update(tuesday_sales) >>> sales Counter({'apple': 39, 'orange': 30, 'banana': 15, 'tomato': 4})В первом примере вы обновляете существующий счетчик,
sales, используя другой счетчик,monday_sales. Обратите внимание, как.update()добавляет значения из обоих счетчиков.Примечание: Вы также можете использовать
.update()с аргументами ключевого слова. Так, например, выполнение чего-то вродеsales.update(apple=10, orange=8, banana=3)работает так же, как иsales.update(monday_sales)в примере выше.Далее вы используете обычный словарь, содержащий элементы и значения счетчиков. В этом случае
.update()добавляет значения существующих ключей и создает недостающие пары ключ-количество.Доступ к содержимому счетчика
Как вы уже знаете,
Counterимеет почти такой же интерфейс, как иdict. Со счетчиками можно выполнять почти те же действия, что и со стандартными словарями. Например, вы можете получить доступ к их значениям, используя доступ к ключам, подобный словарю ([key]). Вы также можете перебирать ключи, значения и элементы, используя обычные приемы и методы:>>> from collections import Counter >>> letters = Counter("mississippi") >>> letters["p"] 2 >>> letters["s"] 4 >>> for letter in letters: ... print(letter, letters[letter]) ... m 1 i 4 s 4 p 2 >>> for letter in letters.keys(): ... print(letter, letters[letter]) ... m 1 i 4 s 4 p 2 >>> for count in letters.values(): ... print(count) ... 1 4 4 2 >>> for letter, count in letters.items(): ... print(letter, count) ... m 1 i 4 s 4 p 2В этих примерах вы получаете доступ к ключам (буквам) и значениям (счетчикам) вашего счетчика и выполняете их итерацию, используя знакомый интерфейс словаря, который включает в себя такие методы, как
.keys(),.values(), и.items().Примечание: Если вы хотите глубже разобраться в том, как выполнять итерацию по словарю, ознакомьтесь с Как выполнять итерацию по словарю в Python.
И последнее замечание по поводу
Counterзаключается в том, что если вы попытаетесь получить доступ к отсутствующему ключу, то вместо символа вы получите нольKeyError:>>> from collections import Counter >>> letters = Counter("mississippi") >>> letters["a"] 0Поскольку буква
"a"не отображается в строке"mississippi", счетчик возвращает значение0при попытке получить доступ к количеству для этой буквы.Поиск наиболее распространенных объектов
Если вам нужно составить список групп объектов в соответствии с их частотой или количеством появлений, то вы можете использовать
.most_common(). Этот метод возвращает список(object, count), отсортированный по текущему количеству объектов. Объекты с одинаковым количеством отображаются в порядке их появления.Если вы введете целое число
nв качестве аргумента для.most_common(), то получитеnнаиболее распространенных объекта. Если вы опуститеnили установите значениеNone, то.most_common()вернет все объекты в счетчике:>>> from collections import Counter >>> sales = Counter(banana=15, tomato=4, apple=39, orange=30) >>> # The most common object >>> sales.most_common(1) [('apple', 39)] >>> # The two most common objects >>> sales.most_common(2) [('apple', 39), ('orange', 30)] >>> # All objects sorted by count >>> sales.most_common() [('apple', 39), ('orange', 30), ('banana', 15), ('tomato', 4)] >>> sales.most_common(None) [('apple', 39), ('orange', 30), ('banana', 15), ('tomato', 4)] >>> sales.most_common(20) [('apple', 39), ('orange', 30), ('banana', 15), ('tomato', 4)]В этих примерах вы используете
.most_common()для извлечения наиболее часто встречающихся объектов изsales. Без аргумента или с помощьюNone, метод возвращает все объекты. Если аргумент.most_common()больше длины текущего счетчика, то вы снова получаете все объекты.Вы также можете получить наименее распространенные объекты, сократив результат
.most_common():>>> from collections import Counter >>> sales = Counter(banana=15, tomato=4, apple=39, orange=30) >>> # All objects in reverse order >>> sales.most_common()[::-1] [('tomato', 4), ('banana', 15), ('orange', 30), ('apple', 39)] >>> # The two least-common objects >>> sales.most_common()[:-3:-1] [('tomato', 4), ('banana', 15)]Первая нарезка,
[::-1], возвращает все объекты вsalesв обратном порядке в соответствии с их соответствующим количеством. При разбиении[:-3:-1]извлекаются последние два объекта из результата.most_common(). Вы можете настроить количество получаемых наименее распространенных объектов, изменив второе значение смещения в операторе разбиения. Например, чтобы получить три наименее часто встречающихся объекта, вы можете изменить-3на-4и так далее.Примечание: Ознакомьтесь с Списками Reverse Python: Beyond .reverse() и reversed() для получения практических примеров использования синтаксиса slicing.
Если вы хотите, чтобы
.most_common()работал корректно, убедитесь, что значения в ваших счетчиках можно сортировать. Это следует иметь в виду, потому что, как уже упоминалось, в счетчике можно хранить любые типы данных.Приведение в действие
CounterНа данный момент вы изучили основы создания и использования объектов
Counterв вашем коде. Теперь вы знаете, как подсчитать, сколько раз каждый объект появляется в заданной последовательности или повторяется. Вы также знаете, как:
- Создать счетчики с начальными значениями
- Обновить существующие счетчики
- Получить наиболее часто встречающиеся объекты в заданном счетчике
В следующих разделах вы приведете несколько практических примеров, чтобы лучше понять, насколько полезными могут быть
Counterв Python.Подсчет букв в текстовом файле
Допустим, у вас есть файл, содержащий некоторый текст. Вам нужно подсчитать, сколько раз каждая буква встречается в тексте. Например, допустим, у вас есть файл под названием
pyzen.txtсо следующим содержимым:The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!Да, это Дзен Python, список руководящих принципов, которые определяют основную философию, лежащую в основе дизайна Python. Чтобы подсчитать, сколько раз каждая буква встречается в этом тексте, вы можете воспользоваться
Counterи написать функцию, подобную этой:1# letters.py 2 3from collections import Counter 4 5def count_letters(filename): 6 letter_counter = Counter() 7 with open(filename) as file: 8 for line in file: 9 line_letters = [ 10 char for char in line.lower() if char.isalpha() 11 ] 12 letter_counter.update(Counter(line_letters)) 13 return letter_counterВот как работает этот код:
- Строка 5 определяет
count_letters(). Эта функция принимает в качестве аргумента путь к файлу в виде строки.- Строка 6 создает пустой счетчик для подсчета букв в целевом тексте.
- Строка 7 открывает входной файл для чтения и создает итератор для обработки содержимого файла.
- Строка 8 запускает цикл, который построчно перебирает содержимое файла.
- Строки с 9 по 11 определяют понимание списка для исключения небуквенных символов из текущей строки с помощью
.isalpha(). Программа "Понимание" записывает буквы в нижний регистр перед их фильтрацией, чтобы предотвратить раздельное использование строчных и прописных букв.- Строка 12 вызывает
.update()на счетчике букв, чтобы обновить количество каждой буквы.Чтобы использовать
count_letters(), вы можете сделать что-то вроде этого:>>> from letters import count_letters >>> letter_counter = count_letters("pyzen.txt") >>> for letter, count in letter_counter.items(): ... print(letter, "->", count) ... t -> 79 h -> 31 e -> 92 z -> 1 ... k -> 2 v -> 5 w -> 4 >>> for letter, count in letter_counter.most_common(5): ... print(letter, "->", count) ... e -> 92 t -> 79 i -> 53 a -> 53 s -> 46Отлично! Ваш код подсчитывает частоту каждой буквы в данном текстовом файле. Лингвисты часто используют частотность букв для идентификации языка. Например, в английском языке исследования средней частоты встречаемости букв показали, что пятью наиболее распространенными буквами являются “e”, “t”, “a”, “o” и “i”. Ничего себе! Это почти совпадает с вашими результатами!
Построение категориальных Данных с помощью столбчатых диаграмм ASCII
Статистика - это еще одно поле, в котором вы можете использовать
Counter. Например, когда вы работаете с категориальными данными, вам может потребоваться создать столбчатых диаграмм, чтобы наглядно представить количество наблюдений в каждой категории. Столбчатые диаграммы особенно удобны для отображения данных такого типа.Теперь предположим, что вы хотите создать функцию, которая позволит вам создавать столбчатую диаграмму ASCII на вашем терминале. Для этого вы можете использовать следующий код:
# bar_chart.py from collections import Counter def print_ascii_bar_chart(data, symbol="#"): counter = Counter(data).most_common() chart = {category: symbol * frequency for category, frequency in counter} max_len = max(len(category) for category in chart) for category, frequency in chart.items(): padding = (max_len - len(category)) * " " print(f"{category}{padding} |{frequency}")В этом примере
print_ascii_bar_chart()берет некоторую категориюdata, подсчитывает, сколько раз каждая уникальная категория появляется в данных (frequency), и генерирует столбчатую диаграмму ASCII, отражающую эту частоту .Вот как вы можете использовать эту функцию:
>>> from bar_chart import print_ascii_bar_chart >>> letters = "mississippimississippimississippimississippi" >>> print_ascii_bar_chart(letters) i |################ s |################ p |######## m |#### >>> from collections import Counter >>> sales = Counter(banana=15, tomato=4, apple=39, orange=30) >>> print_ascii_bar_chart(sales, symbol="+") apple |+++++++++++++++++++++++++++++++++++++++ orange |++++++++++++++++++++++++++++++ banana |+++++++++++++++ tomato |++++Первый вызов
print_ascii_bar_chart()отображает частоту встречаемости каждой буквы во входной строке. Второй вызов отображает продажи по фруктам. В этом случае в качестве входных данных используется счетчик. Также обратите внимание, что вы можете использоватьsymbol, чтобы изменить символ столбцов.Примечание: В приведенном выше примере
print_ascii_bar_chart()не нормализует значенияfrequencyпри построении диаграмм. Если вы используете данные с высокими значениямиfrequency, то ваш экран будет выглядеть как путаница символов.При создании столбчатых диаграмм использование горизонтальных полос позволяет оставить достаточно места для надписей категорий. Еще одной полезной функцией столбчатых диаграмм является возможность сортировки данных в соответствии с их частотой. В этом примере вы сортируете данные с помощью
.most_common().Построение категориальных данных с помощью Matplotlib
Приятно знать, как создавать столбчатые диаграммы ASCII с нуля с помощью Python. Однако в экосистеме Python вы можете найти несколько инструментов для построения графиков данных. Одним из таких инструментов является Matplotlib.
Matplotlib - это сторонняя библиотека для создания статических, анимированных и интерактивных визуализаций на Python. Вы можете установить библиотеку из PyPI, используя
pipкак обычно:$ python -m pip install matplotlibЭта команда устанавливает Matplotlib в вашей среде Python . Установив библиотеку, вы можете использовать ее для создания столбчатых диаграмм и многого другого. Вот как вы можете создать минимальную гистограмму с помощью Matplotlib:
>>> from collections import Counter >>> import matplotlib.pyplot as plt >>> sales = Counter(banana=15, tomato=4, apple=39, orange=30).most_common() >>> x, y = zip(*sales) >>> x ('apple', 'orange', 'banana', 'tomato') >>> y (39, 30, 15, 4) >>> plt.bar(x, y) <BarContainer object of 4 artists> >>> plt.show()Здесь вы сначала выполняете требуемый импорт. Затем вы создаете счетчик с некоторыми исходными данными о продажах фруктов и используете
.most_common()для сортировки данных.Вы используете
zip(), чтобы распаковать содержимоеsalesв две переменные:
xсодержит список фруктов.yсодержит соответствующие единицы, проданные за каждый фрукт.Затем вы создаете столбчатую диаграмму с помощью
plt.bar(). Когда вы запуститеplt.show(),, на вашем экране появится окно, похожее на следующее: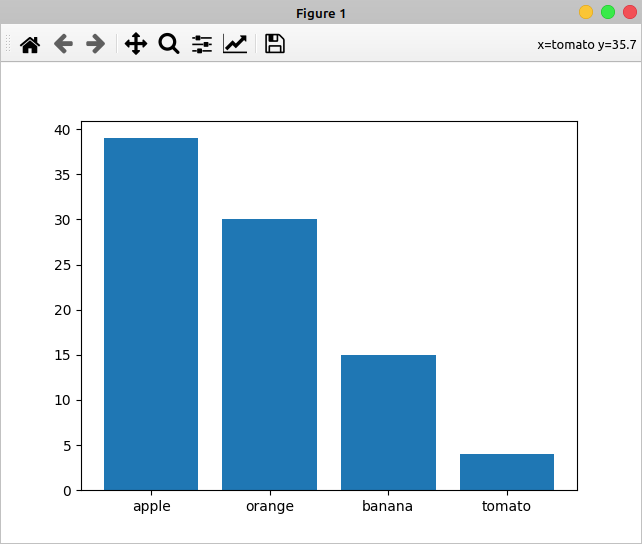
На этой диаграмме по горизонтальной оси отложено название каждого уникального фрукта. А по вертикальной оси - количество проданных единиц каждого фрукта.
Определение режима выборки
В статистике режим является наиболее часто встречающимся значением (или значениями) в выборке данных. Например, если у вас есть образец
[2, 1, 2, 2, 3, 5, 3], то режим будет2, потому что он появляется чаще всего.В некоторых случаях режим не является уникальным значением. Рассмотрим пример
[2, 1, 2, 2, 3, 5, 3, 3]. Здесь у вас есть два режима,2и3, потому что оба они появляются одинаковое количество раз.Вы часто будете использовать этот режим для описания категориальных данных. Например, этот режим полезен, когда вам нужно знать, какая категория является наиболее распространенной в ваших данных.
Чтобы найти нужный режим с помощью Python, вам нужно подсчитать количество вхождений каждого значения в вашей выборке. Затем вам нужно найти наиболее часто встречающееся значение (или значения). Другими словами, значение с наибольшим количеством вхождений. Это похоже на то, что вы можете сделать, используя
Counterи.most_common().Примечание: Язык Python
statisticsмодуль в стандартной библиотеке предоставляет функции для расчета нескольких статистических данных, включая режим унимодальных и мультимодальных выборок. Приведенный ниже пример предназначен только для того, чтобы показать, насколько полезным может бытьCounter.Вот функция, которая вычисляет режим выборки:
# mode.py from collections import Counter def mode(data): counter = Counter(data) _, top_count = counter.most_common(1)[0] return [point for point, count in counter.items() if count == top_count]Внутри
mode()вы сначала подсчитываете, сколько раз каждое наблюдение появлялось во входных данныхdata. Затем вы используете.most_common(1), чтобы получить частоту наиболее распространенных наблюдений. Поскольку.most_common()возвращает список кортежей в виде(point, count), вам нужно получить кортеж с индексом0, который является наиболее распространенным в списке. Затем вы распаковываете кортеж на две переменные:
_содержит самый распространенный объект. Использование символа подчеркивания для обозначения переменной означает, что вам не нужно использовать эту переменную в вашем коде, но она нужна вам как заполнитель.top_countсодержит частоту наиболее распространенного объекта вdata.При составлении списка сравнивается
countдля каждого объекта с количеством наиболее распространенных объектов,top_count. Это позволяет идентифицировать несколько режимов в данной выборке.Чтобы использовать эту функцию, вы можете сделать что-то вроде этого:
>>> from collections import Counter >>> from mode import mode >>> # Single mode, numerical data >>> mode([2, 1, 2, 2, 3, 5, 3]) [2] >>> # Multiple modes, numerical data >>> mode([2, 1, 2, 2, 3, 5, 3, 3]) [2, 3] >>> # Single mode, categorical data >>> data = [ ... "apple", ... "orange", ... "apple", ... "apple", ... "orange", ... "banana", ... "banana", ... "banana", ... "apple", ... ] >>> mode(data) ['apple'] >>> # Multiple modes, categorical data >>> mode(Counter(apple=4, orange=4, banana=2)) ['apple', 'orange']Ваш
mode()работает! Он определяет режим работы с числовыми и категориальными данными. Он также работает с одномодовыми и многомодовыми выборками. В большинстве случаев ваши данные будут поступать в виде последовательности значений. Однако последний пример показывает, что вы также можете использовать счетчик для предоставления входных данных.Подсчет файлов по типу
Другой интересный пример, связанный с
Counter, заключается в подсчете файлов в заданном каталоге, группировании их по расширению или типу файла. Чтобы сделать это, вы можете воспользоватьсяpathlib:>>> import pathlib >>> from collections import Counter >>> entries = pathlib.Path("Pictures/").iterdir() >>> extensions = [entry.suffix for entry in entries if entry.is_file()] ['.gif', '.png', '.jpeg', '.png', '.png', ..., '.png'] >>> Counter(extensions) Counter({'.png': 50, '.jpg': 11, '.gif': 10, '.jpeg': 9, '.mp4': 9})В этом примере вы сначала создаете итератор для записей в заданном каталоге, используя
Path.iterdir(). Затем вы используете понимание списка, чтобы создать список, содержащий расширения (.suffix) всех файлов в целевом каталоге. Наконец, вы подсчитываете количество файлов, используя расширение файла в качестве критерия группировки.Если вы запустите этот код на своем компьютере, то получите другой результат в зависимости от содержимого вашего каталога
Pictures/, если он вообще существует. Таким образом, вам, вероятно, потребуется использовать другой входной каталог, чтобы этот код заработал.Использование экземпляров
Counterв качестве мультимножествВ математике мультимножество представляет собой вариант множества, который допускает множественные экземпляры своих элементов. Количество экземпляров данного элемента известно как его кратность. Таким образом, у вас может быть мультисеть, подобная {1, 1, 2, 3, 3, 3, 4, 4}, но версия набора будет ограничена {1, 2, 3, 4}.
Как и в математике, обычные наборы Python допускают только уникальные элементы:
>>> # A Python set >>> {1, 1, 2, 3, 3, 3, 4, 4} {1, 2, 3, 4}Когда вы создаете набор, подобный этому, Python удаляет все повторяющиеся экземпляры каждого числа. В результате вы получаете набор, содержащий только уникальные элементы.
Python поддерживает концепцию мультинаборов с помощью
Counter. Ключи в экземпляреCounterуникальны, поэтому они эквивалентны набору. Счетчики содержат кратность, или количество экземпляров, каждого элемента:>>> from collections import Counter >>> # A Python multiset >>> multiset = Counter([1, 1, 2, 3, 3, 3, 4, 4]) >>> multiset Counter({3: 3, 1: 2, 4: 2, 2: 1}) >>> # The keys are equivalent to a set >>> multiset.keys() == {1, 2, 3, 4} TrueЗдесь вы сначала создаете мультимножество, используя
Counter. Ключи эквивалентны набору, который вы видели в примере выше. Значения содержат кратность каждого элемента в наборе.
Counterреализует множество функций с несколькими наборами функций, которые вы можете использовать для решения нескольких задач. Распространенным вариантом использования мультисети в программировании является корзина покупок, поскольку она может содержать более одного экземпляра каждого продукта, в зависимости от потребностей клиента:>>> from collections import Counter >>> prices = {"course": 97.99, "book": 54.99, "wallpaper": 4.99} >>> cart = Counter(course=1, book=3, wallpaper=2) >>> for product, units in cart.items(): ... subtotal = units * prices[product] ... price = prices[product] ... print(f"{product:9}: ${price:7.2f} × {units} = ${subtotal:7.2f}") ... course : $ 97.99 × 1 = $ 97.99 book : $ 54.99 × 3 = $ 164.97 wallpaper: $ 4.99 × 2 = $ 9.98В этом примере вы создаете корзину покупок, используя объект
Counterв качестве мультимножества. Счетчик предоставляет информацию о заказе клиента, которая включает в себя несколько обучающих ресурсов. Циклforвыполняет итерацию по счетчику и вычисляетsubtotalдля каждогоproductи выводит на экран.Чтобы закрепить свои знания об использовании объектов
Counterв качестве мультимножеств, вы можете развернуть поле ниже и выполнить упражнение. Когда закончите, разверните поле "Решение", чтобы сравнить свои результаты.
В качестве упражнения вы можете изменить приведенный выше пример, чтобы рассчитать общую сумму для оплаты при оформлении заказа.
Вот возможное решение:
>>> from collections import Counter >>> prices = {"course": 97.99, "book": 54.99, "wallpaper": 4.99} >>> cart = Counter(course=1, book=3, wallpaper=2) >>> total = 0.0 >>> for product, units in cart.items(): ... subtotal = units * prices[product] ... price = prices[product] ... print(f"{product:9}: ${price:7.2f} × {units} = ${subtotal:7.2f}") ... total += subtotal ... course : $ 97.99 × 1 = $ 97.99 book : $ 54.99 × 3 = $ 164.97 wallpaper: $ 4.99 × 2 = $ 9.98 >>> total 272.94В первой выделенной строке вы добавляете новую переменную для хранения общей стоимости всех заказанных вами товаров. Во второй выделенной строке вы используете расширенное назначение для накопления всех
subtotalвtotal.Теперь, когда у вас есть представление о том, что такое мультисеть и как они реализуются в Python, вы можете взглянуть на некоторые функции мультисети, которые предоставляет
Counter.Восстановление элементов из счетчика
Первая функция мультисети
Counter, о которой вы узнаете, - это.elements(). Этот метод возвращает итератор для элементов в мультимножестве (Counterэкземпляров), повторяющий каждый из них столько раз, сколько указано в его счетчике:>>> from collections import Counter >>> for letter in Counter("mississippi").elements(): ... print(letter) ... m i i i i s s s s p pКонечным результатом вызова
.elements()для счетчика является восстановление исходных данных, которые вы использовали для создания самого счетчика. Метод возвращает элементы — буквы в этом примере — в том же порядке, в котором они впервые появляются в базовом счетчике. Поскольку Python 3.7,Counterзапоминает порядок вставки своих ключей как функцию, унаследованную отdict.Примечание: Как вы уже знаете, вы можете создавать счетчики с нулевым и отрицательным значением. Если количество элементов меньше единицы, то
.elements()игнорирует его.Строка документации из
.elements()в файле исходного кода представляет собой интересный пример использования этого метода для вычисления число из его простых множителей. Поскольку данный простой множитель может встречаться более одного раза, в итоге может получиться мультимножество. Например, вы можете выразить число 1836 как произведение его простых множителей следующим образом:1836 = 2 × 2 × 3 × 3 × 3 × 17 = 2< sup>2 × 33 × 171
Вы можете записать это выражение в виде мультимножества, например {2, 2, 3, 3, 3, 17}. Используя
Counterв Python, у вас получитсяCounter({2: 2, 3: 3, 17: 1}). Установив этот счетчик, вы можете вычислить исходное число, используя его простые множители:>>> from collections import Counter >>> # Prime factors of 1836 >>> prime_factors = Counter({2: 2, 3: 3, 17: 1}) >>> product = 1 >>> for factor in prime_factors.elements(): ... product *= factor ... >>> product 1836Цикл выполняет итерацию по элементам в
prime_factorsи умножает их для вычисления исходного числа1836. Если вы используете Python версии 3.8 или более поздней, то вы можете использоватьprod()frommathдля получения аналогичного результата. Эта функция вычисляет произведение всех элементов во входной итерационной таблице:>>> import math >>> from collections import Counter >>> prime_factors = Counter({2: 2, 3: 3, 17: 1}) >>> math.prod(prime_factors.elements()) 1836В этом примере вызов
.elements()восстанавливает простые множители. Затемmath.prod()вычисляет1836из них за один раз, что избавляет вас от написания цикла и наличия нескольких промежуточных переменных.Использование
.elements()позволяет восстановить исходные входные данные. Его единственным недостатком является то, что в большинстве случаев порядок элементов во входных данных не будет соответствовать порядку в выходных данных:>>> from collections import Counter >>> "".join(Counter("mississippi").elements()) 'miiiisssspp'В этом примере результирующая строка не соответствует по буквам исходному слову,
mississippi. Однако в буквенном выражении она имеет то же содержание.Вычитание кратности элементов
Иногда вам нужно вычесть кратность (количество) элементов в мультимножестве или счетчике. В этом случае вы можете использовать
.subtract(). Как следует из его названия, этот метод вычитает значения, указанные в iterable или mapping, из значений в целевом счетчике.Допустим, у вас есть мультисеть с текущим запасом фруктов, и вам нужно поддерживать ее в актуальном состоянии. Затем вы можете выполнить некоторые из следующих операций:
>>> from collections import Counter >>> inventory = Counter(apple=39, orange=30, banana=15) >>> # Use a counter >>> wastage = Counter(apple=6, orange=5, banana=8) >>> inventory.subtract(wastage) >>> inventory Counter({'apple': 33, 'orange': 25, 'banana': 7}) >>> # Use a mapping of counts >>> order_1 = {"apple": 12, "orange": 12} >>> inventory.subtract(order_1) >>> inventory Counter({'apple': 21, 'orange': 13, 'banana': 7}) >>> # Use an iterable >>> order_2 = ["apple", "apple", "apple", "apple", "banana", "banana"] >>> inventory.subtract(order_2) >>> inventory Counter({'apple': 17, 'orange': 13, 'banana': 5})Здесь вы используете несколько способов предоставления входных данных в
.subtract(). Во всех случаях вы обновляете значения каждого уникального объекта, вычитая значения, указанные во входных данных. Вы можете думать о.subtract()как о аналоге.update().Выполнение арифметических действий С Кратностью Элементов
С помощью
.subtract()и.update()вы можете комбинировать счетчики, вычитая и добавляя количество соответствующих элементов. В качестве альтернативы, Python предоставляет удобные операторы для сложения (+) и вычитания (-) количества элементов, а также операторы для пересечения (&) и объединения (|). Оператор пересечение возвращает минимальное количество соответствующих значений, в то время как оператор объединение возвращает максимальное количество значений.Вот несколько примеров того, как работают все эти операторы:
>>> from collections import Counter >>> # Fruit sold per day >>> sales_day1 = Counter(apple=4, orange=9, banana=4) >>> sales_day2 = Counter(apple=10, orange=8, banana=6) >>> # Total sales >>> sales_day1 + sales_day2 Counter({'orange': 17, 'apple': 14, 'banana': 10}) >>> # Sales increment >>> sales_day2 - sales_day1 Counter({'apple': 6, 'banana': 2}) >>> # Minimum sales >>> sales_day1 & sales_day2 Counter({'orange': 8, 'apple': 4, 'banana': 4}) >>> # Maximum sales >>> sales_day1 | sales_day2 Counter({'apple': 10, 'orange': 9, 'banana': 6})Здесь вы сначала складываете два счетчика вместе, используя оператор сложения (
+). Результирующий счетчик содержит одни и те же ключи (элементы), в то время как их соответствующие значения (кратности) содержат сумму значений обоих задействованных счетчиков.Во втором примере показано, как работает оператор вычитания (
-). Обратите внимание, что отрицательные и нулевые значения приводят к тому, что пара ключ-счетчик не включается в результирующий счетчик. Итак, вы не видитеorangeв выходных данных, потому что 8 - 9 = -1.Оператор пересечения (
&) извлекает объекты с меньшим количеством значений из обоих счетчиков, тогда как оператор объединения (|) возвращает объекты с большим количеством значений из обоих задействованных счетчиков.Примечание: Для получения дополнительной информации о том, как
Counterвыполняет арифметические операции, ознакомьтесь с документацией по классу .
Counterтакже поддерживает некоторые унарные операции. Например, вы можете получить элементы с положительным и отрицательным количеством, используя знаки плюс (+) и минус (-) соответственно:>>> from collections import Counter >>> counter = Counter(a=2, b=-4, c=0) >>> +counter Counter({'a': 2}) >>> -counter Counter({'b': 4})Когда вы используете знак плюс (
+) в качестве унарного оператора для существующего счетчика, вы получаете все объекты, количество которых больше нуля. С другой стороны, если вы используете знак минус (-),, вы получаете объекты с отрицательным количеством элементов. Обратите внимание, что в результате исключаются объекты, количество которых в обоих случаях равно нулю.Заключение
Когда вам нужно подсчитать несколько повторяющихся объектов в Python, вы можете использовать
Counterизcollections. Этот класс предоставляет эффективный способ подсчета на языке Python без использования традиционных методов, включающих циклы и вложенные структуры данных. Это может сделать ваш код более чистым и быстрым.В этом руководстве вы узнали, как:
- Подсчитайте несколько повторяющихся объектов используя различные инструменты Python
- Создавайте быстрые и эффективные счетчики с помощью Python
Counter- Извлеките наиболее распространенных объектов из определенного счетчика
- Обновлять и манипулировать количеством объектов
- Используйте
Counterдля облегчения дальнейших вычисленийВы также изучили основы использования экземпляров
<статус завершения article-slug="python-счетчик" class="btn-group mb-0" data-api-article-bookmark-url="/api/v1/articles/python-счетчик/закладка/" data-api-article-статус завершения-url="/api/v1/articles/python-счетчик/completion_status/"> <кнопка поделиться bluesky-text="Интересная статья на #Python от @realpython.com :" email-body="Ознакомьтесь с этой статьей о Python:%0A%0apython's Counter: способ подсчета объектов на языке Python" email-subject="Статья о Python для вас" twitter-text="Интересная #Статья о Python от @realpython:" url="https://realpython.com/python-counter /" url-title="Счетчик Python: способ подсчета объектов на языке Python">Counterв качестве мультимножеств. Обладая всеми этими знаниями, вы сможете быстро подсчитывать объекты в своем коде, а также выполнять математические операции с мультимножествами.Смотрите сейчас, к этому уроку прилагается соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Подсчет с помощью счетчика Python
Back to Top