Python против C++: выбор подходящего инструмента для работы
Оглавление
- Сравнение языков: Python и C++
- Компиляция против виртуальной машины
- Синтаксические различия
- Статическая и динамическая типизация
- Объектно-ориентированное программирование
- Управление памятью
- Многопоточность, многопроцессорность и асинхронный ввод-вывод
- Прочие вопросы
- Краткое описание: Python против C++
- Заключение
Вы разработчик C++, сравниваете Python и C++? Вы смотрите на Python и удивляетесь, из-за чего весь сыр-бор? Вам интересно, как Python соотносится с концепциями, которые вы уже знаете? Или, может быть, вы заключили пари на то, кто победит, если вы посадите C++ и Python в клетку и позволите им сразиться? Тогда эта статья для вас!
В этой статье вы узнаете о:
- Различия и сходства при сравнении Python и C++
- Случаи, когда Python может быть лучшим выбором для решения задачи, и наоборот
- Ресурсы, к которым вы можете обратиться, если у вас возникнут вопросы при изучении Python
Эта статья предназначена для разработчиков на C++, которые изучают Python. Это предполагает базовые знания обоих языков и использование концепций из Python 3.6 и выше, а также C++11 или более поздней версии.
Давайте рассмотрим сравнение Python и C++!
Скачать бесплатно: Ознакомьтесь с примером главы из книги "Приемы работы с Python: Книга", в которой показаны лучшие практики Python на простых примерах, которые вы можете подайте заявку немедленно, чтобы написать более красивый + Pythonic код.
Сравнение языков: Python и C++
Часто можно встретить статьи, в которых превозносятся достоинства одного языка программирования по сравнению с другими. Довольно часто они сводятся к попыткам продвигать один язык за счет унижения другого. Это статьи не такого типа.
Когда вы сравниваете Python и C++, помните, что это оба инструмента, и оба они могут быть использованы для решения разных задач. Подумайте о сравнении молотка и отвертки. Вы могли бы использовать отвертку для забивания гвоздей, и вы могли бы использовать молоток для завинчивания шурупов, но ни тот, ни другой опыт не будут столь эффективными.
Важно правильно использовать инструмент для работы. В этой статье вы узнаете об особенностях Python и C++, которые делают каждый из них подходящим для решения определенных типов задач. Итак, не рассматривайте “против” в Python и C++ как означающее “против”. Скорее, думайте об этом как о сравнении.
Компиляция против виртуальной машины
Давайте начнем с самого главного различия при сравнении Python и C++. В C++ вы используете компилятор, который преобразует ваш исходный код в машинный и создает исполняемый файл. Исполняемый файл представляет собой отдельный файл, который затем может быть запущен как автономная программа:

Этот процесс выводит фактические машинные инструкции для конкретного процессора и операционной системы, для которых он создан. На этом рисунке это программа для Windows. Это означает, что вам придется перекомпилировать вашу программу отдельно для Windows, Mac и Linux:

Вам, вероятно, потребуется изменить свой код на C++, чтобы он также работал в этих разных системах.
Python, с другой стороны, использует другой процесс. Теперь помните, что вы будете рассматривать CPython, который является стандартной реализацией для языка. Если вы не занимаетесь чем-то особенным, то это Python, который вы используете.
Python запускается каждый раз, когда вы выполняете свою программу. Он компилирует исходный код точно так же, как компилятор C++. Разница в том, что Python компилируется в байт-код вместо машинного кода. Байт-код - это собственный код инструкции для виртуальной машины Python. Чтобы ускорить последующие запуски вашей программы, Python сохраняет байт-код в .pyc файлах:

Если вы используете Python 2, то вы найдете эти файлы рядом с файлами .py. Для Python 3 вы найдете их в каталоге __pycache__.
Сгенерированный байт-код не запускается на вашем процессоре изначально. Вместо этого он запускается виртуальной машиной Python. Это похоже на виртуальную машину Java или среду выполнения .NET Common Runtime Environment. Первоначальный запуск вашего кода приведет к этапу компиляции. Затем байт-код будет интерпретирован для работы на вашем конкретном оборудовании:

Пока программа не была изменена, каждый последующий запуск будет пропускать этап компиляции и использовать ранее скомпилированный байт-код для интерпретации:

Интерпретация кода будет происходить медленнее, чем запуск машинного кода непосредственно на оборудовании. Так почему же Python работает именно так? Интерпретация кода на виртуальной машине означает, что только виртуальная машина должна быть скомпилирована для конкретной операционной системы на конкретном процессоре. Весь код на Python, который он запускает, будет выполняться на любой машине, поддерживающей Python.
Примечание: CPython написан на C, поэтому он может работать в большинстве систем, оснащенных компилятором C.
Еще одной особенностью этой кроссплатформенной поддержки является то, что обширная стандартная библиотека Python написана для работы во всех операционных системах.
Использование pathlib,, например, позволит вам управлять разделителями путей независимо от того, используете ли вы Windows, Mac или Linux. Разработчики этих библиотек потратили много времени на то, чтобы сделать их переносимыми, так что вам не нужно беспокоиться об этом в вашей программе на Python!
Прежде чем вы продолжите, давайте рассмотрим таблицу сравнения Python и C++. По мере того, как вы будете описывать новые сравнения, они будут добавляться курсивом:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x |
Теперь, когда вы увидели разницу во времени выполнения при сравнении Python и C++, давайте углубимся в особенности синтаксиса этих языков.
Синтаксические различия
Python и C++ имеют много общего в синтаксисе, но есть несколько областей, заслуживающих обсуждения:
- Пробел
- Логические выражения
- Переменные и указатели
- Понимание
Давайте начнем с самого спорного: с пробелов.
Пробел
Первое, на что обращают внимание большинство разработчиков при сравнении Python и C++, - это “проблема с пробелами”. В Python для обозначения области видимости используется начальный пробел. Это означает, что текст блока if или другой подобной структуры обозначается уровнем отступа. В C++ используются фигурные скобки ({}) для обозначения той же идеи.
В то время как лексер Python будет принимать любые пробелы, если вы будете последовательны, PEP8 (официальное руководство по стилю для Python) указывает По 4 пробела для каждого уровня отступа. Большинство редакторов можно настроить таким образом, чтобы они делали это автоматически.
Было написано огромное количество , кричащих и разглагольствований о правилах использования пробелов в Python мы уже говорили, так что давайте просто оставим этот вопрос в стороне и перейдем к другим вопросам.
Вместо того, чтобы полагаться на лексический маркер, такой как ;, для завершения каждого оператора, Python использует конец строки. Если вам нужно расширить инструкцию на одну строку, вы можете использовать обратную косую черту (\), чтобы указать на это. (Обратите внимание, что если вы находитесь внутри круглых скобок, то символ продолжения не нужен.)
Есть люди, которые недовольны проблемой пробелов с обеих сторон. Некоторым разработчикам Python нравится, что вам не нужно вводить фигурные скобки и точки с запятой. Некоторым разработчикам C++ не нравится зависимость от форматирования. Лучше всего научиться чувствовать себя комфортно и с тем, и с другим.
Теперь, когда вы разобрались с проблемой пробелов, давайте перейдем к менее спорному вопросу: логическим выражениям.
Логические выражения
Способ использования логических выражений немного отличается в Python от C++. В C++ вы можете использовать числовые значения для обозначения true или false в дополнение к встроенным значениям. Все, что имеет значение 0, считается false, в то время как любое другое числовое значение равно true.
В Python есть похожая концепция, но она расширяет ее, включая другие случаи. Основы довольно схожи. В документации на Python указано, что следующие элементы оцениваются следующим образом False:
- Константы, определенные как ложные:
NoneFalse
- Нули любого числового типа:
00.00jDecimal(0)Fraction(0, 1)
- Пустые последовательности и коллекции:
''()[]{}set()range(0)
Все остальные элементы равны True. Это означает, что пустой список [] равен False, в то время как список, содержащий только ноль [0], по-прежнему равен True.
Для большинства объектов значение будет равно True, если только у объекта нет __bool__(), который возвращает False, или __len__(), который возвращает 0. Это позволяет вам расширить ваши пользовательские классы, чтобы они действовали как логические выражения.
В Python также есть несколько незначительных изменений по сравнению с C++ в логических операторах. Для начала, операторы if и while не требуют заключения в круглые скобки, как это делается в C++. Однако круглые скобки могут улучшить читаемость, поэтому руководствуйтесь своим здравым смыслом.
Большинство логических операторов C++ имеют аналогичные операторы в Python:
| C++ Operator | Python Operator |
|---|---|
&& |
and |
|| |
or |
! |
not |
& |
& |
| |
| |
Большинство операторов похожи на C++, но если вы хотите освежить свои знания, вы можете прочитать Операторы и выражения в Python.
Переменные и указатели
Когда вы впервые начинаете использовать Python после написания на C++, вы, возможно, не придаете особого значения переменным. Кажется, что в целом они работают так же, как и в C++. Однако это не одно и то же. В то время как в C++ вы используете переменные для ссылок на значения, в Python вы используете имена.
Примечание: В этом разделе, где вы рассматриваете переменные и имена в Python и C++, вы будете использовать переменные для C++ и названия для Python. В другом месте они оба будут называться переменными.
Сначала давайте немного вернемся назад и более широко рассмотрим объектную модель Python .
В Python все является объектом. Числа хранятся в объектах. Модули хранятся в объектах. Как объект класса , так и сам класс являются объектами. Функции также являются объектами:
>>> a_list_object = list() >>> a_list_object [] >>> a_class_object = list >>> a_class_object <class 'list'> >>> def sayHi(name): ... print(f'Hello, {name}') ... >>> a_function_object = sayHi >>> a_function_object <function sayHi at 0x7faa326ac048>Вызов
list()создает новый объект списка, который вы присваиваетеa_list_object. Использование имени классаlistсамо по себе накладывает метку на объект класса. Вы также можете поместить новую метку на функцию. Это мощный инструмент, и, как все мощные инструменты, он может быть опасен. (Я смотрю на вас, мистер Бензопила.)Примечание: Приведенный выше код показан запущенным в режиме REPL, который расшифровывается как “Цикл чтения, вычисления, печати”. Эта интерактивная среда часто используется для проверки идей на Python и других интерпретируемых языках.
Если вы введете
pythonв командной строке, то откроется окно REPL, в котором вы можете начать вводить код и пробовать все самостоятельно!Возвращаясь к обсуждению Python и C++, обратите внимание, что это поведение отличается от того, что вы увидите в C++. В отличие от Python, в C++ есть переменные, которые привязаны к определенной ячейке памяти, и вы должны указать, сколько памяти будет использовать эта переменная:
int an_int; float a_big_array_of_floats[REALLY_BIG_NUMBER];В Python все объекты создаются в памяти, и вы применяете к ним метки. Сами метки не имеют типов и могут быть применены к объектам любого типа:
>>> my_flexible_name = 1 >>> my_flexible_name 1 >>> my_flexible_name = 'This is a string' >>> my_flexible_name 'This is a string' >>> my_flexible_name = [3, 'more info', 3.26] >>> my_flexible_name [3, 'more info', 3.26] >>> my_flexible_name = print >>> my_flexible_name <built-in function print>Вы можете назначить
my_flexible_nameобъекту любого типа, и Python просто будет работать с ним.Когда вы сравниваете Python и C++, разница в переменных и именах может немного сбить с толку, но это дает некоторые отличные преимущества. Одна из них заключается в том, что в Python у вас нет указателей , и вам никогда не нужно думать о проблемах с кучей и стеком. Чуть позже в этой статье вы познакомитесь с управлением памятью.
Понимание
В Python есть языковая функция, которая называется перечисление понятий. Хотя в C++ можно имитировать понимание списков, это довольно сложно. В Python они являются базовым инструментом, которому обучают начинающих программистов.
Один из способов понимания списков заключается в том, что они похожи на перегруженный инициализатор для списков, диктовок или наборов. Имея один повторяющийся объект, вы можете создать список и отфильтровать или изменить исходный, выполнив это следующим образом:
>>> [x**2 for x in range(5)] [0, 1, 4, 9, 16]Этот скрипт запускается с iterable
range(5)и создает список, содержащий квадрат для каждого элемента в iterable.Можно добавить условия к значениям в первой итерации:
>>> odd_squares = [x**2 for x in range(5) if x % 2] >>> odd_squares [1, 9]
if x % 2в конце этого описания ограничивает использование чисел отrange(5)только нечетными.В этот момент у вас могут возникнуть две мысли:
- Это мощный синтаксический прием, который упростит некоторые части моего кода.
- Вы можете сделать то же самое в C++.
Хотя в C++ действительно можно создать
vectorиз квадратов нечетных чисел, обычно для этого требуется немного больше кода:std::vector<int> odd_squares; for (int ii = 0; ii < 10; ++ii) { if (ii % 2) { odd_squares.push_back(ii*ii); } }Для разработчиков, использующих языки в стиле Си, понимание списков является одним из первых заметных способов, с помощью которых они могут писать больше кода на Python. Многие разработчики начинают писать Python со структуры C++:
odd_squares = [] for ii in range(5): if (ii % 2): odd_squares.append(ii)Это вполне корректный Python. Однако, скорее всего, он будет работать медленнее и не будет таким понятным и сжатым, как при использовании списка. Обучение использованию списков не только ускорит ваш код, но и сделает его более понятным на языке Python и более легким для чтения!
Примечание: Когда вы читаете о Python, вы часто будете видеть слово Pythonic, используемое для описания чего-либо. Это просто термин, который сообщество использует для описания кода, который является чистым, элегантным и выглядит так, как будто он был написан джедаем Python.
Питоновские
std::algorithmsC++ имеет богатый набор алгоритмов, встроенных в стандартную библиотеку. Python имеет аналогичный набор встроенных функций, которые охватывают те же области.
Первым и наиболее эффективным из них является
inоператор, который предоставляет вполне читаемый тест, позволяющий определить, включен ли элемент в список , установите словарь или :>>> x = [1, 3, 6, 193] >>> 6 in x True >>> 7 in x False >>> y = { 'Jim' : 'gray', 'Zoe' : 'blond', 'David' : 'brown' } >>> 'Jim' in y True >>> 'Fred' in y False >>> 'gray' in y FalseОбратите внимание, что оператор
in, используемый в словарях, проверяет только ключи, а не значения. Это показано в заключительном тесте,'gray' in y.
inможет быть объединен сnotдля получения вполне читаемого синтаксиса:if name not in y: print(f"{name} not found")Следующим в вашем списке встроенных операторов Python является
any(). Это логическая функция, которая возвращаетTrue, если какой-либо элемент данной итерируемой переменной равенTrue. Это может показаться немного глупым, пока вы не вспомните, как вы разбираетесь в списках! Сочетание этих двух элементов может привести к созданию мощного и понятного синтаксиса для многих ситуаций:>>> my_big_list = [10, 23, 875] >>> my_small_list = [1, 2, 8] >>> any([x < 3 for x in my_big_list]) False >>> any([x < 3 for x in my_small_list]) TrueНаконец, у вас есть
all(),, который похож наany(). Это возвращаетTrueтолько, если — как вы уже догадались — все элементов в итерируемой переменной равныTrue. Опять же, сочетание этого с пониманием списков создает мощную языковую функцию:>>> list_a = [1, 2, 9] >>> list_b = [1, 3, 9] >>> all([x % 2 for x in list_a]) False >>> all([x % 2 for x in list_b]) True
any()иall()может охватывать во многом ту же область, на которую разработчики C++ обратили бы вниманиеstd::findилиstd::find_if.примечание: в
any()иall()выше примерах, вы можете удалить скобки ([]) без потери функциональности. (например:all(x % 2 for x in list_a)) Здесь используются генераторные выражения, которые, хотя и весьма удобны, выходят за рамки данной статьи.Прежде чем перейти к вводу переменных, давайте обновим вашу таблицу сравнения Python и C++:
Feature Python C++ Faster Execution x Cross-Platform Execution x Single-Type Variables x Multiple-Type Variables x Comprehensions x Rich Set of Built-In Algorithms x x Итак, теперь вы готовы перейти к набору переменных и параметров. Поехали!
Статическая и динамическая типизация
Еще одна важная тема при сравнении Python и C++ - это использование типов данных. C++ - это язык со статической типизацией, в то время как Python - язык с динамической типизацией. Давайте разберемся, что это значит.
Статическая типизация
C++ статически типизирован, что означает, что каждая переменная, которую вы используете в своем коде, должна иметь определенный тип данных, например
int,char,float, и так далее. Вы можете присваивать переменной значения только правильного типа, если только не перепрыгиваете через какие-то препятствия.Это имеет некоторые преимущества как для разработчика, так и для компилятора. Разработчик получает преимущество в том, что заранее знает тип конкретной переменной и, следовательно, какие операции разрешены. Компилятор может использовать информацию о типе для оптимизации кода, делая его меньше, быстрее или и то, и другое вместе.
Однако за эти предварительные знания приходится платить. Параметры, передаваемые в функцию, должны соответствовать типу, ожидаемому функцией, что может снизить гибкость и потенциальную полезность кода.
Набор текста уткой
Динамический ввод часто называют утиным вводом. Это странное название, и вы узнаете об этом подробнее буквально через минуту! Но сначала давайте рассмотрим пример. Эта функция берет файловый объект и считывает первые десять строк:
def read_ten(file_like_object): for line_number in range(10): x = file_like_object.readline() print(f"{line_number} = {x.strip()}")Чтобы использовать эту функцию, вы создадите файловый объект и передадите его в:
with open("types.py") as f: read_ten(f)Здесь показано, как работает базовая структура функции. Хотя эта функция была описана как “чтение первых десяти строк из файлового объекта”, в Python нет ничего, что требовало бы, чтобы
file_like_objectбыло файлом. Пока передаваемый объект поддерживает.readline(), объект может быть любого типа:class Duck(): def readline(self): return "quack" my_duck = Duck() read_ten(my_duck)Вызов
read_ten()с помощью объектаDuckприводит к:0 = quack 1 = quack 2 = quack 3 = quack 4 = quack 5 = quack 6 = quack 7 = quack 8 = quack 9 = quackВ этом суть утиного набора текста. Пословица гласит: “Если это выглядит как утка, плавает как утка и крякает как утка, то это, вероятно, и есть утка”.
Другими словами, если у объекта есть необходимые методы, то его допустимо передавать, независимо от типа объекта. Утиная или динамическая типизация дает вам огромную гибкость, поскольку позволяет использовать любой тип там, где он соответствует требуемым интерфейсам.
Однако здесь есть проблема. Что произойдет, если вы передадите объект, который не соответствует требуемому интерфейсу? Например, что, если вы введете число в
read_ten(), например, так:read_ten(3)?Это приводит к возникновению исключения. Если вы не перехватите исключение, ваша программа завершит работу с обратной трассировкой:
Traceback (most recent call last): File "<stdin>", line 1, in <module> File "duck_test.py", line 4, in read_ten x = file_like_object.readline() AttributeError: 'int' object has no attribute 'readline'Динамический ввод текста может быть довольно мощным инструментом, но, как вы можете видеть, вы должны соблюдать осторожность при его использовании.
Примечание: Python и C++ считаются языками со строгой типизацией. Хотя C++ имеет более совершенную систему типов, детали этого, как правило, не имеют значения для тех, кто изучает Python.
Давайте перейдем к функции, которая извлекает выгоду из динамической типизации в Python: шаблоны.
Шаблоны
В Python нет шаблонов, как в C++, но, как правило, они ему и не нужны. В Python все является подклассом одного базового типа. Это то, что позволяет вам создавать функции уточняющего ввода, подобные описанным выше.
Система шаблонов в C++ позволяет создавать функции или алгоритмы, которые работают с несколькими различными типами файлов. Это довольно мощный инструмент, который может значительно сэкономить ваше время и усилия. Однако это также может стать источником путаницы и разочарования, поскольку ошибки компилятора в шаблонах могут поставить вас в тупик.
Возможность использовать утиный ввод вместо шаблонов значительно упрощает некоторые задачи. Но это тоже может привести к трудноопределимым проблемам. Как и во всех сложных решениях, при сравнении Python и C++ существуют компромиссы.
Проверка типа
В последнее время в сообществе Python наблюдается большой интерес и дискуссии по поводу статической проверки типов в Python. В таких проектах, как mypy, появилась возможность добавлять проверку типов перед выполнением в определенные области языка. Это может быть весьма полезно при управлении интерфейсами между частями больших пакетов или конкретными API.
Это помогает устранить один из недостатков утиной типизации. Разработчикам, использующим функцию, полезно, если они могут полностью понять, каким должен быть каждый параметр. Это может быть полезно в больших проектных командах, где многим разработчикам необходимо взаимодействовать через API.
Давайте еще раз взглянем на вашу сравнительную таблицу Python и C++:
Feature Python C++ Faster Execution x Cross-Platform Execution x Single-Type Variables x Multiple-Type Variables x Comprehensions x Rich Set of Built-In Algorithms x x Static Typing x Dynamic Typing x Теперь вы готовы перейти к различиям в объектно-ориентированном программировании.
Объектно-ориентированное программирование
Как и C++, Python поддерживает объектно-ориентированную модель программирования. Многие из тех концепций, которые вы изучали на C++, переносятся в Python. Вам все равно придется принимать решения о наследовании, композиции и множественном наследовании.
Сходства
Наследование между классами работает аналогично в Python и C++. Новый класс может наследовать методы и атрибуты от одного или нескольких базовых классов, точно так же, как вы видели в C++. Однако некоторые детали немного отличаются.
Конструктор базовых классов в Python не вызывается автоматически, как в C++. Это может привести к путанице при переключении языков.
Множественное наследование также работает в Python, и в нем столько же особенностей и странных правил, сколько и в C++.
Аналогично, вы также можете использовать композицию для создания классов, в которых объекты одного типа содержат объекты других типов. Учитывая, что в Python все является объектами, это означает, что классы могут содержать что угодно еще в этом языке.
Различия
Однако при сравнении Python и C++ есть некоторые различия. Первые два параметра связаны между собой.
Первое отличие заключается в том, что в Python нет понятия модификаторов доступа к классам. Все объекты класса являются общедоступными. Сообщество Python разработало соглашение, согласно которому любой член класса, начинающийся с одного символа подчеркивания , считается закрытым. Это никоим образом не предусмотрено языком, но, похоже, работает довольно хорошо.
Тот факт, что каждый член класса и метод являются общедоступными в Python, приводит ко второму отличию: Python имеет гораздо более слабую поддержку инкапсуляции, чем C++.
Как уже упоминалось, соглашение об одиночном подчеркивании делает эту проблему гораздо менее актуальной в практических кодовых базах, чем в теоретическом смысле. В общем, любой пользователь, нарушающий это правило и зависящий от внутренней работы класса, нарывается на неприятности.
Перегрузки операторов в сравнении с методами Dunder
В C++ вы можете добавить перегрузки операторов. Они позволяют вам определять поведение определенных синтаксических операторов (например,
==) для определенных типов данных. Обычно это используется для более естественного использования ваших классов. Для оператора==вы можете точно определить, что означает, что два объекта класса равны.Одно из отличий, на понимание которого у некоторых разработчиков уходит много времени, заключается в том, как обойти отсутствие перегрузки операторов в Python. Замечательно, что все объекты Python работают в любом из стандартных контейнеров, но что, если вы хотите, чтобы оператор
==выполнял глубокое сравнение между двумя объектами вашего нового класса? В C++ вы бы создалиoperator==()в своем классе и провели сравнение.У Python похожая структура, которая используется довольно последовательно во всех языках: методы dunder. Методы Dunder получили свое название потому, что все они начинаются и заканчиваются двойным подчеркиванием, или “d-под”.
Многие из встроенных функций, которые работают с объектами в Python, обрабатываются вызовами методов dunder этого объекта . В приведенном выше примере вы можете добавить
__eq__()в свой класс, чтобы выполнить любое необычное сравнение, которое вам нравится:class MyFancyComparisonClass(): def __eq__(self, other): return TrueЭто создает класс, который сравнивается так же, как и любой другой экземпляр этого класса. Не особенно полезно, но демонстрирует суть.
В Python используется большое количество методов dunder, и встроенные функции широко их используют. Например, добавление
__lt__()позволит Python сравнить относительный порядок расположения двух ваших объектов. Это означает, что теперь будет работать не только оператор<, но и операторы>,<=, и>=.Еще лучше, если у вас есть несколько объектов вашего нового класса в списке, тогда вы можете использовать
sorted()в списке, и они будут отсортированы с помощью__lt__().Давайте еще раз взглянем на вашу сравнительную таблицу Python и C++:
Feature Python C++ Faster Execution x Cross-Platform Execution x Single-Type Variables x Multiple-Type Variables x Comprehensions x Rich Set of Built-In Algorithms x x Static Typing x Dynamic Typing x Strict Encapsulation x Теперь, когда вы познакомились с объектно-ориентированным программированием на обоих языках, давайте посмотрим, как Python и C++ управляют этими объектами в памяти.
Управление памятью
Одно из самых больших различий, когда вы сравниваете Python и C++, заключается в том, как они обрабатывают память. Как вы видели в разделе о переменных в C++ и именах Python, Python не содержит указателей и не позволяет легко манипулировать памятью напрямую. Хотя иногда вам хочется иметь такой уровень контроля, в большинстве случаев в этом нет необходимости.
Отказ от прямого управления ячейками памяти дает ряд преимуществ. Вам не нужно беспокоиться о владении памятью или о том, чтобы убедиться, что память освобождается один (и только один) раз после ее выделения. Вам также никогда не придется беспокоиться о том, был ли объект размещен в стеке или куче, что, как правило, сбивает с толку начинающих разработчиков C++.
Python решает все эти проблемы за вас. Для этого все, что есть в Python, является производным классом от
objectPython. Это позволяет интерпретатору Python реализовать подсчет ссылок как средство отслеживания того, какие объекты все еще используются, а какие могут быть освобождены.За это удобство, конечно, приходится платить. Чтобы освободить выделенные вам объекты памяти, Python иногда нужно запускать так называемый сборщик мусора, который находит неиспользуемые объекты памяти и освобождает их.
Примечание: CPython имеет сложную схему управления памятью , что означает, что освобождение памяти не обязательно означает, что память возвращается в операционную систему.
Python использует два инструмента для освобождения памяти:
- Коллектор для подсчета ссылок
- Коллектор поколений
Давайте рассмотрим каждый из них в отдельности.
Коллектор для подсчета ссылок
Сборщик подсчета ссылок является фундаментальным для стандартного интерпретатора Python и всегда запущен. Он работает, отслеживая, сколько раз к данному блоку памяти (который всегда является Python
object) присваивалось имя во время выполнения вашей программы. Многие правила описывают, когда количество ссылок увеличивается или уменьшается, но пример одного случая может прояснить ситуацию:1>>> x = 'A long string' 2>>> y = x 3>>> del x 4>>> del yВ приведенном выше примере в строке 1 создается новый объект, содержащий строку
"A long string". Затем этому объекту присваивается имяx, что увеличивает количество ссылок на объект до 1:
В строке 2 он присваивает
yимя тому же объекту, что увеличит количество ссылок до 2: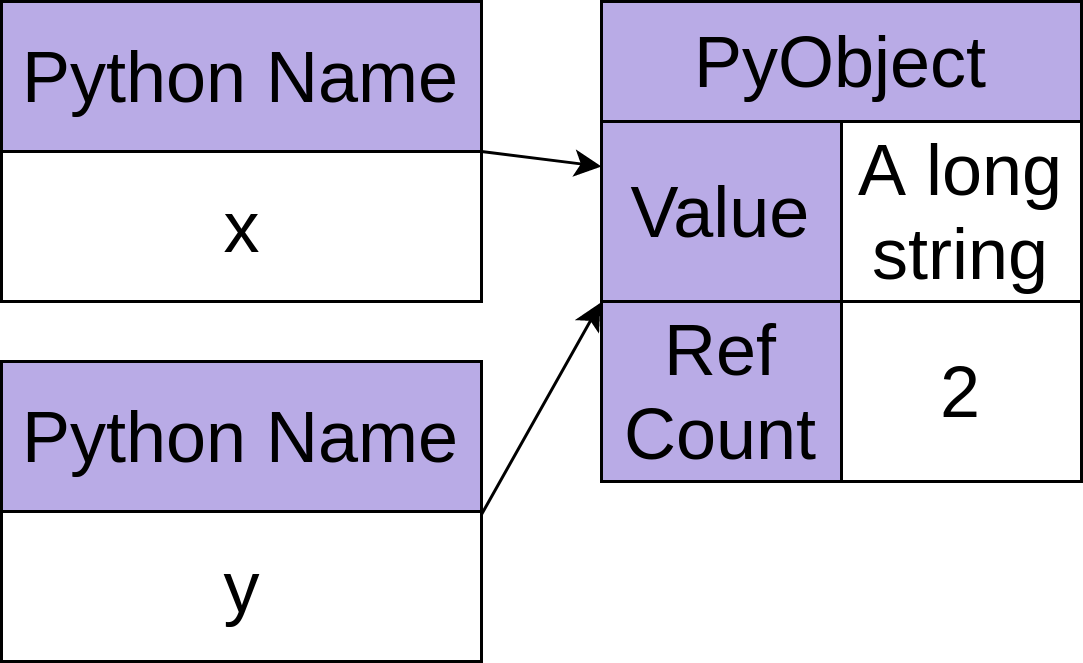
Когда вы вызываете
delс помощьюxв строке 3, вы удаляете одну из ссылок на объект, возвращая значение count обратно к 1:
Наконец, когда вы удаляете
y, последнюю ссылку на объект, количество его ссылок падает до нуля, и он может быть освобожден сборщиком мусора, подсчитывающим ссылки. На данный момент он может быть немедленно освобожден, а может и не быть, но, как правило, это не должно иметь значения для разработчика:
Хотя это позволит найти и освободить многие объекты, которые необходимо освободить, есть несколько ситуаций, в которых это не сработает. Для этого вам понадобится сборщик мусора поколения.
Сборщик мусора нового поколения
Одним из больших недостатков схемы подсчета ссылок является то, что ваша программа может создавать цикл ссылок, где объект
Aимеет ссылку на объектB, который имеет обратную ссылку на объектA. Вполне возможно, что в такой ситуации в вашем коде не будет ссылок ни на один из объектов. В этом случае количество ссылок ни на один из объектов никогда не достигнет 0.Сборщик мусора поколения использует сложный алгоритм, который выходит за рамки этой статьи, но он найдет некоторые из этих потерянных ссылочных циклов и освободит их для вас. Он запускается время от времени в соответствии с настройками, описанными в документации. Одним из этих параметров является полное отключение этого сборщика мусора.
Когда Вы не хотите собирать мусор
Когда вы сравниваете Python и C++, как и при сравнении любых двух инструментов, каждое преимущество имеет свои недостатки. Python не требует явного управления памятью, но иногда на сборку мусора уходит больше времени, чем ожидалось. Для C++ верно обратное: у вашей программы будет стабильное время отклика, но вам потребуется приложить больше усилий для управления памятью.
Во многих программах случайные сбои при сборке мусора не имеют значения. Если вы пишете скрипт, который выполняется всего 10 секунд, то вряд ли заметите разницу. Однако в некоторых ситуациях требуется постоянное время отклика. Отличным примером могут служить системы реального времени, в которых реагирование на аппаратные средства в течение определенного периода времени может иметь важное значение для правильной работы вашей системы.
Системы с жесткими требованиями к работе в режиме реального времени - это одни из тех систем, для которых Python является неподходящим языком. Наличие жестко контролируемой системы, в которой вы уверены в сроках, является хорошим вариантом использования C++. Это те вопросы, которые следует учитывать при выборе языка для проекта.
Время обновить таблицу Python и C++:
Feature Python C++ Faster Execution x Cross-Platform Execution x Single-Type Variables x Multiple-Type Variables x Comprehensions x Rich Set of Built-In Algorithms x x Static Typing x Dynamic Typing x Strict Encapsulation x Direct Memory Control x Garbage Collection x Многопоточность, многопроцессорность и асинхронный ввод-вывод
Модели параллелизма в C++ и Python схожи, но они дают разные результаты и преимущества. Оба языка поддерживают многопоточность, многопроцессорность и асинхронные операции ввода-вывода. Давайте рассмотрим каждый из них.
Нарезание резьбы
Хотя и в C++, и в Python встроена многопоточность, результаты могут заметно отличаться в зависимости от решаемой задачи. Часто для решения проблем с производительностью используется многопоточность . В C++ многопоточность может обеспечить общее ускорение решения задач, связанных как с вычислениями, так и с вводом-выводом, поскольку потоки могут в полной мере использовать преимущества ядер многопроцессорной системы.
Python, с другой стороны, пошел на конструктивный компромисс, чтобы использовать Глобальную блокировку интерпретатора или GIL, чтобы упростить его многопоточную реализацию. У GIL много преимуществ, но недостаток заключается в том, что одновременно будет запущен только один поток, даже при наличии нескольких ядер.
Если ваша проблема связана с вводом-выводом, например, с выборкой нескольких веб-страниц одновременно, то это ограничение вас нисколько не побеспокоит. Вы по достоинству оцените упрощенную потоковую модель Python и встроенные методы для взаимодействия между потоками. Однако, если ваша проблема связана с процессором, то GIL ограничит вашу производительность до уровня одного процессора. К счастью, многопроцессорная библиотека Python имеет интерфейс, аналогичный интерфейсу потоковой библиотеки.
Многопроцессорная обработка
Поддержка многопроцессорности в Python встроена в стандартную библиотеку. Она имеет понятный интерфейс, который позволяет запускать несколько процессов и обмениваться информацией между ними. Вы можете создать пул процессов и распределить работу по ним, используя несколько методов.
Хотя Python по-прежнему использует аналогичные примитивы операционной системы для создания новых процессов, большая часть низкоуровневых сложностей скрыта от разработчика.
C++ использует
fork()для обеспечения поддержки многопроцессорности. Хотя это дает вам прямой доступ ко всем элементам управления и решает проблемы, связанные с запуском нескольких процессов, это также намного сложнее.Асинхронный ввод-вывод
Хотя и Python, и C++ поддерживают процедуры асинхронного ввода-вывода, они обрабатываются по-разному. В C++ методы
std::async, скорее всего, используют многопоточность для достижения асинхронного характера операций ввода-вывода. В Python Код асинхронного ввода-вывода будет выполняться только в одном потоке.Здесь также есть компромиссы. Использование отдельных потоков позволяет коду асинхронного ввода-вывода на C++ быстрее выполнять задачи, связанные с вычислениями. Задачи Python, используемые в его реализации асинхронного ввода-вывода, более легкие, поэтому их большое количество можно быстрее использовать для решения проблем, связанных с вводом-выводом.
В этом разделе таблица сравнения Python и C++ остается неизменной. Оба языка поддерживают полный спектр возможностей параллелизма с различными компромиссами между скоростью и удобством.
Прочие вопросы
Если вы сравниваете Python с C++ и рассматриваете возможность добавления Python в свой набор инструментов, то есть еще несколько моментов, которые следует учитывать. Хотя ваш текущий редактор или IDE, безусловно, будут работать с Python, вы можете захотеть добавить определенные расширения или языковые пакеты. Также стоит обратить внимание на PyCharm, поскольку он специфичен для Python.
Несколько проектов на C++ имеют привязки к Python. Такие вещи, как Qt, wxWidgets и многие API обмена сообщениями, имеющие многоязычные привязки.
Если вы хотите встроить Python в C++, то вы можете использовать API Python/C.
Наконец, есть несколько способов использовать свои навыки работы с C++ для расширения Python и добавления функциональности или для вызова существующих библиотек C++ из вашего кода на Python. Такие инструменты, как CTypes, Cython, CFFI, Boost.Python и Swig помогут вам объединить эти языки и использовать каждый из них наилучшим образом.
Краткое описание: Python против C++
Вы потратили некоторое время на чтение и обдумывание различий между Python и C++. Хотя синтаксис Python проще и у него меньше острых углов, он не идеально подходит для решения всех задач. Вы рассмотрели синтаксис, управление памятью, обработку и некоторые другие аспекты этих двух языков.
Давайте в последний раз взглянем на вашу сравнительную таблицу Python и C++:
Feature Python C++ Faster Execution x Cross-Platform Execution x Single-Type Variables x Multiple-Type Variables x Comprehensions x Rich Set of Built-In Algorithms x x Static Typing x Dynamic Typing x Strict Encapsulation x Direct Memory Control x Garbage Collection x Если вы сравниваете Python и C++, то из вашей диаграммы вы можете видеть, что это не тот случай, когда один из них лучше другого. Каждый из них - это инструмент, который хорошо разработан для различных случаев использования. Точно так же, как вы не пользуетесь молотком для забивания шурупов, правильное использование языка для выполнения работы облегчит вашу жизнь!
Заключение
Поздравляю! Теперь вы увидели некоторые сильные и слабые стороны как Python, так и C++. Вы узнали о некоторых особенностях каждого языка и о том, чем они похожи.
Вы видели, что C++ великолепен, когда вы хотите:
- Высокая скорость выполнения (возможно, за счет скорости разработки)
- Полный контроль над памятью
И наоборот, Python хорош, когда вы хотите:
- Высокая скорость разработки (возможно, за счет скорости выполнения)
- Управляемая память
Теперь вы готовы сделать правильный выбор языка, когда дело дойдет до вашего следующего проекта!
<статус завершения article-slug="python-vs-cpp" class="btn-group mb-0" data-api-article-bookmark-url="/api/v1/articles/python-vs-cpp/bookmark/" data-api-article-завершение-статус-url="/api/v1/articles/python-vs-cpp/завершение_статуса/"> <кнопка поделиться bluesky-text="Интересная статья на #Python от @realpython.com :" email-body="Ознакомьтесь с этой статьей о Python:%0A%0APython против C++: выбор подходящего инструмента для работы" email-subject="Статья о Python для вас" twitter-text="Интересная статья на #Python от @realpython:" url="https://realpython.com/python-vs-cpp/" url-title="Python против C++: выбор подходящего инструмента для работы"> Back to Top