Практические задачи по Python: Приготовьтесь к следующему собеседованию
Оглавление
- Практическая задача на Python 1: Сумма ряда целых чисел
- Практическая задача 2 на Python: Шифр Цезаря
- Практическая задача 3 на Python: Восстановление шифра Цезаря
- Практическая задача 4 на Python: Анализатор журналов
- Практическая задача 5 на Python: Решатель судоку
- Заключение
Вы разработчик на Python, совершенствующий свои навыки перед собеседованием? Если это так, то в этом руководстве вы познакомитесь с серией практических задач на Python, предназначенных для моделирования распространенных сценариев тестирования кода. После того как вы разработаете свои собственные решения, вы ознакомитесь с ответами команды Real Python, чтобы оптимизировать свой код, произвести впечатление на интервьюера и получить работу своей мечты!
В этом руководстве вы узнаете, как:
- Напишите код для задач в стиле интервью
- Обсудите свои решения во время собеседования
- Проработайте часто упускаемых деталей
- Поговорим о дизайнерских решениях и компромиссах
Это руководство предназначено для разработчиков на Python среднего уровня. Оно предполагает базовые знания Python и умение решать задачи на Python. Вы можете получить базовый код с неудачными модульными тестами для каждой из проблем, которые вы увидите в этом руководстве, перейдя по ссылке ниже:
Для каждой из приведенных ниже задач приведен заголовок файла из этого основного кода, описывающий требования к задаче. Итак, скачайте код, запустите свой любимый редактор и давайте разберемся с некоторыми практическими задачами на Python!
Практическая задача на Python 1: Сумма ряда целых чисел
Давайте начнем с вопроса для разминки. В первой практической задаче вы напишете код для суммирования списка из целых чисел. Каждая практическая задача содержит описание задачи. Это описание взято непосредственно из файлов-скелетов в репозитории, чтобы его было легче запомнить во время работы над вашим решением.
Вы также увидите раздел с решениями для каждой проблемы. Большая часть обсуждения будет приведена в развернутом разделе ниже. Клонируйте это репозиторий, если вы еще этого не сделали, разработайте решение следующей проблемы, затем разверните окно решения, чтобы просмотреть свою работу.
Описание проблемы
Вот ваша первая проблема:
Сумма целых чисел С Точностью До n (
integersums.py)Напишите функцию,
add_it_up(), которая принимает одно целое число в качестве входных данных и возвращает сумму целых чисел от нуля до входного параметра.Функция должна возвращать 0, если передано нецелое число.
Не забывайте запускать модульные тесты до тех пор, пока они не будут успешно пройдены!
Решение проблемы
Вот краткое обсуждение нескольких возможных решений.
Примечание: Помните, не открывайте свернутый раздел ниже, пока не будете готовы ознакомиться с ответом на эту практическую задачу на Python!
Как прошло написание решения? Готовы взглянуть на ответ?
Для этой задачи вы рассмотрите несколько различных решений. Первое из них не так хорошо:
# integersums.py
def first(n):
num = 1
sum = 0
while num < n + 1:
sum = sum + num
num = num + 1
return sum
В этом решении вы вручную создаете цикл while для прохождения чисел от 1 до n. Вы сохраняете запущенный sum, а затем возвращаете его, когда завершаете цикл.
Это решение работает, но у него есть две проблемы:
-
Это не показывает ваших знаний Python и того, как этот язык упрощает подобные задачи.
-
Это не соответствует условиям ошибки, указанным в описании проблемы. Передача строки приведет к тому, что функция выдаст исключение, когда она должна просто вернуть
0.
Вы разберетесь с условиями ошибки в окончательном ответе ниже, но сначала давайте доработаем основное решение, чтобы оно было немного более питоническим.
Первое, о чем нужно подумать, это то, что while цикл. В Python есть мощные механизмы для итерации по спискам и диапазонам. Создавать свой собственный, как правило, не нужно, и в данном случае, безусловно, именно так. Вы можете заменить цикл while циклом, который повторяется по range():
# integersums.py
def better(n):
sum = 0
for num in range(n + 1):
sum += num
return sum
Вы можете видеть, что конструкция for...range() заменила ваш цикл while и сократила код. Следует отметить, что range() соответствует указанному числу, но не включает его, поэтому здесь вам нужно использовать n + 1.
Это был хороший шаг! Он устраняет часть шаблонного кода для зацикливания на диапазоне и проясняет ваши намерения. Но здесь вы можете сделать еще больше.
Суммирование списка целых чисел - это еще одна вещь, в которой Python хорош:
# integersums.py
def even_better(n):
return sum(range(n + 1))
Ничего себе! С помощью встроенного sum(), вы сократили это до одной строчки кода! Хотя code golf обычно не создает наиболее читаемый код, в данном случае у вас есть беспроигрышный вариант: более короткий и более читаемый код.
Однако остается одна проблема. Этот код по-прежнему неправильно обрабатывает условия ошибки. Чтобы исправить это, вы можете обернуть свой предыдущий код в блок try...except:
# integersums.py
def add_it_up(n):
try:
result = sum(range(n + 1))
except TypeError:
result = 0
return result
Это решает проблему и корректно обрабатывает условия ошибки. Так держать!
Иногда интервьюеры задают этот вопрос с фиксированным ограничением, что-то вроде “Выведите сумму первых девяти целых чисел”. Когда проблема сформулирована таким образом, одним из правильных решений было бы print(45).
Однако, если вы дадите этот ответ, то вам следует перейти к коду, который решает проблему шаг за шагом. Ответ с подвохом - хорошее начало для вашего ответа, но не самое подходящее место для завершения.
Если вы хотите расширить эту проблему, попробуйте добавить необязательный нижний предел к add_it_up(), чтобы придать ей больше гибкости!
Практическая задача 2 на Python: Шифр Цезаря
Следующий вопрос состоит из двух частей. Вы создадите функцию для вычисления шифра Цезаря при вводе текста. Для решения этой задачи вы можете использовать любую часть стандартной библиотеки Python для выполнения преобразования.
Подсказка: В классе str есть функция, которая значительно упростит эту задачу!
Описание проблемы
Описание проблемы находится в верхней части исходного файла скелета:
Шифр Цезаря (
caesar.py)Шифр Цезаря - это простой шифр подстановки, в котором каждая буква открытого текста заменяется буквой, найденной путем перемещения
nпозиций вниз по алфавиту. Например, предположим, что вводимый обычный текст выглядит следующим образом:abcd xyzЕсли значение сдвига,
n, равно 4, то зашифрованный текст будет выглядеть следующим образом:efgh bcdВам нужно написать функцию, которая принимает два аргумента, сообщение в виде обычного текста и количество букв, которые необходимо изменить в шифре. Функция вернет зашифрованную строку, в которой все буквы будут преобразованы, а знаки препинания и пробелы останутся неизменными.
Примечание: Вы можете предположить, что весь обычный текст написан строчными буквами ASCII, за исключением пробелов и знаков препинания.
Помните, что эта часть вопроса на самом деле касается того, насколько хорошо вы можете работать со стандартной библиотекой. Если вы обнаружите, что не знаете, как выполнить преобразование без библиотеки, оставьте эту мысль при себе! Она понадобится вам позже!
Решение проблемы
Вот решение проблемы с шифром Цезаря, описанное выше.
Примечание: Помните, не открывайте свернутый раздел ниже, пока не будете готовы ознакомиться с ответами на эту практическую задачу по Python!
В этом решении используется .translate() из класса str в стандартной библиотеке. Если вы столкнулись с этой проблемой, то, возможно, захотите сделать паузу и подумать о том, как вы могли бы использовать .translate() в своем решении.
Хорошо, теперь, когда вы готовы, давайте рассмотрим это решение:
1# caesar.py
2import string
3
4def caesar(plain_text, shift_num=1):
5 letters = string.ascii_lowercase
6 mask = letters[shift_num:] + letters[:shift_num]
7 trantab = str.maketrans(letters, mask)
8 return plain_text.translate(trantab)
Вы можете видеть, что функция использует три элемента из модуля string:
.ascii_lowercase.maketrans().translate()
В первых двух строках вы создаете переменную со всеми строчными буквами алфавита (только ASCII для этой программы), а затем создаете mask, который представляет собой тот же набор букв, только со сдвигом. Синтаксис нарезки не всегда очевиден, поэтому давайте рассмотрим его на примере из реального мира:
>>> import string
>>> x = string.ascii_lowercase
>>> x
'abcdefghijklmnopqrstuvwxyz'
>>> x[3:]
'defghijklmnopqrstuvwxyz'
>>> x[:3]
'abc'
Вы можете видеть, что x[3:] - это все буквы после третьей буквы, 'c', в то время как x[:3] - это только первая буква. первые три буквы.
Строка 6 в решении, letters[shift_num:] + letters[:shift_num], создает список букв, сдвинутых на shift_num буквы, при этом буквы в конце обтекаются спереди. Как только у вас будет список букв и mask букв, которые вы хотите сопоставить, вы вызываете .maketrans(), чтобы создать таблицу перевода.
Затем вы передаете таблицу перевода методу string .translate(). Он сопоставляет все символы в letters с соответствующими буквами в mask и оставляет все остальные символы в покое.
Этот вопрос - упражнение на знание и использование стандартной библиотеки. Вам могут задать подобный вопрос в какой-то момент во время собеседования. Если это случится с вами, полезно потратить некоторое время на обдумывание возможных ответов. Если вы можете вспомнить метод — .translate() в данном случае — тогда все готово.
Но есть несколько других сценариев, которые следует рассмотреть:
-
Вы можете полностью заполнить пробел. В этом случае вы, вероятно, решите эту проблему так же, как вы решаете следующую, и это приемлемый ответ.
-
Возможно, вы помните, что в стандартной библиотеке есть функция, позволяющая делать то, что вы хотите, но не запоминать детали.
Если бы вы выполняли обычную работу и столкнулись с любой из этих ситуаций, вы бы просто немного поискали и продолжили свой путь. Но в ситуации собеседования вашему делу поможет озвучить проблему вслух.
Просить интервьюера о конкретной помощи гораздо лучше, чем просто игнорировать ее. Попробуйте что-нибудь вроде “Я думаю, что есть функция, которая сопоставляет один набор символов с другим. Не могли бы вы помочь мне вспомнить, как это называется?”
В ситуации собеседования часто лучше признать, что вы чего-то не знаете, чем пытаться блефовать.
Теперь, когда вы увидели решение, использующее стандартную библиотеку Python, давайте попробуем решить ту же проблему еще раз, но без этой помощи!
Практическая задача 3 на Python: Восстановление шифра Цезаря
В третьей тренировочной задаче вы снова решите шифр Цезаря, но на этот раз вы сделаете это без использования .translate().
Описание проблемы
Описание этой задачи такое же, как и в предыдущей. Прежде чем приступить к решению, вы, возможно, задаетесь вопросом, почему вы повторяете одно и то же упражнение, только без помощи .translate().
Это отличный вопрос. В обычной жизни, когда ваша цель - получить работающую, удобную в обслуживании программу, переписывать части стандартной библиотеки - плохой выбор. Стандартная библиотека Python содержит работающие, хорошо протестированные и быстрые решения для больших и малых задач. Использование всех ее преимуществ - признак хорошего программиста.
Тем не менее, это не рабочий проект и не программа, которую вы разрабатываете для удовлетворения потребностей. Это учебное упражнение, и именно такой вопрос может быть задан во время собеседования. Цель обоих проектов - увидеть, как вы можете решить проблему и на какие интересные дизайнерские компромиссы вы при этом идете.
Итак, в духе обучения, давайте попробуем разгадать шифр Цезаря без .translate().
Решение проблемы
Для решения этой проблемы у вас будет два разных решения, которые вы сможете рассмотреть, когда будете готовы расширить раздел ниже.
Примечание: Помните, не открывайте свернутый раздел ниже, пока не будете готовы ознакомиться с ответами на эту практическую задачу по Python!
Для этой задачи предлагаются два разных решения. Ознакомьтесь с обоими и посмотрите, какое из них вам больше нравится!
Решение 1
Для первого решения вы внимательно следите за описанием задачи, добавляя количество к каждому символу и возвращая его в начало алфавита, когда он переходит за пределы z:
1# caesar.py
2import string
3
4def shift_n(letter, amount):
5 if letter not in string.ascii_lowercase:
6 return letter
7 new_letter = ord(letter) + amount
8 while new_letter > ord("z"):
9 new_letter -= 26
10 while new_letter < ord("a"):
11 new_letter += 26
12 return chr(new_letter)
13
14def caesar(message, amount):
15 enc_list = [shift_n(letter, amount) for letter in message]
16 return "".join(enc_list)
Начиная со строки 14, вы можете видеть, что caesar() выполняет анализ списка, вызывая вспомогательную функцию для каждой буквы в message. Затем он выполняет .join(), чтобы создать новую закодированную строку. Это коротко и понятно, и вы увидите аналогичную структуру во втором решении. Самое интересное происходит в shift_n().
Здесь вы можете увидеть другое применение для string.ascii_lowercase, на этот раз отфильтровывая все буквы, которых нет в этой группе. Как только вы убедитесь, что отфильтровали все буквы, не входящие в эту группу, вы можете перейти к кодированию. В этой версии кодирования вы используете две функции из стандартной библиотеки Python:
Опять же, вам рекомендуется не только изучить эти функции, но и подумать о том, как вы могли бы ответить на собеседовании, если бы не смогли вспомнить их имена.
ord() выполняет работу по преобразованию буквы в число, а chr() преобразует ее обратно в букву. Это удобно, так как позволяет выполнять арифметические действия с буквами, что и требуется для данной задачи.
На первом шаге кодирования в строке 7 вы получаете числовое значение закодированной буквы, используя ord() для получения числового значения исходной буквы. ord() возвращает Юникод кодовая точка символа, который оказывается значением ASCII.
Для многих букв с небольшими значениями сдвига вы можете преобразовать букву обратно в символ, и все будет готово. Но обратите внимание на начальную букву, z.
При сдвиге на один символ должна получиться буква a. Для достижения этого результата необходимо найти разницу между закодированной буквой и буквой z. Если эта разница положительна, то вам нужно вернуться к началу.
Это делается в строках с 8 по 11 путем многократного добавления 26 к символу или вычитания из него, пока он не окажется в диапазоне символов ASCII. Обратите внимание, что это довольно неэффективный метод устранения этой проблемы. Вы увидите лучшее решение в следующем ответе.
Наконец, в строке 12 ваша функция преобразования shift принимает числовое значение новой буквы и преобразует его обратно в букву, чтобы вернуть ее.
Хотя в этом решении используется буквальный подход к решению задачи о шифре Цезаря, вы также можете использовать другой подход, основанный на решении .translate() из практической задачи 2.
Решение 2
Второе решение этой проблемы имитирует поведение встроенного метода Python .translate(). Вместо того, чтобы сдвигать каждую букву на заданную величину, он создает карту перевода и использует ее для кодирования каждой буквы:
1# caesar.py
2import string
3
4def shift_n(letter, table):
5 try:
6 index = string.ascii_lowercase.index(letter)
7 return table[index]
8 except ValueError:
9 return letter
10
11def caesar(message, amount):
12 amount = amount % 26
13 table = string.ascii_lowercase[amount:] + string.ascii_lowercase[:amount]
14 enc_list = [shift_n(letter, table) for letter in message]
15 return "".join(enc_list)
Начиная с caesar() в строке 11, вы начинаете с устранения проблемы, заключающейся в том, что amount больше, чем 26. В предыдущем решении вы повторяли цикл несколько раз, пока результат не был в нужном диапазоне. Здесь вы используете более прямой и эффективный подход, используя оператор mod (%).
Оператор mod вычисляет остаток от целочисленного деления. В этом случае вы делите на 26, что означает, что результаты гарантированно будут от 0 до 25 включительно.
Далее вы создаете таблицу перевода. Это изменение отличается от предыдущих решений и заслуживает некоторого внимания. Подробнее об этом вы узнаете в конце этого раздела.
Как только вы создадите table, остальная часть caesar() будет идентична предыдущему решению: список для шифрования каждой буквы и .join() для создания строки.
shift_n() находит индекс данной буквы в алфавите, а затем использует его для извлечения буквы из table. Блок try...except фиксирует те регистры, которые не найдены в списке строчных букв.
Теперь давайте обсудим проблему создания таблиц. Для этого игрушечного примера это, вероятно, не имеет большого значения, но он иллюстрирует ситуацию, которая часто возникает в повседневной разработке: баланс между ясностью кода и известными узкими местами производительности.
Если вы еще раз изучите код, то увидите, что table используется только внутри shift_n(). Это указывает на то, что в обычных обстоятельствах он должен был быть создан в и, следовательно, его область применения ограничена, shift_n():
# caesar.py
import string
def slow_shift_n(letter, amount):
table = string.ascii_lowercase[amount:] + string.ascii_lowercase[:amount]
try:
index = string.ascii_lowercase.index(letter)
return table[index]
except ValueError:
return letter
def slow_caesar(message, amount):
amount = amount % 26
enc_list = [shift_n(letter, amount) for letter in message]
return "".join(enc_list)
Проблема этого подхода в том, что он тратит время на вычисление одной и той же таблицы для каждой буквы сообщения. Для небольших сообщений этим временем можно пренебречь, но для больших сообщений оно может увеличиться.
Другим возможным способом избежать этого снижения производительности было бы создать table в качестве глобальной переменной. Хотя это также сокращает штраф за строительство, это делает область применения table еще больше. Этот подход не кажется лучше, чем подход, показанный выше.
В конечном счете, выбор между созданием table сразу и расширением области его применения или просто созданием его для каждой буквы - это то, что называется дизайнерским решением. Вам нужно выбрать дизайн, основываясь на том, что вы знаете о реальной проблеме, которую пытаетесь решить.
Если это небольшой проект, и вы знаете, что он будет использоваться для кодирования больших сообщений, то создание таблицы только один раз может быть правильным решением. Если это только часть более крупного проекта, а это означает, что удобство обслуживания является ключевым фактором, то, возможно, лучшим вариантом будет создание таблицы каждый раз.
Поскольку вы рассмотрели два решения, стоит уделить немного времени обсуждению их сходств и различий.
Сравнение решений
В этой части шифра Цезаря вы видели два решения, и они во многом схожи. В них примерно одинаковое количество строк. Две основные процедуры идентичны, за исключением ограничения amount и создания table. Различия проявляются только при рассмотрении двух версий вспомогательной функции shift_n().
Первый shift_n() - это почти буквальный перевод того, о чем просит задача: “Сдвиньте букву вниз по алфавиту и оберните ее на z”. Это явно соответствует постановке задачи, но имеет несколько недостатков.
Хотя он примерно такой же длины, как и вторая версия, первая версия shift_n() более сложная. Эта сложность связана с преобразованием букв и математическими расчетами, необходимыми для перевода. Необходимые детали — преобразование в числа, вычитание и перенос - маскируют выполняемую операцию. Вторая операция shift_n() гораздо менее детализирована.
Первая версия функции также предназначена для решения этой конкретной задачи. Вторая версия shift_n(), как и версия стандартной библиотеки .translate(), на основе которой она создана, является более универсальной и может использоваться для решения более широкого круга задач. Обратите внимание, что это не обязательно является хорошей целью проектирования.
Одна из мантр, пришедших из движения Экстремальное программирование, звучит так: “Тебе это не понадобится” (ЯГНИ). Часто разработчики программного обеспечения рассматривают функцию, подобную shift_n(), и решают, что она была бы лучше и более универсальной, если бы они сделали ее еще более гибкой, возможно, передав параметр вместо использования string.ascii_lowercase.
Хотя это действительно сделало бы функцию более универсальной, это также сделало бы ее более сложной. Мантра ЯГНИ призвана напомнить вам, что не следует усложнять ее, пока у вас нет конкретного варианта использования.
Подводя итог вашему разделу о шифре Цезаря, скажу, что между этими двумя решениями есть явные компромиссы, но второе shift_n() кажется немного лучшей и более питонической функцией.
Теперь, когда вы написали шифр Цезаря тремя разными способами, давайте перейдем к новой задаче.
Практическая задача 4 на Python: анализатор журналов
Проблема с анализатором журналов часто возникает при разработке программного обеспечения. Многие системы создают файлы журналов во время нормальной работы, и иногда вам нужно проанализировать эти файлы, чтобы найти аномалии или общую информацию о работающей системе.
Описание проблемы
Для решения этой проблемы вам потребуется проанализировать файл журнала в указанном формате и сгенерировать отчет:
Анализатор журналов (
logparse.py)Принимает имя файла в командной строке. Файл представляет собой лог-файл, подобный Linux, из системы, которую вы отлаживаете. Среди различных инструкций содержатся сообщения, указывающие на состояние устройства. Они выглядят следующим образом:
Jul 11 16:11:51:490 [139681125603136] dut: Device State: ONСообщение о состоянии устройства имеет множество возможных значений, но эта программа учитывает только три:
ON,OFF, иERR.Ваша программа проанализирует данный файл журнала и распечатает отчет о том, как долго устройство находилось в состоянии
ONи временную метку любыхERRсостояний.
Обратите внимание, что предоставленный базовый код не включает модульные тесты. Это было опущено, поскольку точный формат отчета зависит от вас. Подумайте и напишите свой собственный в процессе работы.
Прилагается файл test.log, в котором приведен пример. Решение, которое вы изучите, приведет к следующему результату:
$ ./logparse.py test.log
Device was on for 7 seconds
Timestamps of error events:
Jul 11 16:11:54:661
Jul 11 16:11:56:067
Хотя этот формат генерируется реальным решением на Python, вы можете создать свой собственный формат для вывода. Пример входного файла должен генерировать эквивалентную информацию.
Решение проблемы
В свернутом разделе ниже вы найдете возможное решение проблемы с анализатором журналов. Когда будете готовы, разверните поле и сравните его с тем, что у вас получилось!
Примечание: Помните, не открывайте свернутый раздел ниже, пока не будете готовы ознакомиться с ответами на эту практическую задачу по Python!
Полное решение
Поскольку это решение длиннее, чем то, что вы видели для целых сумм или задач с шифром Цезаря, давайте начнем с полной программы:
# logparse.py
import datetime
import sys
def get_next_event(filename):
with open(filename, "r") as datafile:
for line in datafile:
if "dut: Device State: " in line:
line = line.strip()
# Parse out the action and timestamp
action = line.split()[-1]
timestamp = line[:19]
yield (action, timestamp)
def compute_time_diff_seconds(start, end):
format = "%b %d %H:%M:%S:%f"
start_time = datetime.datetime.strptime(start, format)
end_time = datetime.datetime.strptime(end, format)
return (end_time - start_time).total_seconds()
def extract_data(filename):
time_on_started = None
errs = []
total_time_on = 0
for action, timestamp in get_next_event(filename):
# First test for errs
if "ERR" == action:
errs.append(timestamp)
elif ("ON" == action) and (not time_on_started):
time_on_started = timestamp
elif ("OFF" == action) and time_on_started:
time_on = compute_time_diff_seconds(time_on_started, timestamp)
total_time_on += time_on
time_on_started = None
return total_time_on, errs
if __name__ == "__main__":
total_time_on, errs = extract_data(sys.argv[1])
print(f"Device was on for {total_time_on} seconds")
if errs:
print("Timestamps of error events:")
for err in errs:
print(f"\t{err}")
else:
print("No error events found.")
Это ваше полное решение. Вы можете видеть, что программа состоит из трех функций и основного раздела. Вы будете работать с ними сверху.
Вспомогательная функция: get_next_event()
Во-первых, это get_next_event():
# logparse.py
def get_next_event(filename):
with open(filename, "r") as datafile:
for line in datafile:
if "dut: Device State: " in line:
line = line.strip()
# Parse out the action and timestamp
action = line.split()[-1]
timestamp = line[:19]
yield (action, timestamp)
Поскольку она содержит инструкцию yield, эта функция является генератором . Это означает, что вы можете использовать ее для создания одного события из файла журнала за раз.
Вы могли бы просто использовать for line in datafile, но вместо этого вы добавляете немного фильтрации. Вызывающая процедура получит только те события, в которых есть dut: Device State:. Это позволяет сохранить весь синтаксический анализ, относящийся к конкретному файлу, в одной функции.
Это может немного усложнить get_next_event(), но это относительно небольшая функция, поэтому она остается достаточно короткой для чтения и понимания. Кроме того, этот сложный код хранится в одном месте.
Возможно, вам интересно, когда закроется datafile. Пока вы вызываете генератор, пока все строки не будут прочитаны из datafile, цикл for завершится, что позволит вам покинуть блок with и выйти из функции.
Вспомогательная функция: compute_time_diff_seconds()
Вторая функция - compute_time_diff_seconds(), которая, как следует из названия, вычисляет количество секунд между двумя временными метками:
# logparse.py
def compute_time_diff_seconds(start, end):
format = "%b %d %H:%M:%S:%f"
start_time = datetime.datetime.strptime(start, format)
end_time = datetime.datetime.strptime(end, format)
return (end_time - start_time).total_seconds()
В этой функции есть несколько интересных моментов. Во-первых, при вычитании двух объектов datetime получается datetime.timedelta. Для этой задачи вы будете указывать общее количество секунд, поэтому уместно вернуть .total_seconds() из timedelta.
Второй момент, на который следует обратить внимание, заключается в том, что в Python существует множество пакетов, которые упрощают обработку дат и времени. В этом случае ваша модель использования достаточно проста, чтобы не требовать привлечения внешней библиотеки, когда стандартных библиотечных функций будет достаточно.
Тем не менее, datetime.datetime.strptime() заслуживает упоминания. При передаче строки в определенном формате.strptime() анализирует эту строку в соответствии с заданным форматом и создает объект datetime.
Это еще одно место, где в ситуации собеседования важно не паниковать, если вы не можете вспомнить точные названия функций стандартной библиотеки Python.
Вспомогательная функция: extract_data()
Далее идет extract_data(), который выполняет основную часть работы в этой программе. Прежде чем вы углубитесь в код, давайте сделаем шаг назад и поговорим о конечных автоматах.
Конечные автоматы - это программные (или аппаратные) устройства, которые переходят из одного состояния в другое в зависимости от конкретных входных данных. Это действительно широкое определение, которое может оказаться трудным для понимания, поэтому давайте посмотрим на схему конечного автомата, которую вы будете использовать ниже:
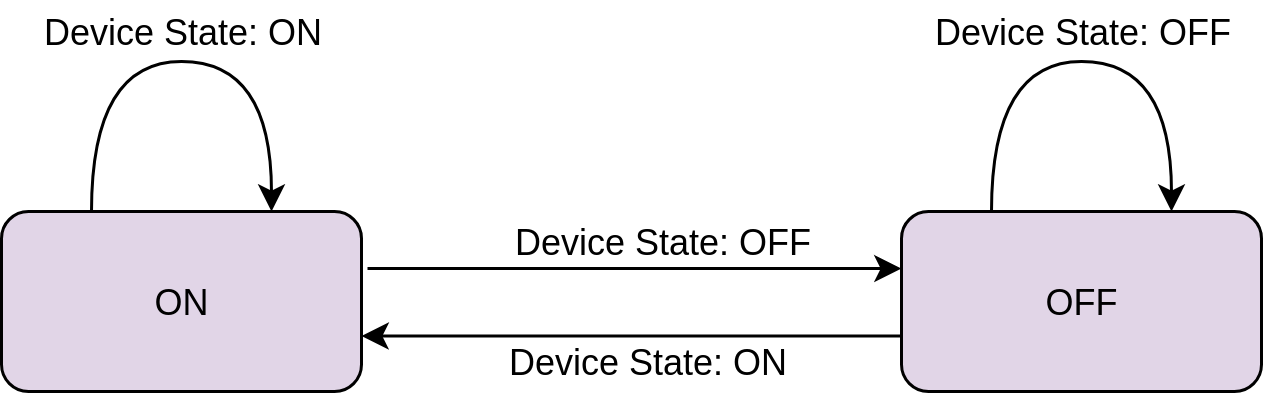
На этой диаграмме состояния представлены помеченными прямоугольниками. Здесь есть только два состояния, ON и OFF, которые соответствуют состоянию устройства. Также имеется два входных сигнала: Device State: ON и Device State: OFF. На диаграмме стрелками показано, что происходит при вводе данных, когда устройство находится в каждом из состояний.
Например, если устройство находится в состоянии ON и вводится Device State: ON, то устройство остается в состоянии ON. Никаких изменений не происходит. И наоборот, если компьютер получает Device State: OFF входных данных, находясь в состоянии ON, то он перейдет в состояние OFF.
Хотя конечный автомат здесь имеет только два состояния с двумя входными данными, конечные автоматы часто намного сложнее. Создание диаграммы ожидаемого поведения может помочь вам сделать код, реализующий конечный автомат, более кратким.
Давайте вернемся к extract_data():
# logparse.py
def extract_data(filename):
time_on_started = None
errs = []
total_time_on = 0
for action, timestamp in get_next_event(filename):
# First test for errs
if "ERR" == action:
errs.append(timestamp)
elif ("ON" == action) and (not time_on_started):
time_on_started = timestamp
elif ("OFF" == action) and time_on_started:
time_on = compute_time_diff_seconds(time_on_started, timestamp)
total_time_on += time_on
time_on_started = None
return total_time_on, errs
Здесь может быть сложно увидеть конечный автомат. Обычно конечным автоматам требуется переменная для хранения состояния. В этом случае вы используете time_on_started для двух целей:
- Укажите состояние:
time_on_startedсодержит состояние вашего конечного автомата. Если значениеNone, то машина находится в состоянииOFF. Если значениеnot None, то машина находится в состоянииON. - Сохранить время запуска: Если состояние равно
ON, тоtime_on_startedтакже содержит временную метку включения устройства. Вы используете эту временную метку для вызоваcompute_time_diff_seconds().
В верхней части extract_data() задается ваша переменная состояния, time_on_started, а также два выходных сигнала, которые вы хотите получить. errs - это список временных меток, при которых ERR сообщение найдено, и total_time_on - это сумма всех периодов, в течение которых устройство было включено.
После завершения первоначальной настройки вы вызываете генератор get_next_event() для извлечения каждого события и временной метки. action, который он получает, используется для управления конечным автоматом, но прежде чем он проверит изменения состояния, он сначала использует блок if, чтобы отфильтровать любые условия ERR и добавить их в errs.
После проверки ошибки первый блок elif обрабатывает переходы в состояние ON. Вы можете перейти к ON только тогда, когда вы находитесь в состоянии OFF, о котором сигнализирует time_on_started, равное False. Если вы еще не находитесь в состоянии ON, а действие выполняется в состоянии "ON", то вы сохраняете значение timestamp, переводя машину в состояние ON.
Второй elif управляет переходом в состояние OFF. При этом переходе extract_data() необходимо вычислить количество секунд, в течение которых устройство было включено. Он делает это с помощью compute_time_diff_seconds(), который вы видели выше. Это добавляет это время к текущему total_time_on и возвращает значение time_on_started None,, фактически возвращая машину в состояние OFF.
Основная функция
Наконец, вы можете перейти к разделу __main__. В этом последнем разделе sys.argv[1], который является первым аргументом командной строки, передается в extract_data(), а затем представляется отчет о результатах:
# logparse.py
if __name__ == "__main__":
total_time_on, errs = extract_data(sys.argv[1])
print(f"Device was on for {total_time_on} seconds")
if errs:
print("Timestamps of error events:")
for err in errs:
print(f"\t{err}")
else:
print("No error events found.")
Чтобы вызвать это решение, вы запускаете скрипт и передаете имя файла журнала. Выполнение вашего примера кода приводит к следующему результату:
$ python3 logparse.py test.log
Device was on for 7 seconds
Timestamps of error events:
Jul 11 16:11:54:661
Jul 11 16:11:56:067
Ваше решение может иметь другой формат, но информация для примера файла журнала должна быть такой же.
Существует множество способов решения подобной проблемы. Помните, что в ситуации собеседования обсуждение проблемы и ваш мыслительный процесс могут быть важнее, чем то, какое решение вы выберете для реализации.
Вот и все решение для разбора логов. Давайте перейдем к последнему заданию: судоку!
Практическая задача 5 на Python: Решатель судоку
Ваша последняя практическая задача на Python - решить головоломку судоку!
Найти быстрое и экономичное с точки зрения памяти решение этой проблемы может оказаться непростой задачей. Рассматриваемое вами решение было выбрано из соображений удобства чтения, а не скорости, но вы можете оптимизировать его по своему усмотрению.
Описание проблемы
Описание решения судоку немного сложнее, чем в предыдущих задачах:
Решатель судоку (
sudokusolve.py)Учитывая строку в формате SDM, описанную ниже, напишите программу, которая найдет и вернет решение головоломки судоку в этой строке. Решение должно быть возвращено в том же формате SDM, что и входные данные.
Некоторые головоломки будут неразрешимы. В этом случае верните строку “Unsolvable”.
Общий формат SDM описан здесь.
Для наших целей каждая строка SDM будет представлять собой последовательность из 81 цифры, по одной для каждой позиции в головоломке судоку. Будут указаны известные числа, а неизвестные позиции будут иметь нулевое значение.
Например, предположим, что вам дана такая строка цифр:
004006079000000602056092300078061030509000406020540890007410920105000000840600100Строка представляет собой начальную головоломку судоку:
0 0 4 0 0 6 0 7 9 0 0 0 0 0 0 6 0 2 0 5 6 0 9 2 3 0 0 0 7 8 0 6 1 0 3 0 5 0 9 0 0 0 4 0 6 0 2 0 5 4 0 8 9 0 0 0 7 4 1 0 9 2 0 1 0 5 0 0 0 0 0 0 8 4 0 6 0 0 1 0 0Выполнение предоставленных модульных тестов может занять некоторое время, поэтому наберитесь терпения.
Примечание: Описание головоломки судоку можно найти в Википедии.
Вы можете видеть, что вам нужно будет иметь дело с чтением и записью в определенном формате, а также с созданием решения.
Решение проблемы
Когда вы будете готовы, вы сможете найти подробное объяснение решения задачи судоку в поле ниже. Файл-скелет с модульными тестами представлен в репозитории.
Примечание: Помните, не открывайте свернутый раздел ниже, пока не будете готовы ознакомиться с ответами на эту практическую задачу по Python!
Это более масштабная и сложная задача, чем та, которую вы рассматривали до сих пор в этом руководстве. Вы пройдете через решение задачи шаг за шагом, заканчивая рекурсивной функцией, которая решает головоломку. Вот примерный план шагов, которые вы предпримете:
- Разложите головоломку в виде сетки.
- Для каждой ячейки:
- Для каждого возможного числа в этой ячейке:
- Поместите число в ячейку.
- Удалите это число из строки, столбца и маленького квадратика.
- Переместите на следующую позицию.
- Если не осталось возможных чисел, то объявите головоломку неразрешимой.
- Если все ячейки заполнены, то верните решение.
- Для каждого возможного числа в этой ячейке:
Сложная часть этого алгоритма заключается в отслеживании сетки на каждом этапе процесса. Для сохранения этой информации вы будете использовать рекурсию, создавая новую копию сетки на каждом уровне рекурсии.
Имея в виду этот план, давайте начнем с первого шага - создания сетки.
Создание сетки из линии
Для начала полезно преобразовать данные головоломки в более удобный формат. Даже если вы в конечном итоге захотите решить головоломку в заданном формате SDM, вы, скорее всего, быстрее добьетесь прогресса, работая с деталями вашего алгоритма, используя данные в виде таблицы. Как только у вас будет подходящее решение, вы сможете преобразовать его для работы с другой структурой данных.
Для этого давайте начнем с нескольких функций преобразования:
1# sudokusolve.py
2def line_to_grid(values):
3 grid = []
4 line = []
5 for index, char in enumerate(values):
6 if index and index % 9 == 0:
7 grid.append(line)
8 line = []
9 line.append(int(char))
10 # Add the final line
11 grid.append(line)
12 return grid
13
14def grid_to_line(grid):
15 line = ""
16 for row in grid:
17 r = "".join(str(x) for x in row)
18 line += r
19 return line
Ваша первая функция, line_to_grid(), преобразует данные из одной строки из восьмидесяти одной цифры в список списков. Например, он преобразует строку line в сетку типа start:
line = "0040060790000006020560923000780...90007410920105000000840600100"
start = [
[ 0, 0, 4, 0, 0, 6, 0, 7, 9],
[ 0, 0, 0, 0, 0, 0, 6, 0, 2],
[ 0, 5, 6, 0, 9, 2, 3, 0, 0],
[ 0, 7, 8, 0, 6, 1, 0, 3, 0],
[ 5, 0, 9, 0, 0, 0, 4, 0, 6],
[ 0, 2, 0, 5, 4, 0, 8, 9, 0],
[ 0, 0, 7, 4, 1, 0, 9, 2, 0],
[ 1, 0, 5, 0, 0, 0, 0, 0, 0],
[ 8, 4, 0, 6, 0, 0, 1, 0, 0],
]
Каждый внутренний список здесь представляет собой горизонтальную строку в вашей головоломке судоку.
Вы начинаете с пустого grid и пустого line. Затем вы создаете каждый line, преобразуя девять символов из строки values в однозначные целые числа, а затем добавляете их к текущему line. Как только у вас будет девять значений в line, как указано в index % 9 == 0 в строке 7, вы вставляете это line в grid и начинаете новое.
Функция завершается добавлением конечного line к grid. Вам это нужно, потому что цикл for завершится с последним line, который все еще хранится в локальной переменной и еще не добавлен к grid.
Обратная функция, grid_to_line(), немного короче. Она использует генерирующее выражение с .join() для создания девятизначной строки для каждой строки. Затем он добавляет эту строку к общему line и возвращает ее. Обратите внимание, что можно использовать вложенные генераторы для получения этого результата за меньшее количество строк кода, но удобочитаемость решения начинает резко снижаться.
Теперь, когда у вас есть данные в нужной вам структуре данных, давайте начнем с ними работать.
Генерация небольшого квадратного итератора
Ваша следующая функция - это генератор, который поможет вам найти меньший квадрат размером три на три, в котором находится данная позиция. Учитывая координаты x и y соответствующей ячейки, этот генератор выдаст список координат, соответствующих квадрату, который ее содержит:
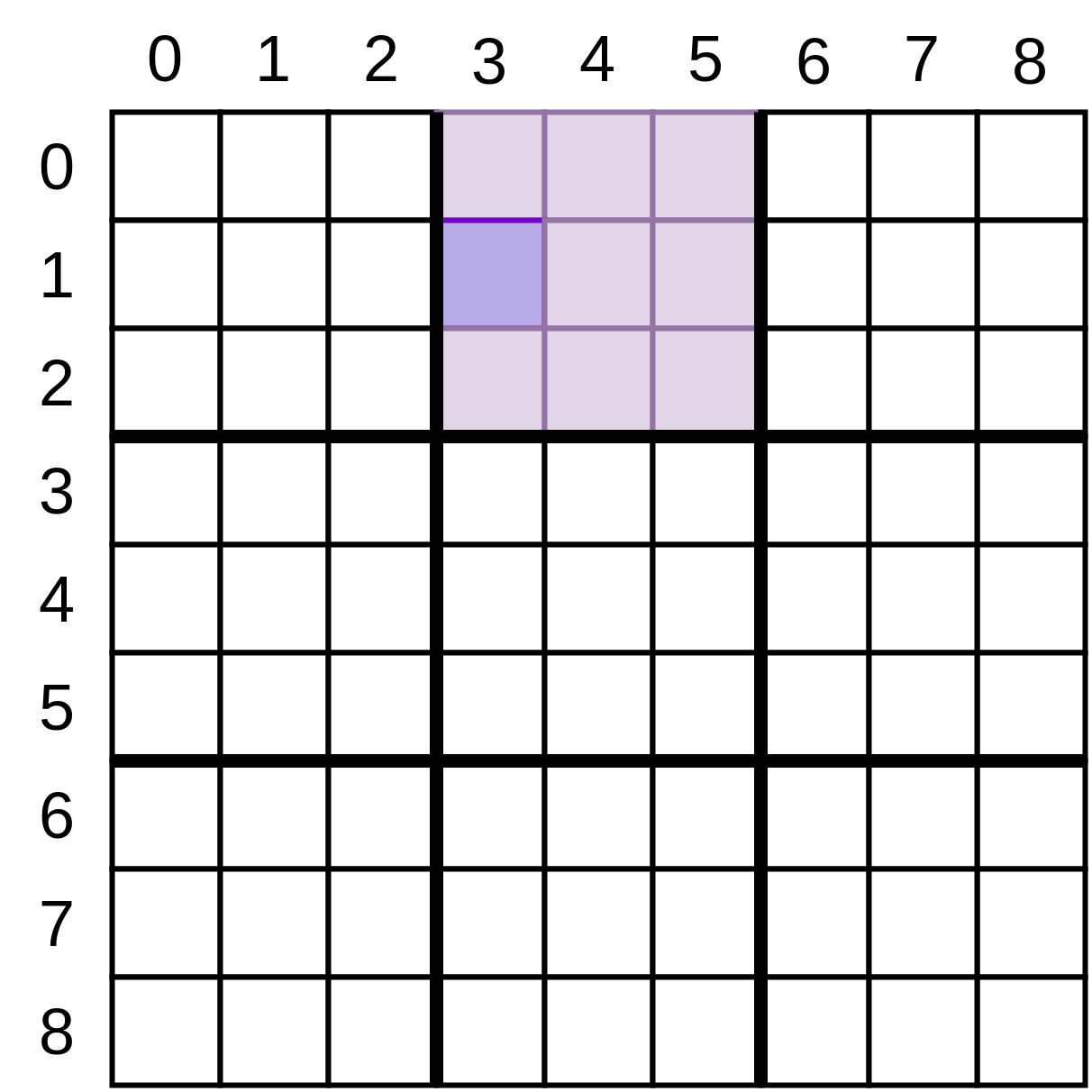
На изображении выше вы рассматриваете ячейку (3, 1), поэтому ваш генератор создаст пары координат, соответствующие всем слегка заштрихованным ячейкам, пропуская координаты, которые были переданы в:
(3, 0), (4, 0), (5, 0), (4, 1), (5, 1), (3, 2), (4, 2), (5, 2)
Вывод логики для определения этого небольшого квадрата в отдельную служебную функцию делает работу других ваших функций более понятной. Создание генератора позволяет использовать его в цикле for для перебора каждого из значений.
Функция для этого использует ограничения целочисленной математики:
# sudokusolve.py
def small_square(x, y):
upperX = ((x + 3) // 3) * 3
upperY = ((y + 3) // 3) * 3
lowerX = upperX - 3
lowerY = upperY - 3
for subX in range(lowerX, upperX):
for subY in range(lowerY, upperY):
# If subX != x or subY != y:
if not (subX == x and subY == y):
yield subX, subY
В паре этих строк много троек, из-за чего строки типа ((x + 3) // 3) * 3 выглядят запутанно. Вот что происходит, когда x является 1.
>>> x = 1
>>> x + 3
4
>>> (x + 3) // 3
1
>>> ((x + 3) // 3) * 3
3
Использование математического округления целых чисел позволяет получить следующее по величине число, кратное трем, выше заданного значения. Как только вы получите это значение, вычитание трех даст вам число, кратное трем, ниже заданного числа.
Есть еще несколько низкоуровневых полезных функций, которые необходимо изучить, прежде чем вы начнете создавать поверх них.
Переход к следующему пункту
Ваше решение должно будет проходить через структуру сетки по одной ячейке за раз. Это означает, что в какой-то момент вам нужно будет выяснить, какой должна быть следующая позиция. compute_next_position() спешим на помощь!
compute_next_position() принимает текущие координаты x и y в качестве входных данных и возвращает кортеж, содержащий флаг finished вместе с координатами x и y следующей позиции:
# sudokusolve.py
def compute_next_position(x, y):
nextY = y
nextX = (x + 1) % 9
if nextX < x:
nextY = (y + 1) % 9
if nextY < y:
return (True, 0, 0)
return (False, nextX, nextY)
Флажок finished сообщает вызывающей стороне, что алгоритм подошел к концу головоломки и заполнил все квадраты. Как это используется, вы увидите в следующем разделе.
Удаление невозможных чисел
Ваша конечная низкоуровневая утилита довольно мала. Она принимает целочисленное значение и повторяемость. Если значение отличное от нуля и появляется в iterable, то функция удаляет его из iterable:
# sudokusolve.py
def test_and_remove(value, possible):
if value != 0 and value in possible:
possible.remove(value)
Как правило, вы не стали бы превращать этот небольшой фрагмент функциональности в функцию. Однако вы будете использовать эту функцию несколько раз, поэтому лучше всего следовать принципу DRY и преобразовать ее в функцию.
Теперь вы увидели нижний уровень пирамиды функциональности. Пришло время сделать шаг вперед и использовать эти инструменты для создания более сложной функции. Вы почти готовы к решению головоломки!
Поиск того, что возможно
Ваша следующая функция использует некоторые из низкоуровневых функций, с которыми вы только что ознакомились. Учитывая сетку и позицию в этой сетке, она определяет, какие значения еще могут быть у этой позиции:
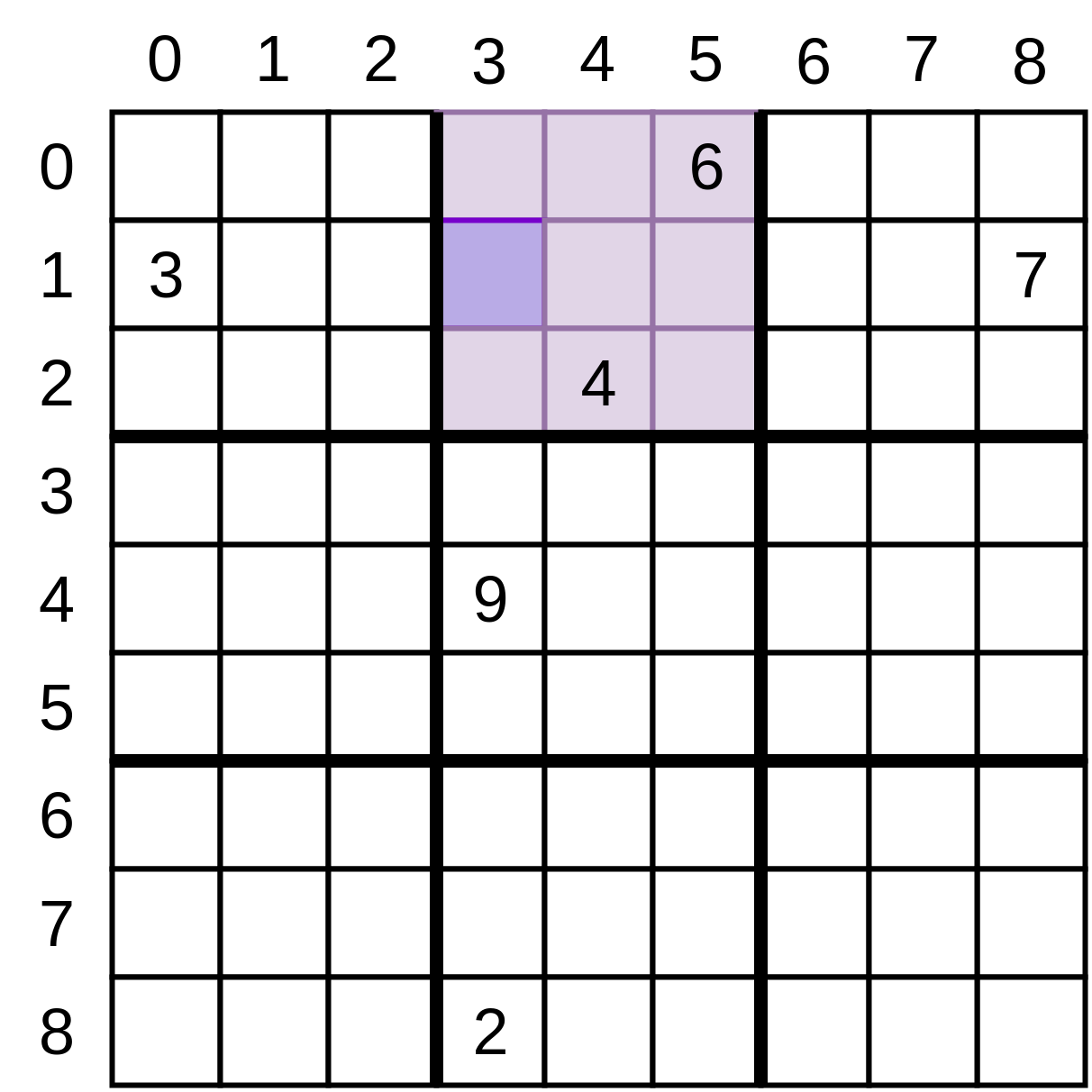
Для приведенной выше таблицы в позиции (3, 1) возможными значениями являются [1, 5, 8], поскольку все остальные значения присутствуют либо в этой строке, либо в столбце, либо в маленьком квадрате, на который вы смотрели ранее.
За это отвечает detect_possible():
# sudokusolve.py
def detect_possible(grid, x, y):
if grid[x][y]:
return [grid[x][y]]
possible = set(range(1, 10))
# Test horizontal and vertical
for index in range(9):
if index != y:
test_and_remove(grid[x][index], possible)
if index != x:
test_and_remove(grid[index][y], possible)
# Test in small square
for subX, subY in small_square(x, y):
test_and_remove(grid[subX][subY], possible)
return list(possible)
Функция запускается с проверки того, что заданная позиция в x и y уже имеет ненулевое значение. Если это так, то это единственно возможное значение, и оно возвращается.
Если нет, то функция создает набор чисел от одного до девяти. Далее функция проверяет различные блокирующие номера и удаляет их из этого набора.
Все начинается с проверки столбца и строки заданной позиции. Это можно сделать с помощью одного цикла, просто чередуя изменения нижнего индекса. grid[x][index] проверяет значения в одном столбце, в то время как grid[index][y] проверяет эти значения в одной строке. Вы можете видеть, что здесь вы используете test_and_remove() для упрощения кода.
Как только эти значения будут удалены из вашего набора possible, функция перейдет к маленькому квадрату. Вот где пригодится генератор small_square(), который вы создали ранее. Вы можете использовать его для перебора каждой позиции в маленьком квадрате, снова используя test_and_remove(), чтобы исключить все известные значения из вашего списка possible.
Как только все известные блокирующие значения будут удалены из вашего набора, у вас появится список всех значений possible для данной позиции в этой сетке.
Вы можете задаться вопросом, почему в коде и его описании указывается, что позиция находится “на этой сетке”. В следующей функции вы увидите, что программа создает множество копий сетки, пытаясь ее решить.
Решение этой проблемы
Вы добрались до сути этого решения: solve()! Эта функция является рекурсивной, поэтому небольшое предварительное объяснение может помочь.
Общая схема solve() основана на тестировании одной позиции за раз. Для интересующей позиции алгоритм получает список возможных значений и затем выбирает эти значения по одному, чтобы они соответствовали этой позиции.
Для каждого из этих значений он создает сетку с предполагаемым значением в этой позиции. Затем он вызывает функцию для проверки решения, передавая новую сетку и следующую позицию.
Так уж получилось, что вызываемая функция - это она сама.
Для любой рекурсии требуется условие завершения. В этом алгоритме их четыре:
- Для этой позиции нет возможных значений. Это означает, что тестируемое решение не может работать.
- Он дошел до конца сетки и нашел возможное значение для каждой позиции. Головоломка решена!
- Одно из предположений в этой позиции, когда оно передается обратно решателю, возвращает решение.
- Он перепробовал все возможные значения в этой позиции, но ни одно из них не сработает.
Давайте посмотрим на код для этого и посмотрим, как все это работает:
# sudokusolve.py
import copy
def solve(start, x, y):
temp = copy.deepcopy(start)
while True:
possible = detect_possible(temp, x, y)
if not possible:
return False
finished, nextX, nextY = compute_next_position(x, y)
if finished:
temp[x][y] = possible[0]
return temp
if len(possible) > 1:
break
temp[x][y] = possible[0]
x = nextX
y = nextY
for guess in possible:
temp[x][y] = guess
result = solve(temp, nextX, nextY)
if result:
return result
return False
Первое, на что следует обратить внимание в этой функции, это то, что она создает .deepcopy() из сетки. Он выполняет глубокое копирование, потому что алгоритму необходимо точно отслеживать, где он находился в любой точке рекурсии. Если бы функция создавала только поверхностную копию, то каждая рекурсивная версия этой функции использовала бы одну и ту же сетку.
Как только сетка скопирована, solve() может работать с новой копией, temp. Была передана позиция в сетке, так что это число, которое будет вычисляться в этой версии функции. Первый шаг - посмотреть, какие значения возможны в этой позиции. Как вы видели ранее, detect_possible() возвращает список возможных значений, который может быть пустым.
Если возможных значений нет, значит, выполнено первое условие завершения рекурсии. Функция возвращает False, и вызывающая процедура продолжает выполнение.
Если есть и возможных значения, то вам нужно двигаться дальше и посмотреть, является ли какое-либо из них решением. Прежде чем вы это сделаете, вы можете немного оптимизировать код. Если существует только одно возможное значение, то вы можете вставить это значение и перейти к следующей позиции. В приведенном решении это выполняется в цикле, поэтому вы можете поместить несколько чисел в таблицу без необходимости повторения.
Это может показаться небольшим улучшением, и я признаю, что в моей первой реализации этого не было. Но некоторые тесты показали, что это решение значительно быстрее, чем простое повторение здесь за счет более сложного кода.
Примечание: Это отличный момент для обсуждения во время собеседования, даже если вы не добавляете код для этого. Показать им, что вы думаете о том, как сделать выбор между скоростью и сложностью, - это сильный позитивный сигнал для интервьюеров.
Иногда, конечно, для текущей позиции может быть несколько возможных значений, и вам нужно будет решить, приведет ли какое-либо из них к решению. К счастью, вы уже определили следующую позицию в таблице, так что можете отказаться от размещения возможных значений.
Если следующая позиция находится за пределами таблицы, то текущая позиция является последней для заполнения. Если вы знаете, что для этой позиции существует хотя бы одно возможное значение, значит, вы нашли решение! Текущая позиция заполняется, и заполненная таблица возвращается в вызывающую функцию.
Если следующая позиция все еще находится в сетке, то вы перебираете каждое возможное значение для текущей позиции, вводя предположение о текущей позиции, а затем вызываете solve() с сеткой temp и новым значением. положение для проверки.
solve() может возвращать только заполненную сетку или False, поэтому, если любое из возможных предположений возвращает результат, отличный от False, значит, результат найден, и эта сетка может быть возвращена вверх по стеку.
Если были сделаны все возможные предположения и ни одно из них не является решением, то переданная сетка неразрешима. Если это вызов верхнего уровня, то это означает, что головоломка неразрешима. Если вызов находится ниже в дереве рекурсии, то это просто означает, что данная ветвь дерева рекурсии нежизнеспособна.
Собираем Все Это воедино
На данный момент вы почти закончили с решением. Осталась только одна последняя функция, sudoku_solve():
# sudokusolve.py
def sudoku_solve(input_string):
grid = line_to_grid(input_string)
answer = solve(grid, 0, 0)
if answer:
return grid_to_line(answer)
else:
return "Unsolvable"
Эта функция выполняет три функции:
- Преобразует входную строку в таблицу
- Вызывает
solve()с помощью этой таблицы, чтобы получить решение - Возвращает решение в виде строки или
"Unsolvable"если решения нет
Вот и все! Вы ознакомились с решением задачи для решателя судоку.
Темы для обсуждения в интервью
Решение для решения судоку, с которым вы только что ознакомились, - это хороший пример кода для собеседования. Частью процесса собеседования, скорее всего, будет обсуждение кода и, что более важно, некоторых конструктивных компромиссов, которые вы сделали. Давайте рассмотрим некоторые из этих компромиссов.
Рекурсия
Важнейшее дизайнерское решение связано с использованием рекурсии. Можно написать нерекурсивное решение для любой задачи, имеющей рекурсивное решение. Почему рекурсия предпочтительнее другого варианта?
Это обсуждение, которое зависит не только от проблемы, но и от разработчиков, участвующих в написании и поддержке решения. Некоторые проблемы поддаются довольно простым рекурсивным решениям, а некоторые - нет.
Как правило, рекурсивные решения требуют больше времени для запуска и используют больше памяти, чем нерекурсивные решения. Но это не всегда так и, что более важно, это не всегда важно.
Аналогичным образом, некоторым командам разработчиков нравятся рекурсивные решения, в то время как другие считают их экзотическими или излишне сложными. Удобство обслуживания также должно влиять на ваши дизайнерские решения.
Одно из важных обсуждений такого решения касается производительности. Насколько быстро должно быть реализовано это решение? Будет ли оно использовано для решения миллиардов головоломок или всего нескольких? Будет ли он работать на небольшой встроенной системе с ограниченным объемом памяти или на большом сервере?
Эти внешние факторы могут помочь вам выбрать лучшее дизайнерское решение. Это отличные темы для обсуждения на собеседовании, когда вы работаете над проблемой или обсуждаете код. В одном продукте могут быть места, где производительность имеет решающее значение (например, при трассировке лучей в графическом алгоритме), и места, где это вообще не имеет значения (например, при анализе номера версии во время установки).
Обсуждение подобных тем во время собеседования показывает, что вы не только думаете о решении абстрактной проблемы, но и готовы и способны перейти на следующий уровень и решить конкретную проблему, стоящую перед командой.
Удобство чтения и сопровождения
Иногда стоит выбрать более медленное решение, чтобы создать решение, с которым проще работать, отлаживать и расширять. Решение в задаче sudoku solver о преобразовании структуры данных в таблицу является одним из таких решений.
Такое дизайнерское решение, вероятно, замедляет работу программы, но пока вы не провели измерения, вы этого не знаете. Даже если это так, приведение структуры данных в форму, естественную для данной задачи, может облегчить понимание кода.
Вполне возможно написать решатель, который работает с линейными строками, которые вы вводите в качестве входных данных. Вероятно, это быстрее и, вероятно, занимает меньше памяти, но small_square(), помимо прочего, в этой версии будет намного сложнее записывать, читать и поддерживать.
Оплошности
Еще одна вещь, которую стоит обсудить с интервьюером, независимо от того, занимаетесь ли вы программированием вживую или обсуждаете код, написанный в автономном режиме, - это ошибки и ложные повороты, которые вы допускали на этом пути.
Это немного менее очевидно и может быть немного вредно, но, особенно если вы занимаетесь программированием в реальном времени, выполнение шагов по рефакторингу кода, который является неправильным или мог бы быть лучше, может показать, как вы работаете. Немногие разработчики могут написать идеальный код с первого раза. Черт возьми, немногие разработчики могут написать хороший код с первого раза.
Хорошие разработчики пишут код, затем возвращаются к его рефакторингу и исправляют. Например, моя первая реализация detect_possible() выглядела следующим образом:
# sudokusolve.py
def first_detect_possible(x, y, grid):
print(f"position [{x}][{y}] = {grid[x][y]}")
possible = set(range(1, 10))
# Test horizontal
for index, value in enumerate(grid[x]):
if index != y:
if grid[x][index] != 0:
possible.remove(grid[x][index])
# Test vertical
for index, row in enumerate(grid):
if index != x:
if grid[index][y] != 0:
possible.remove(grid[index][y])
print(possible)
Игнорируя тот факт, что он не учитывает информацию small_square(), этот код можно улучшить. Если вы сравните это с окончательной версией detect_possible(), приведенной выше, вы увидите, что в окончательной версии используется один цикл для проверки как горизонтальных , так и вертикальных измерений.
Завершение
Это ваш экскурс в решение для решения судоку. Здесь доступна дополнительная информация о форматах хранения головоломок и огромном списке головоломок судоку, на которых вы можете протестировать свой алгоритм.
Вот и закончилось ваше приключение с практическими задачами на Python! Но если вам хочется большего, ознакомьтесь с видеокурсом "Написание и тестирование функции на Python: практика проведения собеседований", чтобы увидеть, как опытный разработчик решает проблему во время собеседования в режиме реального времени.
Заключение
Поздравляем вас с решением этого набора практических задач на Python! Вы попрактиковались в применении своих навыков работы с Python, а также потратили некоторое время на обдумывание того, как вы можете реагировать в различных ситуациях собеседования.
В этом руководстве вы узнали, как:
- Напишите код для задач в стиле интервью
- Обсудите свои решения во время собеседования
- Проработайте часто упускаемых деталей
- Поговорим о дизайнерских решениях и компромиссах
Удачи на собеседовании!
Back to Top