Построение гистограммы на Python: NumPy, Matplotlib, pandas и Seaborn
Оглавление
- Гистограммы на чистом Python
- Построение на основе: Вычисления гистограммы в NumPy
- Визуализация гистограмм с помощью Matplotlib и pandas
- Построение оценки плотности ядра (KDE)
- Необычная альтернатива с Seaborn
- Другие инструменты в pandas
- Хорошо, Итак, Что Же мне следует Использовать?
В этом руководстве вы узнаете, как создавать высококачественные графики гистограмм на Python, готовые к презентации, с широким спектром возможностей.
Если у вас есть начальные или промежуточные знания по Python и статистике, то вы можете использовать эту статью как универсальный инструмент для построения гистограмм в Python с использованием библиотек из его научного стека, включая NumPy, Matplotlib, pandas и Seaborn.
Гистограмма - отличный инструмент для быстрой оценки распределения вероятностей, который интуитивно понятен практически любой аудитории. Python предлагает несколько различных вариантов построения гистограмм. Большинство людей знают гистограмму по ее графическому представлению, которое похоже на столбчатую диаграмму:
Эта статья поможет вам создать графики, подобные приведенному выше, а также более сложные. Вот что вы рассмотрите:
- Построение гистограмм на чистом Python, без использования сторонних библиотек
- Построение гистограмм с помощью NumPy для обобщения базовых данных
- Построение результирующей гистограммы с помощью Matplotlib, pandas и Seaborn
Бесплатный бонус: Не хватает времени? Нажмите здесь, чтобы получить доступ к бесплатной двухстраничной шпаргалке по гистограммам Python, в которой кратко описываются техники, описанные в этом руководстве.
Гистограммы на чистом Python
Когда вы готовитесь к построению гистограммы, проще всего не думать о ячейках, а указать, сколько раз появляется каждое значение (таблица частот). Словарь Python хорошо подходит для этой задачи:
>>> # Need not be sorted, necessarily
>>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23)
>>> def count_elements(seq) -> dict:
... """Tally elements from `seq`."""
... hist = {}
... for i in seq:
... hist[i] = hist.get(i, 0) + 1
... return hist
>>> counted = count_elements(a)
>>> counted
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
count_elements() возвращает словарь с уникальными элементами из последовательности в качестве ключей и их частотами (количеством) в качестве значений. В цикле over seq, hist[i] = hist.get(i, 0) + 1 говорится: “для каждого элемента последовательности увеличьте соответствующее ему значение в hist на 1.”
На самом деле, это именно то, что делает класс collections.Counter из стандартной библиотеки Python, который создает подклассы словаря Python и переопределяет его .update() способ:
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})
Вы можете убедиться, что ваша функция ручной работы выполняет практически то же самое, что и collections.Counter, проверив их на равенство:
>>> recounted.items() == counted.items()
True
Технические подробности: Приведенное выше сопоставление count_elements() по умолчанию соответствует более оптимизированной функции C, если она доступна . В рамках функции Python count_elements() одна из микрооптимизаций, которую вы могли бы провести, - это объявить get = hist.get перед циклом for. Это позволило бы привязать метод к переменной для более быстрых вызовов в цикле.
Может оказаться полезным создать упрощенные функции с нуля в качестве первого шага к пониманию более сложных функций. Давайте еще немного изобретем колесо с помощью гистограммы ASCII, которая использует преимущества форматирования вывода в Python:
def ascii_histogram(seq) -> None:
"""A horizontal frequency-table/histogram plot."""
counted = count_elements(seq)
for k in sorted(counted):
print('{0:5d} {1}'.format(k, '+' * counted[k]))
Эта функция создает отсортированный график частот, где значения представлены в виде суммы символов плюс (+). Вызов sorted() в словаре возвращает отсортированный список его ключей, а затем вы получаете доступ к соответствующему значению для каждого из них с помощью counted[k]. Чтобы увидеть это в действии, вы можете создать немного больший набор данных с помощью модуля Python random:
>>> # No NumPy ... yet
>>> import random
>>> random.seed(1)
>>> vals = [1, 3, 4, 6, 8, 9, 10]
>>> # Each number in `vals` will occur between 5 and 15 times.
>>> freq = (random.randint(5, 15) for _ in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1 +++++++
3 ++++++++++++++
4 ++++++
6 +++++++++
8 ++++++
9 ++++++++++++
10 ++++++++++++
Здесь вы имитируете выборку из vals с частотами, заданными freq (выражение генератора ). В результирующей выборке данных каждое значение из vals повторяется определенное количество раз от 5 до 15.
Примечание: random.seed() используется для заполнения или инициализации базового генератора псевдослучайных чисел (PRNG), используемого random. Это может звучать как оксюморон, но это способ сделать случайные данные воспроизводимыми и детерминированными. То есть, если вы скопируете код здесь как есть, вы должны получить точно такую же гистограмму, потому что при первом вызове random.randint() после заполнения генератор выдаст идентичные “случайные” данные, используя Твистер Мерсенна.
Построение на основе: Вычисления гистограммы в NumPy
До сих пор вы работали с тем, что лучше всего можно было бы назвать “таблицами частот”. Но математически гистограмма - это отображение интервалов в частотах. Более технически, его можно использовать для аппроксимации функции плотности вероятности (PDF) базовой переменной.
Исходя из приведенной выше “таблицы частот”, истинная гистограмма сначала “разбивает” диапазон значений на ячейки, а затем подсчитывает количество значений, попадающих в каждую ячейку. Это то, что делает функция NumPy histogram(), и это основа для других функций, которые вы увидите позже в библиотеках Python, таких как Matplotlib и pandas.
Рассмотрим выборку чисел с плавающей точкой, взятых из распределения Лапласа. Это распределение имеет более толстые хвосты, чем нормальное распределение и имеет два описательных параметра (местоположение и масштаб):
>>> import numpy as np
>>> # `numpy.random` uses its own PRNG.
>>> np.random.seed(444)
>>> np.set_printoptions(precision=3)
>>> d = np.random.laplace(loc=15, scale=3, size=500)
>>> d[:5]
array([18.406, 18.087, 16.004, 16.221, 7.358])
В этом случае вы работаете с непрерывным распределением, и было бы не очень полезно подсчитывать каждое число с плавающей точкой независимо, вплоть до сотого знака после запятой. Вместо этого вы можете сгруппировать данные и подсчитать наблюдения, которые попадают в каждую ячейку. Гистограмма - это итоговое количество значений в каждой ячейке:
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])
Этот результат может быть не сразу понятен. np.histogram() по умолчанию используется 10 ячеек одинакового размера и возвращает набор значений частоты и соответствующих границ ячеек. Они являются ребрами в том смысле, что ребер ячейки будет на одно больше, чем элементов гистограммы:
>>> hist.size, bin_edges.size
(10, 11)
Техническая деталь: Все ячейки, кроме последней (самой правой), приоткрыты. То есть все ячейки, кроме последней, являются [включающими, exclusive), а последняя ячейка является [включающей, инклюзивной].
Очень краткое описание того, как создаются ячейки с помощью NumPy выглядит следующим образом:
>>> # The leftmost and rightmost bin edges
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10 # NumPy's default
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23. ])
Приведенный выше пример имеет большой смысл: 10 равномерно расположенных ячеек в диапазоне от пика до пика, равном 23, означают интервалы шириной 2,3.
Оттуда функция делегирует либо np.bincount() или np.searchsorted(). bincount() сам по себе может быть использован для эффективного построения “таблицы частот”, с которой вы начали, с той разницей, что в нее включены значения с нулевыми встречаемостями:
>>> bcounts = np.bincount(a)
>>> hist, _ = np.histogram(a, range=(0, a.max()), bins=a.max() + 1)
>>> np.array_equal(hist, bcounts)
True
>>> # Reproducing `collections.Counter`
>>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()]))
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
Обратите внимание: hist здесь действительно используются ячейки шириной 1.0, а не “дискретные” значения. Следовательно, это работает только для подсчета целых чисел, а не чисел с плавающей запятой, таких как [3.9, 4.1, 4.15].
Визуализация гистограмм с помощью Matplotlib и pandas
Теперь, когда вы увидели, как построить гистограмму в Python с нуля, давайте посмотрим, как другие пакеты Python могут выполнить эту работу за вас. Matplotlib предоставляет функциональность для визуализации гистограмм Python "из коробки" с помощью универсальной оболочки для NumPy. histogram():
import matplotlib.pyplot as plt
# An "interface" to matplotlib.axes.Axes.hist() method
n, bins, patches = plt.hist(x=d, bins='auto', color='#0504aa',
alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('My Very Own Histogram')
plt.text(23, 45, r'$\mu=15, b=3$')
maxfreq = n.max()
# Set a clean upper y-axis limit.
plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10)
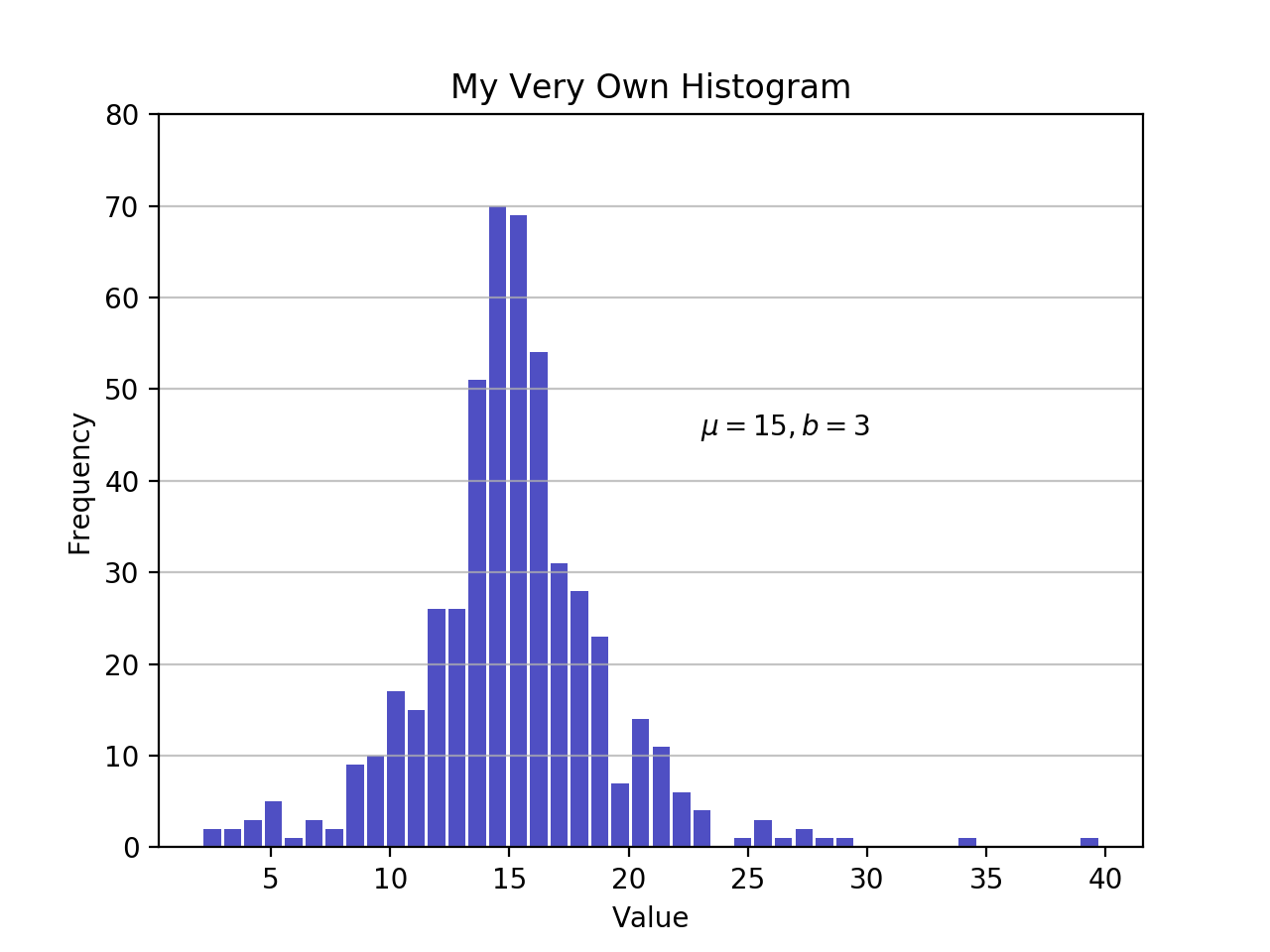
Как было определено ранее, при построении гистограммы на оси x используются границы ячейки, а на оси y - соответствующие частоты. На приведенной выше диаграмме при передаче bins='auto' выбирается один из двух алгоритмов для оценки “идеального” количества ячеек. На высоком уровне целью алгоритма является выбор ширины ячейки, которая обеспечивает наиболее точное представление данных. Для получения дополнительной информации по этому вопросу, который может быть довольно техническим, ознакомьтесь с Выбор ячеек гистограммы из документации Astropy.
Оставаясь в научном стеке Python, pandas’ Series.histogram() использует matplotlib.pyplot.hist() для построения гистограммы Matplotlib входного ряда:
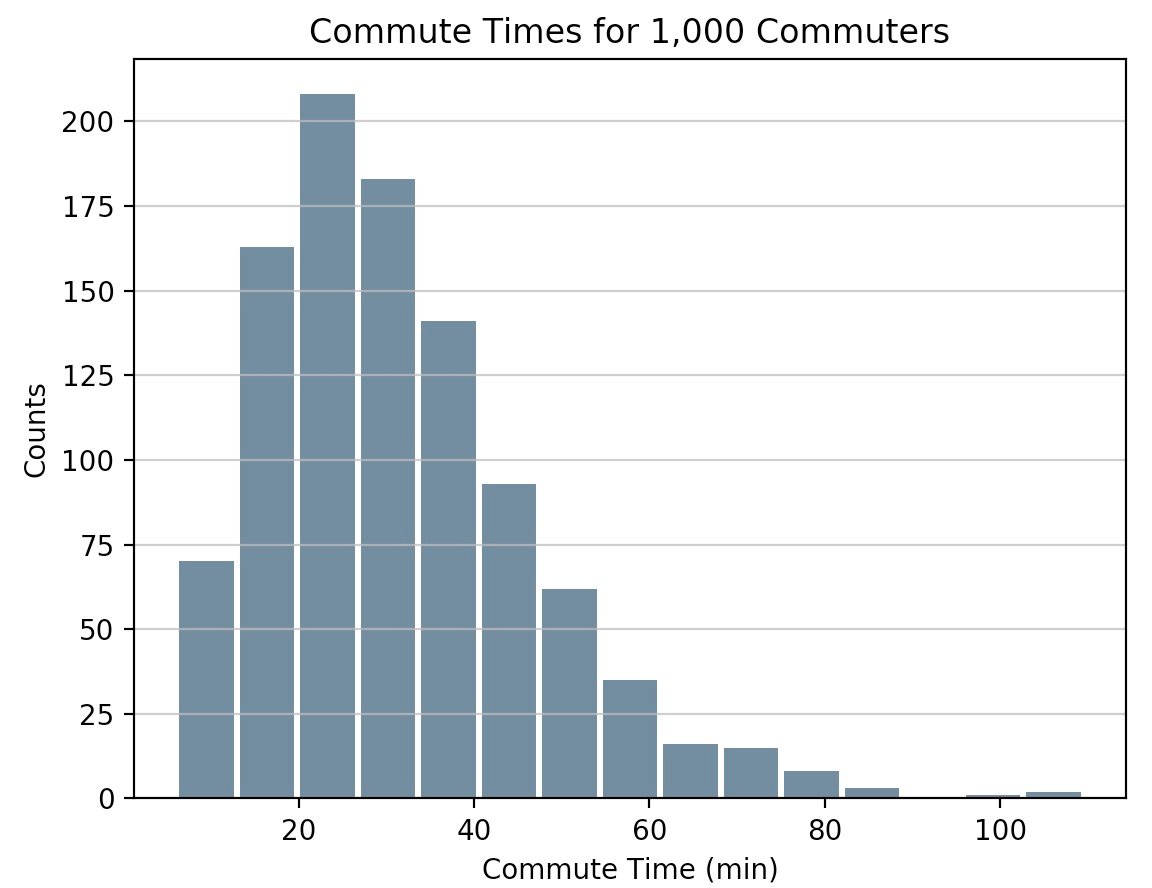
import pandas as pd
# Generate data on commute times.
size, scale = 1000, 10
commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5)
commutes.plot.hist(grid=True, bins=20, rwidth=0.9,
color='#607c8e')
plt.title('Commute Times for 1,000 Commuters')
plt.xlabel('Counts')
plt.ylabel('Commute Time')
plt.grid(axis='y', alpha=0.75)
pandas.DataFrame.histogram() аналогично, но создает гистограмму для каждого столбца данных в фрейме данных.
Построение оценки плотности ядра (KDE)
В этом руководстве вы работали с выборками, с точки зрения статистики. Независимо от того, являются ли данные дискретными или непрерывными, предполагается, что они получены из совокупности, которая имеет истинное, точное распределение, описываемое всего несколькими параметрами.
Оценка плотности ядра (KDE) - это способ оценки функции плотности вероятности (PDF) случайной величины, которая “лежит в основе” нашей выборки. KDE - это средство сглаживания данных.
Используя библиотеку pandas, вы можете создавать графики плотности и накладывать их друг на друга с помощью plot.kde(), которая доступна как для объектов Series, так и для объектов DataFrame. Но сначала давайте сгенерируем две различные выборки данных для сравнения:
>>> # Sample from two different normal distributions
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=(1000, 2)),
... columns=['a', 'b'])
>>> dist.agg(['min', 'max', 'mean', 'std']).round(decimals=2)
a b
min -1.57 12.46
max 25.32 26.44
mean 10.12 19.94
std 3.94 1.94
Теперь, чтобы построить каждую гистограмму на одних и тех же осях Matplotlib:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend=False, title='Histogram: A vs. B')
dist.plot.hist(density=True, ax=ax)
ax.set_ylabel('Probability')
ax.grid(axis='y')
ax.set_facecolor('#d8dcd6')
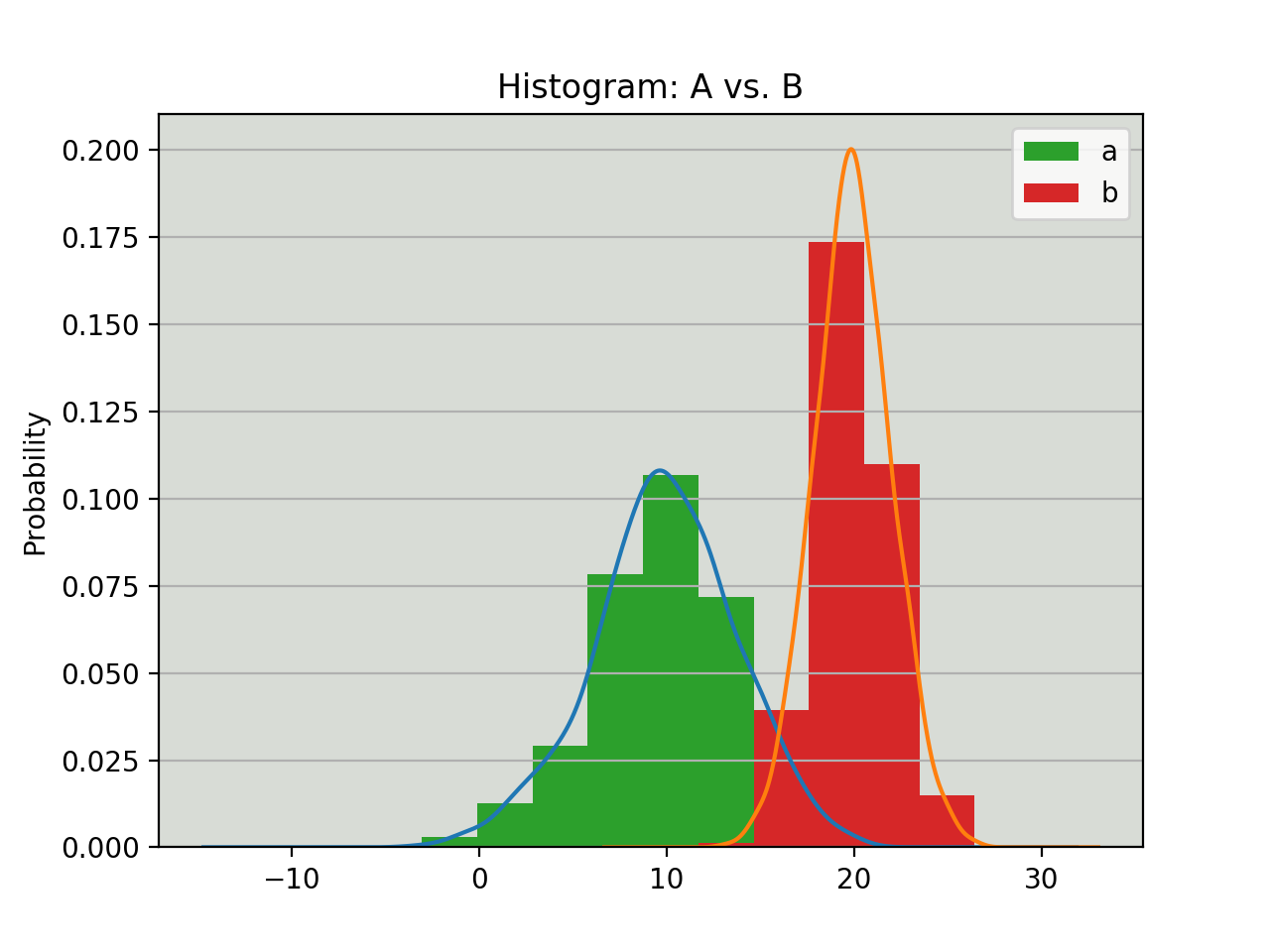
В этих методах используется SciPy gaussian_kde(),, что позволяет сделать PDF-файл более гладким на вид.
Если вы присмотритесь к этой функции повнимательнее, то увидите, насколько хорошо она приближает “истинный” PDF-файл к относительно небольшой выборке из 1000 точек данных. Ниже вы можете сначала построить “аналитическое” распределение с помощью scipy.stats.norm(). Это экземпляр класса, который инкапсулирует статистическое стандартное нормальное распределение, его моменты и описательные функции. Его PDF-файл является “точным” в том смысле, что он точно определен как norm.pdf(x) = exp(-x**2/2) / sqrt(2*pi).
Исходя из этого, вы можете взять случайную выборку из 1000 точек данных из этого распределения, а затем попытаться вернуться к оценке PDF с помощью scipy.stats.gaussian_kde():
from scipy import stats
# An object representing the "frozen" analytical distribution
# Defaults to the standard normal distribution, N~(0, 1)
dist = stats.norm()
# Draw random samples from the population you built above.
# This is just a sample, so the mean and std. deviation should
# be close to (1, 0).
samp = dist.rvs(size=1000)
# `ppf()`: percent point function (inverse of cdf — percentiles).
x = np.linspace(start=stats.norm.ppf(0.01),
stop=stats.norm.ppf(0.99), num=250)
gkde = stats.gaussian_kde(dataset=samp)
# `gkde.evaluate()` estimates the PDF itself.
fig, ax = plt.subplots()
ax.plot(x, dist.pdf(x), linestyle='solid', c='red', lw=3,
alpha=0.8, label='Analytical (True) PDF')
ax.plot(x, gkde.evaluate(x), linestyle='dashed', c='black', lw=2,
label='PDF Estimated via KDE')
ax.legend(loc='best', frameon=False)
ax.set_title('Analytical vs. Estimated PDF')
ax.set_ylabel('Probability')
ax.text(-2., 0.35, r'$f(x) = \frac{\exp(-x^2/2)}{\sqrt{2*\pi}}$',
fontsize=12)
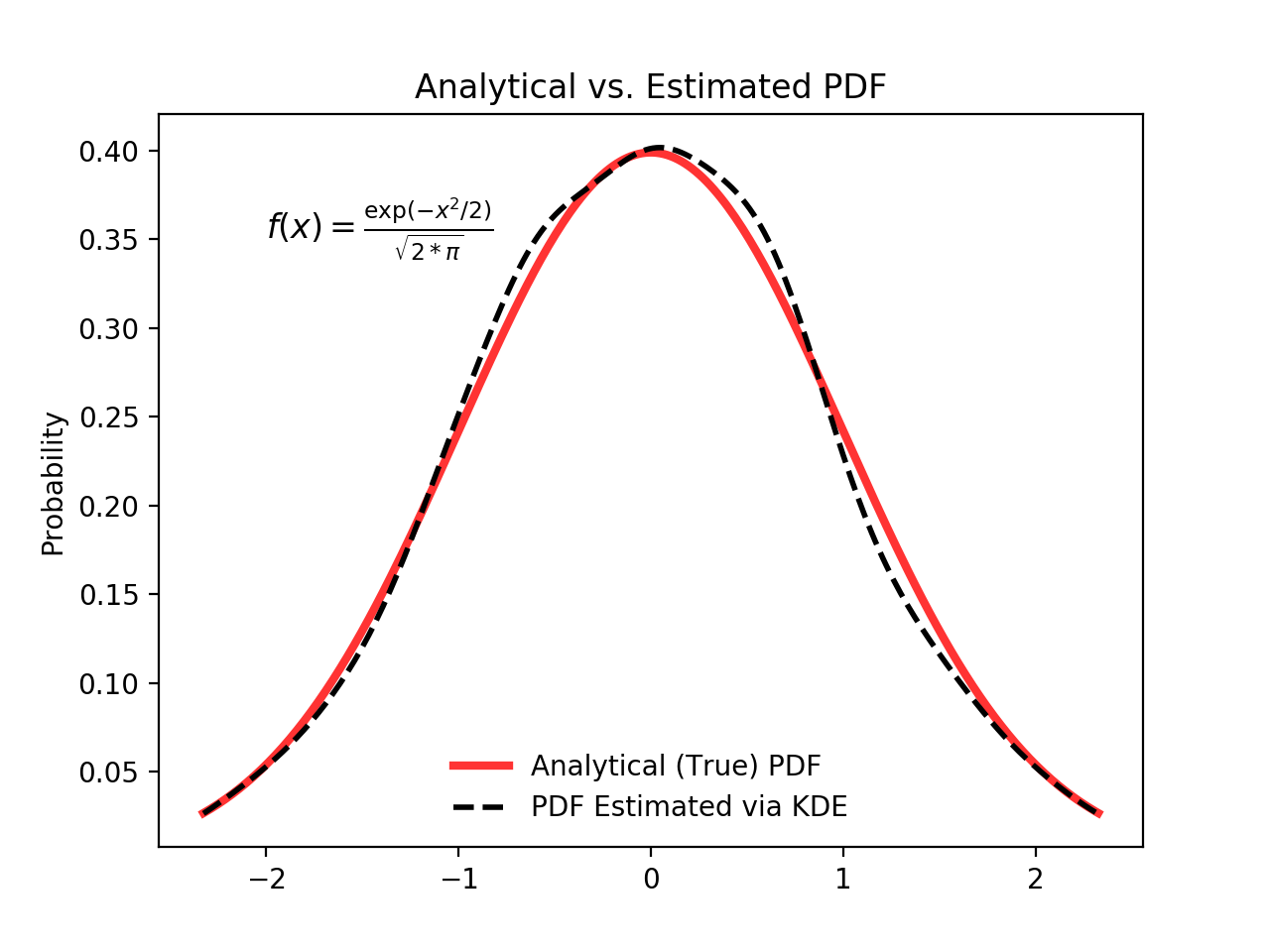
Это большой фрагмент кода, поэтому давайте уделим секунду тому, чтобы остановиться на нескольких ключевых строках:
- Подпакет SciPy
statsпозволяет создавать объекты Python, представляющие аналитические распределения, из которых вы можете выполнять выборку для создания фактических данных. Таким образом,dist = stats.norm()представляет собой обычную непрерывную случайную величину, и вы генерируете из нее случайные числа с помощьюdist.rvs(). - Чтобы оценить как аналитический PDF, так и гауссовский KDE, вам нужен массив
xквантилей (стандартных отклонений выше/ниже среднего значения для нормального распределения).stats.gaussian_kde()представляет собой приблизительный PDF-файл, который вам необходимо обработать в массиве, чтобы в данном случае создать что-то визуально значимое. - Последняя строка содержит некоторый LaTeX, который прекрасно интегрируется с Matplotlib.
Необычная альтернатива с Seaborn
Давайте добавим еще один пакет на Python. В Seaborn есть функция displot(), которая строит гистограмму и KDE для одномерного распределения за один шаг. Используя массив NumPy d из ealier:
import seaborn as sns
sns.set_style('darkgrid')
sns.distplot(d)
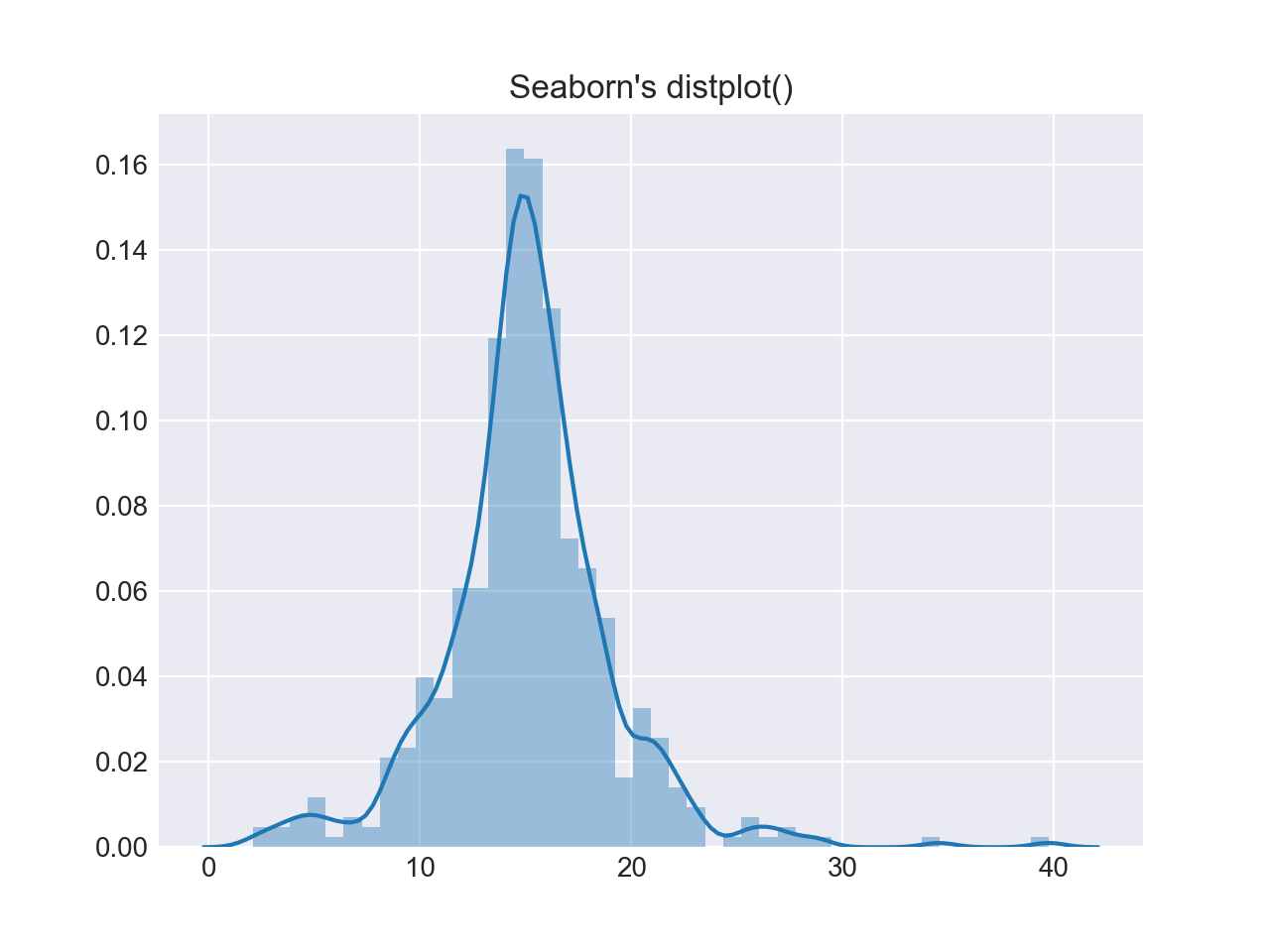
В приведенном выше вызове создается KDE. Также есть возможность настроить конкретное распределение для данных. Это отличается от KDE и состоит из оценки параметров для общих данных и указанного имени распределения:
sns.distplot(d, fit=stats.laplace, kde=False)
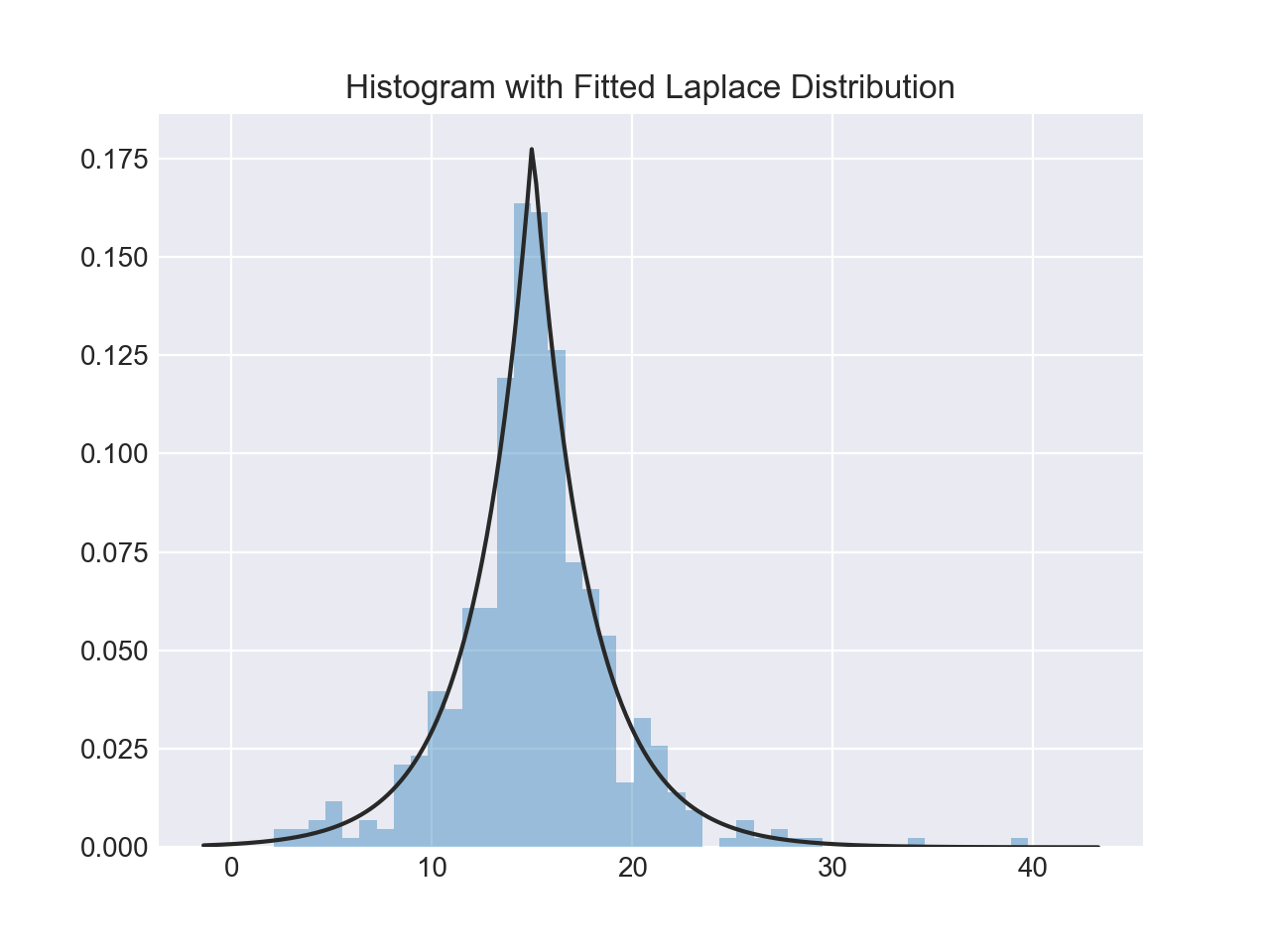
Опять же, обратите внимание на небольшое различие. В первом случае вы оцениваете какой-то неизвестный PDF-файл; во втором вы берете известное распределение и находите, какие параметры наилучшим образом описывают его с учетом эмпирических данных.
Другие инструменты в pandas
В дополнение к своим инструментам построения графиков, pandas также предлагает удобный метод .value_counts(), который вычисляет гистограмму ненулевых значений для pandas Series:
>>> import pandas as pd
>>> data = np.random.choice(np.arange(10), size=10000,
... p=np.linspace(1, 11, 10) / 60)
>>> s = pd.Series(data)
>>> s.value_counts()
9 1831
8 1624
7 1423
6 1323
5 1089
4 888
3 770
2 535
1 347
0 170
dtype: int64
>>> s.value_counts(normalize=True).head()
9 0.1831
8 0.1624
7 0.1423
6 0.1323
5 0.1089
dtype: float64
В другом месте, pandas.cut() это удобный способ разбиения значений на произвольные интервалы. Допустим, у вас есть некоторые данные о возрасте людей и вы хотите разумно их распределить:
>>> ages = pd.Series(
... [1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = (0, 10, 13, 18, 21, np.inf) # The edges
>>> labels = ('child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype: int64
>>> pd.concat((ages, groups), axis=1).rename(columns={0: 'age', 1: 'group'})
age group
0 1 child
1 1 child
2 3 child
3 5 child
4 8 child
5 10 child
6 12 preteen
7 15 teen
8 18 teen
9 18 teen
10 19 military_age
11 20 military_age
12 25 adult
13 30 adult
14 40 adult
15 51 adult
16 52 adult
Приятно то, что обе эти операции в конечном счете используют код Cython, что делает их конкурентоспособными по скорости при сохранении гибкости.
Хорошо, итак, что же мне следует использовать?
На данный момент вы ознакомились с большим количеством функций и методов, из которых можно выбирать для построения гистограммы на Python. Как они соотносятся? Короче говоря, не существует “универсального решения для всех”. Вот краткое описание функций и методов, которые вы рассмотрели до сих пор, и все они относятся к разбивке и представлению дистрибутивов в Python:
гистограмма, представляющая интервалы и соответствующие частоты. Методы pandas, такие как Series.plot.hist(), DataFrame.plot.hist(), Series.value_counts() и cut(), а также Series.plot.kde() и DataFrame.plot.kde().
| У вас есть/Хотите использовать | Рассмотрите возможность использования | Примечание(я) |
|---|---|---|
| Четко структурированные целочисленные данные, хранящиеся в структуре данных, такой как список, кортеж или множество, и вы хотите создать гистограмму Python без импорта каких-либо сторонних библиотек. | collections.Counter() из стандартной библиотеки Python предлагает быстрый и простой способ получить частотные подсчеты из контейнера данных. |
Это частотная таблица, поэтому она не использует концепция группировки данных, как это делает «истинная» гистограмма. |
| Большой массив данных, и вы хотите вычислить «математическую» формулу. | Функция NumPy np.histogram() и np.bincount() полезны для численного вычисления значений гистограммы и соответствующих границ интервалов. |
Более подробную информацию см. в np.digitize(). |
Таблицовые данные в pandasSeries или объект DataFrame. |
Ознакомьтесь с документацией pandas по визуализации для вдохновение. | |
| Создайте высоко настраиваемый, точно настроенный график из любой структуры данных. | pyplot.hist() — это широко используемая функция построения гистограмм, которая использует np.histogram() и является основой для функций построения графиков pandas. |
Matplotlib, и особенно его объектно-ориентированная структура, отлично подходит для точной настройки деталей гистограммы. Освоение этого интерфейса может занять некоторое время, но в конечном итоге он позволяет очень точно настроить отображение любой визуализации. |
| Предварительно настроенный дизайн и интеграция. | Seaborn's distplot(), для объединения гистограммы и графика KDE или построения графика подгонки распределения. |
По сути, это «оболочка вокруг другой оболочки», которая использует гистограмму Matplotlib внутри, а та, в свою очередь, использует NumPy. |
Back to Top