Python, Boto3 и AWS S3
Оглавление
- Установка
- Клиент против ресурса
- Общие операции
- Дополнительные конфигурации
- Траверсалы
- Удаление ведер и объектов
- Код на Python или инфраструктура как код (IaC)?
- Заключение
- Дальнейшее чтение
Amazon Web Services (AWS) стала лидером в области облачных вычислений. Одним из его основных компонентов является S3, сервис хранения объектов, предлагаемый AWS. Благодаря впечатляющей доступности и долговечности он стал стандартным способом хранения видео, изображений и данных. Вы можете комбинировать S3 с другими сервисами для создания бесконечно масштабируемых приложений.
Boto3 - это название Python SDK для AWS. Он позволяет напрямую создавать, обновлять и удалять ресурсы AWS из ваших скриптов на Python.
Если вы уже сталкивались с AWS, имеете собственный аккаунт AWS и хотите поднять свои навыки на новый уровень, начав использовать сервисы AWS из кода на Python, то продолжайте читать.
К концу этого урока вы:
- Будьте уверены в том, что работаете с ведрами и объектами непосредственно из ваших Python-скриптов
- Знайте, как избежать распространенных ловушек при использовании Boto3 и S3
- Поймите, как настроить данные с самого начала, чтобы избежать проблем с производительностью в дальнейшем
- Узнайте, как настроить ваши объекты, чтобы воспользоваться лучшими возможностями S3
Прежде чем приступить к изучению возможностей Boto3, вы узнаете, как настроить SDK на вашей машине. Этот шаг подготовит вас к остальной части учебника.
Установка
Чтобы установить Boto3 на свой компьютер, зайдите в терминал и выполните следующие действия:
$ pip install boto3
У вас есть SDK. Но вы не сможете использовать его прямо сейчас, потому что он не знает, к какому аккаунту AWS ему следует подключиться.
Чтобы заставить его работать с вашей учетной записью AWS, вам нужно будет предоставить некоторые действительные учетные данные. Если у вас уже есть пользователь IAM с полными правами на S3, вы можете использовать его учетные данные (ключ доступа и секретный ключ доступа) без необходимости создавать нового пользователя. В противном случае проще всего создать нового пользователя AWS, а затем сохранить новые учетные данные.
Чтобы создать нового пользователя, зайдите в свою учетную запись AWS, затем перейдите в Services и выберите IAM. Затем выберите Users и нажмите Add user.
Задайте пользователю имя (например, boto3user). Включите программный доступ. Это обеспечит этому пользователю возможность работать с любым SDK, поддерживаемым AWS, или выполнять отдельные вызовы API:
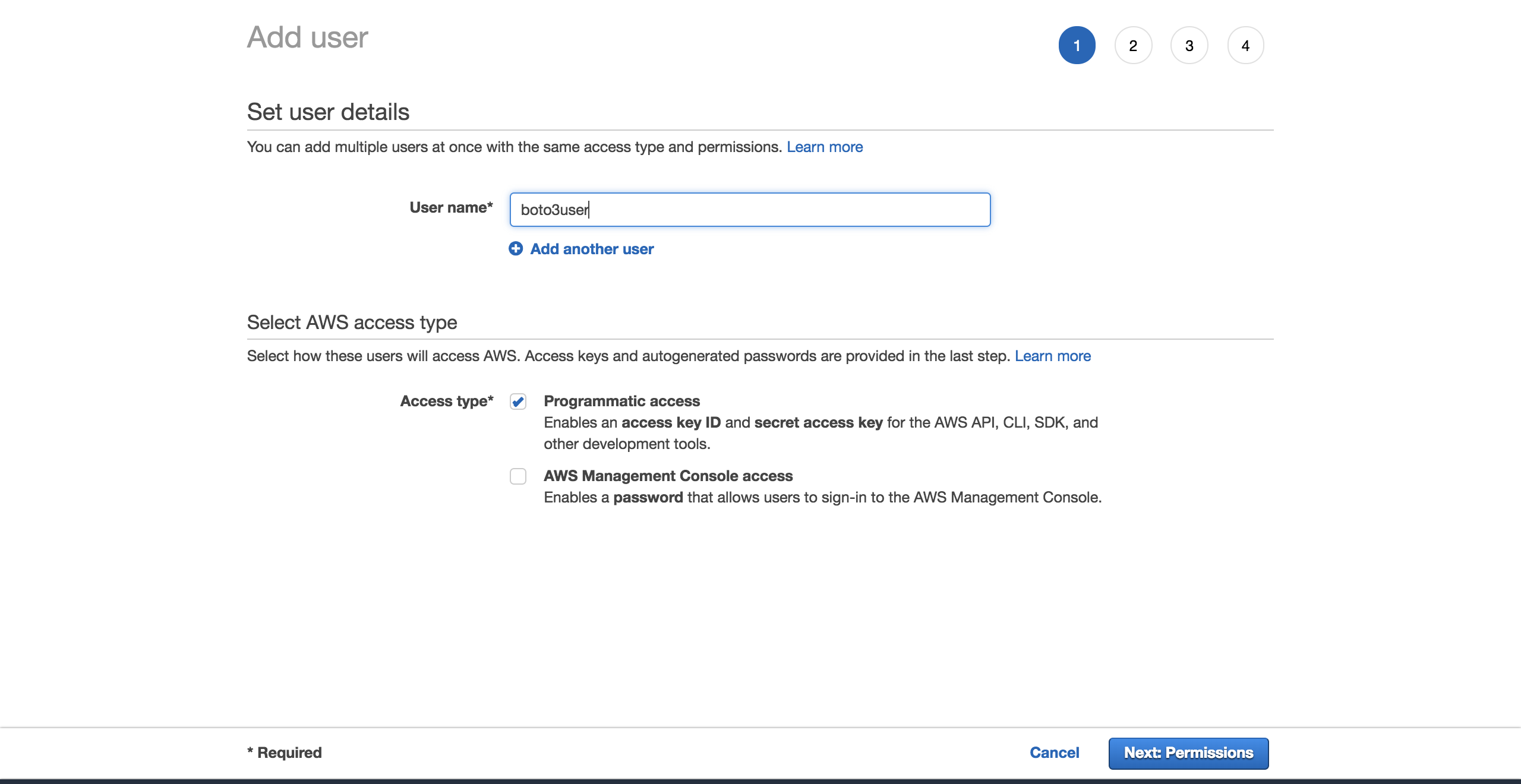
Для простоты выберите предварительно настроенную политику AmazonS3FullAccess. С помощью этой политики новый пользователь сможет получить полный контроль над S3. Нажмите на Next: Обзор:
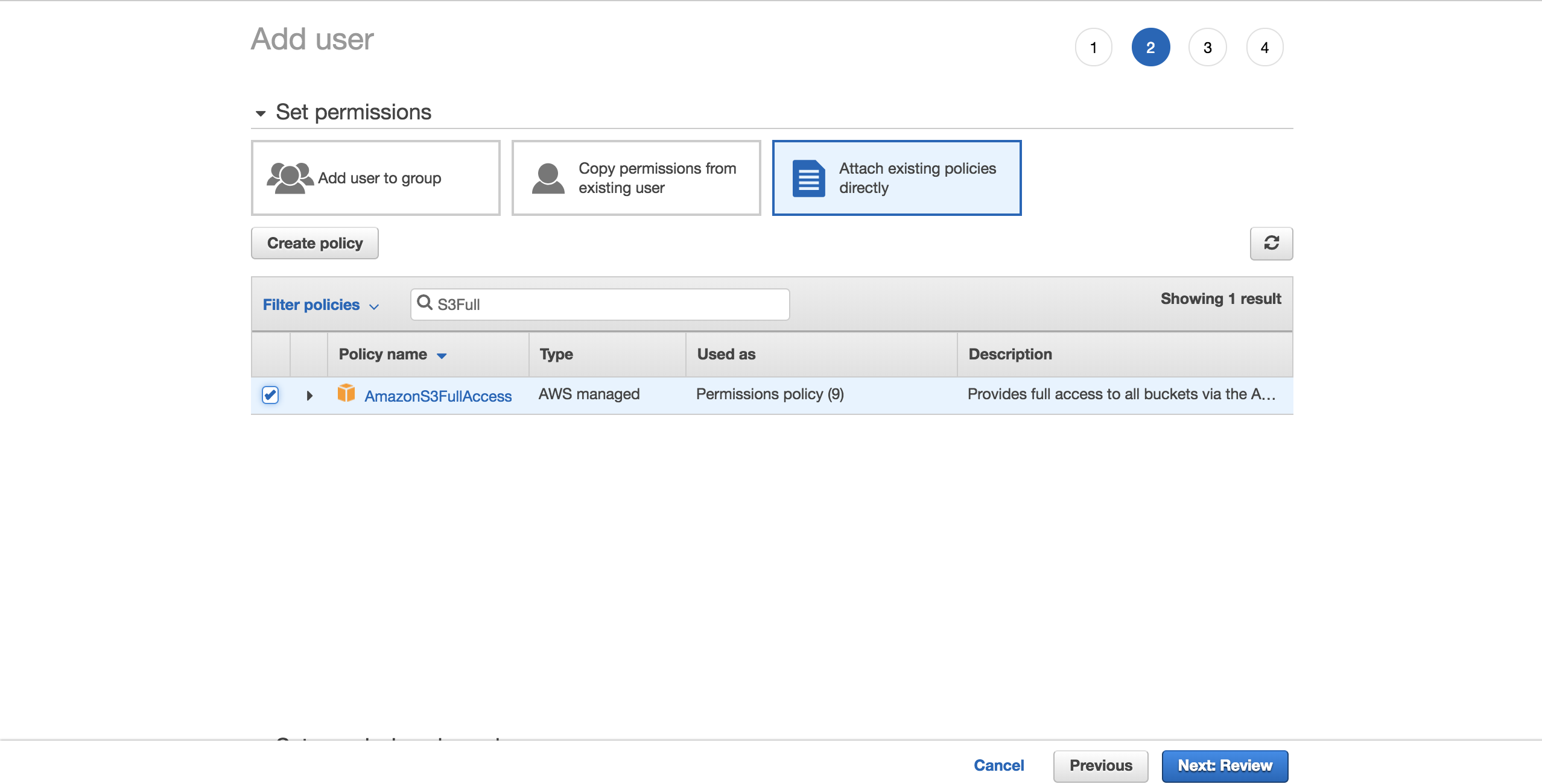
Выберите Создать пользователя:
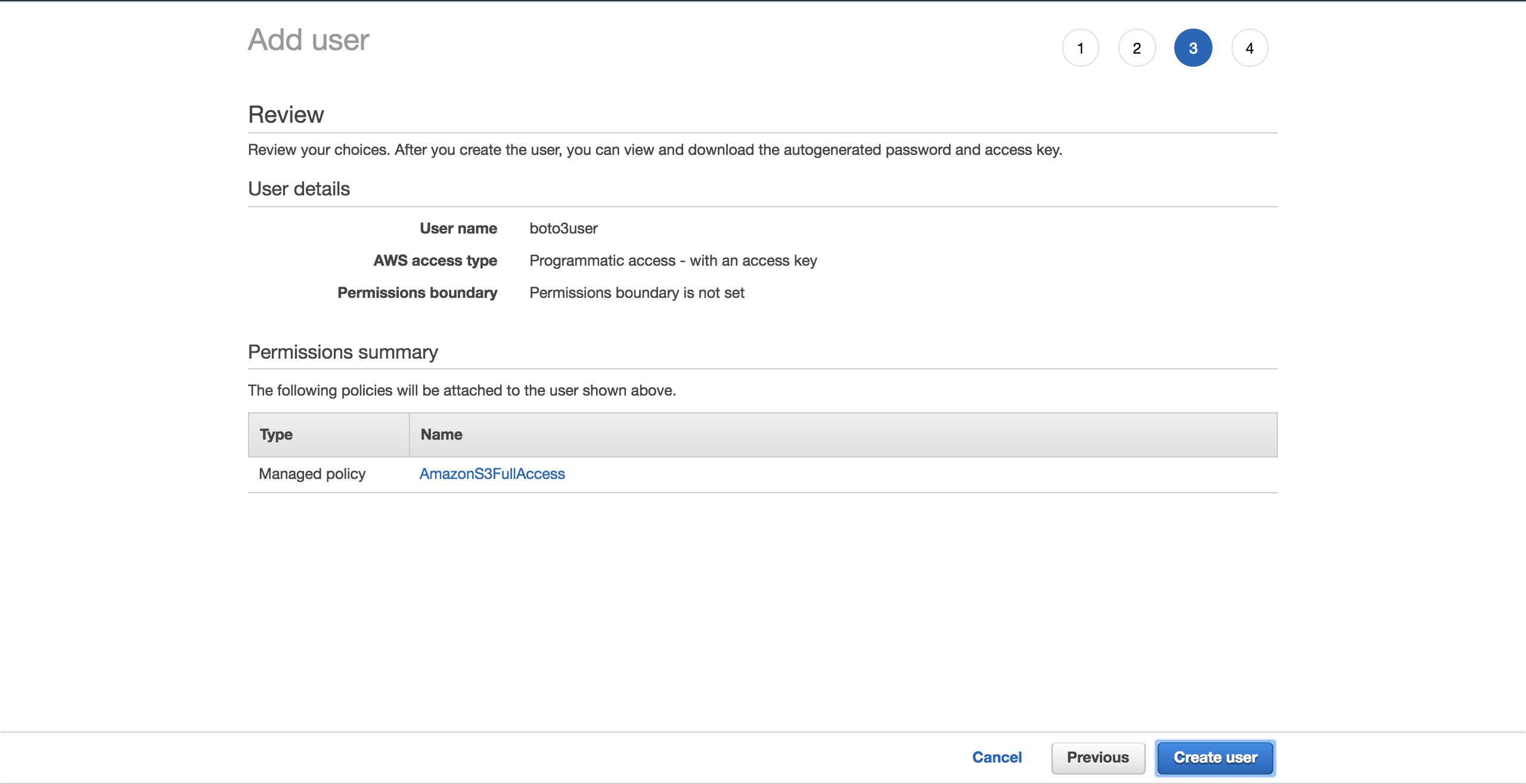
На новом экране вы увидите сгенерированные учетные данные пользователя. Нажмите на кнопку Download .csv, чтобы сделать копию учетных данных. Они понадобятся вам для завершения настройки.
Теперь, когда у вас есть новый пользователь, создайте новый файл, ~/.aws/credentials:
$ touch ~/.aws/credentials
Откройте файл и вставьте в него приведенную ниже структуру. Заполните поля новыми учетными данными пользователя, которые вы загрузили:
[default]
aws_access_key_id = YOUR_ACCESS_KEY_ID
aws_secret_access_key = YOUR_SECRET_ACCESS_KEY
Сохраните файл.
Теперь, когда вы установили эти учетные данные, у вас есть default профиль, который будет использоваться Boto3 для взаимодействия с вашей учетной записью AWS.
Осталось настроить еще одну конфигурацию: регион по умолчанию, с которым будет взаимодействовать Boto3. Вы можете ознакомиться с полной таблицей поддерживаемых регионов AWS. Выберите ближайший к вам регион. Скопируйте нужный вам регион из столбца Region. В моем случае я использую eu-west-1 (Ирландия).
Создайте новый файл, ~/.aws/config:
$ touch ~/.aws/config
Добавьте следующую строку и замените вставку на region, которую вы скопировали:
[default]
region = YOUR_PREFERRED_REGION
Сохраните файл.
Теперь вы официально настроены на дальнейшую работу с учебником.
Далее вы увидите различные опции, которые Boto3 предоставляет для подключения к S3 и другим сервисам AWS.
Клиент против ресурса
По сути, все, что делает Boto3, - это вызывает API AWS от вашего имени. Для большинства сервисов AWS Boto3 предлагает два различных способа доступа к этим абстрактным API:
- Client: низкоуровневый доступ к сервисам
- Resource: высокоуровневый объектно-ориентированный доступ к сервису
Вы можете использовать любой из них для взаимодействия с S3.
Чтобы подключиться к низкоуровневому клиентскому интерфейсу, необходимо использовать client() от Boto3. Затем вы передаете имя сервиса, к которому хотите подключиться, в данном случае s3:
import boto3
s3_client = boto3.client('s3')
Для подключения к высокоуровневому интерфейсу вы будете следовать аналогичному подходу, но использовать resource():
import boto3
s3_resource = boto3.resource('s3')
Вы успешно подключились к обеим версиям, но теперь, возможно, задаетесь вопросом: "Какую из них мне использовать?".
При работе с клиентами приходится выполнять больше программной работы. Большинство клиентских операций дают вам ответ в виде словаря. Чтобы получить нужную информацию, вам придется самостоятельно разобрать этот словарь. При использовании ресурсных методов SDK делает эту работу за вас.
При использовании клиента вы можете заметить небольшое улучшение производительности. Недостатком является то, что ваш код становится менее читабельным, чем если бы вы использовали ресурс. Ресурсы предлагают лучшую абстракцию, и ваш код будет проще для восприятия.
Понимание того, как генерируются клиент и ресурс, также важно, когда вы решаете, какой из них выбрать:
- Boto3 генерирует клиента из файла определения сервиса в формате JSON. Методы клиента поддерживают все типы взаимодействия с целевым AWS-сервисом.
- Ресурсы, с другой стороны, генерируются из файлов определения ресурсов JSON.
Boto3 генерирует клиента и ресурс из разных определений. В результате вы можете столкнуться с ситуацией, когда операция, поддерживаемая клиентом, не предлагается ресурсом. Но вот что интересно: вам не нужно менять свой код, чтобы использовать клиента везде. Для этой операции вы можете обратиться к клиенту напрямую через ресурс, например: s3_resource.meta.client.
Одной из таких операций client является .generate_presigned_url(), которая позволяет предоставить пользователям доступ к объекту в вашем ведре на определенный период времени, не требуя от них наличия учетных данных AWS.
Общие операции
Теперь, когда вы знаете о различиях между клиентами и ресурсами, давайте начнем использовать их для создания новых компонентов S3.
Создание бакета
Для начала вам понадобится S3 bucket. Чтобы создать его программно, сначала нужно выбрать имя для ведра. Помните, что это имя должно быть уникальным для всей платформы AWS, поскольку имена ведер соответствуют DNS. Если вы попытаетесь создать ведро, но другой пользователь уже занял желаемое имя ведра, ваш код потерпит неудачу. Вместо успеха вы увидите следующую ошибку: botocore.errorfactory.BucketAlreadyExists.
Вы можете увеличить шансы на успех при создании ведра, выбрав случайное имя. Вы можете сгенерировать собственную функцию, которая будет делать это за вас. В этой реализации вы увидите, как использование модуля uuid поможет вам добиться этого. Строковое представление UUID4 состоит из 36 символов (включая дефисы), и вы можете добавить префикс, чтобы указать, для чего предназначена каждая ячейка.
Вот способ, с помощью которого вы можете этого добиться:
import uuid
def create_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])
Вы получили имя ведра, но теперь вам нужно знать еще одну вещь: если ваш регион не находится в Соединенных Штатах, вам нужно будет явно определить регион при создании ведра. В противном случае вы получите IllegalLocationConstraintException.
Чтобы проиллюстрировать, что это значит, когда вы создаете ведро S3 в неамериканском регионе, посмотрите на приведенный ниже код:
s3_resource.create_bucket(Bucket=YOUR_BUCKET_NAME,
CreateBucketConfiguration={
'LocationConstraint': 'eu-west-1'})
Вам нужно указать как имя ведра, так и конфигурацию ведра, в которой необходимо указать регион, в моем случае это eu-west-1.
Это не идеальный вариант. Представьте, что вы хотите взять свой код и развернуть его в облаке. Ваша задача становится все сложнее, потому что теперь вы жестко закодировали регион. Вы можете рефакторить регион и превратить его в переменную окружения, но тогда вам придется управлять еще одной вещью.
К счастью, есть лучший способ получить регион программно, воспользовавшись объектом session. Boto3 создаст session на основе ваших учетных данных. Вам нужно только взять регион и передать его create_bucket() в качестве конфигурации LocationConstraint. Вот как это сделать:
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={
'LocationConstraint': current_region})
print(bucket_name, current_region)
return bucket_name, bucket_response
Приятная часть заключается в том, что этот код работает независимо от того, где вы хотите его развернуть: локально/EC2/Lambda. Более того, вам не нужно жестко кодировать свой регион.
Поскольку и клиент, и ресурс создают ведра одинаковым образом, в качестве параметра s3_connection можно передать любой из них.
Теперь вы создадите два ведра. Сначала создайте один с помощью клиента, который вернет вам bucket_response в виде словаря:
>>> first_bucket_name, first_response = create_bucket(
... bucket_prefix='firstpythonbucket',
... s3_connection=s3_resource.meta.client)
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 eu-west-1
>>> first_response
{'ResponseMetadata': {'RequestId': 'E1DCFE71EDE7C1EC', 'HostId': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'x-amz-request-id': 'E1DCFE71EDE7C1EC', 'date': 'Fri, 05 Oct 2018 15:00:00 GMT', 'location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/'}
Затем создайте второй бакет, используя этот ресурс, который вернет вам экземпляр Bucket в качестве bucket_response:
>>> second_bucket_name, second_response = create_bucket(
... bucket_prefix='secondpythonbucket', s3_connection=s3_resource)
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644 eu-west-1
>>> second_response
s3.Bucket(name='secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644')
У вас есть ведра. Далее вам нужно начать добавлять в них файлы.
Именование ваших файлов
Вы можете называть свои объекты, используя стандартные соглашения об именовании файлов. Вы можете использовать любое допустимое имя. В этой статье вы рассмотрите более конкретный случай, который поможет вам понять, как работает S3 под капотом.
Если вы планируете разместить большое количество файлов в своем ведре S3, вам следует кое-что иметь в виду. Если все имена ваших файлов имеют детерминированный префикс, который повторяется для каждого файла, например формат временной метки "YYYY-MM-DDThh:mm:ss", то вскоре вы столкнетесь с проблемами производительности при попытке взаимодействия с вашим ведром.
Это произойдет потому, что S3 берет префикс файла и сопоставляет его с разделом. Чем больше файлов вы добавляете, тем больше их будет назначено одному и тому же разделу, и этот раздел будет очень тяжелым и менее отзывчивым.
Что вы можете сделать, чтобы этого не произошло?
Самое простое решение - рандомизировать имя файла. Можно представить множество различных реализаций, но в данном случае в этом вам поможет доверенный модуль uuid. Чтобы имена файлов было легче читать в этом учебнике, вы возьмете первые шесть символов представления сгенерированного числа hex и соедините их с именем вашего базового файла.
Приведенная ниже вспомогательная функция позволяет передать количество байт, которое вы хотите получить в файле, имя файла и образец содержимого файла, который нужно повторить, чтобы получить желаемый размер файла:
def create_temp_file(size, file_name, file_content):
random_file_name = ''.join([str(uuid.uuid4().hex[:6]), file_name])
with open(random_file_name, 'w') as f:
f.write(str(file_content) * size)
return random_file_name
Создайте свой первый файл, который вы будете использовать в ближайшее время:
first_file_name = create_temp_file(300, 'firstfile.txt', 'f')
Добавив случайность в имена файлов, вы сможете эффективно распределить данные в ведре S3.
Создание Bucket и Object экземпляров
Следующий шаг после создания файла - посмотреть, как интегрировать его в рабочий процесс S3.
Именно здесь классы ресурса играют важную роль, поскольку эти абстракции упрощают работу с S3.
Используя ресурс, вы получаете доступ к классам высокого уровня (Bucket и Object). Вот как вы можете создать по одному из них:
first_bucket = s3_resource.Bucket(name=first_bucket_name)
first_object = s3_resource.Object(
bucket_name=first_bucket_name, key=first_file_name)
Причина отсутствия ошибок при создании переменной first_object заключается в том, что Boto3 не делает вызовов AWS для создания ссылки. Переменные bucket_name и key называются идентификаторами, и они являются необходимыми параметрами для создания Object. Любой другой атрибут Object, например его размер, загружается лениво. Это означает, что для получения запрошенных атрибутов Boto3 должен обратиться к AWS.
Понимание субресурсов
Bucket и Object являются подресурсами друг друга. Подресурсы - это методы, которые создают новый экземпляр дочернего ресурса. Идентификаторы родительского ресурса передаются дочернему ресурсу.
Если у вас есть переменная Bucket, вы можете создать Object напрямую:
first_object_again = first_bucket.Object(first_file_name)
Или если у вас есть переменная Object, то вы можете получить Bucket:
first_bucket_again = first_object.Bucket()
Отлично, теперь вы понимаете, как сгенерировать Bucket и Object. Далее вам предстоит загрузить только что созданный файл в S3, используя эти конструкции.
Загрузка файла
Существует три способа загрузки файла:
- Из экземпляра
Object - От
Bucketэкземпляра - От
client
В каждом случае необходимо указать Filename, который является путем к файлу, который вы хотите загрузить. Сейчас вы рассмотрите три альтернативных варианта. Не стесняйтесь выбрать тот, который вам больше нравится, чтобы загрузить first_file_name в S3.
Версия экземпляра объекта
Вы можете загрузить, используя Object экземпляр:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
Filename=first_file_name)
Или вы можете использовать экземпляр first_object:
first_object.upload_file(first_file_name)
Версия экземпляра ведра
Вот как вы можете загрузить данные, используя экземпляр Bucket:
s3_resource.Bucket(first_bucket_name).upload_file(
Filename=first_file_name, Key=first_file_name)
Версия клиента
Вы также можете загружать файлы, используя client:
s3_resource.meta.client.upload_file(
Filename=first_file_name, Bucket=first_bucket_name,
Key=first_file_name)
Вы успешно загрузили свой файл в S3 одним из трех доступных способов. В последующих разделах вы будете работать в основном с классом Object, поскольку операции в версиях client и Bucket очень похожи.
Загрузка файла
Чтобы локально загрузить файл из S3, выполните те же действия, что и при загрузке. Но в этом случае параметр Filename будет соответствовать желаемому локальному пути. На этот раз файл будет загружен в каталог tmp:
s3_resource.Object(first_bucket_name, first_file_name).download_file(
f'/tmp/{first_file_name}') # Python 3.6+
Вы успешно загрузили свой файл из S3. Далее вы увидите, как скопировать один и тот же файл между вашими ведрами S3 с помощью одного вызова API.
Копирование объекта между ведрами
Если вам нужно скопировать файлы из одного ведра в другое, Boto3 предлагает вам такую возможность. В этом примере вы скопируете файл из первого ведра во второе, используя .copy():
def copy_to_bucket(bucket_from_name, bucket_to_name, file_name):
copy_source = {
'Bucket': bucket_from_name,
'Key': file_name
}
s3_resource.Object(bucket_to_name, file_name).copy(copy_source)
copy_to_bucket(first_bucket_name, second_bucket_name, first_file_name)
Примечание: Если вы хотите реплицировать объекты S3 в ведро в другом регионе, ознакомьтесь с Cross Region Replication.
Удаление объекта
Давайте удалим новый файл из второго ведра, вызвав .delete() на эквивалентном экземпляре Object:
s3_resource.Object(second_bucket_name, first_file_name).delete()
Теперь вы узнали, как использовать основные операции S3. Вы готовы поднять свои знания на новый уровень, изучив более сложные характеристики в следующих разделах.
Расширенные конфигурации
В этом разделе вы изучите более сложные функции S3. Вы увидите примеры их использования и преимущества, которые они могут принести вашим приложениям.
ACL (списки контроля доступа)
Списки контроля доступа (ACL) помогают управлять доступом к ведрам и объектам в них. Они считаются традиционным способом администрирования разрешений в S3. Почему вы должны знать о них? Если вам нужно управлять доступом к отдельным объектам, то вы используете объектный ACL.
По умолчанию, когда вы загружаете объект в S3, этот объект является частным. Если вы хотите сделать этот объект доступным для кого-то еще, вы можете установить ACL объекта как публичный во время создания. Вот как вы загружаете новый файл в ведро и делаете его доступным для всех:
second_file_name = create_temp_file(400, 'secondfile.txt', 's')
second_object = s3_resource.Object(first_bucket.name, second_file_name)
second_object.upload_file(second_file_name, ExtraArgs={
'ACL': 'public-read'})
Вы можете получить экземпляр ObjectAcl из Object, поскольку он является одним из его классов-подресурсов:
second_object_acl = second_object.Acl()
Чтобы узнать, кто имеет доступ к вашему объекту, используйте атрибут grants:
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}, {'Grantee': {'Type': 'Group', 'URI': 'http://acs.amazonaws.com/groups/global/AllUsers'}, 'Permission': 'READ'}]
Вы можете снова сделать свой объект приватным, не загружая его заново:
>>> response = second_object_acl.put(ACL='private')
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}]
Вы видели, как можно использовать ACL для управления доступом к отдельным объектам. Далее вы увидите, как можно добавить дополнительный уровень безопасности к объектам с помощью шифрования.
Примечание: Если вы хотите разделить данные на несколько категорий, обратите внимание на теги. Вы можете предоставлять доступ к объектам на основе их тегов.
Шифрование
С помощью S3 вы можете защитить свои данные с помощью шифрования. Вы изучите шифрование на стороне сервера с использованием алгоритма AES-256, где AWS управляет как шифрованием, так и ключами.
Создайте новый файл и загрузите его с помощью ServerSideEncryption:
third_file_name = create_temp_file(300, 'thirdfile.txt', 't')
third_object = s3_resource.Object(first_bucket_name, third_file_name)
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256'})
Вы можете проверить алгоритм, который был использован для шифрования файла, в данном случае AES256:
>>> third_object.server_side_encryption
'AES256'
Теперь вы понимаете, как добавить дополнительный уровень защиты к вашим объектам с помощью алгоритма шифрования AES-256 на стороне сервера, предлагаемого AWS.
Хранилище
Каждый объект, который вы добавляете в ведро S3, связан с классом хранилища. Все доступные классы хранения обеспечивают высокую долговечность. Вы выбираете способ хранения объектов в зависимости от требований к производительности и доступу вашего приложения.
В настоящее время в S3 можно использовать следующие классы хранилищ:
- STANDARD: по умолчанию для часто используемых данных
- STANDARD_IA: для редко используемых данных, которые должны быть быстро получены по запросу
- ONEZONE_IA: для того же случая использования, что и STANDARD_IA, но данные хранятся в одной зоне доступности вместо трех
- REDUCED_REDUNDANCY: для часто используемых некритичных данных, которые легко воспроизводятся
Если вы хотите изменить класс хранения существующего объекта, вам нужно создать объект заново.
Например, перезагрузите third_object и установите его класс хранения на Standard_IA:
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256',
'StorageClass': 'STANDARD_IA'})
Примечание: Если вы внесли изменения в свой объект, вы можете обнаружить, что ваш локальный экземпляр не отображает их. В этом случае вам нужно вызвать .reload(), чтобы получить самую новую версию вашего объекта.
Перезагрузите объект, и вы увидите его новый класс хранения:
>>> third_object.reload()
>>> third_object.storage_class
'STANDARD_IA'
Примечание: Используйте LifeCycle Configurations для перехода объектов через различные классы по мере возникновения потребности в них. Они будут автоматически переводить эти объекты для вас.
Версионирование
Вы должны использовать версионность, чтобы сохранять полную информацию о своих объектах с течением времени. Это также служит механизмом защиты от случайного удаления объектов. Когда вы запрашиваете объект с версией, Boto3 получит последнюю версию.
Когда вы добавляете новую версию объекта, объем памяти, занимаемый этим объектом, равен сумме размеров его версий. Так что если вы храните объект размером 1 ГБ, а создаете 10 версий, то вам придется заплатить за 10 ГБ хранилища.
Включите версионность для первого ведра. Для этого необходимо использовать класс BucketVersioning:
def enable_bucket_versioning(bucket_name):
bkt_versioning = s3_resource.BucketVersioning(bucket_name)
bkt_versioning.enable()
print(bkt_versioning.status)
>>> enable_bucket_versioning(first_bucket_name)
Enabled
Затем создайте две новые версии для первого файла Object, одну с содержимым оригинального файла, а другую с содержимым третьего файла:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
first_file_name)
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
third_file_name)
Теперь перезагрузите второй файл, который создаст новую версию:
s3_resource.Object(first_bucket_name, second_file_name).upload_file(
second_file_name)
Вы можете получить последнюю доступную версию ваших объектов следующим образом:
>>> s3_resource.Object(first_bucket_name, first_file_name).version_id
'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'
В этом разделе вы узнали, как работать с некоторыми из наиболее важных атрибутов S3 и добавлять их к своим объектам. Далее вы увидите, как легко перемещаться по ведрам и объектам.
Траверсалы
Если вам нужно получить информацию или применить операцию ко всем ресурсам S3, Boto3 предоставляет вам несколько способов итеративного обхода ведер и объектов. Вы начнете с обхода всех созданных вами ведер.
Обход бакета
Чтобы обойти все ведра в вашем аккаунте, вы можете использовать атрибут buckets ресурса наряду с .all(), который дает вам полный список Bucket экземпляров:
>>> for bucket in s3_resource.buckets.all():
... print(bucket.name)
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644
Вы можете использовать client для получения информации о ведре, но код будет сложнее, так как вам нужно извлечь ее из словаря, который возвращает client:
>>> for bucket_dict in s3_resource.meta.client.list_buckets().get('Buckets'):
... print(bucket_dict['Name'])
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644
Вы уже видели, как выполнять итерации по ведрам, которые есть в вашем аккаунте. В следующем разделе вы выберете одну из ведер и итеративно просмотрите содержащиеся в ней объекты.
Обход объекта
Если вы хотите перечислить все объекты из ведра, следующий код сгенерирует для вас итератор:
>>> for obj in first_bucket.objects.all():
... print(obj.key)
...
127367firstfile.txt
616abesecondfile.txt
fb937cthirdfile.txt
Переменная obj является ObjectSummary. Это облегченное представление Object. Облегченная версия не поддерживает все атрибуты, которые есть у Object. Если вам нужно получить к ним доступ, используйте подресурс Object() для создания новой ссылки на базовый хранимый ключ. Тогда вы сможете извлечь недостающие атрибуты:
>>> for obj in first_bucket.objects.all():
... subsrc = obj.Object()
... print(obj.key, obj.storage_class, obj.last_modified,
... subsrc.version_id, subsrc.metadata)
...
127367firstfile.txt STANDARD 2018-10-05 15:09:46+00:00 eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv {}
616abesecondfile.txt STANDARD 2018-10-05 15:09:47+00:00 WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6 {}
fb937cthirdfile.txt STANDARD_IA 2018-10-05 15:09:05+00:00 null {}
Теперь вы можете итеративно выполнять операции над ведрами и объектами. Вы почти закончили. На этом этапе вы должны знать еще одну вещь: как удалить все ресурсы, которые вы создали в этом уроке.
Удаление бакетов и объектов
Чтобы удалить все созданные вами ведра и объекты, сначала нужно убедиться, что в ведрах нет объектов.
Удаление непустого бакета
Чтобы удалить ведро, вы должны сначала удалить все объекты в нем, иначе возникнет исключение BucketNotEmpty. Если у вас есть ведро с версиями, вам нужно удалить каждый объект и все его версии.
Если вы обнаружите, что правило LifeCycle, которое будет делать это автоматически, не подходит для ваших нужд, вот как вы можете программно удалить объекты:
def delete_all_objects(bucket_name):
res = []
bucket=s3_resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
print(res)
bucket.delete_objects(Delete={'Objects': res})
Приведенный выше код работает независимо от того, включили ли вы версионирование на вашем ведре или нет. Если нет, версия объектов будет равна null. Вы можете пакетно удалить до 1000 объектов за один вызов API, используя .delete_objects() на экземпляре Bucket, что более экономично, чем удалять каждый объект по отдельности.
Запустите новую функцию в первом ведре, чтобы удалить все объекты с версиями:
>>> delete_all_objects(first_bucket_name)
[{'Key': '127367firstfile.txt', 'VersionId': 'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'}, {'Key': '127367firstfile.txt', 'VersionId': 'UnQTaps14o3c1xdzh09Cyqg_hq4SjB53'}, {'Key': '127367firstfile.txt', 'VersionId': 'null'}, {'Key': '616abesecondfile.txt', 'VersionId': 'WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6'}, {'Key': '616abesecondfile.txt', 'VersionId': 'null'}, {'Key': 'fb937cthirdfile.txt', 'VersionId': 'null'}]
В качестве последнего теста можно загрузить файл во второе ведро. В этом ведре не включена версионность, поэтому версия будет равна null. Примените ту же функцию для удаления содержимого:
>>> s3_resource.Object(second_bucket_name, first_file_name).upload_file(
... first_file_name)
>>> delete_all_objects(second_bucket_name)
[{'Key': '9c8b44firstfile.txt', 'VersionId': 'null'}]
Вы успешно удалили все объекты из обоих ведер. Теперь вы готовы удалить ведра.
Удаление бакетов
Чтобы закончить, вы используете .delete() на экземпляре Bucket для удаления первого ведра:
s3_resource.Bucket(first_bucket_name).delete()
Если вы хотите, вы можете использовать версию client для удаления второго ведра:
s3_resource.meta.client.delete_bucket(Bucket=second_bucket_name)
Обе операции прошли успешно, потому что вы опустошили каждое ведро перед попыткой его удаления.
Теперь вы выполнили некоторые из самых важных операций, которые можно выполнить с помощью S3 и Boto3. Поздравляем вас с тем, что вы продвинулись так далеко! В качестве бонуса давайте рассмотрим некоторые преимущества управления ресурсами S3 с помощью Infrastructure as Code.
Код на Python или Инфраструктура как код (IaC)?
Как вы видели, большинство взаимодействий с S3 в этом учебнике было связано с объектами. Вы не видели многих операций, связанных с ведрами, таких как добавление политик к ведру, добавление правила LifeCycle для перехода объектов через классы хранения, архивирования их в Glacier или полного удаления, или принудительное шифрование всех объектов с помощью настройки Bucket Encryption.
Ручное управление состоянием ведер с помощью клиентов или ресурсов Boto3 становится все более сложным, когда ваше приложение начинает добавлять другие сервисы и становится все более сложным. Чтобы контролировать инфраструктуру совместно с Boto3, рассмотрите возможность использования инструмента Infrastructure as Code (IaC), такого как CloudFormation или Terraform, для управления инфраструктурой вашего приложения. Любой из этих инструментов будет поддерживать состояние инфраструктуры и информировать вас об изменениях, которые вы внесли.
Если вы решите пойти по этому пути, имейте в виду следующее:
- Любая операция, связанная с ведром и изменяющая его каким-либо образом, должна выполняться через IaC.
- Если вы хотите, чтобы все ваши объекты действовали одинаково (все зашифрованы или все публичны, например), обычно есть способ сделать это непосредственно с помощью IaC, добавив политику ведра или определенное свойство ведра.
- Операции чтения из ведра, такие как итерация по содержимому ведра, должны выполняться с помощью Boto3.
- Операции, связанные с объектами на уровне отдельных объектов, должны выполняться с помощью Boto3.
Заключение
Поздравляем вас с тем, что вы дошли до конца этого урока!
Теперь вы готовы начать работать с S3 программно. Теперь вы знаете, как создавать объекты, загружать их в S3, скачивать их содержимое и изменять их атрибуты прямо из вашего скрипта, избегая при этом распространенных ловушек с Boto3.
Пусть этот учебник станет ступенькой на вашем пути к созданию чего-то великого с помощью AWS!
Дальнейшее чтение
Если вы хотите узнать больше, ознакомьтесь со следующими материалами:
- Документация Boto3
- Генерирование случайных данных на Python (руководство)
- Политики IAM и политики ведер и ACL
- Тегирование объектов
- Конфигурации жизненного цикла
- Кросс-региональная репликация
- CloudFormation
- Terraform