pandas Sort: Ваше руководство по сортировке данных в Python
Оглавление
- Начало работы с методами сортировки Pandas
- Сортировка вашего фрейма данных по одному столбцу
- Сортировка вашего фрейма данных по нескольким столбцам
- Сортировка вашего фрейма данных по его индексу
- Сортировка столбцов вашего фрейма данных
- Работа с отсутствующими Данными при Сортировке в Pandas
- Использование методов сортировки для изменения вашего фрейма данных
- Заключение
Изучение pandas методов сортировки - отличный способ начать или попрактиковаться в базовом анализе данных с использованием Python. Чаще всего анализ данных выполняется с помощью электронных таблиц, SQL или pandas. Одним из преимуществ использования pandas является то, что он может обрабатывать большой объем данных и обладает высокопроизводительными возможностями манипулирования данными.
В этом руководстве вы узнаете, как использовать .sort_values() и .sort_index(), которые позволят вам эффективно сортировать данные во фрейме данных.
К концу этого урока вы будете знать, как:
- Отсортировать Фрейм данных pandas по значениям одного или нескольких столбцов
- Используйте параметр
ascending, чтобы изменить порядок сортировки - Сортировка фрейма данных по его
indexс помощью.sort_index() - Упорядочивать недостающие данные при сортировке значений
- Отсортировать фрейм данных на месте, используя
inplaceзначениеTrue
Чтобы следовать этому руководству, вам потребуется базовое понимание фреймов данных pandas и некоторое знакомство с чтением данных из файлов.
Начало работы с методами сортировки Pandas
В качестве краткого напоминания, Фрейм данных - это структура данных с обозначенными осями как для строк, так и для столбцов. Вы можете отсортировать фрейм данных по значению строки или столбца, а также по индексу строки или столбца.
Как строки, так и столбцы имеют индексы, которые представляют собой числовые представления того, где находятся данные в вашем фрейме данных. Вы можете извлекать данные из определенных строк или столбцов, используя расположение индексов фрейма данных. По умолчанию номера индексов начинаются с нуля. Вы также можете вручную присвоить свой собственный индекс.
Подготовка набора данных
В этом руководстве вы будете работать с данными об экономии топлива, собранными Агентством по охране окружающей среды США (EPA) для автомобилей, выпущенных в период с 1984 по 2021 год. Набор данных по экономии топлива EPA великолепен тем, что содержит множество различных типов информации, по которой вы можете выполнять сортировку, от текстовых до числовых типов данных. Всего набор данных содержит восемьдесят три столбца.
Чтобы продолжить, вам потребуется установить библиотеку Python pandas. Код, приведенный в этом руководстве, был выполнен с использованием pandas 1.2.0 и Python 3.9.1.
Примечание: Объем всего набора данных об экономии топлива составляет около 18 МБ. Считывание всего набора данных в память может занять минуту или две. Ограничение количества строк и столбцов повысит производительность, но загрузка данных все равно займет несколько секунд.
Для целей анализа вы будете просматривать данные о пробеге (милях на галлон) транспортных средств по марке, модели, году выпуска и другим атрибутам транспортного средства. Вы можете указать, какие столбцы следует считывать в вашем фрейме данных. Для этого руководства вам понадобится только часть доступных столбцов .
Вот команды для считывания соответствующих столбцов набора данных об экономии топлива во фрейм данных и отображения первых пяти строк:
>>> import pandas as pd
>>> column_subset = [
... "id",
... "make",
... "model",
... "year",
... "cylinders",
... "fuelType",
... "trany",
... "mpgData",
... "city08",
... "highway08"
... ]
>>> df = pd.read_csv(
... "https://www.fueleconomy.gov/feg/epadata/vehicles.csv",
... usecols=column_subset,
... nrows=100
... )
>>> df.head()
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
[5 rows x 10 columns]
Вызывая .read_csv() с URL-адресом набора данных, вы можете загрузить данные в DataFrame. Уменьшение количества столбцов приводит к ускорению загрузки и снижению использования памяти. Чтобы еще больше ограничить потребление памяти и быстро ознакомиться с данными, вы можете указать, сколько строк загружать с помощью nrows.
Знакомство с .sort_values()
Используется .sort_values() для сортировки значений во фрейме данных по любой оси (столбцам или строкам). Как правило, вы хотите отсортировать строки во фрейме данных по значениям одного или нескольких столбцов:
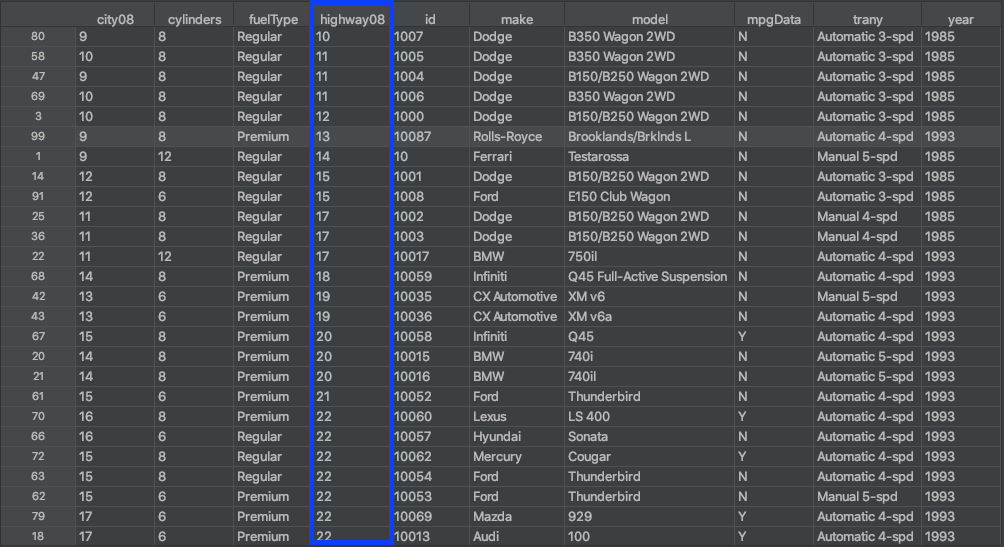
На рисунке выше показаны результаты использования .sort_values() для сортировки строк фрейма данных на основе значений в столбце highway08. Это похоже на то, как вы сортируете данные в электронной таблице с помощью столбца.
Знакомство с .sort_index()
Вы используете .sort_index() для сортировки фрейма данных по индексу строки или меткам столбца. Отличие от использования .sort_values() заключается в том, что вы сортируете фрейм данных на основе его индекса строки или имен столбцов, а не по значениям в этих строках или столбцах:
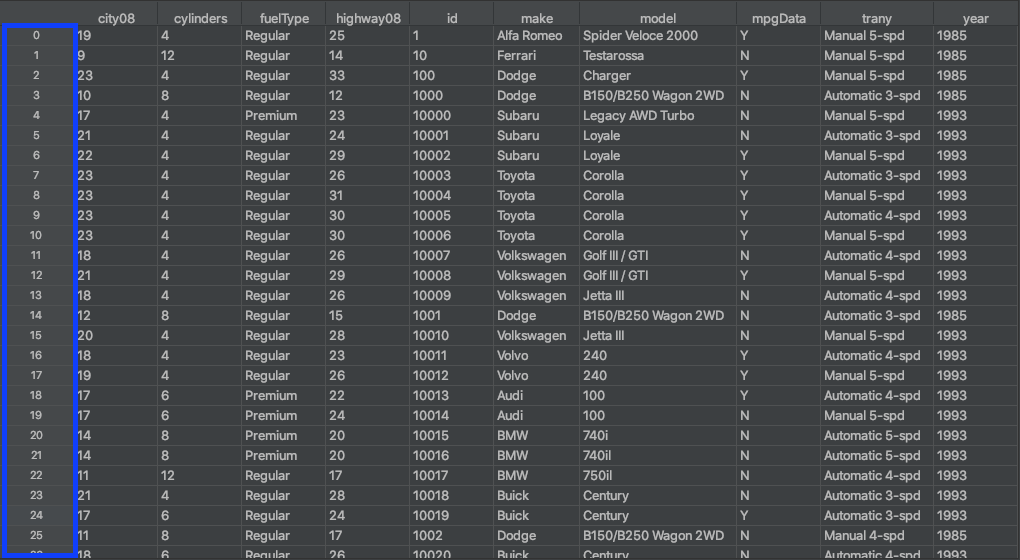
Индекс строки фрейма данных выделен синим цветом на рисунке выше. Индекс не считается столбцом, и обычно у вас есть только индекс одной строки. Индекс строки можно рассматривать как номера строк, которые начинаются с нуля.
Сортировка вашего фрейма данных по одному столбцу
Чтобы отсортировать фрейм данных на основе значений в одном столбце, вы будете использовать .sort_values(). По умолчанию будет возвращен новый фрейм данных, отсортированный в порядке возрастания. Это не изменяет исходный фрейм данных.
Сортировка по столбцу в порядке возрастания
Чтобы использовать .sort_values(), вы передаете методу единственный аргумент, содержащий имя столбца, по которому вы хотите выполнить сортировку. В этом примере вы сортируете фрейм данных по столбцу city08, который представляет количество миль на галлон в городе для автомобилей, работающих только на топливе:
>>> df.sort_values("city08")
city08 cylinders fuelType ... mpgData trany year
99 9 8 Premium ... N Automatic 4-spd 1993
1 9 12 Regular ... N Manual 5-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
.. ... ... ... ... ... ... ...
9 23 4 Regular ... Y Automatic 4-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
7 23 4 Regular ... Y Automatic 3-spd 1993
76 23 4 Regular ... Y Manual 5-spd 1993
2 23 4 Regular ... Y Manual 5-spd 1985
[100 rows x 10 columns]
При этом выполняется сортировка вашего фрейма данных по значениям столбцов из city08, в первую очередь отображаются автомобили с наименьшим количеством миль на галлон. По умолчанию .sort_values() сортирует ваши данные в порядке возрастания. Хотя вы не указали имя аргумента, который вы передали в .sort_values(), на самом деле вы использовали параметр by, который вы увидите в следующем примере.
Изменение порядка сортировки
Другим параметром .sort_values() является ascending. По умолчанию для .sort_values() для ascending установлено значение True. Если вы хотите, чтобы фрейм данных был отсортирован в порядке убывания, то вы можете передать False этому параметру:
>>> df.sort_values(
... by="city08",
... ascending=False
... )
city08 cylinders fuelType ... mpgData trany year
9 23 4 Regular ... Y Automatic 4-spd 1993
2 23 4 Regular ... Y Manual 5-spd 1985
7 23 4 Regular ... Y Automatic 3-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
76 23 4 Regular ... Y Manual 5-spd 1993
.. ... ... ... ... ... ... ...
58 10 8 Regular ... N Automatic 3-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
При переходе от False к ascending порядок сортировки меняется на противоположный. Теперь ваш фрейм данных сортируется в порядке убывания среднего значения миль на галлон, измеренного в городских условиях. Автомобили с самыми высокими значениями миль на галлон находятся в первых рядах.
Выбор алгоритма сортировки
Приятно отметить, что pandas позволяет вам выбирать различные алгоритмы сортировки для использования как с .sort_values(), так и с .sort_index(). Доступны следующие алгоритмы quicksort, mergesort, и heapsort. Для получения дополнительной информации об этих различных алгоритмах сортировки ознакомьтесь с Алгоритмами сортировки в Python.
Алгоритм, используемый по умолчанию при сортировке по одному столбцу, следующий quicksort. Чтобы изменить этот алгоритм на стабильный, используйте mergesort. Вы можете сделать это с помощью параметра kind в .sort_values() или .sort_index(), например, так:
>>> df.sort_values(
... by="city08",
... ascending=False,
... kind="mergesort"
... )
city08 cylinders fuelType ... mpgData trany year
2 23 4 Regular ... Y Manual 5-spd 1985
7 23 4 Regular ... Y Automatic 3-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
9 23 4 Regular ... Y Automatic 4-spd 1993
10 23 4 Regular ... Y Manual 5-spd 1993
.. ... ... ... ... ... ... ...
69 10 8 Regular ... N Automatic 3-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
Используя kind, вы устанавливаете алгоритм сортировки на mergesort. В предыдущем выводе использовался алгоритм по умолчанию quicksort. Взглянув на выделенные индексы, вы можете увидеть, что строки расположены в другом порядке. Это связано с тем, что quicksort не является стабильным алгоритмом сортировки, в отличие от mergesort.
Примечание: В pandas значение kind игнорируется при сортировке более чем по одному столбцу или метке.
Когда вы сортируете несколько записей с одинаковым ключом, стабильный алгоритм сортировки сохранит первоначальный порядок этих записей после сортировки. По этой причине, если вы планируете выполнять несколько сортировок, необходимо использовать стабильный алгоритм сортировки.
Сортировка вашего фрейма данных по нескольким столбцам
При анализе данных часто возникает необходимость сортировать данные на основе значений нескольких столбцов. Представьте, что у вас есть набор данных с именами и фамилиями людей. Было бы разумно отсортировать данные по фамилии, а затем по имени, чтобы люди с одинаковой фамилией были расположены в алфавитном порядке в соответствии с их именами.
В первом примере вы отсортировали свой фрейм данных по одному столбцу с именем city08. С точки зрения анализа, количество миль на галлон в городских условиях является важным фактором, который может определить желательность автомобиля. В дополнение к показателям миль на галлон в городских условиях, вы также можете обратить внимание на показатели миль на галлон на шоссе. Для сортировки по двум ключам вы можете передать список имен столбцов в by:
>>> df.sort_values(
... by=["city08", "highway08"]
... )[["city08", "highway08"]]
city08 highway08
80 9 10
47 9 11
99 9 13
1 9 14
58 10 11
.. ... ...
9 23 30
10 23 30
8 23 31
76 23 31
2 23 33
[100 rows x 2 columns]
Указав список имен столбцов city08 и highway08, вы сортируете фрейм данных по двум столбцам, используя .sort_values(). В следующем примере будет объяснено, как задать порядок сортировки и почему важно обращать внимание на список используемых имен столбцов.
Сортировка по нескольким столбцам в порядке возрастания
Чтобы отсортировать фрейм данных по нескольким столбцам, вы должны предоставить список имен столбцов. Например, для сортировки по make и model вам следует создать следующий список и затем передать его в .sort_values():
>>> df.sort_values(
... by=["make", "model"]
... )[["make", "model"]]
make model
0 Alfa Romeo Spider Veloce 2000
18 Audi 100
19 Audi 100
20 BMW 740i
21 BMW 740il
.. ... ...
12 Volkswagen Golf III / GTI
13 Volkswagen Jetta III
15 Volkswagen Jetta III
16 Volvo 240
17 Volvo 240
[100 rows x 2 columns]
Теперь ваш фрейм данных сортируется в порядке возрастания по make. Если есть две или более одинаковых марки, то они сортируются по model. Порядок, в котором указаны имена столбцов в вашем списке, соответствует тому, как будет отсортирован ваш фрейм данных.
Изменение порядка сортировки столбцов
Поскольку вы выполняете сортировку по нескольким столбцам, вы можете указать порядок сортировки ваших столбцов. Если вы хотите изменить порядок логической сортировки из предыдущего примера, то вы можете изменить порядок имен столбцов в списке, который вы передаете параметру by:
>>> df.sort_values(
... by=["model", "make"]
... )[["make", "model"]]
make model
18 Audi 100
19 Audi 100
16 Volvo 240
17 Volvo 240
75 Mazda 626
.. ... ...
62 Ford Thunderbird
63 Ford Thunderbird
88 Oldsmobile Toronado
42 CX Automotive XM v6
43 CX Automotive XM v6a
[100 rows x 2 columns]
Теперь ваш фрейм данных отсортирован по столбцу model в порядке возрастания, а затем отсортирован по make, если есть две или более одинаковых модели. Вы можете видеть, что изменение порядка столбцов также изменяет порядок сортировки значений.
Сортировка по нескольким столбцам в порядке убывания
До этого момента вы сортировали только в порядке возрастания по нескольким столбцам. В следующем примере вы будете выполнять сортировку в порядке убывания по столбцам make и model. Для сортировки в порядке убывания установите для ascending значение False:
>>> df.sort_values(
... by=["make", "model"],
... ascending=False
... )[["make", "model"]]
make model
16 Volvo 240
17 Volvo 240
13 Volkswagen Jetta III
15 Volkswagen Jetta III
11 Volkswagen Golf III / GTI
.. ... ...
21 BMW 740il
20 BMW 740i
18 Audi 100
19 Audi 100
0 Alfa Romeo Spider Veloce 2000
[100 rows x 2 columns]
Значения в столбце make расположены в обратном алфавитном порядке, а значения в столбце model расположены в порядке убывания для любых автомобилей с одинаковыми номерами make. При сортировке текстовых данных учитывается регистр символов , что означает, что текст с заглавной буквы будет отображаться первым в порядке возрастания и последним в порядке убывания.
Сортировка по Нескольким столбцам С Разным порядком Сортировки
Возможно, вам интересно, возможно ли выполнить сортировку, используя несколько столбцов, и чтобы эти столбцы использовали разные аргументы ascending. В pandas это можно сделать с помощью одного вызова метода. Если вы хотите отсортировать некоторые столбцы в порядке возрастания, а некоторые - в порядке убывания, то вы можете передать список логических значений в ascending.
В этом примере вы сортируете фрейм данных по столбцам make, model, и city08, при этом первые два столбца сортируются в порядке возрастания, а city08 сортируются в порядке убывания. Для этого вы передаете список имен столбцов в by и список логических значений в ascending:
>>> df.sort_values(
... by=["make", "model", "city08"],
... ascending=[True, True, False]
... )[["make", "model", "city08"]]
make model city08
0 Alfa Romeo Spider Veloce 2000 19
18 Audi 100 17
19 Audi 100 17
20 BMW 740i 14
21 BMW 740il 14
.. ... ... ...
11 Volkswagen Golf III / GTI 18
15 Volkswagen Jetta III 20
13 Volkswagen Jetta III 18
17 Volvo 240 19
16 Volvo 240 18
[100 rows x 3 columns]
Теперь ваш фрейм данных отсортирован по make и model в порядке возрастания, но со столбцом city08 в порядке убывания. Это полезно, поскольку позволяет группировать автомобили в категориальном порядке и первыми показывать автомобили с наибольшим количеством миль на галлон.
Сортировка вашего фрейма данных по его индексу
Перед сортировкой по индексу полезно знать, что представляет собой индекс. Фрейм данных имеет свойство .index, которое по умолчанию представляет собой числовое представление расположения его строк. Индекс можно представить как номера строк. Это помогает в быстром поиске строк и их идентификации.
Сортировка по индексу в порядке возрастания
Вы можете отсортировать фрейм данных на основе его индекса строки с помощью .sort_index(). Сортировка по значениям столбцов, как вы делали в предыдущих примерах, изменяет порядок строк в вашем фрейме данных, поэтому индекс становится неорганизованным. Это также может произойти при фильтрации фрейма данных или при удалении или добавлении строк.
Чтобы проиллюстрировать использование .sort_index(), начните с создания нового отсортированного фрейма данных с помощью .sort_values():
>>> sorted_df = df.sort_values(by=["make", "model"])
>>> sorted_df
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
18 17 6 Premium ... Y Automatic 4-spd 1993
19 17 6 Premium ... N Manual 5-spd 1993
20 14 8 Premium ... N Automatic 5-spd 1993
21 14 8 Premium ... N Automatic 5-spd 1993
.. ... ... ... ... ... ... ...
12 21 4 Regular ... Y Manual 5-spd 1993
13 18 4 Regular ... N Automatic 4-spd 1993
15 20 4 Regular ... N Manual 5-spd 1993
16 18 4 Regular ... Y Automatic 4-spd 1993
17 19 4 Regular ... Y Manual 5-spd 1993
[100 rows x 10 columns]
Вы создали фрейм данных, отсортированный по нескольким значениям. Обратите внимание, что индекс строки расположен в произвольном порядке. Чтобы вернуть ваш новый фрейм данных к исходному порядку, вы можете использовать .sort_index():
>>> sorted_df.sort_index()
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Y Automatic 3-spd 1993
96 17 6 Regular ... N Automatic 4-spd 1993
97 15 6 Regular ... N Automatic 4-spd 1993
98 15 6 Regular ... N Manual 5-spd 1993
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
Теперь индекс расположен в порядке возрастания. Как и в случае с .sort_values(), аргументом по умолчанию для ascending в .sort_index() является True, и вы можете изменить порядок убывания, передав False. Сортировка по индексу никак не влияет на сами данные, поскольку значения остаются неизменными.
Это особенно полезно, когда вы назначили пользовательский индекс с .set_index(). Если вы хотите задать пользовательский индекс, используя столбцы make и model, вы можете передать список в .set_index():
>>> assigned_index_df = df.set_index(
... ["make", "model"]
... )
>>> assigned_index_df
city08 cylinders ... trany year
make model ...
Alfa Romeo Spider Veloce 2000 19 4 ... Manual 5-spd 1985
Ferrari Testarossa 9 12 ... Manual 5-spd 1985
Dodge Charger 23 4 ... Manual 5-spd 1985
B150/B250 Wagon 2WD 10 8 ... Automatic 3-spd 1985
Subaru Legacy AWD Turbo 17 4 ... Manual 5-spd 1993
... ... ... ... ...
Pontiac Grand Prix 17 6 ... Automatic 3-spd 1993
Grand Prix 17 6 ... Automatic 4-spd 1993
Grand Prix 15 6 ... Automatic 4-spd 1993
Grand Prix 15 6 ... Manual 5-spd 1993
Rolls-Royce Brooklands/Brklnds L 9 8 ... Automatic 4-spd 1993
[100 rows x 8 columns]
Используя этот метод, вы заменяете индекс строки, основанный на целых числах по умолчанию, двумя метками оси. Это считается MultiIndex или иерархическим индексом. Ваш фрейм данных теперь индексируется по нескольким ключам, по которым вы можете выполнять сортировку с помощью .sort_index():
>>> assigned_index_df.sort_index()
city08 cylinders ... trany year
make model ...
Alfa Romeo Spider Veloce 2000 19 4 ... Manual 5-spd 1985
Audi 100 17 6 ... Automatic 4-spd 1993
100 17 6 ... Manual 5-spd 1993
BMW 740i 14 8 ... Automatic 5-spd 1993
740il 14 8 ... Automatic 5-spd 1993
... ... ... ... ...
Volkswagen Golf III / GTI 21 4 ... Manual 5-spd 1993
Jetta III 18 4 ... Automatic 4-spd 1993
Jetta III 20 4 ... Manual 5-spd 1993
Volvo 240 18 4 ... Automatic 4-spd 1993
240 19 4 ... Manual 5-spd 1993
[100 rows x 8 columns]
Сначала вы присваиваете новый индекс своему фрейму данных, используя столбцы make и model, затем сортируете индекс, используя .sort_index(). Вы можете прочитать больше об использовании .set_index() в документации по pandas.
Сортировка по индексу в порядке убывания
В следующем примере вы отсортируете свой фрейм данных по его индексу в порядке убывания. Помните, что при сортировке вашего фрейма данных с помощью .sort_values() вы можете изменить порядок сортировки, установив для ascending значение False. Этот параметр также работает с .sort_index(), поэтому вы можете отсортировать свой фрейм данных в обратном порядке следующим образом:
>>> assigned_index_df.sort_index(ascending=False)
city08 cylinders ... trany year
make model ...
Volvo 240 18 4 ... Automatic 4-spd 1993
240 19 4 ... Manual 5-spd 1993
Volkswagen Jetta III 18 4 ... Automatic 4-spd 1993
Jetta III 20 4 ... Manual 5-spd 1993
Golf III / GTI 18 4 ... Automatic 4-spd 1993
... ... ... ... ...
BMW 740il 14 8 ... Automatic 5-spd 1993
740i 14 8 ... Automatic 5-spd 1993
Audi 100 17 6 ... Automatic 4-spd 1993
100 17 6 ... Manual 5-spd 1993
Alfa Romeo Spider Veloce 2000 19 4 ... Manual 5-spd 1985
[100 rows x 8 columns]
Теперь ваш фрейм данных отсортирован по индексу в порядке убывания. Одно из отличий между использованием .sort_index() и .sort_values() заключается в том, что .sort_index() не имеет параметра by, поскольку по умолчанию он сортирует фрейм данных по индексу строки.
Изучение передовых концепций сортировки по индексу
При анализе данных часто возникает необходимость в сортировке по иерархическому индексу. Вы уже видели, как можно использовать make и model в MultiIndex. Для этого набора данных вы также можете использовать столбец id в качестве индекса.
Установка столбца id в качестве индекса может быть полезна при связывании связанных наборов данных. Например, набор данных о выбросах EPA также использует id для представления регистрационных идентификаторов транспортных средств. Это связывает данные о выбросах с данными об экономии топлива. Сортировку индекса обоих наборов данных в DataFrames можно ускорить, используя другие методы, такие как .merge(). Чтобы узнать больше об объединении данных в pandas, ознакомьтесь с разделом Объединение данных в Pandas с помощью merge(), .join() и concat().
Сортировка столбцов вашего фрейма данных
Вы также можете использовать метки столбцов вашего фрейма данных для сортировки значений строк. Использование .sort_index() с необязательным параметром axis, равным 1, приведет к сортировке фрейма данных по меткам столбцов. Алгоритм сортировки применяется к меткам оси , а не к фактическим данным. Это может быть полезно для визуального контроля фрейма данных.
Работа с фреймворком данных axis
Когда вы используете .sort_index() без передачи каких-либо явных аргументов, он использует axis=0 в качестве аргумента по умолчанию. Ось фрейма данных относится либо к индексу (axis=0), либо к столбцам (axis=1). Вы можете использовать обе оси для индексации и выбора данных во фрейме данных, а также для сортировки данных.
Использование меток столбцов для сортировки
Вы также можете использовать метки столбцов фрейма данных в качестве ключа сортировки для .sort_index(). Установка значения axis на 1 сортирует столбцы вашего фрейма данных на основе меток столбцов:
>>> df.sort_index(axis=1)
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Y Automatic 3-spd 1993
96 17 6 Regular ... N Automatic 4-spd 1993
97 15 6 Regular ... N Automatic 4-spd 1993
98 15 6 Regular ... N Manual 5-spd 1993
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
Столбцы вашего фрейма данных сортируются слева направо в алфавитном порядке по возрастанию. Если вы хотите отсортировать столбцы в порядке убывания, вы можете использовать ascending=False:
>>> df.sort_index(axis=1, ascending=False)
year trany mpgData ... fuelType cylinders city08
0 1985 Manual 5-spd Y ... Regular 4 19
1 1985 Manual 5-spd N ... Regular 12 9
2 1985 Manual 5-spd Y ... Regular 4 23
3 1985 Automatic 3-spd N ... Regular 8 10
4 1993 Manual 5-spd N ... Premium 4 17
.. ... ... ... ... ... ... ...
95 1993 Automatic 3-spd Y ... Regular 6 17
96 1993 Automatic 4-spd N ... Regular 6 17
97 1993 Automatic 4-spd N ... Regular 6 15
98 1993 Manual 5-spd N ... Regular 6 15
99 1993 Automatic 4-spd N ... Premium 8 9
[100 rows x 10 columns]
Используя axis=1 в .sort_index(), вы отсортировали столбцы вашего фрейма данных как по возрастанию, так и по убыванию. Это может оказаться более полезным в других наборах данных, например, в том, в котором метки столбцов соответствуют месяцам года. В этом случае имеет смысл расположить данные в порядке возрастания или убывания по месяцам.
Работа с Отсутствующими Данными При Сортировке в Pandas
Часто реальные данные имеют много недостатков. Хотя в pandas есть несколько методов, которые вы можете использовать для очистки ваших данных перед сортировкой, иногда приятно посмотреть, какие данные отсутствуют во время сортировки. Вы можете сделать это с помощью параметра na_position.
В подмножестве данных об экономии топлива, используемых в этом руководстве, нет пропущенных значений. Чтобы проиллюстрировать использование na_position, сначала вам нужно создать некоторые недостающие данные. Следующий фрагмент кода создает новый столбец на основе существующего столбца mpgData, сопоставляя True, где mpgData равно Y и NaN где этого нет:
>>> df["mpgData_"] = df["mpgData"].map({"Y": True})
>>> df
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
1 9 12 Regular ... Manual 5-spd 1985 NaN
2 23 4 Regular ... Manual 5-spd 1985 True
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Automatic 3-spd 1993 True
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
[100 rows x 11 columns]
Теперь у вас есть новый столбец с именем mpgData_, который содержит значения True и NaN. Вы будете использовать этот столбец, чтобы увидеть, какой эффект дает na_position при использовании двух методов сортировки. Чтобы узнать больше об использовании .map(), вы можете прочитать Проект Pandas: Создание зачетной книжки с помощью Python и Pandas.
Понимание параметра na_position в .sort_values()
.sort_values() принимает параметр с именем na_position,, который помогает упорядочить отсутствующие данные в столбце, по которому выполняется сортировка. Если вы выполняете сортировку по столбцу с отсутствующими данными, то строки с отсутствующими значениями появятся в конце вашего фрейма данных. Это происходит независимо от того, выполняете ли вы сортировку по возрастанию или по убыванию.
Вот как выглядит ваш фрейм данных при сортировке по столбцу с отсутствующими данными:
>>> df.sort_values(by="mpgData_")
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
55 18 6 Regular ... Automatic 4-spd 1993 True
56 18 6 Regular ... Automatic 4-spd 1993 True
57 16 6 Premium ... Manual 5-spd 1993 True
59 17 6 Regular ... Automatic 4-spd 1993 True
.. ... ... ... ... ... ... ...
94 18 6 Regular ... Automatic 4-spd 1993 NaN
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
[100 rows x 11 columns]
Чтобы изменить это поведение и чтобы отсутствующие данные отображались первыми в вашем фрейме данных, вы можете установить для na_position значение first. Параметр na_position принимает только значения last, которые используются по умолчанию, и first. Вот как использовать na_postion в .sort_values():
>>> df.sort_values(
... by="mpgData_",
... na_position="first"
... )
city08 cylinders fuelType ... trany year mpgData_
1 9 12 Regular ... Manual 5-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
5 21 4 Regular ... Automatic 3-spd 1993 NaN
11 18 4 Regular ... Automatic 4-spd 1993 NaN
.. ... ... ... ... ... ... ...
32 15 8 Premium ... Automatic 4-spd 1993 True
33 15 8 Premium ... Automatic 4-spd 1993 True
37 17 6 Regular ... Automatic 3-spd 1993 True
85 17 6 Regular ... Automatic 4-spd 1993 True
95 17 6 Regular ... Automatic 3-spd 1993 True
[100 rows x 11 columns]
Теперь все отсутствующие данные из столбцов, по которым вы выполняли сортировку, будут отображаться в верхней части вашего фрейма данных. Это особенно полезно, когда вы только начинаете анализировать свои данные и не уверены, есть ли пропущенные значения.
Понимание параметра na_position в .sort_index()
.sort_index() также принимает na_position. Ваш фрейм данных обычно не будет содержать значений NaN в качестве части своего индекса, поэтому этот параметр менее полезен в .sort_index(). Однако полезно знать, что если в вашем фрейме данных есть NaN либо в индексе строки, либо в имени столбца, то вы можете быстро определить это, используя .sort_index() и na_position.
По умолчанию для этого параметра установлено значение last, что помещает значения NaN в конец отсортированного результата. Чтобы изменить это поведение и сначала ввести недостающие данные в ваш фрейм данных, установите для na_position значение first.
Использование методов сортировки для изменения вашего фрейма данных
Во всех примерах, которые вы видели до сих пор, как .sort_values(), так и .sort_index() возвращали объекты DataFrame при вызове этих методов. Это связано с тем, что сортировка в pandas по умолчанию не работает на месте. В целом, это наиболее распространенный и предпочтительный способ анализа ваших данных с помощью pandas, поскольку он создает новый фрейм данных вместо изменения исходного. Это позволяет вам сохранить состояние данных на момент их считывания из вашего файла.
Однако вы можете изменить исходный фрейм данных напрямую, указав необязательный параметр inplace со значением True. Большинство методов pandas включают параметр inplace. Ниже вы увидите несколько примеров использования inplace=True для сортировки вашего фрейма данных на месте.
Используя .sort_values() Вместо
Если для параметра inplace установлено значение True, вы изменяете исходный фрейм данных, поэтому методы сортировки возвращают None. Отсортируйте ваш фрейм данных по значениям столбца city08, как в самом первом примере, но для inplace задайте значение True:
>>> df.sort_values("city08", inplace=True)
Обратите внимание, что вызов .sort_values() не возвращает фрейм данных. Вот как выглядит исходный df:
>>> df
city08 cylinders fuelType ... trany year mpgData_
99 9 8 Premium ... Automatic 4-spd 1993 NaN
1 9 12 Regular ... Manual 5-spd 1985 NaN
80 9 8 Regular ... Automatic 3-spd 1985 NaN
47 9 8 Regular ... Automatic 3-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
.. ... ... ... ... ... ... ...
9 23 4 Regular ... Automatic 4-spd 1993 True
8 23 4 Regular ... Manual 5-spd 1993 True
7 23 4 Regular ... Automatic 3-spd 1993 True
76 23 4 Regular ... Manual 5-spd 1993 True
2 23 4 Regular ... Manual 5-spd 1985 True
[100 rows x 11 columns]
В объекте df значения теперь сортируются в порядке возрастания на основе столбца city08. Ваш исходный фрейм данных был изменен, и изменения сохранятся. Как правило, рекомендуется избегать использования inplace=True для анализа, поскольку изменения в вашем фрейме данных невозможно отменить.
Используя .sort_index() Вместо
Следующий пример иллюстрирует, что inplace также работает с .sort_index().
Поскольку индекс был создан в порядке возрастания при чтении вашего файла во фрейме данных, вы можете снова изменить свой объект df, чтобы вернуть его к первоначальному порядку. Используйте .sort_index() с inplace равным True, чтобы изменить фрейм данных:
>>> df.sort_index(inplace=True)
>>> df
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
1 9 12 Regular ... Manual 5-spd 1985 NaN
2 23 4 Regular ... Manual 5-spd 1985 True
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Automatic 3-spd 1993 True
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
[100 rows x 11 columns]
Теперь ваш фрейм данных снова изменен с использованием .sort_index(). Поскольку ваш фрейм данных по-прежнему имеет индекс по умолчанию, его сортировка по возрастанию возвращает данные в исходный порядок.
Если вы знакомы со встроенными функциями Python sort() и sorted(), то параметр inplace, доступный в методах сортировки pandas, может показаться вам очень похожим. Для получения дополнительной информации вы можете ознакомиться с Как использовать sorted() и .sort() в Python.
Заключение
Теперь вы знаете, как использовать два основных метода библиотеки pandas: .sort_values() и .sort_index(). Обладая этими знаниями, вы можете выполнять базовый анализ данных с помощью фрейма данных. Несмотря на то, что между этими двумя методами много общего, понимание разницы между ними позволяет понять, какой из них следует использовать для различных аналитических задач.
В этом руководстве вы узнали, как:
- Отсортировать Фрейм данных pandas по значениям одного или нескольких столбцов
- Используйте параметр
ascending, чтобы изменить порядок сортировки - Сортировка фрейма данных по его
indexс помощью.sort_index() - Упорядочивать недостающие данные при сортировке значений
- Отсортировать фрейм данных на месте, используя
inplaceзначениеTrue
Эти методы являются важной частью навыков анализа данных. Они помогут вам создать прочную основу, на которой вы сможете выполнять более сложные операции с pandas. Если вы хотите ознакомиться с некоторыми примерами более продвинутого использования методов сортировки pandas, то документация по pandas - отличный ресурс.
Back to Top