pandas: как читать и записывать файлы
Оглавление
- Установка панд
- Подготовка данных
- Использование функций pandas read_csv() и .to_csv()
- Использование pandas для записи и чтения файлов Excel
- Понимание работы pandas IO API
- Работа С Различными Типами Файлов
- Работа с Большими данными
- Заключение
pandas - это мощный и гибкий пакет на Python, который позволяет работать с помеченными данными и временными рядами. Он также предоставляет статистические методы, позволяет создавать графики и многое другое. Одной из важнейших особенностей pandas является его способность записывать и считывать файлы Excel, CSV и многие другие типы файлов. Функции, подобные методу pandas read_csv(), позволяют эффективно работать с файлами. Вы можете использовать их для сохранения данных и меток из объектов pandas в файл и последующей загрузки их как экземпляров pandas Series или DataFrame.
В этом уроке вы узнаете:
- Что такое Инструменты ввода-вывода pandas API
- Как считывать и записывать данные в файлы и из них
- Как работать с различными форматами файлов
- Как работать с большими данными эффективно
Давайте начнем читать и записывать файлы!
Установка pandas
Код, приведенный в этом руководстве, выполнен на CPython 3.7.4 и pandas 0.25.1. Было бы полезно убедиться, что на вашем компьютере установлены последние версии Python и pandas. Возможно, вам захочется создать новую виртуальную среду и установить зависимости для этого руководства.
Во-первых, вам понадобится библиотека pandas. Возможно, она у вас уже установлена. Если у вас ее нет, то вы можете установить ее с помощью pip:
$ pip install pandas
Как только процесс установки завершится, pandas будет установлен и готов к работе.
Anaconda - это отличный дистрибутив Python, который поставляется с Python, множеством полезных пакетов, таких как pandas, и менеджером пакетов и среды под названием Conda. Чтобы узнать больше об Anaconda, ознакомьтесь с разделом Настройка Python для машинного обучения в Windows.
Если в вашей виртуальной среде нет pandas, вы можете установить ее с помощью Conda:
$ conda install pandas
Conda эффективен, поскольку управляет зависимостями и их версиями. Чтобы узнать больше о работе с Conda, вы можете ознакомиться с официальной документацией .
Подготовка данных
В этом руководстве вы будете использовать данные, относящиеся к 20 странам. Вот обзор данных и источников, с которыми вы будете работать:
-
Страна обозначается названием страны. Каждая страна входит в топ-10 по численности населения, площади или валовому внутреннему продукту (ВВП). Метки строк для набора данных представляют собой трехбуквенные коды стран, определенные в стандарте ISO 3166-1. Метка столбца для набора данных выглядит следующим образом
COUNTRY. -
Численность населения выражается в миллионах человек. Данные взяты из списка стран и зависимых территорий с разбивкой по численности населения в Википедии. Метка столбца для набора данных выглядит следующим образом
POP. -
Площадь выражается в тысячах километров в квадрате. Данные взяты из списка стран и зависимых территорий по регионам в Википедии. Метка столбца для набора данных является
AREA. -
Согласно данным Организации Объединенных Наций за 2017 год, валовой внутренний продукт выражается в миллионах долларов США. Вы можете найти эти данные в списке стран по номинальному ВВП на странице Википедии. Заголовок столбца для набора данных выглядит следующим образом
GDP. -
Континент - это либо Африка, либо Азия, либо Океания, либо Европа, либо Северная Америка, либо Южная Америка. Вы также можете найти эту информацию в Википедии. Метка столбца для набора данных выглядит следующим образом
CONT. -
День независимости - это дата, отмечающая независимость страны. Данные взяты из списка дней национальной независимости в Википедии. Даты указаны в формате ISO 8601. Первые четыре цифры обозначают год, следующие два числа - месяц, а последние два - день месяца. В качестве метки столбца для набора данных используется
IND_DAY.
Вот как данные выглядят в виде таблицы:
| COUNTRY | POP | AREA | GDP | CONT | IND_DAY | |
|---|---|---|---|---|---|---|
| CHN | China | 1398.72 | 9596.96 | 12234.78 | Asia | |
| IND | India | 1351.16 | 3287.26 | 2575.67 | Asia | 1947-08-15 |
| USA | US | 329.74 | 9833.52 | 19485.39 | N.America | 1776-07-04 |
| IDN | Indonesia | 268.07 | 1910.93 | 1015.54 | Asia | 1945-08-17 |
| BRA | Brazil | 210.32 | 8515.77 | 2055.51 | S.America | 1822-09-07 |
| PAK | Pakistan | 205.71 | 881.91 | 302.14 | Asia | 1947-08-14 |
| NGA | Nigeria | 200.96 | 923.77 | 375.77 | Africa | 1960-10-01 |
| BGD | Bangladesh | 167.09 | 147.57 | 245.63 | Asia | 1971-03-26 |
| RUS | Russia | 146.79 | 17098.25 | 1530.75 | 1992-06-12 | |
| MEX | Mexico | 126.58 | 1964.38 | 1158.23 | N.America | 1810-09-16 |
| JPN | Japan | 126.22 | 377.97 | 4872.42 | Asia | |
| DEU | Germany | 83.02 | 357.11 | 3693.20 | Europe | |
| FRA | France | 67.02 | 640.68 | 2582.49 | Europe | 1789-07-14 |
| GBR | UK | 66.44 | 242.50 | 2631.23 | Europe | |
| ITA | Italy | 60.36 | 301.34 | 1943.84 | Europe | |
| ARG | Argentina | 44.94 | 2780.40 | 637.49 | S.America | 1816-07-09 |
| DZA | Algeria | 43.38 | 2381.74 | 167.56 | Africa | 1962-07-05 |
| CAN | Canada | 37.59 | 9984.67 | 1647.12 | N.America | 1867-07-01 |
| AUS | Australia | 25.47 | 7692.02 | 1408.68 | Oceania | |
| KAZ | Kazakhstan | 18.53 | 2724.90 | 159.41 | Asia | 1991-12-16 |
Вы можете заметить, что некоторые данные отсутствуют. Например, континент для России не указан, поскольку он охватывает как Европу, так и Азию. Также пропущено несколько дней независимости, поскольку источник данных не содержит их.
Вы можете упорядочить эти данные на Python, используя вложенный словарь :
data = {
'CHN': {'COUNTRY': 'China', 'POP': 1_398.72, 'AREA': 9_596.96,
'GDP': 12_234.78, 'CONT': 'Asia'},
'IND': {'COUNTRY': 'India', 'POP': 1_351.16, 'AREA': 3_287.26,
'GDP': 2_575.67, 'CONT': 'Asia', 'IND_DAY': '1947-08-15'},
'USA': {'COUNTRY': 'US', 'POP': 329.74, 'AREA': 9_833.52,
'GDP': 19_485.39, 'CONT': 'N.America',
'IND_DAY': '1776-07-04'},
'IDN': {'COUNTRY': 'Indonesia', 'POP': 268.07, 'AREA': 1_910.93,
'GDP': 1_015.54, 'CONT': 'Asia', 'IND_DAY': '1945-08-17'},
'BRA': {'COUNTRY': 'Brazil', 'POP': 210.32, 'AREA': 8_515.77,
'GDP': 2_055.51, 'CONT': 'S.America', 'IND_DAY': '1822-09-07'},
'PAK': {'COUNTRY': 'Pakistan', 'POP': 205.71, 'AREA': 881.91,
'GDP': 302.14, 'CONT': 'Asia', 'IND_DAY': '1947-08-14'},
'NGA': {'COUNTRY': 'Nigeria', 'POP': 200.96, 'AREA': 923.77,
'GDP': 375.77, 'CONT': 'Africa', 'IND_DAY': '1960-10-01'},
'BGD': {'COUNTRY': 'Bangladesh', 'POP': 167.09, 'AREA': 147.57,
'GDP': 245.63, 'CONT': 'Asia', 'IND_DAY': '1971-03-26'},
'RUS': {'COUNTRY': 'Russia', 'POP': 146.79, 'AREA': 17_098.25,
'GDP': 1_530.75, 'IND_DAY': '1992-06-12'},
'MEX': {'COUNTRY': 'Mexico', 'POP': 126.58, 'AREA': 1_964.38,
'GDP': 1_158.23, 'CONT': 'N.America', 'IND_DAY': '1810-09-16'},
'JPN': {'COUNTRY': 'Japan', 'POP': 126.22, 'AREA': 377.97,
'GDP': 4_872.42, 'CONT': 'Asia'},
'DEU': {'COUNTRY': 'Germany', 'POP': 83.02, 'AREA': 357.11,
'GDP': 3_693.20, 'CONT': 'Europe'},
'FRA': {'COUNTRY': 'France', 'POP': 67.02, 'AREA': 640.68,
'GDP': 2_582.49, 'CONT': 'Europe', 'IND_DAY': '1789-07-14'},
'GBR': {'COUNTRY': 'UK', 'POP': 66.44, 'AREA': 242.50,
'GDP': 2_631.23, 'CONT': 'Europe'},
'ITA': {'COUNTRY': 'Italy', 'POP': 60.36, 'AREA': 301.34,
'GDP': 1_943.84, 'CONT': 'Europe'},
'ARG': {'COUNTRY': 'Argentina', 'POP': 44.94, 'AREA': 2_780.40,
'GDP': 637.49, 'CONT': 'S.America', 'IND_DAY': '1816-07-09'},
'DZA': {'COUNTRY': 'Algeria', 'POP': 43.38, 'AREA': 2_381.74,
'GDP': 167.56, 'CONT': 'Africa', 'IND_DAY': '1962-07-05'},
'CAN': {'COUNTRY': 'Canada', 'POP': 37.59, 'AREA': 9_984.67,
'GDP': 1_647.12, 'CONT': 'N.America', 'IND_DAY': '1867-07-01'},
'AUS': {'COUNTRY': 'Australia', 'POP': 25.47, 'AREA': 7_692.02,
'GDP': 1_408.68, 'CONT': 'Oceania'},
'KAZ': {'COUNTRY': 'Kazakhstan', 'POP': 18.53, 'AREA': 2_724.90,
'GDP': 159.41, 'CONT': 'Asia', 'IND_DAY': '1991-12-16'}
}
columns = ('COUNTRY', 'POP', 'AREA', 'GDP', 'CONT', 'IND_DAY')
Каждая строка таблицы записывается как внутренний словарь, ключами которого являются имена столбцов, а значениями - соответствующие данные. Затем эти словари собираются как значения во внешнем словаре data. Соответствующие клавиши для data - это трехбуквенные коды стран.
Вы можете использовать это data для создания экземпляра панды DataFrame. Во-первых, вам нужно импортировать панд:
>>> import pandas as pd
Теперь, когда вы импортировали панд, вы можете использовать DataFrame конструктор и data для создания объекта DataFrame.
data он организован таким образом, что коды стран соответствуют столбцам. Вы можете перевернуть строки и столбцы DataFrame с помощью свойства .T:
>>> df = pd.DataFrame(data=data).T
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.8 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.4 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.2 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.2 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.5 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.4 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.9 159.41 Asia 1991-12-16
Теперь у вас есть свой объект DataFrame, заполненный данными о каждой стране.
Примечание: Вы можете использовать .transpose() вместо .T, чтобы поменять местами строки и столбцы вашего набора данных. Если вы используете .transpose(), то вы можете задать необязательный параметр copy, чтобы указать, хотите ли вы скопировать базовые данные. По умолчанию используется следующий параметр False.
В версиях Python старше 3.6 порядок ключей в словарях не гарантировался. Чтобы обеспечить сохранение порядка столбцов в более старых версиях Python и pandas, вы можете указать index=columns:
>>> df = pd.DataFrame(data=data, index=columns).T
Теперь, когда вы подготовили свои данные, вы готовы приступить к работе с файлами!
Использование функций pandas read_csv() и .to_csv()
Файл значений, разделенных запятыми (CSV) - это обычный текстовый файл с расширением .csv, содержащий табличные данные. Это один из самых популярных форматов файлов для хранения больших объемов данных. Каждая строка CSV-файла представляет собой отдельную строку таблицы. Значения в одной строке по умолчанию разделены запятыми, но вы можете заменить разделитель на точку с запятой, табуляцию, пробел или какой-либо другой символ.
Записать CSV-файл
Вы можете сохранить своих панд DataFrame в виде CSV-файла с .to_csv():
>>> df.to_csv('data.csv')
Вот и все! Вы создали файл data.csv в своем текущем рабочем каталоге. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть, как должен выглядеть ваш CSV-файл:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,,1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
Этот текстовый файл содержит данные, разделенные запятыми. В первом столбце указаны названия строк. В некоторых случаях они могут показаться вам неуместными. Если вы не хотите их сохранять, то вы можете передать аргумент index=False в .to_csv().
Чтение CSV-файла
Как только ваши данные будут сохранены в CSV-файле, вы, скорее всего, захотите время от времени загружать их и использовать. Вы можете сделать это с помощью функции pandas read_csv():
>>> df = pd.read_csv('data.csv', index_col=0)
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
В этом случае функция pandas read_csv() возвращает новый DataFrame с данными и метками из файла data.csv, который вы указали в первом аргументе. Этой строкой может быть любой допустимый путь, включая URL-адреса.
Параметр index_col указывает столбец из CSV-файла, содержащий метки строк. Этому параметру присваивается индекс столбца, основанный на нуле. Вам следует определить значение index_col, когда CSV-файл содержит метки строк, чтобы избежать их загрузки в качестве данных.
Вы узнаете больше об использовании pandas с CSV-файлами далее в этом руководстве. Вы также можете ознакомиться с Чтение и запись CSV-файлов в Python, чтобы узнать, как обрабатывать CSV-файлы с помощью встроенной библиотеки Python csv.
Использование pandas для записи и чтения файлов Excel
Microsoft Excel, вероятно, является наиболее широко используемой программой для работы с электронными таблицами. В то время как в более старых версиях использовались двоичные .xls файлы, в Excel 2007 появился новый .xlsx файл на основе XML. Вы можете читать и записывать файлы Excel в pandas, аналогично файлам CSV. Однако сначала вам потребуется установить следующие пакеты Python:
- xlwt для записи в
.xlsфайлы - откройте pyxl или XlsxWriter для записи в
.xlsxфайлы - xlrd для чтения файлов Excel
Вы можете установить их с помощью pip с помощью одной команды:
$ pip install xlwt openpyxl xlsxwriter xlrd
Вы также можете использовать Conda:
$ conda install xlwt openpyxl xlsxwriter xlrd
Пожалуйста, обратите внимание, что вам не обязательно устанавливать все эти пакеты. Например, вам не нужны ни openpyxl, ни XlsxWriter. Если вы собираетесь работать только с файлами .xls, то вам не нужен ни один из них! Однако, если вы собираетесь работать только с .xlsx файлами, то вам понадобится хотя бы один из них, но не с xlwt. Потратьте некоторое время на то, чтобы решить, какие пакеты подходят для вашего проекта.
Записать файл Excel
Как только вы установите эти пакеты, вы можете сохранить свой DataFrame в файле Excel с .to_excel():
>>> df.to_excel('data.xlsx')
Аргумент 'data.xlsx' представляет целевой файл и, необязательно, путь к нему. Приведенная выше инструкция должна создать файл data.xlsx в вашем текущем рабочем каталоге. Этот файл должен выглядеть следующим образом:
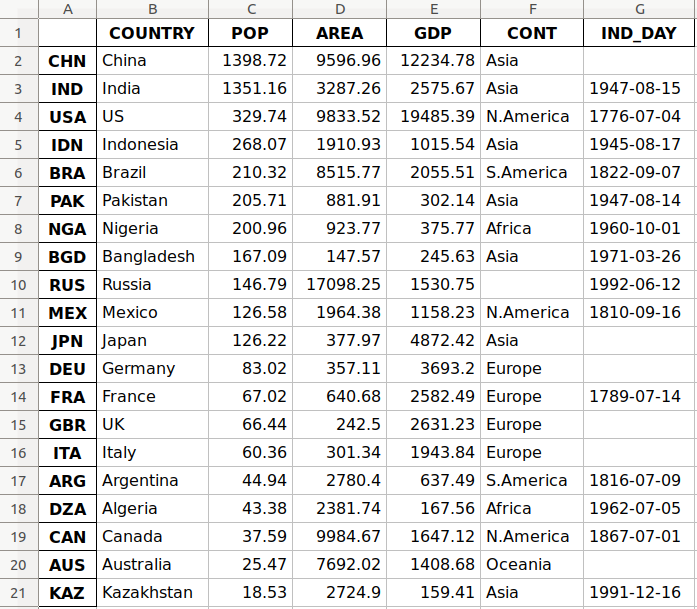
Первый столбец файла содержит названия строк, в то время как в других столбцах хранятся данные.
Чтение файла Excel
Вы можете загружать данные из файлов Excel с помощью read_excel():
>>> df = pd.read_excel('data.xlsx', index_col=0)
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
read_excel() возвращает новый DataFrame, содержащий значения из data.xlsx. Вы также можете использовать read_excel() с электронными таблицами OpenDocument или .ods файлами.
Вы узнаете больше о работе с файлами Excel далее в этом руководстве. Вы также можете ознакомиться с Использование pandas для чтения больших файлов Excel на Python.
Понимание API ввода-вывода pandas
pandas IO Tools - это API, который позволяет сохранять содержимое объектов Series и DataFrame в буфер обмена, объекты или файлы различных типов. Это также позволяет загружать данные из буфера обмена, объектов или файлов.
Запись файлов
Series и DataFrame объекты имеют методы, которые позволяют записывать данные и метки в буфер обмена или файлы. Они называются по шаблону .to_<file-type>(),, где <file-type> - это тип целевого файла.
Вы узнали о .to_csv() и .to_excel(), но есть и другие, в том числе:
.to_json().to_html().to_sql().to_pickle()
Существует еще больше типов файлов, в которые вы можете выполнять запись, поэтому этот список не является исчерпывающим.
Примечание: Чтобы найти похожие методы, ознакомьтесь с официальной документацией о сериализации, вводе-выводе и преобразовании, относящихся к объектам Series и DataFrame.
У этих методов есть параметры, указывающие путь к целевому файлу, в котором вы сохранили данные и метки. В некоторых случаях это обязательно, а в других - необязательно. Если этот параметр доступен и вы решили его не использовать, то методы возвращают объекты (например, строки или повторяющиеся значения) с содержимым экземпляров DataFrame.
Необязательный параметр compression определяет, как сжать файл с данными и метками. Подробнее об этом вы узнаете позже. Есть еще несколько параметров, но в основном они относятся к одному или нескольким методам. Здесь вы не будете вдаваться в подробности.
Чтение файлов
функции pandas для чтения содержимого файлов называются по шаблону .read_<file-type>(),, где <file-type> указывает на тип файла для чтения. Вы уже видели функции pandas read_csv() и read_excel(). Вот еще несколько функций:
read_json()read_html()read_sql()read_pickle()
У этих функций есть параметр, который указывает путь к целевому файлу. Это может быть любая допустимая строка, представляющая путь, как на локальном компьютере, так и в URL-адресе. Другие объекты также допустимы в зависимости от типа файла.
Необязательный параметр compression определяет тип распаковки, который будет использоваться для сжатых файлов. Вы узнаете об этом позже в этом руководстве. Существуют и другие параметры, но они специфичны для одной или нескольких функций. Здесь вы не будете вдаваться в подробности.
Работа с Различными Типами Файлов
Библиотека pandas предлагает широкий спектр возможностей для сохранения ваших данных в файлах и загрузки данных из файлов. В этом разделе вы узнаете больше о работе с файлами CSV и Excel. Вы также увидите, как использовать другие типы файлов, такие как JSON, веб-страницы, базы данных и файлы Python pickle.
CSV-файлы
Вы уже научились читать и записывать CSV-файлы. Теперь давайте немного углубимся в детали. Когда вы используете .to_csv() для сохранения вашего DataFrame, вы можете указать аргумент для параметра path_or_buf, чтобы указать путь, имя и расширение целевого файла.
path_or_buf это первый аргумент, который получит .to_csv(). Это может быть любая строка, представляющая допустимый путь к файлу, включающий имя файла и его расширение. Вы видели это в предыдущем примере. Однако, если вы опустите path_or_buf, то .to_csv() не создаст никаких файлов. Вместо этого он вернет соответствующую строку:
>>> df = pd.DataFrame(data=data).T
>>> s = df.to_csv()
>>> print(s)
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,,1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
Теперь у вас есть строка s вместо файла CSV. У вас также есть некоторые пропущенные значения в вашем DataFrame объекте. Например, континент для России и дни независимости для нескольких стран (Китая, Японии и т.д.) недоступны. В области обработки данных и машинного обучения необходимо тщательно обрабатывать пропущенные значения. Здесь pandas превосходен! По умолчанию pandas использует значение NaN для замены отсутствующих значений.
Обратите внимание, что: nan,, что означает “не число”, является конкретным значением с плавающей запятой в Python.
Вы можете получить значение nan с помощью любой из следующих функций:
Континентом, который соответствует России в df, является nan:
>>> df.loc['RUS', 'CONT']
nan
В этом примере используется .loc[] для получения данных с указанными именами строк и столбцов.
Когда вы сохраняете свой DataFrame в CSV-файл, пустые строки ('') будут представлять недостающие данные. Вы можете увидеть это как в вашем файле data.csv, так и в строке s. Если вы хотите изменить это поведение, используйте необязательный параметр na_rep:
>>> df.to_csv('new-data.csv', na_rep='(missing)')
Этот код создает файл new-data.csv, в котором пропущенные значения больше не являются пустыми строками. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть, как должен выглядеть этот файл:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,(missing)
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,(missing),1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,(missing)
DEU,Germany,83.02,357.11,3693.2,Europe,(missing)
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,(missing)
ITA,Italy,60.36,301.34,1943.84,Europe,(missing)
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,(missing)
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
Теперь строка '(missing)' в файле соответствует значениям nan из df.
Когда pandas читает файлы, он по умолчанию рассматривает пустую строку ('') и несколько других как пропущенные значения:
'nan''-nan''NA''N/A''NaN''null'
Если вы не хотите такого поведения, то вы можете передать keep_default_na=False функции pandas read_csv(). Чтобы указать другие метки для пропущенных значений, используйте параметр na_values:
>>> pd.read_csv('new-data.csv', index_col=0, na_values='(missing)')
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
Здесь вы пометили строку '(missing)' как новую метку отсутствующих данных, и pandas заменил ее на nan при чтении файла.
Когда вы загружаете данные из файла, pandas по умолчанию присваивает значениям каждого столбца типы данных . Вы можете проверить эти типы с помощью .dtypes:
>>> df = pd.read_csv('data.csv', index_col=0)
>>> df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY object
dtype: object
Столбцы со строками и датами ('COUNTRY', 'CONT', и 'IND_DAY') имеют тип данных object. Между тем, числовые столбцы содержат 64-разрядные числа с плавающей запятой (float64).
Вы можете использовать параметр dtype для указания желаемых типов данных и parse_dates для принудительного использования дат и времени:
>>> dtypes = {'POP': 'float32', 'AREA': 'float32', 'GDP': 'float32'}
>>> df = pd.read_csv('data.csv', index_col=0, dtype=dtypes,
... parse_dates=['IND_DAY'])
>>> df.dtypes
COUNTRY object
POP float32
AREA float32
GDP float32
CONT object
IND_DAY datetime64[ns]
dtype: object
>>> df['IND_DAY']
CHN NaT
IND 1947-08-15
USA 1776-07-04
IDN 1945-08-17
BRA 1822-09-07
PAK 1947-08-14
NGA 1960-10-01
BGD 1971-03-26
RUS 1992-06-12
MEX 1810-09-16
JPN NaT
DEU NaT
FRA 1789-07-14
GBR NaT
ITA NaT
ARG 1816-07-09
DZA 1962-07-05
CAN 1867-07-01
AUS NaT
KAZ 1991-12-16
Name: IND_DAY, dtype: datetime64[ns]
Теперь у вас есть 32-разрядные числа с плавающей запятой (float32), как указано в dtype. Они немного отличаются от исходных 64-разрядных чисел из-за меньшей точности . Значения в последнем столбце считаются датами и имеют тип данных datetime64. Вот почему значения NaN в этом столбце заменяются на NaT.
Теперь, когда у вас есть реальные даты, вы можете сохранить их в удобном вам формате:
>>> df = pd.read_csv('data.csv', index_col=0, parse_dates=['IND_DAY'])
>>> df.to_csv('formatted-data.csv', date_format='%B %d, %Y')
Здесь вы указали для параметра date_format значение '%B %d, %Y'. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть результирующий файл:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,"August 15, 1947"
USA,US,329.74,9833.52,19485.39,N.America,"July 04, 1776"
IDN,Indonesia,268.07,1910.93,1015.54,Asia,"August 17, 1945"
BRA,Brazil,210.32,8515.77,2055.51,S.America,"September 07, 1822"
PAK,Pakistan,205.71,881.91,302.14,Asia,"August 14, 1947"
NGA,Nigeria,200.96,923.77,375.77,Africa,"October 01, 1960"
BGD,Bangladesh,167.09,147.57,245.63,Asia,"March 26, 1971"
RUS,Russia,146.79,17098.25,1530.75,,"June 12, 1992"
MEX,Mexico,126.58,1964.38,1158.23,N.America,"September 16, 1810"
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,"July 14, 1789"
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,"July 09, 1816"
DZA,Algeria,43.38,2381.74,167.56,Africa,"July 05, 1962"
CAN,Canada,37.59,9984.67,1647.12,N.America,"July 01, 1867"
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,"December 16, 1991"
Формат дат теперь другой. Формат '%B %d, %Y' означает, что сначала в дате будет отображаться полное название месяца, затем день, за которым следует запятая, и, наконец, полный год.
Есть несколько других необязательных параметров, которые вы можете использовать с .to_csv():
sepобозначает разделитель значений.decimalуказывает десятичный разделитель.encodingустанавливает кодировку файла.headerуказывает, хотите ли вы записывать метки столбцов в файл.
Вот как вы могли бы передать аргументы для sep и header:
>>> s = df.to_csv(sep=';', header=False)
>>> print(s)
CHN;China;1398.72;9596.96;12234.78;Asia;
IND;India;1351.16;3287.26;2575.67;Asia;1947-08-15
USA;US;329.74;9833.52;19485.39;N.America;1776-07-04
IDN;Indonesia;268.07;1910.93;1015.54;Asia;1945-08-17
BRA;Brazil;210.32;8515.77;2055.51;S.America;1822-09-07
PAK;Pakistan;205.71;881.91;302.14;Asia;1947-08-14
NGA;Nigeria;200.96;923.77;375.77;Africa;1960-10-01
BGD;Bangladesh;167.09;147.57;245.63;Asia;1971-03-26
RUS;Russia;146.79;17098.25;1530.75;;1992-06-12
MEX;Mexico;126.58;1964.38;1158.23;N.America;1810-09-16
JPN;Japan;126.22;377.97;4872.42;Asia;
DEU;Germany;83.02;357.11;3693.2;Europe;
FRA;France;67.02;640.68;2582.49;Europe;1789-07-14
GBR;UK;66.44;242.5;2631.23;Europe;
ITA;Italy;60.36;301.34;1943.84;Europe;
ARG;Argentina;44.94;2780.4;637.49;S.America;1816-07-09
DZA;Algeria;43.38;2381.74;167.56;Africa;1962-07-05
CAN;Canada;37.59;9984.67;1647.12;N.America;1867-07-01
AUS;Australia;25.47;7692.02;1408.68;Oceania;
KAZ;Kazakhstan;18.53;2724.9;159.41;Asia;1991-12-16
Данные разделяются точкой с запятой (';'), поскольку вы указали sep=';'. Кроме того, поскольку вы передали header=False, вы видите свои данные без строки заголовка с именами столбцов.
Функция pandas read_csv() имеет множество дополнительных опций для управления отсутствующими данными, работы с датами и временем, цитирования, кодирования, обработки ошибок и многого другого. Например, если у вас есть файл с одним столбцом данных и вы хотите получить объект Series вместо DataFrame, то вы можете передать squeeze=True в read_csv(). Позже вы узнаете о сжатии и распаковке данных, а также о том, как пропускать строки и столбцы.
JSON-файлы
JSON расшифровывается как объектная нотация JavaScript. Файлы JSON - это текстовые файлы, используемые для обмена данными, и люди могут легко их прочитать. Они соответствуют стандартам ISO/IEC 21778:2017 и ECMA-404 и используют расширение .json. Python и pandas хорошо работают с файлами JSON, поскольку библиотека Python json предлагает встроенную поддержку для них.
Вы можете сохранить данные из вашего DataFrame в файл JSON с помощью .to_json(). Начните с повторного создания объекта DataFrame. Воспользуйтесь словарем data, содержащим данные о странах, а затем примените .to_json():
>>> df = pd.DataFrame(data=data).T
>>> df.to_json('data-columns.json')
Этот код создает файл data-columns.json. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть, как должен выглядеть этот файл:
{"COUNTRY":{"CHN":"China","IND":"India","USA":"US","IDN":"Indonesia","BRA":"Brazil","PAK":"Pakistan","NGA":"Nigeria","BGD":"Bangladesh","RUS":"Russia","MEX":"Mexico","JPN":"Japan","DEU":"Germany","FRA":"France","GBR":"UK","ITA":"Italy","ARG":"Argentina","DZA":"Algeria","CAN":"Canada","AUS":"Australia","KAZ":"Kazakhstan"},"POP":{"CHN":1398.72,"IND":1351.16,"USA":329.74,"IDN":268.07,"BRA":210.32,"PAK":205.71,"NGA":200.96,"BGD":167.09,"RUS":146.79,"MEX":126.58,"JPN":126.22,"DEU":83.02,"FRA":67.02,"GBR":66.44,"ITA":60.36,"ARG":44.94,"DZA":43.38,"CAN":37.59,"AUS":25.47,"KAZ":18.53},"AREA":{"CHN":9596.96,"IND":3287.26,"USA":9833.52,"IDN":1910.93,"BRA":8515.77,"PAK":881.91,"NGA":923.77,"BGD":147.57,"RUS":17098.25,"MEX":1964.38,"JPN":377.97,"DEU":357.11,"FRA":640.68,"GBR":242.5,"ITA":301.34,"ARG":2780.4,"DZA":2381.74,"CAN":9984.67,"AUS":7692.02,"KAZ":2724.9},"GDP":{"CHN":12234.78,"IND":2575.67,"USA":19485.39,"IDN":1015.54,"BRA":2055.51,"PAK":302.14,"NGA":375.77,"BGD":245.63,"RUS":1530.75,"MEX":1158.23,"JPN":4872.42,"DEU":3693.2,"FRA":2582.49,"GBR":2631.23,"ITA":1943.84,"ARG":637.49,"DZA":167.56,"CAN":1647.12,"AUS":1408.68,"KAZ":159.41},"CONT":{"CHN":"Asia","IND":"Asia","USA":"N.America","IDN":"Asia","BRA":"S.America","PAK":"Asia","NGA":"Africa","BGD":"Asia","RUS":null,"MEX":"N.America","JPN":"Asia","DEU":"Europe","FRA":"Europe","GBR":"Europe","ITA":"Europe","ARG":"S.America","DZA":"Africa","CAN":"N.America","AUS":"Oceania","KAZ":"Asia"},"IND_DAY":{"CHN":null,"IND":"1947-08-15","USA":"1776-07-04","IDN":"1945-08-17","BRA":"1822-09-07","PAK":"1947-08-14","NGA":"1960-10-01","BGD":"1971-03-26","RUS":"1992-06-12","MEX":"1810-09-16","JPN":null,"DEU":null,"FRA":"1789-07-14","GBR":null,"ITA":null,"ARG":"1816-07-09","DZA":"1962-07-05","CAN":"1867-07-01","AUS":null,"KAZ":"1991-12-16"}}
data-columns.json имеет один большой словарь с метками столбцов в качестве ключей и соответствующими внутренними словарями в качестве значений.
Вы можете получить другую структуру файла, если передадите аргумент для необязательного параметра orient:
>>> df.to_json('data-index.json', orient='index')
Параметр orient по умолчанию имеет значение 'columns'. Здесь вы установили для него значение index.
У вас должен появиться новый файл data-index.json. Вы можете развернуть блок кода ниже, чтобы увидеть изменения:
{"CHN":{"COUNTRY":"China","POP":1398.72,"AREA":9596.96,"GDP":12234.78,"CONT":"Asia","IND_DAY":null},"IND":{"COUNTRY":"India","POP":1351.16,"AREA":3287.26,"GDP":2575.67,"CONT":"Asia","IND_DAY":"1947-08-15"},"USA":{"COUNTRY":"US","POP":329.74,"AREA":9833.52,"GDP":19485.39,"CONT":"N.America","IND_DAY":"1776-07-04"},"IDN":{"COUNTRY":"Indonesia","POP":268.07,"AREA":1910.93,"GDP":1015.54,"CONT":"Asia","IND_DAY":"1945-08-17"},"BRA":{"COUNTRY":"Brazil","POP":210.32,"AREA":8515.77,"GDP":2055.51,"CONT":"S.America","IND_DAY":"1822-09-07"},"PAK":{"COUNTRY":"Pakistan","POP":205.71,"AREA":881.91,"GDP":302.14,"CONT":"Asia","IND_DAY":"1947-08-14"},"NGA":{"COUNTRY":"Nigeria","POP":200.96,"AREA":923.77,"GDP":375.77,"CONT":"Africa","IND_DAY":"1960-10-01"},"BGD":{"COUNTRY":"Bangladesh","POP":167.09,"AREA":147.57,"GDP":245.63,"CONT":"Asia","IND_DAY":"1971-03-26"},"RUS":{"COUNTRY":"Russia","POP":146.79,"AREA":17098.25,"GDP":1530.75,"CONT":null,"IND_DAY":"1992-06-12"},"MEX":{"COUNTRY":"Mexico","POP":126.58,"AREA":1964.38,"GDP":1158.23,"CONT":"N.America","IND_DAY":"1810-09-16"},"JPN":{"COUNTRY":"Japan","POP":126.22,"AREA":377.97,"GDP":4872.42,"CONT":"Asia","IND_DAY":null},"DEU":{"COUNTRY":"Germany","POP":83.02,"AREA":357.11,"GDP":3693.2,"CONT":"Europe","IND_DAY":null},"FRA":{"COUNTRY":"France","POP":67.02,"AREA":640.68,"GDP":2582.49,"CONT":"Europe","IND_DAY":"1789-07-14"},"GBR":{"COUNTRY":"UK","POP":66.44,"AREA":242.5,"GDP":2631.23,"CONT":"Europe","IND_DAY":null},"ITA":{"COUNTRY":"Italy","POP":60.36,"AREA":301.34,"GDP":1943.84,"CONT":"Europe","IND_DAY":null},"ARG":{"COUNTRY":"Argentina","POP":44.94,"AREA":2780.4,"GDP":637.49,"CONT":"S.America","IND_DAY":"1816-07-09"},"DZA":{"COUNTRY":"Algeria","POP":43.38,"AREA":2381.74,"GDP":167.56,"CONT":"Africa","IND_DAY":"1962-07-05"},"CAN":{"COUNTRY":"Canada","POP":37.59,"AREA":9984.67,"GDP":1647.12,"CONT":"N.America","IND_DAY":"1867-07-01"},"AUS":{"COUNTRY":"Australia","POP":25.47,"AREA":7692.02,"GDP":1408.68,"CONT":"Oceania","IND_DAY":null},"KAZ":{"COUNTRY":"Kazakhstan","POP":18.53,"AREA":2724.9,"GDP":159.41,"CONT":"Asia","IND_DAY":"1991-12-16"}}
data-index.json также есть один большой словарь, но на этот раз метки строк являются ключами, а внутренние словари - значениями.
Есть еще несколько вариантов для orient. Одним из них является 'records':
>>> df.to_json('data-records.json', orient='records')
Этот код должен привести к файлу data-records.json. Вы можете развернуть блок кода ниже, чтобы увидеть содержимое:
[{"COUNTRY":"China","POP":1398.72,"AREA":9596.96,"GDP":12234.78,"CONT":"Asia","IND_DAY":null},{"COUNTRY":"India","POP":1351.16,"AREA":3287.26,"GDP":2575.67,"CONT":"Asia","IND_DAY":"1947-08-15"},{"COUNTRY":"US","POP":329.74,"AREA":9833.52,"GDP":19485.39,"CONT":"N.America","IND_DAY":"1776-07-04"},{"COUNTRY":"Indonesia","POP":268.07,"AREA":1910.93,"GDP":1015.54,"CONT":"Asia","IND_DAY":"1945-08-17"},{"COUNTRY":"Brazil","POP":210.32,"AREA":8515.77,"GDP":2055.51,"CONT":"S.America","IND_DAY":"1822-09-07"},{"COUNTRY":"Pakistan","POP":205.71,"AREA":881.91,"GDP":302.14,"CONT":"Asia","IND_DAY":"1947-08-14"},{"COUNTRY":"Nigeria","POP":200.96,"AREA":923.77,"GDP":375.77,"CONT":"Africa","IND_DAY":"1960-10-01"},{"COUNTRY":"Bangladesh","POP":167.09,"AREA":147.57,"GDP":245.63,"CONT":"Asia","IND_DAY":"1971-03-26"},{"COUNTRY":"Russia","POP":146.79,"AREA":17098.25,"GDP":1530.75,"CONT":null,"IND_DAY":"1992-06-12"},{"COUNTRY":"Mexico","POP":126.58,"AREA":1964.38,"GDP":1158.23,"CONT":"N.America","IND_DAY":"1810-09-16"},{"COUNTRY":"Japan","POP":126.22,"AREA":377.97,"GDP":4872.42,"CONT":"Asia","IND_DAY":null},{"COUNTRY":"Germany","POP":83.02,"AREA":357.11,"GDP":3693.2,"CONT":"Europe","IND_DAY":null},{"COUNTRY":"France","POP":67.02,"AREA":640.68,"GDP":2582.49,"CONT":"Europe","IND_DAY":"1789-07-14"},{"COUNTRY":"UK","POP":66.44,"AREA":242.5,"GDP":2631.23,"CONT":"Europe","IND_DAY":null},{"COUNTRY":"Italy","POP":60.36,"AREA":301.34,"GDP":1943.84,"CONT":"Europe","IND_DAY":null},{"COUNTRY":"Argentina","POP":44.94,"AREA":2780.4,"GDP":637.49,"CONT":"S.America","IND_DAY":"1816-07-09"},{"COUNTRY":"Algeria","POP":43.38,"AREA":2381.74,"GDP":167.56,"CONT":"Africa","IND_DAY":"1962-07-05"},{"COUNTRY":"Canada","POP":37.59,"AREA":9984.67,"GDP":1647.12,"CONT":"N.America","IND_DAY":"1867-07-01"},{"COUNTRY":"Australia","POP":25.47,"AREA":7692.02,"GDP":1408.68,"CONT":"Oceania","IND_DAY":null},{"COUNTRY":"Kazakhstan","POP":18.53,"AREA":2724.9,"GDP":159.41,"CONT":"Asia","IND_DAY":"1991-12-16"}]
data-records.json содержит список с одним словарем для каждой строки. Метки строк не записаны.
Вы можете получить еще одну интересную файловую структуру с помощью orient='split':
>>> df.to_json('data-split.json', orient='split')
Результирующий файл будет иметь вид data-split.json. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть, как должен выглядеть этот файл:
{"columns":["COUNTRY","POP","AREA","GDP","CONT","IND_DAY"],"index":["CHN","IND","USA","IDN","BRA","PAK","NGA","BGD","RUS","MEX","JPN","DEU","FRA","GBR","ITA","ARG","DZA","CAN","AUS","KAZ"],"data":[["China",1398.72,9596.96,12234.78,"Asia",null],["India",1351.16,3287.26,2575.67,"Asia","1947-08-15"],["US",329.74,9833.52,19485.39,"N.America","1776-07-04"],["Indonesia",268.07,1910.93,1015.54,"Asia","1945-08-17"],["Brazil",210.32,8515.77,2055.51,"S.America","1822-09-07"],["Pakistan",205.71,881.91,302.14,"Asia","1947-08-14"],["Nigeria",200.96,923.77,375.77,"Africa","1960-10-01"],["Bangladesh",167.09,147.57,245.63,"Asia","1971-03-26"],["Russia",146.79,17098.25,1530.75,null,"1992-06-12"],["Mexico",126.58,1964.38,1158.23,"N.America","1810-09-16"],["Japan",126.22,377.97,4872.42,"Asia",null],["Germany",83.02,357.11,3693.2,"Europe",null],["France",67.02,640.68,2582.49,"Europe","1789-07-14"],["UK",66.44,242.5,2631.23,"Europe",null],["Italy",60.36,301.34,1943.84,"Europe",null],["Argentina",44.94,2780.4,637.49,"S.America","1816-07-09"],["Algeria",43.38,2381.74,167.56,"Africa","1962-07-05"],["Canada",37.59,9984.67,1647.12,"N.America","1867-07-01"],["Australia",25.47,7692.02,1408.68,"Oceania",null],["Kazakhstan",18.53,2724.9,159.41,"Asia","1991-12-16"]]}
data-split.json содержит один словарь, содержащий следующие списки:
- Названия столбцов
- Метки строк
- Внутренние списки (двумерная последовательность), содержащие значения данных
Если вы не укажете значение необязательного параметра path_or_buf, который определяет путь к файлу, то .to_json() вернет строку JSON вместо записи результатов в файл. Такое поведение согласуется с .to_csv().
Есть и другие необязательные параметры, которые вы можете использовать. Например, вы можете установить index=False, чтобы отказаться от сохранения меток строк. Вы можете управлять точностью с помощью double_precision, а датами - с помощью date_format и date_unit. Эти последние два параметра особенно важны, когда в ваших данных есть временные ряды:
>>> df = pd.DataFrame(data=data).T
>>> df['IND_DAY'] = pd.to_datetime(df['IND_DAY'])
>>> df.dtypes
COUNTRY object
POP object
AREA object
GDP object
CONT object
IND_DAY datetime64[ns]
dtype: object
>>> df.to_json('data-time.json')
В этом примере вы создали DataFrame из словаря data и использовали to_datetime() для преобразования значений в последнем столбце в datetime64. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть результирующий файл:
{"COUNTRY":{"CHN":"China","IND":"India","USA":"US","IDN":"Indonesia","BRA":"Brazil","PAK":"Pakistan","NGA":"Nigeria","BGD":"Bangladesh","RUS":"Russia","MEX":"Mexico","JPN":"Japan","DEU":"Germany","FRA":"France","GBR":"UK","ITA":"Italy","ARG":"Argentina","DZA":"Algeria","CAN":"Canada","AUS":"Australia","KAZ":"Kazakhstan"},"POP":{"CHN":1398.72,"IND":1351.16,"USA":329.74,"IDN":268.07,"BRA":210.32,"PAK":205.71,"NGA":200.96,"BGD":167.09,"RUS":146.79,"MEX":126.58,"JPN":126.22,"DEU":83.02,"FRA":67.02,"GBR":66.44,"ITA":60.36,"ARG":44.94,"DZA":43.38,"CAN":37.59,"AUS":25.47,"KAZ":18.53},"AREA":{"CHN":9596.96,"IND":3287.26,"USA":9833.52,"IDN":1910.93,"BRA":8515.77,"PAK":881.91,"NGA":923.77,"BGD":147.57,"RUS":17098.25,"MEX":1964.38,"JPN":377.97,"DEU":357.11,"FRA":640.68,"GBR":242.5,"ITA":301.34,"ARG":2780.4,"DZA":2381.74,"CAN":9984.67,"AUS":7692.02,"KAZ":2724.9},"GDP":{"CHN":12234.78,"IND":2575.67,"USA":19485.39,"IDN":1015.54,"BRA":2055.51,"PAK":302.14,"NGA":375.77,"BGD":245.63,"RUS":1530.75,"MEX":1158.23,"JPN":4872.42,"DEU":3693.2,"FRA":2582.49,"GBR":2631.23,"ITA":1943.84,"ARG":637.49,"DZA":167.56,"CAN":1647.12,"AUS":1408.68,"KAZ":159.41},"CONT":{"CHN":"Asia","IND":"Asia","USA":"N.America","IDN":"Asia","BRA":"S.America","PAK":"Asia","NGA":"Africa","BGD":"Asia","RUS":null,"MEX":"N.America","JPN":"Asia","DEU":"Europe","FRA":"Europe","GBR":"Europe","ITA":"Europe","ARG":"S.America","DZA":"Africa","CAN":"N.America","AUS":"Oceania","KAZ":"Asia"},"IND_DAY":{"CHN":null,"IND":-706320000000,"USA":-6106060800000,"IDN":-769219200000,"BRA":-4648924800000,"PAK":-706406400000,"NGA":-291945600000,"BGD":38793600000,"RUS":708307200000,"MEX":-5026838400000,"JPN":null,"DEU":null,"FRA":-5694969600000,"GBR":null,"ITA":null,"ARG":-4843411200000,"DZA":-236476800000,"CAN":-3234729600000,"AUS":null,"KAZ":692841600000}}
В этом файле вместо дат для дней независимости указаны большие целые числа. Это связано с тем, что значение необязательного параметра date_format по умолчанию равно 'epoch' всякий раз, когда orient не равно 'table'. Это поведение по умолчанию отображает даты в виде эпох в миллисекундах относительно полуночи января 1, 1970.
Однако, если вы передадите date_format='iso', то получите даты в формате ISO 8601. Кроме того, date_unit определяет единицы измерения времени:
>>> df = pd.DataFrame(data=data).T
>>> df['IND_DAY'] = pd.to_datetime(df['IND_DAY'])
>>> df.to_json('new-data-time.json', date_format='iso', date_unit='s')
Этот код создает следующий JSON-файл:
{"COUNTRY":{"CHN":"China","IND":"India","USA":"US","IDN":"Indonesia","BRA":"Brazil","PAK":"Pakistan","NGA":"Nigeria","BGD":"Bangladesh","RUS":"Russia","MEX":"Mexico","JPN":"Japan","DEU":"Germany","FRA":"France","GBR":"UK","ITA":"Italy","ARG":"Argentina","DZA":"Algeria","CAN":"Canada","AUS":"Australia","KAZ":"Kazakhstan"},"POP":{"CHN":1398.72,"IND":1351.16,"USA":329.74,"IDN":268.07,"BRA":210.32,"PAK":205.71,"NGA":200.96,"BGD":167.09,"RUS":146.79,"MEX":126.58,"JPN":126.22,"DEU":83.02,"FRA":67.02,"GBR":66.44,"ITA":60.36,"ARG":44.94,"DZA":43.38,"CAN":37.59,"AUS":25.47,"KAZ":18.53},"AREA":{"CHN":9596.96,"IND":3287.26,"USA":9833.52,"IDN":1910.93,"BRA":8515.77,"PAK":881.91,"NGA":923.77,"BGD":147.57,"RUS":17098.25,"MEX":1964.38,"JPN":377.97,"DEU":357.11,"FRA":640.68,"GBR":242.5,"ITA":301.34,"ARG":2780.4,"DZA":2381.74,"CAN":9984.67,"AUS":7692.02,"KAZ":2724.9},"GDP":{"CHN":12234.78,"IND":2575.67,"USA":19485.39,"IDN":1015.54,"BRA":2055.51,"PAK":302.14,"NGA":375.77,"BGD":245.63,"RUS":1530.75,"MEX":1158.23,"JPN":4872.42,"DEU":3693.2,"FRA":2582.49,"GBR":2631.23,"ITA":1943.84,"ARG":637.49,"DZA":167.56,"CAN":1647.12,"AUS":1408.68,"KAZ":159.41},"CONT":{"CHN":"Asia","IND":"Asia","USA":"N.America","IDN":"Asia","BRA":"S.America","PAK":"Asia","NGA":"Africa","BGD":"Asia","RUS":null,"MEX":"N.America","JPN":"Asia","DEU":"Europe","FRA":"Europe","GBR":"Europe","ITA":"Europe","ARG":"S.America","DZA":"Africa","CAN":"N.America","AUS":"Oceania","KAZ":"Asia"},"IND_DAY":{"CHN":null,"IND":"1947-08-15T00:00:00Z","USA":"1776-07-04T00:00:00Z","IDN":"1945-08-17T00:00:00Z","BRA":"1822-09-07T00:00:00Z","PAK":"1947-08-14T00:00:00Z","NGA":"1960-10-01T00:00:00Z","BGD":"1971-03-26T00:00:00Z","RUS":"1992-06-12T00:00:00Z","MEX":"1810-09-16T00:00:00Z","JPN":null,"DEU":null,"FRA":"1789-07-14T00:00:00Z","GBR":null,"ITA":null,"ARG":"1816-07-09T00:00:00Z","DZA":"1962-07-05T00:00:00Z","CAN":"1867-07-01T00:00:00Z","AUS":null,"KAZ":"1991-12-16T00:00:00Z"}}
Даты в результирующем файле указаны в формате ISO 8601.
Вы можете загрузить данные из файла JSON с помощью read_json():
>>> df = pd.read_json('data-index.json', orient='index',
... convert_dates=['IND_DAY'])
Параметр convert_dates имеет то же назначение, что и parse_dates, когда вы используете его для чтения CSV-файлов. Необязательный параметр orient очень важен, поскольку он определяет, как pandas понимает структуру файла.
Есть и другие необязательные параметры, которые вы также можете использовать:
- Установите кодировку с помощью
encoding. - Манипулируйте датами с помощью
convert_datesиkeep_default_dates. - Точность удара при
dtypeиprecise_float. - Декодировать числовые данные непосредственно в массивы NumPy с помощью
numpy=True.
Обратите внимание, что при использовании формата JSON для хранения данных может быть нарушен порядок следования строк и столбцов.
HTML-файлы
HTML - это обычный текстовый файл, который использует язык гипертекстовой разметки, чтобы помочь браузерам отображать веб-страницы. Расширения для HTML-файлов - .html и .htm. Вам нужно будет установить библиотеку синтаксического анализа HTML, такую как lxml или html5lib, чтобы иметь возможность работать с HTML-файлами:
$pip install lxml html5lib
Вы также можете использовать Conda для установки тех же пакетов:
$ conda install lxml html5lib
Как только у вас будут эти библиотеки, вы можете сохранить содержимое вашего DataFrame в виде HTML-файла с помощью .to_html():
df = pd.DataFrame(data=data).T
df.to_html('data.html')
Этот код генерирует файл data.html. Вы можете развернуть приведенный ниже блок кода, чтобы увидеть, как должен выглядеть этот файл:
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>COUNTRY</th>
<th>POP</th>
<th>AREA</th>
<th>GDP</th>
<th>CONT</th>
<th>IND_DAY</th>
</tr>
</thead>
<tbody>
<tr>
<th>CHN</th>
<td>China</td>
<td>1398.72</td>
<td>9596.96</td>
<td>12234.8</td>
<td>Asia</td>
<td>NaN</td>
</tr>
<tr>
<th>IND</th>
<td>India</td>
<td>1351.16</td>
<td>3287.26</td>
<td>2575.67</td>
<td>Asia</td>
<td>1947-08-15</td>
</tr>
<tr>
<th>USA</th>
<td>US</td>
<td>329.74</td>
<td>9833.52</td>
<td>19485.4</td>
<td>N.America</td>
<td>1776-07-04</td>
</tr>
<tr>
<th>IDN</th>
<td>Indonesia</td>
<td>268.07</td>
<td>1910.93</td>
<td>1015.54</td>
<td>Asia</td>
<td>1945-08-17</td>
</tr>
<tr>
<th>BRA</th>
<td>Brazil</td>
<td>210.32</td>
<td>8515.77</td>
<td>2055.51</td>
<td>S.America</td>
<td>1822-09-07</td>
</tr>
<tr>
<th>PAK</th>
<td>Pakistan</td>
<td>205.71</td>
<td>881.91</td>
<td>302.14</td>
<td>Asia</td>
<td>1947-08-14</td>
</tr>
<tr>
<th>NGA</th>
<td>Nigeria</td>
<td>200.96</td>
<td>923.77</td>
<td>375.77</td>
<td>Africa</td>
<td>1960-10-01</td>
</tr>
<tr>
<th>BGD</th>
<td>Bangladesh</td>
<td>167.09</td>
<td>147.57</td>
<td>245.63</td>
<td>Asia</td>
<td>1971-03-26</td>
</tr>
<tr>
<th>RUS</th>
<td>Russia</td>
<td>146.79</td>
<td>17098.2</td>
<td>1530.75</td>
<td>NaN</td>
<td>1992-06-12</td>
</tr>
<tr>
<th>MEX</th>
<td>Mexico</td>
<td>126.58</td>
<td>1964.38</td>
<td>1158.23</td>
<td>N.America</td>
<td>1810-09-16</td>
</tr>
<tr>
<th>JPN</th>
<td>Japan</td>
<td>126.22</td>
<td>377.97</td>
<td>4872.42</td>
<td>Asia</td>
<td>NaN</td>
</tr>
<tr>
<th>DEU</th>
<td>Germany</td>
<td>83.02</td>
<td>357.11</td>
<td>3693.2</td>
<td>Europe</td>
<td>NaN</td>
</tr>
<tr>
<th>FRA</th>
<td>France</td>
<td>67.02</td>
<td>640.68</td>
<td>2582.49</td>
<td>Europe</td>
<td>1789-07-14</td>
</tr>
<tr>
<th>GBR</th>
<td>UK</td>
<td>66.44</td>
<td>242.5</td>
<td>2631.23</td>
<td>Europe</td>
<td>NaN</td>
</tr>
<tr>
<th>ITA</th>
<td>Italy</td>
<td>60.36</td>
<td>301.34</td>
<td>1943.84</td>
<td>Europe</td>
<td>NaN</td>
</tr>
<tr>
<th>ARG</th>
<td>Argentina</td>
<td>44.94</td>
<td>2780.4</td>
<td>637.49</td>
<td>S.America</td>
<td>1816-07-09</td>
</tr>
<tr>
<th>DZA</th>
<td>Algeria</td>
<td>43.38</td>
<td>2381.74</td>
<td>167.56</td>
<td>Africa</td>
<td>1962-07-05</td>
</tr>
<tr>
<th>CAN</th>
<td>Canada</td>
<td>37.59</td>
<td>9984.67</td>
<td>1647.12</td>
<td>N.America</td>
<td>1867-07-01</td>
</tr>
<tr>
<th>AUS</th>
<td>Australia</td>
<td>25.47</td>
<td>7692.02</td>
<td>1408.68</td>
<td>Oceania</td>
<td>NaN</td>
</tr>
<tr>
<th>KAZ</th>
<td>Kazakhstan</td>
<td>18.53</td>
<td>2724.9</td>
<td>159.41</td>
<td>Asia</td>
<td>1991-12-16</td>
</tr>
</tbody>
</table>
В этом файле хорошо отображено содержимое DataFrame. Однако обратите внимание, что вы получили не всю веб-страницу целиком. Вы только что вывели данные, соответствующие df в формате HTML.
.to_html() файл не будет создан, если вы не укажете необязательный параметр buf, который обозначает буфер для записи. Если вы не зададите этот параметр, то ваш код вернет строку, как это было с .to_csv() и .to_json().
Вот некоторые другие необязательные параметры:
headerопределяет, следует ли сохранять имена столбцов.indexопределяет, следует ли сохранять метки строк.classesназначает каскадную таблицу стилей (CSS) классам.render_linksуказывает, следует ли преобразовывать URL-адреса в HTML-ссылки.table_idприсваивает CSS-кодidтегуtable.escapeопределяет, следует ли преобразовать символы<,>, и&в HTML-безопасные строки.
Подобные параметры используются для определения различных аспектов результирующих файлов или строк.
Вы можете создать объект DataFrame из подходящего HTML-файла, используя read_html(), , который вернет экземпляр DataFrame или список из них:
>>> df = pd.read_html('data.html', index_col=0, parse_dates=['IND_DAY'])
Это очень похоже на то, что вы делали при чтении CSV-файлов. У вас также есть параметры, которые помогают работать с датами, пропущенными значениями, точностью, кодировкой, анализаторами HTML и многим другим.
Файлы Excel
Вы уже научились читать и записывать файлы Excel с помощью pandas. Однако есть еще несколько вариантов, которые стоит рассмотреть. Например, когда вы используете .to_excel(), вы можете указать имя целевого листа с помощью необязательного параметра sheet_name:
>>> df = pd.DataFrame(data=data).T
>>> df.to_excel('data.xlsx', sheet_name='COUNTRIES')
Здесь вы создаете файл data.xlsx с рабочим листом под названием COUNTRIES, в котором хранятся данные. Строка 'data.xlsx' является аргументом для параметра excel_writer, который определяет имя файла Excel или путь к нему.
Необязательные параметры startrow и startcol по умолчанию равны 0 и указывают крайнюю верхнюю левую ячейку, в которую должны быть записаны данные:
>>> df.to_excel('data-shifted.xlsx', sheet_name='COUNTRIES',
... startrow=2, startcol=4)
Здесь вы указываете, что таблица должна начинаться с третьей строки и пятого столбца. Вы также использовали индексацию на основе нуля, поэтому третья строка обозначается как 2, а пятый столбец - как 4.
Теперь результирующий рабочий лист выглядит следующим образом:
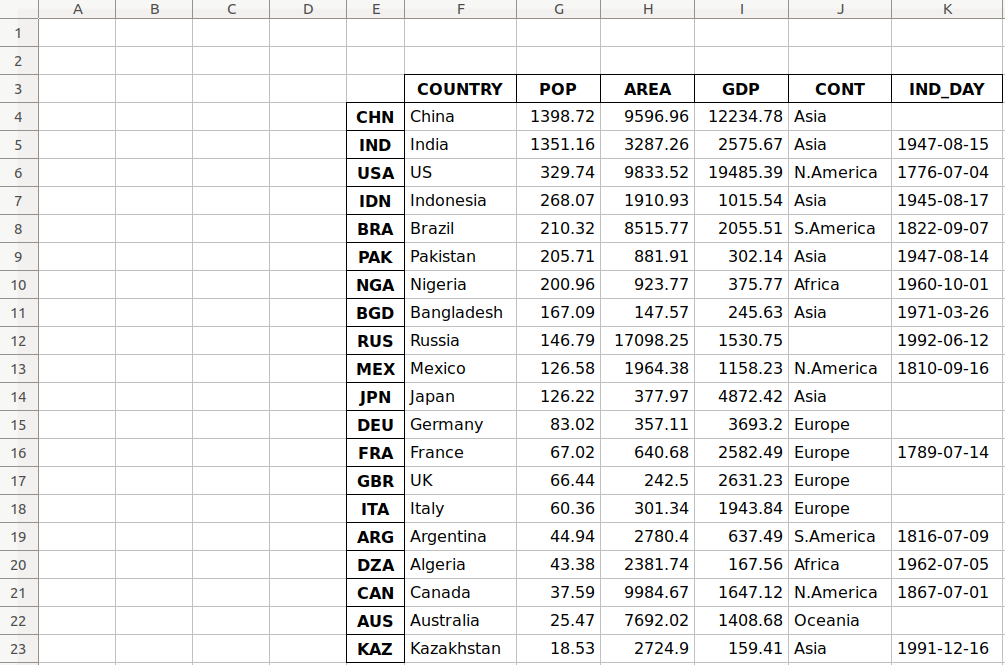
Как вы можете видеть, таблица начинается с третьей строки 2 и пятого столбца E.
.read_excel() также имеет необязательный параметр sheet_name, который определяет, какие рабочие листы следует считывать при загрузке данных. Он может принимать одно из следующих значений:
- Нулевой индекс рабочего листа
- Название рабочего листа
- Список индексов или названий для чтения на нескольких листах
- Значение
Noneдля чтения всех листов
Вот как вы могли бы использовать этот параметр в своем коде:
>>> df = pd.read_excel('data.xlsx', sheet_name=0, index_col=0,
... parse_dates=['IND_DAY'])
>>> df = pd.read_excel('data.xlsx', sheet_name='COUNTRIES', index_col=0,
... parse_dates=['IND_DAY'])
Оба приведенных выше утверждения создают один и тот же DataFrame, поскольку параметры sheet_name имеют одинаковые значения. В обоих случаях sheet_name=0 и sheet_name='COUNTRIES' относятся к одному и тому же рабочему листу. Аргумент parse_dates=['IND_DAY'] указывает pandas попытаться рассматривать значения в этом столбце как даты или время.
Существуют и другие необязательные параметры, которые вы можете использовать с .read_excel() и .to_excel(), чтобы определить механизм Excel, кодировку, способ обработки пропущенных значений и бесконечностей, метод записи имен столбцов и меток строк, а также и так далее.
SQL-файлы
инструменты ввода-вывода pandas также могут считывать и записывать базы данных. В следующем примере вы будете записывать свои данные в базу данных с именем data.db. Для начала вам понадобится пакет SQLAlchemy. Чтобы узнать о нем больше, вы можете прочитать официальное руководство по ORM. Вам также понадобится драйвер базы данных. В Python есть встроенный драйвер для SQLite.
Вы можете установить SQLAlchemy с помощью pip:
$ pip install sqlalchemy
Вы также можете установить его с помощью Conda:
$ conda install sqlalchemy
После установки SQLAlchemy импортируйте create_engine() и создайте компонент database engine:
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///data.db', echo=False)
Теперь, когда вы все настроили, следующим шагом будет создание объекта DataFrame. Удобно указывать типы данных и применять их .to_sql().
>>> dtypes = {'POP': 'float64', 'AREA': 'float64', 'GDP': 'float64',
... 'IND_DAY': 'datetime64'}
>>> df = pd.DataFrame(data=data).T.astype(dtype=dtypes)
>>> df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY datetime64[ns]
dtype: object
.astype() это очень удобный метод, который вы можете использовать для установки нескольких типов данных одновременно.
Как только вы создадите свой DataFrame, вы можете сохранить его в базе данных с помощью .to_sql():
>>> df.to_sql('data.db', con=engine, index_label='ID')
Параметр con используется для указания подключения к базе данных или обработчика, который вы хотите использовать. Необязательный параметр index_label указывает, как вызывать столбец базы данных с метками строк. Вы часто будете видеть, как оно принимает значение ID, Id, или id.
Вы должны получить базу данных data.db с одной таблицей, которая выглядит следующим образом:
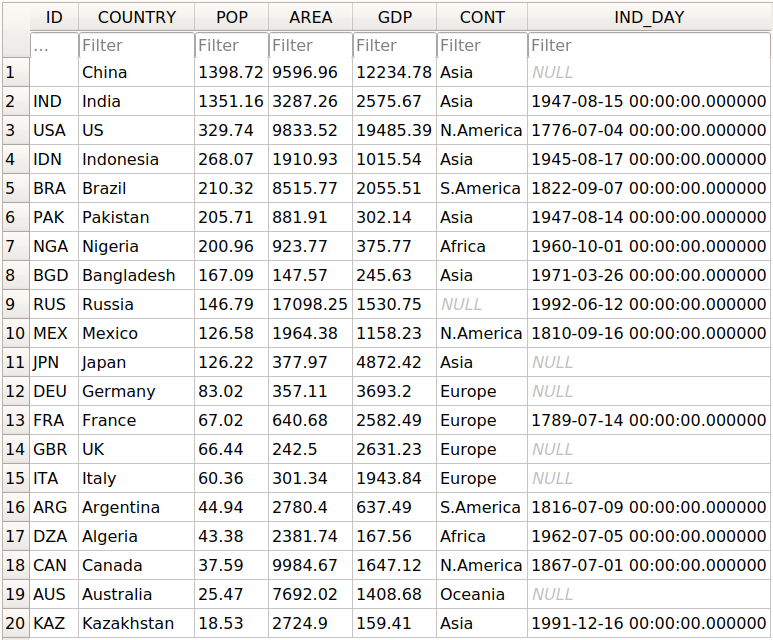
В первом столбце содержатся метки строк. Чтобы не записывать их в базу данных, измените index=False на .to_sql(). Остальные столбцы соответствуют столбцам таблицы DataFrame.
Есть еще несколько необязательных параметров. Например, вы можете использовать schema для указания схемы базы данных и dtype для определения типов столбцов базы данных. Вы также можете использовать if_exists, в котором указано, что делать, если база данных с таким же именем и путем уже существует:
if_exists='fail'вызывает ошибку ValueError и используется по умолчанию.if_exists='replace'удаляет таблицу и вставляет новые значения.if_exists='append'вставляет новые значения в таблицу.
Вы можете загрузить данные из базы данных с помощью read_sql():
>>> df = pd.read_sql('data.db', con=engine, index_col='ID')
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
ID
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 None 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
Параметр index_col указывает название столбца с метками строк. Обратите внимание, что при этом после заголовка, начинающегося с ID, будет вставлена дополнительная строка. Вы можете исправить это поведение с помощью следующей строки кода:
>>> df.index.name = None
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 None 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
Теперь у вас есть тот же DataFrame объект, что и раньше.
Обратите внимание, что континент для России теперь None вместо nan. Если вы хотите заполнить недостающие значения nan, то вы можете использовать .fillna():
>>> df.fillna(value=float('nan'), inplace=True)
.fillna() заменяет все пропущенные значения на те, которые вы передаете в value. Здесь вы передали float('nan'), в котором указано заполнить все пропущенные значения с помощью nan.
Также обратите внимание, что вам не нужно было передавать parse_dates=['IND_DAY'] в read_sql(). Это потому, что ваша база данных смогла обнаружить, что последний столбец содержит даты. Однако вы можете пропустить parse_dates, если хотите. Вы получите те же результаты.
Существуют и другие функции, которые вы можете использовать для чтения баз данных, например read_sql_table() и read_sql_query(). Не стесняйтесь попробовать их!
Файлы для pickle
pickle - это процесс преобразования объектов Python в байтовые потоки. Распаковка - это обратный процесс. Файлы Python pickle - это двоичные файлы, в которых хранятся данные и иерархия объектов Python. Обычно они имеют расширение .pickle или .pkl.
Вы можете сохранить свой DataFrame в файле pickle с .to_pickle():
>>> dtypes = {'POP': 'float64', 'AREA': 'float64', 'GDP': 'float64',
... 'IND_DAY': 'datetime64'}
>>> df = pd.DataFrame(data=data).T.astype(dtype=dtypes)
>>> df.to_pickle('data.pickle')
Как и в случае с базами данных, может быть удобно сначала указать типы данных. Затем вы создаете файл data.pickle, содержащий ваши данные. Вы также можете передать целочисленное значение необязательному параметру protocol, который определяет протокол средства выбора.
Вы можете получить данные из файла pickle с помощью read_pickle():
>>> df = pd.read_pickle('data.pickle')
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
read_pickle() возвращает DataFrame с сохраненными данными. Вы также можете проверить типы данных:
>>> df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY datetime64[ns]
dtype: object
Это те же самые параметры, которые вы указали перед использованием .to_pickle().
В качестве предостережения, вам всегда следует остерегаться покупать маринованные огурцы из ненадежных источников. Это может быть опасно! Когда вы извлекаете ненадежный файл, он может выполнить произвольный код на вашем компьютере, получить удаленный доступ к вашему компьютеру или иным образом использовать ваше устройство другими способами.
Работа с Большими данными
Если ваши файлы слишком велики для сохранения или обработки, то есть несколько способов уменьшить требуемое дисковое пространство:
- Сжимайте ваши файлы
- Выберите только те столбцы, которые вам нужны
- Опустите строки, которые вам не нужны
- Принудительное использование менее точных типов данных
- Разделить данные на фрагменты
Вы по очереди рассмотрите каждую из этих техник.
Сжимать и распаковывать файлы
Вы можете создать архивный файл как обычный, с добавлением суффикса, соответствующего желаемому типу сжатия:
'.gz''.bz2''.zip''.xz'
pandas может сам определить тип сжатия:
>>> df = pd.DataFrame(data=data).T
>>> df.to_csv('data.csv.zip')
Здесь вы создаете сжатый .csv файл в виде архива. Размер обычного файла .csv составляет 1048 байт, в то время как размер сжатого файла составляет всего 766 байт.
Вы можете открыть этот сжатый файл как обычно с помощью функции pandas read_csv():
>>> df = pd.read_csv('data.csv.zip', index_col=0,
... parse_dates=['IND_DAY'])
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
read_csv() распаковывает файл перед чтением его в DataFrame.
Вы можете указать тип сжатия с помощью необязательного параметра compression, который может принимать любое из следующих значений:
'infer''gzip''bz2''zip''xz'None
Значение по умолчанию compression='infer' указывает на то, что pandas должен определять тип сжатия по расширению файла.
Вот как вы могли бы сжать файл pickle:
>>> df = pd.DataFrame(data=data).T
>>> df.to_pickle('data.pickle.compress', compression='gzip')
У вас должен получиться файл data.pickle.compress, который вы позже сможете распаковать и прочитать:
>>> df = pd.read_pickle('data.pickle.compress', compression='gzip')
df снова соответствует DataFrame с теми же данными, что и раньше.
Вы также можете попробовать другие методы сжатия. Если вы используете pickle-файлы, то имейте в виду, что формат .zip поддерживает только чтение.
Выберите столбцы
Функции pandas read_csv() и read_excel() имеют необязательный параметр usecols, который можно использовать для указания столбцов, которые вы хотите загрузить из файла. Вы можете передать список имен столбцов в качестве соответствующего аргумента:
>>> df = pd.read_csv('data.csv', usecols=['COUNTRY', 'AREA'])
>>> df
COUNTRY AREA
0 China 9596.96
1 India 3287.26
2 US 9833.52
3 Indonesia 1910.93
4 Brazil 8515.77
5 Pakistan 881.91
6 Nigeria 923.77
7 Bangladesh 147.57
8 Russia 17098.25
9 Mexico 1964.38
10 Japan 377.97
11 Germany 357.11
12 France 640.68
13 UK 242.50
14 Italy 301.34
15 Argentina 2780.40
16 Algeria 2381.74
17 Canada 9984.67
18 Australia 7692.02
19 Kazakhstan 2724.90
Теперь у вас есть DataFrame, который содержит меньше данных, чем раньше. Здесь указаны только названия стран и их районов.
Вместо имен столбцов вы также можете передать их индексы:
>>> df = pd.read_csv('data.csv',index_col=0, usecols=[0, 1, 3])
>>> df
COUNTRY AREA
CHN China 9596.96
IND India 3287.26
USA US 9833.52
IDN Indonesia 1910.93
BRA Brazil 8515.77
PAK Pakistan 881.91
NGA Nigeria 923.77
BGD Bangladesh 147.57
RUS Russia 17098.25
MEX Mexico 1964.38
JPN Japan 377.97
DEU Germany 357.11
FRA France 640.68
GBR UK 242.50
ITA Italy 301.34
ARG Argentina 2780.40
DZA Algeria 2381.74
CAN Canada 9984.67
AUS Australia 7692.02
KAZ Kazakhstan 2724.90
Разверните приведенный ниже блок кода, чтобы сравнить эти результаты с файлом 'data.csv':
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,,1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
Вы можете увидеть следующие столбцы:
- Столбец с индексом
0содержит метки строк. - Столбец с индексом
1содержит названия стран. - Столбец с индексом
3содержит области.
Аналогично, read_sql() имеет необязательный параметр columns, который принимает для чтения список имен столбцов:
>>> df = pd.read_sql('data.db', con=engine, index_col='ID',
... columns=['COUNTRY', 'AREA'])
>>> df.index.name = None
>>> df
COUNTRY AREA
CHN China 9596.96
IND India 3287.26
USA US 9833.52
IDN Indonesia 1910.93
BRA Brazil 8515.77
PAK Pakistan 881.91
NGA Nigeria 923.77
BGD Bangladesh 147.57
RUS Russia 17098.25
MEX Mexico 1964.38
JPN Japan 377.97
DEU Germany 357.11
FRA France 640.68
GBR UK 242.50
ITA Italy 301.34
ARG Argentina 2780.40
DZA Algeria 2381.74
CAN Canada 9984.67
AUS Australia 7692.02
KAZ Kazakhstan 2724.90
Опять же, DataFrame содержит только столбцы с названиями стран и областей. Если columns равно None или опущено, то будут прочитаны все столбцы, как , которые вы видели ранее. Поведение по умолчанию таково columns=None.
Опустить строки
Когда вы тестируете алгоритм обработки данных или машинного обучения, вам часто не требуется весь набор данных. Для ускорения процесса удобно загружать только часть данных. Функции pandas read_csv() и read_excel() имеют несколько необязательных параметров, которые позволяют вам выбрать, какие строки вы хотите загрузить:
skiprows: либо количество строк, которые нужно пропустить в начале файла, если это целое число, либо индексы строк, которые нужно пропустить, основанные на нуле, если это объект, похожий на списокskipfooter: количество строк, которые нужно пропустить в конце файлаnrows: количество строк для чтения
Вот как вы могли бы пропустить строки с нечетными индексами, основанными на нуле, сохранив четные:
>>> df = pd.read_csv('data.csv', index_col=0, skiprows=range(1, 20, 2))
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
DEU Germany 83.02 357.11 3693.20 Europe NaN
GBR UK 66.44 242.50 2631.23 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
В этом примере skiprows равно range(1, 20, 2) и соответствует значениям 1, 3, ..., 19. Экземпляры встроенного класса Python range ведут себя как последовательности. Первая строка файла data.csv является строкой заголовка. Он имеет индекс 0, поэтому pandas загружает его. Вторая строка с индексом 1 соответствует метке CHN, и pandas пропускает ее. Загружается третья строка с индексом 2 и меткой IND и так далее.
Если вы хотите выбирать строки случайным образом, то skiprows может быть списком или числовым массивом с псевдослучайными числами, полученными либо с помощью чистый Python или с NumPy.
Принудительно использовать менее точные типы данных
Если вас устраивают менее точные типы данных, то вы потенциально можете сэкономить значительный объем памяти! Сначала снова введите типы данных с помощью .dtypes:
>>> df = pd.read_csv('data.csv', index_col=0, parse_dates=['IND_DAY'])
>>> df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY datetime64[ns]
dtype: object
Столбцы с числами с плавающей запятой являются 64-разрядными числами с плавающей запятой. Каждое число этого типа float64 занимает 64 бита или 8 байт. Каждый столбец содержит 20 чисел и требует 160 байт. Вы можете убедиться в этом с помощью .memory_usage():
>>> df.memory_usage()
Index 160
COUNTRY 160
POP 160
AREA 160
GDP 160
CONT 160
IND_DAY 160
dtype: int64
.memory_usage() возвращает экземпляр Series с использованием памяти для каждого столбца в байтах. Вы можете удобно комбинировать его с .loc[] и .sum() чтобы получить объем памяти для группы столбцов:
>>> df.loc[:, ['POP', 'AREA', 'GDP']].memory_usage(index=False).sum()
480
В этом примере показано, как можно объединить числовые столбцы 'POP', 'AREA', и 'GDP', чтобы получить общее количество требуемой памяти. Аргумент index=False исключает данные для меток строк из результирующего объекта Series. Для этих трех столбцов вам потребуется 480 байт.
Вы также можете извлечь значения данных в виде числового массива с помощью .to_numpy() или .values. Затем используйте атрибут .nbytes, чтобы получить общее количество байт, потребляемых элементами массива:
>>> df.loc[:, ['POP', 'AREA', 'GDP']].to_numpy().nbytes
480
Результат тот же - 480 байт. Итак, как вы экономите память?
В этом случае вы можете указать, что ваши числовые столбцы 'POP', 'AREA', и 'GDP' должны иметь тип float32. Для этого используйте необязательный параметр dtype:
>>> dtypes = {'POP': 'float32', 'AREA': 'float32', 'GDP': 'float32'}
>>> df = pd.read_csv('data.csv', index_col=0, dtype=dtypes,
... parse_dates=['IND_DAY'])
В словаре dtypes указаны желаемые типы данных для каждого столбца. Он передается функции pandas read_csv() в качестве аргумента, соответствующего параметру dtype.
Теперь вы можете убедиться, что для каждого числового столбца требуется 80 байт, или по 4 байта на элемент:
>>> df.dtypes
COUNTRY object
POP float32
AREA float32
GDP float32
CONT object
IND_DAY datetime64[ns]
dtype: object
>>> df.memory_usage()
Index 160
COUNTRY 160
POP 80
AREA 80
GDP 80
CONT 160
IND_DAY 160
dtype: int64
>>> df.loc[:, ['POP', 'AREA', 'GDP']].memory_usage(index=False).sum()
240
>>> df.loc[:, ['POP', 'AREA', 'GDP']].to_numpy().nbytes
240
Каждое значение представляет собой число с плавающей запятой длиной 32 бита или 4 байта. Три числовых столбца содержат по 20 элементов в каждом. В общей сложности при работе с типом float32 вам потребуется 240 байт памяти. Это вдвое меньше тех 480 байт, с которыми вам пришлось бы работать float64.
В дополнение к экономии памяти, вы можете значительно сократить время, необходимое для обработки данных, используя float32 вместо float64 в некоторых случаях.
Используйте фрагменты для перебора файлов
Другой способ обработки очень больших наборов данных - разбить данные на более мелкие фрагменты и обрабатывать по одному фрагменту за раз. Если вы используете read_csv(), read_json() или read_sql(), то вы можете указать необязательный параметр chunksize:
>>> data_chunk = pd.read_csv('data.csv', index_col=0, chunksize=8)
>>> type(data_chunk)
<class 'pandas.io.parsers.TextFileReader'>
>>> hasattr(data_chunk, '__iter__')
True
>>> hasattr(data_chunk, '__next__')
True
chunksize по умолчанию используется значение None и может принимать целое значение, указывающее количество элементов в одном блоке. Когда chunksize является целым числом, read_csv() возвращает итерацию, которую можно использовать в цикле for для получения и обработки только фрагмента набора данных на каждой итерации:
>>> for df_chunk in pd.read_csv('data.csv', index_col=0, chunksize=8):
... print(df_chunk, end='\n\n')
... print('memory:', df_chunk.memory_usage().sum(), 'bytes',
... end='\n\n\n')
...
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
memory: 448 bytes
COUNTRY POP AREA GDP CONT IND_DAY
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
memory: 448 bytes
COUNTRY POP AREA GDP CONT IND_DAY
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
memory: 224 bytes
В этом примере chunksize равно 8. Первая итерация цикла for возвращает значение DataFrame только для первых восьми строк набора данных. Вторая итерация возвращает другое значение DataFrame со следующими восемью строками. Третья и последняя итерация возвращает оставшиеся четыре строки.
Примечание: Вы также можете передать iterator=True, чтобы заставить функцию pandas read_csv() возвращать объект-итератор вместо объекта DataFrame.
На каждой итерации вы получаете и обрабатываете DataFrame с количеством строк, равным chunksize. На последней итерации может быть меньше строк, чем значение chunksize. Вы можете использовать эту функциональность, чтобы контролировать объем памяти, необходимый для обработки данных, и поддерживать этот объем на достаточно низком уровне.
Заключение
Теперь вы знаете, как сохранять данные и метки из объектов pandas DataFrame в различные типы файлов. Вы также знаете, как загружать свои данные из файлов и создавать DataFrame объектов.
Вы использовали методы pandas read_csv() и .to_csv() для чтения и записи файлов CSV. Вы также использовали аналогичные методы для чтения и записи файлов Excel, JSON, HTML, SQL и pickle. Эти функции очень удобны и широко используются. Они позволяют сохранять или загружать ваши данные одним вызовом функции или метода.
Вы также узнали, как экономить время, память и дисковое пространство при работе с большими файлами данных:
- Сжимать или распаковывать файлов
- Выберите строки и столбцы, которые вы хотите загрузить
- Используйте менее точные типы данных
- Разделите данные на блоки и обработайте их один за другим
Вы сделали важный шаг в процессе машинного обучения и обработки данных! Если у вас есть какие-либо вопросы или комментарии, пожалуйста, задавайте их в разделе комментариев ниже.
Back to Top