Линейная алгебра в Python: Обратные матрицы и наименьшие квадраты
Оглавление
- Начало работы с линейной алгеброй в Python
- Понимание векторов, матриц и роли линейной алгебры
- Решение задач с использованием обратных матриц и определителей
- Вычисление инверсий и определителей с помощью scipy.linalg
- Интерполирующие многочлены с линейными системами
- Минимизация ошибки с помощью метода Наименьших квадратов
- Пример: Прогнозирование цен на автомобили с помощью метода Наименьших квадратов
- Заключение
Линейная алгебра является важной темой для изучения в самых разных предметах. Это позволяет вам решать задачи, связанные с векторами, матрицами и линейными уравнениями. В Python большинство процедур, связанных с этим предметом, реализованы на языке scipy.linalg,, который предлагает очень быстрые возможности линейной алгебры.
В частности, линейные модели играют важную роль в решении множества реальных задач, а scipy.linalg предоставляет инструменты для их эффективного вычисления.
В этом руководстве вы узнаете, как:
- Изучайте линейные системы, используя определители и решайте задачи, используя обратные матрицы
- Интерполируйте многочлены, чтобы они соответствовали набору точек, используя линейные системы
- Используйте Python для решения задач линейной регрессии
- Используйте линейную регрессию для прогнозирования цен на основе исторических данных
Это вторая часть серии учебных пособий по линейной алгебре с использованием scipy.linalg. Итак, прежде чем продолжить, обязательно ознакомьтесь с первым руководством из серии, прежде чем читать это.
Теперь вы готовы приступить к работе!
Начало работы с линейной алгеброй в Python
Линейная алгебра - это раздел математики, который имеет дело с линейными уравнениями и их представлениями с использованием векторов и матриц. Это фундаментальный предмет в нескольких областях инженерии, и он является необходимым условием для более глубокого понимания машинного обучения.
Для работы с линейной алгеброй на Python вы можете рассчитывать на SciPy, которая представляет собой библиотеку Python с открытым исходным кодом, используемую для научных вычислений, включая несколько модулей для решения распространенных задач в науке и технике.
Конечно, SciPy включает в себя модули для линейной алгебры, но это еще не все. Он также предлагает возможности оптимизации, интеграции, интерполяции и обработки сигналов . Это часть стека SciPy, который включает в себя несколько других пакетов для научных вычислений, таких как NumPy, Matplotlib, SymPy, IPython и панды.
scipy.linalg включает в себя несколько инструментов для работы с задачами линейной алгебры, включая функции для выполнения матричных вычислений, такие как определители, обратные, собственные значения, собственные векторы и разложение по сингулярным значениям .
В предыдущем уроке этой серии вы узнали, как работать с матрицами и векторами в Python для моделирования практических задач с использованием линейных систем. Вы решили эти проблемы с помощью scipy.linalg.
В этом руководстве вы сделаете еще один шаг вперед, используя scipy.linalg для изучения линейных систем и построения линейных моделей для решения реальных задач.
Чтобы использовать scipy.linalg, вам необходимо установить и настроить библиотеку SciPy. Кроме того, вы собираетесь использовать Jupyter Notebook для запуска кода в интерактивной среде. SciPy и Jupyter Notebook - это пакеты сторонних производителей, которые вам необходимо установить. Для установки вы можете использовать conda или pip менеджер пакетов. Ознакомьтесь с Работой с линейными системами в Python с помощью scipy.linalg для получения подробной информации об установке.
Примечание: Использование Jupyter Notebook для запуска кода не является обязательным, но облегчает работу с численными и научными приложениями.
Чтобы получить дополнительные сведения о работе с Jupyter Notebook, ознакомьтесь с Jupyter Notebook: Введение.
Далее вы познакомитесь с некоторыми фундаментальными понятиями линейной алгебры и узнаете, как использовать Python для работы с этими понятиями.
Понимание векторов, матриц и роли линейной алгебры
Вектор - это математическая единица, используемая для представления физических величин, которые имеют как величину, так и направление. Это фундаментальный инструмент для решения инженерных задач и задач машинного обучения. Так же как и матрицы, которые используются, среди прочего, для представления векторных преобразований.
Примечание: В Python NumPy является наиболее используемой библиотекой для работы с матрицами и векторами. Для их представления используется специальный тип, называемый ndarray. В качестве примера, представьте, что вам нужно создать следующую матрицу:
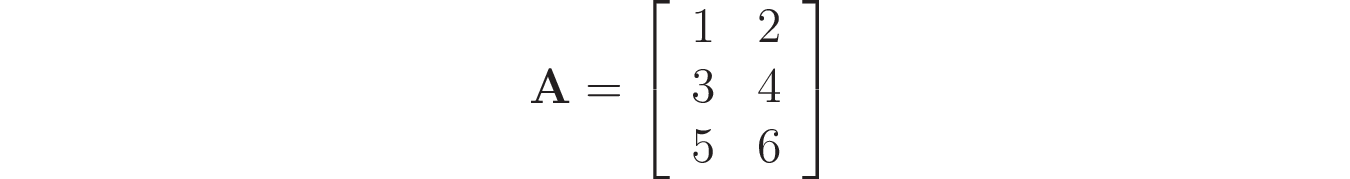
С помощью NumPy вы можете использовать np.array() для его создания, предоставляя вложенный список, содержащий элементы каждой строки матрицы:
In [1]: import numpy as np
In [2]: np.array([[1, 2], [3, 4], [5, 6]])
Out[2]:
array([[1, 2],
[3, 4],
[5, 6]])
NumPy предоставляет несколько функций, облегчающих работу с векторными и матричными вычислениями. Более подробную информацию о том, как использовать NumPy для представления векторов и матриц и выполнения операций с ними, вы можете найти в предыдущем руководстве из этой серии.
Линейная система или, точнее, система линейных уравнений - это набор уравнений, линейно связанных с набором переменных. Вот пример линейной системы, относящейся к переменным x₁ и x₂:
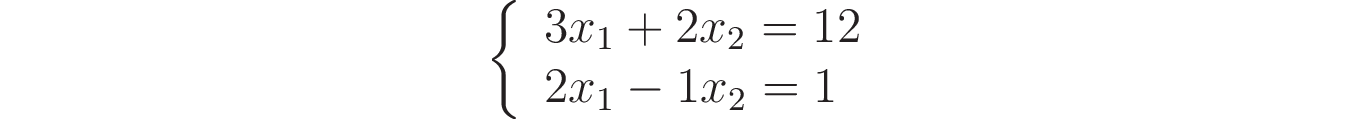
Здесь у вас есть два уравнения, включающие две переменные. Чтобы получить линейную систему, значения, на которые умножаются переменные x₁ и x₂ должны быть константами, как в этом примере. Обычно линейные системы записываются с использованием матриц и векторов. Например, предыдущую систему можно записать в виде следующего матричного произведения:
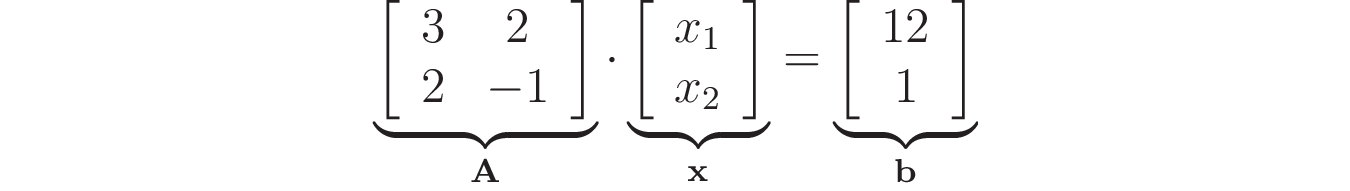
Сравнивая форму матричного произведения с исходной системой, вы можете заметить, что элементы матрицы A соответствуют коэффициентам, которые умножают x₁ и x₂. Кроме того, значения в правой части исходных уравнений теперь составляют вектор b.
Линейная алгебра - это математическая дисциплина, которая имеет дело с векторами, матрицами и векторными пространствами, а также с линейными преобразованиями в более общем плане. Используя концепции линейной алгебры, можно создавать алгоритмы для выполнения вычислений для нескольких приложений, включая решение линейных систем.
Когда имеется всего два или три уравнения и переменные, возможно выполнить вычисления вручную, объединить уравнения и найти значения для переменных.
Однако в реальных приложениях число уравнений может быть очень большим, что делает невозможным выполнение вычислений вручную. Именно тогда пригодятся концепции и алгоритмы линейной алгебры, позволяющие разрабатывать полезные приложения, например, для инженерии и машинного обучения.
В Работе с линейными системами в Python с помощью scipy.linalg, вы видели, как решать линейные системы с помощью scipy.linalg.solve(). Теперь вы узнаете, как использовать детерминанты для изучения возможных решений и как решать задачи, используя концепцию обратных матриц.
Решение задач с использованием обратных матриц и определителей
Обратные матрицы и определители - это инструменты, которые позволяют вам получить некоторую информацию о линейной системе, а также решить ее. Прежде чем подробно рассказать о том, как вычислять обратные матрицы и определители с помощью scipy.linalg, потратьте некоторое время на то, чтобы запомнить, как использовать эти структуры.
Использование детерминант для изучения линейных систем
Как вы, наверное, помните из уроков математики, не каждая линейная система может быть решена. Возможно, у вас есть противоречивая комбинация уравнений, которая не имеет решения. Например, система с двумя уравнениями, заданными как x₁ + x₂ = 2 и x₁ + x₂ = 3 является противоречивым и не имеет решения. Это происходит потому, что никакие два числа x₁ и x₂ не могут составлять в сумме 2 и 3 одновременно.
Кроме того, некоторые системы могут быть решены, но имеют более одного решения. Например, если у вас есть система с двумя эквивалентными уравнениями, такими как x₁ + x₂ = 2 и 2x₁ + 2x₂ = 4, тогда вы можете найти бесконечное количество решений, таких как (x₁=1, x₂=1), (x₁=0, x₂=2), (x₁=2, x₂=0) и так далее.
Определитель - это число, вычисляемое с использованием матрицы коэффициентов, которая сообщает вам, существует ли решение для системы. Поскольку для его вычисления вы будете использовать scipy.linalg, вам не нужно сильно задумываться о деталях выполнения расчета. Однако имейте в виду следующее:
- Если определитель матрицы коэффициентов линейной системы отличается от нуля, то можно сказать, что система имеет уникальное решение.
- Если определитель матрицы коэффициентов линейной системы равен нулю, то система может иметь либо нулевых решений, либо бесконечное количество решений.
Теперь, когда вы это запомнили, вы узнаете, как решать линейные системы с использованием матриц.
Использование обратных матриц для решения линейных систем
Чтобы понять идею, лежащую в основе обращения матрицы, начните с того, что вспомните концепцию мультипликативного обратного числа. Когда вы умножаете число на его обратное значение, вы получаете 1 в качестве результата. Возьмем в качестве примера 3. Значение, обратное 3, равно 1/3, и когда вы перемножаете эти числа, вы получаете 3 × 1/3 = 1.
С квадратными матрицами вы можете придумать аналогичную идею. Однако вместо 1 вы получите единичную матрицу в качестве результата. Единичная матрица содержит единицы на своей диагонали и нули в элементах за пределами диагонали, как в следующих примерах:
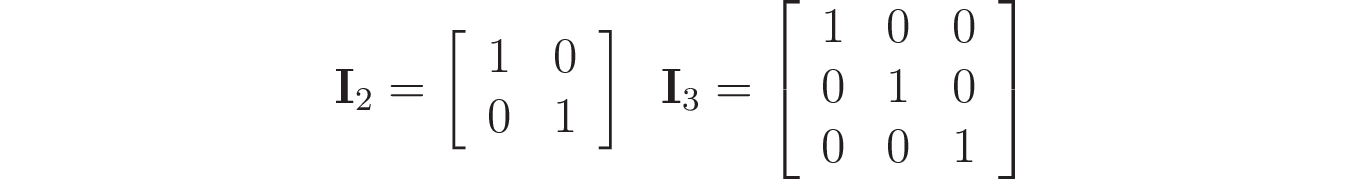
Единичная матрица обладает интересным свойством: при умножении на другую матрицу A той же размерности получается результат A. Напомним, что это справедливо и для числа 1, когда вы рассматриваете умножение чисел.
Это позволяет решить линейную систему, выполнив те же действия, что и для решения уравнения. В качестве примера рассмотрим следующую линейную систему, записанную в виде матричного произведения:
Вызывая A-1 как обратную матрицу A, вы можете умножить обе части уравнения на A-1, что дало бы вам следующий результат:
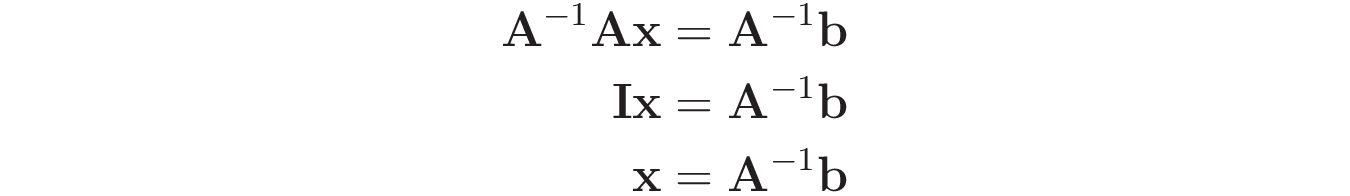
Таким образом, используя обратное значение A-1, вы можете получить решение x для системы, вычислив A-1b.
Стоит отметить, что, хотя ненулевые числа всегда имеют обратное значение, не все матрицы имеют обратное значение. Когда система не имеет решения или когда у нее есть несколько решений, определитель A будет равен нулю, а обратный, A-1, не будет существовать.
Теперь вы увидите, как использовать Python с scipy.linalg для выполнения этих вычислений.
Вычисление обратных величин и определителей с помощью scipy.linalg
Вы можете вычислить обратные матрицы и определители, используя scipy.linalg.inv() и scipy.linalg.det().
Например, рассмотрим проблему с планированием питания, над которой вы работали в предыдущем уроке этой серии. Напомним, что линейная система для этой задачи может быть записана в виде матричного произведения:

Ранее вы использовали scipy.linalg.solve() для получения решения 10, 10, 20, 20, 10 для переменных от x₁ до x₅ соответственно. Но, как вы только что узнали, также можно использовать обратную матрицу коэффициентов для получения вектора x, который содержит решения задачи. Вам нужно вычислить x = A-1b, что вы можете сделать с помощью следующей программы:
1In [1]: import numpy as np
2 ...: from scipy import linalg
3
4In [2]: A = np.array(
5 ...: [
6 ...: [1, 9, 2, 1, 1],
7 ...: [10, 1, 2, 1, 1],
8 ...: [1, 0, 5, 1, 1],
9 ...: [2, 1, 1, 2, 9],
10 ...: [2, 1, 2, 13, 2],
11 ...: ]
12 ...: )
13
14In [3]: b = np.array([170, 180, 140, 180, 350]).reshape((5, 1))
15
16In [4]: A_inv = linalg.inv(A)
17
18In [5]: x = A_inv @ b
19 ...: x
20Out[5]:
21array([[10.],
22 [10.],
23 [20.],
24 [20.],
25 [10.]])
Вот краткое описание происходящего:
-
Строки 1 и 2 импортируют NumPy как
np, а такжеlinalgизscipy. Этот импорт позволяет вам использоватьlinalg.inv(). -
Строки с 4 по 12 создают матрицу коэффициентов в виде числового массива, называемого
A. -
Строка 14 создает вектор независимых терминов в виде числового массива с именем
b. Чтобы превратить его в вектор-столбец с пятью элементами, вы используете.reshape((5, 1)). -
В строке 16 используется
linalg.inv()для получения обратной матрицыA. -
В строках 18 и 19 используется оператор
@для вычисления матричного произведения, чтобы решить линейную систему, характеризуемуюAиb. Вы сохраняете результат вx, который выводится на печать.
Вы получите точно такое же решение, как и в случае с scipy.linalg.solve(). Поскольку эта система имеет единственное решение, определитель матрицы A должен отличаться от нуля. Вы можете подтвердить, что это так, рассчитав его с помощью det() из scipy.linalg:
In [6]: linalg.det(A)
Out[6]:
45102.0
Как и ожидалось, определитель не равен нулю. Это указывает на то, что существует обратная величина A, обозначаемая как A-1 и вычисляемая с помощью inv(A), поэтому система имеет единственное решение. A-1 - это квадратная матрица с теми же размерами, что и A, поэтому произведение A-1 и A приводит к единичной матрице. В этом примере это задается следующим образом:
In [7]: A_inv
Out[7]:
array([[-0.01077558, 0.10655847, -0.03565252, -0.0058534 , -0.00372489],
[ 0.11287748, -0.00512172, -0.04010909, -0.00658507, -0.0041905 ],
[ 0.0052991 , -0.01536517, 0.21300608, -0.01975522, -0.0125715 ],
[-0.0064077 , -0.01070906, -0.02325839, -0.01376879, 0.08214713],
[-0.00931223, -0.01902355, -0.00611946, 0.1183983 , -0.01556472]])
Теперь, когда вы знаете основы использования обратных матриц и определителей, вы увидите, как использовать эти инструменты для нахождения коэффициентов многочленов.
Интерполирующие многочлены с линейными системами
Вы можете использовать линейные системы для вычисления коэффициентов многочленов таким образом, чтобы эти многочлены включали некоторые конкретные точки.
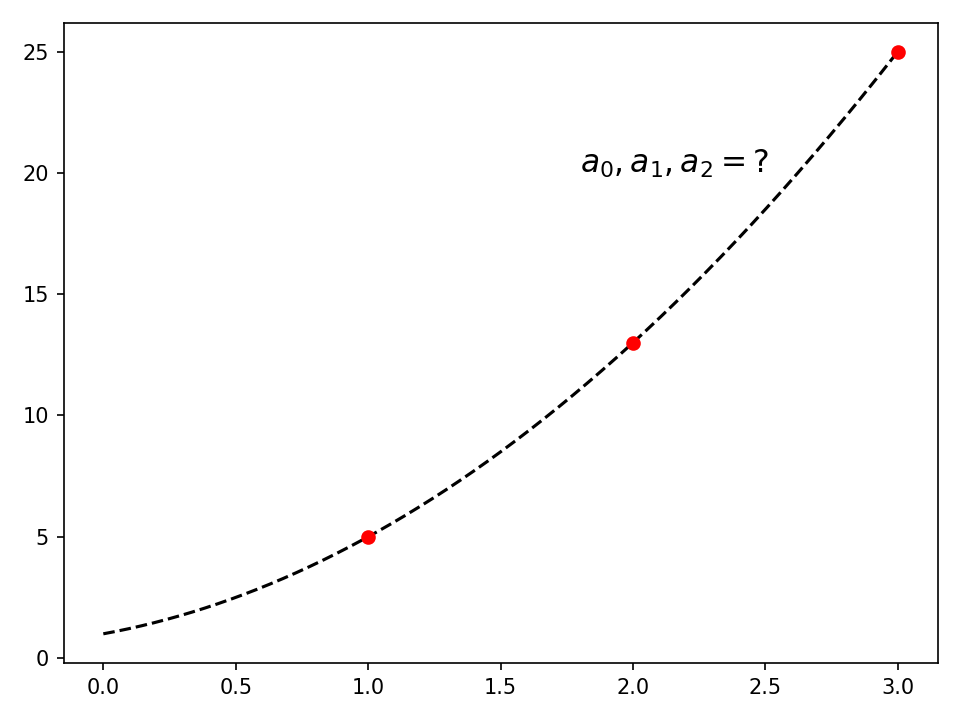
Например, рассмотрим многочлен второй степени y = P(x) = a₀ + a₁x + a₂x2. Напомним, что когда вы строите график многочлена второй степени, вы получаете параболу, которая будет отличаться в зависимости от коэффициентов a₀, a₁ и а₂.
Теперь предположим, что вы хотите найти определенный многочлен второй степени, который включает в себя (x, y) точки (1, 5), (2, 13), и (3, 25). Как вы могли бы вычислить a₀, a₁ и a₂ так, чтобы P(x) включает эти точки в свою параболу? Другими словами, вы хотите найти коэффициенты многочлена на этом рисунке:
Для каждой точки, которую вы хотели бы включить в параболу, вы можете использовать общее выражение многочлена, чтобы получить линейное уравнение. Например, возьмем вторую точку (x=2, y=13), и учтем, что y = a₀ + a₁x + a₂x2, вы могли бы записать следующее уравнение:
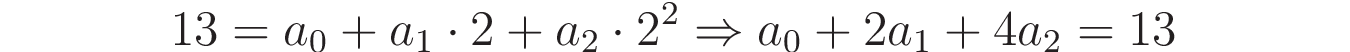
Таким образом, для каждой точки (x, y) вы получите уравнение, включающее a₀, a₁ и a₂. Поскольку вы рассматриваете три разные точки, в итоге у вас получится система из трех уравнений:
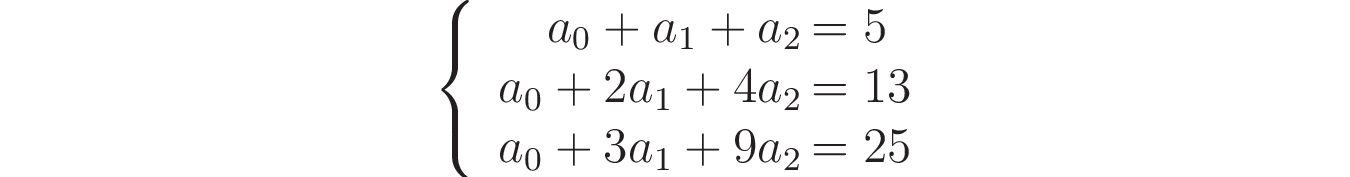
Чтобы проверить, имеет ли эта система уникальное решение, вы можете вычислить определитель матрицы коэффициентов и проверить, не равен ли он нулю. Вы можете сделать это с помощью следующего кода:
In [1]: import numpy as np
...: from scipy import linalg
In [2]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 3, 9]])
In [3]: linalg.det(A)
Out[3]:
1.9999999999999996
Стоит отметить, что существование решения зависит только от A. Поскольку значение определителя не равно нулю, вы можете быть уверены, что для системы существует уникальное решение. Вы можете решить это с помощью метода обратной матрицы со следующим кодом:
In [4]: b = np.array([5, 13, 25]).reshape((3, 1))
In [5]: a = linalg.inv(A) @ b
...: a
Out[5]:
array([[1.],
[2.],
[2.]])
Этот результат говорит о том, что a₀ = 1, a₁ = 2, и a₂ = 2 - это решение для системы. Другими словами, многочлен, включающий точки (1, 5), (2, 13), и (3, 25) задается через y = P( x) = 1 + 2 x + 2 x2. Вы можете протестировать решение для каждой точки, введя x и убедившись, что P(x) равно y.
В качестве примера системы без какого-либо решения, предположим, что вы пытаетесь интерполировать параболу с точками (x, y), заданными через (1, 5), (2, 13), и (2, 25). Если вы внимательно посмотрите на эти цифры, то заметите, что во втором и третьем пунктах x = 2 и разные значения для y, что делает невозможным вычисление найдите функцию, которая включает в себя обе точки.
Выполнив те же действия, что и раньше, вы получите следующие уравнения для этой системы:
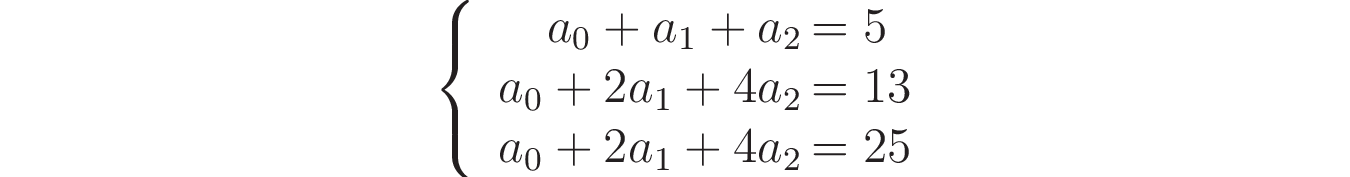
Чтобы подтвердить, что эта система не предлагает однозначного решения, вы можете вычислить определитель матрицы коэффициентов со следующим кодом:
In [6]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 2, 4]])
...: linalg.det(A)
Out[6]:
0.0
Вы можете заметить, что значение определителя равно нулю, что означает, что система не имеет однозначного решения. Это также означает, что обратной матрицы коэффициентов не существует. Другими словами, матрица коэффициентов является сингулярной.
В зависимости от архитектуры вашего компьютера вы можете получить очень малое число вместо нуля. Это происходит из-за числовых алгоритмов, которые det() использует для вычисления определителя. В этих алгоритмах числовые погрешности точности приводят к тому, что этот результат не совсем равен нулю.
В общем, всякий раз, когда вы сталкиваетесь с небольшим числом, вы можете сделать вывод, что у системы нет уникального решения.
Вы можете попробовать решить линейную систему, используя метод обратной матрицы со следующим кодом:
In [7]: b = np.array([5, 13, 25]).reshape((3, 1))
In [8]: x = linalg.inv(A) @ b
---------------------------------------------------------------------------
LinAlgError Traceback (most recent call last)
<ipython-input-10-e6ee9b06a6fe> in <module>
----> 1 x = linalg.inv(A) @ b
LinAlgError: singular matrix
Поскольку система не имеет решения, вы получаете исключение, сообщающее вам, что матрица коэффициентов является сингулярной.
Если система имеет более одного решения, вы получите аналогичный результат. Значение определителя матрицы коэффициентов будет равно нулю или очень мало, что указывает на то, что матрица коэффициентов снова является сингулярной.
В качестве примера системы с несколькими решениями вы можете попытаться интерполировать параболу, учитывая точки (x, y), заданные формулами (1, 5), (2, 13), и (2, 13). Как вы могли заметить, здесь вы рассматриваете две точки в одном и том же положении, что допускает бесконечное число решений для , ₀, , ₁ и а₂.
Теперь, когда вы разобрались, как работать с полиномиальной интерполяцией с использованием линейных систем, вы познакомитесь с другим методом, который позволяет найти коэффициенты для любого набора точек.
Минимизация ошибки с помощью метода Наименьших квадратов
Вы видели, что иногда не удается найти многочлен, который бы точно соответствовал набору точек. Однако обычно, когда вы пытаетесь интерполировать многочлен, вас не интересует точное соответствие. Вы просто ищете решение, которое аппроксимирует точки, обеспечивая минимально возможную ошибку.
Как правило, это происходит, когда вы работаете с реальными данными. Обычно это включает в себя некоторые помехи, вызванные ошибками, возникающими в процессе сбора данных, такими как неточности или неисправности датчиков, а также опечатки, когда пользователи вводят данные вручную.
Используя метод наименьших квадратов, вы можете найти решение для интерполяции многочлена, даже если матрица коэффициентов является сингулярной. Используя этот метод, вы будете искать коэффициенты полинома, которые обеспечивают минимальную квадратичную ошибку при сравнении полиномиальной кривой с вашими точками данных.
На самом деле, метод наименьших квадратов обычно используется для сопоставления многочленов с большими наборами данных. Идея состоит в том, чтобы попытаться разработать модель , которая представляет некоторое наблюдаемое поведение.
Примечание: Если линейная система имеет единственное решение, то решение методом наименьших квадратов будет равно этому единственному решению.
Например, вы могли бы разработать модель, позволяющую прогнозировать цены на автомобили. Для этого вы могли бы собрать некоторые реальные данные, включая цену автомобиля и некоторые другие характеристики, такие как пробег, год выпуска и тип автомобиля. Используя эти данные, вы можете сконструировать полином, который моделирует цену как функцию других характеристик, и использовать метод наименьших квадратов для нахождения оптимальных коэффициентов этой модели.
Вскоре вы начнете работать над моделью для решения этой проблемы. Но сначала вы увидите, как использовать scipy.linalg для построения моделей с использованием метода наименьших квадратов.
Построение моделей наименьших квадратов с использованием scipy.linalg
Для решения задач наименьших квадратов scipy.linalg предоставляет функцию, называемую lstsq(). Чтобы понять, как это работает, рассмотрим предыдущий пример, в котором вы пытались построить параболу в точках (x, y), заданных формулой (1, 5), (2, 13) и (2, 25). Помните, что эта система не имеет решения, так как есть две точки с одинаковым значением для x.
Точно так же, как вы делали это раньше, используя модель y = a₀ + a₁x + a₂x2, вы получите следующую линейную систему :
Используя метод наименьших квадратов, вы можете найти решение для коэффициентов a₀, a₁ и a₂, который представляет собой параболу, минимизирующую квадратичную разницу между кривой и точками данных. Для этого вы можете использовать следующий код:
1In [1]: import numpy as np
2 ...: from scipy import linalg
3
4In [2]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 2, 4]])
5 ...: b = np.array([5, 13, 25]).reshape((3, 1))
6
7In [3]: p, *_ = linalg.lstsq(A, b)
8 ...: p
9Out[3]:
10array([[-0.42857143],
11 [ 1.14285714],
12 [ 4.28571429]])
В этой программе вы настроили следующее:
-
Строки с 1 по 2: Вы импортируете
numpyкакnpиlinalgизscipyв порядок использованияlinalg.lstsq(). -
Строки с 4 по 5: Вы создаете матрицу коэффициентов A, используя массив NumPy с именем
Aи вектор с независимыми членами b, используя массив NumPy, называемыйb. -
Строка 7: Вы вычисляете решение задачи методом наименьших квадратов, используя
linalg.lstsq(), которое использует матрицу коэффициентов и вектор с независимыми членами в качестве входных данных.
lstsq() предоставляет несколько фрагментов информации о системе, включая остатки, ранг и сингулярные значения матрицы коэффициентов. В этом случае вас интересуют только коэффициенты многочлена для решения задачи в соответствии с критериями наименьших квадратов, которые хранятся в p.
Как вы можете видеть, даже при рассмотрении линейной системы, не имеющей точного решения, lstsq() предоставляет коэффициенты, которые минимизируют квадратичные ошибки. С помощью следующего кода вы можете визуализировать решение, полученное путем построения параболы и точек данных:
1In [4]: import matplotlib.pyplot as plt
2
3In [5]: x = np.linspace(0, 3, 1000)
4 ...: y = p[0] + p[1] * x + p[2] * x ** 2
5
6In [6]: plt.plot(x, y)
7 ...: plt.plot(1, 5, "ro")
8 ...: plt.plot(2, 13, "ro")
9 ...: plt.plot(2, 25, "ro")
Эта программа использует matplotlib для построения результатов:
-
Строка 1: Вы импортируете
matplotlib.pyplotкакplt, что является типичным. -
Строки с 3 по 4: Вы создаете массив NumPy с именем
x, значения которого варьируются от0до3, содержащий1000точек. Вы также создаете массив NumPy с именемyс соответствующими значениями модели. -
Строка 6: Вы строите кривую для параболы, полученной с помощью модели, заданной точками в массивах
xиy. -
Строки с 7 по 9: Выделены красным цветом (
"ro"), вы наносите на график три точки, использованные для построения модели.
На выходе должна получиться следующая цифра:
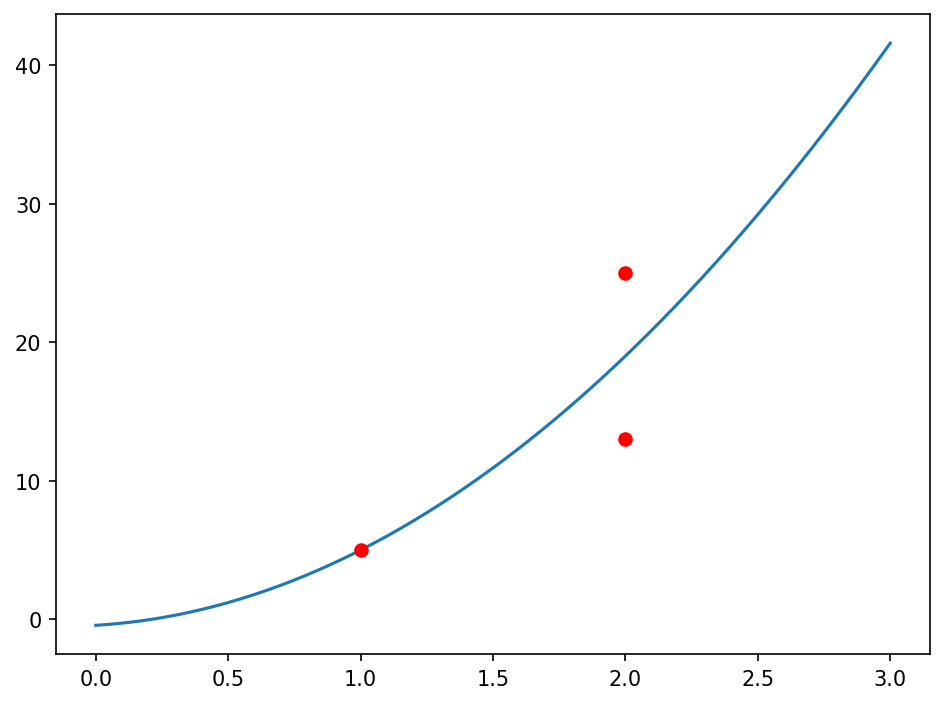
Обратите внимание, как кривая, представленная моделью, пытается максимально приблизить точки.
Помимо lstsq(), существуют и другие способы вычисления решений методом наименьших квадратов с помощью SciPy. Одной из альтернатив является использование псевдообращения , которое вы изучите далее.
Получение решений методом наименьших квадратов с использованием псевдообратной
Другим способом вычисления решения методом наименьших квадратов является использование псевдообратной матрицы Мура-Пенроуза матрицы.
Вы можете рассматривать псевдообратную матрицу как обобщение обратной матрицы, поскольку она равна обычной обратной матрице, когда матрица не является сингулярной.
Однако, когда матрица является сингулярной, что имеет место в линейных системах, не имеющих однозначного решения, псевдообратная вычисляет матрицу, которая обеспечивает наилучшее соответствие, что приводит к решению методом наименьших квадратов.
Используя псевдообрат, вы можете найти коэффициенты для параболы, использованной в предыдущем примере:
1In [1]: import numpy as np
2 ...: from scipy import linalg
3
4In [2]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 2, 4]])
5 ...: b = np.array([5, 13, 25]).reshape((3, 1))
6
7In [3]: A_pinv = linalg.pinv(A)
8
9In [4]: p2 = A_pinv @ b
10 ...: p2
11Out[4]:
12array([[-0.42857143],
13 [ 1.14285714],
14 [ 4.28571429]])
Этот код очень похож на код из предыдущего раздела, за исключением выделенных строк:
-
Строка 7: Вы вычисляете псевдообратную матрицу коэффициентов и сохраняете ее в
A_pinv. -
Строка 9: Следуя тому же подходу, который используется для решения линейных систем с обратной матрицей, вы вычисляете коэффициенты уравнения параболы, используя псевдообратную формулу, и сохраняете их в векторе
p2.
Как и следовало ожидать, решение методом наименьших квадратов совпадает с решением lstsq(). В этом случае, поскольку A является квадратной матрицей, pinv() предоставит квадратную матрицу с теми же размерами, что и A, оптимизируя для наилучшее соответствие в смысле наименьших квадратов:
In [5]: A_pinv
Out[5]:
array([[ 1. , -0.14285714, -0.14285714],
[ 0.5 , -0.03571429, -0.03571429],
[-0.5 , 0.17857143, 0.17857143]])
Однако стоит отметить, что вы также можете вычислить pinv() для неквадратичных матриц, что обычно имеет место на практике. Далее вы углубитесь в это на примере использования реальных данных.
Пример: Прогнозирование цен на автомобили с помощью метода Наименьших квадратов
В этом примере вы собираетесь построить модель с использованием метода наименьших квадратов для прогнозирования цен на подержанные автомобили, используя данные из набора данных Подержанные автомобили. Этот набор данных представляет собой огромную коллекцию, содержащую 957 МБ списков транспортных средств из craigslist.org, включая самые разные типы транспортных средств.
При работе с реальными данными часто возникает необходимость выполнить некоторые действия по фильтрации и очистке, чтобы использовать данные для построения модели. В этом случае необходимо сузить круг типов транспортных средств, которые вы будете включать, чтобы получить лучшие результаты с вашей моделью.
Поскольку основное внимание здесь уделяется использованию метода наименьших квадратов для построения модели, вы начнете с очищенного набора данных, который является небольшим подмножеством исходного. Прежде чем приступить к работе над кодом, получите CSV-файл с очищенными данными, перейдя по ссылке ниже и перейдя по ссылке vehicles_cleaned.csv:
Бесплатный исходный код: Нажмите здесь, чтобы загрузить бесплатный код и набор данных, которые вы будете использовать для работы с линейными системами и алгеброй в Python с scipy.linalg.
Среди загружаемых материалов вы также можете ознакомиться с записной книжкой Jupyter, чтобы узнать больше о подготовке данных.
Подготовка данных
Чтобы загрузить CSV-файл и обработать данные, вы будете использовать pandas. Итак, убедитесь, что вы установили его в conda среде linalg следующим образом:
(linalg) $ conda install pandas
После загрузки данных и настройки pandas вы можете запустить новый Jupyter Notebook и загрузить данные, выполнив следующий блок кода:
In [1]: import pandas as pd
...: cars_data = pd.read_csv("vehicles_cleaned.csv")
Это создаст фрейм данных pandas с именем cars_data, содержащий данные из CSV-файла. Из этого фрейма данных вы сгенерируете числовые массивы, которые будете использовать в качестве входных данных для lstsq() и pinv(), чтобы получить решение методом наименьших квадратов. Чтобы узнать больше о том, как использовать pandas для обработки данных, ознакомьтесь с разделом Использование pandas и Python для изучения вашего набора данных.
Объект DataFrame содержит атрибут с именем columns, который позволяет вам просматривать названия столбцов, включенных в данные. Это означает, что вы можете проверить столбцы, включенные в этот набор данных, с помощью следующего кода:
In [2]: cars_data.columns
Out[2]:
Index(['price', 'year', 'condition', 'cylinders', 'fuel', 'odometer',
'transmission', 'size', 'type'],
dtype='object')
Вы можете заглянуть в одну из строк фрейма данных, используя .iloc:
In [3]: cars_data.iloc[0]
Out[3]:
price 7000
year 2011
condition good
cylinders 4 cylinders
fuel gas
odometer 76202
transmission automatic
size compact
type sedan
Name: 0, dtype: object
Как вы можете видеть, этот набор данных включает в себя девять столбцов со следующими данными:
| Название столбца | Описание |
|---|---|
Цена |
Цена автомобиля, это столбец, который вы хотите предсказать с помощью вашей модели |
год |
Год выпуска автомобиля |
состояние |
Категориальная переменная, которая может принимать значения хорошее, удовлетворительное, отличное, как новый, утилизированный или новый |
цилиндры |
Категориальная переменная, которая может принимать значения 4 цилиндра или 6 цилиндров |
топливо |
Категориальная переменная, которая может принимать значения бензин или дизель |
одометр |
Пробег транспортного средства, указанный на одометре |
трансмиссия |
Категориальная переменная, которая может принимать значения автоматическая или механическая |
размер |
Категорийное значение, которое может принимать значения компактный, средний, субкомпактный или полный |
тип |
Категорийное значение, которое может принимать значения седан, купе, универсал или хэтчбек |
Чтобы использовать эти данные для построения модели наименьших квадратов, вам необходимо представить категориальные данные в числовом виде. В большинстве случаев категориальные данные преобразуются в набор фиктивных переменных, которые могут принимать значения 0 или 1.
В качестве примера такого преобразования рассмотрим столбец fuel, который может принимать значение gas или diesel. Вы могли бы преобразовать этот категориальный столбец в фиктивный столбец с именем fuel_gas, который принимает значение 1, когда fuel равно gas и 0, когда fuel равно diesel.
Обратите внимание, что вам понадобится всего один фиктивный столбец для представления категориального столбца, который может принимать два разных значения. Аналогично, для категориального столбца, который может принимать N значений, вам понадобятся N-1 фиктивных столбцов, поскольку одно из значений будет приниматься как значение по умолчанию.
В pandas вы можете преобразовать эти категориальные столбцы в фиктивные столбцы с помощью get_dummies():
In [4]: cars_data_dummies = pd.get_dummies(
...: cars_data,
...: columns=[
...: "condition",
...: "cylinders",
...: "fuel",
...: "transmission",
...: "size",
...: "type",
...: ],
...: drop_first=True,
...: )
Здесь вы создаете новый фрейм данных с именем cars_data_dummies, который включает фиктивные переменные для столбцов, указанных в аргументе columns. Теперь вы можете проверить новые столбцы, включенные в этот фрейм данных:
In [5]: cars_data_dummies.columns
Out[5]:
Index(['price', 'year', 'odometer', 'condition_fair', 'condition_good',
'condition_like new', 'condition_new', 'condition_salvage',
'cylinders_6 cylinders', 'fuel_gas', 'transmission_manual',
'size_full-size', 'size_mid-size', 'size_sub-compact', 'type_hatchback',
'type_sedan', 'type_wagon'],
dtype='object')
Теперь, когда вы преобразовали категориальные переменные в наборы фиктивных переменных, вы можете использовать эту информацию для построения своей модели. В принципе, модель будет включать коэффициент для каждого из этих столбцов, за исключением price, который будет использоваться в качестве выходных данных модели. Цена будет определяться взвешенной комбинацией других переменных, где веса задаются коэффициентами модели.
Однако обычно учитывается дополнительный коэффициент, представляющий собой постоянное значение, которое добавляется к взвешенной комбинации других переменных. Этот коэффициент известен как перехват, и вы можете включить его в свою модель, добавив к данным дополнительный столбец, все строки которого равны 1:
In [6]: cars_data_dummies["intercept"] = 1
Теперь, когда все данные упорядочены, вы можете сгенерировать массивы NumPy для построения вашей модели, используя scipy.linalg. Это то, что вы будете делать дальше.
Построение модели
Чтобы сгенерировать числовые массивы для ввода в lstsq() или pinv(), вы можете использовать .to_numpy():
In [7]: A = cars_data_dummies.drop(columns=["price"]).to_numpy()
...: b = cars_data_dummies.loc[:, "price"].to_numpy()
Матрица коэффициентов A задается по всем столбцам, кроме price. Вектор b с независимыми членами задается значениями, которые вы хотите предсказать, в данном случае это столбец price. Установив A и b, вы можете использовать lstsq() для нахождения решения методом наименьших квадратов для коэффициентов:
In [8]: from scipy import linalg
In [9]: p, *_ = linalg.lstsq(A, b)
...: p
Out[9]:
array([ 8.47362988e+02, -3.53913729e-02, -3.47144752e+03, -1.66981155e+03,
-1.80240398e+02, -7.15885691e+03, -6.36540791e+03, 3.76583261e+03,
-1.84837210e+03, 1.31935783e+03, 6.60484388e+02, 6.38913933e+02,
1.54163679e+02, -1.76423109e+03, -1.99439766e+03, 6.97365788e+02,
-1.68998811e+06])
Это коэффициенты, которые вы должны использовать для моделирования price в терминах взвешенной комбинации других переменных, чтобы минимизировать квадратичную ошибку. Как вы уже видели, эти коэффициенты также можно получить, используя pinv() со следующим кодом:
In [10]: p2 = linalg.pinv(A) @ b
...: p2
Out[10]:
array([ 8.47362988e+02, -3.53913729e-02, -3.47144752e+03, -1.66981155e+03,
-1.80240398e+02, -7.15885691e+03, -6.36540791e+03, 3.76583261e+03,
-1.84837210e+03, 1.31935783e+03, 6.60484388e+02, 6.38913933e+02,
1.54163679e+02, -1.76423109e+03, -1.99439766e+03, 6.97365788e+02,
-1.68998811e+06])
Одной из приятных характеристик модели линейной регрессии является то, что ее довольно легко интерпретировать. В этом случае из коэффициентов можно сделать вывод, что стоимость автомобиля увеличивается примерно на 847 долларов при увеличении year на 1, что означает, что стоимость автомобиля уменьшается на 847 долларов в год с учетом возраста автомобиля. Аналогично, согласно второму коэффициенту, стоимость автомобиля уменьшается примерно на 35,39 доллара за 1000 миль.
Теперь, когда вы получили модель, вы можете использовать ее для прогнозирования цены автомобиля.
Прогнозирование цен
Используя модель, заданную методом наименьших квадратов, вы можете предсказать цену автомобиля, представленную вектором со значениями для каждой из переменных, используемых в модели:
In [11]: cars_data_dummies.drop(columns=["price"]).columns
Out[11]:
Index(['year', 'odometer', 'condition_fair', 'condition_good',
'condition_like new', 'condition_new', 'condition_salvage',
'cylinders_6 cylinders', 'fuel_gas', 'transmission_manual',
'size_full-size', 'size_mid-size', 'size_sub-compact', 'type_hatchback',
'type_sedan', 'type_wagon', 'intercept'],
dtype='object')
Итак, 4-цилиндровый хэтчбек 2010 года выпуска, с автоматической коробкой передач, газовым топливом и пробегом 50 000 миль в хорошем состоянии можно представить следующим вектором:
In [12]: import numpy as np
...: car = np.array(
...: [2010, 50000, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1]
...: )
Вы можете получить прогноз цены, вычислив точечное произведение между вектором car и вектором p коэффициентов. Поскольку оба вектора являются одномерными числовыми массивами, вы можете использовать @ для получения скалярного произведения:
In [13]: predicted_price = p @ car
...: predicted_price
Out[13]:
6159.510724281656
В этом примере прогнозируемая цена хэтчбека составляет приблизительно 6160 долларов. Стоит отметить, что коэффициенты модели содержат некоторую неопределенность, поскольку данные, используемые для построения модели, могут быть смещены, например, в сторону определенного типа автомобиля.
Кроме того, выбор модели играет большую роль в качестве оценок. Метод наименьших квадратов - один из наиболее часто используемых методов построения моделей, поскольку он прост и позволяет получить объяснимые модели. В этом примере вы увидели, как использовать scipy.linalg для построения таких моделей. Для получения более подробной информации о моделях наименьших квадратов ознакомьтесь с Линейной регрессией в Python..
Заключение
Поздравляем! Вы научились использовать некоторые концепции линейной алгебры в Python для решения задач, связанных с линейными моделями. Вы обнаружили, что векторы и матрицы полезны для представления данных и что, используя линейные системы, вы можете моделировать практические задачи и эффективно их решать.
В этом руководстве вы узнали, как:
- Изучайте линейные системы, используя определители и решайте задачи, используя обратные матрицы
- Интерполируйте многочлены, чтобы они соответствовали набору точек, используя линейные системы
- Используйте Python для решения задач линейной регрессии
- Используйте линейную регрессию для прогнозирования цен на основе исторических данных
Линейная алгебра - очень обширная тема. Для получения дополнительной информации о некоторых других приложениях линейной алгебры ознакомьтесь со следующими ресурсами:
- Работа с линейными системами на Python с
scipy.linalg - Scientific Python: Использование SciPy для оптимизации
- Практическое линейное программирование: Оптимизация с помощью Python
- NumPy, SciPy и pandas: Корреляция с Python