Первые шаги с PySpark и обработкой больших данных
Оглавление
- Концепции больших данных в Python
- Привет, мир в PySpark
- Что такое Искра?
- Что такое PySpark?
- API и структуры данных PySpark
- Установка PySpark
- Запуск программ PySpark
- Объединение PySpark с Другими Инструментами
- Следующие шаги для реальной обработки больших объемов данных
- Заключение
Все чаще приходится сталкиваться с ситуациями, когда объем данных просто слишком велик для обработки на одном компьютере. К счастью, такие технологии, как Apache Spark, Hadoop и другие, были разработаны именно для решения этой проблемы. Мощь этих систем может быть использована непосредственно на Python с помощью PySpark!
Эффективная обработка наборов данных объемом в гигабайт и более доступна любому разработчику на Python, независимо от того, являетесь ли вы специалистом по обработке данных, веб-разработчиком или кем-то средним между ними.
В этом уроке вы узнаете:
- Какие концепции Python можно применить к большим данным
- Как использовать Apache Spark и PySpark
- Как писать базовые программы PySpark
- Как локально запускать программы PySpark на небольших наборах данных
- Что делать дальше, чтобы применить свои навыки PySpark в распределенной системе
Скачать бесплатно: Ознакомьтесь с примером главы из книги "Приемы работы с Python: Книга", в которой показаны лучшие практики Python на простых примерах, которые вы можете подайте заявку немедленно, чтобы написать более красивый + Pythonic код.
Концепции больших данных в Python
Несмотря на свою популярность как просто язык сценариев, Python предоставляет несколько парадигм программирования например, массиво-ориентированное программирование, объектно-ориентированное программирование, асинхронное программирование и многие другие. Одной из парадигм, представляющих особый интерес для начинающих специалистов по работе с большими данными, является функциональное программирование.
Функциональное программирование - это распространенная парадигма, когда вы имеете дело с большими данными. Написание функциональным способом приводит к ошеломляюще параллельному коду. Это означает, что проще взять ваш код и запустить его на нескольких процессорах или даже на совершенно разных машинах. Вы можете обойти ограничения на физическую память и процессорные возможности одной рабочей станции, запустив его одновременно на нескольких системах.
В этом и заключается мощь экосистемы PySpark, позволяющей вам брать функциональный код и автоматически распределять его по целому кластеру компьютеров.
К счастью для программистов на Python, многие из основных идей функционального программирования доступны в стандартной библиотеке и встроенных модулях Python. Вы можете изучить многие концепции, необходимые для обработки больших объемов данных, не выходя из Python.
Основная идея функционального программирования заключается в том, что функции должны манипулировать данными без сохранения какого-либо внешнего состояния. Это означает, что ваш код избегает глобальных переменных и всегда возвращает новые данные вместо того, чтобы манипулировать данными на месте.
Еще одной распространенной идеей в функциональном программировании является анонимные функции. Python предоставляет анонимные функции, используя lambda ключевое слово, которое не следует путать с Лямбда-функциями AWS.
Теперь, когда вы знакомы с некоторыми терминами и концепциями, вы можете изучить, как эти идеи проявляются в экосистеме Python.
Лямбда-функции
лямбда-функции в Python определены встроенно и ограничены одним выражением. Вероятно, вы уже видели lambda функций при использовании встроенной функции sorted():
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(sorted(x))
['Python', 'awesome!', 'is', 'programming']
>>> print(sorted(x, key=lambda arg: arg.lower()))
['awesome!', 'is', 'programming', 'Python']
Параметр key, равный sorted, вызывается для каждого элемента в повторяемом. Это делает сортировку нечувствительной к регистру, изменяя все строки на строчные перед сортировкой.
Это обычный вариант использования для lambda функций, небольших анонимных функций, которые не поддерживают внешнее состояние.
В Python также существуют другие распространенные функции функционального программирования, такие как filter(), map(), и reduce(). Все эти функции могут использовать функции lambda или стандартные функции, определенные с помощью def аналогичным образом.
filter(), map(), и reduce()
Встроенные функции filter(), map(), и reduce() широко распространены в функциональном программировании. Вскоре вы увидите, что эти концепции могут составлять значительную часть функциональности программы PySpark.
Важно понимать эти функции в контексте основного языка Python. Затем вы сможете применить полученные знания в программах PySpark и Spark API.
filter() отфильтровывает элементы из повторяющегося списка на основе условия, обычно выражаемого в виде функции lambda:
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(filter(lambda arg: len(arg) < 8, x)))
['Python', 'is']
filter() принимает итерацию, вызывает функцию lambda для каждого элемента и возвращает элементы, для которых lambda возвращено True.
Примечание: Вызов list() необходим, потому что filter() также является повторяемым. filter() выдает вам значения только в том виде, в каком вы их использовали. выполните цикл по ним. list() помещает все элементы в память сразу, вместо того чтобы использовать цикл.
Вы можете представить, что используете filter() для замены обычного шаблона for loop, подобного следующему:
def is_less_than_8_characters(item):
return len(item) < 8
x = ['Python', 'programming', 'is', 'awesome!']
results = []
for item in x:
if is_less_than_8_characters(item):
results.append(item)
print(results)
Этот код собирает все строки, содержащие менее 8 символов. Код более подробный, чем в примере filter(), но он выполняет ту же функцию с теми же результатами.
Еще одно менее очевидное преимущество filter() заключается в том, что оно возвращает повторяемую строку. Это означает, что filter() не требует, чтобы на вашем компьютере было достаточно памяти для одновременного хранения всех элементов в повторяемой строке. Это становится все более важным при работе с большими массивами данных, размер которых может быстро вырасти до нескольких гигабайт.
map() аналогичен filter() в том, что он применяет функцию к каждому элементу в iterable, но всегда создает сопоставление исходных элементов 1 к 1. Новая итерируемая , которую возвращает map(), всегда будет содержать то же количество элементов, что и исходная итерируемая, чего не было в случае с filter():
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(map(lambda arg: arg.upper(), x)))
['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME!']
map() автоматически вызывает функцию lambda для всех элементов, эффективно заменяя цикл for следующим образом:
results = []
x = ['Python', 'programming', 'is', 'awesome!']
for item in x:
results.append(item.upper())
print(results)
Цикл for приводит к тому же результату, что и в примере map(), который собирает все элементы в их верхнем регистре. Однако, как и в примере с filter(), map() возвращает значение iterable, что снова позволяет обрабатывать большие наборы данных, которые слишком велики, чтобы полностью поместиться в памяти.
Наконец, последним из функционального трио стандартной библиотеки Python является reduce(). Как и в случае с filter() и map(), reduce() применяет функцию к элементам в итерационной переменной.
Опять же, применяемая функция может быть стандартной функцией Python, созданной с помощью ключевого слова def или функции lambda.
Однако, reduce() не возвращает новую повторяемую строку. Вместо этого, reduce() использует функцию, вызываемую для сокращения повторяемой строки до одного значения:
>>> from functools import reduce
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(reduce(lambda val1, val2: val1 + val2, x))
Pythonprogrammingisawesome!
Этот код объединяет все элементы в iterable, слева направо, в один элемент. Здесь нет вызова list(), потому что reduce() уже возвращает один элемент.
Примечание: Python 3.x переместил встроенную функцию reduce() в пакет functools.
lambda, map(), filter(), и reduce() - это понятия, которые существуют во многих языках и могут быть использованы в обычных программах на Python. Вскоре вы увидите, что эти концепции распространяются на API PySpark для обработки больших объемов данных.
Наборы
Наборы - это еще одна распространенная функциональность, которая существует в стандартном Python и широко используется при обработке больших данных. Наборы очень похожи на списки, за исключением того, что они не имеют никакого порядка и не могут содержать повторяющихся значений. Вы можете представить себе набор, аналогичный ключам в Python dict.
Привет, мир в PySpark
Как и в любом хорошем учебнике по программированию, вы захотите начать с примера Hello World. Ниже приведен эквивалент PySpark:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python3/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())
Пока не беспокойтесь обо всех деталях. Основная идея заключается в том, чтобы помнить, что программа на PySpark мало чем отличается от обычной программы на Python.
Примечание: Эта программа, скорее всего, вызовет Исключение в вашей системе, если у вас еще не установлен PySpark или нет указанный copyright файл, как это сделать, вы увидите позже. Название каталога также может немного отличаться. Например, это может быть python вместо python3.
Скоро вы узнаете все подробности этой программы, но посмотрите внимательно. Программа подсчитывает общее количество строк и количество строк, содержащих слово python в файле с именем copyright.
Помните, программа PySpark не сильно отличается от обычной программы на Python, но модель выполнения может сильно отличаться от обычной программы на Python. обычная программа на Python, особенно если вы работаете в кластере.
За кулисами может происходить множество событий, которые распределяют обработку по нескольким узлам, если вы работаете в кластере. Однако пока представьте себе программу на Python, использующую библиотеку PySpark.
Теперь, когда вы ознакомились с некоторыми общими функциональными концепциями, существующими в Python, а также с простой программой PySpark, пришло время углубиться в Spark и PySpark.
Что такое Spark?
Apache Spark состоит из нескольких компонентов, поэтому его описание может быть затруднено. По своей сути, Spark является универсальным движком для обработки больших объемов данных.
Spark написан на Scala и запускается на JVM. В Spark есть встроенные компоненты для обработки потоковых данных, машинного обучения, обработки графиков и даже взаимодействия с данными через SQL.
В этом руководстве вы узнаете только об основных компонентах Spark для обработки больших данных. Однако все остальные компоненты, такие как машинное обучение, SQL и т.д., также доступны для проектов на Python через PySpark.
Что такое PySpark?
Spark реализован на Scala, языке, который работает на JVM, так как же вы можете получить доступ ко всем этим функциям через Python?
Ответ - это PySpark.
Текущая версия PySpark - 2.4.3, она работает с Python 2.7, 3.3 и выше.
Вы можете рассматривать PySpark как оболочку на основе Python поверх Scala API. Это означает, что у вас есть два набора документации, на которые нужно ссылаться:
В документах PySpark API есть примеры, но часто вам захочется обратиться к документации Scala и перевести код на синтаксис Python для ваших программ на PySpark. К счастью, Scala - очень читаемый функциональный язык программирования.
PySpark взаимодействует с API, основанным на Spark Scala, через библиотеку Py4J. Py4J не является специфичным для PySpark или Spark. Py4J позволяет любой программе на Python взаимодействовать с кодом на основе JVM.
Есть две причины, по которым PySpark основан на функциональной парадигме:
- Родной язык Spark, Scala, основан на функциональности.
- Функциональный код гораздо проще распараллеливать.
Еще одно представление о PySpark - это библиотека, которая позволяет обрабатывать большие объемы данных на одной машине или кластере машин.
В контексте Python подумайте о PySpark как о способе обработки параллельной обработки без необходимости в модулях threading или multiprocessing. Вся сложная коммуникация и синхронизация между потоками, процессами и даже разными процессорами осуществляется с помощью Spark.
API и структуры данных PySpark
Для взаимодействия с PySpark вы создаете специализированные структуры данных, называемые Устойчивыми распределенными наборами данных (RDDS).
RDDS скрывают всю сложность автоматического преобразования и распределения ваших данных по нескольким узлам с помощью планировщика, если вы работаете в кластере.
Чтобы лучше понять API и структуры данных PySpark, вспомните программу Hello World, упомянутую ранее:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python3/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())
Точкой входа в любую программу PySpark является объект SparkContext. Этот объект позволяет подключаться к кластеру Spark и создавать RDDS. Строка local[*] - это специальная строка, обозначающая, что вы используете локальный кластер, что является еще одним способом сказать, что вы работаете в режиме одной машины. * указывает Spark создать столько рабочих потоков, сколько логических ядер на вашем компьютере.
Создание SparkContext может быть более сложным, если вы используете кластер. Чтобы подключиться к кластеру Spark, вам, возможно, потребуется выполнить аутентификацию и некоторые другие действия, относящиеся к вашему кластеру. Вы можете настроить эти данные аналогично следующему:
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)
Вы можете приступить к созданию RDDS, как только у вас будет SparkContext.
Вы можете создавать RDD несколькими способами, но одним из распространенных способов является функция PySpark parallelize(). parallelize() может преобразовывать некоторые структуры данных Python, такие как списки и кортежи, в RDD, что дает вам функциональность, которая делает их отказоустойчивый и распределенный.
Чтобы лучше понять RDDS, рассмотрим другой пример. Следующий код создает итератор из 10 000 элементов, а затем использует parallelize() для распределения этих данных на 2 секции:
>>> big_list = range(10000)
>>> rdd = sc.parallelize(big_list, 2)
>>> odds = rdd.filter(lambda x: x % 2 != 0)
>>> odds.take(5)
[1, 3, 5, 7, 9]
parallelize() превращает этот итератор в распределенный набор чисел и предоставляет вам все возможности инфраструктуры Spark.
Обратите внимание, что в этом коде используется метод RDD filter() вместо встроенного метода Python filter(), который вы видели ранее. Результат тот же, но то, что происходит за кулисами, кардинально отличается. При использовании метода RDD filter() эта операция выполняется распределенным образом между несколькими процессорами или компьютерами.
Опять же, представьте, что Spark выполняет multiprocessing работу за вас, и все это инкапсулировано в структуру данных RDD.
take() это способ просмотреть содержимое вашего RDD, но только небольшое подмножество. take() извлекает это подмножество данных из распределенной системы на одну машину.
take() это важно для отладки, поскольку проверка всего набора данных на одном компьютере может оказаться невозможной. RDD оптимизированы для работы с большими объемами данных, поэтому в реальных условиях на одном компьютере может не хватить оперативной памяти для хранения всего набора данных.
Примечание: Spark временно выводит информацию в stdout при запуске примеров, подобных этому, в командной строке, что вы скоро увидите, как это сделать. Ваш stdout может временно отображать что-то вроде [Stage 0:> (0 + 1) / 1].
В тексте stdout показано, как Spark разбивает RDD и обрабатывает ваши данные на несколько этапов на разных процессорах и машинах.
Другой способ создания RDD - это чтение в файле с textFile(), который вы видели в предыдущих примерах. RDDS являются одной из базовых структур данных для использования PySpark, поэтому многие функции в API возвращают RDDS.
Одно из ключевых различий между RDDS и другими структурами данных заключается в том, что обработка задерживается до тех пор, пока не будет запрошен результат. Это похоже на Генератор Python. Разработчики в экосистеме Python обычно используют термин ленивая оценка для объяснения такого поведения.
Вы можете объединить несколько преобразований в одном RDD без какой-либо обработки. Эта функциональность возможна, потому что Spark поддерживает направленный ациклический граф преобразований. Базовый график активируется только при запросе окончательных результатов. В предыдущем примере вычисления не производились до тех пор, пока вы не запросили результаты по вызову take().
Существует несколько способов запросить результаты из RDD. Вы можете явно запросить результаты для оценки и сбора в одном узле кластера, используя collect() в RDD. Вы также можете неявно запросить результаты различными способами, одним из которых было использование count(), как вы видели ранее.
Примечание: Будьте осторожны при использовании этих методов, поскольку они загружают весь набор данных в память, что не сработает, если набор данных слишком велик, чтобы поместиться в оперативной памяти одной машины.
Опять же, обратитесь к Документации по API PySpark для получения более подробной информации обо всех возможных функциональных возможностях.
Установка PySpark
Как правило, вы запускаете программы PySpark в кластере Hadoop, но поддерживаются и другие варианты развертывания кластера. Вы можете прочитать Обзор кластерного режима Spark для получения более подробной информации.
Примечание: Настройка одного из этих кластеров может быть сложной и выходит за рамки данного руководства. В идеале, в вашей команде должны быть мастера инженеры DevOps, которые помогут вам в этом. Если нет, Hadoop опубликует руководство, которое поможет вам.
В этом руководстве вы увидите несколько способов запуска программ PySpark на вашем локальном компьютере. Это полезно для тестирования и обучения, но вскоре вам захочется использовать свои новые программы и запускать их в кластере, чтобы по-настоящему обрабатывать большие объемы данных.
Иногда настройка PySpark сама по себе также может быть сложной задачей из-за наличия всех необходимых зависимостей.
PySpark работает поверх JVM и требует для функционирования большого количества базовой инфраструктуры Java. Как бы то ни было, мы живем в эпоху Docker, что значительно упрощает эксперименты с PySpark.
Что еще лучше, замечательные разработчики, стоящие за Jupyter, сделали всю тяжелую работу за вас. Они публикуют Dockerfile, который включает в себя все зависимости от PySpark вместе с Jupiter. Таким образом, вы можете поэкспериментировать непосредственно в записной книжке Jupyter!
Примечание: Ноутбуки Jupyter обладают большим количеством функциональных возможностей. Проверять Записная книжка Jupyter: Введение более подробная информация о том, как эффективно использовать записные книжки.
Сначала вам нужно установить Docker. Взгляните на Создание надежной непрерывной интеграции с Docker и друзьями, если у вас еще не установлен Docker.
Примечание: Изображения Docker могут быть довольно большими, поэтому убедитесь, что вы согласны использовать около 5 Гб дискового пространства для использования PySpark и Jupyter.
Далее вы можете выполнить следующую команду для загрузки и автоматического запуска контейнера Docker с предварительно созданной настройкой одного узла PySpark. Выполнение этой команды может занять несколько минут, поскольку она загружает изображения непосредственно из DockerHub вместе со всеми требованиями для Spark, PySpark и Jupyter:
$ docker run -p 8888:8888 jupyter/pyspark-notebook
Как только эта команда прекратит вывод на печать, у вас будет запущенный контейнер, в котором есть все необходимое для тестирования ваших программ PySpark в одноузловой среде.
Чтобы остановить контейнер, введите Ctrl+C в том же окне, в котором вы ввели команду docker run..
Теперь пришло время, наконец, запустить некоторые программы!
Запуск программ PySpark
Существует несколько способов запуска программ PySpark, в зависимости от того, предпочитаете ли вы командную строку или более наглядный интерфейс. Для интерфейса командной строки вы можете использовать команду spark-submit, стандартную оболочку Python или специализированную оболочку PySpark.
Во-первых, вы увидите более наглядный интерфейс Jupyter notebook.
Записная книжка Jupyter
Вы можете запустить свою программу в Jupyter notebook, выполнив следующую команду для запуска ранее загруженного контейнера Docker (если он еще не запущен):
$ docker run -p 8888:8888 jupyter/pyspark-notebook
Executing the command: jupyter notebook
[I 08:04:22.869 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret
[I 08:04:25.022 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab
[I 08:04:25.022 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 08:04:25.027 NotebookApp] Serving notebooks from local directory: /home/jovyan
[I 08:04:25.028 NotebookApp] The Jupyter Notebook is running at:
[I 08:04:25.029 NotebookApp] http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
[I 08:04:25.029 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 08:04:25.037 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/nbserver-6-open.html
Or copy and paste one of these URLs:
http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
Теперь у вас есть контейнер, запущенный с помощью PySpark. Обратите внимание, что в конце вывода команды docker run упоминается локальный URL-адрес.
Примечание: Результат выполнения команд docker будет немного отличаться на каждом компьютере, поскольку токены, идентификаторы контейнеров и названия контейнеров генерируются случайным образом.
Вам необходимо использовать этот URL-адрес для подключения к контейнеру Docker, в котором запущен Jupyter в веб-браузере. Скопируйте и вставьте URL-адрес из ваших выходных данных непосредственно в ваш веб-браузер. Вот пример URL-адреса, который вы, скорее всего, увидите:
$ http://127.0.0.1:8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
URL-адрес в приведенной ниже команде, вероятно, будет немного отличаться на вашем компьютере, но как только вы подключитесь к этому URL-адресу в своем браузере, вы сможете получить доступ к среде Jupyter notebook, которая должна выглядеть примерно так:
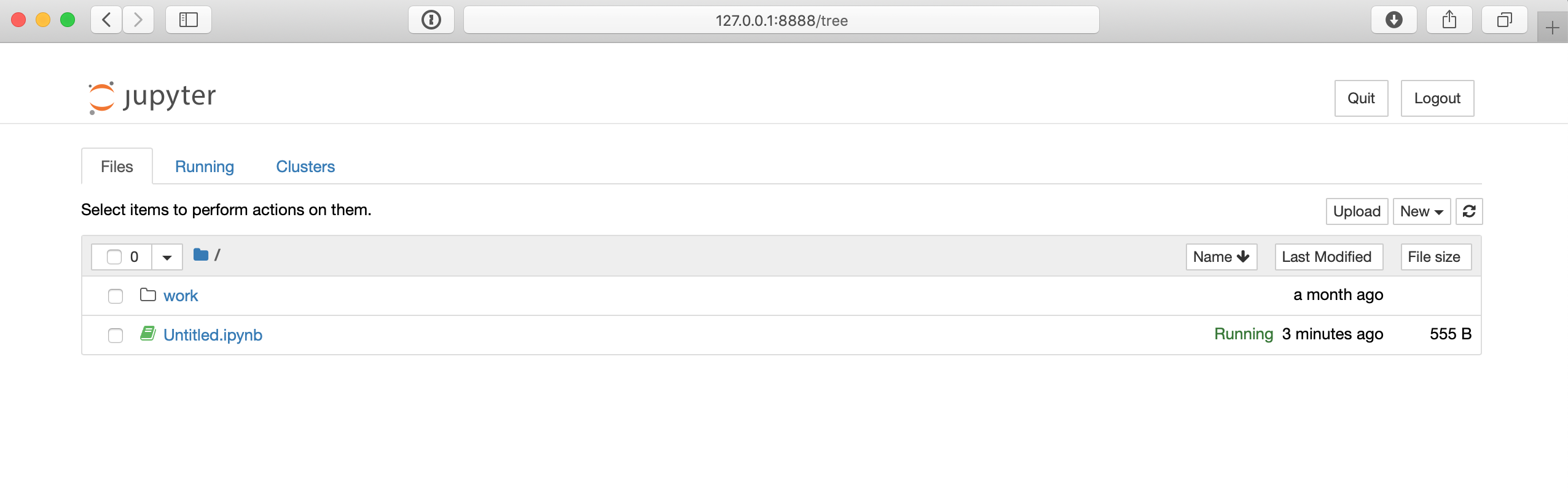
На странице Jupyter notebook вы можете использовать кнопку Создать в крайнем правом углу, чтобы создать новую оболочку Python 3. Затем вы можете протестировать какой-нибудь код, например, в примере Hello World, приведенном ранее:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python3/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())
Вот как будет выглядеть запуск этого кода в Jupyter notebook:
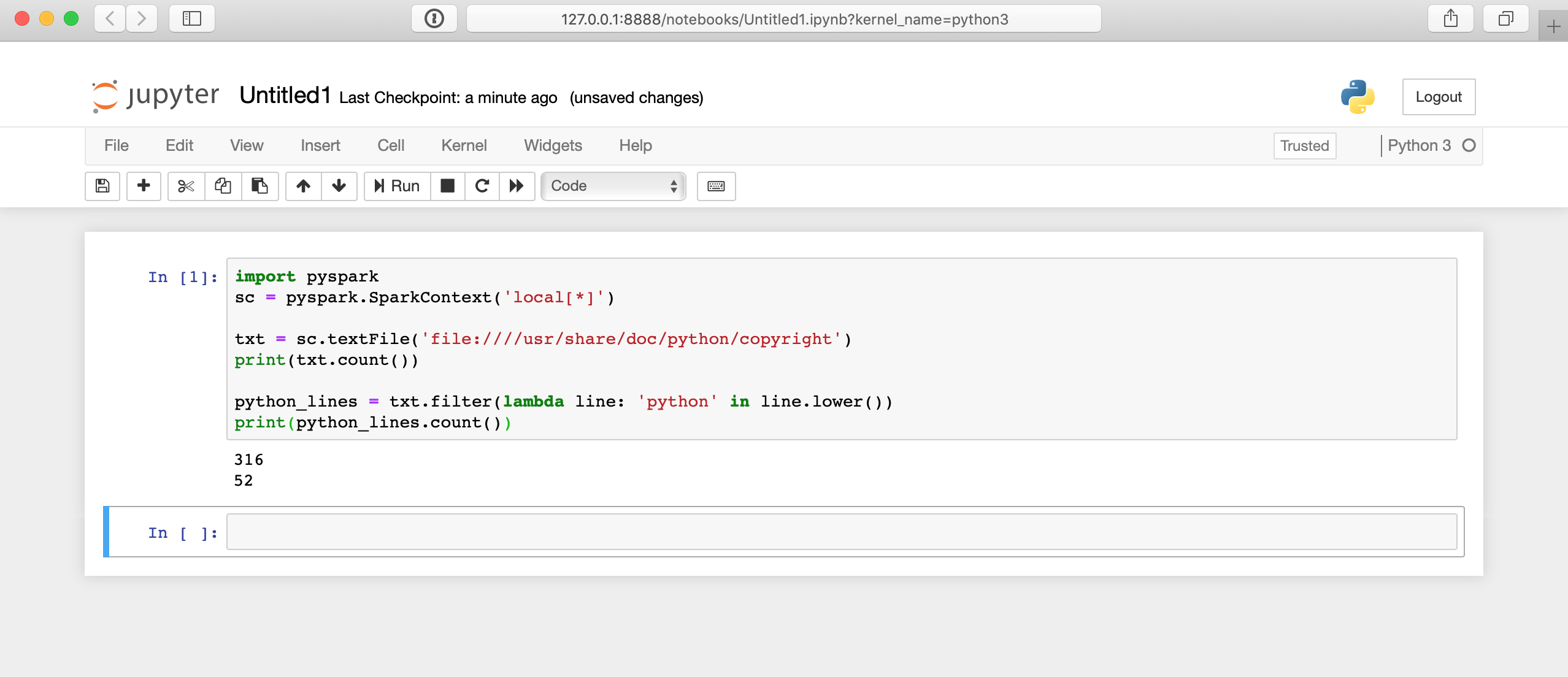
Здесь многое происходит за кулисами, поэтому отображение результатов может занять несколько секунд. Ответ появится не сразу после того, как вы нажмете на ячейку.
Интерфейс командной строки
Интерфейс командной строки предлагает множество способов отправки программ PySpark, включая оболочку PySpark и команду spark-submit. Чтобы использовать эти подходы к интерфейсу командной строки, вам сначала нужно подключиться к интерфейсу командной строки системы, в которой установлен PySpark.
Чтобы подключиться к командной строке настройки Docker, вам нужно запустить контейнер, как и раньше, а затем подключиться к этому контейнеру. Опять же, чтобы запустить контейнер, вы можете выполнить следующую команду:
$ docker run -p 8888:8888 jupyter/pyspark-notebook
Как только вы запустите контейнер Docker, вам нужно подключиться к нему через оболочку, а не через Jupyter notebook. Для этого выполните следующую команду, чтобы найти имя контейнера:
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d5ab7a93902 jupyter/pyspark-notebook "tini -g -- start-no…" 12 seconds ago Up 10 seconds 0.0.0.0:8888->8888/tcp kind_edison
Эта команда покажет вам все запущенные контейнеры. Найдите CONTAINER ID контейнера, в котором запущен jupyter/pyspark-notebook образ, и используйте его для подключения к bash оболочке внутри контейнера:
$ docker exec -it 4d5ab7a93902 bash
jovyan@4d5ab7a93902:~$
Теперь вы должны быть подключены к bash командной строке внутри контейнера. Вы можете убедиться, что все работает, потому что приглашение вашей оболочки изменится на что-то похожее на jovyan@4d5ab7a93902, но с использованием уникального идентификатора вашего контейнера.
Примечание: Замените 4d5ab7a93902 на CONTAINER ID, используемый на вашем компьютере.
Кластер
Вы можете использовать команду spark-submit, установленную вместе со Spark, для отправки кода PySpark в кластер с помощью командной строки. Эта команда берет программу PySpark или Scala и выполняет ее в кластере. Скорее всего, именно так вы будете выполнять свои настоящие задачи по обработке больших объемов данных.
Примечание: Путь к этим командам зависит от того, где был установлен Spark, и, скорее всего, будет работать только при использовании указанного контейнера Docker.
Чтобы запустить пример Hello World (или любую другую программу PySpark) с запущенным контейнером Docker, сначала откройте оболочку, как описано выше. Как только вы окажетесь в среде оболочки контейнера, вы сможете создавать файлы с помощью текстового редактора nano.
Чтобы создать файл в вашей текущей папке, просто запустите nano, указав имя файла, который вы хотите создать:
$ nano hello_world.py
Введите содержимое примера Hello World и сохраните файл, набрав Ctrl+X и выполнив следующие действия появится запрос на сохранение:
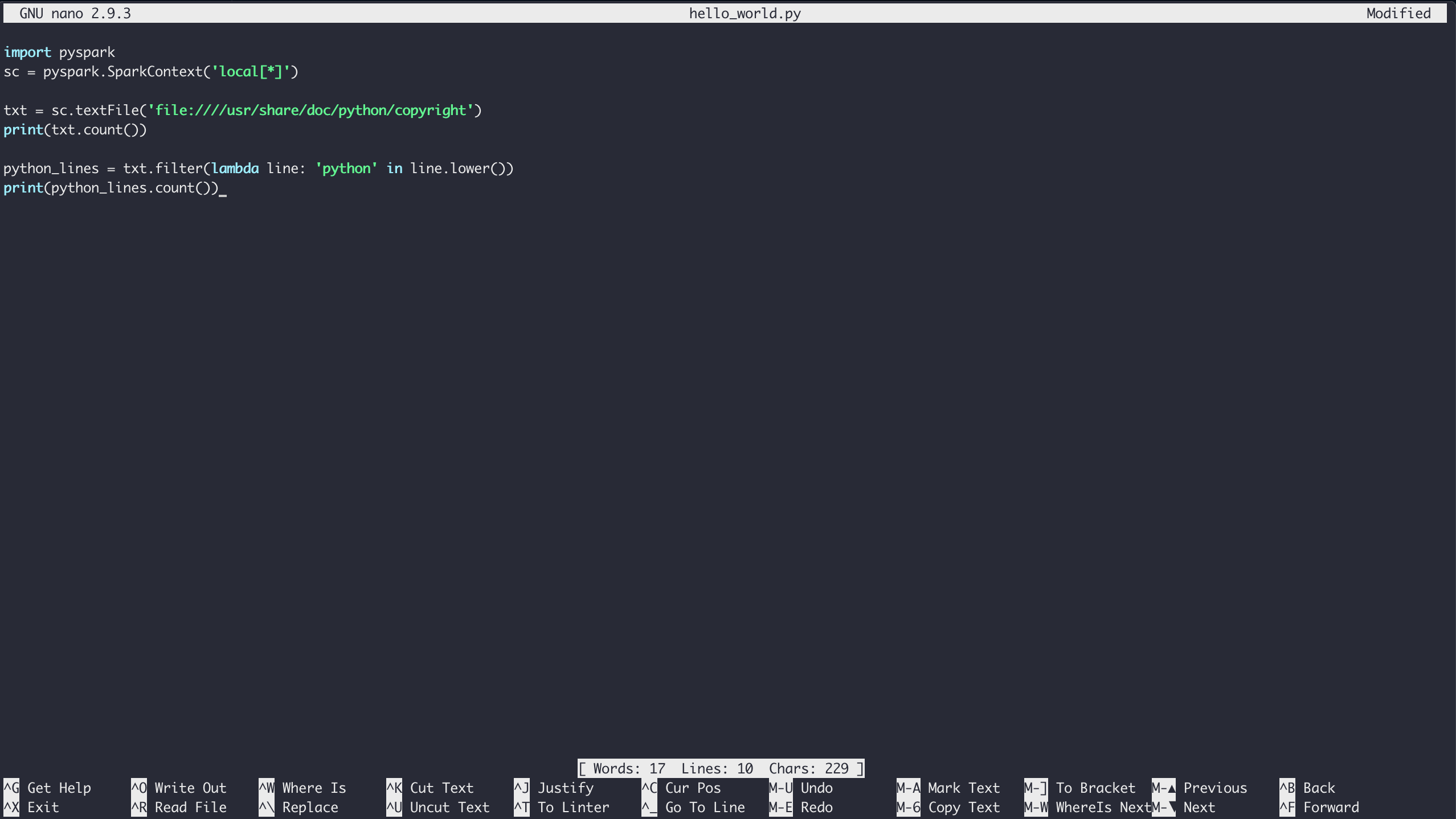
Наконец, вы можете запустить код через Spark с помощью команды pyspark-submit:
$ /usr/local/spark/bin/spark-submit hello_world.py
Результатом выполнения этой команды по умолчанию является много выходных данных, поэтому может быть трудно просмотреть выходные данные вашей программы. Вы можете немного регулировать детализацию журнала в своей программе PySpark, изменяя уровень переменной SparkContext. Для этого поместите эту строку в начало вашего скрипта:
sc.setLogLevel('WARN')
Это приведет к пропуску некоторых выходных данных spark-submit, чтобы вы могли более четко видеть выходные данные вашей программы. Однако в реальном сценарии вы захотите поместить любые выходные данные в файл, базу данных или какой-либо другой механизм хранения для облегчения последующей отладки.
К счастью, программа PySpark по-прежнему имеет доступ ко всей стандартной библиотеке Python, поэтому сохранение результатов в файл не является проблемой:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python3/copyright')
python_lines = txt.filter(lambda line: 'python' in line.lower())
with open('results.txt', 'w') as file_obj:
file_obj.write(f'Number of lines: {txt.count()}\n')
file_obj.write(f'Number of lines with python: {python_lines.count()}\n')
Теперь ваши результаты хранятся в отдельном файле под названием results.txt для более удобного использования в дальнейшем.
Примечание: В приведенном выше коде используются f-строки, которые были введены в Python 3.6.
Оболочка PySpark
Еще один специфичный для PySpark способ запуска ваших программ - это использование командной оболочки, поставляемой с самим PySpark. Опять же, используя настройки Docker, вы можете подключиться к CLI контейнера, как описано выше. Затем вы можете запустить специализированную оболочку Python со следующей командой:
$ /usr/local/spark/bin/pyspark
Python 3.7.3 | packaged by conda-forge | (default, Mar 27 2019, 23:01:00)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.1
/_/
Using Python version 3.7.3 (default, Mar 27 2019 23:01:00)
SparkSession available as 'spark'.
Теперь вы находитесь в среде Pyspark shell внутри вашего контейнера Docker и можете протестировать код, аналогичный примеру Jupyter notebook:
>>> txt = sc.textFile('file:////usr/share/doc/python3/copyright')
>>> print(txt.count())
316
Теперь вы можете работать в оболочке Pyspark так же, как и в обычной оболочке Python.
Примечание: Вам не нужно было создавать переменную SparkContext в примере оболочки Pyspark. Оболочка PySpark автоматически создает переменную sc, которая подключает вас к Spark Engine в одноузловом режиме.
Вы должны создать свой собственный SparkContext при отправке реальных программ PySpark с помощью spark-submit или Jupyter notebook.
Вы также можете использовать стандартную оболочку Python для выполнения своих программ, если PySpark установлен в этой среде Python. В контейнере Docker, который вы использовали , не включен PySpark для стандартной среды Python. Итак, вы должны использовать один из предыдущих методов, чтобы использовать PySpark в контейнере Docker.
Объединение PySpark с Другими Инструментами
Как вы уже видели, PySpark поставляется с дополнительными библиотеками для выполнения таких задач, как машинное обучение и SQL-подобные манипуляции с большими наборами данных. Однако вы также можете использовать другие распространенные научные библиотеки, такие как NumPy и Pandas.
Вы должны установить их в одной и той же среде на каждом узле кластера, и тогда ваша программа сможет использовать их как обычно. Затем вы можете использовать все знакомые идиоматические приемы панд, которые вы уже знаете.
Помните, что: Фреймы данных Pandas обрабатываются быстро, поэтому все данные должны быть помещены в память на одном компьютере.
Следующие шаги для реальной обработки больших объемов данных
Вскоре после изучения основ PySpark вам наверняка захочется приступить к анализу огромных объемов данных, что, скорее всего, не сработает при использовании режима работы на одной машине. Установка и обслуживание кластера Spark выходит за рамки данного руководства и, скорее всего, само по себе требует полной занятости.
Итак, возможно, пришло время обратиться в ИТ-отдел вашего офиса или изучить размещенное решение Spark cluster. Одним из возможных размещенных решений является Databricks.
Databricks позволяет размещать ваши данные в Microsoft Azure или AWS и имеет бесплатную 14-дневная пробная версия.
Когда у вас будет работающий кластер Spark, вы захотите перенести все свои данные в этот кластер для анализа. В Spark есть несколько способов импорта данных:
- Amazon S3
- Хранилище данных Apache Hive
- Любая база данных с JDBC или ODBC интерфейсом
Вы даже можете считывать данные непосредственно из сетевой файловой системы, как это делалось в предыдущих примерах.
Нет недостатка в способах получить доступ ко всем вашим данным, независимо от того, используете ли вы размещенное решение, такое как Databricks, или свой собственный кластер компьютеров.
Заключение
PySpark - хорошая отправная точка для обработки больших объемов данных.
Из этого руководства вы узнали, что вам не нужно тратить много времени на предварительное изучение, если вы знакомы с несколькими концепциями функционального программирования, такими как map(), filter(), и основы Python. Фактически, вы можете использовать весь Python, который вы уже знаете, включая такие знакомые инструменты, как NumPy и Pandas, непосредственно в своих программах PySpark.
Теперь вы можете:
- Понимать встроенные концепции Python, применимые к большим данным
- Написать базовые программы PySpark
- Запускайте Программы PySpark на небольших наборах данных на вашем локальном компьютере
- Изучите более эффективные решения для обработки больших данных, такие как кластер Spark или другое пользовательское размещенное решение