Кэширование в Python с использованием стратегии кэширования LRU
Оглавление
- Кэширование и его использование
- Использование @lru_cache для реализации кэша LRU в Python
- Добавление срока действия кэша
- Заключение
Существует множество способов создания быстрых и отзывчивых приложений. Кэширование - это один из подходов, который при правильном использовании значительно ускоряет работу и снижает нагрузку на вычислительные ресурсы. В Python functools модуль поставляется с @lru_cache декоратором, который дает вам возможность кэшировать результат выполнения выполняйте свои функции, используя стратегию, используемую в последнее время (LRU). Это простой, но мощный метод, который вы можете использовать для повышения эффективности кэширования в вашем коде.
В этом уроке вы узнаете:
- Какие стратегии кэширования доступны и как их реализовать с помощью Декораторов Python
- Что такое стратегия LRU и как она работает
- Как улучшить производительность за счет кэширования с
@lru_cacheдекоратор - Как расширить функциональность
@lru_cacheдекоратора и сделать так, чтобы срок его действия истек через определенное время
К концу этого урока вы получите более глубокое представление о том, как работает кэширование и как им воспользоваться в Python.
Кэширование и его использование
Кэширование - это метод оптимизации, который вы можете использовать в своих приложениях для хранения последних или часто используемых данных в местах памяти, доступ к которым быстрее или дешевле с точки зрения вычислений, чем к их источнику.
Представьте, что вы создаете приложение для чтения новостей, которое получает последние новости из разных источников. Пока пользователь просматривает список, ваше приложение загружает статьи и отображает их на экране.
Что произойдет, если пользователь решит несколько раз перейти от одной новостной статьи к другой? Если бы вы не кэшировали данные, вашему приложению пришлось бы каждый раз извлекать один и тот же контент! Это привело бы к замедлению работы системы вашего пользователя и оказало бы дополнительную нагрузку на сервер, на котором размещены статьи.
Лучшим подходом было бы сохранять содержимое локально после извлечения каждой статьи. Тогда в следующий раз, когда пользователь решит открыть статью, ваше приложение сможет открыть содержимое из локально сохраненной копии, вместо того чтобы возвращаться к источнику. В информатике этот метод называется кэшированием.
Реализация кэша с использованием словаря Python
Вы можете реализовать решение для кэширования на Python, используя словарь .
Если придерживаться примера с программой чтения новостей, то вместо того, чтобы обращаться непосредственно к серверу каждый раз, когда вам нужно загрузить статью, вы можете проверить, есть ли у вас контент в кэше, и вернуться к серверу, только если его нет. Вы можете использовать URL-адрес статьи в качестве ключа, а ее содержимое - в качестве значения.
Вот пример того, как может выглядеть этот метод кэширования:
1import requests
2
3cache = dict()
4
5def get_article_from_server(url):
6 print("Fetching article from server...")
7 response = requests.get(url)
8 return response.text
9
10def get_article(url):
11 print("Getting article...")
12 if url not in cache:
13 cache[url] = get_article_from_server(url)
14
15 return cache[url]
16
17get_article("https://realpython.com/sorting-algorithms-python/")
18get_article("https://realpython.com/sorting-algorithms-python/")
Сохраните этот код в caching.py файл, установите библиотеку requests, затем запустите скрипт:
$ pip install requests
$ python caching.py
Getting article...
Fetching article from server...
Getting article...
Обратите внимание, что строка "Fetching article from server..." напечатана один раз, несмотря на то, что get_article() вызывается дважды, в строках 17 и 18. Это происходит потому, что после получения доступа к статье в первый раз вы помещаете ее URL-адрес и содержимое в словарь cache. Во второй раз коду не нужно снова получать элемент с сервера.
Стратегии кэширования
У этой реализации кэширования есть одна большая проблема: содержимое словаря будет увеличиваться бесконечно! По мере того, как пользователь загружает все больше статей, приложение будет сохранять их в памяти, что в конечном итоге приведет к сбою приложения.
Чтобы обойти эту проблему, вам нужна стратегия, позволяющая решить, какие статьи следует сохранить в памяти, а какие удалить. Эти стратегии кэширования представляют собой алгоритмы, которые направлены на управление кэшированной информацией и выбор того, какие элементы следует удалить, чтобы освободить место для новых.
Существует несколько различных стратегий, которые вы можете использовать, чтобы удалить элементы из кэша и не допустить превышения его максимального размера. Вот пять наиболее популярных из них с объяснением того, когда каждый из них наиболее полезен:
| Стратегия | Политика вытеснения | Вариант использования |
|---|---|---|
| Первым пришел/Первым ушел (FIFO) | Вытесняет самые старые записи | Более новые записи с наибольшей вероятностью будут использованы повторно |
| Последним пришел/Первым ушел (LIFO) | Вытесняет самые новые записи | Более старые записи с наибольшей вероятностью будут использованы повторно |
| Наименее недавно использованные (LRU) | Вытесняет наименее недавно использованные запись | Недавно использованные записи с наибольшей вероятностью будут использованы повторно |
| Наиболее недавно использованные (MRU) | Удаляет наиболее недавно использованную запись | Наименее недавно использованные записи с наибольшей вероятностью будут использованы повторно |
| Наименее часто используемые (LFU) | Удаляет наименее часто используемую запись | Записи с большим количеством обращений с большей вероятностью будут использованы повторно |
В следующих разделах вы более подробно рассмотрите стратегию LRU и то, как ее реализовать с помощью @lru_cache decorator из модуля functools Python.
Переходим к наименее используемой в последнее время стратегии кэширования (LRU)
Кэш, реализованный с использованием стратегии LRU, упорядочивает свои элементы в порядке их использования. Каждый раз, когда вы обращаетесь к записи, алгоритм LRU перемещает ее в начало кэша. Таким образом, алгоритм может быстро определить запись, которая дольше всего не использовалась, просмотрев ее в нижней части списка.
На следующем рисунке показано гипотетическое представление кэша после того, как ваш пользователь запросит статью из сети:

Обратите внимание, что кэш сохраняет статью в самой последней ячейке перед отправкой пользователю. На следующем рисунке показано, что происходит, когда пользователь запрашивает вторую статью:

Вторая статья занимает самое последнее место, перемещая первую статью вниз по списку.
Стратегия LRU предполагает, что чем более недавно использовался объект, тем больше вероятность, что он понадобится в будущем, поэтому она пытается сохранить этот объект в кэше как можно дольше.
Заглядываем за кулисы кэша LRU
Одним из способов реализации кэша LRU в Python является использование комбинации двусвязного списка и хэш-карты. Элемент head двусвязного списка будет указывать на самую последнюю использованную запись, а элемент tail будет указывать на наименее недавно использованную запись.
На рисунке ниже показана потенциальная структура реализации кэша LRU за кулисами:
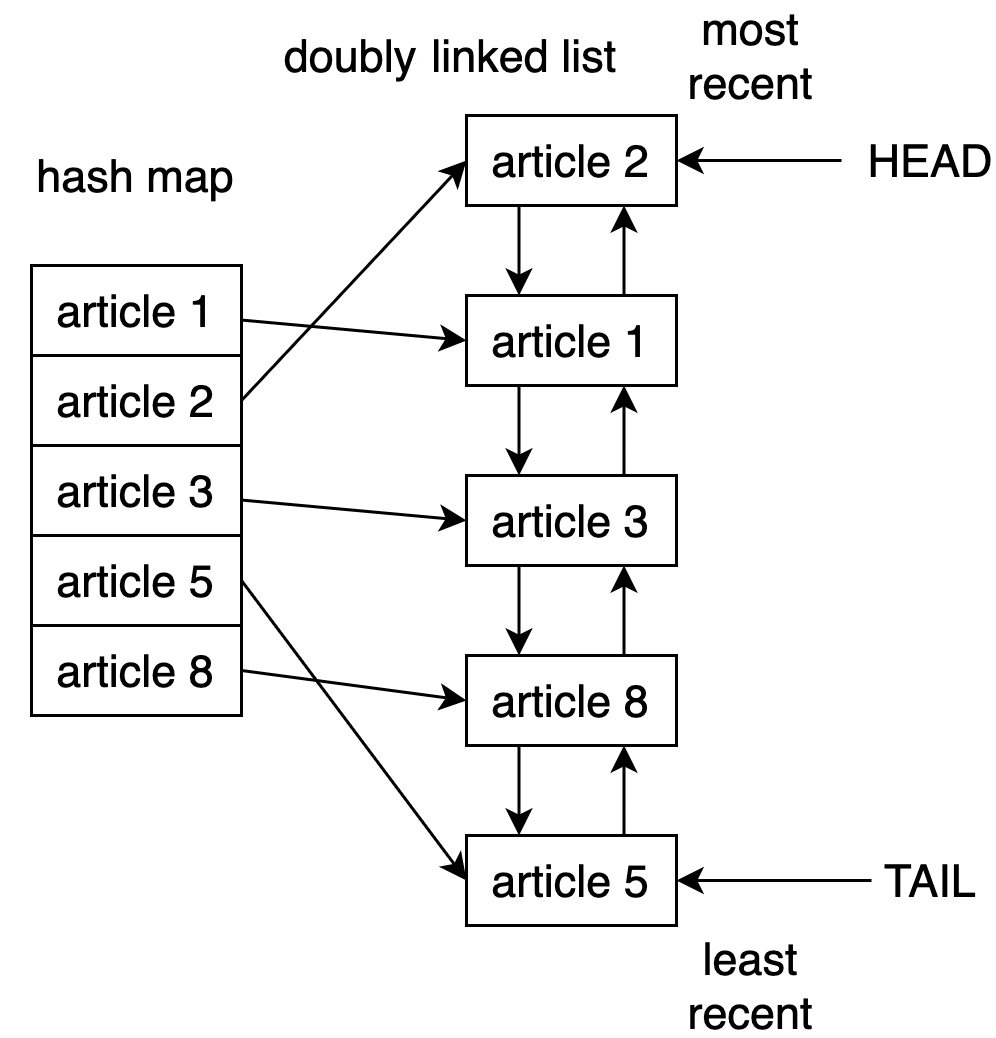
Используя хэш-карту, вы можете обеспечить доступ к каждому элементу в кэше, сопоставив каждую запись с определенным местоположением в двусвязном списке.
Эта стратегия работает очень быстро. Доступ к наименее используемому элементу и обновление кэша - это операции, время выполнения которых составляет O(1).
Примечание: Для более глубокого понимания нотации Big O, а также нескольких практических примеров на Python ознакомьтесь с Нотацией Big O и анализом алгоритмов на примерах Python..
Начиная с версии 3.2, Python включает в себя @lru_cache декоратор для реализации стратегии LRU. Вы можете использовать этот декоратор для переноса функций и кэширования их результатов с максимальным количеством записей.
Использование @lru_cache для реализации кэша LRU в Python
Как и в случае с решением для кэширования, которое вы реализовали ранее, @lru_cache использует словарь за кулисами. Оно кэширует результат функции под ключом, который состоит из вызова функции, включая предоставленные аргументы. Это важно, потому что это означает, что эти аргументы должны быть хэшируемыми для работы декоратора.
Играем с лестницами
Представьте, что вы хотите определить все возможные способы подняться на определенную ступеньку лестницы, перепрыгивая через одну, две или три ступеньки за раз. Сколько существует путей к четвертой ступеньке? Вот все различные комбинации:

Вы могли бы сформулировать решение этой проблемы, заявив, что, чтобы добраться до вашей текущей лестницы, вы можете перепрыгнуть с одной, двух или трех нижних ступенек. Суммируя количество комбинаций прыжков, которые вы можете использовать, чтобы добраться до каждой из этих точек, вы получите общее количество возможных способов достичь вашей текущей позиции.
Например, количество комбинаций для подъема на четвертую ступеньку будет равно общему количеству различных способов подняться на третью, вторую и первую ступеньки:
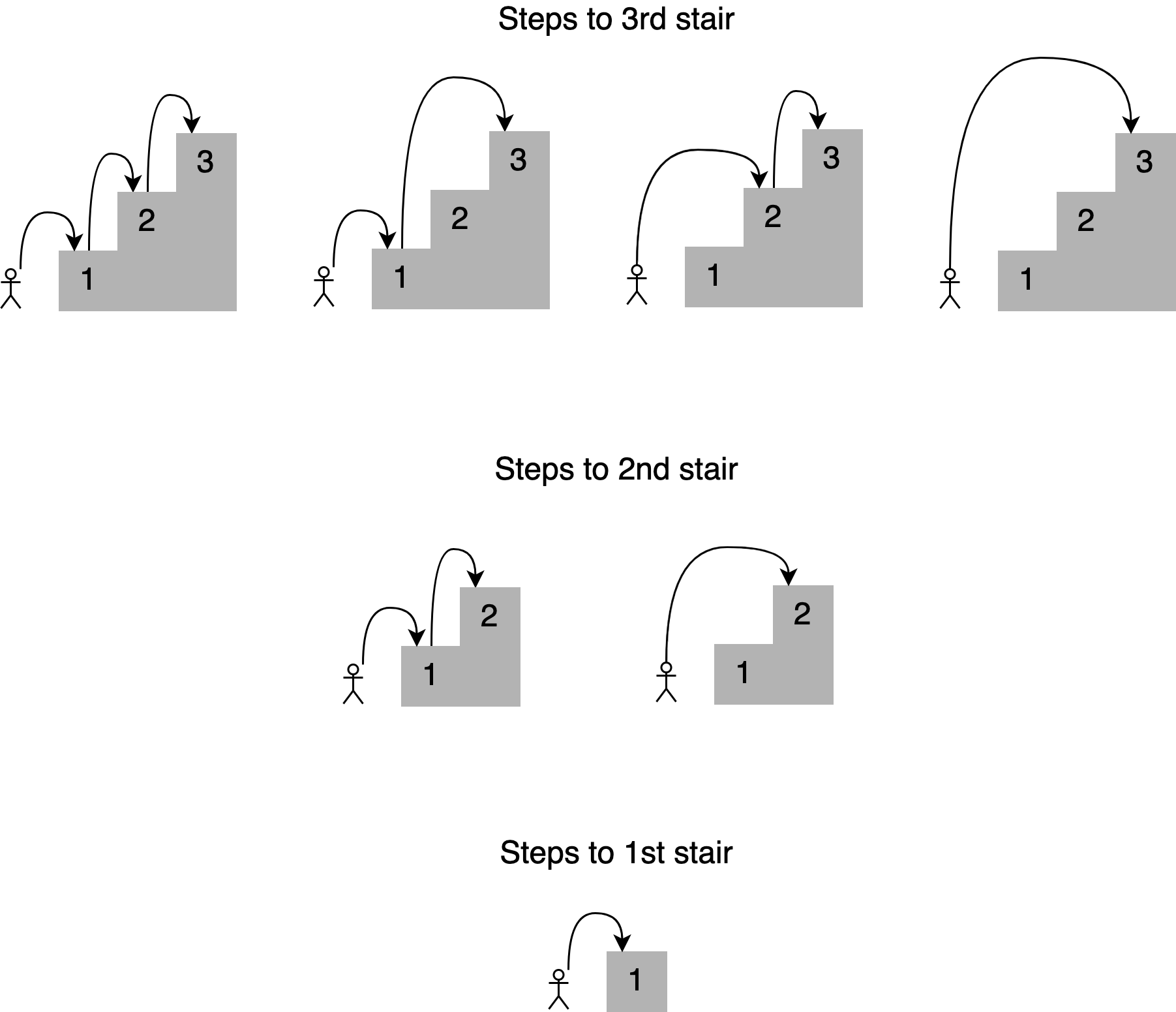
Как показано на рисунке, существует семь различных способов подняться на четвертую ступеньку. Обратите внимание, что решение для данной ступеньки основывается на ответах на более мелкие подзадачи. В этом случае, чтобы определить различные пути к четвертой ступеньке, вы можете сложить четыре способа подняться на третью ступеньку, два способа подняться на вторую ступеньку и один способ подняться на первую ступеньку.
Этот подход называется рекурсией. Если вы хотите узнать больше, ознакомьтесь с Рекурсия в Python: введение, чтобы ознакомиться с этой темой.
Вот функция, которая реализует эту рекурсию:
1def steps_to(stair):
2 if stair == 1:
3 # You can reach the first stair with only a single step
4 # from the floor.
5 return 1
6 elif stair == 2:
7 # You can reach the second stair by jumping from the
8 # floor with a single two-stair hop or by jumping a single
9 # stair a couple of times.
10 return 2
11 elif stair == 3:
12 # You can reach the third stair using four possible
13 # combinations:
14 # 1. Jumping all the way from the floor
15 # 2. Jumping two stairs, then one
16 # 3. Jumping one stair, then two
17 # 4. Jumping one stair three times
18 return 4
19 else:
20 # You can reach your current stair from three different places:
21 # 1. From three stairs down
22 # 2. From two stairs down
23 # 2. From one stair down
24 #
25 # If you add up the number of ways of getting to those
26 # those three positions, then you should have your solution.
27 return (
28 steps_to(stair - 3)
29 + steps_to(stair - 2)
30 + steps_to(stair - 1)
31 )
32
33print(steps_to(4))
Сохраните этот код в файл с именем stairs.py и запустите его с помощью следующей команды:
$ python stairs.py
7
Отлично! Код работает для лестницы 4, но как насчет подсчета количества ступенек, необходимых для подъема на более высокую ступень лестницы? Измените номер ступеньки в строке 33 на 30 и повторно запустите скрипт:
$ python stairs.py
53798080
Ух ты, более 53 миллионов комбинаций! Это очень много переходов!
Синхронизация Вашего кода
При поиске решения для тридцатого этапа работы над сценарием потребовалось довольно много времени. Чтобы получить исходные данные, вы можете измерить, сколько времени требуется для выполнения кода.
Для достижения этой цели вы можете использовать модуль Python timeit. Добавьте следующие строки после строки 33:
35setup_code = "from __main__ import steps_to"
36stmt = "steps_to(30)"
37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
38print(f"Minimum execution time: {min(times)}")
Вам также необходимо импортировать модуль timeit в верхней части кода:
1from timeit import repeat
Вот построчное объяснение этих дополнений:
- Строка 35 импортирует имя
steps_to(), чтобыtimeit.repeat()знал, как его вызвать. - Строка 36 подготавливает вызов функции с номером ступени, которого вы хотите достичь, который в данном случае равен
30. Это инструкция, которая будет выполнена по расписанию. - В строке 37 вызывается
timeit.repeat()с кодом настройки и инструкцией. При этом функция будет вызвана10раз, возвращая количество секунд, затраченных на каждое выполнение. - Строка 38 определяет и выводит на печать наименьшее возвращаемое время.
Примечание: Распространенным заблуждением является то, что вы должны определять среднее время каждого запуска функции вместо выбора самого короткого времени.
При измерении времени возникают помехи, поскольку система одновременно запускает другие процессы. Наименьшее время всегда является наименее зашумленным, что делает его наилучшим отображением времени выполнения функции.
Теперь запустите скрипт еще раз:
$ python stairs.py
53798080
Minimum execution time: 40.014977024000004
Количество секунд, которое вы увидите, зависит от вашего конкретного оборудования. В моей системе выполнение скрипта заняло сорок секунд, что довольно медленно всего для тридцати ступенек!
Примечание: Вы можете узнать больше о модуле timeit в официальной документации по Python .
Решение, требующее столько времени, является проблемой, но вы можете улучшить его, используя запоминание.
Использование запоминания для улучшения решения
Эта рекурсивная реализация решает проблему, разбивая ее на более мелкие этапы, которые основываются друг на друге. На следующем рисунке показано дерево, в котором каждый узел представляет определенный вызов steps_to():
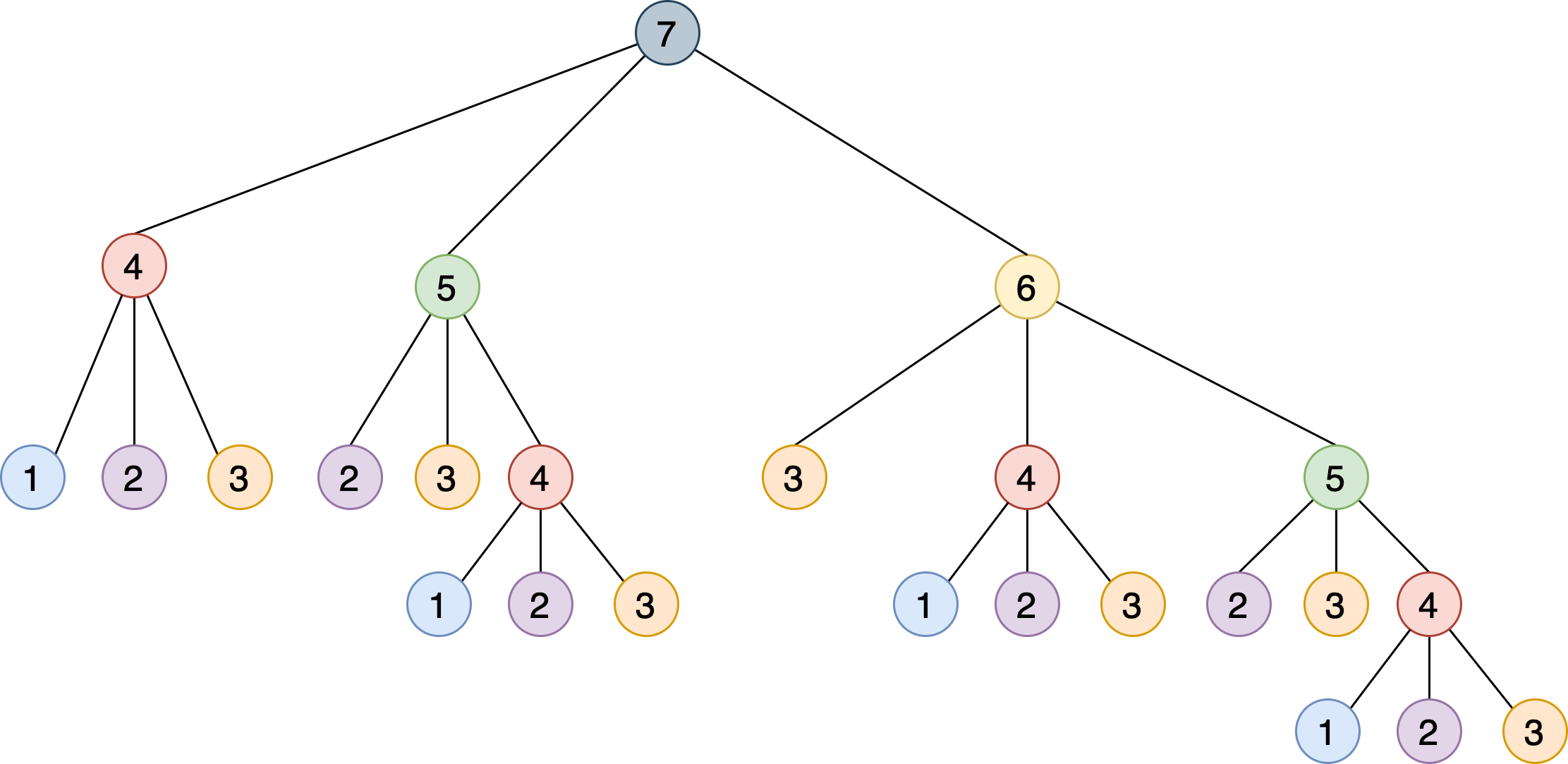
Обратите внимание, что вам нужно вызывать steps_to() с одним и тем же аргументом несколько раз. Например, steps_to(5) вычисляется два раза, steps_to(4) вычисляется четыре раза, steps_to(3) семь раз и steps_to(2) шесть раз. Повторный вызов одной и той же функции приводит к увеличению количества вычислительных циклов, которые не являются необходимыми — результат всегда будет одним и тем же.
Чтобы устранить эту проблему, вы можете использовать метод, называемый запоминание. Такой подход гарантирует, что функция не будет выполняться для одних и тех же входных данных более одного раза, сохраняя свой результат в памяти и затем обращаясь к нему позже, когда это необходимо. Этот сценарий звучит как прекрасная возможность использовать декоратор Python @lru_cache!
Примечание: Для получения дополнительной информации о запоминании и использовании @lru_cache для его реализации ознакомьтесь с Запоминание в Python.
Сделав всего два изменения, вы можете значительно улучшить время работы алгоритма:
- Импортируйте
@lru_cacheдекоратор из модуляfunctools. - Используйте
@lru_cacheдля украшенияsteps_to().
Вот как будет выглядеть верхняя часть скрипта после двух обновлений:
1from functools import lru_cache
2from timeit import repeat
3
4@lru_cache
5def steps_to(stair):
6 if stair == 1:
Запуск обновленного скрипта приводит к следующему результату:
$ python stairs.py
53798080
Minimum execution time: 7.999999999987184e-07
Кэширование результата работы функции сокращает время выполнения с 40 секунд до 0,0008 миллисекунд! Это фантастическое улучшение!
Примечание: в в Python 3.8 и выше, вы можете использовать @lru_cache декоратор без скобок если вы не указания каких-либо параметров. В предыдущих версиях вам, возможно, потребуется включить круглые скобки: @lru_cache().
Помните, что за кулисами @lru_cache декоратор сохраняет результат steps_to() для каждого отдельного входного сигнала. Каждый раз, когда код вызывает функцию с теми же параметрами, вместо того, чтобы заново вычислять ответ, он возвращает правильный результат непосредственно из памяти. Это объясняет значительное повышение производительности при использовании @lru_cache.
Распаковка функционала @lru_cache
С помощью @lru_cache декоратора вы сохраняете каждый вызов и ответ в памяти, чтобы получить доступ к ним позже, если потребуется снова. Но сколько вызовов вы сможете сохранить, прежде чем закончится память?
Декоратор Python @lru_cache предлагает атрибут maxsize, который определяет максимальное количество записей до того, как кэш начнет удалять старые элементы. По умолчанию для maxsize установлено значение 128. Если для maxsize установить значение None, то кэш будет увеличиваться бесконечно, и никакие записи никогда не будут удалены. Это может стать проблемой, если вы храните в памяти большое количество различных вызовов.
Вот пример @lru_cache с использованием атрибута maxsize:
1from functools import lru_cache
2from timeit import repeat
3
4@lru_cache(maxsize=16)
5def steps_to(stair):
6 if stair == 1:
В этом случае вы ограничиваете объем кэша максимальным количеством 16 записей. Когда поступает новый вызов, реализация декоратора удаляет наименее использовавшиеся в последнее время записи из существующих 16, чтобы освободить место для нового элемента.
Чтобы увидеть, что произойдет с этим новым дополнением к коду, вы можете использовать cache_info(), предоставленный @lru_cache декоратором, для проверки количества обращений и не хватает и текущего размера кэша. Для наглядности удалите код, который увеличивает время выполнения функции. Вот как выглядит окончательный сценарий после всех изменений:
1from functools import lru_cache
2from timeit import repeat
3
4@lru_cache(maxsize=16)
5def steps_to(stair):
6 if stair == 1:
7 # You can reach the first stair with only a single step
8 # from the floor.
9 return 1
10 elif stair == 2:
11 # You can reach the second stair by jumping from the
12 # floor with a single two-stair hop or by jumping a single
13 # stair a couple of times.
14 return 2
15 elif stair == 3:
16 # You can reach the third stair using four possible
17 # combinations:
18 # 1. Jumping all the way from the floor
19 # 2. Jumping two stairs, then one
20 # 3. Jumping one stair, then two
21 # 4. Jumping one stair three times
22 return 4
23 else:
24 # You can reach your current stair from three different places:
25 # 1. From three stairs down
26 # 2. From two stairs down
27 # 2. From one stair down
28 #
29 # If you add up the number of ways of getting to those
30 # those three positions, then you should have your solution.
31 return (
32 steps_to(stair - 3)
33 + steps_to(stair - 2)
34 + steps_to(stair - 1)
35 )
36
37print(steps_to(30))
38
39print(steps_to.cache_info())
Если вы снова вызовете скрипт, то увидите следующий результат:
$ python stairs.py
53798080
CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
Вы можете использовать информацию, возвращаемую cache_info(), чтобы понять, как работает кэш, и точно настроить его, чтобы найти оптимальный баланс между скоростью и объемом памяти.
Вот краткое описание свойств, предоставляемых cache_info():
-
hits=52это количество вызовов, которые@lru_cacheбыли возвращены непосредственно из памяти, поскольку они существовали в кэше. -
misses=30это количество вызовов, которые поступили не из памяти, а были вычислены. Поскольку вы пытаетесь вычислить количество ступеней, необходимых для достижения тридцатой ступени, логично предположить, что каждый из этих вызовов не попал в кэш при первом выполнении. -
maxsize=16это размер кэша, который вы определили с помощью атрибутаmaxsizeдекоратора. -
currsize=16это текущий размер кэша. В этом случае это показывает, что ваш кэш заполнен.
Если вам нужно удалить все записи из кэша, то вы можете использовать cache_clear(), предоставленный @lru_cache.
Добавление срока действия кэша
Представьте, что вы хотите разработать скрипт, который отслеживает Реальный Python и выводит количество символов в любой статье, содержащей это слово python.
Реальный Python предоставляет Канал Atom, поэтому вы можете использовать библиотеку feedparser для анализа канала и библиотека requests для загрузки содержимого статьи, как вы делали это раньше.
Вот реализация сценария мониторинга:
1import feedparser
2import requests
3import ssl
4import time
5
6if hasattr(ssl, "_create_unverified_context"):
7 ssl._create_default_https_context = ssl._create_unverified_context
8
9def get_article_from_server(url):
10 print("Fetching article from server...")
11 response = requests.get(url)
12 return response.text
13
14def monitor(url):
15 maxlen = 45
16 while True:
17 print("\nChecking feed...")
18 feed = feedparser.parse(url)
19
20 for entry in feed.entries[:5]:
21 if "python" in entry.title.lower():
22 truncated_title = (
23 entry.title[:maxlen] + "..."
24 if len(entry.title) > maxlen
25 else entry.title
26 )
27 print(
28 "Match found:",
29 truncated_title,
30 len(get_article_from_server(entry.link)),
31 )
32
33 time.sleep(5)
34
35monitor("https://realpython.com/atom.xml")
Сохраните этот скрипт в файл с именем monitor.py, установите библиотеки feedparser и requests и запустите скрипт. Он будет работать непрерывно, пока вы не остановите его, нажав Ctrl+C в вашем окне терминала:
$ pip install feedparser requests
$ python monitor.py
Checking feed...
Fetching article from server...
The Real Python Podcast – Episode #28: Using ... 29520
Fetching article from server...
Python Community Interview With David Amos 54256
Fetching article from server...
Working With Linked Lists in Python 37099
Fetching article from server...
Python Practice Problems: Get Ready for Your ... 164888
Fetching article from server...
The Real Python Podcast – Episode #27: Prepar... 30784
Checking feed...
Fetching article from server...
The Real Python Podcast – Episode #28: Using ... 29520
Fetching article from server...
Python Community Interview With David Amos 54256
Fetching article from server...
Working With Linked Lists in Python 37099
Fetching article from server...
Python Practice Problems: Get Ready for Your ... 164888
Fetching article from server...
The Real Python Podcast – Episode #27: Prepar... 30784
Вот пошаговое объяснение кода:
- Строки 6 и 7: Это решение проблемы, возникающей при попытке
feedparserполучить доступ к контенту, передаваемому по протоколу HTTPS. Смотрите примечание ниже для получения дополнительной информации. - Строка 16:
monitor()будет повторяться бесконечно. - Строка 18: Используя
feedparser, код загружает и анализирует фид из реального Python. - Строка 20: Цикл проходит через первые
5записи в списке. - Строки с 21 по 31: Если слово
pythonявляется частью заголовка, то код выводит его вместе с длиной статьи. - Строка 33: Код переходит в режим ожидания на
5секунд, прежде чем продолжить. - Строка 35: Эта строка запускает процесс мониторинга, передавая URL-адрес реального канала Python в
monitor().
Каждый раз, когда скрипт загружает статью, на консоль выводится сообщение "Fetching article from server...". Если вы дадите скрипту поработать достаточно долго, то увидите, что это сообщение появляется повторно, даже при загрузке одной и той же ссылки.
Примечание: Для получения дополнительной информации о проблеме с feedparser доступом к контенту, предоставляемому по протоколу HTTPS, ознакомьтесь с проблемой 84 в feedparser репозитории. В PEP 476 описано, как Python начал включать проверку сертификата по умолчанию для stdlib HTTP-клиентов, что является основной причиной этой ошибки.
Это отличная возможность кэшировать содержимое статьи и не выходить в сеть каждые пять секунд. Вы могли бы использовать @lru_cache декоратор, но что произойдет, если содержимое статьи будет обновлено?
При первом доступе к статье декоратор сохранит ее содержимое и каждый раз будет возвращать одни и те же данные. Если публикация будет обновлена, скрипт мониторинга никогда этого не заметит, потому что он будет извлекать старую копию, хранящуюся в кэше. Чтобы решить эту проблему, вы можете установить срок действия ваших записей в кэше.
Удаление записей кэша с учетом как времени, так и пространства
Декоратор @lru_cache удаляет существующие записи только тогда, когда больше нет места для хранения новых списков. При наличии достаточного пространства записи в кэше будут жить вечно и никогда не обновляться.
Это создает проблему для вашего сценария мониторинга, поскольку вы никогда не будете получать обновления, опубликованные для ранее кэшированных статей. Чтобы обойти эту проблему, вы можете обновить реализацию кэширования, чтобы срок ее действия истек через определенное время.
Вы можете реализовать эту идею в новом декораторе, который расширяет @lru_cache. Если вызывающий абонент пытается получить доступ к элементу, срок службы которого истек, кэш не возвращает его содержимое, заставляя вызывающего абонента извлекать статью из сети.
Примечание: Для получения дополнительной информации о декораторах Python ознакомьтесь с Руководством по декораторам Python и Python Decorators 101.
Вот возможная реализация этого нового декоратора:
1from functools import lru_cache, wraps
2from datetime import datetime, timedelta
3
4def timed_lru_cache(seconds: int, maxsize: int = 128):
5 def wrapper_cache(func):
6 func = lru_cache(maxsize=maxsize)(func)
7 func.lifetime = timedelta(seconds=seconds)
8 func.expiration = datetime.utcnow() + func.lifetime
9
10 @wraps(func)
11 def wrapped_func(*args, **kwargs):
12 if datetime.utcnow() >= func.expiration:
13 func.cache_clear()
14 func.expiration = datetime.utcnow() + func.lifetime
15
16 return func(*args, **kwargs)
17
18 return wrapped_func
19
20 return wrapper_cache
Вот краткое описание этой реализации:
- Строка 4:
@timed_lru_cacheДекоратор будет поддерживать время жизни записей в кэше (в секундах) и максимальный размер кэша. - Строка 6: Код оборачивает оформленную функцию с помощью
lru_cacheдекоратора. Это позволяет вам использовать функциональность кэширования, уже предоставленнуюlru_cache. - Строки 7 и 8: Эти две строки описывают оформленную функцию с помощью двух атрибутов, представляющих время жизни кэша и фактическую дату, когда оно истечет.
- Строки с 12 по 14: Перед доступом к записи в кэше декоратор проверяет, не истек ли срок действия текущей даты. Если это так, то программа очищает кэш и повторно вычисляет время жизни и дату истечения срока действия.
Обратите внимание, что, когда срок действия записи истекает, этот декоратор очищает весь кэш, связанный с функцией. Срок службы применяется к кэшу в целом, а не к отдельным статьям. Более сложная реализация этой стратегии привела бы к выселению участников на основе их индивидуального срока службы.
Кэширование статей с помощью нового декоратора
Теперь вы можете использовать свой новый @timed_lru_cache декоратор со скриптом monitor, чтобы предотвратить выборку содержимого статьи при каждом обращении к ней.
Объединив код в один скрипт для простоты, вы получите следующее:
1import feedparser
2import requests
3import ssl
4import time
5
6from functools import lru_cache, wraps
7from datetime import datetime, timedelta
8
9if hasattr(ssl, "_create_unverified_context"):
10 ssl._create_default_https_context = ssl._create_unverified_context
11
12def timed_lru_cache(seconds: int, maxsize: int = 128):
13 def wrapper_cache(func):
14 func = lru_cache(maxsize=maxsize)(func)
15 func.lifetime = timedelta(seconds=seconds)
16 func.expiration = datetime.utcnow() + func.lifetime
17
18 @wraps(func)
19 def wrapped_func(*args, **kwargs):
20 if datetime.utcnow() >= func.expiration:
21 func.cache_clear()
22 func.expiration = datetime.utcnow() + func.lifetime
23
24 return func(*args, **kwargs)
25
26 return wrapped_func
27
28 return wrapper_cache
29
30@timed_lru_cache(10)
31def get_article_from_server(url):
32 print("Fetching article from server...")
33 response = requests.get(url)
34 return response.text
35
36def monitor(url):
37 maxlen = 45
38 while True:
39 print("\nChecking feed...")
40 feed = feedparser.parse(url)
41
42 for entry in feed.entries[:5]:
43 if "python" in entry.title.lower():
44 truncated_title = (
45 entry.title[:maxlen] + "..."
46 if len(entry.title) > maxlen
47 else entry.title
48 )
49 print(
50 "Match found:",
51 truncated_title,
52 len(get_article_from_server(entry.link)),
53 )
54
55 time.sleep(5)
56
57monitor("https://realpython.com/atom.xml")
Обратите внимание, что строка 30 заменяет get_article_from_server() на @timed_lru_cache и указывает срок действия 10 секунд. Любая попытка получить доступ к той же статье с сервера в течение 10 секунд после ее получения вернет содержимое из кэша и никогда не попадет в сеть.
Запустите скрипт и посмотрите на результаты:
$ python monitor.py
Checking feed...
Fetching article from server...
Match found: The Real Python Podcast – Episode #28: Using ... 29521
Fetching article from server...
Match found: Python Community Interview With David Amos 54254
Fetching article from server...
Match found: Working With Linked Lists in Python 37100
Fetching article from server...
Match found: Python Practice Problems: Get Ready for Your ... 164887
Fetching article from server...
Match found: The Real Python Podcast – Episode #27: Prepar... 30783
Checking feed...
Match found: The Real Python Podcast – Episode #28: Using ... 29521
Match found: Python Community Interview With David Amos 54254
Match found: Working With Linked Lists in Python 37100
Match found: Python Practice Problems: Get Ready for Your ... 164887
Match found: The Real Python Podcast – Episode #27: Prepar... 30783
Checking feed...
Match found: The Real Python Podcast – Episode #28: Using ... 29521
Match found: Python Community Interview With David Amos 54254
Match found: Working With Linked Lists in Python 37100
Match found: Python Practice Problems: Get Ready for Your ... 164887
Match found: The Real Python Podcast – Episode #27: Prepar... 30783
Checking feed...
Fetching article from server...
Match found: The Real Python Podcast – Episode #28: Using ... 29521
Fetching article from server...
Match found: Python Community Interview With David Amos 54254
Fetching article from server...
Match found: Working With Linked Lists in Python 37099
Fetching article from server...
Match found: Python Practice Problems: Get Ready for Your ... 164888
Fetching article from server...
Match found: The Real Python Podcast – Episode #27: Prepar... 30783
Обратите внимание, как код выводит сообщение "Fetching article from server..." при первом обращении к соответствующим статьям. После этого, в зависимости от скорости вашей сети и вычислительной мощности, скрипт извлечет статьи из кэша один или два раза, прежде чем снова отправить их на сервер.
Скрипт пытается получить доступ к статьям каждые 5 секунды, а срок действия кэша истекает каждые 10 секунды. Вероятно, это слишком короткое время для реального приложения, поэтому вы можете добиться значительного улучшения, изменив эти настройки.
Заключение
Кэширование является важным методом оптимизации для повышения производительности любой программной системы. Понимание того, как работает кэширование, является фундаментальным шагом на пути к эффективному внедрению его в ваши приложения.
В этом уроке вы узнали:
- Каковы различные стратегии кэширования и как они работают
- Как использовать
@lru_cacheдекоратор Python - Как создать новый декоратор для расширения функциональности
@lru_cache - Как измерить время выполнения вашего кода с помощью
timeitмодуля - Что такое рекурсия и как с ее помощью решить задачу
- Как запоминание улучшает время выполнения за счет сохранения промежуточных результатов в памяти
Следующим шагом к реализации различных стратегий кэширования в ваших приложениях является изучение модуля cachetools. Эта библиотека предоставляет несколько коллекций и средств оформления, охватывающих некоторые из наиболее популярных стратегий кэширования, которые вы можете начать использовать прямо сейчас.