Создайте хэш-таблицу на Python с помощью TDD
Оглавление
- Познакомьтесь со структурой данных хеш-таблицы
- понять хеш-функцию
- создайте прототип хеш-таблицы в Python с помощью TDD
- пройдите краш-курс по разработке, основанной на тестировании
- определите пользовательский класс хэш-таблицы
- вставьте пару ключ-значение
- найти значение по ключу
- удалить пару ключ-значение
- обновите значение существующей пары
- получить пары ключ-значение
- Используйте Защитное Копирование
- получить ключи и значения
- сообщить длину хеш-таблицы
- сделайте хеш-таблицу Итерабельной
- представлять хеш-таблицу в тексте
- Проверьте равенство хеш-таблиц
- Устранение Коллизий Хэш-Кода
- сохранить порядок вставки в хеш-таблицу
- Используйте Хэшируемые Ключи
- заключение
Изобретенная более полувека назад, хэш-таблица является классической структурой данных, которая является фундаментальной для программирования. По сей день это помогает решать многие реальные проблемы, такие как индексация таблиц базы данных, кэширование вычисленных значений или реализация наборов. Это часто всплывает на собеседованиях при приеме на работу, и Python повсеместно использует хэш-таблицы, чтобы сделать поиск по имени практически мгновенным.
Несмотря на то, что Python поставляется со своей собственной хэш-таблицей под названием dict, может быть полезно понять, как работают хэш-таблицы за кулисами. Оценка кода может даже помочь вам создать такую таблицу. В этом руководстве вы узнаете, как создать хэш-таблицу с нуля, как будто в Python ее нет. На этом пути вы столкнетесь с несколькими трудностями, которые познакомят вас с важными концепциями и дадут представление о том, почему хэш-таблицы создаются так быстро.
В дополнение к этому, вы получите практический ускоренный курс по разработке на основе тестирования (TDD) и будете активно практиковаться в этом, шаг за шагом создавая свою хэш-таблицу мода. От вас не требуется никакого предварительного опыта работы с TDD, но в то же время вам не придется скучать, даже если вы это сделаете!
В этом уроке вы узнаете:
- Чем хэш-таблица отличается от словаря
- Как вы можете реализовать хэш-таблицу с нуля на Python
- Как вы можете справиться с коллизиями хэшей и другими проблемами
- Каковы желаемые свойства хэш-функции
- Как
hash()работает Python за кулисами
Это поможет, если вы уже знакомы с словарями Python и обладаете базовыми знаниями принципов объектно-ориентированного программирования. Чтобы получить полный исходный код и промежуточные этапы создания хэш-таблицы, описанные в этом руководстве, перейдите по ссылке ниже:
Исходный код: Нажмите здесь, чтобы загрузить исходный код, который вы будете использовать для создания хэш-таблицы на Python.
Познакомьтесь со структурой данных хэш-таблицы
Прежде чем погрузиться глубже, вам следует ознакомиться с терминологией, поскольку она может немного сбить с толку. В разговорной речи термин хэш-таблица или хэш-карта часто используется как взаимозаменяемый со словом словарь. Однако между этими двумя понятиями есть небольшая разница, поскольку первое является более конкретным, чем второе.
Хэш-таблица и словарь
В информатике словарь - это абстрактный тип данных, состоящий из ключей и значения расположены попарно. Кроме того, он определяет следующие операции для этих элементов:
- Добавить пару ключ-значение
- Удалить пару ключ-значение
- Обновите пару ключ-значение
- Найдите значение, связанное с данным ключом
В некотором смысле этот абстрактный тип данных напоминает двуязычный словарь , где ключами являются иностранные слова, а значениями - их определения или переводы на другие языки. Но не всегда должно быть ощущение эквивалентности между ключами и значениями. Телефонная книга - это еще один пример словаря, который объединяет имена с соответствующими телефонными номерами.
Примечание: Всякий раз, когда вы сопоставляете один объект с другим или связываете значение с ключом, вы, по сути, используете своего рода словарь. Вот почему словари также известны как карты или ассоциативные массивы.
Словари обладают несколькими интересными свойствами. Одно из них заключается в том, что словарь можно рассматривать как математическую функцию, которая преобразует один или несколько аргументов ровно в одно значение. Прямыми последствиями этого факта являются следующие:
- Только пары ключ-значение: У вас не может быть ключа без значения, или наоборот, в словаре. Они всегда ходят вместе.
- Произвольные ключи и значения: Ключи и значения могут принадлежать двум непересекающимся наборам одного или разных типов. Как ключи, так и значения могут быть практически любыми, например цифрами, словами или даже картинками.
- Неупорядоченные пары ключ-значение: Из-за последнего пункта словари обычно не определяют какой-либо порядок для своих пар ключ-значение. Однако это может зависеть от конкретной реализации.
- Уникальные ключи: Словарь не может содержать повторяющиеся ключи, поскольку это нарушило бы определение функции.
- Неуникальные значения: Одно и то же значение может быть связано со многими ключами, но это необязательно.
Существуют связанные понятия, которые расширяют идею словаря. Например, мультикарта позволяет использовать более одного значения для каждого ключа, в то время как двунаправленная карта не только сопоставляет ключи со значениями, но и обеспечивает отображение в обратном направлении направление. Однако в этом руководстве вы будете рассматривать только обычный словарь, который сопоставляет каждому ключу ровно одно значение.
Вот графическое изображение гипотетического словаря, который сопоставляет некоторые абстрактные понятия с соответствующими им английскими словами:
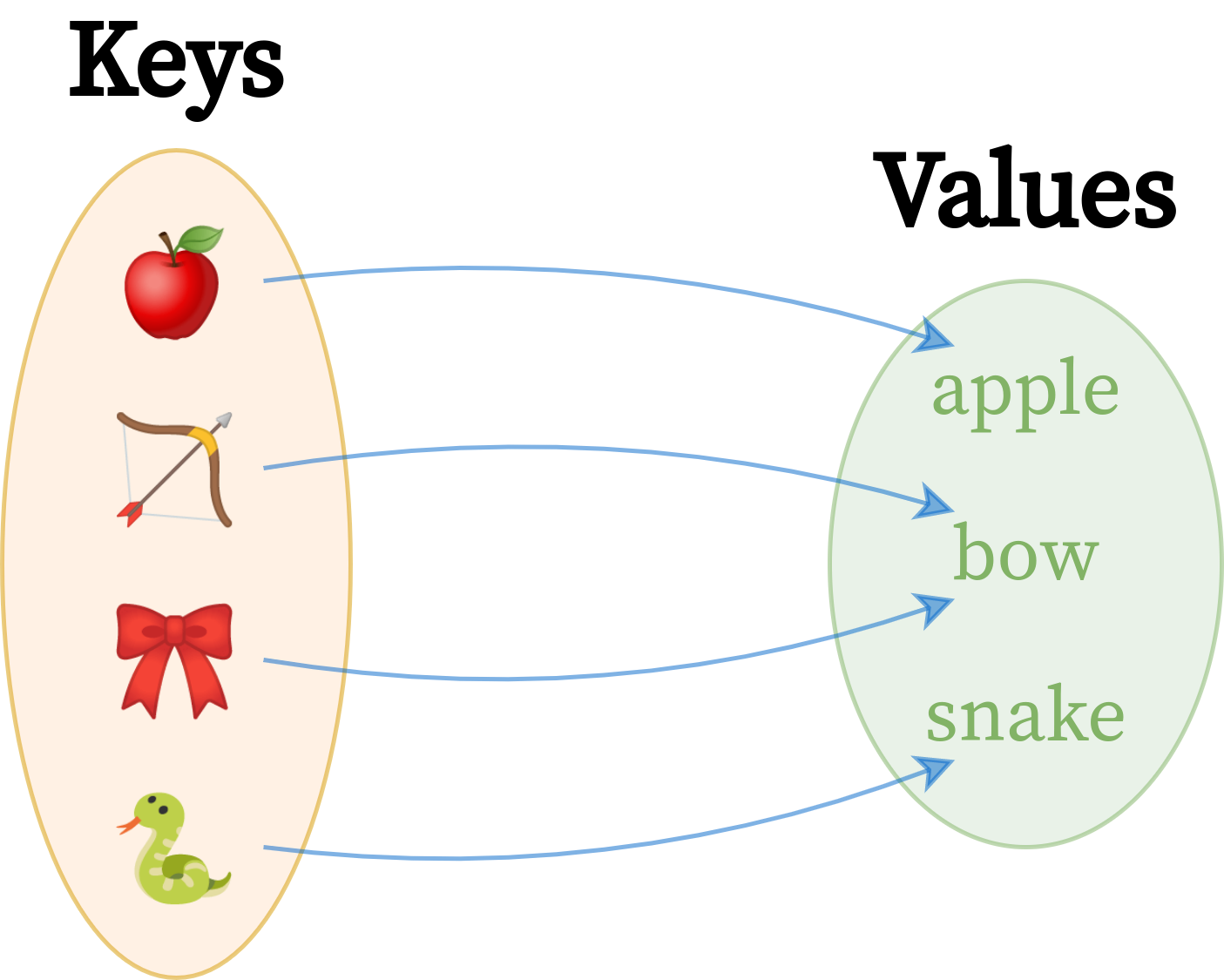 Графическое изображение абстрактного типа данных словаря
Графическое изображение абстрактного типа данных словаря
Это односторонняя карта ключей к значениям, которые представляют собой два совершенно разных набора элементов. Сразу же вы можете увидеть меньше значений, чем ключей, потому что слово лук является омонимом с несколькими значениями. Однако концептуально этот словарь по-прежнему содержит четыре пары. В зависимости от того, как вы решили это реализовать, вы можете повторно использовать повторяющиеся значения для экономии памяти или дублировать их для простоты.
Теперь, как вы кодируете такой словарь на языке программирования? Правильный ответ - вы не , потому что большинство современных языков имеют словари либо как примитивные типы данных, либо как классы в их стандартном исполнении библиотеки. Python поставляется со встроенным типом dict, который уже содержит оптимизированную структуру данных, написанную на C, так что вам не придется самостоятельно составлять словарь.
Программа Python dict позволяет выполнять все операции со словарем, перечисленные в начале этого раздела:
>>> glossary = {"BDFL": "Benevolent Dictator For Life"} >>> glossary["GIL"] = "Global Interpreter Lock" # Add >>> glossary["BDFL"] = "Guido van Rossum" # Update >>> del glossary["GIL"] # Delete >>> glossary["BDFL"] # Search 'Guido van Rossum' >>> glossary {'BDFL': 'Guido van Rossum'}Используя синтаксис квадратных скобок (
[ ]), вы можете добавить в словарь новую пару ключ-значение. Вы также можете обновить значение или удалить существующую пару, идентифицируемую ключом. Наконец, вы можете просмотреть значение, связанное с данным ключом.Тем не менее, вы можете задать другой вопрос. Как на самом деле работает встроенный словарь? Как он сопоставляет ключи произвольных типов данных и как ему удается это делать так быстро?
Поиск эффективной реализации этого абстрактного типа данных известен как проблема словаря. Одно из наиболее известных решений использует преимущества структуры данных хэш-таблицы, которую вы собираетесь изучить. Однако обратите внимание, что это не единственный способ реализации словаря в целом. Другая популярная реализация строится на вершине красно-черного дерева .
Хэш-таблица: Массив с хэш-функцией
Задумывались ли вы когда-нибудь, почему доступ к элементам последовательности в Python выполняется так быстро, независимо от того, какой индекс вы запрашиваете? Допустим, вы работали с очень длинной строкой символов, например, с этой:
>>> import string >>> text = string.ascii_uppercase * 100_000_000 >>> text[:50] # Show the first 50 characters 'ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWX' >>> len(text) 2600000000В переменной
text, указанной выше, содержится 2,6 миллиарда символов из повторяющихся букв ASCII, которые вы можете подсчитать с помощью Pythonlen()функция. Тем не менее, получение первого, среднего, последнего или любого другого символа из этой строки происходит одинаково быстро:>>> text[0] # The first element 'A' >>> text[len(text) // 2] # The middle element 'A' >>> text[-1] # The last element, same as text[len(text) - 1] 'Z'То же самое верно для всех типов последовательностей в Python, таких как списки и кортежи. Как так вышло? Секрет такой невероятной скорости заключается в том, что последовательности в Python поддерживаются массивом, который представляет собой структуру данных с произвольным доступом. Это следует двум принципам:
- Массив занимает непрерывных блока памяти.
- Каждый элемент в массиве имеет фиксированный размер, известный заранее.
Когда вы знаете адрес памяти массива, который называется смещением , вы можете мгновенно добраться до нужного элемента в массиве, вычислив довольно простую формулу:
Формула для вычисления адреса в памяти элемента последовательности
Вы начинаете со смещения массива, которое также является адресом первого элемента массива, с нулевым индексом. Затем вы продвигаетесь вперед, добавляя необходимое количество байт, которое вы получаете, умножая размер элемента на индекс целевого элемента. На умножение и сложение нескольких чисел всегда уходит одинаковое количество времени.
Примечание: В отличие от массивов, списки Python могут содержать разнородные элементы разного размера, что нарушило бы приведенную выше формулу. Чтобы смягчить это, Python добавляет еще один уровень косвенности, вводя массив из указателей на ячейки памяти вместо того, чтобы хранить значения непосредственно в массиве:
Массив указателей на адреса памяти
Указатели - это просто целые числа, которые всегда занимают одинаковое количество места. Адреса памяти принято обозначать с помощью шестнадцатеричной системы счисления . В Python и некоторых других языках к таким числам добавляется префикс
0x.Итак, вы знаете, что поиск элемента в массиве выполняется быстро, независимо от того, где этот элемент физически расположен. Можете ли вы воспользоваться той же идеей и повторно использовать ее в словаре? Да!
Хэш-таблицы получили свое название благодаря трюку под названием хэширование, который позволяет им преобразовывать произвольный ключ в целое число, которое может работать как индекс в обычном массиве. Таким образом, вместо поиска значения по числовому индексу вы будете искать его по произвольному ключу без заметной потери производительности. Это здорово!
На практике хэширование не будет работать с каждым ключом, но большинство встроенных типов в Python могут быть хэшированы. Если вы будете следовать нескольким правилам, то сможете создавать и свои собственные хэшируемые типы. Подробнее о хэшировании вы узнаете в следующем разделе.
Разберитесь в хэш-функции
Хэш-функция выполняет хэширование, преобразуя любые данные в последовательность байтов фиксированного размера, называемую хэш-значением или хэш-код. Это число, которое может выступать в качестве цифрового отпечатка пальца или дайджеста, обычно намного меньше исходных данных, что позволяет проверить их целостность. Если вы когда-либо загружали большой файл из Интернета, например, образ диска дистрибутива Linux, то, возможно, вы заметили MD5 или SHA-2 контрольная сумма на странице загрузки.
Помимо проверки целостности данных и решения проблемы со словарем, хэш-функции помогают в других областях, включая безопасность и криптографию. Например, обычно вы храните хэшированные пароли в базах данных, чтобы снизить риск утечки данных. Цифровые подписи включают хэширование для создания дайджеста сообщений перед шифрованием. Блокчейн транзакции являются еще одним ярким примером использования хэш-функции в криптографических целях.
Примечание: Криптографическая хэш-функция - это особый тип хэш-функции, который должен соответствовать нескольким дополнительным требованиям. Однако в этом руководстве вы познакомитесь только с самой базовой формой хэш-функции, используемой в структуре данных хэш-таблицы.
Хотя существует множество алгоритмов хэширования, все они обладают несколькими общими свойствами, с которыми вы познакомитесь в этом разделе. Правильная реализация хорошей хэш-функции - сложная задача, которая может потребовать понимания продвинутой математики, включающей простых чисел. К счастью, обычно вам не нужно реализовывать такой алгоритм вручную.
Python поставляется со встроенным модулем hashlib, который предоставляет множество хорошо известных криптографических хэш-функций, а также менее безопасные алгоритмы определения контрольной суммы. В языке также есть глобальная функция
hash(), используемая в основном для быстрого поиска элементов в словарях и наборах. Сначала вы можете изучить, как это работает, чтобы узнать о наиболее важных свойствах хэш-функций.Изучите встроенный в Python
hash()Прежде чем приступить к реализации хэш-функции с нуля, остановитесь на минутку и проанализируйте
hash()в Python, чтобы разобраться в ее свойствах. Это поможет вам понять, с какими проблемами приходится сталкиваться при разработке собственной хэш-функции.Примечание: Выбор хэш-функции может существенно повлиять на производительность вашей хэш-таблицы. Поэтому при построении пользовательской хэш-таблицы далее в этом руководстве вы будете полагаться на встроенную функцию
hash(). Реализация хэш-функции в этом разделе является лишь упражнением.Для начала попробуйте свои силы в вызове
hash()нескольких литералов типов данных, встроенных в Python, таких как числа и строки, чтобы увидеть, как ведет себя функция:>>> hash(3.14) 322818021289917443 >>> hash(3.14159265358979323846264338327950288419716939937510) 326490430436040707 >>> hash("Lorem") 7677195529669851635 >>> hash("Lorem ipsum dolor sit amet, consectetur adipisicing elit," ... "sed do eiusmod tempor incididunt ut labore et dolore magna" ... "aliqua. Ut enim ad minim veniam, quis nostrud exercitation" ... "ullamco laboris nisi ut aliquip ex ea commodo consequat." ... "Duis aute irure dolor in reprehenderit in voluptate velit" ... "esse cillum dolore eu fugiat nulla pariatur. Excepteur sint" ... "occaecat cupidatat non proident, sunt in culpa qui officia" ... "deserunt mollit anim id est laborum.") 1107552240612593693Уже есть несколько замечаний, которые вы можете сделать, посмотрев на результат. Во-первых, встроенная хэш-функция может возвращать разные значения для некоторых входных данных, показанных выше. В то время как числовой ввод, по-видимому, всегда выдает идентичное хэш-значение, строка, скорее всего, этого не делает. Почему это так?» Может показаться, что
hash()- это недетерминированная функция, но это не может быть дальше от истины!Когда вы вызываете
hash()с тем же аргументом в рамках существующего сеанса интерпретатора, вы продолжаете получать тот же результат:>>> hash("Lorem") 7677195529669851635 >>> hash("Lorem") 7677195529669851635 >>> hash("Lorem") 7677195529669851635Это потому, что хэш-значения являются неизменяемыми и не меняются на протяжении всего срока службы объекта. Однако, как только вы выйдете из Python и запустите его снова, вы почти наверняка увидите разные значения хэша при вызовах Python. Вы можете проверить это, попробовав опцию
-cдля запуска однострочного скрипта в вашем терминале:C:\> python -c print(hash('Lorem')) 6182913096689556094 C:\> python -c print(hash('Lorem')) 1756821463709528809 C:\> python -c print(hash('Lorem')) 8971349716938911741$ python -c 'print(hash("Lorem"))' 6182913096689556094 $ python -c 'print(hash("Lorem"))' 1756821463709528809 $ python -c 'print(hash("Lorem"))' 8971349716938911741Это ожидаемое поведение, которое было реализовано в Python в качестве контрмеры против атаки типа "Отказ в обслуживании" (DoS), которая использовала известную уязвимость хэш-функций на веб-серверах. Злоумышленники могли использовать слабый алгоритм хэширования для преднамеренного создания так называемых коллизий хэшей, перегружая сервер и делая его недоступным. Типичным мотивом атаки был выкуп, поскольку большинство жертв зарабатывали деньги за счет постоянного присутствия в Сети.
Сегодня Python по умолчанию включает рандомизацию хэша для некоторых входных данных, таких как строки, чтобы сделать значения хэша менее предсказуемыми. Это делает
hash()немного более безопасным и затрудняет атаку. Однако вы можете отключить рандомизацию, установив фиксированное начальное значение с помощью переменной окруженияPYTHONHASHSEED, например:C:\> set PYTHONHASHSEED=1 C:\> python -c print(hash('Lorem')) 440669153173126140 C:\> python -c print(hash('Lorem')) 440669153173126140 C:\> python -c print(hash('Lorem')) 440669153173126140$ PYTHONHASHSEED=1 python -c 'print(hash("Lorem"))' 440669153173126140 $ PYTHONHASHSEED=1 python -c 'print(hash("Lorem"))' 440669153173126140 $ PYTHONHASHSEED=1 python -c 'print(hash("Lorem"))' 440669153173126140Теперь каждый вызов Python выдает одно и то же значение хэша для известных входных данных. Это может помочь в разделении или совместном использовании данных в кластере распределенных интерпретаторов Python. Просто будьте осторожны и осознайте риски, связанные с отключением рандомизации хэша. В целом,
hash()в Python действительно является детерминированной функцией, которая является одной из самых фундаментальных особенностей хэш-функции.Кроме того,
hash()кажется довольно универсальным, поскольку он принимает произвольные входные данные. Другими словами, он принимает значения различных типов и размеров. Функция без проблем принимает строки и числа с плавающей запятой независимо от их длины или величины. На самом деле, вы можете вычислять хэш-значения и более экзотических типов:>>> hash(None) 5904497366826 >>> hash(hash) 2938107101725 >>> class Person: ... pass ... >>> hash(Person) 5904499092884 >>> hash(Person()) 8738841746871 >>> hash(Person()) 8738841586112Здесь вы вызвали хэш-функцию для объекта
Noneв Python, саму функциюhash()и даже пользовательскуюPersonкласс с несколькими его экземплярами. Тем не менее, не все объекты имеют соответствующее хэш-значение. Функцияhash()вызовет исключение, если вы попытаетесь вызвать ее для одного из этих немногих объектов:>>> hash([1, 2, 3]) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list'Базовый тип входных данных будет определять, сможете ли вы вычислить хэш-значение. В Python экземпляры встроенных изменяемых типов, таких как списки, наборы и dicts, не являются хэшируемыми. Вы получили представление о том, почему это так, но подробнее вы узнаете в следующем разделе. На данный момент вы можете предположить, что большинство типов данных в целом должны работать с хэш-функцией.
Погрузитесь глубже в язык Python.
hash()Еще одной интересной характеристикой
hash()является то, что она всегда выдает результат фиксированного размера независимо от того, насколько большими были входные данные. В Python хэш-значение представляет собой целое число с умеренной величиной. Иногда оно может быть отрицательным, поэтому примите это во внимание, если вы планируете так или иначе полагаться на хэш-значения:>>> hash("Lorem") -972535290375435184Естественным следствием вывода данных фиксированного размера является то, что большая часть исходной информации необратимо теряется в процессе обработки. Это нормально, поскольку вы хотите, чтобы результирующее значение хэша действовало как единый свод сколь угодно больших данных. Однако, поскольку хэш-функция проецирует потенциально бесконечный набор значений на конечное пространство, это может привести к коллизии хэшей, когда два разных входных сигнала выдают одно и то же хэш-значение.
Примечание: Если вы склонны к математике, то вы могли бы использовать принцип упорядочения для более формального описания коллизий хэшей:
Задано m элементов и n контейнеров, если m > n, то существует по крайней мере один контейнер с более чем одним элементом.
В этом контексте элементы - это потенциально бесконечное число значений, которые вы вводите в хэш-функцию, в то время как контейнеры - это их хэш-значения, назначенные из конечного пула.
Коллизии хэшей - это важная концепция хэш-таблиц, к которой вы вернетесь позже более подробно при реализации вашей пользовательской хэш-таблицы. На данный момент вы можете считать их крайне нежелательными. Вам следует по возможности избегать коллизий хэшей, поскольку они могут привести к очень неэффективному поиску и могут быть использованы хакерами. Следовательно, хорошая хэш-функция должна минимизировать вероятность коллизии хэшей как для обеспечения безопасности, так и для повышения эффективности.
На практике это часто означает, что хэш-функция должна присваивать равномерно распределенные значения в доступном пространстве. Вы можете визуализировать распределение хэш-значений, полученных с помощью
hash()в Python, построив текстовую гистограмму в вашем терминале. Скопируйте следующий блок кода и сохраните его в файле с именемhash_distribution.py:# hash_distribution.py from collections import Counter def distribute(items, num_containers, hash_function=hash): return Counter([hash_function(item) % num_containers for item in items]) def plot(histogram): for key in sorted(histogram): count = histogram[key] padding = (max(histogram.values()) - count) * " " print(f"{key:3} {'■' * count}{padding} ({count})")В нем используется
Counterэкземпляр для удобного представления гистограммы хэш-значений предоставленных элементов. Значения хэша распределяются по указанному количеству контейнеров путем их переноса с помощью оператора по модулю. Теперь вы можете взять, например, сто символов ASCII, пригодных для печати, затем вычислить их хэш-значения и показать их распределение:>>> from hash_distribution import plot, distribute >>> from string import printable >>> plot(distribute(printable, num_containers=2)) 0 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (51) 1 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (49) >>> plot(distribute(printable, num_containers=5)) 0 ■■■■■■■■■■■■■■■ (15) 1 ■■■■■■■■■■■■■■■■■■■■■■■■■■ (26) 2 ■■■■■■■■■■■■■■■■■■■■■■ (22) 3 ■■■■■■■■■■■■■■■■■■ (18) 4 ■■■■■■■■■■■■■■■■■■■ (19)Если контейнеров всего два, то следует ожидать примерно равного распределения. Добавление большего количества контейнеров должно привести к более или менее равномерному их заполнению. Как вы можете видеть, встроенная функция
hash()довольно хороша, но не идеальна для равномерного распределения значений хэша.В связи с этим равномерное распределение хэш-значений обычно является псевдослучайным, что особенно важно для криптографических хэш-функций. Это не позволяет потенциальным злоумышленникам использовать статистический анализ, чтобы попытаться предсказать корреляцию между вводимыми и выводимыми данными хэш-функции. Попробуйте изменить одну букву в строке и проверьте, как это повлияет на результирующее значение хэша в Python:
>>> hash("Lorem") 1090207136701886571 >>> hash("Loren") 4415277245823523757Теперь это совершенно другое хэш-значение, несмотря на то, что отличается только одна буква. Хэш-значения часто подвержены лавинообразному эффекту, поскольку даже малейшее изменение входных данных усиливается. Тем не менее, эта особенность хэш-функции не является существенной для реализации структуры данных хэш-таблицы.
В большинстве случаев
hash()в Python реализована еще одна несущественная особенность криптографических хэш-функций, которая вытекает из упомянутого ранее принципа разделения. Она ведет себя как односторонняя функция, поскольку в большинстве случаев найти ее обратную функцию практически невозможно. Однако есть заметные исключения:>>> hash(42) 42Хэш-значения небольших целых чисел равны сами себе, что является деталью реализации, которую CPython использует для простоты и эффективности. Имейте в виду, что фактические значения хэша не имеют значения до тех пор, пока вы можете вычислить их детерминированным способом.
И последнее, но не менее важное: вычисление хэш-значения в Python выполняется быстро даже для очень больших входных данных. На современном компьютере вызов
hash()со строкой из 100 миллионов символов в качестве аргумента возвращает результат мгновенно. Если бы это было не так быстро, то дополнительные затраты на вычисление значения хэша в первую очередь свели бы на нет преимущества хэширования.Определение свойств хэш-функции
Основываясь на том, что вы уже узнали о
hash()в Python, теперь вы можете сделать выводы о желаемых свойствах хэш-функции в целом. Вот краткое описание этих функций, сравнивающее обычную хэш-функцию с ее криптографической разновидностью:
Feature Hash Function Cryptographic Hash Function Deterministic ✔️ ✔️ Universal Input ✔️ ✔️ Fixed-Sized Output ✔️ ✔️ Fast to Compute ✔️ ✔️ Uniformly Distributed ✔️ ✔️ Randomly Distributed ✔️ Randomized Seed ✔️ One-Way Function ✔️ Avalanche Effect ✔️ Цели обоих типов хэш-функций совпадают, поэтому у них есть несколько общих черт. С другой стороны, криптографическая хэш-функция обеспечивает дополнительные гарантии безопасности.
Прежде чем создавать свою собственную хэш-функцию, вы ознакомитесь с другой функцией, встроенной в Python, которая, по-видимому, является ее наиболее простой заменой.
Сравните Идентификатор Объекта с Его Хэшем
Вероятно, одной из самых простых реализаций хэш-функции, которые только можно вообразить в Python, является встроенная
id(), которая сообщает вам идентификатор объекта. В стандартном интерпретаторе Python идентификатор совпадает с адресом памяти объекта, выраженным в виде целого числа:>>> id("Lorem") 139836146678832Функция
id()обладает большинством необходимых свойств хэш-функции. В конце концов, она очень быстрая и работает с любыми входными данными. Она возвращает целое число фиксированного размера детерминированным образом. В то же время, вы не сможете легко восстановить исходный объект на основе его адреса в памяти. Сами адреса памяти неизменяемы в течение всего времени существования объекта и в некоторой степени рандомизируются между запусками интерпретатора.Итак, почему же тогда Python настаивает на использовании другой функции для хэширования?
Прежде всего, назначение
id()отличается отhash(), поэтому другие дистрибутивы Python могут реализовывать идентификацию альтернативными способами. Во-вторых, адреса памяти предсказуемы без равномерного распределения, что небезопасно и крайне неэффективно для хэширования. Наконец, одинаковые объекты, как правило, должны выдавать один и тот же хэш-код, даже если они имеют разные идентификаторы.Примечание: Позже вы узнаете больше о контракте между равенством значений и соответствующими хэш-кодами.
Покончив с этим, вы, наконец, можете подумать о создании своей собственной хэш-функции.
Создайте свою собственную хэш-функцию
Разработать хэш-функцию, отвечающую всем требованиям, с нуля сложно. Как упоминалось ранее, в следующем разделе вы будете использовать встроенную функцию
hash()для создания прототипа вашей хэш-таблицы. Однако попытка создать хэш-функцию с нуля - отличный способ узнать, как она работает. К концу этого раздела у вас будет только элементарная хэш-функция, которая далека от совершенства, но вы получите ценную информацию.В этом упражнении вы можете сначала ограничиться только одним типом данных и реализовать на его основе грубую хэш-функцию. Например, вы могли бы рассмотреть строки и суммировать порядковые значения отдельных символов в них:
>>> def hash_function(text): ... return sum(ord(character) for character in text)Вы выполняете итерацию по тексту, используя генераторное выражение, затем преобразуете каждый отдельный символ в соответствующую кодовую точку в Юникоде с помощью встроенногов функции
ord()и, наконец, суммируйте порядковые значения вместе. Это приведет к выдаче единственного числа для любого заданного текста, предоставленного в качестве аргумента:>>> hash_function("Lorem") 511 >>> hash_function("Loren") 512 >>> hash_function("Loner") 512Сразу же вы заметите несколько проблем с этой функцией. Она не только привязана к конкретной строке, но и страдает от плохого распределения хэш-кодов, которые, как правило, образуют кластеры при одинаковых входных значениях. Небольшое изменение входных данных практически не влияет на наблюдаемый результат. Хуже того, функция остается нечувствительной к порядку символов в тексте, что означает анаграммы одного и того же слова, такие как Лорен и Одиночка, приводит к коллизии хэш-кода.
Чтобы устранить первую проблему, попробуйте преобразовать входные данные в строку с помощью вызова
str(). Теперь ваша функция сможет обрабатывать аргументы любого типа:>>> def hash_function(key): ... return sum(ord(character) for character in str(key)) >>> hash_function("Lorem") 511 >>> hash_function(3.14) 198 >>> hash_function(True) 416Вы можете вызвать
hash_function()с аргументом любого типа данных, включая строку, число с плавающей запятой или логическое значение.Обратите внимание, что эта реализация будет настолько же хороша, насколько и соответствующее строковое представление. Некоторые объекты могут не иметь текстового представления, подходящего для приведенного выше кода. В частности, хорошим примером являются экземпляры пользовательского класса без надлежащим образом реализованных специальных методов
.__str__()и.__repr__(). Кроме того, вы больше не сможете различать различные типы данных:>>> hash_function("3.14") 198 >>> hash_function(3.14) 198На самом деле, вы бы хотели рассматривать строку
"3.14"и число с плавающей запятой3.14как разные объекты с разными хэш-кодами. Один из способов смягчить это - заменитьstr()наrepr(),, который содержит представление строк с дополнительными апострофами ('):>>> repr("3.14") "'3.14'" >>> repr(3.14) '3.14'Это в некоторой степени улучшит вашу хэш-функцию:
>>> def hash_function(key): ... return sum(ord(character) for character in repr(key)) >>> hash_function("3.14") 276 >>> hash_function(3.14) 198Строки теперь можно отличить от чисел. Чтобы решить проблему с анаграммами, такими как Лорен и Одиночка, вы можете изменить свою хэш-функцию, приняв во внимание значение символа, а также его положение внутри текст:
>>> def hash_function(key): ... return sum( ... index * ord(character) ... for index, character in enumerate(repr(key), start=1) ... )Здесь вы берете сумму произведений, полученных в результате умножения порядковых значений символов и соответствующих им индексов. Обратите внимание, что вы перечисляете индексы, начиная с единицы, а не с нуля. В противном случае первый символ всегда отбрасывался бы, так как его значение умножалось бы на ноль.
Теперь ваша хэш-функция достаточно универсальна и не вызывает такого количества коллизий, как раньше, но ее выходные данные могут быть сколь угодно большими, потому что чем длиннее строка, тем больше хэш-код. Кроме того, она довольно медленная для больших входных данных:
>>> hash_function("Tiny") 1801 >>> hash_function("This has a somewhat medium length.") 60919 >>> hash_function("This is very long and slow!" * 1_000_000) 33304504435500117Вы всегда можете решить проблему неограниченного роста, сопоставив модуль (
%) вашего хэш-кода с известным максимальным размером, например, сто:>>> hash_function("Tiny") % 100 1 >>> hash_function("This has a somewhat medium length.") % 100 19 >>> hash_function("This is very long and slow!" * 1_000_000) % 100 17Помните, что выбор меньшего количества хэш-кодов увеличивает вероятность коллизий с хэш-кодами. Если вы заранее не знаете количество вводимых значений, то лучше отложить это решение на потом, если сможете. Вы также можете установить ограничение на свои хэш-коды, установив разумное максимальное значение, например,
sys.maxsize, которое представляет собой наибольшее значение целых чисел, изначально поддерживаемых в Python.Не обращая внимания на низкую скорость работы функции, вы заметите еще одну странную проблему с вашей хэш-функцией. Это приводит к неоптимальному распределению хэш-кодов с помощью кластеризации и не позволяет использовать все доступные интервалы:
>>> from hash_distribution import plot, distribute >>> from string import printable >>> plot(distribute(printable, 6, hash_function)) 0 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (31) 1 ■■■■ (4) 2 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (31) 4 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (33) 5 ■ (1)Распределение неравномерное. Кроме того, доступно шесть контейнеров, но на гистограмме отсутствует один. Эта проблема связана с тем, что два апострофа, добавленные с помощью
repr(), приводят к тому, что практически все ключи в этом примере приводят к четному хэш-номеру. Вы можете избежать этого, удалив левый апостроф, если он существует:>>> hash_function("a"), hash_function("b"), hash_function("c") (350, 352, 354) >>> def hash_function(key): ... return sum( ... index * ord(character) ... for index, character in enumerate(repr(key).lstrip("'"), 1) ... ) >>> hash_function("a"), hash_function("b"), hash_function("c") (175, 176, 177) >>> plot(distribute(printable, 6, hash_function)) 0 ■■■■■■■■■■■■■■■■ (16) 1 ■■■■■■■■■■■■■■■■ (16) 2 ■■■■■■■■■■■■■■■ (15) 3 ■■■■■■■■■■■■■■■■■■ (18) 4 ■■■■■■■■■■■■■■■■■ (17) 5 ■■■■■■■■■■■■■■■■■■ (18)Вызов
str.lstrip()повлияет на строку только в том случае, если она начинается с указанного префикса strip.Естественно, вы можете продолжать совершенствовать свою хэш-функцию и дальше. Если вам интересно узнать о реализации
hash()для строк и байтовых последовательностей в Python, то в настоящее время в нем используется алгоритм SipHash, который может вернуться к модифицированной версии FNV, если первый недоступен. Чтобы узнать, какой алгоритм хэширования использует ваш интерпретатор Python, перейдите к модулюsys:>>> import sys >>> sys.hash_info.algorithm 'siphash24'На данный момент вы довольно хорошо представляете себе хэш-функцию, как она должна работать и с какими трудностями вы можете столкнуться при ее реализации. В следующих разделах вы будете использовать хэш-функцию для построения хэш-таблицы. Выбор конкретного алгоритма хэширования будет влиять на производительность хэш-таблицы. Опираясь на эти знания, вы можете смело использовать встроенный
hash().Создайте прототип хэш-таблицы на Python с помощью TDD
В этом разделе вы создадите пользовательский класс, представляющий структуру данных хэш-таблицы. Он не будет поддерживаться словарем Python, поэтому вы можете создать хэш-таблицу с нуля и попрактиковаться в том, чему вы уже научились. В то же время вы будете моделировать свою реализацию по образцу встроенного словаря, имитируя его наиболее важные функции.
Примечание: Это всего лишь краткое напоминание о том, что внедрение хэш-таблицы - это всего лишь упражнение и образовательный инструмент, который расскажет вам о проблемах, решаемых этой структурой данных. Как и при кодировании пользовательской хэш-функции ранее, реализация хэш-таблицы на чистом Python не имеет практического применения в реальных приложениях.
Ниже приведен список требований высокого уровня к вашей хэш-таблице, которые вы будете выполнять сейчас. К концу этого раздела ваша хэш-таблица будет обладать следующими основными функциями. Это позволит вам:
- Создайте пустую хэш-таблицу
- Вставьте пару ключ-значение в хэш-таблицу
- Удалить пару ключ-значение из хэш-таблицы
- Найти значение по ключу в хэш-таблице
- Обновите значение, связанное с существующим ключом
- Проверьте, есть ли в хэш-таблице заданный ключ
В дополнение к этому вы реализуете несколько несущественных, но все же полезных функций. В частности, вы должны уметь:
- Создайте хэш-таблицу из словаря Python
- Создайте неглубокую копию существующей хэш-таблицы
- Возвращает значение по умолчанию, если соответствующий ключ не найден
- Сообщает количество пар ключ-значение, хранящихся в хэш-таблице
- Возвращать ключи, значения и пары ключ-значение
- Сделать хэш-таблицу повторяемой
- Сделайте хэш-таблицу сопоставимой, используя оператор проверки на равенство
- Покажите текстовое представление хэш-таблицы
При реализации этих функций вы будете активно использовать разработку на основе тестирования, постепенно добавляя дополнительные функции в свою хэш-таблицу. Обратите внимание, что ваш прототип будет охватывать только основы. Чуть позже в этом руководстве вы узнаете, как справиться с некоторыми более сложными угловыми ситуациями. В частности, в этом разделе не будет рассказано о том, как:
- Устранить коллизии хэш-кода
- Сохранить порядок вставки
- Динамически изменять размер хэш-таблицы
- Рассчитать коэффициент загрузки
Не стесняйтесь использовать дополнительные материалы в качестве контрольных точек, если вы застряли или хотите пропустить некоторые промежуточные этапы рефакторинга. Каждый подраздел заканчивается полным этапом внедрения и соответствующими тестами, с которых вы можете начать. Перейдите по следующей ссылке и загрузите вспомогательные материалы с полным исходным кодом и промежуточными шагами, использованными в этом руководстве:
Исходный код: Нажмите здесь, чтобы загрузить исходный код, который вы будете использовать для создания хэш-таблицы на Python.
Пройдите ускоренный курс по разработке на основе тестирования
Теперь, когда вы знаете высокоуровневые свойства хэш-функции и ее назначение, вы можете применить подход к разработке на основе тестирования для построения хэш-таблицы. Если вы никогда раньше не пробовали этот метод программирования, то он сводится к трем шагам, которые вы, как правило, повторяете в цикле:
- 🟥 Red: Придумайте один тестовый пример и автоматизируйте его, используя модульное тестирование фреймворк по вашему выбору. На этом этапе ваш тест завершится неудачей, но это нормально. Участники тестирования обычно обозначают неудачный тест красным цветом, отсюда и название этой фазы цикла.
- 🟩 Зеленый: Реализуйте самый минимум, чтобы ваш тест прошел успешно, но не более того! Это обеспечит более высокий охват кода и избавит вас от написания избыточного кода. После этого отчет о тестировании загорится приятным зеленым цветом.
- ♻️ Рефакторинг: При необходимости измените свой код, не меняя его поведения, пока все тестовые примеры по-прежнему проходят проверку. Вы можете использовать это как возможность устранить дублирование и улучшить читаемость вашего кода.
Python поставляется с пакетом unittest "из коробки", но сторонняя библиотека pytest имеет, возможно, более низкую степень освоения, так что вы будете использовать это в этом руководстве вместо этого. Продолжайте и установите
pytestв свою виртуальную среду прямо сейчас:(venv) C:\> python -m pip install pytest(venv) $ python -m pip install pytestПомните, что вы можете проверить каждый этап реализации с помощью нескольких контрольных точек. Затем создайте файл с именем
test_hashtable.pyи определите в нем фиктивную тестовую функцию, чтобы проверить, примет ли ее pytest:# test_hashtable.py def test_should_always_pass(): assert 2 + 2 == 22, "This is just a dummy test"Фреймворк использует встроенную инструкцию
assertдля запуска ваших тестов и составления отчета об их результатах. Это означает, что вы можете просто использовать обычный синтаксис Python, не импортируя никаких специальных API до тех пор, пока это не станет абсолютно необходимым. Он также распознает тестовые файлы и тестовые функции, если их имена начинаются с префиксаtest.Оператор
assertпринимает логическое выражение в качестве аргумента, за которым следует необязательное сообщение об ошибке. Когда условие принимает значениеTrue, ничего не происходит, как если бы никакого утверждения вообще не было. В противном случае Python вызоветAssertionErrorи отобразит сообщение в стандартном потоке ошибок (stderr). Тем временем pytest перехватывает ошибки в утверждениях и строит отчет на их основе.Теперь откройте терминал, измените свой рабочий каталог на тот, в котором вы сохранили тестовый файл, и запустите команду
pytestбез каких-либо аргументов. Результат должен выглядеть примерно так:(venv) C:\> python -m pytest =========================== test session starts =========================== platform win32 -- Python 3.10.2, pytest-6.2.5, pluggy-1.0.0 rootdir: C:\Users\realpython\hashtable collected 1 item test_hashtable.py F [100%] ================================ FAILURES ================================= _________________________ test_should_always_pass _________________________ def test_should_always_pass(): > assert 2 + 2 == 22, "This is just a dummy test" E AssertionError: This is just a dummy test E assert (2 + 2) == 22 test_hashtable.py:4: AssertionError ========================= short test summary info ========================= FAILED test_hashtable.py::test_should_always_pass - AssertionError: This... ============================ 1 failed in 0.03s ============================(venv) $ pytest =========================== test session starts =========================== platform linux -- Python 3.10.0, pytest-6.2.5, py-1.11.0, pluggy-1.0.0 rootdir: /home/realpython/hashtable collected 1 item test_hashtable.py F [100%] ================================ FAILURES ================================= _________________________ test_should_always_pass _________________________ def test_should_always_pass(): > assert 2 + 2 == 22, "This is just a dummy test" E AssertionError: This is just a dummy test E assert (2 + 2) == 22 test_hashtable.py:4: AssertionError ========================= short test summary info ========================= FAILED test_hashtable.py::test_should_always_pass - AssertionError: This... ============================ 1 failed in 0.03s ============================Ого. В вашем тесте произошел сбой. Чтобы найти основную причину, увеличьте детализацию выходных данных pytest, добавив к команде флаг
-v. Теперь вы можете точно определить, в чем заключается проблема:def test_should_always_pass(): > assert 2 + 2 == 22, "This is just a dummy test" E AssertionError: This is just a dummy test E assert 4 == 22 E +4 E -22Выходные данные показывают, какими были фактические и ожидаемые значения для неудачного утверждения. В этом случае при сложении двух плюс два получается четыре, а не двадцать два. Вы можете исправить код, исправив ожидаемое значение:
# test_hashtable.py def test_should_always_pass(): assert 2 + 2 == 4, "This is just a dummy test"При повторном запуске pytest сбоев в тестировании больше быть не должно:
(venv) C:\> python -m pytest =========================== test session starts =========================== platform win32 -- Python 3.10.2, pytest-6.2.5, pluggy-1.0.0 rootdir: C:\Users\realpython\hashtable collected 1 item test_hashtable.py . [100%] ============================ 1 passed in 0.00s ============================(venv) $ pytest =========================== test session starts =========================== platform linux -- Python 3.10.0, pytest-6.2.5, py-1.11.0, pluggy-1.0.0 rootdir: /home/realpython/hashtable collected 1 item test_hashtable.py . [100%] ============================ 1 passed in 0.00s ============================Вот и все! Вы только что изучили основные шаги по автоматизации тестовых примеров для вашей реализации хэш-таблицы. Естественно, вы можете использовать IDE, такую как PyCharm, или редактор, такой как VS Code, который интегрируется с платформами тестирования, если вам так удобнее. Далее вы собираетесь применить эти новые знания на практике.
Определите пользовательский класс
HashTableНе забудьте выполнить цикл красный-зеленый-рефакторинг, описанный ранее. Таким образом, вы должны начать с определения вашего первого тестового примера. Например, вы должны иметь возможность создать экземпляр новой хэш-таблицы, вызвав гипотетический класс
HashTable, импортированный из модуляhashtable. Этот вызов должен возвращать непустой объект:# test_hashtable.py from hashtable import HashTable def test_should_create_hashtable(): assert HashTable() is not NoneНа этом этапе ваш тест откажется выполняться из-за невыполненной инструкции import в верхней части файла. В конце концов, вы находитесь в красной фазе. Красная фаза - это единственное время, когда вам разрешено добавлять новые функции, поэтому продолжайте и создайте еще один модуль с именем
hashtable.pyи поместите в него определение классаHashTable:# hashtable.py class HashTable: passЭто простой заполнитель класса, но его должно быть достаточно, чтобы ваш тест прошел успешно. Кстати, если вы используете редактор кода, то вы можете удобно разделить представление на столбцы, отображая тестируемый код и соответствующие тесты рядом:
Разделение экрана в PyCharm
Если вам интересна цветовая гамма, изображенная на скриншоте выше, то это тема Дракула. Он доступен для многих редакторов кода, а не только для PyCharm.
Как только запуск pytest завершится успешно, вы можете начать думать о другом тестовом примере, поскольку пока практически нечего перерабатывать. Например, базовая хэш-таблица должна содержать последовательность значений. На этом раннем этапе вы можете предположить, что последовательность имеет фиксированный размер, установленный во время создания хэш-таблицы. Соответствующим образом измените существующий тестовый пример:
# test_hashtable.py from hashtable import HashTable def test_should_create_hashtable(): assert HashTable(size=100) is not NoneВы указываете размер, используя аргумент ключевого слова. Однако, прежде чем добавлять новый код в класс
HashTable, повторно запустите тесты, чтобы убедиться, что вы снова перешли в красную фазу. Наблюдение за неудачным тестом может оказаться бесценным. Когда вы позже реализуете фрагмент кода, вы узнаете, удовлетворяет ли он определенной группе тестов или они остаются незатронутыми. В противном случае ваши тесты могут вас обмануть, подтвердив что-то отличное от того, что вы думали!После подтверждения того, что вы находитесь в красной фазе, объявите метод
.__init__()в классеHashTableс ожидаемой сигнатурой, но не реализовывайте его тело:# hashtable.py class HashTable: def __init__(self, size): passБум! Вы снова вернулись к активной фазе, так как насчет небольшого рефакторинга на этот раз? Например, вы могли бы переименовать аргумент
sizeвcapacity, если это более наглядно для вас. Не забудьте сначала изменить тестовый пример, затем запустить pytest и всегда обновлять тестируемый код в качестве последнего шага:# hashtable.py class HashTable: def __init__(self, capacity): passКак вы можете заметить, цикл "красный-зеленый-рефакторинг" состоит из коротких этапов, каждый из которых часто длится не более нескольких секунд. Итак, почему бы вам не продолжить, добавив больше тестовых примеров? Было бы неплохо, если бы ваша структура данных могла сообщать о емкости хэш-таблицы, используя встроенную функцию Python
len(). Добавьте еще один тестовый пример и понаблюдайте, как он с треском проваливается:# test_hashtable.py from hashtable import HashTable def test_should_create_hashtable(): assert HashTable(capacity=100) is not None def test_should_report_capacity(): assert len(HashTable(capacity=100)) == 100Для корректной обработки
len()необходимо реализовать специальный метод.__len__()в вашем классе и запомните емкость, предоставляемую через инициализатор класса:# hashtable.py class HashTable: def __init__(self, capacity): self.capacity = capacity def __len__(self): return self.capacityВы можете подумать, что TDD не продвигает вас в правильном направлении. Возможно, вы не так представляли себе реализацию хэш-таблицы. Где последовательность значений, с которой вы начинали? К сожалению, при разработке на основе тестирования часто критикуют использование маленьких шагов и внесение большого количества исправлений в курс. Поэтому, возможно, это не подходит для проектов, требующих большого количества экспериментов.
С другой стороны, реализация хорошо известной структуры данных, такой как хэш-таблица, является идеальным применением этой методологии разработки программного обеспечения. У вас есть четкие ожидания, которые легко сформулировать в виде тестовых примеров. Вскоре вы сами увидите, что следующий шаг приведет к небольшим изменениям в реализации. Однако не беспокойтесь об этом, потому что совершенствование самого кода менее важно, чем успешное выполнение ваших тестовых примеров.
Поскольку вы продолжаете добавлять новые ограничения в тестовых примерах, вам часто приходится переосмысливать свою реализацию. Например, новая хэш-таблица, вероятно, должна начинаться с пустых ячеек для сохраненных значений:
# test_hashtable.py # ... def test_should_create_empty_value_slots(): assert HashTable(capacity=3).values == [None, None, None]Другими словами, новая хэш-таблица должна содержать атрибут
.values, имеющий запрошенную длину и заполненный элементамиNone. Кстати, обычно используются такие подробные названия функций, потому что они будут отображаться в вашем отчете о тестировании. Чем более понятными и описательными будут ваши тесты, тем быстрее вы поймете, какая часть нуждается в исправлении.Примечание: Как правило, ваши тестовые примеры должны быть как можно более независимыми и атомарными, что обычно означает использование только одного утверждения для каждой функции. Тем не менее, ваши тестовые сценарии иногда могут нуждаться в некоторой настройке или демонтаже. Они также могут включать в себя несколько шагов. В таких случаях принято структурировать вашу функцию на основе так называемого соглашения дано-когда-затем:
def test_should_create_empty_value_slots(): # Given expected_values = [None, None, None] hash_table = HashTable(capacity=3) # When actual_values = hash_table.values # Then assert actual_values == expected_valuesЧасть , приведенная в , описывает начальное состояние и предварительные условия для вашего тестового примера, в то время как , когда , представляет действие вашего тестируемого кода, и , то отвечает за утверждение конечного результата.
Это один из многих возможных способов выполнить существующие тесты:
# hashtable.py class HashTable: def __init__(self, capacity): self.values = capacity * [None] def __len__(self): return len(self.values)Вы заменяете атрибут
.capacityсписком требуемой длины, содержащим толькоNoneэлемента. Умножение числа на список или наоборот - это быстрый способ заполнить этот список заданным значением или значениями. Кроме этого, вы обновляете специальный метод.__len__(), чтобы все тесты прошли успешно.Примечание: Длина словаря Python соответствует фактическому количеству хранимых пар ключ-значение, а не его внутреннему объему. Вскоре вы достигнете аналогичного эффекта.
Теперь, когда вы познакомились с TDD, пришло время углубиться и добавить остальные функции в вашу хэш-таблицу.
Вставьте пару Ключ-значение
Теперь, когда вы можете создать хэш-таблицу, пришло время предоставить ей некоторые возможности для хранения. Традиционная хэш-таблица поддерживается массивом, способным хранить только один тип данных. Из-за этого реализации хэш-таблиц на многих языках, таких как Java, требуют, чтобы вы заранее объявляли тип их ключей и значений:
Map<String, Integer> phonesByNames = new HashMap<>();Например, эта конкретная хэш-таблица преобразует строки в целые числа. Однако, поскольку массивы не являются встроенными в Python, вы продолжите использовать вместо них список. В качестве побочного эффекта ваша хэш-таблица сможет принимать произвольные типы данных как для ключей, так и для значений, точно так же, как в Python
dict.Примечание: В Python есть эффективная коллекция
array, но она предназначена только для числовых значений. Иногда это может оказаться удобным для обработки необработанных двоичных данных.Теперь добавьте еще один тестовый пример для вставки пар ключ-значение в вашу хэш-таблицу, используя знакомый синтаксис квадратных скобок:
# test_hashtable.py # ... def test_should_insert_key_value_pairs(): hash_table = HashTable(capacity=100) hash_table["hola"] = "hello" hash_table[98.6] = 37 hash_table[False] = True assert "hello" in hash_table.values assert 37 in hash_table.values assert True in hash_table.valuesСначала вы создаете хэш-таблицу с сотней пустых ячеек, а затем заполняете ее тремя парами ключей и значений различных типов, включая строки, числа с плавающей запятой и логические значения. Наконец, вы утверждаете, что хэш-таблица содержит ожидаемые значения в любом порядке. Обратите внимание, что ваша хэш-таблица запоминает только значения , но не связанные с ними ключи на данный момент!
Наиболее простая и, возможно, немного наивная реализация, которая удовлетворяла бы этому тесту, выглядит следующим образом:
# hashtable.py class HashTable: def __init__(self, capacity): self.values = capacity * [None] def __len__(self): return len(self.values) def __setitem__(self, key, value): self.values.append(value)Он полностью игнорирует ключ и просто добавляет значение в правый конец списка, увеличивая его длину. Вы можете сразу же подумать о другом тестовом примере. Вставка элементов в хэш-таблицу не должна увеличивать ее размер. Аналогично, удаление элемента не должно приводить к уменьшению хэш-таблицы, но вы только принимаете это к сведению, потому что пока нет возможности удалять пары ключ-значение.
Примечание: Вы также можете написать тест-заполнитель и попросить pytest безоговорочно пропустить его до следующего раза:
import pytest @pytest.mark.skip def test_should_not_shrink_when_removing_elements(): passВ нем используется один из декораторов, предоставляемых pytest.
В реальном мире вы бы захотели создать отдельные тестовые случаи с описательными названиями, предназначенные для тестирования такого поведения. Однако, поскольку это всего лишь учебное пособие, для краткости вы собираетесь добавить новое утверждение к существующей функции:
# test_hashtable.py # ... def test_should_insert_key_value_pairs(): hash_table = HashTable(capacity=100) hash_table["hola"] = "hello" hash_table[98.6] = 37 hash_table[False] = True assert "hello" in hash_table.values assert 37 in hash_table.values assert True in hash_table.values assert len(hash_table) == 100Сейчас вы находитесь в красной фазе, поэтому перепишите свой специальный метод, чтобы всегда сохранять емкость постоянной:
# hashtable.py class HashTable: def __init__(self, capacity): self.values = capacity * [None] def __len__(self): return len(self.values) def __setitem__(self, key, value): index = hash(key) % len(self) self.values[index] = valueВы преобразуете произвольный ключ в числовое хэш-значение и используете оператор modulo для ограничения результирующего индекса в пределах доступного адресного пространства. Отлично! Ваш отчет о тестировании снова загорается зеленым.
Примечание: Приведенный выше код основан на встроенной функции Python
hash(), которая, как вы уже узнали, содержит элемент рандомизации. Таким образом, ваш тест может завершиться неудачей в редких случаях, когда два ключа случайно выдают идентичный хэш-код. Поскольку позже вы столкнетесь с коллизиями хэш-кода, вы можете отключить рандомизацию хэша или использовать предсказуемое начальное значение при запуске pytest:(venv) C:\> set PYTHONHASHSEED=128 (venv) C:\> python -m pytest(venv) $ PYTHONHASHSEED=128 pytestУбедитесь, что вы выбрали начальное значение хэша, которое не вызовет никаких коллизий в ваших образцах данных. Поиск такого значения может потребовать проб и ошибок. В моем случае значение
128, казалось, работало нормально.Но, может быть, вы можете придумать какие-нибудь крайние случаи? Как насчет того, чтобы вставить
Noneв вашу хэш-таблицу? Это привело бы к конфликту между допустимым значением и указанным контрольным значением, которое вы выбрали для указания пробелов в вашей хэш-таблице. Этого следует избегать.Как всегда, начните с написания тестового примера, чтобы выразить желаемое поведение:
# test_hashtable.py # ... def test_should_not_contain_none_value_when_created(): assert None not in HashTable(capacity=100).valuesОдним из способов обойти это было бы заменить
Noneв вашем методе.__init__()другим уникальным значением, которое пользователи вряд ли будут вставлять. Например, вы могли бы определить специальную константу, создав совершенно новый объект для представления пробелов в вашей хэш-таблице:# hashtable.py BLANK = object() class HashTable: def __init__(self, capacity): self.values = capacity * [BLANK] # ...Вам нужен только один пустой экземпляр, чтобы пометить слоты как пустые. Естественно, вам потребуется обновить старый тестовый пример, чтобы вернуться к зеленой фазе:
# test_hashtable.py from hashtable import HashTable, BLANK # ... def test_should_create_empty_value_slots(): assert HashTable(capacity=3).values == [BLANK, BLANK, BLANK] # ...Затем напишите положительный тестовый пример, использующий счастливый путь для обработки вставки значения
None:def test_should_insert_none_value(): hash_table = HashTable(capacity=100) hash_table["key"] = None assert None in hash_table.valuesВы создаете пустую хэш-таблицу с сотней ячеек и вставляете
None, связанный с некоторым произвольным ключом. Это должно сработать как по маслу, если вы внимательно следовали инструкциям до сих пор. Если нет, то ознакомьтесь с сообщениями об ошибках, поскольку они часто содержат подсказки о том, что пошло не так. В качестве альтернативы, ознакомьтесь с примером кода, доступным для скачивания по этой ссылке:Исходный код: Нажмите здесь, чтобы загрузить исходный код, который вы будете использовать для создания хэш-таблицы на Python.
В следующем подразделе вы добавите возможность извлекать значения по связанным с ними ключам.
Найдите значение по ключу
Чтобы извлечь значение из хэш-таблицы, вам потребуется использовать тот же синтаксис квадратных скобок, что и раньше, только без использования оператора присваивания. Вам также понадобится образец хэш-таблицы. Чтобы избежать дублирования одного и того же установочного кода в отдельных тестовых примерах в вашем наборе тестов, вы можете поместить его в тестовый набор, предоставляемый pytest:
# test_hashtable.py import pytest # ... @pytest.fixture def hash_table(): sample_data = HashTable(capacity=100) sample_data["hola"] = "hello" sample_data[98.6] = 37 sample_data[False] = True return sample_data def test_should_find_value_by_key(hash_table): assert hash_table["hola"] == "hello" assert hash_table[98.6] == 37 assert hash_table[False] is TrueТестовое приспособление - это функция, аннотируемая с помощью
@pytest.fixtureдекоратора. Он возвращает примеры данных для ваших тестовых примеров, таких как хэш-таблица, заполненная известными ключами и значениями. Ваш pytest автоматически вызовет эту функцию для вас и введет ее результат в любую тестовую функцию, которая объявляет аргумент с тем же именем, что и ваш fixture. В этом случае тестовая функция ожидаетhash_tableаргумент, который соответствует имени вашего устройства.Чтобы иметь возможность находить значения по ключу, вы можете реализовать поиск элемента с помощью другого специального метода, называемого
.__getitem__()в вашем классеHashTable:# hashtable.py BLANK = object() class HashTable: def __init__(self, capacity): self.values = capacity * [BLANK] def __len__(self): return len(self.values) def __setitem__(self, key, value): index = hash(key) % len(self) self.values[index] = value def __getitem__(self, key): index = hash(key) % len(self) return self.values[index]Вы вычисляете индекс элемента на основе хэш-кода предоставленного ключа и возвращаете все, что находится под этим индексом. Но как насчет отсутствующих ключей? На данный момент вы можете возвращать пустой экземпляр, если данный ключ ранее не использовался, что не так уж и полезно. Чтобы воспроизвести то, как Python
dictработал бы в таком случае, вы должны создать исключениеKeyErrorвместо этого:# test_hashtable.py # ... def test_should_raise_error_on_missing_key(): hash_table = HashTable(capacity=100) with pytest.raises(KeyError) as exception_info: hash_table["missing_key"] assert exception_info.value.args[0] == "missing_key"Вы создаете пустую хэш-таблицу и пытаетесь получить доступ к одному из ее значений с помощью отсутствующего ключа. Платформа pytest включает специальную конструкцию для тестирования исключений. Как указано выше, вы используете
pytest.raisesдиспетчер контекста, чтобы ожидать определенного типа исключения в следующем блоке кода. Обработка этого случая заключается в добавлении условного оператора к вашему методу доступа:# hashtable.py # ... class HashTable: # ... def __getitem__(self, key): index = hash(key) % len(self) value = self.values[index] if value is BLANK: raise KeyError(key) return valueЕсли значение по данному индексу пустое, то вы создаете исключение. Кстати, вы используете оператор
isвместо оператора проверки на равенство (==), чтобы убедиться, что вы сравниваете идентификаторы , а не значения. Хотя реализация проверки на равенство в пользовательских классах по умолчанию сводится к сравнению идентификаторов их экземпляров, большинство встроенных типов данных различают эти два оператора и реализуют их по-разному.Поскольку теперь вы можете определить, имеет ли данный ключ соответствующее значение в вашей хэш-таблице, вы можете также реализовать оператор
inдля имитации словаря Python. Не забудьте написать и описать эти тестовые примеры по отдельности, чтобы соблюсти принципы разработки на основе тестирования:# test_hashtable.py # ... def test_should_find_key(hash_table): assert "hola" in hash_table def test_should_not_find_key(hash_table): assert "missing_key" not in hash_tableВ обоих тестовых примерах используются преимущества тестового набора, который вы подготовили ранее, и проверяется
.__contains__()специальный метод, который вы можете реализовать следующим образом:# hashtable.py # ... class HashTable: # ... def __contains__(self, key): try: self[key] except KeyError: return False else: return TrueКогда при обращении к данному ключу возникает
KeyError, вы перехватываете это исключение и возвращаетеFalse, чтобы указать на отсутствующий ключ. В противном случае вы объединяетеtry...exceptblock с предложениемelseи возвращаетеTrue. Обработка исключений великолепна, но иногда это может быть неудобно, поэтомуdict.get()позволяет указать необязательное значение по умолчанию. Вы можете повторить то же самое в своей пользовательской хэш-таблице:# test_hashtable.py # ... def test_should_get_value(hash_table): assert hash_table.get("hola") == "hello" def test_should_get_none_when_missing_key(hash_table): assert hash_table.get("missing_key") is None def test_should_get_default_value_when_missing_key(hash_table): assert hash_table.get("missing_key", "default") == "default" def test_should_get_value_with_default(hash_table): assert hash_table.get("hola", "default") == "hello"Код
.get()выглядит аналогично специальному методу, который вы только что реализовали:# hashtable.py # ... class HashTable: # ... def get(self, key, default=None): try: return self[key] except KeyError: return defaultВы пытаетесь вернуть значение, соответствующее предоставленному ключу. В случае исключения вы возвращаете значение по умолчанию, которое является необязательным аргументом. Когда пользователь оставляет его неопределенным, то он равен
None.Для полноты картины в следующем подразделе вы добавите возможность удаления пары ключ-значение из вашей хэш-таблицы.
Удалить пару Ключ-значение
Словари Python позволяют удалять ранее вставленные пары ключ-значение с помощью встроенного ключевого слова
del, которое удаляет информацию как о ключе, так и о значении. Вот как это могло бы работать с вашей хэш-таблицей:# test_hashtable.py # ... def test_should_delete_key_value_pair(hash_table): assert "hola" in hash_table assert "hello" in hash_table.values del hash_table["hola"] assert "hola" not in hash_table assert "hello" not in hash_table.valuesСначала вы проверяете, есть ли в образце хэш-таблицы нужные ключ и значение. Затем вы удаляете оба, указывая только ключ, и повторяете утверждения, но с перевернутыми ожиданиями. Вы можете выполнить этот тест следующим образом:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): index = hash(key) % len(self) del self.values[index]Вы вычисляете индекс, связанный с ключом, и безоговорочно удаляете соответствующее значение из списка. Однако вы сразу же вспоминаете свое предыдущее мысленное замечание о том, что ваша хэш-таблица не должна уменьшаться при удалении из нее элементов. Итак, вы добавляете еще два утверждения:
# test_hashtable.py # ... def test_should_delete_key_value_pair(hash_table): assert "hola" in hash_table assert "hello" in hash_table.values assert len(hash_table) == 100 del hash_table["hola"] assert "hola" not in hash_table assert "hello" not in hash_table.values assert len(hash_table) == 100Это гарантирует, что размер базового списка вашей хэш-таблицы не изменится. Теперь вам нужно обновить свой код, чтобы он помечал ячейку как пустую, а не выбрасывал ее полностью:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): index = hash(key) % len(self) self.values[index] = BLANKУчитывая, что вы снова вступаете в новую фазу, вы можете воспользоваться этой возможностью и потратить некоторое время на рефакторинг. Одна и та же формула индекса появляется три раза в разных местах. Вы можете извлечь ее и упростить код:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): self.values[self._index(key)] = BLANK def __setitem__(self, key, value): self.values[self._index(key)] = value def __getitem__(self, key): value = self.values[self._index(key)] if value is BLANK: raise KeyError(key) return value # ... def _index(self, key): return hash(key) % len(self)Внезапно, после применения всего лишь этого небольшого изменения, возникает закономерность. Удаление элемента эквивалентно вставке пустого объекта. Итак, вы можете переписать процедуру удаления, чтобы воспользоваться преимуществами метода mutator:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): self[key] = BLANK # ...Присвоение значения с помощью синтаксиса квадратных скобок делегирует методу
.__setitem__(). Ладно, на данный момент достаточно рефакторинга. На данном этапе гораздо важнее подумать о других тестовых примерах. Например, что происходит, когда вы запрашиваете удаление отсутствующего ключа? В Pythondictв этом случае возникает исключениеKeyError, поэтому вы можете сделать то же самое:# hashtable.py # ... def test_should_raise_key_error_when_deleting(hash_table): with pytest.raises(KeyError) as exception_info: del hash_table["missing_key"] assert exception_info.value.args[0] == "missing_key"Выполнить этот тестовый пример относительно просто, поскольку вы можете положиться на код, который вы написали при реализации оператора
in:# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): if key in self: self[key] = BLANK else: raise KeyError(key) # ...Если вы найдете ключ в своей хэш-таблице, вы замените связанное с ним значение контрольным значением, чтобы удалить эту пару. В противном случае вы создадите исключение. Итак, осталось рассмотреть еще одну базовую операцию с хэш-таблицей, которую вы будете выполнять далее.
Обновить значение существующей пары
Метод insertion уже должен позаботиться об обновлении пары ключ-значение, поэтому вам нужно только добавить соответствующий тестовый пример и проверить, работает ли он должным образом:
# test_hashtable.py # ... def test_should_update_value(hash_table): assert hash_table["hola"] == "hello" hash_table["hola"] = "hallo" assert hash_table["hola"] == "hallo" assert hash_table[98.6] == 37 assert hash_table[False] is True assert len(hash_table) == 100После изменения значения hello существующего ключа и изменения его на hallo вы также проверяете, есть ли другое значение ключа пары, а также длина хэш-таблицы остаются неизменными. Это оно. У вас уже есть базовая реализация хэш-таблицы, но несколько дополнительных функций, которые относительно дешевы в реализации, все еще отсутствуют.
Получаем пары Ключ-значение
Пришло время обратиться к слону в комнате. Словари Python позволяют выполнять итерацию по их ключам , значениям или парам ключ-значение, называемым элементами. Однако ваша хэш-таблица на самом деле представляет собой всего лишь список значений с причудливой индексацией поверх него. Если вы когда-нибудь захотите восстановить исходные ключи, помещенные в вашу хэш-таблицу, то вам не повезет, потому что текущая реализация хэш-таблицы никогда их не запомнит.
В этом подразделе вы проведете масштабный рефакторинг вашей хэш-таблицы, чтобы добавить возможность сохранения ключей и значений. Имейте в виду, что потребуется выполнить несколько шагов, и в результате многие тесты начнут завершаться неудачно. Если вы хотите пропустить эти промежуточные шаги и увидеть эффект, то переходите к защитному копированию.
Подождите минутку. Вы продолжаете читать о парах ключ-значение в этом руководстве, так почему бы не заменить значения кортежами? В конце концов, кортежи в Python понятны. Еще лучше, если вы могли бы использовать именованные кортежи, чтобы воспользоваться поиском именованных элементов в них. Но сначала вам нужно придумать тест.
Примечание: При разработке тестового примера не забудьте сосредоточиться на высокоуровневой функциональности, ориентированной на пользователя. Не пытайтесь тестировать фрагмент кода, который вы можете предвидеть, основываясь на своем опыте программиста или на интуиции. Именно тесты должны в конечном итоге определять вашу реализацию в TDD, а не наоборот.
Прежде всего, вам понадобится еще один атрибут в вашем классе
HashTableдля хранения пар ключ-значение:# test_hashtable.py # ... def test_should_return_pairs(hash_table): assert ("hola", "hello") in hash_table.pairs assert (98.6, 37) in hash_table.pairs assert (False, True) in hash_table.pairsПорядок пар ключ-значение на данном этапе не имеет значения, поэтому вы можете предположить, что они могут отображаться в любом порядке каждый раз, когда вы их запрашиваете. Однако вместо того, чтобы вводить в класс еще одно поле, вы могли бы повторно использовать
.values, переименовав его в.pairsи внеся другие необходимые изменения. Есть несколько вариантов. Просто имейте в виду, что это временно приведет к сбою некоторых тестов, пока вы не исправите реализацию.Примечание: Если вы используете редактор кода, то вы можете удобно переименовать переменную или элемент класса одним нажатием кнопки, используя возможности рефакторинга. В PyCharm, например, вы можете щелкнуть правой кнопкой мыши по переменной, выбрать Рефакторинг из контекстного меню, а затем Переименовать.... Или вы можете использовать соответствующее сочетание клавиш:
Рефакторинг переименования в PyCharmЭто самый простой и надежный способ изменить имя переменной в вашем проекте. Редактор кода обновит все ссылки на переменные в файлах вашего проекта.
Когда вы переименуете
.valuesв.pairsвhashtable.pyиtest_hashtable.py, вам также потребуется обновить специальный метод.__setitem__(). В частности, теперь он должен хранить кортежи ключа и связанного с ним значения:# hashtable.py # ... class HashTable: # ... def __setitem__(self, key, value): self.pairs[self._index(key)] = (key, value)Вставка элемента в вашу хэш-таблицу преобразует ключ и значение в кортеж, а затем помещает этот кортеж с нужным индексом в ваш список пар. Обратите внимание, что изначально ваш список будет содержать только пустые объекты, а не кортежи, поэтому в вашем списке пар вы будете использовать два разных типа данных. Один из них - кортеж, в то время как другой может быть любым, кроме кортежа, для обозначения пустого места.
Из-за этого вам больше не нужна какая-либо специальная контрольная константа, чтобы пометить слот как пустой. Вы можете безопасно удалить свою константу
BLANKи при необходимости заменить ее простой константойNone, так что продолжайте и сделайте это прямо сейчас.Примечание: С удалением кода поначалу может быть трудно смириться, но чем меньше, тем лучше! Как вы можете видеть, разработка на основе тестирования иногда может заставить вас ходить по кругу.
Вы можете сделать еще один шаг назад, чтобы восстановить контроль над удалением элемента:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): if key in self: self.pairs[self._index(key)] = None else: raise KeyError(key)К сожалению, ваш метод
.__delitem__()больше не может использовать синтаксис квадратных скобок, поскольку это привело бы к переносу любого значения sentinel, которое вы выбрали, в ненужный кортеж. Здесь вы должны использовать явный оператор присваивания, чтобы избежать излишне сложной логики в будущем.Последним важным элементом головоломки является обновление метода
.__getitem__():# hashtable.py # ... class HashTable: # ... def __getitem__(self, key): pair = self.pairs[self._index(key)] if pair is None: raise KeyError(key) return pair[1]Вы просматриваете индекс, ожидая найти пару ключ-значение. Если вы вообще ничего не получаете, вы создаете исключение. С другой стороны, если вы видите что-то интересное, вы берете второй элемент кортежа с индексом один, который соответствует отображаемому значению. Однако вы можете записать это более элегантно, используя именованный кортеж, как предлагалось ранее:
# hashtable.py from typing import NamedTuple, Any class Pair(NamedTuple): key: Any value: Any class HashTable: # ... def __setitem__(self, key, value): self.pairs[self._index(key)] = Pair(key, value) def __getitem__(self, key): pair = self.pairs[self._index(key)] if pair is None: raise KeyError(key) return pair.value # ...Класс
Pairсостоит из атрибутов.keyи.value, которые могут принимать значения любого типа данных. Одновременно ваш класс наследует все свойства обычного кортежа, поскольку он расширяет родительскийNamedTuple. Обратите внимание, что вы должны явно вызватьPair()для вашего ключа и значения в методе.__setitem__(), чтобы воспользоваться доступом к именованному атрибуту в.__getitem__().Примечание: Несмотря на использование пользовательского типа данных для представления пар ключ-значение, вы можете написать свои тесты так, чтобы они содержали либо экземпляры
Pair, либо обычные кортежи, благодаря совместимости обоих типов.Естественно, на данный момент вам необходимо обновить несколько тестовых примеров, прежде чем отчет снова станет зеленым. Не торопитесь и внимательно просмотрите свой набор тестов. В качестве альтернативы, если вы чувствуете, что застряли, ознакомьтесь с кодом из вспомогательных материалов или загляните сюда:
# test_hashtable.py # ... def test_should_insert_key_value_pairs(): hash_table = HashTable(capacity=100) hash_table["hola"] = "hello" hash_table[98.6] = 37 hash_table[False] = True assert ("hola", "hello") in hash_table.pairs assert (98.6, 37) in hash_table.pairs assert (False, True) in hash_table.pairs assert len(hash_table) == 100 # ... def test_should_delete_key_value_pair(hash_table): assert "hola" in hash_table assert ("hola", "hello") in hash_table.pairs assert len(hash_table) == 100 del hash_table["hola"] assert "hola" not in hash_table assert ("hola", "hello") not in hash_table.pairs assert len(hash_table) == 100Будет еще один тестовый пример, который требует особого внимания. В частности, речь идет о проверке того, что в пустой хэш-таблице при создании не было значений
None. Вы только что заменили список значений списком пар. Чтобы снова найти значения, вы можете использовать список для понимания, например, такой:# test_hashtable.py # ... def test_should_not_contain_none_value_when_created(): hash_table = HashTable(capacity=100) values = [pair.value for pair in hash_table.pairs if pair] assert None not in valuesЕсли вы беспокоитесь о том, что в тестовом примере будет слишком много логики, то вы будете абсолютно правы. В конце концов, вы хотите протестировать поведение хэш-таблицы. Но пока не беспокойтесь об этом. Вскоре вы вернетесь к этому тестовому примеру.
Использовать защитное копирование
Как только вы вернетесь к "зеленой" фазе, попробуйте разобраться с возможными угловыми вариантами. Например,
.pairsотображается как общедоступный атрибут, который любой может намеренно или непреднамеренно изменить. На практике методы доступа никогда не должны допускать утечки информации из вашей внутренней реализации, но должны создавать защитные копии для защиты изменяемых атрибутов от внешних изменений:# test_hashtable.py # ... def test_should_return_copy_of_pairs(hash_table): assert hash_table.pairs is not hash_table.pairsВсякий раз, когда вы запрашиваете пары ключ-значение из хэш-таблицы, вы ожидаете получить совершенно новый объект с уникальным идентификатором. Вы можете скрыть приватное поле за свойством Python, поэтому создайте его и замените все ссылки на
.pairsна._pairsтолько в вашемHashTableклассе. Начальное подчеркивание - это стандартное соглашение об именовании в Python, которое указывает на внутреннюю реализацию:# hashtable.py # ... class HashTable: def __init__(self, capacity): self._pairs = capacity * [None] def __len__(self): return len(self._pairs) def __delitem__(self, key): if key in self: self._pairs[self._index(key)] = None else: raise KeyError(key) def __setitem__(self, key, value): self._pairs[self._index(key)] = Pair(key, value) def __getitem__(self, key): pair = self._pairs[self._index(key)] if pair is None: raise KeyError(key) return pair.value def __contains__(self, key): try: self[key] except KeyError: return False else: return True def get(self, key, default=None): try: return self[key] except KeyError: return default @property def pairs(self): return self._pairs.copy() def _index(self, key): return hash(key) % len(self)Когда вы запрашиваете список пар ключ-значение, хранящихся в вашей хэш-таблице, вы каждый раз получаете их неполную копию. Поскольку у вас не будет ссылки на внутреннее состояние вашей хэш-таблицы, возможные изменения в ее копии не повлияют на нее.
Примечание: Порядок следования методов класса, к которому вы пришли, может немного отличаться от приведенного в блоке кода, представленном выше. Это нормально, потому что порядок следования методов не имеет значения с точки зрения Python. Однако обычно начинается с статических методов или методов класса, за которыми следует открытый интерфейс вашего класса, на который вы, скорее всего, обратите внимание. Внутренняя реализация, как правило, должна появляться в самом конце.
Чтобы избежать путаницы в коде, рекомендуется организовать методы таким образом, чтобы они напоминали историю. В частности, перед вызываемыми низкоуровневыми функциями следует указывать функции более высокого уровня.
Чтобы еще больше имитировать
dict.items()в вашем свойстве, результирующий список пар не должен содержать пустых ячеек. Другими словами, в этом списке не должно быть никаких значенийNone:# test_hashtable.py # ... def test_should_not_include_blank_pairs(hash_table): assert None not in hash_table.pairsЧтобы выполнить этот тест, вы можете отфильтровать пустые значения, добавив условие для понимания списка в вашем свойстве:
# hashtable.py # ... class HashTable: # ... @property def pairs(self): return [pair for pair in self._pairs if pair]Вам не нужен явный вызов
.copy(), потому что понимание списка создает новый список. Для каждой пары в исходном списке пар ключ-значение вы проверяете, соответствует ли эта конкретная пара действительности, и сохраняете ее в результирующем списке. Однако это приведет к нарушению двух других тестов, которые вам необходимо обновить сейчас:# test_hashtable.py # ... def test_should_create_empty_value_slots(): assert HashTable(capacity=3)._pairs == [None, None, None] # ... def test_should_insert_none_value(): hash_table = HashTable(100) hash_table["key"] = None assert ("key", None) in hash_table.pairsЭто не идеально, потому что один из ваших тестов нацелен на внутреннюю реализацию, а не на общедоступные интерфейсы. Тем не менее, такое тестирование известно как тестирование в режиме "белого ящика", которое имеет свое место.
Получить ключи и значения
Помните тестовый пример, который вы изменили, добавив понимание списка для извлечения значений из ваших пар ключ-значение? Ну, вот он снова, если вам нужно освежить память:
# test_hashtable.py # ... def test_should_not_contain_none_value_when_created(): hash_table = HashTable(capacity=100) values = [pair.value for pair in hash_table.pairs if pair] assert None not in valuesВыделенная строка выглядит точно так же, как вам нужно для реализации свойства
.values, которое вы ранее заменили на.pairs. Вы можете обновить тестовую функцию, чтобы снова воспользоваться преимуществами.values:# test_hashtable.py # ... def test_should_not_contain_none_value_when_created(): assert None not in HashTable(capacity=100).valuesМожет показаться, что это напрасные усилия. Но теперь эти значения вычисляются динамически с помощью свойства getter, тогда как раньше они хранились в списке фиксированного размера. Чтобы выполнить этот тест, вы можете повторно использовать часть его старой реализации, которая использует понимание списка:
# hashtable.py # ... class HashTable: # ... @property def values(self): return [pair.value for pair in self.pairs]Обратите внимание, что вам больше не нужно указывать здесь необязательное условие фильтрации, потому что оно уже есть за свойством
.pairs.Пуристы могли бы подумать об использовании понимания набора вместо понимания списка, чтобы сообщить об отсутствии гарантий для порядка значений. Однако это привело бы к потере информации о повторяющихся значениях в хэш-таблице. Заранее защитите себя от такой возможности, написав другой тестовый пример:
# test_hashtable.py # ... def test_should_return_duplicate_values(): hash_table = HashTable(capacity=100) hash_table["Alice"] = 24 hash_table["Bob"] = 42 hash_table["Joe"] = 42 assert [24, 42, 42] == sorted(hash_table.values)Если у вас есть хэш-таблица с именами и возрастом, например, и у нескольких человек одинаковый возраст, то в
.valuesследует сохранить все повторяющиеся значения возраста. Вы можете отсортировать возрасты, чтобы обеспечить повторяемость тестовых запусков. Хотя этот тестовый пример не требует написания нового кода, он защитит от регрессий .Стоит проверить ожидаемые значения, их типы и количество. Однако вы не можете сравнивать два списка напрямую, поскольку фактические значения в хэш-таблице могут отображаться в непредсказуемом порядке. Чтобы не нарушать порядок в вашем тесте, вы могли бы преобразовать оба списка в наборы или отсортировать их, как и раньше. К сожалению, наборы удаляют потенциальные дубликаты, в то время как сортировка невозможна, если списки содержат несовместимые типы.
Чтобы надежно проверить, содержат ли два списка абсолютно одинаковые элементы произвольных типов с потенциальными дубликатами, игнорируя их порядок, вы можете использовать следующую идиому Python:
def have_same_elements(list1, list2): return all(element in list1 for element in list2)В нем используется встроенная функция
all(), но она довольно подробная. Вероятно, вам лучше использовать плагинpytest-unordered. Не забудьте сначала установить его в свою виртуальную среду:(venv) C:\> python -m pip install pytest-unordered(venv) $ python -m pip install pytest-unorderedЗатем импортируйте функцию
unordered()в свой набор тестов и используйте ее для переноса значений хэш-таблицы:# test_hashtable.py import pytest from pytest_unordered import unordered from hashtable import HashTable # ... def test_should_get_values(hash_table): assert unordered(hash_table.values) == ["hello", 37, True]При этом значения преобразуются в неупорядоченный список, который переопределяет оператор проверки равенства таким образом, чтобы он не учитывал порядок при сравнении элементов списка. Кроме того, значения пустой хэш-таблицы должны быть пустым списком, в то время как свойство
.valuesвсегда должно возвращать новую копию списка:# test_hashtable.py # ... def test_should_get_values_of_empty_hash_table(): assert HashTable(capacity=100).values == [] def test_should_return_copy_of_values(hash_table): assert hash_table.values is not hash_table.valuesС другой стороны, ключи хэш-таблицы должны быть уникальными, поэтому имеет смысл подчеркнуть это, возвращая набор, а не список ключей. В конце концов, наборы по определению представляют собой неупорядоченные коллекции элементов без дубликатов:
# test_hashtable.py # ... def test_should_get_keys(hash_table): assert hash_table.keys == {"hola", 98.6, False} def test_should_get_keys_of_empty_hash_table(): assert HashTable(capacity=100).keys == set() def test_should_return_copy_of_keys(hash_table): assert hash_table.keys is not hash_table.keysВ Python нет пустого литерала set, поэтому в этом случае вам придется напрямую вызывать встроенную функцию
set(). Реализация соответствующей функции getter будет выглядеть знакомо:# hashtable.py # ... class HashTable: # ... @property def keys(self): return {pair.key for pair in self.pairs}Это похоже на свойство
.values. Разница в том, что вы используете фигурные скобки вместо квадратных и ссылаетесь на атрибут.keyвместо.valueв вашем именованном кортеже. В качестве альтернативы вы могли бы использоватьpair[0], если бы захотели, но это было бы менее читабельно.Это также напоминает вам о необходимости аналогичного тестового примера, который вы пропустили при рассмотрении атрибута
.pairs. Имеет смысл вернуть набор пар для обеспечения согласованности:# test_hashtable.py # ... def test_should_return_pairs(hash_table): assert hash_table.pairs == { ("hola", "hello"), (98.6, 37), (False, True) } def test_should_get_pairs_of_empty_hash_table(): assert HashTable(capacity=100).pairs == set()Таким образом, свойство
.pairsотныне также будет использовать заданное значение:# hashtable.py # ... class HashTable: # ... @property def pairs(self): return {pair for pair in self._pairs if pair}Вам не нужно беспокоиться о потере какой-либо информации, потому что каждая пара ключ-значение уникальна. На этом этапе вы снова должны перейти в зеленую фазу.
Обратите внимание, что вы можете воспользоваться свойством
.pairsдля преобразования вашей хэш-таблицы в обычный старый словарь и использовать.keysи.valuesдля проверки этого:def test_should_convert_to_dict(hash_table): dictionary = dict(hash_table.pairs) assert set(dictionary.keys()) == hash_table.keys assert set(dictionary.items()) == hash_table.pairs assert list(dictionary.values()) == unordered(hash_table.values)Чтобы не обращать внимания на порядок элементов, не забудьте обернуть ключи словаря и пары ключ-значение наборами перед выполнением сравнения. Напротив, значения вашей хэш-таблицы отображаются в виде списка, поэтому обязательно используйте функцию
unordered()для сравнения списков, игнорируя порядок элементов.Итак, теперь ваша хэш-таблица действительно начинает обретать форму!
Укажите длину хэш-таблицы
Есть одна небольшая деталь, которую вы намеренно оставили неработающей для простоты. Это длина вашей хэш-таблицы, которая в настоящее время показывает максимальную емкость, даже если в ней есть только пустые ячейки. К счастью, для исправления этого не требуется много усилий. Найдите свою функцию с именем
test_should_report_capacity(), переименуйте, как показано ниже, и проверьте, равна ли длина пустой хэш-таблицы нулю, а не ста:# test_hashtable.py # ... def test_should_report_length_of_empty_hash_table(): assert len(HashTable(capacity=100)) == 0Чтобы сделать емкость независимой от длины, измените свой специальный метод
.__len__()так, чтобы он ссылался на общедоступное свойство с отфильтрованными парами вместо частного списка всех слотов:# hashtable.py # ... class HashTable: # ... def __len__(self): return len(self.pairs) # ...Вы только что убрали начальное подчеркивание из имени переменной. Но это небольшое изменение теперь приводит к внезапному завершению целого ряда тестов с ошибкой, а некоторые из них завершаются неудачей.
Примечание: Неудачные тесты менее серьезны, поскольку их утверждения оцениваются как
False, в то время как ошибки указывают на совершенно неожиданное поведение в вашем коде.Похоже, что большинство тестовых примеров страдают от одного и того же необработанного исключения из-за деления на ноль при сопоставлении ключа с индексом. Это имеет смысл, потому что
._index()использует длину хэш-таблицы, чтобы найти остаток от деления хэшированного ключа на количество доступных ячеек. Однако теперь длина хэш-таблицы имеет другое значение. Вместо этого вам нужно использовать длину внутреннего списка:# hashtable.py class HashTable: # ... def _index(self, key): return hash(key) % len(self._pairs)Теперь это намного лучше. В трех тестовых примерах, которые по-прежнему не выполняются, используются неверные предположения о длине хэш-таблицы. Измените эти предположения, чтобы тесты прошли успешно:
# test_hashtable.py # ... def test_should_insert_key_value_pairs(): hash_table = HashTable(capacity=100) hash_table["hola"] = "hello" hash_table[98.6] = 37 hash_table[False] = True assert ("hola", "hello") in hash_table.pairs assert (98.6, 37) in hash_table.pairs assert (False, True) in hash_table.pairs assert len(hash_table) == 3 # ... def test_should_delete_key_value_pair(hash_table): assert "hola" in hash_table assert ("hola", "hello") in hash_table.pairs assert len(hash_table) == 3 del hash_table["hola"] assert "hola" not in hash_table assert ("hola", "hello") not in hash_table.pairs assert len(hash_table) == 2 # ... def test_should_update_value(hash_table): assert hash_table["hola"] == "hello" hash_table["hola"] = "hallo" assert hash_table["hola"] == "hallo" assert hash_table[98.6] == 37 assert hash_table[False] is True assert len(hash_table) == 3Вы вернулись в игру, но
ZeroDivisionErrorбыл красным флажком, который должен был немедленно вызвать у вас желание добавить дополнительные тестовые примеры:# test_hashtable.py # ... def test_should_not_create_hashtable_with_zero_capacity(): with pytest.raises(ValueError): HashTable(capacity=0) def test_should_not_create_hashtable_with_negative_capacity(): with pytest.raises(ValueError): HashTable(capacity=-100)Создание
HashTableс неположительной емкостью не имеет особого смысла. Как у вас может быть контейнер с отрицательной длиной? Поэтому вам следует создать исключение, если кто-то попытается это сделать, намеренно или случайно. Стандартный способ указать на такие некорректные входные аргументы в Python - это создать исключениеValueError:# hashtable.py # ... class HashTable: def __init__(self, capacity): if capacity < 1: raise ValueError("Capacity must be a positive number") self._pairs = capacity * [None] # ...Если вы прилежны, то вам, вероятно, следует также проверить наличие недопустимых типов аргументов, но это выходит за рамки данного руководства. Вы можете рассматривать это как добровольное упражнение.
Затем добавьте другой сценарий для тестирования длины непустой хэш-таблицы, предоставленной в качестве фиксированного значения pytest:
# test_hashtable.py # ... def test_should_report_length(hash_table): assert len(hash_table) == 3Существует три пары ключ-значение, поэтому длина хэш-таблицы также должна быть равна трем. Для этого теста не требуется никакого дополнительного кода. Наконец, поскольку сейчас вы находитесь на этапе рефакторинга, вы можете добавить немного синтаксического сахара, введя свойство
.capacityи используя его там, где это возможно:# test_hashtable.py # ... def test_should_report_capacity_of_empty_hash_table(): assert HashTable(capacity=100).capacity == 100 def test_should_report_capacity(hash_table): assert hash_table.capacity == 100Емкость является постоянной и определяется во время создания хэш-таблицы. Вы можете получить ее из длины базового списка пар:
# hashtable.py # ... class HashTable: # ... @property def capacity(self): return len(self._pairs) def _index(self, key): return hash(key) % self.capacityПо мере того, как вы вводите новую лексику в свою проблемную область, это помогает вам открывать новые возможности для более точного и недвусмысленного именования. Например, вы видели, что слово пары используется взаимозаменяемо для обозначения как фактических пар ключ-значение, хранящихся в вашей хэш-таблице, так и внутреннего списка ячеек для пар. Возможно, это хорошая возможность провести рефакторинг вашего кода, изменив везде
._pairsна._slots.Затем в одном из ваших предыдущих тестовых примеров будет более четко указано его назначение:
# test_hashtable.py # ... def test_should_create_empty_value_slots(): assert HashTable(capacity=3)._slots == [None, None, None]Возможно, было бы еще разумнее переименовать этот тест, заменив в нем слово значение на пара:
# test_hashtable.py # ... def test_should_create_empty_pair_slots(): assert HashTable(capacity=3)._slots == [None, None, None]Вы можете подумать, что в таких философских размышлениях нет необходимости. Однако, чем более описательными будут ваши имена, тем более читабельным будет ваш код — если не для других, то уж точно для вас в будущем. Есть даже книги и анекдоты об этом. Ваши тесты - это форма документации, поэтому стоит уделять им такое же внимание к деталям, как и тестируемому коду.
Сделайте хэш-таблицу повторяемой
Python позволяет вам выполнять итерацию по словарю с помощью ключей, значений или пар ключ-значение, известных как элементы. Вы хотите, чтобы в вашей пользовательской хэш-таблице было такое же поведение, поэтому для начала набросайте несколько тестовых примеров:
# test_hashtable.py # ... def test_should_iterate_over_keys(hash_table): for key in hash_table.keys: assert key in ("hola", 98.6, False) def test_should_iterate_over_values(hash_table): for value in hash_table.values: assert value in ("hello", 37, True) def test_should_iterate_over_pairs(hash_table): for key, value in hash_table.pairs: assert key in hash_table.keys assert value in hash_table.valuesИтерация по ключам, значениям или парам ключ-значение в текущей реализации работает "из коробки", поскольку базовые наборы и списки уже могут с этим справиться. С другой стороны, чтобы сделать экземпляры вашего
HashTableкласса итерируемыми, вы должны определить другой специальный метод, который позволит вам напрямую взаимодействовать с цикламиfor:# test_hashtable.py # ... def test_should_iterate_over_instance(hash_table): for key in hash_table: assert key in ("hola", 98.6, False)В отличие от предыдущего, здесь вы передаете ссылку на экземпляр
HashTable, но поведение такое же, как если бы вы выполняли итерацию по свойству.keys. Такое поведение совместимо со встроеннымdictв Python.Специальный метод, который вам нужен,
.__iter__(), должен возвращать объект-итератор, который цикл использует внутренне:# hashtable.py # ... class HashTable: # ... def __iter__(self): yield from self.keysЭто пример генераторного итератора, который использует ключевое слово yield в Python.
Примечание: Выражение
yield fromпередает итерацию подгенератору, который может быть другим повторяемым объектом , таким как список или набор.Ключевое слово
yieldпозволяет вам определить итератор на месте, используя функциональный стиль без создания другого класса. Специальный метод с именем.__iter__()вызывается цикломforпри его запуске.Итак, на данный момент в вашей хэш-таблице отсутствуют только несколько несущественных функций.
Представляет хэш-таблицу в текстовом виде
Следующий шаг, который вы собираетесь реализовать в этом разделе, придаст вашей хэш-таблице приятный вид при выводе на стандартный вывод. Текстовое представление вашей хэш-таблицы будет выглядеть аналогично литералу Python
dict:# test_hashtable.py # ... def test_should_use_dict_literal_for_str(hash_table): assert str(hash_table) in { "{'hola': 'hello', 98.6: 37, False: True}", "{'hola': 'hello', False: True, 98.6: 37}", "{98.6: 37, 'hola': 'hello', False: True}", "{98.6: 37, False: True, 'hola': 'hello'}", "{False: True, 'hola': 'hello', 98.6: 37}", "{False: True, 98.6: 37, 'hola': 'hello'}", }В литерале используются фигурные скобки, запятые и двоеточия, в то время как ключи и значения имеют соответствующие представления. Например, строки заключены в одинарные апострофы. Поскольку вы не знаете точного порядка расположения пар ключ-значение, вы проверяете, соответствует ли строковое представление вашей хэш-таблицы одной из возможных перестановок пар.
Чтобы заставить ваш класс работать со встроенной функцией
str(), вы должны реализовать соответствующий специальный метод вHashTable:# hashtable.py # ... class HashTable: # ... def __str__(self): pairs = [] for key, value in self.pairs: pairs.append(f"{key!r}: {value!r}") return "{" + ", ".join(pairs) + "}"Вы перебираете ключи и значения с помощью свойства
.pairsи используете f-строки для форматирования отдельных пар. Обратите внимание на флаг преобразования!rв строке шаблона, который принудительно вызываетrepr()вместо значения по умолчаниюstr()для ключей и значений. Это обеспечивает более четкое представление, которое варьируется в зависимости от типа данных. Например, он заключает строки в одинарные апострофы.Разница между
str()иrepr()более тонкая. В общем, оба они предназначены для преобразования объектов в строки. Однако, хотя вы можете ожидать, чтоstr()вернет понятный пользователю текст,repr()часто возвращает корректный фрагмент кода на Python, который вы можете оценить, чтобы воссоздать исходный объект:>>> from fractions import Fraction >>> quarter = Fraction("1/4") >>> str(quarter) '1/4' >>> repr(quarter) 'Fraction(1, 4)' >>> eval(repr(quarter)) Fraction(1, 4)В этом примере строковое представление дроби Python равно
'1/4', но каноническое строковое представление того же объекта представляет собой вызовFractionкласс.Вы можете добиться аналогичного эффекта в своем классе
HashTable. К сожалению, в данный момент инициализатор вашего класса не позволяет создавать новые экземпляры из значений. Вы решите эту проблему, введя метод класса, который позволит вам создаватьHashTableэкземпляра из словарей Python:# test_hashtable.py # ... def test_should_create_hashtable_from_dict(): dictionary = {"hola": "hello", 98.6: 37, False: True} hash_table = HashTable.from_dict(dictionary) assert hash_table.capacity == len(dictionary) * 10 assert hash_table.keys == set(dictionary.keys()) assert hash_table.pairs == set(dictionary.items()) assert unordered(hash_table.values) == list(dictionary.values())Это хорошо согласуется с вашим предыдущим преобразованием, которое было выполнено в противоположном направлении. Однако вам нужно предположить, что хэш-таблица должна быть достаточно большой, чтобы содержать все пары ключ-значение из исходного словаря. Разумная оценка, по-видимому, в десять раз превышает количество пар. На данный момент вы можете жестко запрограммировать это:
# hashtable.py # ... class HashTable: @classmethod def from_dict(cls, dictionary): hash_table = cls(len(dictionary) * 10) for key, value in dictionary.items(): hash_table[key] = value return hash_tableВы создаете новую хэш-таблицу и устанавливаете ее емкость, используя произвольный коэффициент. Затем вы вставляете пары ключ-значение, копируя их из словаря, переданного методу в качестве аргумента. Вы можете разрешить переопределение емкости по умолчанию, если хотите, поэтому добавьте аналогичный тестовый пример:
# test_hashtable.py # ... def test_should_create_hashtable_from_dict_with_custom_capacity(): dictionary = {"hola": "hello", 98.6: 37, False: True} hash_table = HashTable.from_dict(dictionary, capacity=100) assert hash_table.capacity == 100 assert hash_table.keys == set(dictionary.keys()) assert hash_table.pairs == set(dictionary.items()) assert unordered(hash_table.values) == list(dictionary.values())Чтобы сделать емкость необязательной, вы можете воспользоваться вычислением короткого замыкания логических выражений:
# hashtable.py # ... class HashTable: @classmethod def from_dict(cls, dictionary, capacity=None): hash_table = cls(capacity or len(dictionary) * 10) for key, value in dictionary.items(): hash_table[key] = value return hash_tableЕсли значение
capacityне указано, то вы возвращаетесь к поведению по умолчанию, при котором длина словаря умножается на десять. Благодаря этому вы, наконец, сможете предоставить каноническое строковое представление для ваших экземпляровHashTable:# test_hashtable.py # ... def test_should_have_canonical_string_representation(hash_table): assert repr(hash_table) in { "HashTable.from_dict({'hola': 'hello', 98.6: 37, False: True})", "HashTable.from_dict({'hola': 'hello', False: True, 98.6: 37})", "HashTable.from_dict({98.6: 37, 'hola': 'hello', False: True})", "HashTable.from_dict({98.6: 37, False: True, 'hola': 'hello'})", "HashTable.from_dict({False: True, 'hola': 'hello', 98.6: 37})", "HashTable.from_dict({False: True, 98.6: 37, 'hola': 'hello'})", }Как и прежде, вы проверяете все возможные перестановки порядка атрибутов в результирующем представлении. Каноническое строковое представление хэш-таблицы выглядит в основном так же, как и в случае с
str(), но оно также оборачивает литерал dict в вызов вашего нового метода класса.from_dict(). Соответствующая реализация делегирует специальному методу.__str__()вызов встроенной функцииstr():# hashtable.py # ... class HashTable: # ... def __repr__(self): cls = self.__class__.__name__ return f"{cls}.from_dict({str(self)})"Обратите внимание, что имя класса не задается жестко, чтобы избежать проблем, если вы когда-нибудь решите переименовать свой класс позже.
Ваш прототип хэш-таблицы почти готов, так как вы реализовали почти все основные и несущественные функции из списка, упомянутого во введении к этому разделу. Вы только что добавили возможность создавать хэш-таблицу с помощью Python
dictи предоставили строковые представления для ее экземпляров. Последний и заключительный момент заключается в том, что экземпляры хэш-таблицы можно сравнивать по значению.Проверьте равенство хэш-таблиц
Хэш-таблицы похожи на наборы в том смысле, что они не устанавливают какой-либо определенный порядок для своего содержимого. На самом деле, у хэш-таблиц и наборов больше общего, чем вы могли бы подумать, поскольку они оба поддерживаются хэш-функцией. Именно хэш-функция делает пары ключ-значение в хэш-таблице неупорядоченными. Однако помните, что, начиная с Python 3.6,
dictдействительно сохраняет порядок вставки в качестве детали реализации.Две хэш-таблицы должны сравниваться одинаково тогда и только тогда, когда они имеют одинаковый набор пар ключ-значение. Однако Python по умолчанию сравнивает объекты с идентификаторами, поскольку он не знает, как интерпретировать значения пользовательских типов данных. Таким образом, два экземпляра вашей хэш-таблицы всегда будут сравниваться неравномерно, даже если они используют один и тот же набор пар ключ-значение.
Чтобы исправить это, вы можете реализовать оператор проверки на равенство (
==), предоставив специальный метод.__eq__()в вашем классеHashTable. Кроме того, Python вызовет этот метод для вычисления оператора not equal (!=), если вы также не реализуете.__ne__()явно.Вы хотите, чтобы хэш-таблица была равна самой себе, своей копии или другому экземпляру с одинаковыми парами ключ-значение независимо от их порядка. И наоборот, хэш-таблица должна , а не быть равна экземпляру с другим набором пар ключ-значение или совершенно другим типом данных:
# test_hashtable.py # ... def test_should_compare_equal_to_itself(hash_table): assert hash_table == hash_table def test_should_compare_equal_to_copy(hash_table): assert hash_table is not hash_table.copy() assert hash_table == hash_table.copy() def test_should_compare_equal_different_key_value_order(hash_table): h1 = HashTable.from_dict({"a": 1, "b": 2, "c": 3}) h2 = HashTable.from_dict({"b": 2, "a": 1, "c": 3}) assert h1 == h2 def test_should_compare_unequal(hash_table): other = HashTable.from_dict({"different": "value"}) assert hash_table != other def test_should_compare_unequal_another_data_type(hash_table): assert hash_table != 42Вы используете
.from_dict(), описанный в предыдущем подразделе, для быстрого заполнения новых хэш-таблиц значениями. Вы можете воспользоваться тем же методом класса, чтобы создать новую копию экземпляра хэш-таблицы. Вот код, который удовлетворяет этим тестовым примерам:# hashtable.py # ... class HashTable: # ... def __eq__(self, other): if self is other: return True if type(self) is not type(other): return False return set(self.pairs) == set(other.pairs) # ... def copy(self): return HashTable.from_dict(dict(self.pairs), self.capacity)Специальный метод
.__eq__()принимает некоторый объект для сравнения в качестве аргумента. Если этот объект является текущим экземпляромHashTable, то вы возвращаетеTrue, поскольку один и тот же идентификатор подразумевает равенство значений. В противном случае вы продолжаете сравнивать типы и наборы пар ключ-значение. Преобразование в наборы помогает сделать порядок неактуальным, даже если вы решите превратить.pairsв другой упорядоченный список в будущем.Кстати, результирующая копия должна иметь не только те же пары ключ-значение, но и ту же емкость, что и исходная хэш-таблица. В то же время две хэш-таблицы с разной емкостью все равно должны быть сопоставимы: