Руководство по электронным таблицам Excel на Python с помощью openpyxl
Оглавление
- Прежде чем Вы начнете
- Чтение электронных таблиц Excel с помощью openpyxl
- Создание электронных таблиц Excel с помощью openpyxl
- Заключение
Электронные таблицы Excel - это одна из тех вещей, с которыми вам, возможно, придется столкнуться в какой-то момент. Либо потому, что они нравятся вашему боссу, либо потому, что они нужны маркетингу, вам, возможно, придется научиться работать с электронными таблицами, и вот тогда знание openpyxl пригодится!
Электронные таблицы - это очень интуитивно понятный и удобный способ манипулирования большими наборами данных без какой-либо предварительной технической подготовки. Вот почему они все еще так широко используются сегодня.
В этой статье вы узнаете, как использовать openpyxl для:
- Уверенно работать с электронными таблицами Excel
- Извлекать информацию из электронных таблиц
- Создавайте простые или более сложные электронные таблицы, включая добавление стилей, диаграмм и т.д.
Эта статья написана для разработчиков среднего уровня, которые довольно хорошо разбираются в структурах данных Python, таких как dicts и lists, но также чувствуйте себя комфортно при изучении ООП и других тем среднего уровня.
Скачать набор данных: Нажмите здесь, чтобы загрузить набор данных для упражнения openpyxl, которое вы будете выполнять в этом руководстве.
Прежде чем Вы начнете
Если вас когда-нибудь попросят извлечь какие-либо данные из базы данных или файла журнала в электронную таблицу Excel, или если вам часто приходится преобразовывать электронную таблицу Excel в более удобную программную форму, то это руководство идеально вам подойдет. Давайте запрыгнем в фургон openpyxl!
Практические примеры использования
Перво-наперво, когда вам понадобится использовать пакет, подобный openpyxl, в реальном сценарии? Ниже вы увидите несколько примеров, но на самом деле существуют сотни возможных сценариев, в которых эти знания могут пригодиться.
Импорт новых Продуктов в Базу Данных
Вы отвечаете за технологии в компании, занимающейся интернет-магазинами, и ваш начальник не хочет платить за крутую и дорогую CMS-систему.
Каждый раз, когда они хотят добавить новые товары в интернет-магазин, они приходят к вам с электронной таблицей Excel, содержащей несколько сотен строк, и для каждой из них у вас есть название продукта, описание, цена и так далее.
Теперь, чтобы импортировать данные, вам нужно будет выполнить итерацию по каждой строке электронной таблицы и добавить каждый товар в интернет-магазин.
Экспорт данных Базы Данных в Электронную Таблицу
Допустим, у вас есть таблица базы данных, в которую вы записываете всю информацию о своих пользователях, включая имя, номер телефона, адрес электронной почты и так далее.
Теперь маркетинговая команда хочет связаться со всеми пользователями, чтобы предложить им какую-нибудь скидку или рекламную акцию. Однако у них нет доступа к базе данных или они не знают, как использовать SQL для простого извлечения этой информации.
Чем вы можете помочь? Итак, вы можете быстро создать скрипт, используя openpyxl, который выполняет итерацию по каждой записи пользователя и заносит всю необходимую информацию в электронную таблицу Excel.
За это вы получите дополнительный кусок торта на следующем дне рождения вашей компании!
Добавление информации в существующую электронную таблицу
Возможно, вам также придется открыть электронную таблицу, прочитать содержащуюся в ней информацию и, в соответствии с некоторой бизнес-логикой, добавить к ней дополнительные данные.
Например, снова используя сценарий с интернет-магазином, предположим, вы получаете электронную таблицу Excel со списком пользователей, и вам нужно добавить к каждой строке общую сумму, которую они потратили в вашем магазине.
Эти данные находятся в базе данных, и для того, чтобы это сделать, вам необходимо прочитать электронную таблицу, выполнить итерацию по каждой строке, извлечь из базы данных общую потраченную сумму и затем записать ее обратно в электронную таблицу.
Это не проблема для openpyxl!
Изучение некоторых базовых терминов Excel
Вот краткий список основных терминов, с которыми вы познакомитесь при работе с электронными таблицами Excel:
| Термин | Пояснение |
|---|---|
| Электронная таблица или рабочая книга | Электронная таблица — это основной файл, который вы создаёте или с которым работаете. |
| Рабочий лист или лист | Лист используется для разделения различных типов содержимого в одной электронной таблице. Электронная таблица может содержать один или несколько листов. |
| Столбец | Столбец — это вертикальная линия, которая обозначается заглавной буквой: A. |
| Строка | Строка — это горизонтальная линия, которая обозначается числом: 1. |
| Ячейка | Ячейка — это комбинация Столбца и Строки, которая обозначается заглавной буквой и числом: A1. |
Начало работы с openpyxl
Теперь, когда вы знаете о преимуществах такого инструмента, как openpyxl, давайте приступим к делу и начнем с установки пакета. Для этого руководства вы должны использовать Python 3.7 и openpyxl 2.6.2. Чтобы установить пакет, вы можете выполнить следующие действия:
$ pip install openpyxl
После установки пакета вы сможете создать очень простую электронную таблицу со следующим кодом:
from openpyxl import Workbook
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "hello"
sheet["B1"] = "world!"
workbook.save(filename="hello_world.xlsx")
Приведенный выше код должен создать файл с именем hello_world.xlsx в папке, которую вы используете для запуска кода. Если вы откроете этот файл в Excel, вы увидите что-то вроде этого:
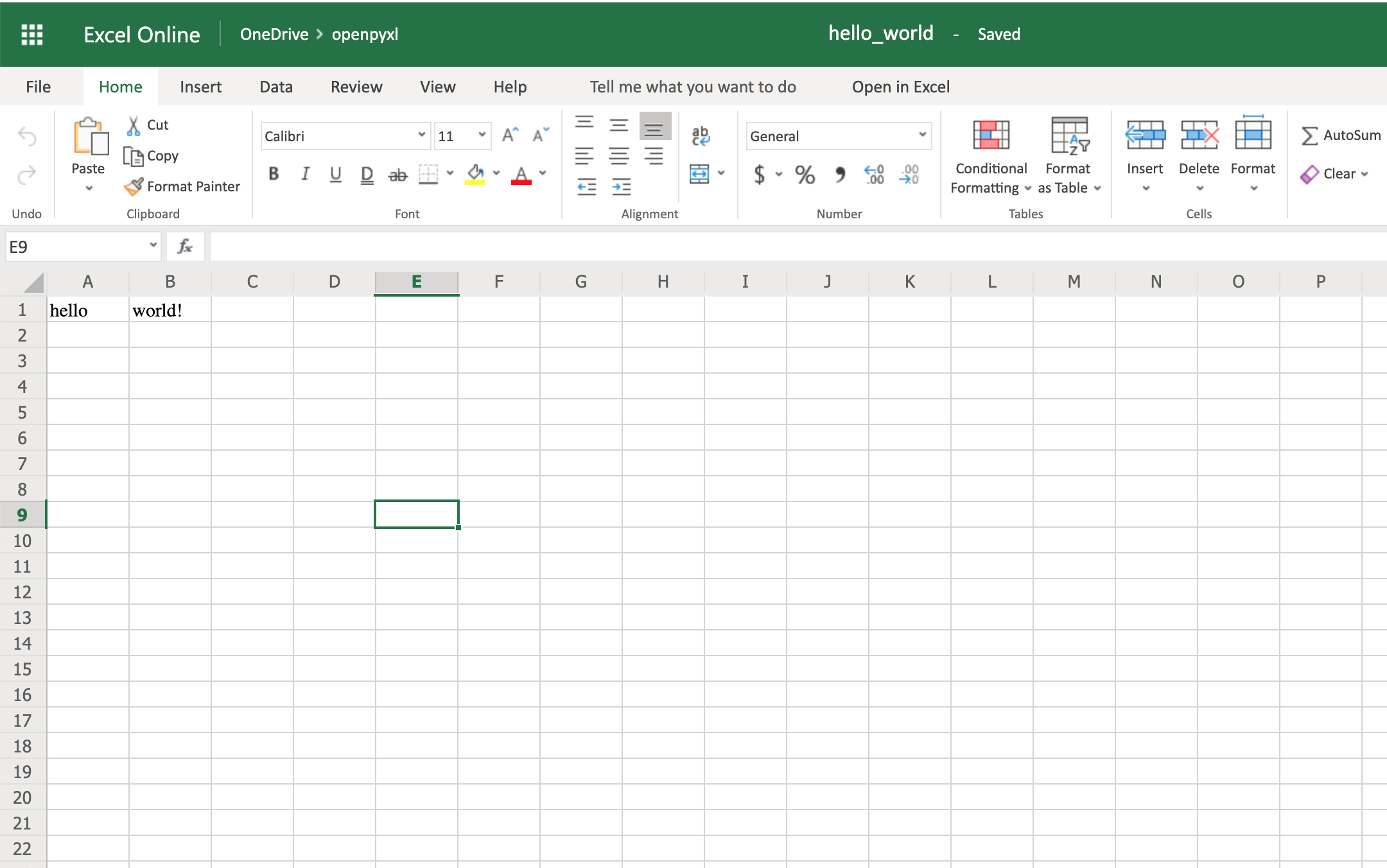
Ого-го, ваша первая электронная таблица создана!
Чтение электронных таблиц Excel с помощью openpyxl
Давайте начнем с самого важного, что можно сделать с электронной таблицей: прочтите ее.
Вы перейдете от простого подхода к чтению электронной таблицы к более сложным примерам, в которых вы считываете данные и преобразуете их в более полезные структуры Python.
Набор данных для этого руководства
Прежде чем вы углубитесь в некоторые примеры кода, вам следует загрузить этот примерный набор данных и сохранить его где-нибудь в виде sample.xlsx:
Это один из наборов данных, которые вы будете использовать в этом руководстве, и это электронная таблица с образцами реальных данных из онлайн-обзоров товаров Amazon. Этот набор данных - лишь малая часть того, что предоставляет Amazon , но для целей тестирования этого более чем достаточно.
Простой подход к чтению электронной таблицы Excel
Наконец, давайте начнем читать некоторые электронные таблицы! Для начала откройте наш пример электронной таблицы:
>>> from openpyxl import load_workbook
>>> workbook = load_workbook(filename="sample.xlsx")
>>> workbook.sheetnames
['Sheet 1']
>>> sheet = workbook.active
>>> sheet
<Worksheet "Sheet 1">
>>> sheet.title
'Sheet 1'
В приведенном выше коде вы сначала открываете электронную таблицу sample.xlsx с помощью load_workbook(), а затем можете использовать workbook.sheetnames, чтобы просмотреть все доступные для работы таблицы. После этого workbook.active выбирает первый доступный лист, и в этом случае вы можете видеть, что он автоматически выбирает Лист 1. Использование этих методов является стандартным способом открытия электронной таблицы, и вы будете видеть это много раз в ходе этого руководства.
Теперь, открыв электронную таблицу, вы можете легко извлечь из нее данные следующим образом:
>>> sheet["A1"]
<Cell 'Sheet 1'.A1>
>>> sheet["A1"].value
'marketplace'
>>> sheet["F10"].value
"G-Shock Men's Grey Sport Watch"
Чтобы вернуть фактическое значение ячейки, вам нужно выполнить .value. В противном случае вы получите основной объект Cell. Вы также можете использовать метод .cell() для извлечения ячейки с использованием индексной записи. Не забудьте добавить .value, чтобы получить фактическое значение, а не объект Cell:
>>> sheet.cell(row=10, column=6)
<Cell 'Sheet 1'.F10>
>>> sheet.cell(row=10, column=6).value
"G-Shock Men's Grey Sport Watch"
Вы можете видеть, что результаты будут одинаковыми, независимо от того, какой способ вы выберете. Однако в этом руководстве вы будете в основном использовать первый подход: ["A1"].
Примечание: Несмотря на то, что в Python вы привыкли к записи с нулевым индексом, в электронных таблицах вы всегда будете использовать запись с одним индексом, где первая строка или столбец всегда имеют индекс 1.
Выше показан самый быстрый способ открыть электронную таблицу. Однако вы можете задать дополнительные параметры, чтобы изменить способ загрузки электронной таблицы.
Дополнительные параметры чтения
Есть несколько аргументов, которые вы можете передать в load_workbook(), которые изменяют способ загрузки электронной таблицы. Наиболее важными из них являются следующие два логических значения :
- read_only загружает электронную таблицу в режиме только для чтения, что позволяет открывать очень большие файлы Excel.
- data_only игнорирует загрузку формул и вместо этого загружает только результирующие значения.
Импорт данных из Электронной Таблицы
Теперь, когда вы освоили основы загрузки электронной таблицы, самое время перейти к самому интересному: повторение и фактическое использование значений в электронной таблице.
В этом разделе вы узнаете обо всех различных способах обработки данных, а также о том, как преобразовать эти данные во что-то полезное и, что более важно, как это сделать на языке Python.
Перебор данных
Существует несколько различных способов обработки данных в зависимости от ваших потребностей.
Вы можете разделить данные на части, используя комбинацию столбцов и строк:
>>> sheet["A1:C2"]
((<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.C1>),
(<Cell 'Sheet 1'.A2>, <Cell 'Sheet 1'.B2>, <Cell 'Sheet 1'.C2>))
Вы можете получить диапазоны строк или столбцов:
>>> # Get all cells from column A
>>> sheet["A"]
(<Cell 'Sheet 1'.A1>,
<Cell 'Sheet 1'.A2>,
...
<Cell 'Sheet 1'.A99>,
<Cell 'Sheet 1'.A100>)
>>> # Get all cells for a range of columns
>>> sheet["A:B"]
((<Cell 'Sheet 1'.A1>,
<Cell 'Sheet 1'.A2>,
...
<Cell 'Sheet 1'.A99>,
<Cell 'Sheet 1'.A100>),
(<Cell 'Sheet 1'.B1>,
<Cell 'Sheet 1'.B2>,
...
<Cell 'Sheet 1'.B99>,
<Cell 'Sheet 1'.B100>))
>>> # Get all cells from row 5
>>> sheet[5]
(<Cell 'Sheet 1'.A5>,
<Cell 'Sheet 1'.B5>,
...
<Cell 'Sheet 1'.N5>,
<Cell 'Sheet 1'.O5>)
>>> # Get all cells for a range of rows
>>> sheet[5:6]
((<Cell 'Sheet 1'.A5>,
<Cell 'Sheet 1'.B5>,
...
<Cell 'Sheet 1'.N5>,
<Cell 'Sheet 1'.O5>),
(<Cell 'Sheet 1'.A6>,
<Cell 'Sheet 1'.B6>,
...
<Cell 'Sheet 1'.N6>,
<Cell 'Sheet 1'.O6>))
Вы заметите, что все приведенные выше примеры возвращают значение tuple. Если вы хотите освежить в памяти информацию о том, как обрабатывать tuples в Python, ознакомьтесь со статьей о Списках и кортежах в Python.
Существует также несколько способов использования обычных генераторов Python для обработки данных. Основными методами, которые вы можете использовать для достижения этой цели, являются:
.iter_rows().iter_cols()
Оба метода могут принимать следующие аргументы:
min_rowmax_rowmin_colmax_col
Эти аргументы используются для задания границ итерации:
>>> for row in sheet.iter_rows(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3):
... print(row)
(<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.C1>)
(<Cell 'Sheet 1'.A2>, <Cell 'Sheet 1'.B2>, <Cell 'Sheet 1'.C2>)
>>> for column in sheet.iter_cols(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3):
... print(column)
(<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.A2>)
(<Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.B2>)
(<Cell 'Sheet 1'.C1>, <Cell 'Sheet 1'.C2>)
Вы заметите, что в первом примере при переборе строк с использованием .iter_rows() вы получаете по одному элементу tuple на каждую выбранную строку. В то время как при использовании .iter_cols() и переборе столбцов вместо этого вы получите по одному tuple на столбец.
Одним из дополнительных аргументов, который вы можете передать обоим методам, является логическое значение values_only. Когда для него установлено значение True, вместо объекта Cell возвращаются значения ячейки:
>>> for value in sheet.iter_rows(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id')
('US', 3653882, 'R3O9SGZBVQBV76')
Если вы хотите выполнить итерацию по всему набору данных, вы также можете напрямую использовать атрибуты .rows или .columns, которые являются сокращениями для использования .iter_rows() и .iter_cols().> без каких-либо аргументов:
>>> for row in sheet.rows:
... print(row)
(<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.C1>
...
<Cell 'Sheet 1'.M100>, <Cell 'Sheet 1'.N100>, <Cell 'Sheet 1'.O100>)
Эти сочетания клавиш очень полезны при повторном просмотре всего набора данных.
Манипулируйте данными, используя структуры данных Python по умолчанию
Теперь, когда вы знакомы с основами итерационного просмотра данных в рабочей книге, давайте рассмотрим разумные способы преобразования этих данных в структуры Python.
Как вы видели ранее, результат всех итераций имеет вид tuples. Однако, поскольку tuple - это не что иное, как list , который является неизменяемым, вы можете легко получить доступ к его данным и преобразовать их в другие структуры.
Например, предположим, что вы хотите извлечь информацию о продукте из электронной таблицы sample.xlsx в словарь, где каждый ключ является идентификатором продукта.
Простой способ сделать это - просмотреть все строки, выбрать столбцы, которые, как вы знаете, связаны с информацией о продукте, а затем сохранить их в словаре. Давайте закодируем это!
Прежде всего, взгляните на заголовки и посмотрите, какая информация вас больше всего интересует:
>>> for value in sheet.iter_rows(min_row=1,
... max_row=1,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id', 'product_id', ...)
Этот код возвращает список всех имен столбцов, которые есть в электронной таблице. Для начала выберите столбцы с именами:
product_idproduct_parentproduct_titleproduct_category
К счастью для вас, все нужные вам столбцы расположены рядом друг с другом, поэтому вы можете использовать min_column и max_column, чтобы легко получить нужные данные:
>>> for value in sheet.iter_rows(min_row=2,
... min_col=4,
... max_col=7,
... values_only=True):
... print(value)
('B00FALQ1ZC', 937001370, 'Invicta Women\'s 15150 "Angel" 18k Yellow...)
('B00D3RGO20', 484010722, "Kenneth Cole New York Women's KC4944...)
...
Приятно! Теперь, когда вы знаете, как получить всю необходимую информацию о продукте, давайте введем эти данные в словарь:
import json
from openpyxl import load_workbook
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
products = {}
# Using the values_only because you want to return the cells' values
for row in sheet.iter_rows(min_row=2,
min_col=4,
max_col=7,
values_only=True):
product_id = row[0]
product = {
"parent": row[1],
"title": row[2],
"category": row[3]
}
products[product_id] = product
# Using json here to be able to format the output for displaying later
print(json.dumps(products))
Приведенный выше код возвращает JSON, аналогичный этому:
{
"B00FALQ1ZC": {
"parent": 937001370,
"title": "Invicta Women's 15150 ...",
"category": "Watches"
},
"B00D3RGO20": {
"parent": 484010722,
"title": "Kenneth Cole New York ...",
"category": "Watches"
}
}
Здесь вы можете видеть, что выходные данные сокращены только до 2 продуктов, но если вы запустите скрипт как есть, то получите 98 продуктов.
Преобразование Данных в Классы Python
Чтобы завершить ознакомительный раздел этого руководства, давайте углубимся в Классы Python и посмотрим, как вы могли бы улучшить приведенный выше пример и лучше структурировать данные.
Для этого вы будете использовать новые классы данных Python, доступные с Python 3.7. Если вы используете более старую версию Python, вы можете использовать классы данных по умолчанию Классы вместо этого.
Итак, перво-наперво, давайте рассмотрим имеющиеся у вас данные и решим, что вы хотите сохранить и как вы хотите это сделать.
Как вы видели в самом начале, эти данные получены от Amazon и представляют собой список отзывов о товарах. Вы можете просмотреть список всех столбцов и их значение на Amazon.
Есть два важных элемента, которые вы можете извлечь из имеющихся данных:
- Товары
- Отзывы
Продукт содержит:
- Идентификатор
- Название
- Родитель
- Категория
В отзыве есть еще несколько полей:
- ИДЕНТИФИКАТОР
- Идентификатор клиента
- Звездочек
- Заголовок
- Основная часть
- Дата
Вы можете игнорировать некоторые поля для просмотра, чтобы немного упростить задачу.
Таким образом, простая реализация этих двух классов может быть записана в отдельном файле classes.py:
import datetime
from dataclasses import dataclass
@dataclass
class Product:
id: str
parent: str
title: str
category: str
@dataclass
class Review:
id: str
customer_id: str
stars: int
headline: str
body: str
date: datetime.datetime
После определения ваших классов данных вам необходимо преобразовать данные из электронной таблицы в эти новые структуры.
Перед выполнением преобразования стоит еще раз взглянуть на наш заголовок и создать сопоставление между столбцами и нужными вам полями:
>>> for value in sheet.iter_rows(min_row=1,
... max_row=1,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id', 'product_id', ...)
>>> # Or an alternative
>>> for cell in sheet[1]:
... print(cell.value)
marketplace
customer_id
review_id
product_id
product_parent
...
Давайте создадим файл mapping.py, в котором у вас будет список названий всех полей и расположение их столбцов (с нулевой индексацией) в электронной таблице:
# Product fields
PRODUCT_ID = 3
PRODUCT_PARENT = 4
PRODUCT_TITLE = 5
PRODUCT_CATEGORY = 6
# Review fields
REVIEW_ID = 2
REVIEW_CUSTOMER = 1
REVIEW_STARS = 7
REVIEW_HEADLINE = 12
REVIEW_BODY = 13
REVIEW_DATE = 14
Вам необязательно выполнять приведенное выше сопоставление. Это больше для удобства чтения при анализе данных строк, так что в итоге вы не столкнетесь с большим количеством магических чисел.
Наконец, давайте рассмотрим код, необходимый для преобразования данных электронной таблицы в список продуктов и объектов обзора:
from datetime import datetime
from openpyxl import load_workbook
from classes import Product, Review
from mapping import PRODUCT_ID, PRODUCT_PARENT, PRODUCT_TITLE, \
PRODUCT_CATEGORY, REVIEW_DATE, REVIEW_ID, REVIEW_CUSTOMER, \
REVIEW_STARS, REVIEW_HEADLINE, REVIEW_BODY
# Using the read_only method since you're not gonna be editing the spreadsheet
workbook = load_workbook(filename="sample.xlsx", read_only=True)
sheet = workbook.active
products = []
reviews = []
# Using the values_only because you just want to return the cell value
for row in sheet.iter_rows(min_row=2, values_only=True):
product = Product(id=row[PRODUCT_ID],
parent=row[PRODUCT_PARENT],
title=row[PRODUCT_TITLE],
category=row[PRODUCT_CATEGORY])
products.append(product)
# You need to parse the date from the spreadsheet into a datetime format
spread_date = row[REVIEW_DATE]
parsed_date = datetime.strptime(spread_date, "%Y-%m-%d")
review = Review(id=row[REVIEW_ID],
customer_id=row[REVIEW_CUSTOMER],
stars=row[REVIEW_STARS],
headline=row[REVIEW_HEADLINE],
body=row[REVIEW_BODY],
date=parsed_date)
reviews.append(review)
print(products[0])
print(reviews[0])
После того, как вы запустите приведенный выше код, вы должны получить примерно такой результат:
Product(id='B00FALQ1ZC', parent=937001370, ...)
Review(id='R3O9SGZBVQBV76', customer_id=3653882, ...)
Вот и все! Теперь у вас должны быть данные в очень простом и удобоваримом формате класса, и вы можете подумать о том, чтобы сохранить их в базе данных или в любом другом хранилище данных, которое вам нравится.
Использование такого рода стратегии ООП для анализа электронных таблиц значительно упрощает обработку данных в дальнейшем.
Добавление новых данных
Прежде чем приступить к созданию очень сложных электронных таблиц, ознакомьтесь с примером добавления данных в существующую электронную таблицу.
Вернитесь к первому примеру созданной вами электронной таблицы (hello_world.xlsx) и попробуйте открыть ее и добавить в нее некоторые данные, например, так:
from openpyxl import load_workbook
# Start by opening the spreadsheet and selecting the main sheet
workbook = load_workbook(filename="hello_world.xlsx")
sheet = workbook.active
# Write what you want into a specific cell
sheet["C1"] = "writing ;)"
# Save the spreadsheet
workbook.save(filename="hello_world_append.xlsx")
И вуаля, если вы откроете новую электронную таблицу hello_world_append.xlsx, вы увидите следующие изменения:
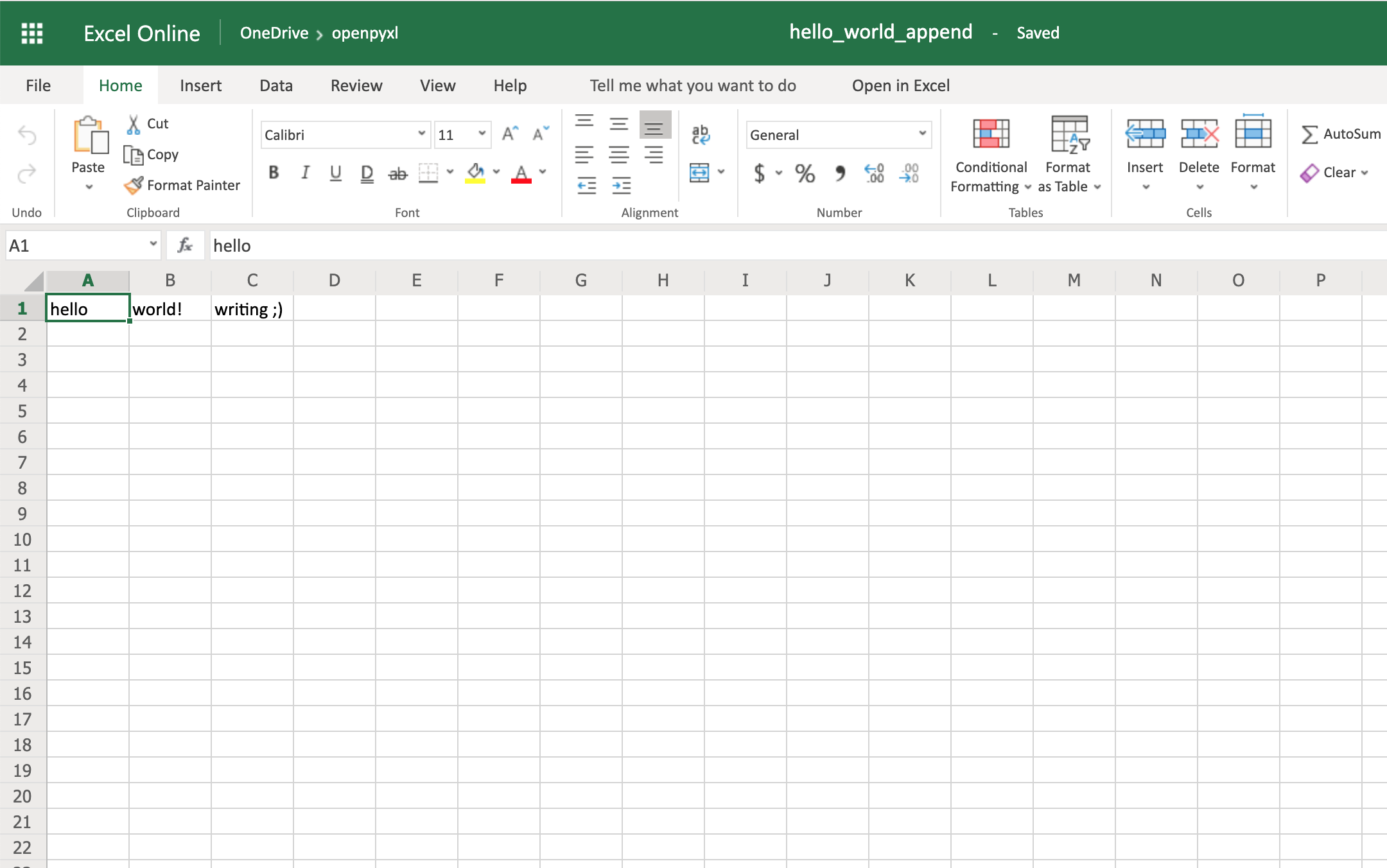
Обратите внимание на дополнительную надпись ;) в ячейке C1.
Создание электронных таблиц Excel с помощью openpyxl
В электронную таблицу можно записать множество различных данных - от простого текста или числовых значений до сложных формул, диаграмм и даже изображений.
Давайте начнем создавать электронные таблицы!
Создание простой электронной таблицы
Ранее вы видели очень краткий пример того, как написать “Hello world!” в электронной таблице, так что вы можете начать с этого:
1from openpyxl import Workbook
2
3filename = "hello_world.xlsx"
4
5workbook = Workbook()
6sheet = workbook.active
7
8sheet["A1"] = "hello"
9sheet["B1"] = "world!"
10
11workbook.save(filename=filename)
Выделенные строки в приведенном выше коде являются наиболее важными для написания. В коде вы можете видеть, что:
- В строке 5 показано, как создать новую пустую рабочую книгу.
- Строки 8 и 9 показывают, как добавлять данные в определенные ячейки.
- В строке 11 показано, как сохранить электронную таблицу, когда вы закончите.
Несмотря на то, что приведенные выше строки могут быть простыми, все равно полезно хорошо знать их на случай, если ситуация станет немного сложнее.
Примечание: Для некоторых из следующих примеров вы будете использовать электронную таблицу hello_world.xlsx, поэтому держите ее под рукой.
Одна вещь, которую вы можете сделать, чтобы помочь с приведением примеров кода, - это добавить следующий метод в свой файл или консоль Python:
>>> def print_rows():
... for row in sheet.iter_rows(values_only=True):
... print(row)
Это упрощает печать всех значений вашей электронной таблицы, просто вызывая print_rows().
Основные операции с электронными таблицами
Прежде чем вы перейдете к более сложным темам, вам полезно знать, как управлять самыми простыми элементами электронной таблицы.
Добавление и обновление значений ячеек
Вы уже научились добавлять значения в электронную таблицу следующим образом:
>>> sheet["A1"] = "value"
Есть другой способ сделать это, сначала выбрав ячейку, а затем изменив ее значение:
>>> cell = sheet["A1"]
>>> cell
<Cell 'Sheet'.A1>
>>> cell.value
'hello'
>>> cell.value = "hey"
>>> cell.value
'hey'
Новое значение сохраняется в электронной таблице только после вызова workbook.save().
Параметр openpyxl создает ячейку при добавлении значения, если эта ячейка ранее не существовала:
>>> # Before, our spreadsheet has only 1 row
>>> print_rows()
('hello', 'world!')
>>> # Try adding a value to row 10
>>> sheet["B10"] = "test"
>>> print_rows()
('hello', 'world!')
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, 'test')
Как вы можете видеть, при попытке добавить значение в ячейку B10 вы получаете кортеж из 10 строк, просто чтобы вы могли получить это тестовое значение.
Управление строками и столбцами
Одной из наиболее распространенных задач, которые вам приходится выполнять при работе с электронными таблицами, является добавление или удаление строк и столбцов. Пакет openpyxl позволяет вам делать это очень простым способом, используя следующие методы:
.insert_rows().delete_rows().insert_cols().delete_cols()
Каждый из этих методов может принимать два аргумента:
idxamount
Снова используя наш базовый пример hello_world.xlsx, давайте посмотрим, как работают эти методы:
>>> print_rows()
('hello', 'world!')
>>> # Insert a column before the existing column 1 ("A")
>>> sheet.insert_cols(idx=1)
>>> print_rows()
(None, 'hello', 'world!')
>>> # Insert 5 columns between column 2 ("B") and 3 ("C")
>>> sheet.insert_cols(idx=3, amount=5)
>>> print_rows()
(None, 'hello', None, None, None, None, None, 'world!')
>>> # Delete the created columns
>>> sheet.delete_cols(idx=3, amount=5)
>>> sheet.delete_cols(idx=1)
>>> print_rows()
('hello', 'world!')
>>> # Insert a new row in the beginning
>>> sheet.insert_rows(idx=1)
>>> print_rows()
(None, None)
('hello', 'world!')
>>> # Insert 3 new rows in the beginning
>>> sheet.insert_rows(idx=1, amount=3)
>>> print_rows()
(None, None)
(None, None)
(None, None)
(None, None)
('hello', 'world!')
>>> # Delete the first 4 rows
>>> sheet.delete_rows(idx=1, amount=4)
>>> print_rows()
('hello', 'world!')
Единственное, что вам нужно помнить, это то, что при вставке новых данных (строк или столбцов) вставка выполняется перед параметром idx.
Итак, если вы сделаете insert_rows(1), он вставит новую строку перед существующей первой строкой.
То же самое и для столбцов: когда вы вызываете insert_cols(2), он вставляет новый столбец справа перед уже существующим вторым столбцом (B).
Однако при удалении строк или столбцов .delete_... удаляются данные , начиная с индекса, переданного в качестве аргумента.
Например, при выполнении delete_rows(2) удаляется строка 2, а при выполнении delete_cols(3) удаляется третий столбец (C).
Управление таблицами
Управление таблицами также является одной из тех вещей, которые вам, возможно, следует знать, даже если вы не так часто ими пользуетесь.
Если вы еще раз посмотрите на примеры кода из этого руководства, то заметите следующий повторяющийся фрагмент кода:
sheet = workbook.active
Это способ выбрать лист электронной таблицы по умолчанию. Однако, если вы открываете электронную таблицу с несколькими листами, вы всегда можете выбрать определенный из них следующим образом:
>>> # Let's say you have two sheets: "Products" and "Company Sales"
>>> workbook.sheetnames
['Products', 'Company Sales']
>>> # You can select a sheet using its title
>>> products_sheet = workbook["Products"]
>>> sales_sheet = workbook["Company Sales"]
Вы также можете очень легко изменить заголовок листа:
>>> workbook.sheetnames
['Products', 'Company Sales']
>>> products_sheet = workbook["Products"]
>>> products_sheet.title = "New Products"
>>> workbook.sheetnames
['New Products', 'Company Sales']
Если вы хотите создавать или удалять листы, вы также можете сделать это с помощью .create_sheet() и .remove():
>>> workbook.sheetnames
['Products', 'Company Sales']
>>> operations_sheet = workbook.create_sheet("Operations")
>>> workbook.sheetnames
['Products', 'Company Sales', 'Operations']
>>> # You can also define the position to create the sheet at
>>> hr_sheet = workbook.create_sheet("HR", 0)
>>> workbook.sheetnames
['HR', 'Products', 'Company Sales', 'Operations']
>>> # To remove them, just pass the sheet as an argument to the .remove()
>>> workbook.remove(operations_sheet)
>>> workbook.sheetnames
['HR', 'Products', 'Company Sales']
>>> workbook.remove(hr_sheet)
>>> workbook.sheetnames
['Products', 'Company Sales']
Еще одна вещь, которую вы можете сделать, это создать дубликаты листа с помощью copy_worksheet():
>>> workbook.sheetnames
['Products', 'Company Sales']
>>> products_sheet = workbook["Products"]
>>> workbook.copy_worksheet(products_sheet)
<Worksheet "Products Copy">
>>> workbook.sheetnames
['Products', 'Company Sales', 'Products Copy']
Если вы откроете свою электронную таблицу после сохранения приведенного выше кода, вы заметите, что лист Копия продуктов является дубликатом листа Продукты.
Замораживание строк и столбцов
При работе с большими электронными таблицами вам может потребоваться заблокировать несколько строк или столбцов, чтобы они оставались видимыми при прокрутке вправо или вниз.
Сохранение данных позволяет вам отслеживать важные строки или столбцы независимо от того, в каком месте электронной таблицы вы проводите прокрутку.
Опять же, у openpyxl также есть способ добиться этого, используя атрибут worksheet freeze_panes. Для этого примера вернитесь к нашей электронной таблице sample.xlsx и попробуйте выполнить следующее:
>>> workbook = load_workbook(filename="sample.xlsx")
>>> sheet = workbook.active
>>> sheet.freeze_panes = "C2"
>>> workbook.save("sample_frozen.xlsx")
Если вы откроете электронную таблицу sample_frozen.xlsx в вашем любимом редакторе электронных таблиц, вы заметите, что строка 1 и столбцы A и B заморожены и всегда видны независимо от того, куда вы перемещаетесь в электронной таблице.
Эта функция удобна, например, для того, чтобы держать заголовки в поле зрения, чтобы вы всегда знали, что представляет собой каждый столбец.
Вот как это выглядит в редакторе:
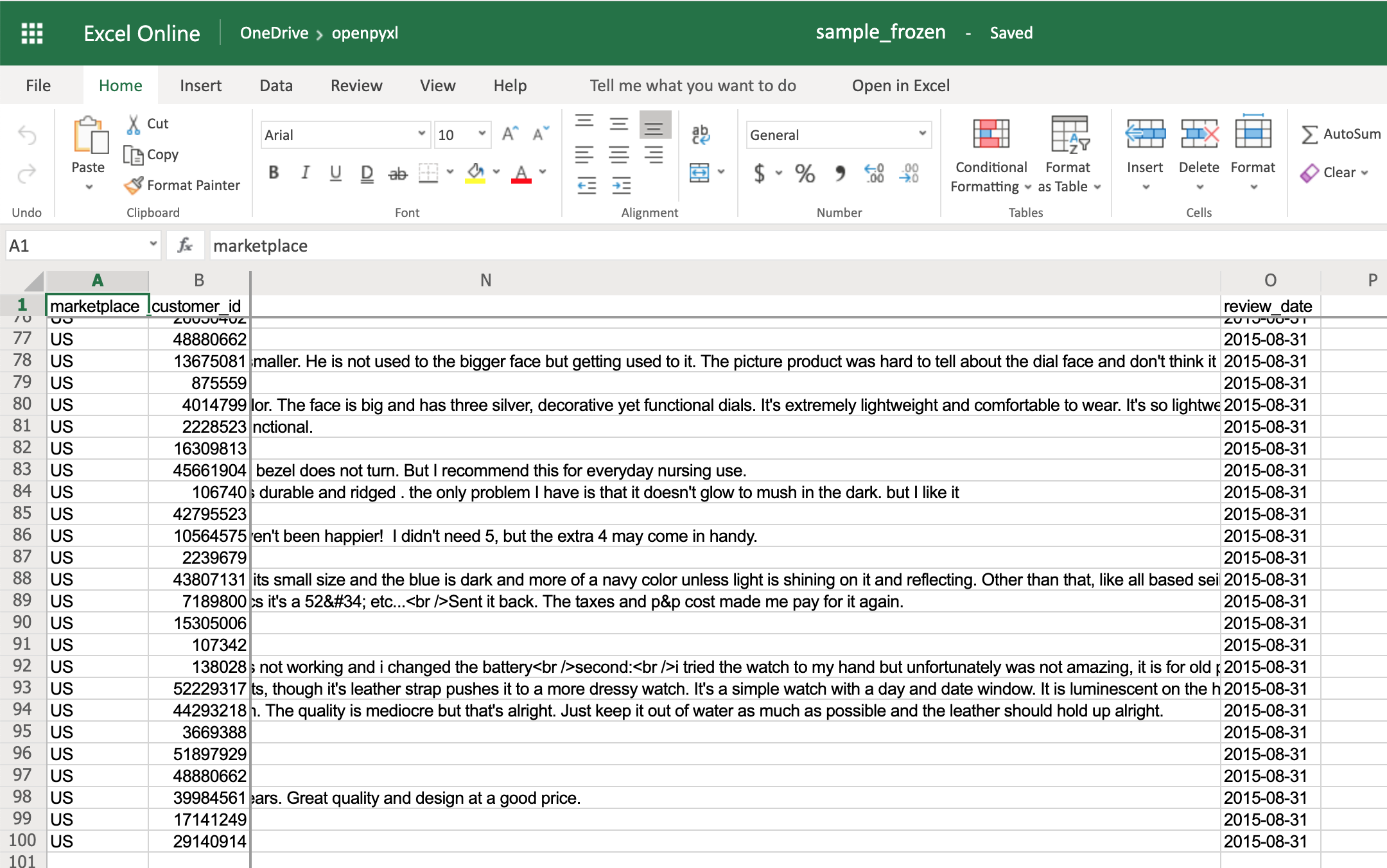
Обратите внимание, что вы находитесь в конце электронной таблицы, и все же вы можете видеть как строку 1, так и столбцы A и B.
Добавление фильтров
Вы можете использовать openpyxl для добавления фильтров и сортировок в свою электронную таблицу. Однако при открытии электронной таблицы данные не будут упорядочены в соответствии с этими сортировками и фильтрами.
На первый взгляд, это может показаться довольно бесполезной функцией, но когда вы программно создаете электронную таблицу, которая будет отправлена и использована кем-то другим, все равно неплохо, по крайней мере, создать фильтры и позволить людям использовать ее позже.
Приведенный ниже код является примером того, как вы могли бы добавить некоторые фильтры в нашу существующую электронную таблицу sample.xlsx:
>>> # Check the used spreadsheet space using the attribute "dimensions"
>>> sheet.dimensions
'A1:O100'
>>> sheet.auto_filter.ref = "A1:O100"
>>> workbook.save(filename="sample_with_filters.xlsx")
Теперь вы должны увидеть фильтры, созданные при открытии электронной таблицы в вашем редакторе:
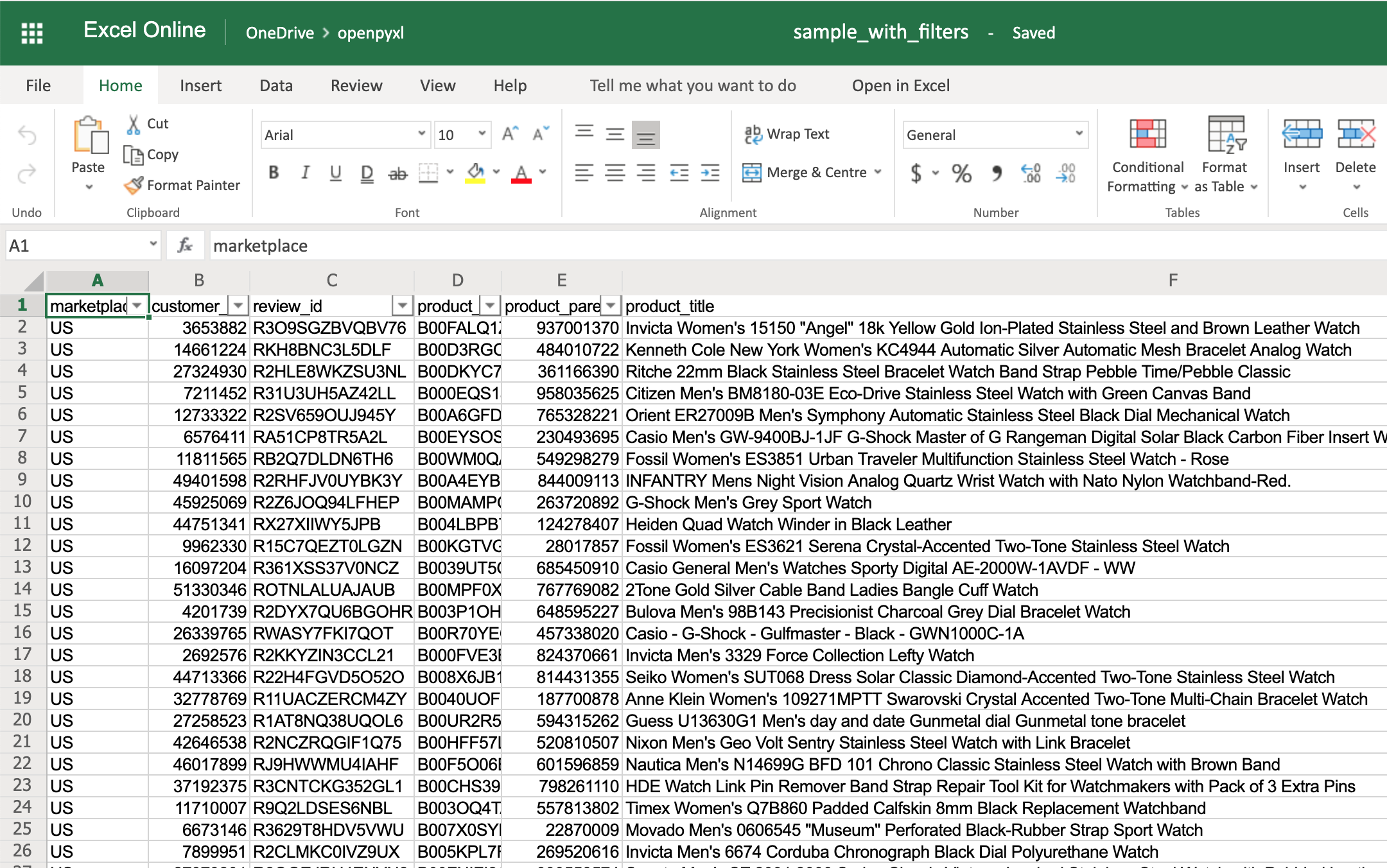
Вам не нужно использовать sheet.dimensions, если вы точно знаете, к какой части электронной таблицы вы хотите применить фильтры.
Добавление формул
Формулы (или формулы) являются одной из самых мощных функций электронных таблиц.
Они дают вам возможность применять определенные математические уравнения к диапазону ячеек. Использовать формулы с openpyxl так же просто, как редактировать значение ячейки.
Вы можете просмотреть список формул, поддерживаемых openpyxl:
>>> from openpyxl.utils import FORMULAE
>>> FORMULAE
frozenset({'ABS',
'ACCRINT',
'ACCRINTM',
'ACOS',
'ACOSH',
'AMORDEGRC',
'AMORLINC',
'AND',
...
'YEARFRAC',
'YIELD',
'YIELDDISC',
'YIELDMAT',
'ZTEST'})
Давайте добавим несколько формул в нашу электронную таблицу sample.xlsx.
Начнем с простого, давайте проверим среднюю звездную оценку для 99 отзывов в электронной таблице:
>>> # Star rating is column "H"
>>> sheet["P2"] = "=AVERAGE(H2:H100)"
>>> workbook.save(filename="sample_formulas.xlsx")
Если вы сейчас откроете электронную таблицу и перейдете к ячейке P2, вы увидите, что ее значение равно: 4.18181818181818. Загляните в редактор:
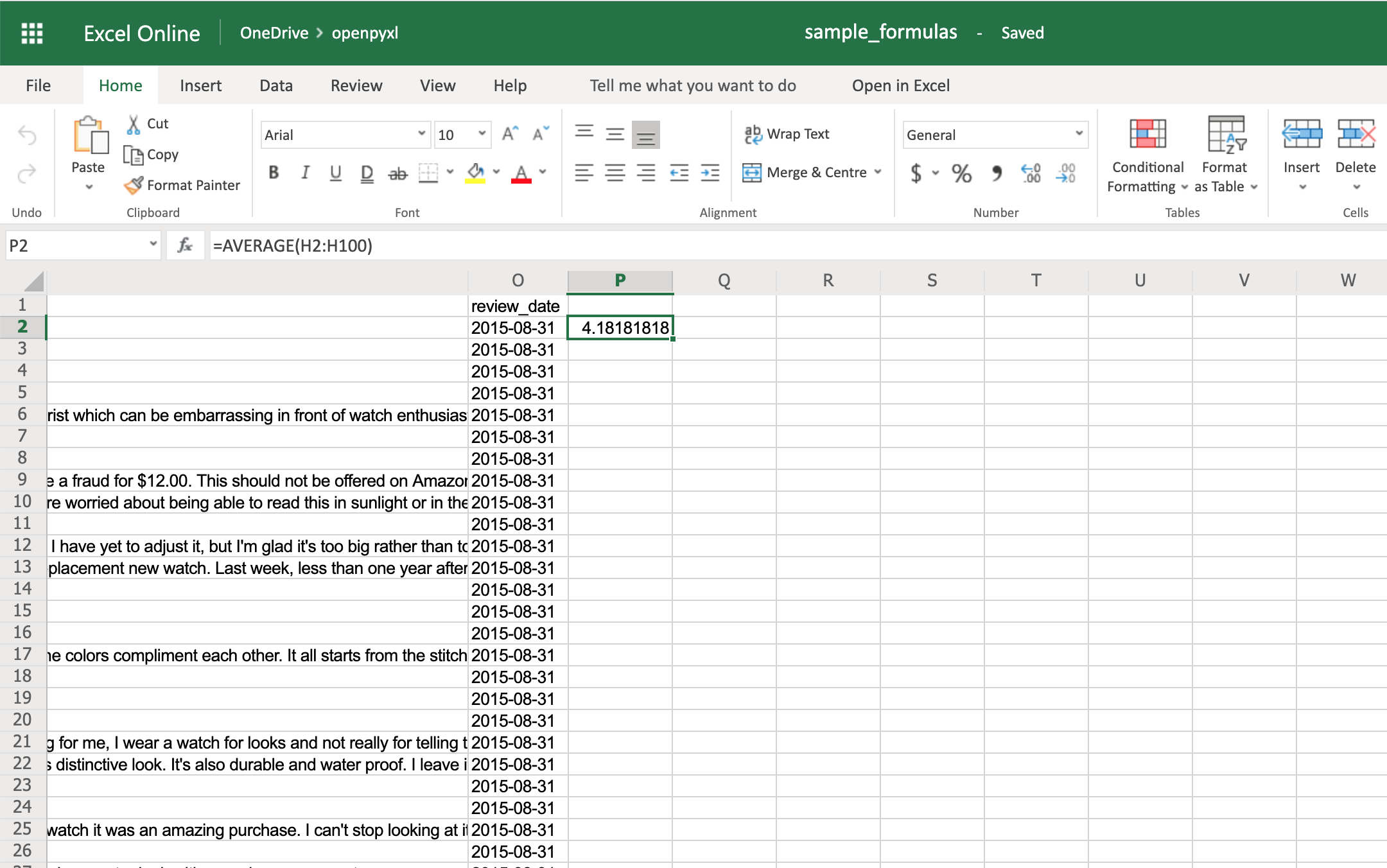
Вы можете использовать ту же методологию для добавления любых формул в свою электронную таблицу. Например, давайте подсчитаем количество отзывов, за которые были отданы полезные голоса:
>>> # The helpful votes are counted on column "I"
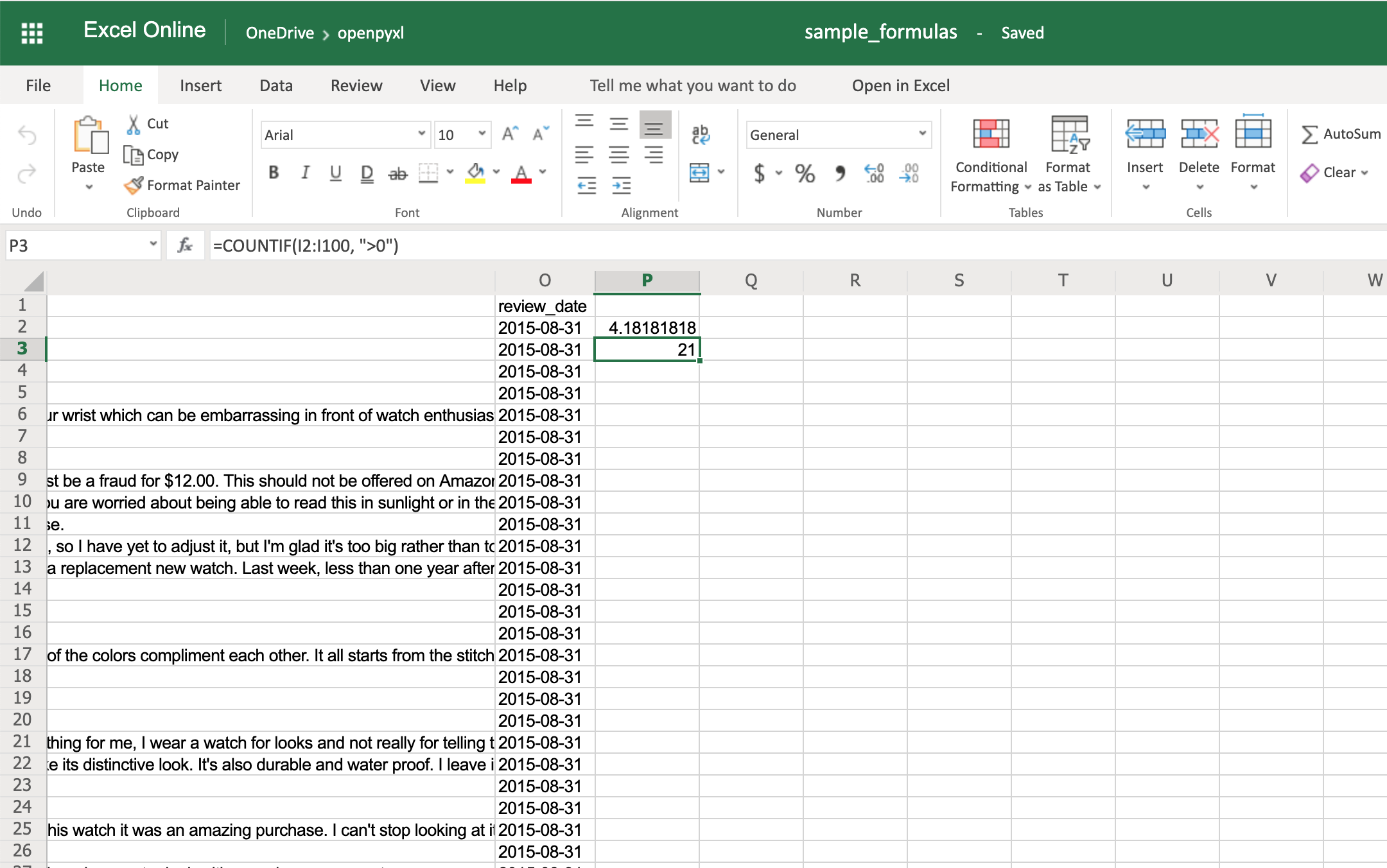
>>> sheet["P3"] = '=COUNTIF(I2:I100, ">0")'
>>> workbook.save(filename="sample_formulas.xlsx")
У вас должно получиться число 21 в вашей ячейке электронной таблицы P3 примерно так:
Вам нужно будет убедиться, что строки в формуле всегда заключены в двойные кавычки, поэтому вам придется либо использовать одинарные кавычки вокруг формулы, как в примере выше, либо экранировать двойные кавычки внутри формулы: "=COUNTIF(I2:I100, \">0\")".
Существует множество других формул, которые вы можете добавить в свою электронную таблицу, используя ту же процедуру, что и описанная выше. Попробуйте сами!
Добавление стилей
Даже если оформление электронной таблицы - это не то, чем вы стали бы заниматься каждый день, все равно полезно знать, как это делается.
Используя openpyxl, вы можете применить к своей электронной таблице несколько вариантов оформления, включая шрифты, границы, цвета и так далее. Ознакомьтесь с документацией openpyxl , чтобы узнать больше.
Вы также можете либо применить стиль непосредственно к ячейке, либо создать шаблон и повторно использовать его для применения стилей к нескольким ячейкам.
Давайте начнем с рассмотрения простого оформления ячеек, снова используя нашу sample.xlsx в качестве базовой таблицы:
>>> # Import necessary style classes
>>> from openpyxl.styles import Font, Color, Alignment, Border, Side
>>> # Create a few styles
>>> bold_font = Font(bold=True)
>>> big_red_text = Font(color="00FF0000", size=20)
>>> center_aligned_text = Alignment(horizontal="center")
>>> double_border_side = Side(border_style="double")
>>> square_border = Border(top=double_border_side,
... right=double_border_side,
... bottom=double_border_side,
... left=double_border_side)
>>> # Style some cells!
>>> sheet["A2"].font = bold_font
>>> sheet["A3"].font = big_red_text
>>> sheet["A4"].alignment = center_aligned_text
>>> sheet["A5"].border = square_border
>>> workbook.save(filename="sample_styles.xlsx")
Если вы сейчас откроете свою электронную таблицу, то увидите довольно много разных стилей в первых 5 ячейках столбца A:
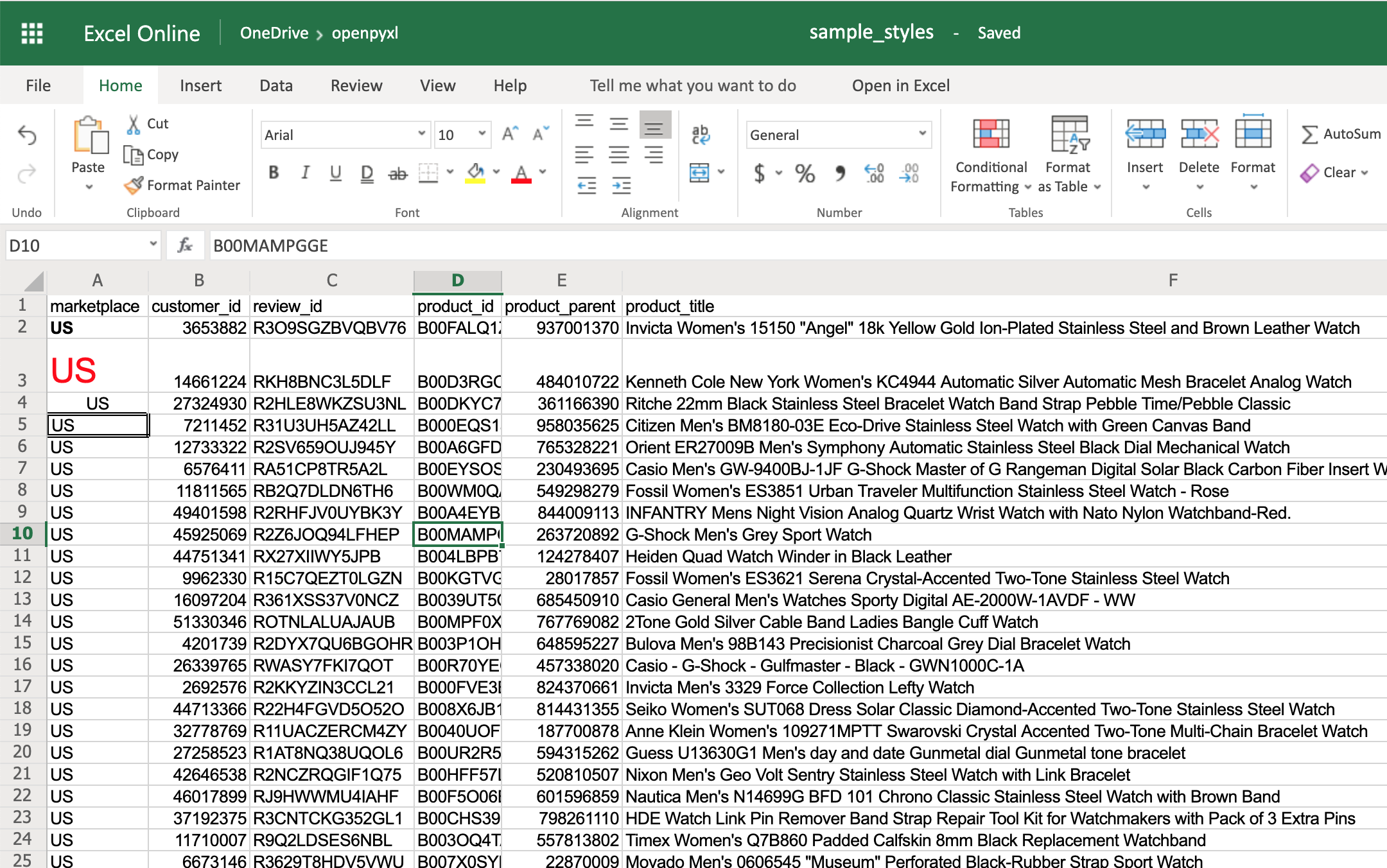
Вот и все. У вас получилось:
- A2 с текстом, выделенным жирным шрифтом
- Формат А3 с текстом красного цвета и увеличенным размером шрифта
- Формат А4 с текстом по центру
- Формат А5 с квадратной рамкой вокруг текста
Примечание: Для цветов вы также можете использовать шестнадцатеричные коды, выполнив следующие действия Font(color="C70E0F").
Вы также можете комбинировать стили, просто добавляя их в ячейку одновременно:
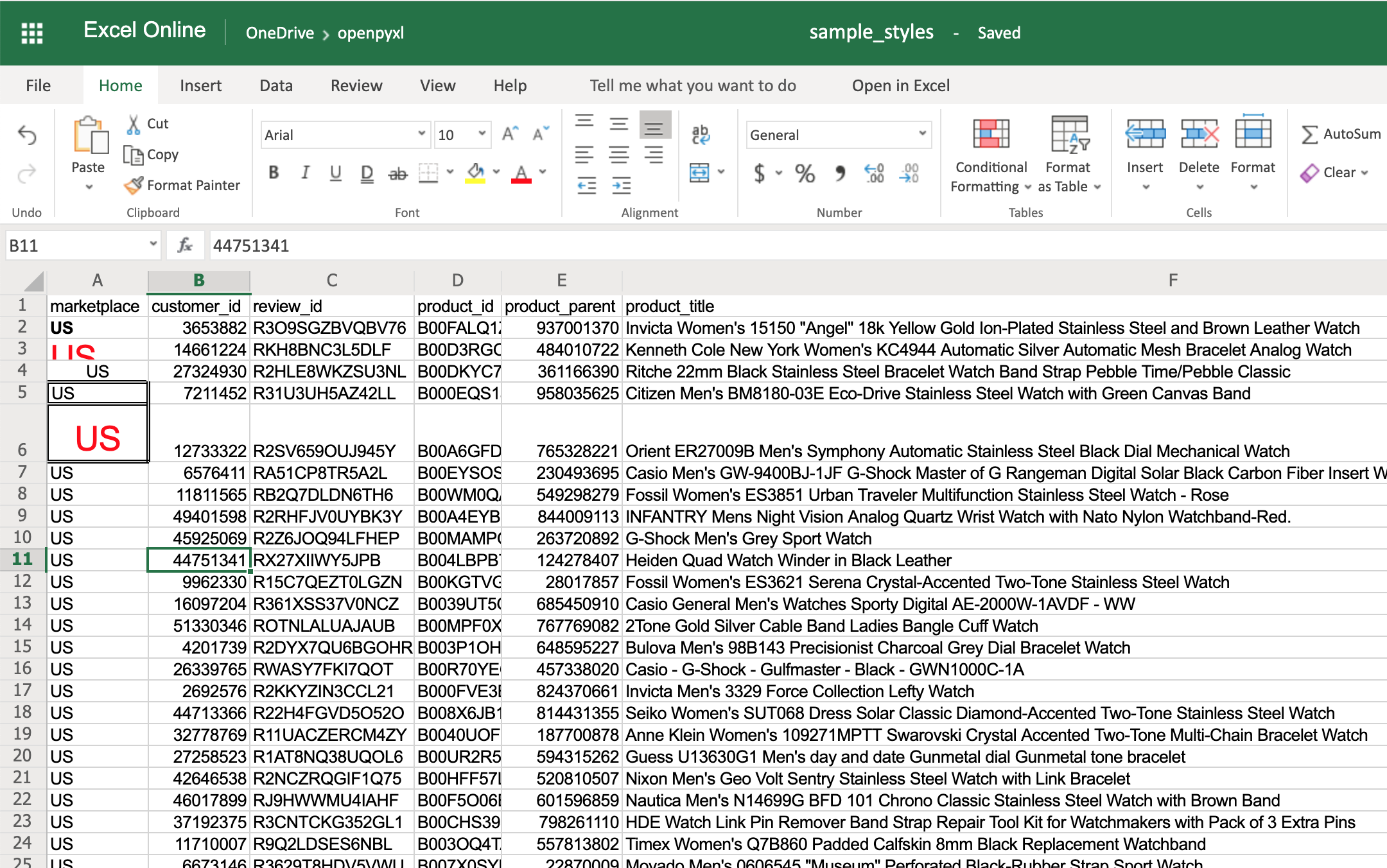
>>> # Reusing the same styles from the example above
>>> sheet["A6"].alignment = center_aligned_text
>>> sheet["A6"].font = big_red_text
>>> sheet["A6"].border = square_border
>>> workbook.save(filename="sample_styles.xlsx")
Взгляните на ячейку A6 здесь:
Если вы хотите применить несколько стилей к одной или нескольким ячейкам, вы можете вместо этого использовать класс NamedStyle, который похож на шаблон стиля, который вы можете использовать снова и снова. Взгляните на приведенный ниже пример:
>>> from openpyxl.styles import NamedStyle
>>> # Let's create a style template for the header row
>>> header = NamedStyle(name="header")
>>> header.font = Font(bold=True)
>>> header.border = Border(bottom=Side(border_style="thin"))
>>> header.alignment = Alignment(horizontal="center", vertical="center")
>>> # Now let's apply this to all first row (header) cells
>>> header_row = sheet[1]
>>> for cell in header_row:
... cell.style = header
>>> workbook.save(filename="sample_styles.xlsx")
Если вы сейчас откроете электронную таблицу, то увидите, что ее первая строка выделена жирным шрифтом, текст выровнен по центру, а внизу есть небольшая рамка! Посмотрите ниже:
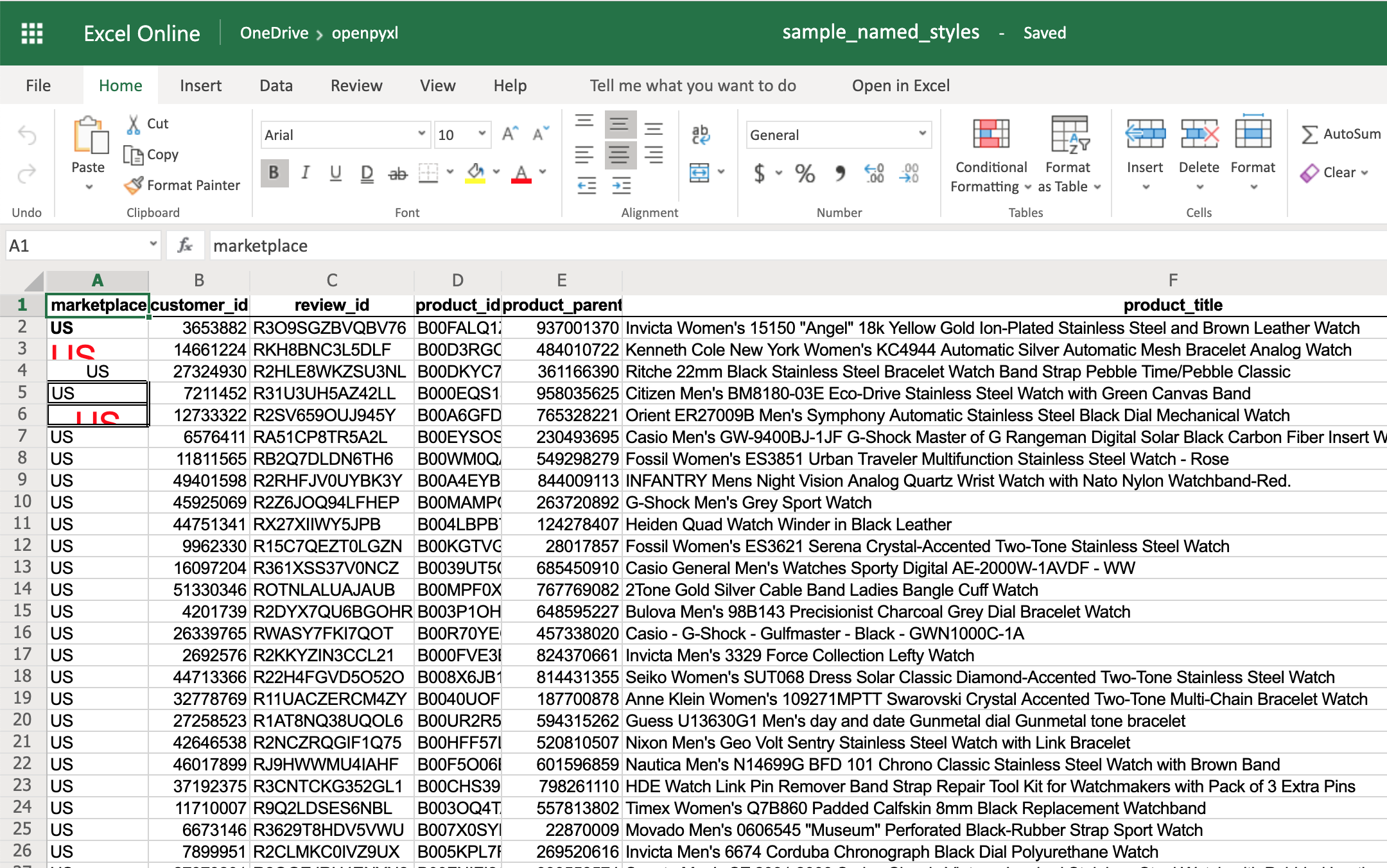
Как вы видели выше, существует множество вариантов оформления, и все зависит от варианта использования, поэтому не стесняйтесь обращаться к документации openpyxl и посмотреть, что еще вы можете сделать.
Условное форматирование
Эта функция - одна из моих любимых, когда речь заходит о добавлении стилей в электронную таблицу.
Это гораздо более эффективный подход к стилизации, поскольку он динамически применяет стили в соответствии с тем, как изменяются данные в электронной таблице.
В двух словах, условное форматирование позволяет указать список стилей для применения к ячейке (или диапазону ячеек) в соответствии с конкретными условиями.
Например, широко распространен вариант составления бухгалтерского баланса, в котором все отрицательные итоги выделены красным цветом, а положительные - зеленым. Такое форматирование позволяет гораздо эффективнее отличать хорошие периоды от плохих.
Не мудрствуя лукаво, давайте выберем нашу любимую электронную таблицу — sample.xlsx — и добавим немного условного форматирования.
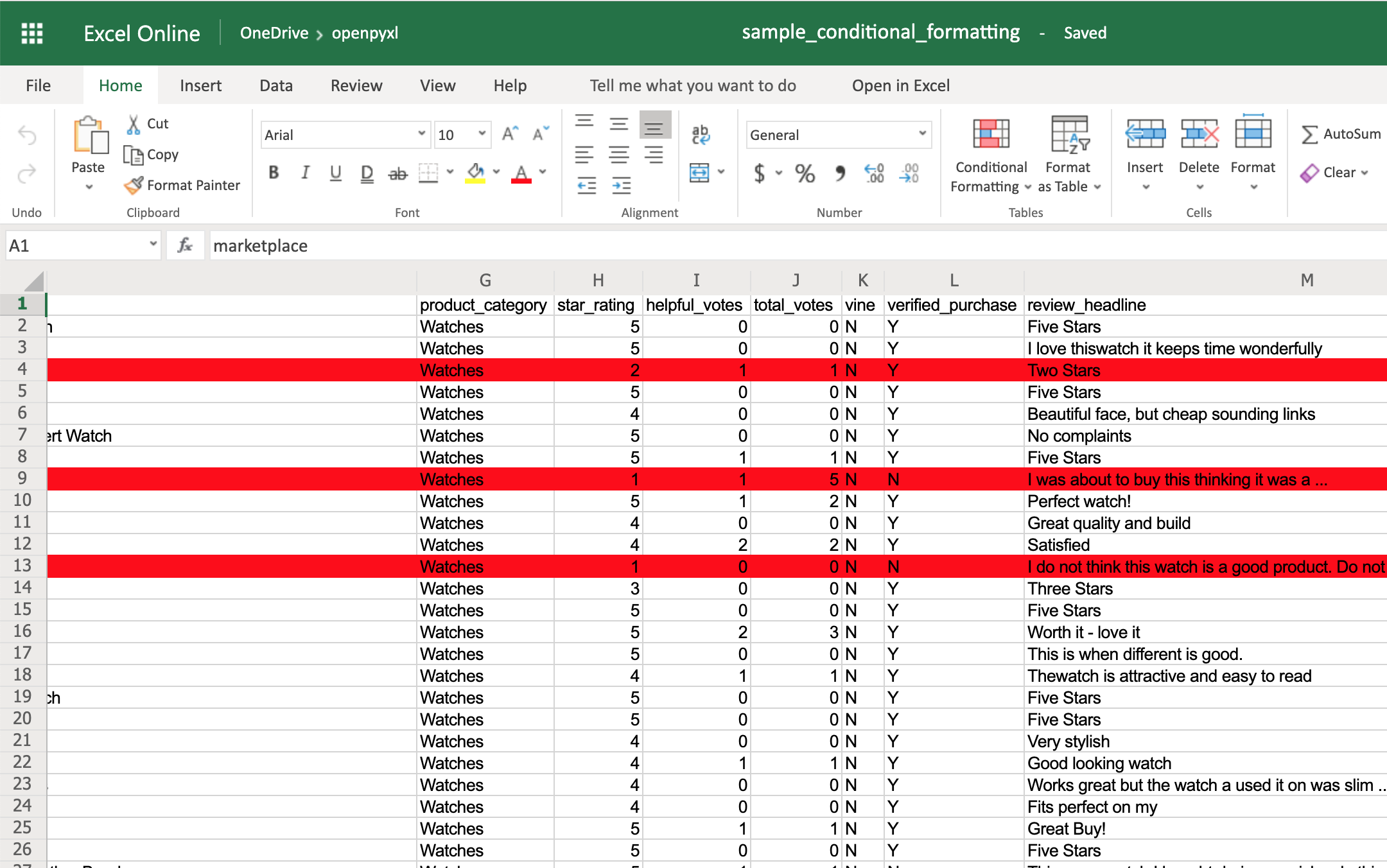
Вы можете начать с простого, который добавит красный фон ко всем отзывам с менее чем 3 звездами:
>>> from openpyxl.styles import PatternFill
>>> from openpyxl.styles.differential import DifferentialStyle
>>> from openpyxl.formatting.rule import Rule
>>> red_background = PatternFill(fgColor="00FF0000")
>>> diff_style = DifferentialStyle(fill=red_background)
>>> rule = Rule(type="expression", dxf=diff_style)
>>> rule.formula = ["$H1<3"]
>>> sheet.conditional_formatting.add("A1:O100", rule)
>>> workbook.save("sample_conditional_formatting.xlsx")
Теперь вы увидите все отзывы с рейтингом ниже 3 звезд, отмеченные красным фоном:
С точки зрения кода, единственное, что здесь является новым, - это объекты DifferentialStyle и Rule:
DifferentialStyleочень похож наNamedStyle, который вы уже видели выше, и используется для объединения нескольких стилей, таких как шрифты, границы, выравнивание и так далее.Ruleотвечает за выбор ячеек и применение стилей, если ячейки соответствуют логике правила.
Используя объект Rule, вы можете создать множество сценариев условного форматирования.
Однако, для простоты, пакет openpyxl предлагает 3 встроенных формата, которые упрощают создание нескольких распространенных шаблонов условного форматирования. Вот эти встроенные модули:
ColorScaleIconSetDataBar
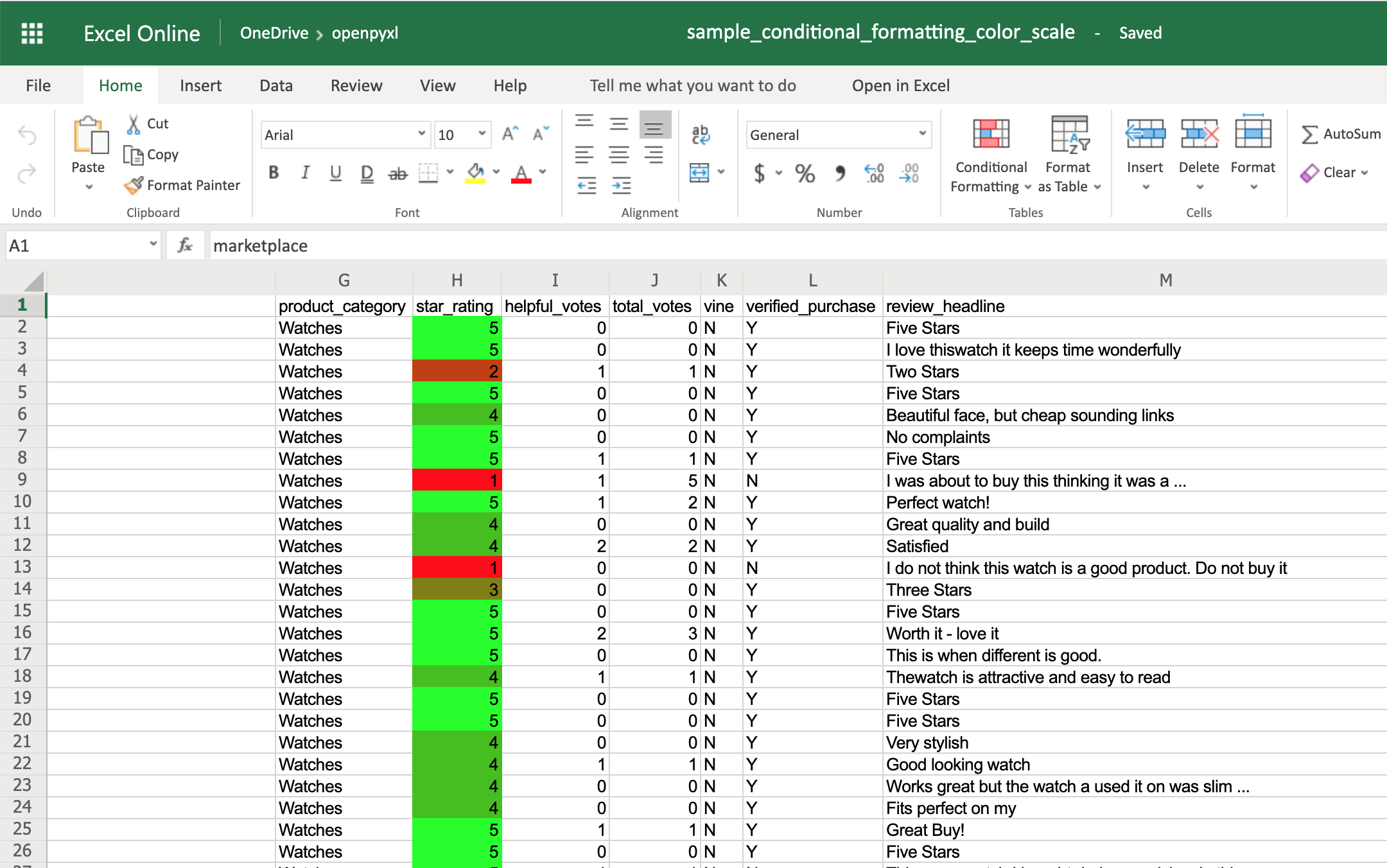
Цветовая шкала позволяет создавать цветовые градиенты:
>>> from openpyxl.formatting.rule import ColorScaleRule
>>> color_scale_rule = ColorScaleRule(start_type="min",
... start_color="00FF0000", # Red
... end_type="max",
... end_color="0000FF00") # Green
>>> # Again, let's add this gradient to the star ratings, column "H"
>>> sheet.conditional_formatting.add("H2:H100", color_scale_rule)
>>> workbook.save(filename="sample_conditional_formatting_color_scale.xlsx")
Теперь вы должны увидеть цветовой градиент в столбце H, от красного к зеленому, в соответствии со звездным рейтингом:
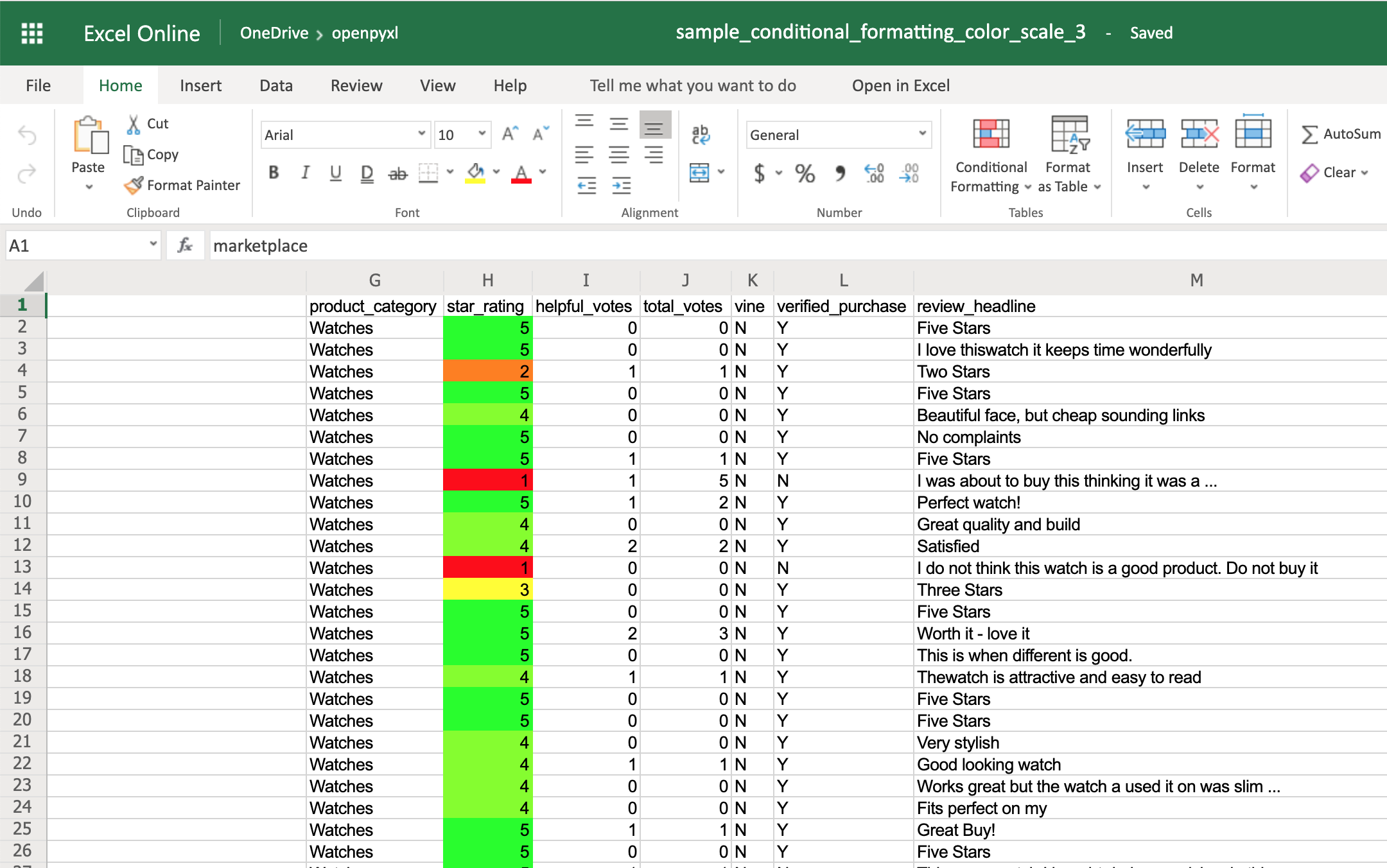
Вы также можете добавить третий цвет и сделать вместо него два градиента:
>>> from openpyxl.formatting.rule import ColorScaleRule
>>> color_scale_rule = ColorScaleRule(start_type="num",
... start_value=1,
... start_color="00FF0000", # Red
... mid_type="num",
... mid_value=3,
... mid_color="00FFFF00", # Yellow
... end_type="num",
... end_value=5,
... end_color="0000FF00") # Green
>>> # Again, let's add this gradient to the star ratings, column "H"
>>> sheet.conditional_formatting.add("H2:H100", color_scale_rule)
>>> workbook.save(filename="sample_conditional_formatting_color_scale_3.xlsx")
На этот раз вы заметите, что звездочки в диапазоне от 1 до 3 имеют градиент от красного к желтому, а звездочки в диапазоне от 3 до 5 имеют градиент от желтого к зеленому:
Набор значков позволяет добавлять значок в ячейку в соответствии с ее значением:
>>> from openpyxl.formatting.rule import IconSetRule
>>> icon_set_rule = IconSetRule("5Arrows", "num", [1, 2, 3, 4, 5])
>>> sheet.conditional_formatting.add("H2:H100", icon_set_rule)
>>> workbook.save("sample_conditional_formatting_icon_set.xlsx")
Вы увидите цветную стрелку рядом со звездочкой рейтинга. Эта стрелка красная и указывает вниз, когда значение ячейки равно 1. По мере повышения рейтинга стрелка начинает указывать вверх и становится зеленой:
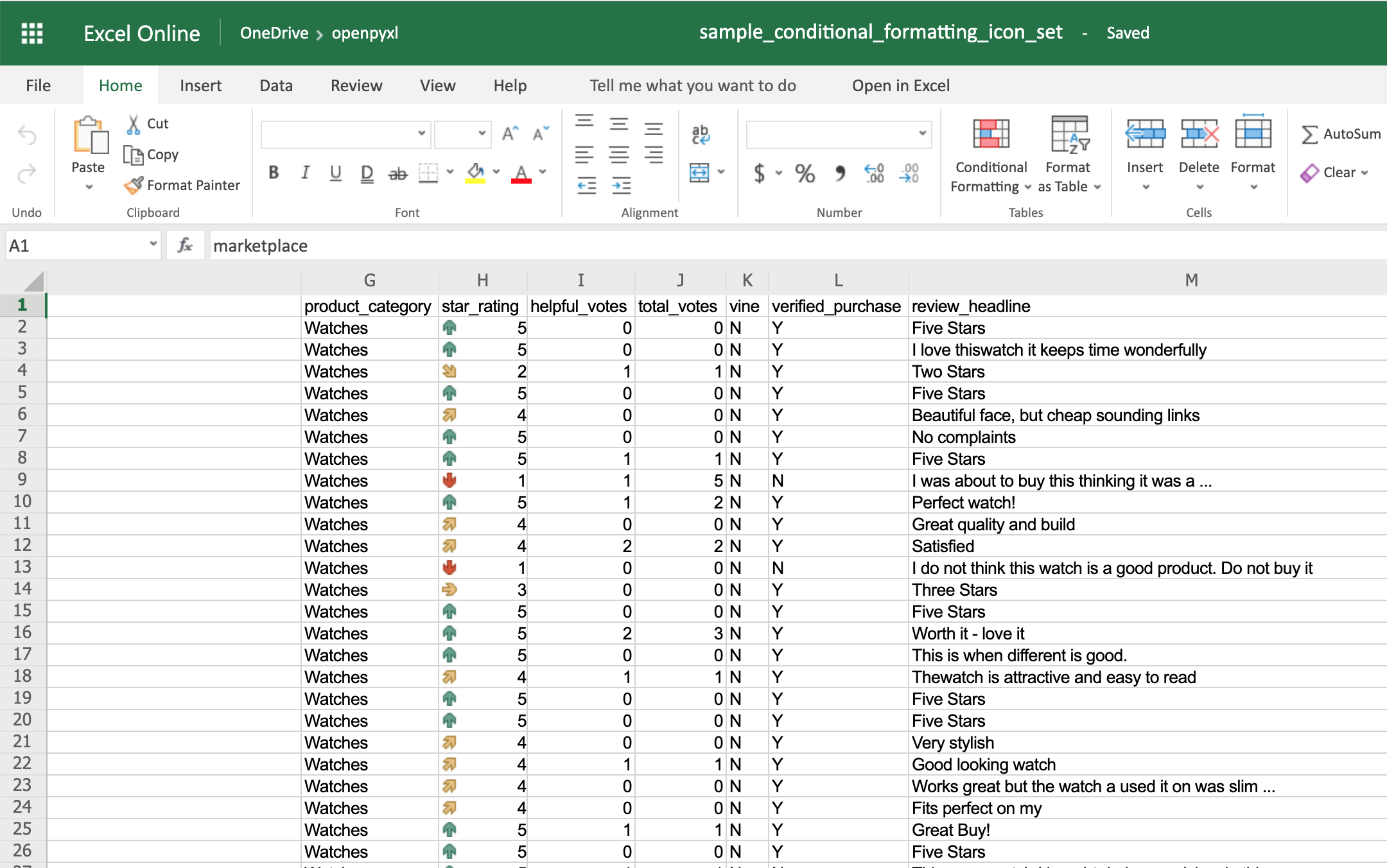
В пакете openpyxl есть полный список других значков, которые вы можете использовать, помимо стрелки.
Наконец, Панель данных позволяет создавать индикаторы выполнения:
>>> from openpyxl.formatting.rule import DataBarRule
>>> data_bar_rule = DataBarRule(start_type="num",
... start_value=1,
... end_type="num",
... end_value="5",
... color="0000FF00") # Green
>>> sheet.conditional_formatting.add("H2:H100", data_bar_rule)
>>> workbook.save("sample_conditional_formatting_data_bar.xlsx")
Теперь вы увидите зеленый индикатор выполнения, который становится тем больше, чем ближе звездный рейтинг к цифре 5:
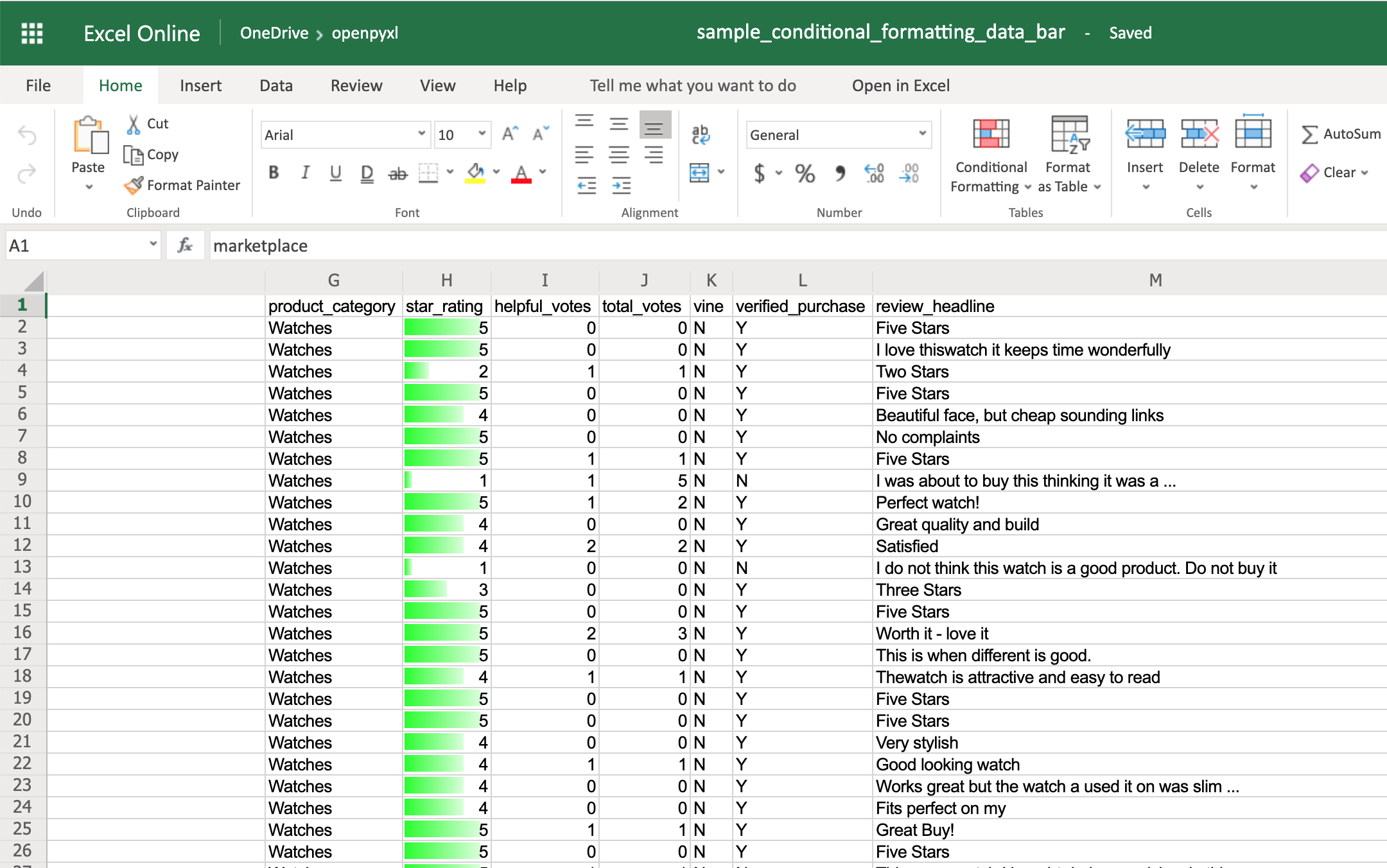
Как видите, с помощью условного форматирования можно сделать множество интересных вещей.
Здесь вы увидели только несколько примеров того, чего вы можете достичь с его помощью, но ознакомьтесь с документацией openpyxl , чтобы увидеть множество других вариантов.
Добавление изображений
Несмотря на то, что изображения - это не то, что вы часто видите в электронных таблицах, очень здорово иметь возможность добавлять их. Возможно, вы сможете использовать это в целях создания бренда или для того, чтобы сделать электронные таблицы более личными.
Чтобы иметь возможность загружать изображения в электронную таблицу с помощью openpyxl, вам необходимо установить Pillow:
$ pip install Pillow
Кроме того, вам также понадобится изображение. В этом примере вы можете взять Логотип Real Python и преобразовать его из .webp в .png с помощью онлайн-конвертера, такого как cloudconvert.com , сохраните конечный файл как logo.png и скопируйте его в корневую папку, в которой вы запускаете свои примеры:
После этого вот код, который вам понадобится для импорта этого изображения в электронную таблицу hello_word.xlsx:
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
# Let's use the hello_world spreadsheet since it has less data
workbook = load_workbook(filename="hello_world.xlsx")
sheet = workbook.active
logo = Image("logo.png")
# A bit of resizing to not fill the whole spreadsheet with the logo
logo.height = 150
logo.width = 150
sheet.add_image(logo, "A3")
workbook.save(filename="hello_world_logo.xlsx")
В вашей электронной таблице есть изображение! Вот оно:
В данном случае левый верхний угол изображения находится в выбранной вами ячейке, A3.
Добавление красивых графиков
Еще одна мощная вещь, которую вы можете сделать с электронными таблицами, - это создать невероятное разнообразие диаграмм.
Диаграммы - отличный способ быстро визуализировать и понимать огромное количество данных. Существует множество различных типов диаграмм: столбчатая диаграмма, круговая диаграмма, линейная диаграмма и так далее. openpyxl поддерживает многие из них.
Здесь вы увидите только пару примеров диаграмм, поскольку теория, лежащая в их основе, одинакова для каждого типа диаграмм:
Примечание: Некоторые типы диаграмм, которые openpyxl в настоящее время не поддерживаются, - это воронка, диаграммы Ганта, Парето, Древовидная карта, Водопад, Map и Sunburst.
Для любой диаграммы, которую вы хотите построить, вам нужно будет определить тип диаграммы: BarChart, LineChart, и так далее, а также данные, которые будут использоваться для диаграммы, которая называется Reference.
Прежде чем вы сможете построить свою диаграмму, вам необходимо определить, какие данные вы хотите видеть представленными на ней. Иногда вы можете использовать набор данных как есть, но в других случаях вам нужно немного изменить данные, чтобы получить дополнительную информацию.
Давайте начнем с создания новой рабочей книги с некоторыми примерами данных:
1from openpyxl import Workbook
2from openpyxl.chart import BarChart, Reference
3
4workbook = Workbook()
5sheet = workbook.active
6
7# Let's create some sample sales data
8rows = [
9 ["Product", "Online", "Store"],
10 [1, 30, 45],
11 [2, 40, 30],
12 [3, 40, 25],
13 [4, 50, 30],
14 [5, 30, 25],
15 [6, 25, 35],
16 [7, 20, 40],
17]
18
19for row in rows:
20 sheet.append(row)
Теперь вы начнете с создания столбчатой диаграммы, которая отображает общее количество продаж по каждому продукту:
22chart = BarChart()
23data = Reference(worksheet=sheet,
24 min_row=1,
25 max_row=8,
26 min_col=2,
27 max_col=3)
28
29chart.add_data(data, titles_from_data=True)
30sheet.add_chart(chart, "E2")
31
32workbook.save("chart.xlsx")
Вот и все. Ниже вы можете увидеть очень простую гистограмму, показывающую разницу между продажами товаров онлайн и продажами товаров в магазине:
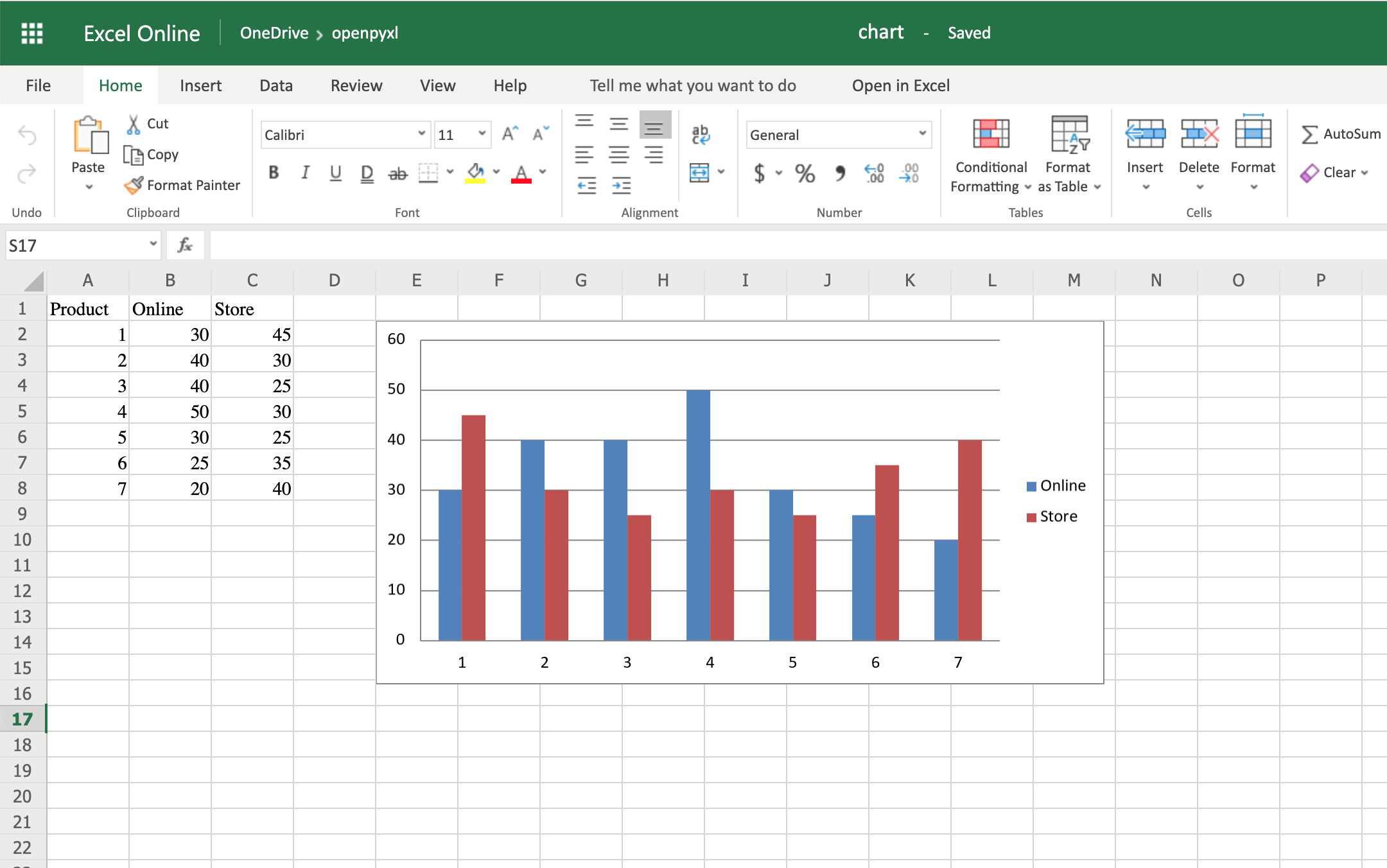
Как и в случае с изображениями, верхний левый угол диаграммы находится в ячейке, в которую вы добавили диаграмму. В вашем случае это было в ячейке E2.
Примечание: В зависимости от того, используете ли вы Microsoft Excel или альтернативу с открытым исходным кодом (LibreOffice или OpenOffice OpenOffice), диаграмма может выглядеть немного по-другому.
Попробуйте вместо этого создать линейную диаграмму , немного изменив данные:
1import random
2from openpyxl import Workbook
3from openpyxl.chart import LineChart, Reference
4
5workbook = Workbook()
6sheet = workbook.active
7
8# Let's create some sample sales data
9rows = [
10 ["", "January", "February", "March", "April",
11 "May", "June", "July", "August", "September",
12 "October", "November", "December"],
13 [1, ],
14 [2, ],
15 [3, ],
16]
17
18for row in rows:
19 sheet.append(row)
20
21for row in sheet.iter_rows(min_row=2,
22 max_row=4,
23 min_col=2,
24 max_col=13):
25 for cell in row:
26 cell.value = random.randrange(5, 100)
С помощью приведенного выше кода вы сможете сгенерировать некоторые случайные данные о продажах 3-х различных продуктов за целый год.
Как только это будет сделано, вы сможете очень легко создать линейную диаграмму со следующим кодом:
28chart = LineChart()
29data = Reference(worksheet=sheet,
30 min_row=2,
31 max_row=4,
32 min_col=1,
33 max_col=13)
34
35chart.add_data(data, from_rows=True, titles_from_data=True)
36sheet.add_chart(chart, "C6")
37
38workbook.save("line_chart.xlsx")
Вот результат выполнения приведенного выше фрагмента кода:
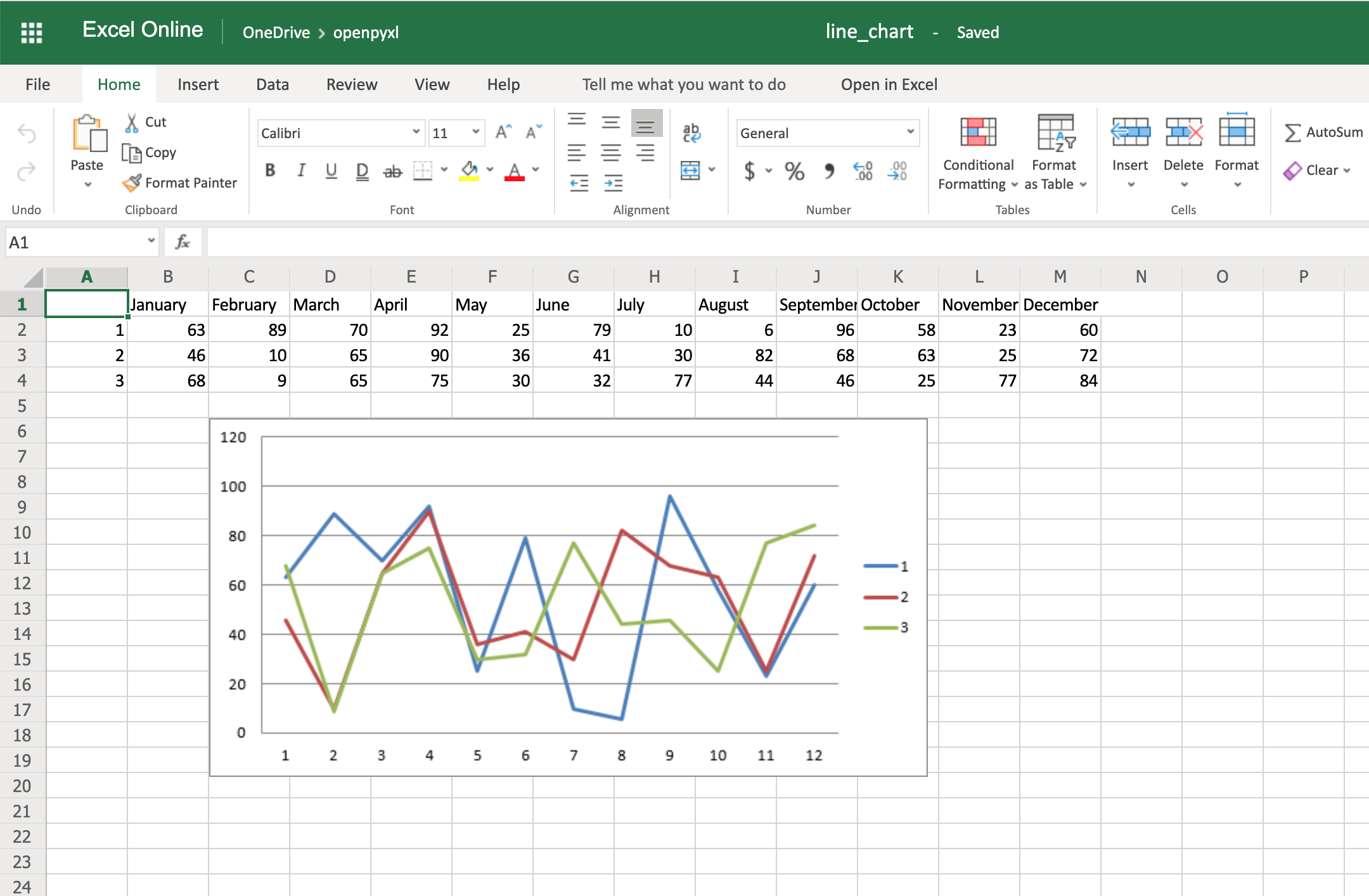
Здесь следует помнить о том факте, что при добавлении данных вы используете from_rows=True. Этот аргумент приводит к построению диаграммы построчно, а не столбцово.
В вашем примере данных вы видите, что каждый продукт содержит строку с 12 значениями (по 1 столбцу в месяц). Вот почему вы используете from_rows. Если вы не передадите этот аргумент, то по умолчанию диаграмма попытается построить график по столбцам, и вы получите сравнение продаж по месяцам.
Еще одно отличие, связанное с приведенным выше изменением аргумента, заключается в том, что наш Reference теперь начинается с первого столбца, min_col=1, а не со второго. Это изменение необходимо, поскольку диаграмма теперь ожидает, что в первом столбце будут заголовки.
Вы также можете изменить несколько других параметров, касающихся стиля диаграммы. Например, вы можете добавить на диаграмму определенные категории:
cats = Reference(worksheet=sheet,
min_row=1,
max_row=1,
min_col=2,
max_col=13)
chart.set_categories(cats)
Добавьте этот фрагмент кода перед сохранением рабочей книги, и вы увидите названия месяцев, отображаемые вместо цифр:
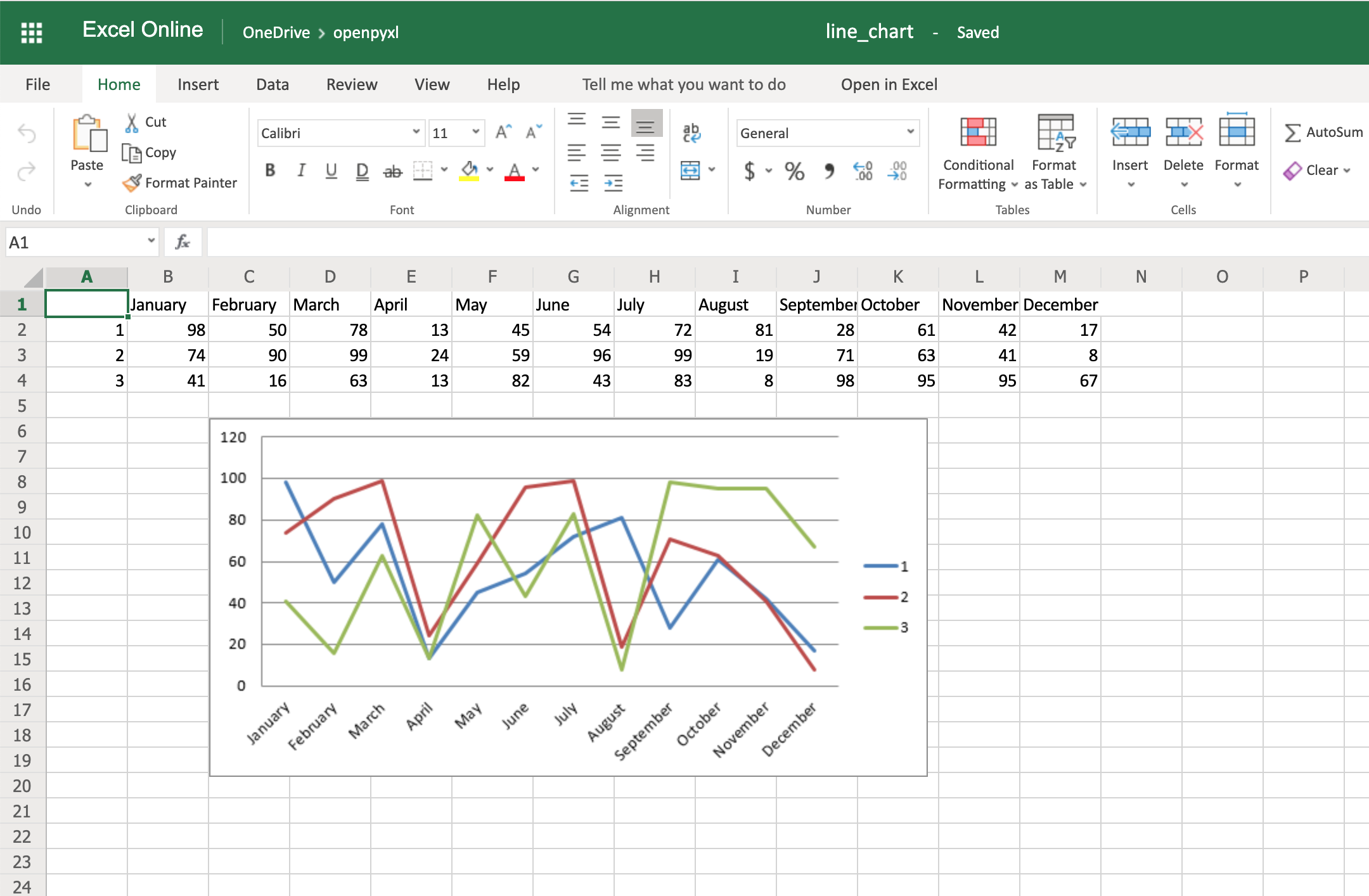
С точки зрения кода это минимальное изменение. Но с точки зрения удобочитаемости электронной таблицы, это значительно упрощает ее открытие и понимание диаграммы сразу.
Еще одна вещь, которую вы можете сделать для улучшения читаемости диаграммы, - это добавить ось. Вы можете сделать это, используя атрибуты x_axis и y_axis:
chart.x_axis.title = "Months"
chart.y_axis.title = "Sales (per unit)"
В результате будет сгенерирована электронная таблица, подобная приведенной ниже:
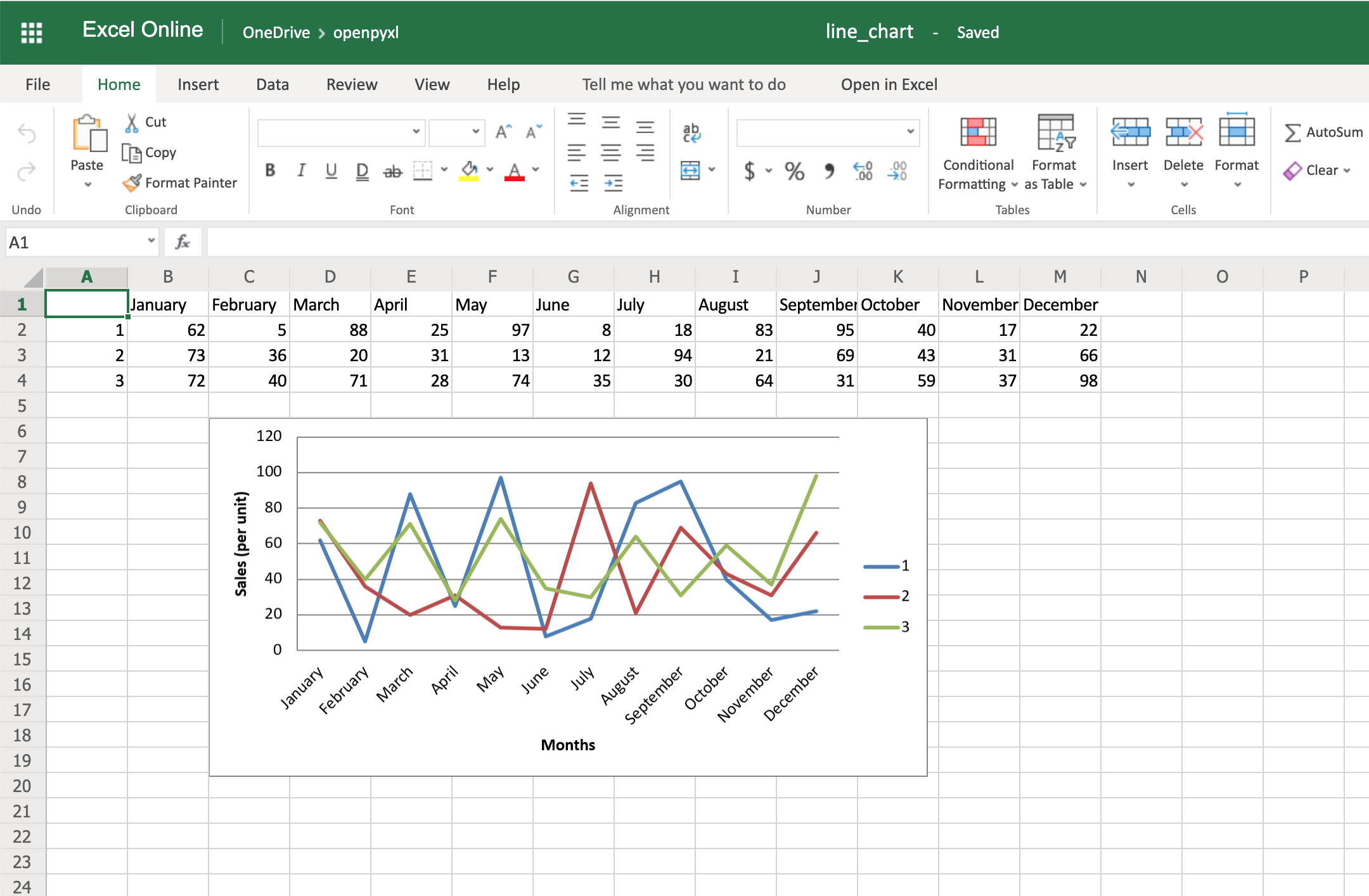
Как вы можете видеть, небольшие изменения, подобные описанным выше, значительно упрощают и ускоряют чтение вашего графика.
Также есть способ стилизовать диаграмму, используя свойство Excel по умолчанию ChartStyle. В этом случае вам нужно выбрать число от 1 до 48. В зависимости от вашего выбора, цвета вашей диаграммы также меняются:
# You can play with this by choosing any number between 1 and 48
chart.style = 24
При выбранном выше стиле все линии будут иметь некоторый оттенок оранжевого:
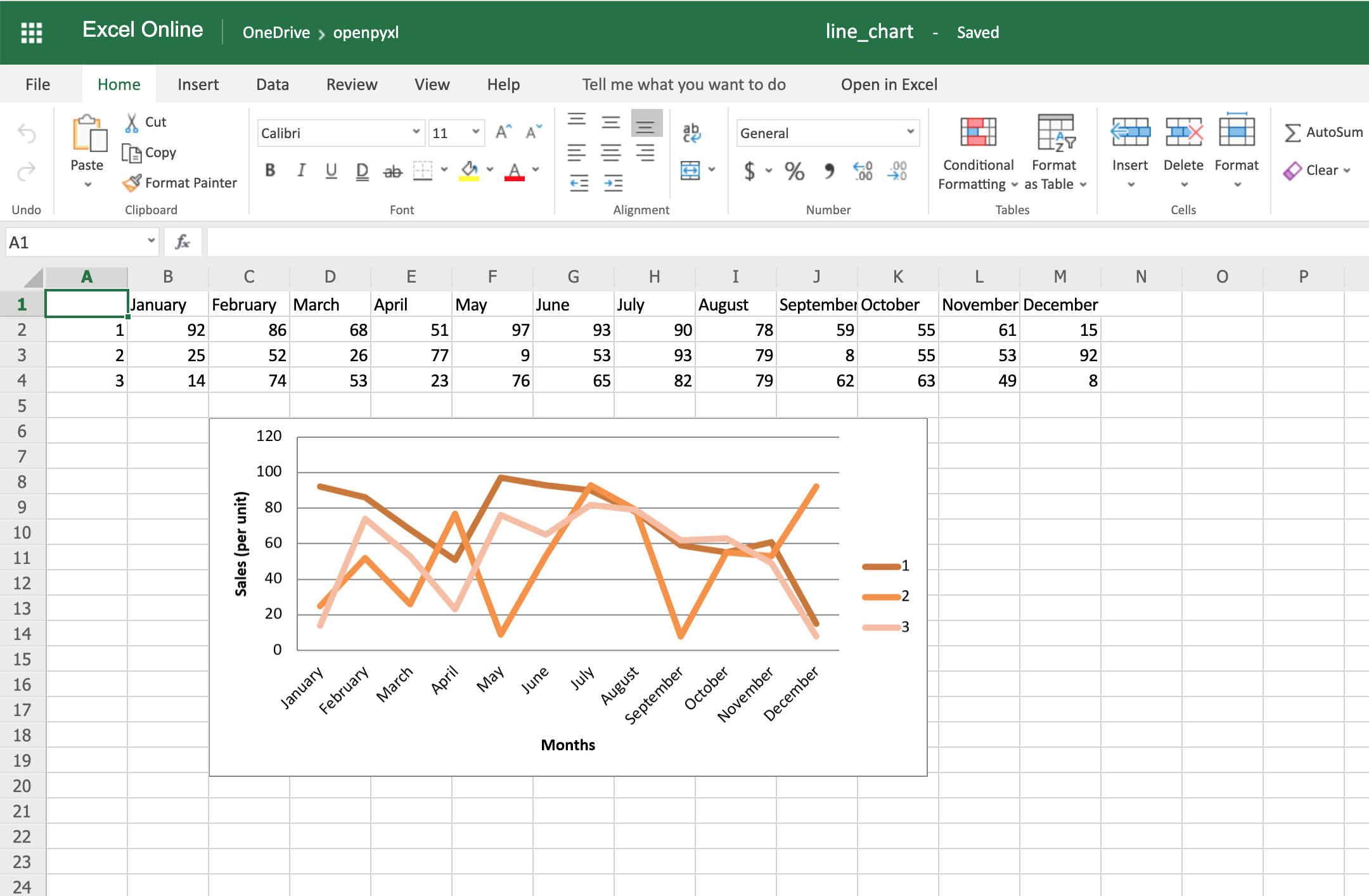
Нет четкой документации о том, как выглядит каждый номер стиля, но в этой электронной таблице есть несколько примеров доступных стилей.
Вот полный код, используемый для создания линейной диаграммы с категориями, названиями осей и стилем:
import random
from openpyxl import Workbook
from openpyxl.chart import LineChart, Reference
workbook = Workbook()
sheet = workbook.active
# Let's create some sample sales data
rows = [
["", "January", "February", "March", "April",
"May", "June", "July", "August", "September",
"October", "November", "December"],
[1, ],
[2, ],
[3, ],
]
for row in rows:
sheet.append(row)
for row in sheet.iter_rows(min_row=2,
max_row=4,
min_col=2,
max_col=13):
for cell in row:
cell.value = random.randrange(5, 100)
# Create a LineChart and add the main data
chart = LineChart()
data = Reference(worksheet=sheet,
min_row=2,
max_row=4,
min_col=1,
max_col=13)
chart.add_data(data, titles_from_data=True, from_rows=True)
# Add categories to the chart
cats = Reference(worksheet=sheet,
min_row=1,
max_row=1,
min_col=2,
max_col=13)
chart.set_categories(cats)
# Rename the X and Y Axis
chart.x_axis.title = "Months"
chart.y_axis.title = "Sales (per unit)"
# Apply a specific Style
chart.style = 24
# Save!
sheet.add_chart(chart, "C6")
workbook.save("line_chart.xlsx")
Существует гораздо больше типов диаграмм и настроек, которые вы можете применить, поэтому обязательно ознакомьтесь с документацией по пакету, если вам нужно какое-то конкретное форматирование.
Преобразование классов Python в электронную таблицу Excel
Вы уже видели, как преобразовать данные электронной таблицы Excel в классы Python, но теперь давайте сделаем наоборот.
Давайте представим, что у вас есть база данных и вы используете объектно-реляционное отображение (ORM) для преобразования объектов базы данных в классы Python. Теперь вы хотите экспортировать те же объекты в электронную таблицу.
Давайте предположим, что следующие классы данных представляют данные, поступающие из вашей базы данных о продажах продуктов:
from dataclasses import dataclass
from typing import List
@dataclass
class Sale:
quantity: int
@dataclass
class Product:
id: str
name: str
sales: List[Sale]
Теперь давайте сгенерируем некоторые случайные данные, предполагая, что вышеуказанные классы хранятся в файле db_classes.py:
1import random
2
3# Ignore these for now. You'll use them in a sec ;)
4from openpyxl import Workbook
5from openpyxl.chart import LineChart, Reference
6
7from db_classes import Product, Sale
8
9products = []
10
11# Let's create 5 products
12for idx in range(1, 6):
13 sales = []
14
15 # Create 5 months of sales
16 for _ in range(5):
17 sale = Sale(quantity=random.randrange(5, 100))
18 sales.append(sale)
19
20 product = Product(id=str(idx),
21 name="Product %s" % idx,
22 sales=sales)
23 products.append(product)
Запустив этот фрагмент кода, вы должны получить 5 продуктов с 5-месячными продажами со случайным количеством продаж за каждый месяц.
Теперь, чтобы преобразовать это в электронную таблицу, вам нужно выполнить итерацию по данным и добавить их в электронную таблицу:
25workbook = Workbook()
26sheet = workbook.active
27
28# Append column names first
29sheet.append(["Product ID", "Product Name", "Month 1",
30 "Month 2", "Month 3", "Month 4", "Month 5"])
31
32# Append the data
33for product in products:
34 data = [product.id, product.name]
35 for sale in product.sales:
36 data.append(sale.quantity)
37 sheet.append(data)
Вот и все. Это должно позволить вам создать электронную таблицу с некоторыми данными, полученными из вашей базы данных.
Однако, почему бы не воспользоваться некоторыми из тех интересных знаний, которые вы недавно получили, и не добавить диаграмму, чтобы более наглядно отобразить эти данные?
Хорошо, тогда вы, вероятно, могли бы сделать что-то вроде этого:
38chart = LineChart()
39data = Reference(worksheet=sheet,
40 min_row=2,
41 max_row=6,
42 min_col=2,
43 max_col=7)
44
45chart.add_data(data, titles_from_data=True, from_rows=True)
46sheet.add_chart(chart, "B8")
47
48cats = Reference(worksheet=sheet,
49 min_row=1,
50 max_row=1,
51 min_col=3,
52 max_col=7)
53chart.set_categories(cats)
54
55chart.x_axis.title = "Months"
56chart.y_axis.title = "Sales (per unit)"
57
58workbook.save(filename="oop_sample.xlsx")
Теперь мы поговорим! Вот электронная таблица, созданная на основе объектов базы данных, с диаграммой и всем остальным:
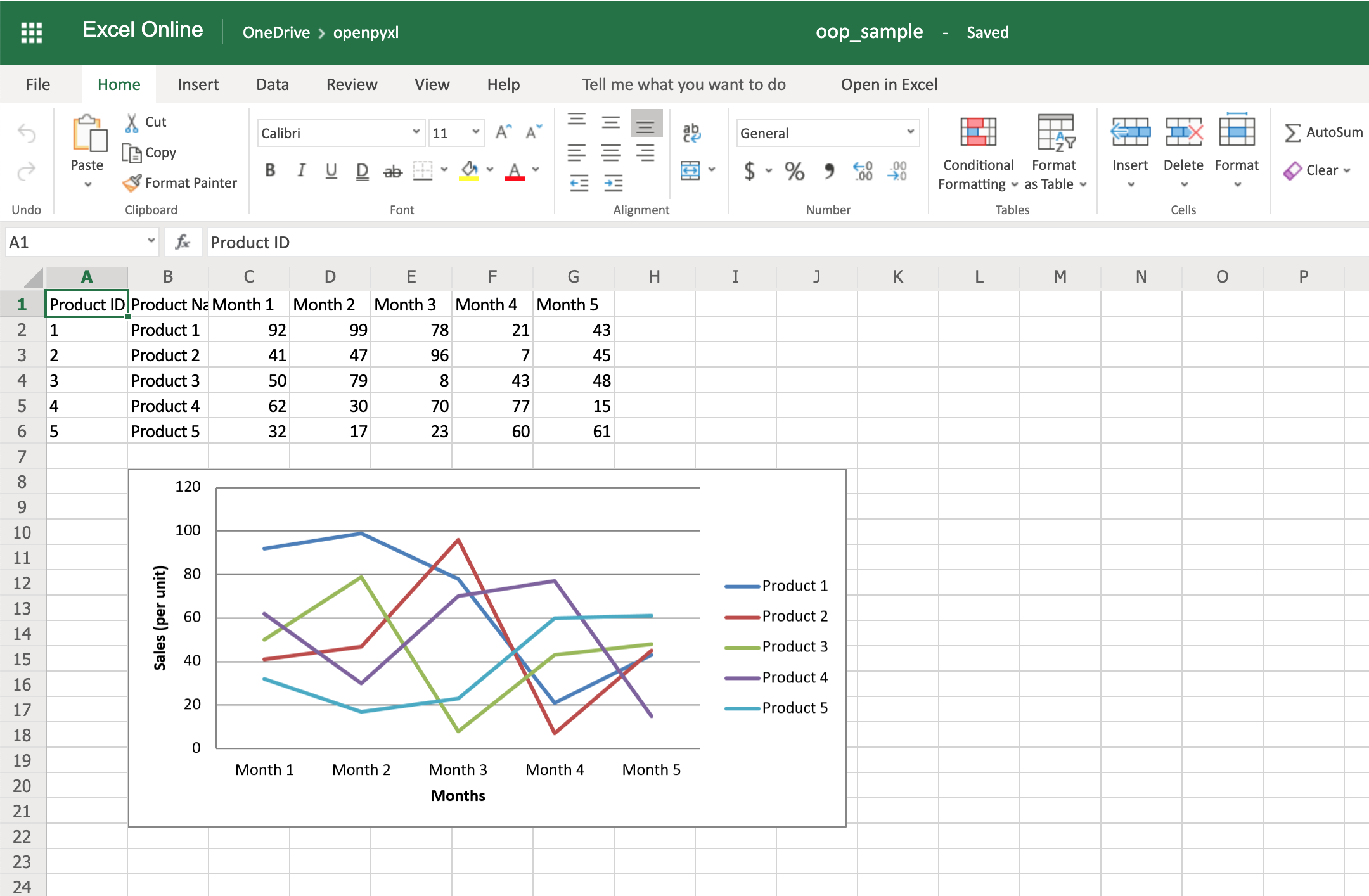
Это отличный способ закрепить ваши новые знания о графиках!
Бонус: Работа с Пандами
Несмотря на то, что вы можете использовать Pandas для работы с файлами Excel, есть несколько вещей, которые вы либо не сможете выполнить с помощью Pandas, либо вам лучше использовать только openpyxl непосредственно.
Например, некоторые из преимуществ использования openpyxl - это возможность легко настраивать электронную таблицу с помощью стилей, условного форматирования и тому подобного.
Но знаешь что, тебе не нужно беспокоиться о выборе. Фактически, openpyxl поддерживает как преобразование данных из фрейма данных Pandas в рабочую книгу, так и наоборот, преобразование openpyxl рабочей книги в фрейм данных Pandas.
Примечание: Если вы новичок в Pandas, заранее ознакомьтесь с нашим курсом по фреймворкам данных Pandas.
Перво-наперво, не забудьте установить пакет pandas:
$ pip install pandas
Затем давайте создадим пример фрейма данных:
1import pandas as pd
2
3data = {
4 "Product Name": ["Product 1", "Product 2"],
5 "Sales Month 1": [10, 20],
6 "Sales Month 2": [5, 35],
7}
8df = pd.DataFrame(data)
Теперь, когда у вас есть некоторые данные, вы можете использовать .dataframe_to_rows() для преобразования их из фрейма данных в рабочий лист:
10from openpyxl import Workbook
11from openpyxl.utils.dataframe import dataframe_to_rows
12
13workbook = Workbook()
14sheet = workbook.active
15
16for row in dataframe_to_rows(df, index=False, header=True):
17 sheet.append(row)
18
19workbook.save("pandas.xlsx")
Вы должны увидеть электронную таблицу, которая выглядит следующим образом:
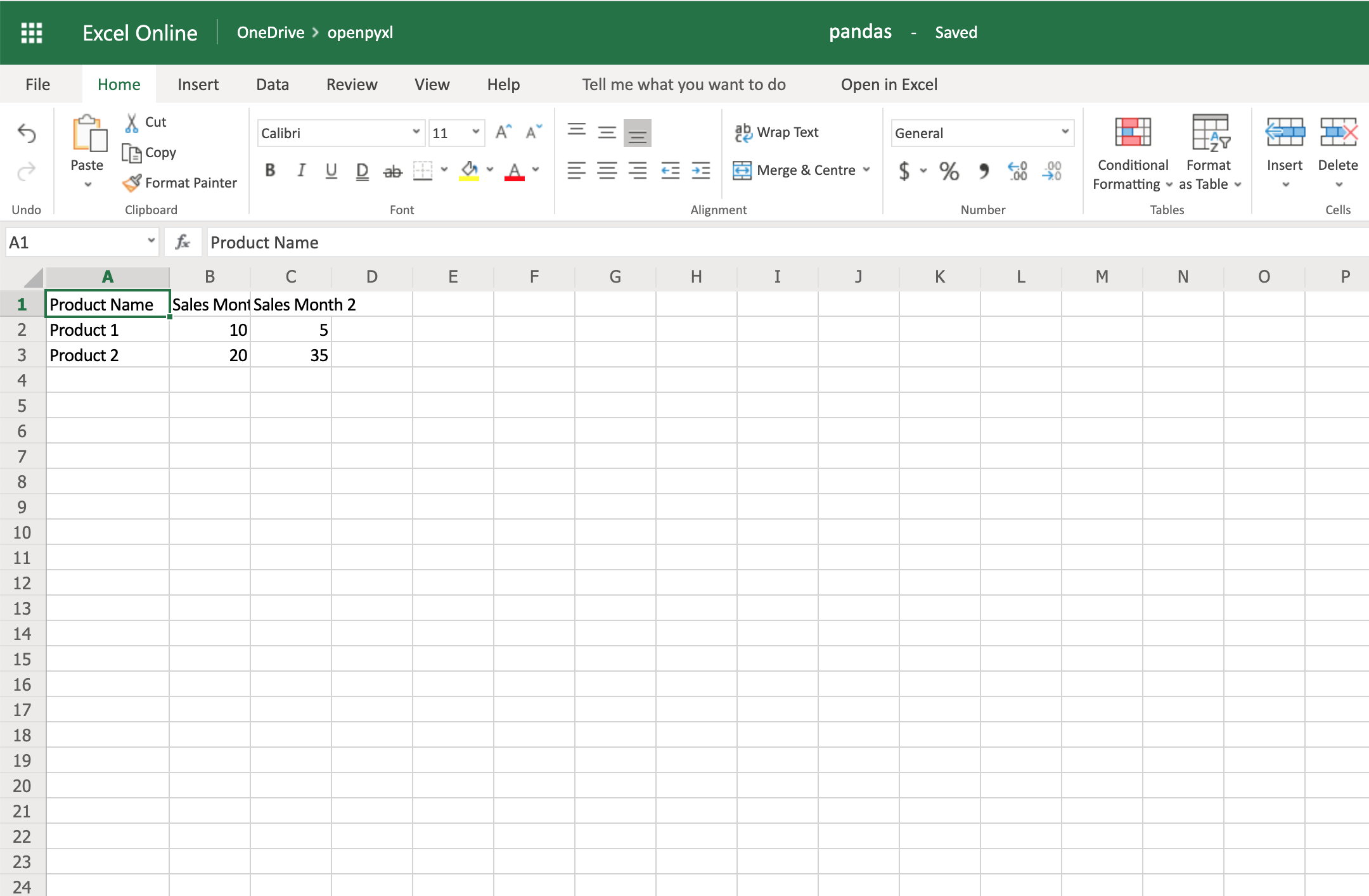
Если вы хотите добавить индекс фрейма данных , вы можете изменить index=True, и это добавит индекс каждой строки в вашу электронную таблицу.
С другой стороны, если вы хотите преобразовать электронную таблицу во фрейм данных, вы также можете сделать это очень простым способом, например:
import pandas as pd
from openpyxl import load_workbook
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
values = sheet.values
df = pd.DataFrame(values)
В качестве альтернативы, если вы хотите добавить правильные заголовки и использовать, например, идентификатор обзора в качестве индекса, вы также можете сделать это следующим образом:
import pandas as pd
from openpyxl import load_workbook
from mapping import REVIEW_ID
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
data = sheet.values
# Set the first row as the columns for the DataFrame
cols = next(data)
data = list(data)
# Set the field "review_id" as the indexes for each row
idx = [row[REVIEW_ID] for row in data]
df = pd.DataFrame(data, index=idx, columns=cols)
Использование индексов и столбцов позволяет вам легко получать доступ к данным из вашего фрейма данных:
>>> df.columns
Index(['marketplace', 'customer_id', 'review_id', 'product_id',
'product_parent', 'product_title', 'product_category', 'star_rating',
'helpful_votes', 'total_votes', 'vine', 'verified_purchase',
'review_headline', 'review_body', 'review_date'],
dtype='object')
>>> # Get first 10 reviews' star rating
>>> df["star_rating"][:10]
R3O9SGZBVQBV76 5
RKH8BNC3L5DLF 5
R2HLE8WKZSU3NL 2
R31U3UH5AZ42LL 5
R2SV659OUJ945Y 4
RA51CP8TR5A2L 5
RB2Q7DLDN6TH6 5
R2RHFJV0UYBK3Y 1
R2Z6JOQ94LFHEP 5
RX27XIIWY5JPB 4
Name: star_rating, dtype: int64
>>> # Grab review with id "R2EQL1V1L6E0C9", using the index
>>> df.loc["R2EQL1V1L6E0C9"]
marketplace US
customer_id 15305006
review_id R2EQL1V1L6E0C9
product_id B004LURNO6
product_parent 892860326
review_headline Five Stars
review_body Love it
review_date 2015-08-31
Name: R2EQL1V1L6E0C9, dtype: object
Итак, независимо от того, хотите ли вы использовать openpyxl для улучшения вашего набора данных Pandas или использовать Pandas для выполнения сложной алгебры, теперь вы знаете, как переключаться между обоими пакетами.
Заключение
Фух, после такого долгого чтения вы теперь знаете, как работать с электронными таблицами на Python! Вы можете положиться на openpyxl, вашего надежного компаньона, в том, что касается:
- Извлекайте ценную информацию из электронных таблиц на языке Python
- Создавайте свои собственные электронные таблицы, независимо от уровня сложности
- Добавьте в свои электронные таблицы интересные функции, такие как условное форматирование или диаграммы
Есть еще несколько вещей, которые вы можете сделать с помощью openpyxl, которые, возможно, не были описаны в этом руководстве, но вы всегда можете посетить официальный веб-сайт документации по пакету, чтобы узнайть об этом побольше. Вы даже можете рискнуть проверить его исходный код и усовершенствовать пакет еще больше.